






Java基础
1、对this和super的理解
调用结构:属性、对象、构造器
this调用属性、方法:表示当前对象或正在创建的对象
调用构造器:表示调用调用当前类中其他构造器
this和super(默认)只能有一个,且在首行声明
2、OOP面向对象的理解
面向对象是利用语言对现实事物进行抽象,面向对象具有以下特征:
封装:把数据和操作数据的方法绑定起来,对数据的访问只能通过已经定义的接口
继承:从已有类得到继承信息创建新类的过程
子类继承父类所有的属性和方法,可能受到封装性的影响无法直接使用
不继承父类的构造器,只通过super(args)方式调用;this和super默认super
多态:允许不同子类型对象对同一消息做出不同响应
前提:类的继承、方法的重写
虚拟方法调用:编译看左边,运行看右边 属性不存在多态性 不能调用子类特有方法,调用需要向下转型
3、重载和重写的区别
1、首先重载发生在本类,重写发生在父类与子类之间
2、重写权限子类大于等于父类,重载无所谓
3、重写的返回值类型、方法名及参数列表都要相同
4、重载只保证方法名相同,参数列表一定不同
4、深拷贝与浅拷贝
数据分为基本数据类型和引用数据类型:
基本数据类型:直接存储在栈(stack)中的数据
引用数据类型:栈中存储对象的引用,真实数据存放在堆中
浅拷贝:拷贝基本数据类型的值,以及某个对象的引用地址,而不会复制对象本身,新旧对象共享同一块内存
深拷贝(clone):拷贝基本数据类型的值,会针对对象的引用地址所指向的对象进行复制,新对象和原对象不共享内存
赋值与浅拷贝的区别:赋值没有产生新的对象,只是对原对象的引用
5、自动装箱与自动拆箱
自动装箱:基本类型数据——>包装类对象
自动拆箱:包装类对象——>基本类型数据
为何自动拆装箱:List集合如果要放整形的话,只能放对象,不能是基本数据类型
6、==与equals的区别
equals只能比较引用数据类型的值,他的底层就是==,如果未被重写,比较的就是引用数据类型的地址,如果进行重写,往往比较的是对象的属性内容。
==对于基本数据类型比较值,引用数据类型比较地址。
7、Object中的方法
clone(深拷贝)、equals、finalize(通知销毁)、getClass、hashCode、notify、notifyAll、wait、toString
8、JDK和JRE的区别
JDK(Java Decelopment Kit) Java开发工具包
JRE(Java Runtime Environment) Java运行环境
JDK中包含JRE和开发工具集(比如javac编译工具),JDK中有一个名为jre的目录,里面包含两个文件夹bin和lib,bin就是JVM,lib就是JVM运行所需要的类库
Java中级
1、static关键字的理解
静态的 修饰:属性、方法、代码块、内部类 随着类的加载而加载
2、final关键字的理解
修饰:类、方法、变量
类:不能被继承 String、System、StringBuffer
方法:不能被重写
常量:没有set方法,必须初始化(显式赋值、初始化块赋值、构造器中)
3、abstract关键字的理解
修饰:类、方法
抽象类:不能创建对象、只能被继承、子类必须重写父类抽象方法并提供方法体、有构造方法,供子类创建对象时初始化父类成员变量
4、接口
特点:无构造器、无初始化块、如果实现类是抽象类,可以不重写接口方法
成员列表:公共的静态常量、公共抽象方法、1.8后 公共静态方法、公共默认方法、1.9后 私有方法
类优先原则
当一个类,既继承一个父类,又实现若干个接口时,父类中的成员方法与接口中的抽象方法重名,子类就近选择执行父类的成员方法。
接口冲突(左右为难)
当一个类同时实现了多个父接口,而多个父接口中包含方法签名相同的默认方法时,只能显式保留一个
5、接口和抽象类的区别
抽象类除了不能实例化外满足类的特征:单继承、有构造器、抽象方法不能是private、可以有成员变量
接口需要被实现:多继承、无构造器、抽象方法只能是public、只有静态常量
6、注解
四个元注解
Retention生命周期 Source、class、Runtime
Target位置
Inherited允许子类继承父类注解
Documented是否被生成到api文档
7、实例变量的赋值顺序
成员变量默认初始化——>显式初始化——>构造器初始化——>对象.属性
8、 包装类的缓冲对象
存储:方法区
Integer、Long、Byte、Short -128~127
Character 0~127
Boolean true/false
Float、Double 无
相同包装类之间比较,包装类的缓冲对象
不同包装类和基本数据类型比较时先自动类型转换(自动拆箱+自动类型提升)
不同包装类之间不能比较 编译出错
9、String
final不能被继承、Serializable接口、Comparable接口(对象能比较大小)
jdk8声明为 private final char value[] 存储在char型的value常量数组中,一旦初始化,地址不可变
jdk9开始,为节省空间,存储在byte型的value常量数组中
因为字符串对象设计为不可变,用字符串常量池来保存常量对象。jdk7之前存储在方法区,jdk7及之后存储在堆空间。
10、String的不可变性体现在哪里
1、对字符串进行赋值时,需要重新指定一个字符串常量的位置进行赋值,不能在原位置进行修改
2、对字符串进行拼接时,重新开辟一个空间保存,不能在原位置修改
11、new String("a")+new String("b")在内存中创建了几个对象
6个
字符串拼接会创建StringBuilder对象
堆
常量池中对象的引用
常量+常量=常量
常量+变量=堆
String s1="hello";常量池
String s2="world";常量池
String s3=s1+s2;变量+变量=堆
String s4="hello"+s2;常量+变量=堆
String s5="hello"+"world";常量+常量=常量池
12、字符串的可变序列 StringBuilder、StringBuffer
StringBuffer jdk1.0声明 线程安全 底层使用char[] jdk9开始使用byte[]
StringBuilder jdk5.0声明 线程不安全 底层使用char[] jdk9开始使用byte[]
StringBuilder sBuilder=new StringBuilder("abc")
创建长度为16+"abc".length长度的char型数组,添加元素时,从索引0时开始添加,容量满时,默认扩容为原容量 2倍+2,并将原有value数组中值复制过来
13、序列化
序列化:Java对象从内存中保存到文件或通过网络传输出去(出内存)
反序列化:文件数据或网络数据还原为内存中的Java对象
14、IO流的分类
按数据的流向分为:输入流和输出流
输入流:数据从其他设备读入到内存的流,以InputStream或Reader结尾
输出流:读出内存,以OutputStream或Writer结尾
按数据单位分为:字符流和字节流
字符流:以字符为单位读写数据的流,一般读写文本文件Reader、Writer结尾
字节流:以字节为单位读写数据,一般读写MP3、avi等文件,以InputStream或OutputStream结尾
