






Structured Streaming
结构化流(Structured Streaming)是流式计算思想的一种实现
是基于 Spark SQL DataFrame API 构建的流处理引擎,提供简单易用的流处理接口,
允许用户使用类似于批处理的方式对流数据执行 SQL 查询和复杂的数据处理操作。 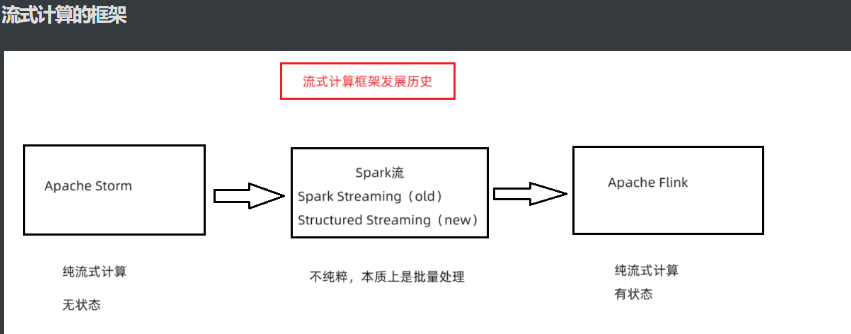
流式程序的开发流程
#1.构建SparkSession对象
#2.Source(指定数据源)
#3.Operations/Transformation(操作,数据处理)
#4.Sink(数据输出)
#5.启动流式任务结构化流的入门案例
# 需求
监听node1节点的10086的端口号,从端口号中获取单词数据,将其转换为DF进行单词统计。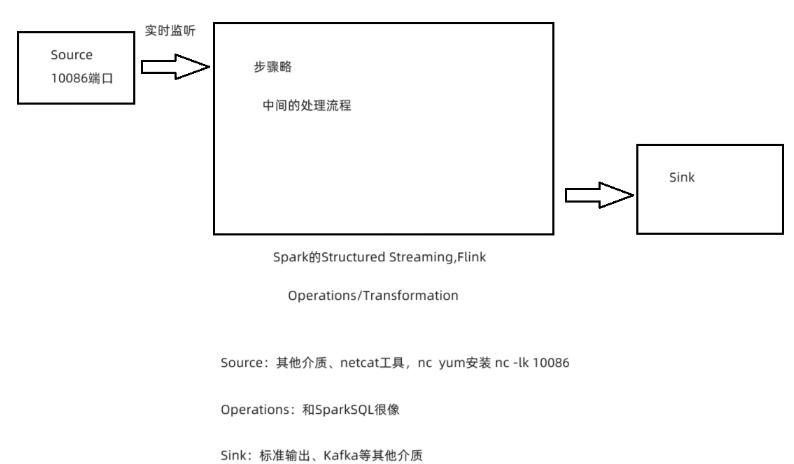
from pyspark.sql import SparkSession
import os
import pyspark.sql.functions as F
# 1.构建SparkSession
# 建造者模式:类名.builder.配置…….getOrCreate()
# 自动帮你构建一个SparkConf对象,只要指定你需要哪些配置就可
spark = SparkSession \
.builder \
.master("local[2]") \
.appName("SparkSQLAppName") \
.config("spark.sql.shuffle.partitions", 4) \
.getOrCreate()
# 2.数据输入
#socket = hostname + port,就是socket数据源
#host:主机名
#port:端口号
#format=socket,说明数据源是socket
lines = spark\
.readStream\
.format("socket")\
.option("host","node1")\
.option("port","10086")\
.load()
# 3.数据处理
#和SparkSQL一样
words = lines.select(
F.explode(
F.split(lines['value'], " ")
).alias("word")
)
wordCounts = words.groupBy("word").count()
# 4.数据输出
lines.printSchema()
#console:控制台
#format:数据输出的介质,console 就是控制台
#outputMode:
#输出模式,append,只能用于非聚合情况
#追加的模式、complete,只能用于聚合的情况
#更新的模式,update,用于聚合和非聚合的情况,但是只显示更新的数据(新增、修改)
query = wordCounts.writeStream.format("console").outputMode("complete")
# 5.启动流式任务
#awaitTermination:阻塞流程程序,处理源源不断到达的数据
#start:启动流式程序
query.start().awaitTermination()
从kafka中读取数据
from pyspark.sql import SparkSession
import os
import pyspark.sql.functions as F
# 1.构建SparkSession
# 建造者模式:类名.builder.配置…….getOrCreate()
# 自动帮你构建一个SparkConf对象,只要指定你需要哪些配置就可
spark = SparkSession \
.builder \
.master("local[2]") \
.appName("SparkSQLAppName") \
.config("spark.sql.shuffle.partitions", 4) \
.getOrCreate()
# 2.数据输入
#kafka:数据源是Kafka的数据源
#kafka.bootstrap.servers:制定Kafka的broker地址
#subscribe:订阅某个Topic
input_df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "node1:9092,node2:9092,node3:9092") \
.option("subscribe", "test06") \
.load()
# 3.数据处理
input_df.printSchema()
#selectExpr:在DSL中运行执行SQL语句
#方式一,必须掌握,官方写法
#input_df = input_df.selectExpr("cast(value as string)")
#方式二,可选
input_df = input_df.withColumn("value",F.expr("cast(value as string)"))
# 4.数据输出
queyr = input_df.writeStream.format("console").outputMode("append")
# 5.启动流式任务
queyr.start().awaitTermination()
# Kafka的结构化流接收到kafka的数据,最终会转换为一个DF对象
+---+-----+-----+---------+------+---------+-------------+
|key|value|topic|partition|offset|timestamp|timestampType|
+---+-----+-----+---------+------+---------+-------------+
+---+-----+-----+---------+------+---------+-------------+
#1.key
生产者发送的key数据, 如果没有发送, 即为NULL
#2.value
生产者发送的value数据, value也是消息数据
#3.topic
消息是从哪个topic接收的
#4.partition
