






JavaOOP面试题
什么是B/S架构?什么是C/S架构?
1、B/S(Browser/Server):浏览器/服务器程序
2、C/S(Client/Server):客户端/服务端
Java开发平台
1、JAVA SE:主要用在客户端开发
2、JAVA EE:主要用在web应用程序开发
3、JAVA ME:主要用在嵌入式应用程序开发
JDK、JRE、JVM、JIT
1、JDK:java development kit:java开发工具包,是开发人员所需要安装的环境
2、JRE:java runtime environment:java运行环境,java程序运行所需要安装的环境
3、JVM:代表 Java 虚拟机(Java virtual machine),它的责任是运行 Java 应用
4、JIT:代表即时编译(Just In Time compilation),当代码执行的次数超过一定的阈值时,会将 Java 字节码转换为本地代码
JDK1.8新特性
A、接口中新增了default方法和static方法,这两种方法可以有方法体
接口中的static方法不能被继承,也不能被实现类调用,只能被自身调用
default方法可以被继承,也可以被实现类调用,被继承时,可以被子接口的default方法覆盖,如果一个类实现了多个接口,且接口间没有继
承关系,如果有相同的default方法,则接口实现类会报错
B、Lambda表达式,可以看作匿名内部类,使用lambda表达式时,接口必须是函数式接口,语法是:
<函数式接口> <变量名>=(参数1,参数2)->{ 方法体 } //无参数,无返回 () -> System.out.println("test"); //有参数,无返回 e -> System.out.println(e); //有参数,有返回 e -> true e -> {return e == null ? false : true;}C、函数式接口:
如果一个接口只有一个抽象方法,则该接口称之为函数式接口.通常在函数式接口上添加@FunctionalInterface注解,如果接口中有多个
抽象方法,编译会报错
Comsumer:消费型接口(void accept(T t)),有参数,无返回值
Supplier:供给型接口(T get()),无参数,有返回值
Function<T,R>:函数式接口(R apply(T t)),一个输入参数,一个输出参数,两个参数可以不同,可以一致
Predicate :断言型接口(Boolean test(T t)),输入一个参数,返回一个Bollean类型的返回值
D、新增stream流接口
E、date类的api新增了Timezones时区、LocalTime本地时间、LocalDate本地日期
F、对hashMap进行了优化,将数组+链表的模式改为了数组+链表+红黑树的模式,对注解进行了优化,支持了重复注解
Java语言有哪些特点
1、简单易学、有丰富的类库
2、面向对象(Java最重要的特性,让程序耦合度更低,内聚性更高)
3、平台无关性(JVM是Java跨平台使用的根本)
4、可靠安全
5、支持多线程
进制转换表
十进制 十六进制 二进制 Symbol 十进制 十六进制 二进制 Symbol 0 00 0000 0000 NUL 64 40 0100 0000 @ 1 01 0000 0001 SOH 65 41 0100 0001 A 2 02 0000 0010 STX 66 42 0100 0010 B 3 03 0000 0011 ETX 67 43 0100 0011 C 4 04 0000 0100 EOT 68 44 0100 0100 D 5 05 0000 0101 ENQ 69 45 0100 0101 E 6 06 0000 0110 ACK 70 46 0100 0110 F 7 07 0000 0111 BEL 71 47 0100 0111 G 8 08 0000 1000 BS 72 48 0100 1000 H 9 09 0000 1001 TAB 73 49 0100 1001 I 10 0A 0000 1010 LF 74 4A 0100 1010 J 11 0B 0000 1011 VT 75 4B 0100 1011 K 12 0C 0000 1100 FF 76 4C 0100 1100 L 13 0D 0000 1101 CR 77 4D 0100 1101 M 14 0E 0000 1110 SO 78 4E 0100 1110 N 15 0F 0000 1111 Sl 79 4F 0100 1111 O 16 10 0001 0000 DLE 80 50 0101 0000 P 17 11 0001 0001 DC1 81 51 0101 0001 Q 18 12 0001 0010 DC2 82 52 0101 0010 R 19 13 0001 0011 DC3 83 53 0101 0011 S 20 14 0001 0100 DC4 84 54 0101 0100 T 21 15 0001 0101 NAK 85 55 0101 0101 U 22 16 0001 0110 SYN 86 56 0101 0110 V 23 17 0001 0111 ETB 87 57 0101 0111 W 24 18 0001 1000 CAN 88 58 0101 1000 X 25 19 0001 1001 EM 89 59 0101 1001 Y 26 1A 0001 1010 SUB 90 5A 0101 1010 Z 27 1B 0001 1011 ESC 91 5B 0101 1011 [ 28 1C 0001 1100 FS 92 5C 0101 1100 / 29 1D 0001 1101 GS 93 5D 0101 1101 ] 30 1E 0001 1110 RS 94 5E 0101 1110 ^ 31 1F 0001 1111 US 95 5F 0101 1111 _ 32 20 0010 0000 (space) 96 60 0110 0000 ` 33 21 0010 0001 ! 97 61 0110 0001 a 34 22 0010 0010 " 98 62 0110 0010 b 35 23 0010 0011 # 99 63 0110 0011 c 36 24 0010 0100 $ 100 64 0110 0100 d 37 25 0010 0101 % 101 65 0110 0101 e 38 26 0010 0110 & 102 66 0110 0110 f 39 27 0010 0111 ` 103 67 0110 0111 g 40 28 0010 1000 ( 104 68 0110 1000 h 41 29 0010 1001 ) 105 69 0110 1001 i 42 2A 0010 1010 * 106 6A 0110 1010 j 43 2B 0010 1011 + 107 6B 0110 1011 k 44 2C 0010 1100 , 108 6C 0110 1100 l 45 2D 0010 1101 - 109 6D 0110 1101 m 46 2E 0010 1110 . 110 6E 0110 1110 n 47 2F 0010 1111 / 111 6F 0110 1111 o 48 30 0011 0000 0 112 70 0111 0000 p 49 31 0011 0001 1 113 71 0111 0001 q 50 32 0011 0010 2 114 72 0111 0010 r 51 33 0011 0011 3 115 73 0111 0011 s 52 34 0011 0100 4 116 74 0111 0100 t 53 35 0011 0101 5 117 75 0111 0101 u 54 36 0011 0110 6 118 76 0111 0110 v 55 37 0011 0111 7 119 77 0111 0111 w 56 38 0011 1000 8 120 78 0111 1000 x 57 39 0011 1001 9 121 79 0111 1001 y 58 3A 0011 1010 : 122 7A 0111 1010 z 59 3B 0011 1011 ; 123 7B 0111 1011 { 60 3C 0011 1100 < 124 7C 0111 1100 | 61 3D 0011 1101 = 125 7D 0111 1101 } 62 3E 0011 1110 > 126 7E 0111 1110 ~ 63 3F 0011 1111 ? 127 7F 0111 1111
计算机数据存储单位
位 bit:
最小值 0
最大值 1