按IO流的角色分为:节点流和处理流
节点流:直接从数据源或目的地读取数据
处理流:如BufferInputStream
15、throw和throws的区别
throw:作用在方法内,表示抛出具体异常,由方法体内的语句处理;一定抛出了异常;
throws:作用在方法的声明上,表示抛出异常,由调用者来进行异常处理;可能出现异常,不一定会发生异常;
16、try-catch-finally
输出先finally在try或者catch
从try到finally入栈执行
17、线程和进程的关系
进程 process:程序的一次执行过程,或是正在内存中运行的应用程序。操作系统调度和分配资源的最小单位,程序是静态的,进程是动态的
线程 thread:进程中一条执行路径 一个进程中至少有一个线程。为 CPU 调度和执行的最小单位 分时调度与抢占式调度
18、并发与并行的区别
并行(parallel):多条指令同一时刻运行,宏观微观都是同一时刻运行
并发(concurrency):多条指令同一时段运行,宏观上同一时刻,微观上依次执行
19、线程的创建方式
1、继承Thread类重写run方法(线程执行体)
2、实现Runable接口重写run方法
3、实现Callable接口
4、使用线程池
20、线程状态的转换
新建new——>就绪Runable<——>运行Running——>死亡Dead
新建——>就绪:start()启动线程
就绪——>运行:run()获得cpu执行权 run()方法由 JVM 调用,什么时候调用,执行的过程控制都有操作系统的CPU 调度决定
运行——>就绪:失去cpu执行权或 yield()
阻塞blocked:计时等待、锁阻塞、无限等待
运行——>阻塞:suspend(挂起)、wait()、join(在A中通过B调用join,阻塞A直到B运行完成)、sleep()、等待同步锁
阻塞——>就绪:resume(恢复)、wait时间到、notify()/notifyAll()、join线程结束、sleep时间到、获取同步锁
运行——>死亡:run正常结束、出现Error或Exception、stop()
21、线程安全
同步代码块或同步方法
synchronized(同步监视器){多个线程必须使用同一个同步监视器}
Lock同步锁ReentrantLock lock与unlock方法
22、wait和sleep的区别
sleep:属于Thread类、进入阻塞状态不释放锁、sleep时间结束
wait:属于Object类、进入阻塞状态同时释放锁、wait时间到或notify
wait必须配合synchronized使用,不然会IllegalMonitorStateException
23、死锁
不同的线程分别占用对方需要的同步资源不放弃 , 都在等待对方放弃自己需要的同步资源,就形成了线程的死锁。
诱发死锁的原因:
互斥条件:基本无法破坏,线程需要互斥来保证安全
占用且等待:一次性分配所有资源,就不存在等待的问题
不可抢占:占用部分资源的线程在进一步申请其他资源时,如果申请不到,就主动释放自身资源
循环等待:将资源改为线性顺序,按序申请
Java高级
1、集合框架分类
单列集合Collection
List有序的、可重复的数据:ArrayList、LinkedList、Vector
Set无序的、不可重复的数据:HashSet-LinkedHashSet、TreeSet
双列集合Map
HashMap-LinkedHashMap
TreeMap
Hashtable-Properties
ConcurrentHashMap
List判断相等的要求:重写equals方法
向Set中添加元素的要求:重写equals和hashCode方法
2、ArrayList添加元素
线程不安全、底层是object[]、查询 添加
* 增:
* add(Object obj)
* addAll(Collection coll)
* 删:
* remove(Object obj)
* remove(int index)
* 改:
* set(int index, Object ele)
* 查:
* get(int index)
* 插:
* add(int index, Object ele)
* addAll(int index, Collection eles)
* 长度:
* size()
* 遍历:
* iterator()
* foreach
* for
jdk7版本时,new ArrayList<>()会在底层创建一个长度为10的object类型数组。在jdk8时,会采用动态创造数组的方式,在首次添加元素时初始化这个长度为10的数组。
当前已使用长度size+1>数组长度,调用grow方法扩容,默认扩容为原来的1.5倍,并将原数组复制
3、new ArrayList(10)时扩容几次
指定了集合初始长度,并没有扩容
4、数组与List之间的转换
数组——>List:jdk中Arrays工具类的asList方法
修改数组,List受影响
List——> 数组:List的toArray方法
修改List,数组不受影响,底层堆数组进行拷贝
5、LinkedList
双向链表 线程不安全 有序的、可重复的数据
6、Vector
List古老实现类 线程安全 底层Object[]
创建对象时初始化长度为10的数组,扩容为原长度的2倍
7、HashSet添加元素
底层是HashMap(用HashMap的key来存储,value默认为object) 数组+单向链表+红黑树 用于过滤重复数据 非线程安全 集合元素可以是null
向HashSet添加元素的过程:
1、向HashSet添加元素时,调用hashCode方法得到该对象的hashCode值,根据hashCode值,通过某个函数得到该对象在底层数组中的存储位置;
2、如果数组该位置没有元素,则直接添加
3、如果该位置有元素,比较其hashCode值,若不相等,通过链表的方式添加;
4、若两个元素的hashCode值相等,则调用equals方法比较,相等则添加失败,不相等则通过链表添加。
8、LinkedHashSet
HashSet的子类 底层:LinkedHashMap 数组+单向链表+红黑树+双向链表(记录元素的先后顺序)
9、TreeSet
添加相同类型的元素 不用考虑重写equals和hashCode方法,比较元素相等的标准是自然排序或定制排序(compareTo或compare的返回值)
10、Set无序性的理解
无序性不等同于随机性,不是指添加元素顺序与遍历元素顺序的不一致。无序性指set元素位置不像ArrayList中依次紧密排列,set是根据hashCode值,进行排列,此位置不是依次排列的,表现为无序性。
11、HashMap理解
线程不安全 key和value可以为null 数组(key的二次哈希+存储值)+单向链表(解决哈希冲突+存储值)+红黑树(提高性能+存储值)
HashMap.Node<K,V>[] table;
static class Node<K,V> implements Map.Entry<K,V>{
final int hash;
final K key;
V value;
HashMap.Node<K,V> next;
}
key不可重复、无序 所有的key构成一个set集合(重写equals和hashCode)遍历:Set keySet()