消息是从哪个topic的那个分片上接收的
#5.offset
偏移量信息
#6.timestamp
时间戳 (消费消息时间)
#7.timestampType
时间戳类型数据写入Kafka中
from pyspark.sql import SparkSession
import os
# 1.构建SparkSession
# 建造者模式:类名.builder.配置…….getOrCreate()
# 自动帮你构建一个SparkConf对象,只要指定你需要哪些配置就可
spark = SparkSession \
.builder \
.master("local[2]") \
.appName("SparkSQLAppName") \
.config("spark.sql.shuffle.partitions", 4) \
.getOrCreate()
# 2.数据输入
input_df = spark.readStream.format("socket").option("host", "node1").option("port", "10086").load()
# 3.数据处理
input_df.printSchema()
# 4.数据输出
# kafka:把数据写进Kafka
# kafka.bootstrap.servers:Kafka的broker地址
# Topic:指定写到Kafka的哪个Topic
query = input_df \
.writeStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "node1:9092,node2:9092,node3:9092") \
.option("topic", "test07") \
.option("checkpointLocation", "file:///root/checkpointLocation2") \
.outputMode("append")
# 5.启动流式任务
query.start().awaitTermination()
#1.Spark读取Kafka的数据,参数需要指定2个:
参数一:kafka.bootstrap.servers,broker地址
参数二:subscribe
#2.Spark写入Kafka的数据,参数需要指定2个:
参数一:kafka.bootstrap.servers,broker地址
参数二:topic物联网分析案例
# 数据模拟器
import json
import random
import time
from kafka import KafkaProducer
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
import os
# 2.数据输入
#2.1 构建Kafka的生产者
producer = KafkaProducer(
bootstrap_servers=['node1:9092', 'node2:9092', 'node3:9092'],
acks='all',
value_serializer=lambda m: json.dumps(m).encode("utf-8")
)
#2.2 物联网设备类型
deviceTypes = ["洗衣机", "油烟机", "空调", "窗帘", "灯", "窗户", "煤气报警器", "水表", "燃气表"]
#2.3 模拟数据生成
while True:
index = random.choice(range(0, len(deviceTypes)))
deviceID = f'device_{index}_{random.randrange(1, 20)}'
deviceType = deviceTypes[index]
deviceSignal = random.choice(range(10, 100))
# 组装数据集
print({'deviceID': deviceID, 'deviceType': deviceType, 'deviceSignal': deviceSignal,
'time': time.strftime('%Y%m%d')})
# 发送数据
producer.send(topic='iot',
value={'deviceID': deviceID, 'deviceType': deviceType, 'deviceSignal': deviceSignal,
'time': time.strftime('%Y%m%d')}
)
# 间隔时间 5s内随机
time.sleep(random.choice(range(1, 5)))
# 模拟器程序会向kafka中源源不断的产生数据
# 需求
用Spark从Kafka中接收数据,并且分析信号强度大于30的设备中,
按照类型统计它们的数量和平均信号强度,打印到标准输出。
**示例数据**
{'deviceID': 'device_5_14', 'deviceType': '窗户', 'deviceSignal': 16, 'time': '20220702'}
{'deviceID': 'device_1_17', 'deviceType': '油烟机', 'deviceSignal': 93, 'time': '20220702'}# DSL实现
from pyspark.sql import SparkSession
import os
import pyspark.sql.functions as F
# 1.构建SparkSession
# 建造者模式:类名.builder.配置…….getOrCreate()
# 自动帮你构建一个SparkConf对象,只要指定你需要哪些配置就可
spark = SparkSession \
.builder \
.master("local[2]") \
.appName("SparkSQLAppName") \
.config("spark.sql.shuffle.partitions", 4) \
.getOrCreate()
# 2.数据输入
input_df = spark\
.readStream\
.format("kafka")\