表示的数的范围 0-1
字节 Byte:
最小值 00000000
最大值 11111111
表示的数的范围 0-255
字符 char:
最小值 0000 0000 0000 0000
最大值 1111 1111 1111 1111
表示的数的范围0-65535
B、KB、MB、GB、TB:
1 Byte=8 bit
1 KB = 1024 Byte
1 MB = 1024 KB
1 GB = 1024 MB
1 TB = 1024 GB
计数范围
符号位:
二进制数如何表示正数和负数:使用最高位作为符号位,0代表正数,1代表负数,其余数位用作数值位,代表数值
字节 byte表示的数的范围:
无符号数:0-255 256个数
有符号数:-128 - 127 还是256个数
字符表示的数的范围:
无符号数 0-65535 65536个数
有符号数 -32768 -32767 还是65536个数
ASCLL表
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ojLYUPMg-1653308049326)(C:\Users\纵横\AppData\Roaming\Typora\typora-user-images\image-20210823143059045.png)]
标识符
标识符的含义:
是指在程序中,我们自己定义的内容,譬如,类的名字,方法名称以及变量名称等等,都是标识符
命名规则:
a、标识符只能由数字、字母(包括中文)、下划线_ 、美元符号$组成,不能含有其他符号
b、标识符不能以数字开头,标识符中不能有空格
c、关键字不能做标识符
d、Java 标识符大小写敏感,且长度无限制
命名规范:
类名规范:首字符大写,后面每个单词首字母大写(大驼峰式)
变量名规范:首字母小写,后面每个单词首字母大写(小驼峰式)
方法名规范:同变量名
常量与变量
变量 :
变量本质上就是代表一个”可操作的存储空间“,空间位置是确定的,但是里面放置什么值不确定。我们可通过变量名来访问“对应的存
储空间”,从而操纵这个“存储空间”存储的值
Java是一种强类型语言,每个变量都必须声明其数据类型。变量的数据类型决定了变量占据存储空间的大小。 比如,int a=3; 表示a
变量的空间大小为4个字节
变量作为程序中最基本的存储单元,其要素包括变量名、变量类型和变量值。变量在使用前必须对其声明, 只有在变量声明以后,才
能为其分配相应长度的存储空间
变量的声明:
变量类型 变量名 =初始值;
type varName = value;
常量 :
可以利用关键字final来定义一个常量,常量一旦被初始化后不能再更改其值
声明格式为:
final type varName = value;
类型分为:字面常量(1,2,true、“hello”)和符号常量(PI)
Java八种基本数据类型
Java的数据类型可分为两大类:
基本数据类型(primitive data type)和引用数据类型(reference data type)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1qp3rW48-1653308049327)(C:\Users\纵横\AppData\Roaming\Typora\typora-user-images\image-20210823145411710.png)]
三类八种基本数据类型:
数值型- byte、 short、int、 long、float、 double
字符型- char
布尔型-boolean
类型 内存大小 默认值 取值范围 byte 1字节 0 -128~127 short 2字节 0 -32768~32767 int 4字节 0 -2的31次方到2的31次方-1 long 8字节 0 -2的63次方到2的63次方-1 float 4字节 0.0 float类型的数值有一个后缀F(例如:3.14F) double 8字节 0.0 没有后缀F的浮点数值(如3.14)默认为double类型 char ISO8859-1 1;GB2312/GBK 2;UTF-8 3 '\u0000 ’ boolean 1字节 false false、true 注意:
1、引用数据类型的大小统一为4个字节,记录的是其引用对象的地址
2、整数数据类型默认为int
float类型又被称作单精度类型,尾数可以精确到7位有效数字
double类型的数值精度约是float类型的两倍,被称作双精度类型,绝大部分应用程序都采用double类型,为默认浮点数据类型
如果需要进行不产生舍入误差的精确数字计算,需要使用BigDecimal类
转义字符:
转义符 含义 Unicode值 \b 退格(backspace) \u0008 \n 换行 \u000a \r 回车 \u000d \t 制表符(tab) \u0009 \“ 双引号 \u0022 \‘ 单引号 \u0027 \ 反斜杠 \u005c boolean类型占用字节数:
在Java虚拟机中没有任何供boolean值专用的字节码指令,Java语言表达式所操作的boolean值,在编译之后都使用Java虚拟机中的
int数据类型来代替,而boolean数组将会被编码成Java虚拟机的byte数组,每个元素boolean元素占8位。这样我们可以得出
boolean类型占了单独使用是4个字节,在数组中又是1个字节
运算符
运算符种类 符号 算术运算符 - 二元运算符 +、-、*、/、% 算术运算符 - 一元运算符 ++、– 赋值运算符 = 扩展运算符 +=,-=,*=,/= 关系运算符 >、<、>=,<=、==、!=、 instanceof 逻辑运算符 &&、||、!、^ 条件运算符 ? : 字符串连接符 + 二元运算符的运算规则:
1、整数运算:
如果两个操作数有一个为long,,则结果也为long,没有long时,结果为int。即使操作数全为short,byte,结果也是int
2、浮点运算:
如果两个操作数有一个为double,则结果为double。只有两个操作数都是float,则结果才为float
3、取模运算:
其操作数可以为浮点数,一般使用整数,结果是“余数”,“余数”符号和左边操作数相同,如:7%3=1,-7%3=-1,7%-3=1
4、i++和++i的区别:
i++:先赋值,后计算
++i:先计算,后赋值
拓展运算符:
运算符 用法举例 等效的表达式 += a += b a = a+b -= a -= b a = a-b *= a *= b a = a*b /= a /= b a = a/b %= a %= b a = a%b 关系运算符:
运算符 含义 示例 == 等于 a==b != 不等于 a!=b > 大于 a>b < 小于 a<b >= 大于或等于 a>=b <= 小于或等于 a<=b 注意事项:
1、= :赋值运算符,而真正的判断两个操作数是否相等的运算符是==
2、== 、!= :所有(基本和引用)数据类型都可以使用
3、> 、>=、 <、 <= :仅针对数值类型(byte/short/int/long,float/double 以及char)
4、> 、>=、 <、 <= :优先级别大于==、!=
逻辑运算符:
运算符 符号表示 说明 逻辑与 & 两个操作数为true,结果才是true,否则是false 逻辑或 | 两个操作数有一个是true,结果就是true 短路与 && 只要有一个为false,则直接返回false 短路或 || 只要有一个为true, 则直接返回true 逻辑非 ! 取反:!false为true,!true为false 逻辑异或 ^ 相同为false,不同为true 逻辑与和短路与:有假则为假,先真就是真
逻辑或和短路或:全假则为假,先真就是真
条件运算符:
三目运算符:表达式 ? 值1 : 值2
表达式为真取值1,表达式为假取值2
运算符的优先级别:
优先级 运算符 类 结合性 1 () 括号运算符 由左至右 2 !、+(正号)、-(负号) 一元运算符 由左至右 2 ~ 位逻辑运算符 由右至左 2 ++、– 递增与递减运算符 由右至左 3 *、/、% 算术运算符 由左至右 4 +、- 算术运算符 由左至右 5 <<、>> 位左移、右移运算符 由左至右 6 >、>=、<、<= 关系运算符 由左至右 7 ==、!= 关系运算符 由左至右 8 & 位运算符、逻辑运算符 由左至右 9 ^ 位运算符、逻辑运算符 由左至右 10 | 位运算符、逻辑运算符 由左至右 11 && 逻辑运算符 由左至右 12 || 逻辑运算符 由左至右 13 ? : 条件运算符 由右至左 14 =、+=、-=、*=、/=、%= 赋值运算符、扩展运算符 由右至左 注意事项:
1、优先级别最低的赋值运算符和条件运算符
2、总体而言,算术>关系>逻辑>条件>赋值
3、运算级别最高的是( ),单目运算符运算级别都很高,比如++、–、~、!