value可重复、无序 所有的value构成一个Collection集合(重写equals) 遍历:Collection values()
HashMap和key-value构成一个Entry,所有的Entry为一个Set集合 遍历:Set entrySet()
* 增:
* put(key,value)
* putAll(Map)
* 删:
* Object(value) remove(key)
* 改:
* put(key,value)
* putAll(Map)
* 查:
* get(key)
* 长度:
* size()
* 遍历:
* 遍历key集:Set keySet()
* 遍历value集:Collection values()
* 遍历entry集:Set entrySet()
12、HashMap添加元素(put)的过程
在jdk7版本中,当new HashMap<>()时,底层会创建并初始化一个长度为16的Entry类型的数组,调用put方法添加元素时,会将key和value封装在一个Entry对象中:
首先,调用key所在类的hashCode方法,得到哈希值1,此值右移16位,两个值进行异或运算得到哈希值2,哈希值经过IndexFor方法后得到数组索引i
如果此位置i上没有元素,则直接添加
如果此位置i上有元素,则判断两元素的hash值2:
如果哈希值2不同,则通过单向链表添加(头插法)
如果哈希值2相同,继续调用equals方法判断:
如果不同,则使用单向链表添加
如果相同,则认为两个key相同,用新的value替代原value
在jdk8版本中,主要有4个不同点:
首先,在new HashMap<>()时没有初始化数组,而是首次添加元素时初始化
第二,用Node数组代替Enty数组
第三,链表节点插入采用尾插法
第四,新增红黑树结构存储
寻址算法:
调用key的hashCode方法得到哈希值1
将哈希值1右移16位得到的值与哈希值1进行异或运算得到哈希值2
将数组长度-1与哈希值2进行位于运算得到索引
13、为什么HashMap的数组长度一定是2的n次幂
hashMap底层计算数组索引使用的是位与运算,如果不是2的n次幂无法进行位于运算,同时位与运算比取模效率高
扩容机制:
当元素个数达到临界值(数组长度*0.75 默认12)时考虑扩容,默认扩容为原来2倍。
当单链表长度达到8并且数组长度大于64转变为红黑树
当红黑树节点小于6时退化为链表
14、HashMap扩容时的死循环问题
线程一:读取当前hashMap数据,比如A、B,当准备扩容时,线程二介入,由于是头插法,线程二执行结束后变成了B的next是A,线程一再将A移入新的链表,再将B插到链头,由于线程二的介入,B的next是A,就造成了死循环
jdk8进行调整,采用尾插法,避免了死循环
15、LinkedHashMap
HashMap的子类、数组+单向链表+红黑树+双向链表(记录添加元素的顺序)
16、TreeMap
红黑树 可以按照key-value中key的属性大小顺序进行遍历(compareTo)
17、Hashtable和Properties
Hashtable:古老实现类、线程安全、不可以添加null和key或value、数组+单向链表
Properties:Hashtable的子类、key和value都是String类型、常用于处理属性文件
18、Hashtable和HashMap的区别
Hashtable:数组+链表 、线程安全、一次hash、扩容当前容量2倍+1、key和value不能是null
HashMap:数组+单向链表+红黑树、线程不安全、两次hash、扩容为2倍、key和value可以是null
19、Iterable接口
Collection 接口继承了 java.lang.Iterable 接口,该接口有一个 iterator()方法,那么所有实现了 Collection 接口的集合类都有一个 iterator()方法,用以返回一个实现了 Iterator接口的对象。
20、对Class类的理解
针对编写的.java用javac.exe进行编辑,会生成一个或多个.class字节码文件,接着用java.exe命令进行解释运行。这个运行过程中,.class文件会被类的加载器加载到内存中,并存放到方法区,这些内存中一个个.class文件对应的结构为一个个Class实例。
21、获取Class的四种方式
1、运行时类的静态属性class
2、运行时类的对象的getClass方法
3、Class的静态方法forName(类的全类名)
4、 类的加载器
22、类的生命周期
类在内存中完整的生命周期为:加载——>使用——>卸载。其中加载,分为装载、链接,初始化三个阶段。
装载:将.class文件读入内存,使用类的加载器为之创建一个Class对象
链接分为三个阶段:
验证:确保加载的类的信息符合JVM规范(以cafebabe开头)
准备:为类变量(static)分配内存并初始化默认值
初始化:类中的符号引用(常量名)替换为直接引用(地址)
初始化:执行类的构造器<clinit>方法的过程,同时对静态变量,静态代码块初始化
使用:JVM开始从入口方法执行用户代码
卸载:Class对象的销毁,最后JVM退出内存
23、类的加载器
启动类加载器(BootStrap ClassLoader):由C/C++实现,加载Java核心库
扩展类加载器(ExtClassLoader):由Java语言编写,是ClassLoader的子类
应用类加载器(AppClassLoader):ClassLoader的子类,加载classpath下的类,也就是开发者编写的类
自定义类加载器:需要开发者继承ClassLoader类,如tomcat、spring等框架的内部实现
24、类的加载器的作用
将.class字节码文件加载到内存中,在堆中生成java.lang.Class文件,作为方法区中类数据访问入口。
25、双亲委派机制
类的加载器体系并不是继承关系,而是委派体系。
当类的加载器接收到加载类的请求时,首先不会自己尝试加载这个类,而是委托自己的父类加载器完成,直到启动类加载器,然后向下加载。
原因:
1、避免某个类被重复加载(父类已经加载的不许重复加载)
2、保证类库API不会被修改
26、Java内存解析
堆heap:存放对象实例
栈stack:存储局部变量、基本数据类型、对象引用
方法区Method Area:被虚拟机加载的类信息、即时编译器编译后的代码、常量、静态变量
MySQL
1、SQL
select 字段列表 from tableName where 条件 group by 分组字段 having 分组后条件 order by排序 limit分页参数
聚合函数:
count、max、min、avg、sum
聚合函数不对null进行计算
where和having的区别:
执行时机不同:where是分组之前的过滤,不满足where条件,不参与分组,而having、是分组之后对结果进行过滤
判断条件不同:where不能对聚合函数进行判断,而having可以
select语句执行的顺序
from子句、where子句、group by分组子句、聚集函数、having子句、select的字段、order by排序
2、MySQL事务的特性(ACID)