.option("kafka.bootstrap.servers","node1:9092,node2:9092,node3:9092")\
.option("subscribe","iot")\
.load()
# 3.数据处理
input_df.printSchema()
print("---------------1.DSL-----------------")
result_df = input_df.selectExpr("cast(value as string)")
#json_tuple(jsonStr,p1,p2...pn)
#json_tuple:专门处理json数据的函数,可以给多个字段,可以抽取每个字段的值
#jsonStr:待处理的json字符串
#p1~pn:字段名
result_df = result_df.select(F.json_tuple(result_df['value'],"deviceID","deviceType","deviceSignal","time")
.alias("deviceID","deviceType","deviceSignal","time"))
result_df = result_df\
.where("deviceSignal > 30")\
.groupBy("deviceType")\
.agg(F.count("deviceType").alias("cnt"),F.avg("deviceSignal").alias("avg_signal"))
# 4.数据输出
#option("truncate","False"):设置不截断
query = result_df.writeStream.format("console").outputMode("complete").option("truncate","False")
# 5.启动流式任务
query.start().awaitTermination()
# 输出
Batch: 2
-------------------------------------------
+----------+---------------+-----------------+
|deviceID |count(deviceID)|avg(deviceSignal)|
+----------+---------------+-----------------+
|device_6_5|1 |85.0 |
|device_7_5|1 |33.0 |
+----------+---------------+-----------------+
......
Batch: 6
-------------------------------------------
+-----------+---------------+-----------------+
|deviceID |count(deviceID)|avg(deviceSignal)|
+-----------+---------------+-----------------+
|device_6_5 |1 |85.0 |
|device_0_13|1 |39.0 |
|device_1_16|1 |56.0 |
|device_7_5 |1 |33.0 |
+-----------+---------------+-----------------+# SQL实现
from pyspark.sql import SparkSession
import os
import pyspark.sql.functions as F
# 1.构建SparkSession
# 建造者模式:类名.builder.配置…….getOrCreate()
# 自动帮你构建一个SparkConf对象,只要指定你需要哪些配置就可
spark = SparkSession \
.builder \
.master("local[2]") \
.appName("SparkSQLAppName") \
.config("spark.sql.shuffle.partitions", 4) \
.getOrCreate()
# 2.数据输入
input_df = spark\
.readStream\
.format("kafka")\
.option("kafka.bootstrap.servers","node1:9092,node2:9092,node3:9092")\
.option("subscribe","iot")\
.load()
# 3.数据处理
input_df.printSchema()
# 4.数据输出
#option("truncate","False"):设置不截断
print("---------------2.SQL-----------------")
input_df.createOrReplaceTempView("t1")
#UDTF函数的使用语法:源表 lateral view UDTF函数()
result_df = spark.sql("""
select
deviceType,
count(deviceType) as cnt,
avg(deviceSignal) as avg_signal
from t1 lateral view
json_tuple(cast(value as string),"deviceID","deviceType","deviceSignal","time") as deviceID,deviceType,deviceSignal,`time`
where deviceSignal > 30
group by deviceType
""")
query = result_df.writeStream.format("console").outputMode("complete").option("truncate","False")
# 5.启动流式任务
query.start().awaitTermination()















 1786
1786











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