面向对象和面向过程的区别
面向过程和面向对象都是对软件分析、设计和开发的一种思想,它指导着人们以不同的方式去分析、设计和开发软件
面向过程:
一种较早的编程思想,顾名思义就是该思想是站在过程的角度思考问题,强调的就是功能行为,功能的执行过程,即先后顺序,而每
一个功能我们都使用函数(类似于方法)把这些步骤一步一步实现。使用的时候依次调用函数就可以了
面向对象:
一种基于面向过程的新编程思想,顾名思义就是该思想是站在对象的角度思考问题,我们把多个功能合理放到不同对象里,强调的是
具备某些功能的对象。具备某种功能的实体,称为对象。面向对象最小的程序单元是:类。面向对象更加符合常规的思维方式,稳定
性好,可重用性强,易于开发大型软件产品,有良好的可维护性。在软件工程上,面向对象可以使工程更加模块化,实现更低的耦合
和更高的内聚
面向对象和面向过程思想的总结:
a、都是解决问题的思维方式,都是代码组织的方式
b、面向过程是一种“执行者思维”,解决简单问题可以使用面向过程
c、面向对象是一种“设计者思维”,解决复杂、需要协作的问题可以使用面向对象
d、面向对象离不开面向过程
e、宏观上:通过面向对象进行整体设计
f、微观上:执行和处理数据,仍然是面向过程
类与对象的关系
1、类是对一类事物的描述,是抽象的
2、对象是一类事物的实例,是具体的
3、类是对象的模板,对象是类的实例
类与对象的构成与创建
java类的构成:
1、属性:
用于定义该类或该类对象包含的数据或者说静态特征,定义成员变量时可以对其初始化,如果不对其初始化,Java使用默认值对其初
始化
属性定义格式:
[修饰符] 属性类型 属性名 = [默认值] ;
局部变量和成员变量:
类中定义的变量是成员变量,而方法中定义的变量,包括方法的参数,代码块中定义的变量被称为局部变量
不同点 成员变量 局部变量 代码中位置不同 类中定义的变量 方法或代码块中定义的变量 内存中位置不同 堆内存 栈内存 是否有默认值 有 没有 代码作用范围(空间) 当前类的方法 当前一个方法或代码块 作用时间不同 当前对象从创建到销毁 定义变量到所属方法或代码块执行完毕 2、方法:
方法用于定义该类或该类实例的行为特征和功能实现。方法是类和对象行为特征的抽象。方法很类似于面向过程中的函数。面向过程
中,函数是最基本单位,整个程序由一个个函数调用组成。面向对象中,整个程序的基本单位是类,方法是从属于类和对象的
方法定义格式:
[修饰符] 方法返回值类型 方法名(形参列表…) { 方法体… }
3、构造方法:
构造方法(constructor)也叫构造器,用于对象的初始化。构造器是一个创建对象时被自动调用的特殊方法,目的是对象的初始化。构
造器的名称应与类的名称一致。Java通过new关键字来调用构造器,从而返回该类的实例
构造器定义格式:
[修饰符] 类名(形参列表){ 方法体 }
构造方法5要点:
a、构造方法的方法名必须和类名一致
b、构造方法通过new关键字调用
c、构造方法虽然有返回值,但是不能定义返回值类型(返回值的类型肯定是本类),不能在构造器里使用return返回某个值
d、如果我们没有定义构造方法,则编译器会自动定义一个无参的构造方法。如果已定义则编译器不会自动添加
e、构造方法可重载
构造方法调用方式:
a、通过new关键字调用,帮助我们初始化对象
b、构造方法可以调用当前类的其他构造方法,通过this()的形式
c、在继承中, 子类构造方法一定会调用父构造方法,通过super()形式
创建对象过程:
a、分配对象空间,对象成员变量初始化为0或空
b、执行属性值的显示初始化(变量初始化为0或空)
c、 执行构造方法
d、返回对象的地址给相关的变量
子类的每一个构造方法都必须显式或隐式调用父类的一个构造方法。如果不显式调用, 则系统隐式调用super(),即父类的无参构造方法
(如果父类无任何构造方法, 则系统为父类自动提供一个无参构造方法; 如果父类已经有一个构造方法, 系统不会额外提供无参的构造方
法,此时, 如果父类仅定义了有参构造方法, 并且子类没有定义任何的构造方法(系统会为它提供一个无参构造方法, 然后隐式调用父类
无参构造方法), 或子类定义的构造方法中没有显式调用父类的有参构造方法(会隐式调用父类的无参构造方法), 就都会因为父类没有无
参构造方法而报错
构造方法的调用顺序:
1、父类的非静态初始化块,构造器
2、本类的非静态初始化块,构造器
注:
1、super用于显示调用父类的构造器,this用于显示调用本类中另一个重载的构造器
2、super调用和this 调用都只能在构造器中使用,并且都必须作为构造器的第一行代码
3、super调用和 this 调用最多只能使用其中之一, 而且最多只能调用一次
this关键字用法:
a、调用成员变量:如果成员变量和局部变量同名,this必须书写,用来区分两者
b、调用成员方法:这种情况下,this可以省略
c、调用构造方法:使用this关键字调用重载的构造方法,避免相同的初始化代码。但只能在构造方法中用,并且必须位于构造方法
的第一句
d、this不能用于static方法中
4、代码块:
分为成员代码块和静态代码块
成员代码块每次创建对象的时候都执行,先执行代码块,再执行构造方法
静态代码块第一次加载类的时候执行,只执行一次,一般用于执行一些全局性的初始化操作,比如创建工厂、加载数据库初始信息等
5、内部类:
值传递
基本数据类型的参数是值传递,引用数据类型的参数传递是引用(地址),本质上也是值传递
无论是值传递还是引用传递,其实都是一种求值策略(Evaluation strategy)。在求值策略中,还有一种叫做按共享传递(call by
sharing)。其实Java中的参数传递严格意义上说应该是按共享传递
按共享传递,是指在调用函数时,传递给函数的是实参的地址的拷贝(如果实参在栈中,则直接拷贝该值)。在函数内部对参数进行
操作时,需要先拷贝的地址寻找到具体的值,再进行操作。如果该值在栈中,那么因为是直接拷贝的值,所以函数内部对参数进行操
作不会对外部变量产生影响。如果原来拷贝的是原值在堆中的地址,那么需要先根据该地址找到堆中对应的位置,再进行操作。因为
传递的是地址的拷贝所以函数内对值的操作对外部变量是可见的
简单点说,Java中的传递,是值传递,而这个值,实际上是对象的引用
static关键字
一个类的成员包括变量、方法、构造方法、代码块和内部类,static可以修饰除了构造方法以外的所有成员
使用static修饰的成员成为静态成员,是属于某个类的。而不使用static修饰的成员成为实例成员,是属于类的每个对象的
1、Static可以修饰方法、变量、代码块以及内部类
2、Static修饰的类是静态内部类
3、Static修饰的方法是静态方法,表示该方法属于当前类的,而不属于某个对象的,静态方法不能被重写,可以直接使用类名打点调
用。在static方法中不能使用this或者super关键字
4、Static修饰变量是静态变量或者叫类变量,静态变量被所有实例所共享,不会依赖于对象。静态变量在内存中只有一份拷贝,在
JVM加载类的时候,只为静态变量分配一次方法区中内存
5、Static修饰的代码块叫静态代码块,通常用来做程序初始化操作的。静态代码块中的代码在整个类加载的时候只会执行一次。静态
代码块可以有多个,如果有多个,按照先后顺序依次执行
static静态成员变量:也称为类变量,生命周期和类相同,在整个应用程序执行期间都有效
类变量特点:
a、为该类的公用变量,属于类,被该类的共享,存储在方法区中在类被载入时被显式初始化
b、对于该类的所有对象来说,static成员变量只有一份。被该类的所有对象共享
c、一般用’类名.类属性/方法’来调用
d、在static方法中不可直接访问非static的成员
静态成员变量与实例成员变量的区别:
1、静态变量用static修饰,实例变量不用
2、静态变量被当前类对象共享是随着类的字节码的加载而被加载进内存的,所以只要程序一启动运行到该类时就会被加载进内存,
不管创建了多少个对象在内存中只存储一份。而实例变量是在创建对象以后才能被分配内存空间,是每个对象独有的,创建多少
个对象就会存储多少份
3、静态变量被存储到内存的方法区,实例变量被存储到堆中
4、静态变量是和类相关的,使用类名直接调用。实例变量是和对象相关的必须通过对象名调用
static静态方法:
通过类名调用 Student.showClassRoom()
通过对象名访问 stu1.showClassRoom()
静态方法中不可以访问非静态变量
静态方法中不可以访问非静态方法
静态方法中不可以访问this
非静态方法中可以访问静态变量
非静态方法中可以访问静态方法
非静态方法中可以访问this
面向对象特征
1、抽象:
抽象是将一类对象的共同特征总结出来构造类的过程,包括数据抽象和行为抽象两方面。抽象只关注对象有哪些属性和行为,并不关
注这些行为的细节是什么
2、继承:
继承是从已有类得到继承信息创建新类的过程,更加容易实现类的扩展,实现代码的重用。提供继承信息的类被称为父类(超类、基
类) ;得到继承信息的类被称为子类(派生类)。private修饰的成员不可被继承
继承使用要点:
a、父类也称作超类、基类。子类:派生类等
b、Java中只有单继承,没有像C++那样的多继承。多继承会引起混乱,使得继承链过于复杂,系统难于维护
c、子类继承父类,可以得到父类的全部属性和方法 (除了父类的构造方法),但不见得可以直接访问(比如,父类私有的属性和方法)。
如果定义一个类时,没有调用extends,则它的父类是:java.lang.Object
继承条件下构造方法的执行顺序:
a、构造方法的第一条语句默认是super(),含义是调用父类无参数的构造方法
b、构造方法的第一条语句可以显式的指定为父类的有参数构造方法:super(…)
c、构造方法的第一条语句可以显式的指定为当前类的构造方法:this(…)
注意事项:
a、每个类最好要提供无参数的构造方法
b、构造方法的第一条语句可以是通过super或者this调用构造方法,须是第一条语句
c、构造方法中不能同时使用super和this调用构造方法,并不是说不能同时出现this和super
d、构造方法不能被子类继承
e、子类的构造方法一定会调用父类的构造方法
f、在子类的构造方法中,使用super()的形式默认调用父类无参构造方法
g、当父类中没有无参构造方法时,子类构造方法中必须显示书写super()并传入实参
h、super()必须是子类构造方法的第一行
3、封装:
封装就是把对象的属性和操作结合为一个独立的整体,并尽可能隐藏对象的内部实现细节,仅仅对外公开使用的接口/方法。达到高