原子性:事务是不可分割的最小单元,要么全部成功,要么全部失败
一致性:事务完成时,所有数据都保持一致(A向B转账,A减款B赠款)
隔离性:事务在不受外部并发操作影响的独立环境下运行(A向B转账,不能受其他事务影响)
持久性:一旦提交或回滚,对数据的影响是永久的
3、事务隔离级别
解决并发事务带来的问题:
读未提交read-uncommitted 脏读 不可重复读 幻读
读已提交read-committed 不可重复读 幻读
可重复读repeatable-read(MySQL默认) 幻读
串行化serializable(一个事务提交后才能进行另一个事务)
并发事务带来的问题:
脏读:事务A正在访问数据并对数据进行修改,而修改并未提交,此时事务B访问了这个数据,此数据为脏数据(事务读到了另一个事务没有提交的数据)
不可重复读:事务A多次读同一数据,事务B在A读取过程中对数据进行更新并提交,导致事务A前后读取的数据不一致(一个事务先后读取同一条记录,但两次读取的数据不同)
幻读:一个事务按条件查询数据时,没有对应数据行,但在插入数据时,又发现这条数据已经存在
4、如何定位慢查询
慢查询指的是sql响应速度慢
在调试阶段, 可以开启MySQL自带的慢日志查询功能,只要sql执行时间超过设置的阈值,就会记录到日志文件中,我们就可以找到慢sql了
也可以使用一些监控工具,比如阿尔萨斯、Skywalking,可以看到哪个接口比较慢,能够看到sql执行时间,从而定位sql
开启mysql慢日志查询开关
slow_query_log=1
设置慢日志时间2s,超过2s就会记录
long_query_time=2
5、SQL执行很慢,如何优化
找到SQL慢的原因:使用explain执行计划
passible key 当前sql可能会用到的索引 key 当前sql实际命中的索引 key_len 索引占用大小 Extra 额外的优化建议
Using where;Using Index查找使用了索引,需要的数据都在索引列中找到,不需要回表查询
Using index condition查找使用了索引,但需要回表查询
type sql连接的类型,性能由好到坏:
null sql执行没有使用到表
system 查询系统中的表
const 根据主键或唯一索引查询
eq_ref 多表联查使用主键或唯一索引
ref 索引查询
range 范围查询
index 索引树扫描
all 全盘扫描
可以使用MySQL自带的explain分析工具:
1、通过key和key_len检查命中索引的情况
2、通过type字段查看是否有进一步优化空间(const、ref、range、index)
3、通过extra字段查看是否存在回表查询
6、索引
索引(index)是帮助MySQL高效获取数据的有序的数据结构。
B+树的特点
1、所有元素存储在叶子节点
2、非叶子节点存储索引
3、叶子节点形成一个单向链表,同时MySQL对B+树进行优化,将叶子节点添加一对指针,升级为双向链表。
B+树的优势
1、相较于二叉树,层级更少,搜索效率高
2、相较于B树,由于B树的叶子节点和非叶子节点都会存储数据,这样导致一叶中存储的key和指针减少,只能增加树的高度,性能降低
3、相较于hash索引,B+树支持范围匹配及排序操作
7、聚集索引和二级索引
索引分类:
一般分为主键索引、唯一索引、常规索引、全文索引。
在InnoDB存储引擎中,根据索引的存储形式,分为:聚集索引和二级索引
根据关联的字段数量分为:单列索引和联合索引
聚集索引:
将数据和索引存储在一起,B+树的叶子节点存储了行数据,有且只有一个。
二级索引:
将数据和索引分别存储,B+树的叶子节点存储对应的主键,可以有多个,除了聚集索引,其他的都是二级索引
聚集索引选取规则:
如果存在主键,主键索引就是聚集索引
如果不存在主键,第一个唯一索引就是聚集索引
如果都不会存在,InnoDB会自动生成一个rowid作为隐藏的聚集索引
什么是回表查询:
通过二级索引找到对应的主键值,通过主键值在聚集索引中找到整行数据
8、覆盖索引
覆盖索引是指查询使用了索引,并且需要返回的列在该索引中能全部找到(无需回表查询的)
比如:id是主键 name是普通索引 select * from user where id=1; select id,name from user where name='lili';
9、Limit优化
当limit 1000000,10时,MySQL会先排序1000010行,扔掉前面的1000000行,返回后面的10行,这个过程会有大量数据进出内存,导致排序时间长。使用覆盖索引+子查询,只让id进出内存,减少时间。
select * from user u1,(select id from user order by id limit 1000000,10)u2 where u1.id=u2.id;
10、创建索引的原则
1、针对于数据量较大,且查询比较频繁的表建立索引。单表超过10万数据(增加用户体验)
2、针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引
3、尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引效率越高。
4、如果是字符串类型的索引,字段长度较长,可以建立前缀索引
5、尽量使用联合索引,联合索引很多时候可以覆盖索引
6、控制索引数量,会影响增删改效率
11、索引失效的情况
1、联合索引违反了最左前缀法则
联合索引做左边的列必须存在,如果跳过了某一列,后面的索引失效
2、联合索引中出现范围查询(> <),范围查询右侧索引失效
3、在索引上运算
4、字符串字段不加单引号,发生了类型转换
5、头部模糊匹配,索引失效,尾部模糊匹配不失效
6、or连接的条件,一侧有索引,一侧没有索引
7、查询条件是两个单列索引用and连接,后面索引失效
8、数据分布影响,如果MySQL评估使用索引比全表查询慢,则不使用索引
12、SQL优化的经验
表的设计优化(阿里开发手册《嵩山版》)
1、设计比较合适的数值(tinyint int bigint)
2、char定长效率高,varchar可变长度,效率低
SQL语句优化
1、select语句尽量使用覆盖索引,避免使用select *
2、避免索引失效
3、用union all代替union union会多一次过滤,效率低
4、能用内连接(join)尽量不使用左外连接(left join)或右外连接,如必须使用小表驱动大表
内连接会对两个表进行优化,优先把小表放到外面,大表放到里面。left join和right join不会
13、Redo Log和Undo Log
redo log
重做日志,记录的是事务提交时数据页的物理修改,用于实现事务的持久性。
当客户端发起了事务操作(update等),首先在缓冲池中查找,有没有需要操作(更新)的数据,没有的话有磁盘文件加载到缓冲池,接下来直接操作缓冲区中的数据,并将数据页的变化记录到redo log buffer中,当事务提交时,redo log buffer中的记录直接刷新到磁盘中。在择机将buffer pool中的脏数据刷新到磁盘中,如果此过程中出错,就用redo log file进行数据的恢复。
为什么每次提交时不直接将buffer pool中变更的数据刷新到磁盘,而是需要redo log?