内聚低耦合的程序设计要求。实现方式是使用private修饰变量,对外提供getter和setter方法。高内聚就是类的内部数据操作细节自
己完成,不允许外部干涉;低耦合是仅暴露少量的方法给外部使用,尽量方便外部调用
编程中封装的具体优点:
a、提高代码的安全性
b、提高代码的复用性
c、“高内聚”:封装细节,便于修改内部代码,提高可维护性
d、“低耦合”:简化外部调用,便于调用者使用,便于扩展和协作
4、多态性:
多态性是指同一个方法调用,由于对象不同可能会有不同的行为。当有继承关系时,可能发生编译期类型和运行期类型不同的情况,
即编译期类型是父类类型,运行期类型是子类类型。即:父类引用指向子类对象。简单的说就是用同样的对象引用调用同样的方法但
是做了不同的事情。多态性分为编译时的多态性和运行时的多态性。方法重载(overload)实现的是编译时的多态性(也称为
前绑定),而方法重写(override)实现的是运行时的多态性(也称为后绑定)
多态的要点:
a、多态是方法的多态,不是属性的多态(多态与属性无关)
b、多态的存在要有3个必要条件:继承,方法重写,父类引用指向子类对象
c、父类引用指向子类对象后,用该父类引用调用子类重写的方法,此时多态就出现了
运行时的多态是面向对象最精髓的东西,要实现多态需要做两件事:
a、方法重写(子类继承父类并重写父类中已有的或抽象的方法)
b、对象引用(用父类型引用引用子类型对象,这样同样的引用调用同样的方法就会根据子类对象的不同而表现出不同的行为)
this和super
this:
this三大作用:this调用属性、调用方法、利用this表示当前对象
this的含义:this是自身的一个对象,代表对象本身,可以理解为:指向对象本身的一个指针
this的用法在java中大体可以分为3种:
1、普通的直接引用,this指向当前对象本身
2、形参与成员名字重名,用this来区分
3、引用构造函数
super(参数):调用父类中的某一个构造函数(应该为构造函数中的第一条语句)
this(参数):调用本类中另一种形式的构造函数(应该为构造函数中的第一条语句)
super:
super可以理解为是指向自己超(父)类对象的一个指针,而这个超类指的是离自己最近的一个父类
super也有三种用法:
1、普通的直接引用,super相当于是指向当前对象的父类,这样就可以用super.xxx来引用父类的成员
2、子类中的成员变量或方法与父类中的成员变量或方法同名
3、引用构造函数
super(参数):调用父类中的某一个构造函数(应该为构造函数中的第一条语句)
this(参数):调用本类中另一种形式的构造函数(应该为构造函数中的第一条语句)
super和this的异同:
1、super(参数):调用基类中的某一个构造函数(应该为构造函数中的第一条语句)
2、this(参数):调用本类中另一种形式的构造函数(应该为构造函数中的第一条语句)
3、super:它引用当前对象的直接父类中的成员(用来访问直接父类中被隐藏的父类中成员数据或函数,基类与派生类中有相同成
员定义时如:super.变量名 super.成员函数据名(实参)
4、this:它代表当前对象名(在程序中易产生二义性之处,应使用this来指明当前对象;如果函数的形参与类中的成员数据同名,这
时需用this来指明成员变量名)
5、调用super()必须写在子类构造方法的第一行,否则编译不通过。每个子类构造方法的第一条语句,都是隐含地调用super(),如果
父类没有这种形式的构造函数,那么在编译的时候就会报错
6、super()和this()类似,区别是,super()从子类中调用父类的构造方法,this()在同一类内调用其它方法
7、super()和this()均需放在构造方法内第一行
8、尽管可以用this调用一个构造器,但却不能调用两个
9、this和super不能同时出现在一个构造函数里面,因为this必然会调用其它的构造函数,其它的构造函数必然也会有super语句的
存在,所以在同一个构造函数里面有相同的语句,就失去了语句的意义,编译器也不会通过
10、this()和super()都指的是对象,所以,均不可以在static环境中使用。包括:static变量,static方法,static语句块
11、从本质上讲,this是一个指向本对象的指针,然而super是一个Java关键字
方法重写和重载
方法的重载和重写都是实现多态的方式,区别在于前者实现的是编译时的多态性,而后者实现的是运行时的多态性。重载发生在一个
类中,同名的方法如果有不同的参数列表(参数类型不同、参数个数不同或者二者都不同)则视为重载;重写发生在子类与父类之
间,重写要求子类被重写方法与父类被重写方法有相同的返回类型,比父类被重写方法更好访问,不能比父类被重写方法声明更多的
异常(里氏替换原则)。重载对返回类型没有特殊的要求
1、重写(Override)
子类继承了父类原有的方法,但有时子类并不想原封不动的继承父类中的某个方法,所以在方法名,参数列表,返回类型(除过子类
中方法的返回值是父类中方法返回值的子类时)都相同的情况下, 对方法体进行修改或重写就是重写。当子类重写父类方法时,从父
类继承的同名方法就会被隐藏,如果想调用父类中被隐藏的同名方法需要super关键字,但要注意子类函数的访问修饰权限不能少于
父类的权限修饰符
public class Father { public static void main(String[] args) { // TODO Auto-generated method stub Son s = new Son(); s.sayHello(); } public void sayHello() { System.out.println("Hello"); } } class Son extends Father{ @Override public void sayHello() { // TODO Auto-generated method stub System.out.println("hello by "); } }重写总结:
a、发生在父类与子类之间
b、方法名,参数列表,返回类型(除过子类中方法的返回类型是父类中返回类型的子类)必须相同
c、访问修饰符的限制一定要大于被重写方法的访问修饰符(public>protected>default>private)
d、重写方法一定不能抛出新的检查异常或者比被重写方法申明更加宽泛的检查型异常
2、重载(Overload)
在一个类中,同名的方法如果有不同的参数列表(参数类型不同、参数个数不同甚至是参数顺序不同)则视为重载。同时,重载对返
回类型没有要求,可以相同也可以不同,不能通过返回类型是否相同来判断一个方法是否是重载重载方法
public class Father { public static void main(String[] args) { // TODO Auto-generated method stub Father s = new Father(); s.sayHello(); s.sayHello("wintershii"); } public void sayHello() { System.out.println("Hello"); } public void sayHello(String name) { System.out.println("Hello" + " " + name); } }重载总结:
a、重载Overload是一个类中多态性的一种表现
b、重载要求同名方法的参数列表不同(参数类型,参数个数甚至是参数顺序)
c、重载的时候,返回值类型可以相同也可以不相同。无法以返回型别作为重载函数的区分标准
instanceof关键字
1、instanceof 是Java中的一个关键字,Java中的关键子都是小写
2、instanceof关键字的作用是判断左边对象是否是右边类的实例,返回值为boolean类型,是则返回true不是返回false
public class Dome{ class Perse extends Object{} class Student extends Perse{} //这个方法判断是否是Perse的实例,用instanceof判断。 void f(Object o){ //Object可以接收任何的类型。 if(o instanceof Perse){ System.out.println("你输入的对象是Perse的实例"); }else{ System.out.println("你输入的对象不是Perse的实例"); } public static void main(String[] args){ Dome dome =new Doem(); Perse perse =new Perse(); Student student =new Student(); Object object = new Object(); dome.f(/*shutdent或者perse或者object对象*/); //输入的是student和perse那么instanceof判断就会是true //if也就执行打印语句System.out.println("你输入的对象是Perse的实例") //那么输入object自然instanceof判断就是false。 //instanceof关键字的作用是判断左边对象是否是右边类的实例(通俗易懂的说就是:子类,或者右边类本身的对象) } }
访问修饰符
类的成员不写访问修饰时默认为default
默认对于同一个包中的其他类相当于公开(public)
对于不是同一个包中的其他类相当于私有(private)
受保护(protected)对子类相当于公开,对不是同一包中的没有父子关系的类相当于私有
Java中,外部类的修饰符只能是public或默认,类的成员(包括内部类)的修饰符可以是以上四种
1、private 表示私有,只有自己类能访问
2、default(friendly)表示没有修饰符修饰,只有同一个包的类能访问
3、protected表示可以被同一个包的类以及其他包中的子类访问
4、public表示可以被该项目的所有包中的所有类访问
修饰符 当前类 同包 子类 其他包 public 能 能 能 能 protected 能 能 能 不能 default 能 能 不能 不能 private 能 不能 不能 不能 类成员的处理:
a、一般使用private访问权限修饰成员变量
b、使用private修饰时提供相应的get/set方法来访问相关属性,这些方法通常是public修饰的,以提供对属性的赋值与读取操作(注
意:boolean变量的get方法是is开头!)
c、一些只用于本类的辅助性方法可以用private修饰,希望其他类调用的方法用public修饰
类的处理:
a、类只能使用public和默认来修饰
b、默认:当前包可访问
c、public:当前项目的所有包均可访问
d、public类要求类名和文件名相同,一个java文件中至多一个public修饰的类
Object类
Object类是所有Java类的根基类,也就意味着所有的 Java 对象都拥有Object类的属性和方法。如果在类的声明中未使用extends关键
字指明其父类,则默认继承Object类
常用方法:
1、equals()–>比较
2、Hashcode()–>计算hash值
3、toString()–>转换为字符串
4、wait()–>线程等待
5、notify()–>线程唤醒
6、clone()–>克隆
7、getClass()–>获得类对象
8、finalize()–>当垃圾回收器确定不存在对该对象的更多引用时,由对象的垃圾回收器调用此方法进行确认
native关键字:
a、一个native方法就是一个 Java 调用非 Java 代码的接口。一个native方法是指该方法的实现由非 Java 语言实现,比如用C或C++实
现
b、在定义一个native方法时,并不提供方法体,因为其实现体是由非 Java 语言在外面实现的。Java语言本身不能对操作系统底层进
行访问和操作,但是可以通过 JNI 接口调用其他语言来实现对底层的访问
c、JNI 是Java本机接口(Java Native Interface),是一个本机编程接口,它是 Java 软件开发工具箱(Java Software Development
Kit,SDK)的一部分。JNI 允许 Java 代码使用以其他语言编写的代码和代码库。Invocation API(JNI的一部分)可以用来将Java
虚拟机(JVM)嵌入到本机应用程序中,从而允许程序员从本机代码内部调用Java代码
==和equals
== 代表比较双方是否相同。如果是基本类型则表示值相等,如果是引用类型则表示地址相等即是同一个对象
Object 的 equals 方法默认就是比较两个对象的hashcode,是同一个对象的引用时返回 true 否则返回 false。显然,这无法满足子
类的要求,可根据要求重写equals方法
==:内存地址是否相同
== 比较的是变量(栈)内存中存放的对象的(堆)内存地址,用来判断两个对象的地址是否相同,即是否是指向相同一个对象。比较的是
真正意义上的指针操作
a、比较的是操作符两端的操作数是否是同一个对象
b、两边的操作数必须是同一类型的(可以是父子类之间)才能编译通过
c、比较的是地址,如果是具体的阿拉伯数字的比较,值相等则为true,如:int a=10 与 long b=10L 与 double c=10.0都是相同的
(为true),因为他们都指向地址为10的堆
equals:内容是否相同
equals用来比较的是两个对象的内容是否相等,由于所有的类都是继承自java.lang.Object类的,所以适用于所有对象,如果没有对
该方法进行覆盖的话,调用的仍然是Object类中的方法,而Object中的equals方法返回的却是==的判断
总结:
所有比较是否相等时,都是用equals并且在对常量相比较时,把常量写在前面,因为使用object的equals,object可能为null则空指
针异常,区别可以考虑常量池问题
hashCode、toString、equals
hashCode:
哈希码:hash码/散列码。是一种无序不重复的一串十六进制数据,Object类中定义的hashcode方法作用就是为每一个对象生成一
个独立的哈希码,用以区分每个对象,我们可以通过重写的方式自定义哈希码的声明规则,让其和属性值相关联。一般在重写equals
方法时,都会重写hashcode方法
toString:
Object 类中定义类一个方便我们快捷查看对象属性信息的一个方法,toString的目的是返回一个对象的字符串表达形式,Object类中
定义的方法规则为类的全路径名+哈希码,我们可以通过重写的方式重新定义该方法
equals:
如果两个对象x和y满足x.equals(y) == true,它们的哈希码(hash code)应当相同。Java对于eqauls方法和hashCode方法是这样规
定的:
(1)如果两个对象相同(即equals方法返回 true),那么它们的hashCode值一定要相同
(2)如果两个对象的hashCode相同,它们并不一定是同一个对象
final、finalize、finally的区别
性质不同:
1、final为关键字
2、finalize()为方法
3、finally{}为区块标志,用于try语句中
作用不同:
1、final
a、被final修饰的类不可以被继承
b、被final修饰的方法不可以被重写
c、被final修饰的变量不可以被改变,如果修饰引用,那么表示引用不可变,引用指向的内容可变
d、被final修饰的方法,JVM会尝试将其内联,以提高运行效率
e、被final修饰的常量,在编译阶段会存入常量池中
注意:
a、final不能修饰构造方法
b、final修饰基本数据类型,值只能赋值一次,后续不能再赋值
c、final修饰引用数据类型,final Dog dog = new Dog(“亚亚”);不能变化的引用变量的值dog,可以变化的是对象的属性"亚亚"
除此之外,编译器对final域要遵守的两个重排序规则更好:
在构造函数内对一个final域的写入,与随后把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序
初次读一个包含final域的对象的引用,与随后初次读这个final域,这两个操作之间不能重排序
2、finalize()
finalize()方法在Object中定义用于GC垃圾回收。当对象变成(GC Roots)不可达时,GC会判断该对象是否覆盖了finalize方法,若未覆
盖,则直接将其回收。否则,若对象未执行过finalize方法,将其放入F-Queue队列,由一低优先级线程执行该队列中对象的finalize
方法。执行finalize方法完毕后,GC会再次判断该对象是否可达,若不可达,则进行回收,否则,对象“复活”
3、finally{}
finally{}用于标识代码块,与try{}进行配合,不论try中的代码执行完或没有执行完(这里指有异常),该代码块之中的程序必定会进
行
接口
接口概念:
接口就是某个事物对外提供的一些功能的声明和规范,是一种特殊的 java 类,接口弥补了java单继承的缺点
声明格式:
[访问修饰符] interface 接口名 [extends 父接口1,父接口2…] { 常量定义;方法定义;}
接口特点:
1、接口中声明全是public static final修饰的常量
2、接口中所有方法都是共有的抽象方法
3、接口是没有构造方法的
4、接口也不能直接实例化
5、接口不可被继承,可被多实现
6、接口作为方法参数,其实现类对象就可以作为实参传入
7、接口作为返回值,其实现类对象就可以作为结果返回
8、只有接口才能继承接口,一个接口还可以同时继承多个接口
9、实现类要实现所有层级接口中定义的抽象方法
定义接口的详细说明:
a、访问修饰符:只能是public或默认
b、接口名:和类名采用相同命名机制
c、extends:接口可以多继承
d、常量:接口中的属性只能是常量,总是:public static final 修饰
e、方法:接口中的方法只能是:public abstract
接口的组成:
a、接口和数组、类、抽象类是同一个层次的概念
b、成员变量:接口中所有的变量都使用public static final修饰,都是全局静态常量
c、成员方法: 接口中所有的方法都使用public abstract修饰,都是全局抽象方法
d、构造方法:接口不能new,也没有构造方法
e、接口做方法的形参,实参可以该接口的所有实现类
普通类、抽象类、接口
一、普通类、抽象类和接口区别:
1、普通类可以实例化,接口都不能被实例化(它没有构造方法),抽象类如果要实例化,必须指向实现所有抽象方法的子类对象(抽象
类可以直接实例化,直接重写自己的抽象方法),接口必须指向实现所有所有接口方法的类对象
2、抽象类要被子类继承,接口要被子类实现
3、接口只能做方法的声明,抽象类可以做方法的声明,也可以做方法的实现
4、接口里定义的变量只能是公共的静态常量,抽象类中定义的变量是普通变量
5、抽象类里的抽象方法必须全部被子类所实现,如果子类不能全部实现父类的抽象方法,那么该子类只能是抽象类。同样,一个类