答:性能问题 。redo log是日志文件,日志是追加的,是顺序磁盘io。而直接刷新脏数据是随机磁盘io,性能不好。
undo log
回滚日志,用于记录数据被修改前的信息,作用包含两个:提供回滚 和 MVCC(多版本并发控制)
redo log和undo log的区别:
1、redo log记录的是数据页的物理变化,服务宕机可用来同步数据
2、undo log记录的是逻辑日志,当事务回滚时,通过逆操作恢复原理的数据
3、redo log保证了事务的持久性,undo log保证了事务的原子性,两个共同保证了数据的一致性
14、事务的隔离性如何保证
锁和MVCC
MVCC解决多个事务并发的时候应该访问哪个版本
多版本并发控制,指维护一个数据的多个版本,使得读写操作没有冲突。MVCC的实现依赖于三个部分:表的隐藏字段、undo log日志、readView
表的隐藏字段
trx_id:事务id,记录每一次操作的事务id,是自增的
roll_pointer:回滚指针,用于配合undo log,指向上一个版本
roll_id:隐藏主键
undo log回滚日志
①用于存储老版本数据
②当多个事务操作某一行记录,会导致该记录的undo log生成一条记录版本链(链表的头部是最新的旧纪录,尾部最早的旧纪录)
readView:快照读sql查询时选择版本的问题
根据readView的匹配规则判断该访问哪个版本的数据
不同隔离级别快照读生成时机不同,访问结果不同:
rc:每次执行快照读生成新的ReadView
rr:仅在事务第一次select时生成readView
快照读:简单的select就是快照读,读取的是记录数据的可见版本,有可能是历史数据
15、不同存储引擎之间的区别
存储引擎是存储数据、建立索引、更新和查询数据等技术的实现方式。存储引擎是基于表的,而不是基于库的
InnoDB存储引擎
支持事务、外键
支持行级锁
支持B+Tree索引结构
逻辑存储结构:段页式存储(表空间、段、区、页、行)对应磁盘文件.ibd
MyISAM存储引擎
不支持事务、外键
支持表锁,不支持行锁
支持B+Tree索引
Memory存储引擎
存储在内存中,只能将这些表作为临时表或缓存
默认hash索引,支持B+Tree
16、锁
协调多个进程或线程并发访问某一资源的机制
全局锁:锁定数据库中所有表
应用场景:全库数据备份
表级锁:每次操作锁定整张表
表锁:读锁和写锁
读锁:客户端1加了读锁,客户端1及其他客户端都能读取,都不能写
写锁:客户端1加了写锁,客户端1能够读写,其他客户端不能读写
元数据锁:(自动加锁)为了避免DML(表数据增删改)与DDL(表结构的创建、修改、删除)冲突。(简单的说,crud时不能修改表结构)
意向锁:为了避免DML(insert、delete、update)执行时,加的行锁与表锁的冲突,在InnoDB中引入意向锁,使得表锁不用检查每行数据是否加锁,使用意向锁来减少表锁的检查.
分类:
意向共享锁(IS):由select...lock in share mode添加
意向排他锁(IX):由insert、delete、update添加
兼容性与互斥性:
意向共享锁:与表锁读锁兼容,与表锁写锁互斥
意向排他锁:与表锁读锁、写锁都互斥。意向锁之间不会互斥。
行级锁:每次操作锁定对应行数据,行锁是通过对索引上的索引项加锁实现的,而不是对记录加锁。分为行锁、间隙锁、临键锁
行锁(Record Lock):锁定单行记录,防止其他事务进行update和delete。在rc、rr隔离级别下支持。解决了脏读、不可重复读。分为共享锁和排他锁
间隙锁(Gap Lock):锁定索引记录间隙(不含该记录),确保索引记录间隙不变,防止其他事务在这个间隙进行insert,产生幻读。在rr隔离级别下都支持。
临键锁(Next-Key Lock):行锁+间隙锁的结合(该行记录及左边间隙)。在rr隔离级别下支持
17、数据表设计的三大范式
第一范式:列不可再分。例如:省市区在一列存储,就不满足
第二范式:一张表只表达一层含义
第三范式:表中每一列直接依赖于主键,而不是间接依赖。例如,如果一个订单表包含商品和商品价格,则商品价格是应该是和商品ID关联的,而不是和订单ID关联的。
数据库的设计范式和查询性能有时候是相悖的,我们需要根据实际情况做一些取舍:
当查询频次相对不高的时候,可以提高设计范式
当查询频次高时,更倾向于牺牲数据库的规范度,允许特定的冗余而提高性能
Mybatis
1、Mybatis获取参数值的两种方式${}和#{}的区别
${} 本质是字符串的拼接,不会加 ''
#{} 本质是占位符赋值,会自动添加 '' ,可防止SQL注入
2、 Mapper和映射文件的配置
映射文件的namespace和mapper接口全类名保持一致
映射文件sql语句的id和mapper接口方法名保持一致
3、Mybatis的一级缓存与二级缓存
一级缓存是sqlSession级别缓存,默认开启(sqlSession消失时,一级缓存会消失)
存储作用域为Session
通过同一个sqlSession查询相同数据会从缓存中取
同一个sqlSession两次查询期间有增删改操作,会清空缓存
手动清除sqlSession(clearCache方法)
二级缓存是sqlSessionFactory级别缓存,需要手动开启
二级缓存在一级缓存关闭后有效(关闭后数据写入二级缓存)
两次查询期间执行了任意增删改操作,一二级缓存失效
缓存查找顺序:二级缓存 ——> 一级缓存 ——> 数据库
4、Mybatis如何获取自动生成的主键值
insert标签中设置useGeneratedKeys=true,keyProperty=主键名
5、Mybatis动态SQL的常用标签
<if>
<where>
<trim>用于去除和添加标签中内容
<choose><when><otherwise>
<foreach>批量插入
6、PageHelper
1、当调用PageHelper的startPage(PageNo页码,PageLimit每页条数)方法时,底层会将分页参数保存到ThreadLocal中(ThreadLocal<Page>)
2、当执行mapper中的查询方法时,被PageInterceptor拦截,并执行interceptor方法,该方法做了两件事:
一是拿到我们写的sql语句,并将他改造成select count(0)的形式,得到总数保存到Page的tocal属性中
二是将sql语句改造成分页语句,得到的结果保存到Page的list属性中
7、Mybatis如何防止sql注入
1、sql执行前对数据类型进行检查(比如如果是日期,就必须是日期类型)
2、使用预编译语句
3、对特殊字符进行过滤
8、Mybatis的延迟加载
延迟加载只存在于级联查询中,单表查询无
需要用到数据时才加载,不需要用到就不加载
lazyLoadingEnabled=true,默认关闭
延迟加载在底层是通过cglib动态代理完成的:
1、首先使用动态代理创建目标方法(开启延迟加载的mapper)的代理对象
2、当调用目标方法,进入invoke方法时,发现目标方法是null,此时执行sql查询
3、获取数据后,赋值给属性,再继续查询目标方法就有值了
9、Mybatis执行流程
1、读取Mybatis配置文件:mybatis-config.xml加载运行环境和映射文件