实现接口的时候,如果不能全部实现接口方法,那么该类只能是抽象类
6、抽象方法只能声明,不能实现。接口是设计的结果,抽象类是重构的结果****
7、抽象类里可以没有抽象方法
8、如果一个类里有抽象方法,那么该类只能是抽象类
9、抽象方法要被实现,所以不能是静态的,也不能是私有的
10、接口可以继承接口,并可多继承接口,但类只能单继承
11、接口中的常量有固定的修饰符 - public static final
12、接口中的抽象方法有固定的修饰符 - public abstract
13、接口细节: 若接口中方法或变量没有写public,static,final / public,abstract ,会自动补齐 。 接口中的成员都是共有的。
接口与接口之间是继承关系,而且可以多继承。 接口不能被实例化。一个类可以实现多个接口。在java开发中,我们经常把常用
的变量,定义在接口中,作为全局变量使用,访问形式:接口名.变量名。 一个接口不能继承其它的类,但是可以继承别的接口
一个重要的原则:当一个类实现了一个接口,要求该类把这个接口的所有方法全部实现注意:
① 抽象类和接口都是用来抽象具体的对象的,但是接口的抽象级别更高
② 抽象类可以有具体的方法和属性,接口只能有抽象方法和静态常量
③ 抽象类主要用来抽象级别,接口主要用来抽象功能
④ 抽象类中抽象方法不包含任何的实现,派生类必须覆盖它们。接口中所有方法都必须是未实现的
⑤ 接口方法,访问权限必须是公共的 public
⑥ 接口内只能有公共方法,不能存在成员变量
⑦ 接口内只能包含未被实现的方法,也叫抽象方法,但是不能用 abstract 关键字修饰
⑧ 抽象类的访问速度比接口要快,接口是稍微有点慢,因为它需要时间去寻找在类中实现的方法
⑨ 抽象类,除了不能被实例化外,与普通 java 类没有任何区别
⑩ 抽象类可以有 main 方法,接口没有 main 方法
⑪ 抽象类可以用构造器,接口没有
⑫ 抽象方法可以有 public、protected 和 default 这些修饰符,接口只能使用默认 public
⑬ 抽象类,添加新方法可以提供默认的实现,不需要改变原有代码。接口添加新方法,子类必须实现
⑭ 抽象类的子类用 extends 关键字继承,接口用 implements 来实现
二、什么时候用抽象类和接口
14、如果你拥有一些方法并且想让他们中的一些有默认实现,那就用抽象类
15、如果你想实现多重继承,那么必须使用接口。由于 java 不支持多继承,子类不能继承多个父类,但是可以实现多个接口,因此
你可以使用接口来实现它
16、如果基本基本功能在不断变化,那么就需要使用抽象类。如果不断改变基本功能并且使用接口,那么所有实现类都需要改变
抽象类和接口的区别
抽象类和接口都不能够实例化,但可以定义抽象类和接口类型的引用
一个类如果继承了某个抽象类或者实现了某个接口都需要对其中的抽象方法全部进行实现,否则该类仍然需要被声明为抽象类。
接口比抽象类更加抽象,因为抽象类中可以定义构造器,可以有抽象方法和具体方法,而接口中不能定义构造器而且其中的方法全部
都是抽象方法。抽象类中的成员可以是private 、default 、protected 、public的,而接口中的成员全都是public的。抽象类中可以
定义成员变量,而接口中定义的成员变量实际上都是常量。有抽象方法的类必须被声明为抽象类,而抽象类未必要有抽象方法。
抽象类:
a、抽象方法,只有行为的概念,没有具体的行为实现。使用abstract关键字修饰,没有方法体。子类必须重写这些抽象方法
b、包含抽象方法的类,一定是抽象类
c、抽象类只能被继承,一个类只能继承一个抽象类
接口:
a、全部的方法都是抽象方法,属性都是常量
b、不能实例化,可以定义变量。
c、接口变量可以引用具体实现类的实例
d、接口只能被实现,一个具体类实现接口,必须实现全部的抽象方法
e、接口之间可以多实现
f、一个具体类可以实现多个接口,实现多继承现象
内部类
成员内部类:定义在类内部的非静态类
成员内部类不能定义静态方法和变量(final修饰的除外)。这是因为成员内部类是非静态的,类初始化的时候先初始化静态成员,如
果允许成员内部类定义静态变量,那么成员内部类的静态变量初始化顺序是有歧义
成员内部类特征:
1、可以使用四个访问修饰符
2、内部类中可以直接使用外部类的成员变量,OuterClass.this.num
3、内部类可以直接调用外部类的成员方法
4、在内部类方法中通过 外部类类名.this.成员变量名 区分内部类和外部类的同名成员变量
5、外部类是不能直接使用内部类的成员变量和成员方法的,需要先创建对象再通过对象名访问
6、内部类可以实现很好的隐藏,当一个类仅仅为另一个类服务,就可以将类作为内部类
7、内部类可以帮我我们区分因继承和实现接口所造成的方法不可区分的问题
8、必须先创建外部类的对象,才能创建内部类的对象。非静态成员内部类是属于某个外部类对象的
9、非静态内部类不能有静态方法、静态属性和静态初始化块
10、外部类的静态方法、静态代码块不能访问非静态内部类,包括不能使用非静态内部类定义变量、创建实例
静态内部类:定义在类内部的静态类
1、静态内部类只能够访问外部类的静态成员
2、静态内部类如何访问外部类的同名的成员变量:OuterClass.num
3、静态内部类属于整个外部类的。创建静态内部类的对象,不需先创建外部类的对象
4、外部类可以通过类名直接访问内部类的静态成员,访问非静态成员依旧需要先创建内部类对象
局部内部类:定义在方法内部的,作用域只限于本方法
1、在方法中声明的类就是局部内部类
2、仅仅在当前方法中可用
3、局部内部类中只能直接使用外部类的常量
4、JDK1.8开始,局部内部类中使用常量的final关键字可以省略不写
匿名内部类:
匿名内部类就是内部类的简化写法,是一种特殊的局部内部类。
前提:存在一个类或者接口,这里的类可以是具体类也可以是抽象类
本质是什么呢? - ->是一个继承了该类或者实现了该接口的子类匿名对象
适合那种只需要创建一次对象的类。比如:Java GUI编程、Android编程键盘监听操作等等。比如Java开发中的线程任务Runnble、
外部比较器Comparator等
匿名内部类特点:
1、当一个接口中/抽象类中抽象方法的数量比较少,匿名内部类应用的位置也比较少,接口的实现类对象应用位置也比较少
2、用一个类去实现接口就显得比较麻烦,可以通过局部内部类去简化写法
3、匿名内部类可以帮助我们快速的为接口或者抽象类产生一个实现对象/子类对象
4、 匿名内部类没有构造方法
5、 匿名内部类自定义的方法和属性的get/set方法往往是无法调用的
6、只能使用代码块对成员变量进行初始化
7、匿名内部类作为局部内部类的一种,是方法内的内部类
语法:
new 父类构造器(实参类表) 实现接口 () {
//匿名内部类类体!
}
-->使用匿名内部类 abstract class Person { public abstract void eat(); } public class Demo { public static void main(String[] args) { Person p = new Person() { public void eat() { System.out.println("eat something"); } }; p.eat(); } } -->接口中使用匿名内部类 interface Person { public void eat(); } public class Demo { public static void main(String[] args) { Person p = new Person() { public void eat() { System.out.println("eat something"); } }; p.eat(); } } -->多线程中使用匿名内部类 public class Demo { public static void main(String[] args) { Thread t = new Thread() { public void run() { for (int i = 1; i <= 5; i++) { System.out.print(i + " "); } } }; t.start(); } }
异常体系
Error:
Error类层次描述了Java运行时系统内部错误和资源耗尽错误,一般指与JVM或动态加载等相关的问题,如虚拟机错误,动态链接失
败,系统崩溃等
这类错误是我们无法控制的,同时也是非常罕见的错误。所以在编程中,不去处理这类错误。注:我们不需要管理Error!
Exception:
所有异常类的父类,其子类对应了各种各样可能出现的异常事件
Exception异常分类:
a、运行时异常Runtime Exception(unchecked Exception)
可不必对其处理,系统自动检测处理
一类特殊的异常,如被 0 除、数组下标超范围等,其产生比较频繁,处理麻烦,如果显式的声明或捕获将会对程序可读性和运行效率
影响很大
b、检查异常 Checked Exception
必须捕获进行处理,否则会出现编译错误
注意:只有 Java 提供了Checked异常,体现了Java的严谨性,提高了 Java 程序的健壮性。同时也是一个备受争议的问题
异常处理方式:
a、try-catch捕获处理
b、throws/throw抛出
try-catch-finally执行情况:
a、try块中代码没有出现异常
不执行catch块代码,执行catch块后边的代码
b、try块中代码出现异常,catch中异常类型匹配(相同或者父类)
执行catch块代码,执行catch块后边的代码
c、try块中代码出现异常, catch中异常类型不匹配
不执行catch块代码,不执行catch块后边的代码,程序会中断运行
d、不论程序是否出现异常,都执行finally中代码,有返回值时先执行finally{}中代码然后返回结果
注意:
a、出现异常后,Java会生成相应的异常对象,Java系统寻找匹配的catch块,找到后将异常对象赋给catch块异常参数
b、出现异常后,try块中尚未执行的语句不会执行
c、出现异常并处理后,catch块后面的语句还会执行
异常类型:
异常类型 说 明 Exception 异常层次结构的根类 ArithmeticException 算术错误情形,如以零作除数 ArrayIndexOutOfBoundsException 数组下标越界 NullPointerException 尝试访问 null 对象成员 ClassNotFoundException 不能加载所需的类 InputMismatchException 想得到的数据类型与实际输入类型不匹配 IllegalArgumentException 方法接收到非法参数 ClassCastException 对象强制类型转换出错 NumberFormatException 数字格式转换异常,如把"ab"转换成数字

char类型
char类型可以存储一个中文汉字,因为Java中使用的编码是Unicode(不选择任何特定的编码,直接使用字符在字符集中的编号,这
是统一的唯一方法),一个char类型占2个字节(16 比特),所以放一个中文是没问题的。
补充:使用Unicode意味着字符在 JVM 内部和外部有不同的表现形式,在JVM内部都是Unicode,当这个字符被从JVM内部转移到外
部时(例如存入文件系统中),需要进行编码转换。所以Java中有字节流和字符流,以及在字符流和字节流之间进行转换的转换流,
如InputStreamReader和OutputStreamReader,这两个类是字节流和字符流之间的适配器类,承担了编码转换的任务
Char在 java 中也是比较特殊的类型,它的int值从1开始,一共有2的16次方个数据
Char<int<long<float<double
Char类型可以隐式转成int,double类型,但是不能隐式转换成string
如果char类型转成byte,short类型的时候,需要强转
String、StringBuffer、StringBuilder的区别
String是只读字符串,它并不是基本数据类型,而是一个对象。从底层源码来看是一个final类型的字符数组,所引用的字符串不能被
改变,一经定义,无法再增删改。每次对String的操作都会生成新的String对象,每次 ‘+’ 拼接字符串操作时,隐式在堆上new了一个
跟原字符串相同的StringBuilder对象,再调用append方法拼接 ‘+’ 后面的字符。当频繁更改字符串时,会造成内存浪费。而
StringBuffer和StringBuilder就不一样了,他们两都继承了AbstractStringBuilder抽象类,又实现了CharSequence接口,从抽象类
中我们可以看到他们的底层都是可变的字符数组,所以在进行频繁的字符串操作时,建议使用StringBuffer和StringBuilder来进行操
作。StringBuilder类在Java5中被提出,它和StringBuffer之间的最大不同在于StringBuilder的方法不是线程安全的(不能同步访
问)。由于StringBuilder相较于StringBuffer有速度优势,所以多数情况下建议使用StringBuilder类。然而在应用程序要求线程安全
的情况下,则必须使用StringBuffer类,此类中国的方法大多都加了synchronized关键字保证多线程情况下的操作安全性
![image-20210814141007793]()
![image-20210814141046678]()
![image-20210814141122917]()
![image-20210814141349122]()
![image-20210814141455639]()
字符串常量池及其具体实现
什么是字符串常量池:
JVM为了减少字符串对象的重复创建,其维护了一块特殊的内存存放已存在的字符串,这段内存被称为字符串常量池(存储在方法区
中)
具体实现:
当代码中出现字符串时,JVM首先会对其进行检查,如果字符串常量池中存在相同内容的字符串对象,则不再创建,直接返回将此字
符串对象的地址返回。如果字符串常量池中不存在相同内容的字符串对象,则创建一个新的字符串对象并放入常量池,并返回新创建
的字符串的引用地址。例如:new String(“str”)时,首先也会去检查常量池是否存在“str”,存在则不创建、不存在则在堆空间再开辟
一块内存区域创建字符串对象 然后放入常量池
什么是拆装箱
装箱就是自动将基本数据类型转换为包装器类型(int–>Integer)
调用方法:Integer的valueOf(int)方法
拆箱就是自动将包装器类型转换为基本数据类型(Integer–>int)
调用方法:Integer的intValue()方法
在Java SE5之前,如果要生成一个数值为10的Integer对象,必须这样进行:Integer i = new Integer(10);
而在从Java SE5开始就提供了自动装箱的特性,如果要生成一个数值为10的Integer对象,只需要这样就可以了:Integer i = 10;
面试题1: 以下代码会输出什么? public class Main { public static void main(String[] args) { Integer i1 = 100; Integer i2 = 100; Integer i3 = 200; Integer i4 = 200; System.out.println(i1==i2); System.out.println(i3==i4); } } 结果:true和false。与Integer的缓冲区有关
Java中的基本数据类型及其包装类
–>基本数据类型与其包装类最主要的区别是基本数据类型不是类对象。包装类的优势在于是继承了Object的类,可以有方法和属
性
byte–>Byteshort–>Short
int–>Integer
long–>Long
float–>Float
double–>Double
char–>Character
boolean–>Boolean
针对浮点型数据运误差问题
使用Bigdecimal类进行浮点型数据的运算 public class ABigDecimal { public static void main(String[] args) { aFloat aFloat = new aFloat(); aFloat.aFloat(); ABigDecimal aBigDecimal = new ABigDecimal(); aBigDecimal.aDouble(); aBigDecimal.aBigDecimal(); } public void aDouble(){ double a = 0.65; double b = 0.6; double c = a-b; System.out.println(c); } public void aBigDecimal(){ BigDecimal b1 = new BigDecimal(Double.toString(1.2)); BigDecimal b2 = BigDecimal.valueOf(0.6); BigDecimal b3 = BigDecimal.valueOf(-0.6); BigDecimal bigDecimal = new BigDecimal(1000); BigDecimal bigDecimal2 = new BigDecimal("1000"); System.out.println("加:"+b1.add(b2)); //System.out.println(b1.add(b2).doubleValue()); System.out.println("减:"+b1.subtract(b2)); System.out.println("乘:"+b1.multiply(b2)); System.out.println("除:"+b1.divide(b2)); System.out.println("绝对值:"+b3.abs()); System.out.println(bigDecimal.multiply(b1)); System.out.println(bigDecimal2.multiply(b1)); } } class aFloat{ void aFloat(){ float a = 0.65f; float b = 0.6f; float c = a-b; System.out.println(c); } } 输出结果为: 0.049999952 0.050000000000000044 加:1.8 减:0.6 乘:0.72 除:2 绝对值:0.6 1200.0 1200.0
float=3.4;是否正确
-->不正确 3.4是双精度数,将双精度型(double)赋值给浮点型(float)属于向下转型(down-casting,也称为窄化)会造成精度损失,因此需要强制类型转换 float f =(float)3.4;或者写成 float f =3.4F;
数组概念、初始化与使用
数组是相同数据类型的有序集合
数组描述的相同类型的若干个数据,按照一定先后顺序排列组合而成
其中每一个数据称作一个数组元素,每一个数组元素可以通过下标来访问
数组的长度是固定的,一旦被创建就不可改变
其元素必须是相同类型有序集合,不可以出现混合类型
数组的变量属于引用类型,数组也可以看成是对象,数组中的每个元素相当于该对象中的成员变量
数组本身就是对象,java对象就是在堆中的,数组无论保持原始类型还是其他类型,数组对象本身实在堆中的
数组长度是确定的,一旦越界报 ArrayIndexOutOfBoundsException 数组下标越界异常