2、构建会话工厂SqlSessionFactory:单例的
3、通过会话工厂创建SqlSession对象
4、通过Executor执行器操作数据库(封装jdbc操作,维护一二级缓存)
5、Executor接口的执行方法中有一个MapperStatement类型的参数,封装了映射信息
6、输入参数映射(java数据类型映射为mysql数据类型)
7、输出参数映射
Spring
1、BeanFactory与ApplicationContext
BeanFactory是Spring的早期接口,称为Spring Bean工厂,ApplicationContext是后期接口,称为Spring容器
Bean创建的主要逻辑和功能封装在BeanFactory中,ApplicationContext不仅继承BeanFactory,内部维护BeanFactory的引用
BeanFactorty的API更偏向底层,ApplicationContext在BeanFactory的基础上对功能进行扩展
Bean初始化时机不同,BeanFactory是首次调用getBean时开始Bean的创建,而ApplicationContext则是配置文件加载,容器一创建就将Bean都实例化且初始化。
scope:Bean的作用范围,常取值singleton和prototype
singleton:单例 spring容器初始化时会创建Bean实例,放在单例池
prototype: 原型 spring容器初始化时不会创建Bean实例,调用getBean才会实例化,每次创建一个新的Bean实例
lazy-init 是否延迟加载(对BeanFactory无效)
2、Bean的实例化
1、Spring容器在进行初始化时,会将xml配置的bean信息封装成一个个BeanDefinition对象
2、所有的BeanDefinition存储在一个BeanDefinitionMap中
3、ApplicationContext对BeanDefinitionMap进行遍历,通过反射创建Bean实例对象,存储在singletonObject的Map中,也就是单例池
4、当调用getBean方法时,直接从单例池中取
3、Spring的后处理器
Spring的后处理器是Spring对外开发的重要扩展点,允许我们介入到Bean的实例化中来,以达到动态注册BeanDefinition,动态修改Bean。有两种后处理器:
BeanFactoryPostProcessor:Bean工厂后处理器,在BeanDefinitionMap填充完毕,Bean实例化之前
BeanPostProcessor:Bean后处理器,Bean实例化之后,填充到单例池之前
BeanFactoryPostProcessor接口:主要是对Bean定义的操作、注册BeanDefinition进Map中、修改BeanDefinitionMap中的数据 、注解开发原理
BeanPostProcessor接口:对Bean的操作、Bean的初始化、AOP思想
4、Bean的生命周期
主要有4个阶段,Bean的实例化阶段,Bean的初始化阶段,Bean的使用,Bean的销毁
1、Bean的实例化
Spring容器将xml文件定义的bean信息封装成一个个BeanDefinition,所有的BeanDefinition存储到一个BeanDefinitionMap中,Spring容器将该Map进行遍历,经过各种if判断,比如是否单例,是否延迟加载等,最终创建一个半成品实例。
2、Bean的初始化阶段
①Bean实例的属性填充,也就是依赖注入
②Aware接口属性注入
③BeanPostProcessor的before方法调用
④InitializingBean接口的初始化方法调用(afterPropertiesSet方法)
⑤自定义初始化方法回调
⑥BeanPostProcessor的after方法回调(AOP)
3、Bean的使用阶段:将成品Bean放入单例池中
4、Bean的销毁
5、循环依赖问题
Spring在进行双向属性注入时产生的问题(比如A依赖B,B依赖A)
一级缓存:singletonObjects单例池,存储Bean成品
二级缓存:earlySingletonObjects早期bean单例池,当前对象已被引用
三级缓存: singletonFactories,对象未被引用,被ObjectFactories包了一下
A实例化,但尚未初始化,将A存入三级缓存
A注入B,从缓存中取,没有
B实例化,尚未初始化,放入三级缓存
B注入A,从三级缓存中取,并将A移入二级缓存
B执行其他生命周期,最终成为完整的Bean,移入单例池
A注入B
A完成其他生命周期,最终成为完整Bean,移入单例池
6、AOP产生Proxy的两种方式
jdk基于接口的动态代理:生成接口的实现类
cglib基于子类的动态代理:动态生成父类的子类
7、对AOP的理解
AOP是面向切面编程,在Spring中,将那些与业务无关,但却对对象产生影响的公共行为和逻辑,抽取出来复用。比如记录操作日志、缓存处理、事务管理
AOP相关概念:
目标对象Target:被增强的方法所在的对象
代理对象Proxy:对目标对象增强后的对象(实际调用的对象)
连接点JoinPoint:目标对象中可以被增强的方法
切入点PointCut:目标对象中实际被增强的方法
通知(增强)Advice:增强部分的代码逻辑
切面Aspect:通知+切入点
织入Weaving:将通知和切入点动态结合的过程
配置:
切点表达式:execution(返回值 包.类.方法(参数)) #任意一级 ..任意
通知类型:
around环绕通知
before前置通知
after最终通知(无论有无异常都执行)
after-returning后置通知(返回后通知)有异常不执行
after-throwing异常通知(异常后通知)异常后执行,无异常不执行
配置切面的两种方式:
advisor:通过接口来确定通知类型(通知类型确定)
aspect:通过配置确定通知类型
8、基于AOP的声明式事务管理
Spring事务相关的类:
平台事务管理器PlatformTransactionManager:接口标准,实现类都具有事务提交、回滚和获得事务对象的功能。不同持久层有不同实现方案DataSourceTransactionManager
事务定义TransactionDefinition:封装事务隔离级别,传播行为,过期时间
事务状态TransactionStatus:存储事务状态信息,是否提交,是否回滚,是否有回滚点等。
事务定义TransactionDefinition:
name:方法名 addXxx=>add*
isolation:隔离级别 解决事务并发问题(脏读、不可重复读、幻读)
read-only:是否只读,默认false
timeout:超时时间 超过x秒就取消当前事务操作
propagation:事务传播行为 事务嵌套问题
required默认:A调B B需要事务,A有就加入,没有B自己创建
supports: A调B B有没有事务无所谓 A有就加入,没有就没有
9、Spring框架中单例Bean是线程安全的吗
如果单例Bean是无状态的(不能保存数据的实例或者不能被修改的实例),那就是线程安全的,Dao类中实例大多都是无状态的
如果是有状态的(比如ViewAndModel对象)那就是非线程安全的
总的来说,Spring底层对bean没有关于线程安全的封装,所以是不安全的
将bean的作用域由单例改为多例(prototype),这样每次都创建新的对象,线程之间不存在对象共享,就是安全的。
10、Spring中事务失效的场景
spring事务本质由AOP完成,对方法前后进行拦截,在执行方法前开启事务,执行完之后提交或回滚
1、如果在方法里自己处理了(try-catch)异常,没有抛出,就会导致事务失效
原因:事务通知只有捉到了目标抛出的异常,才能进行后续回滚处理
解决:在catch中添加throw new RuntimeException(e)
2、抛出检查异常(throws FileNotFoundException)
原因:Spring默认只会回滚非检查异常(RunTimeException)
解决:配置rollbackFor属性 @Transactional(rollbackFor=Exception.class)
3、方法未使用public修饰
原因:Spring为方法创建代理、添加事务通知,前提条件就是该方法是public的
解决:public
11、Spring常用注解
声明bean相关的:
@Component 以及三个衍生注解 @Controller @Service @Repository
依赖注入相关:
@Value(注入普通数据,String)
@Autowired(按照类型,名称)
@Resourse(按照名称,类型)
@Qualifier(配合@Autowired按照名称)
设置作用域
@Scope singleton/prototype
延迟加载
@Lazy
spring配置相关:
@ComponentScan
@Configuration
@Bean(“beanName)将该类交给ioc,标注方法会将方法返回值存储到spring容器
@Import(clazz)
@PropertySource("classpath:jdbc.properties")
AOP:
@Aspect配置切面
切点表达式:@PointCut
配置通知@Around等
开启注解配置@EnableAspectJAutoProxy
AOP声明式事务控制:
@Transactional需要事务的方法或类上
@EnableTransactionManagement
其他:
@Primary提交bean的优先级
@Profile("dev")标注环境,只有dev环境激活才能被注册
applicationContext.getEnvironment().setActiveProfiles("dev");
12、Spring中常用的设计模式
代理模式:spring中两种代理方式,jdk基于接口的动态代理,cglib动态代理,AOP面向切面编程
单例模式:spring中bean默认为单例模式
模板方式模式:用来解决代码重复问题
工厂模式:spring中使用beanFactory来创建bean实例
13、Aware接口
用于辅助依赖注入
ServletContextAware web环境有效
BeanFactoryAware
BeanNameAware 假设我们的类实现了BeanNameAware接口,对应这个接口有一个setBeanName方法,spring在依赖注入的初始化阶段把beanName作为参数传入进来。一般我们在自己写的类里面定义属性进行接收,就可以使用了
ApplicationContextAware
SpringMVC
1、SpringMVC常见注解
1、请求映射:
@RequestMapping用于映射请求路径
派生注解:@GetMapping等
2、报文信息转换器:
@RequestBody实现接收http请求的json数据,将json转换为Java对象(获得请求体,在控制器方法设置一个形参,用于json数据接收)
@ResponseBody类和方法 ,加上注解返回的不再是视图名称,而是响应体(@RestController=@ResponseBody+@Controller)
3、获取请求参数
@RequestParam形参内,指定请求参数名称
@RequestHeader获取请求头数据
@CookieValue
@DataTimeFormat日期类型接收
4、请求路径获取参数
@PathVariable
2、SpringMVC执行流程
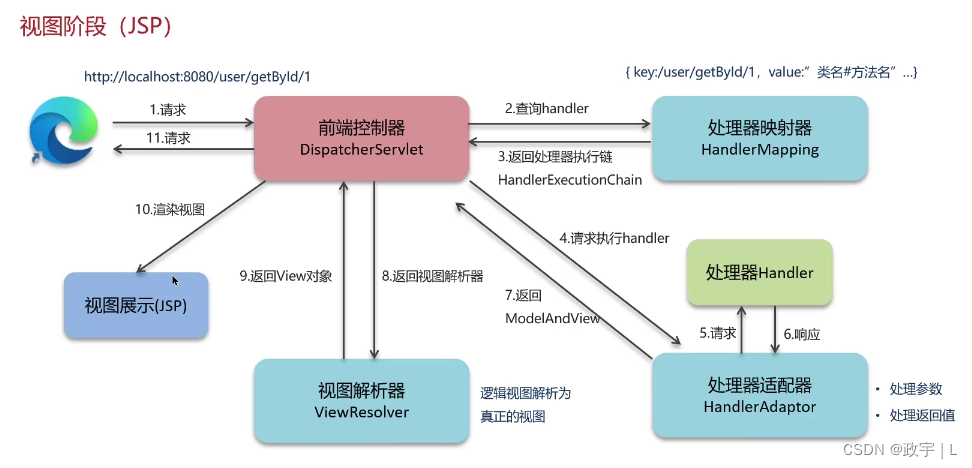
1、用户发送请求到前端控制器DispatcherServlet
2、DispatdcherServlet将收到的请求交给处理器映射器HandlerMapping(DispatcherServlet对请求URL进行解析,得到请求资源标识符URI,如果找不到请求资源标识符对应的映射,看是否配置了mvc:default-servlet-handler,没有就404,有一般访问的是静态资源,找不到也显示404)
3、HandlerMapping找到具体的处理器,返回给DispatcherServlet处理器执行链对象HandlerExecutionChain,包含处理器方法和拦截器
4、DispatcherServlet调用HandlerAdapter(处理器适配器)
5、HandlerAdapter经过适配找到具体处理器,此时开始执行拦截器的preHandler方法【正向】
6、Controller方法执行完成返回ModelAndView对象
7、处理器适配器将Controller返回的ModelAndView对象返回给DispatcherServlet
8、执行拦截器postHandle方法【逆向】
9、DispacherServler对返回的ViewAndView进行判断,如果存在异常,会执行处理器异常解析器进行处理
10、DispatcherServlet将ModelAndView传给视图解析器
11、视图解析器解析后返回具体View
12、DispacherServlet根据View进行渲染视图
13、渲染视图完毕执行拦截器afterCompletion方法【逆向】
14、响应给用户
DispatcherServlet是一个调度中心,接收所有请求
HandlerMapping:通过路径找到对应的控制器方法
HandlerAdaptor:1、执行Handler 2、处理Handler里的参数和返回值
ViewResolver:将逻辑视图转换为真正的视图
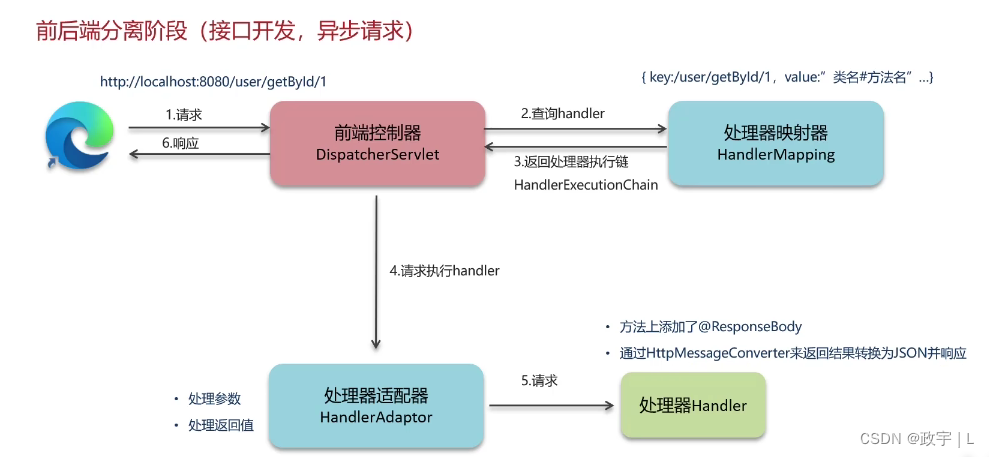
前后端分离开发中,在处理器适配器调用Controller方法执行结束后,通过HttpMessageConverter来返回结果转换为json并响应(方法上添加@ResponseBody)
3、SpringMVC如何发送put请求
1、使用ajax,仅部分浏览器支持
2、使用form表单+HiddenHttpMethodFilter
首先form表单请求方式设置为post,设置为隐藏域,name属性设置为_method,value设置为put
设置过滤器HiddenHttpMethodFilter,过滤器会获取_method的值,并在请求方式为post的情况下换为put
4、域对象共享数据
page request session application
1、向request域共享数据:
①使用原生ServletAPI向域对象共享数据
②new ModelAndView的addObject方法
③形参Model的addAttribute
④形参Map的put
⑤形参ModelMap的addAttribute
2、向session域共享数据:
①使用ServletAPI
②HttpSession
3、application
①session.getServletContext
5、文件上传
文件上传MultipartFile
6、拦截器和过滤器
拦截器(Interceptor)属于SpringMVC规范,Filter属于Servlet规范
拦截器只对进入SpringMVC管辖范围内的进行拦截,主要是Controller请求,Filter可以对所有请求进行拦截
拦截器在DispatcherServlet执行后执行,Filter早于任何Servlet执行
拦截器用来拦截控制器方法的执行
三个抽象方法:
preHandle:控制器方法执行之前执行preHandle(),其boolean类型的返回值表示是否拦截或放行,返回true为放行,即调用控制器方法;返回false表示拦截,即不调用控制器方法
postHandle:控制器方法执行之后执行postHandle()
afterComplation:处理完视图和模型数据,渲染视图完毕之后执行afterComplation()
Springboot
1、Springboot自动配置原理
1、在Spring Boot项目的引导类上有一个注解@SpringBootApplication,这个注解底层有三个注解,
@SpringBootConfiguration这个注解底层就是@Configuration,表示配置类
@EnableAutoConfiguration,这是实现自动化配置的核心注解
@ComponentScan包扫描注解
2、@EnableAutoConfiguration底层通过@Import注解导入对应的配置选择器。内部读取了该项目和引用的jar包的classpath路径下MATA-INF下的spring.factories文件中所配置类的全类名。springboot会根据配置类中所指定的条件来决定是否加载到spring容器中。
@Conditional条件装配 满足条件,进行组件注入
加在方法或类上,条件成立才会向下执行
衍生注解:
@ConditionalOnClass(name="全类名") 环境中存在指定的这个类,才会将该bean加入到IOC容器中
@ConditionalOnMissingBean 不存在该类型的bean才会将该bean加入到IOC容器中--指定类型(value属性)或名称(name属性)应用场景:默认bean对象
@ConditionalOnProperty(name="",havingValue="") 当前环境配置文件是否有对应属性和值
2、加载第三方依赖的方式
1、@ComponentScan
2、@Import
①普通类或配置类
②实现ImportSelector接口/ImportBeanDefinitionRegistrar接口的类(作用:注册普通类到ioc)
3、EnableXxx封装@Bean
3、SpringBoot常见注解
@SpringBootApplication spring引导类
@SpringBootConfiguration
@EnableAutoConfiuration
@Conditional
数据结构
1、Java String和数组
boolean isEmpty():字符串是否为空
int length():返回字符串长度
String concat(str):拼接
boolean equals(Object obj):比较相等
toLowerCase/toUpperCase():大小写转换
trim():去掉前后空白字符
boolean contains(str):是否包含str
int indexOf(String str,[int fromIndex])返回指定字符串在此字符串第一次出现的位置
String subString(int beginIndex,[int endIndex]):截取
char charAt(index)返回index位置的字符
字符串转数组:
1、char[] toCharArray()
2、String[] split(String regex)
数组转字符串:byte或char型数组
1、构造器new String(char[] value)
2、String valueof(char[] data)/copyValueof(char[] data)
数组本身是引用数据类型,而数组元素可以是任何数据类型
静态初始化:
①int[] arr=new int[]{1,2};
②int[] arr;
arr=new int[]{1,2};
③int[] arr={1,2};
动态初始化
①int[] arr=new int[length];
②int[] arr;
arr=new int[length];
③int[][] arr=new int[5][]; 5行的二维数组
2、素数个数统计
import java.util.*;
public class Main{
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int num = scanner.nextInt();
System.out.println(prime(num));
}
public static int prime(int n) {
boolean[] isPrime = new boolean[n];//false代表素数,默认
int count = 0;
for (int i = 2; i < n; i++) {
if (!isPrime[i]) {
count++;
for (int j = i * i; j < n; j += i) {
isPrime[j] = true;
}
}
}
return count;
}
}
3、排序算法
| 排序算法 | 平均时间复杂度 | 最好情况 | 最坏情况 | 空间复杂度 |
| 冒泡 | n² | n | n² | 1 |
| 选择 | n² | n² | n² | 1 |
| 插入 | n² | n | n² | 1 |
| 希尔 | nlogn | nlog²n | nlog²n | 1 |
| 归并 | nlogn | nlogn | nlogn | n |
| 快速 | nlogn | nlogn | n² | logn |
| 堆 | nlogn | nlogn | nlogn | 1 |
| 计数 | ||||
| 桶 | ||||
| 基数 |
结论:最好情况O(n):插入排序, 冒泡排序 最差情况O(nlogn):堆排序
4、二叉树
等差数列求和
Sn=n(a1+an)/2
等比数列求和
Sn=a1(1-q^n)/(1-q)
Sn=(a1-anq)/(1-q)















 513
513











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