动态初始化:实例化数组的时候,只指定了数组程度,数组中所有元素都是数组类型的默认值 int[] num=new int[8]; 静态初始化:创建数组的时候已经指定数组中的元素, int [] num= new int[]{ 1 , 3 , 3} 二维数组: //动态初始化二维数组,开辟一维空间,未赋值 int[][] num1=new int[3][]; //开辟二维空间,未赋值 num1[0]=new int[2]; num1[1]=new int[3]; num1[2]=new int[4]; //为指定二维空间特定元素赋值 num1[0][0]=1; //同时为指定二维空间赋值 num1[0]=new int[]{1,2}; num1[1]=new int[]{5,8,9}; num1[2]=new int[]{4,8,9,5}; //直接静态初始化二维数组,并赋值 String[][] num2={{"yang","jing","da","xu","wang","ye"},{"tian","qi","hen","hao"}}; //数组num1和num2的长度,一维空间 System.out.println(num1.length); System.out.println(num2.length); //数组num1和num2的指定索引值二维空间的长度 System.out.println(num1[0].length); System.out.println(num2[1].length); //一维空间元素打印为hashcode值,二维空间打印为特定元素的值(前提已被赋值) System.out.println(Arrays.toString(num2)); System.out.println(Arrays.toString(num2[0])); System.out.println(num1[0][0]); System.out.println(num2[0][1]); 数组中常用方法: int [] num1={1,5,6,3,9,8,4,5}; //打印数组 System.out.println(Arrays.toString(num1)); //重新排序数组 Arrays.sort(num1); //打印数组 System.out.println(Arrays.toString(num1)); //搜索数组元素并返回索引值,使用前必须为数组重新排序 System.out.println("该数组元素的索引值"+Arrays.binarySearch(num1,6)); //在指定索引范围内填充元素,索引范围2<= && <4,填充值9 Arrays.fill(num1,2,4,9); System.out.println(Arrays.toString(num1));
String常用方法
1、equals()–>比较两个字符串是否为相同
2、toString()–>转换为字符串
3、length()–>返回字符串长度
4、substring()–>截取字符串
5、trim()–>去除字符串两端空白
6、replace()–>字符串替换
7、startsWith()–>判断开头字符串
8、endsWith()–>判断结尾字符串
9、equalsIgnoreCase()与equals()的区别是不分辨大小写
10、charAt():返回指定索引处的字符
11、indexOf():返回指定字符的索引
12、split():分割字符串,返回一个分割后的字符串数组
13、getBytes():返回字符串的byte类型数组
14、toLowerCase():将字符串转成小写字母
15、toUpperCase():将字符串转成大写字符
16、format():格式化字符串
形参与实参的区别
1、实参(argument)
全称为"实际参数"是在调用时传递给函数的参数. 实参可以是常量、变量、表达式、函数等, 无论实参是何种类型的量,在进行函数
调用时,它们都必须具有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使实参获得确定值
2、形参(parameter):
全称为"形式参数" 由于它不是实际存在变量,所以又称虚拟变量。是在定义函数名和函数体的时候使用的参数,目的是用来接收调用
该函数时传入的参数.在调用函数时,实参将赋值给形参。因而,必须注意实参的个数,类型应与形参一一对应,并且实参必须要有
确定的值。形参出现在函数定义中,在整个函数体内都可以使用,离开该函数则不能使用。实参出现在主调函数中,进入被调函数
后,实参变量也不能使用
形参和实参的功能是作数据传送。发生函数调用时,主调函数把实参的值传送给被调函数的形参从而实现主调函数向被调函数的数据
传送
a、形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只有在函数内部有效。函数调用结束返回主调函数后则不能再使用该形参变量
b、实参可以是常量、变量、表达式、函数等, 无论实参是何种类型的量,在进行函数调用时,它们都必须具有确定的值,以便把这
些值传送给形参。 因此应预先用赋值,输入等办法使实参获得确定值
c、实参和形参在数量上,类型上,顺序上应严格一致, 否则会发生“类型不匹配”的错误
d、函数调用中发生的数据传送是单向的。 即只能把实参的值传送给形参,而不能把形参的值反向地传送给实参。 因此在函数调用
过程中,形参的值发生改变,而实参中的值不会变化
e、当形参和实参不是指针类型时,在该函数运行时,形参和实参是不同的变量,他们在内存中位于不同的位置,形参将实参的内容
复制一份,在该函数运行结束的时候形参被释放,而实参内容不会改变。而如果函数的参数是指针类型变量,在调用该函数的过程
中,传给函数的是实参的地址,在函数体内部使用的也是实参的地址,即使用的就是实参本身。所以在函数体内部可以改变实参的
值
String str="a"与String str=new String(“a”)
String str=“a” - 编译期直接在字符串常量池中创建
String str=new String(“a”) - 运行期在堆中创建
math类常用方法
1、Pow():幂运算
2、Sqrt():平方根
3、Round():四舍五入
4、Abs():求绝对值
5、Random():生成一个0-1的随机数,包括0不包括1
Java的四种引用强弱软虚
1、强引用
我们平时声明的变量使用的就是强引用。如果一个对象被被人拥有强引用,那么垃圾回收器绝不会回收它。当内存空间不足,Java虚拟机宁愿抛出 OutOfMemoryError 错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足问题。
Java 的对象是位于 heap 中的,heap 中对象有强可及对象、软可及对象、弱可及对象、虚可及对象和不可到达对象。应用的强弱顺
序是强、软、弱、和虚。对于对象是属于哪种可及的对象,由他的最强的引用决定
String str = new String(“str”);
2、弱引用
如果一个对象只具有弱引用, 那该类就是可有可无的对象, 因为只要该对象被 GC 扫描到了随时都会把它干掉。
弱引用与软引用的区别在于:当GC在进行回收时,需要通过算法检查是否回收软引用对象,而对于弱引用对象总是进行回收。只具
有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不
管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具
有弱引用的对象。弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java 虚拟机就
会把这个弱引用加入到与之关联的引用队列中。
虽然GC在运行时一定回收弱引用对象,但复杂关系的若引用对象群常常需要好几次GC的运行才能完成。弱引用对象常常用于Map结
构中,引用数据量较大的对象,一旦该对象的强引用为 null 时。GC能够快速的回收该对象空间。
WeakReference wrf=newWeakReference(str);
可用场景:Java源码中的java.util.WeakHashMap中的key就是使用弱引用,我的理解就是,一旦我不需要某个引用,JVM会自动帮
我处理它,这样我就不需要做其它操作
3、软引用
如果一个对象只具有软引用,当内存空间足够时,GC就不会回收它,当内存空间不足时,JVM在抛出OOM之前,GC清理所有的软引
用对象。只要GC没有回收软引用,该对象就可以被程序使用。类似弱引用,只不过JVM会尽量让软引用的存活时间长一些,迫不得已
才清理。
软引用可用来实现内存敏感的高速缓存。
软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收,Java 虚拟机就会把这个软引用加
入到与之关联的引用队列中。
软引用是主要用于内存敏感的高速缓存。在 JVM 报告内存不足之前会清除所有的软引用,这样以来 GC就有可能收集软可及的对象,
可能解决内存吃紧问题,避免内存溢出。什么时候会被收集取决于 GC 的算法和 GC 运行时可用内存的大小。
// 注意:wrf这个引用也是强引用,它是指向SoftReference这个对象的
// 这里的软引用指的是指向new String(“str”)的引用,也就是SoftReference类中T
SoftReference wrf = new SoftReference(new String(“str”));
可用场景: 创建缓存的时候,创建的对象放进缓存中,当内存不足时,JVM就会回收早先创建的对象。
4、虚引用
又称为“幽灵引用”,与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何
引用一样,在任何时候都可能被垃圾回收。
虚引用主要用来跟踪对象被垃圾回收的活动,主要目的是在一个对象所占的内存被实际回收之前得到通知,从而可以进行一些相关的
清理工作。虚引用与软引用和弱引用的一个区别在于:虚引用必须和引用队列(ReferenceQueue)联合使用。当垃圾回收器准备回
收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。程序可以通过判
断引用队列中是否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。程序如果发现某个虚引用已经被加入到引用队列,
那么就可以在所引用的对象的内存被回收之前采取必要的行动。
虚引用的回收机制跟弱引用差不多,但是它被回收之前,会被放入ReferenceQueue中。注意哦,其它引用是被JVM回收后才被传入
ReferenceQueue中的。由于这个机制,所以虚引用大多被用于引用销毁前的处理工作。还有就是,虚引用创建的时候,必须带有
ReferenceQueue,使用例子:
PhantomReference prf=newPhantomReference(new String(“str”),newReferenceQueue<>());
可用场景:对象销毁前的一些操作,比如说资源释放等。Object.finalize() 虽然也可以做这类动作,但是这个方式即不安全又低效
上诉所说的几类引用,都是指对象本身的引用,而不是指Reference的四个子类的引用( SoftReference 等)
Java创建对象有几种方式
1、使用new 关键字
使用 new 关键字创建对象,实际上是做了两个工作,一是在内存中开辟空间,二是初始化对象。但是new 关键字只能创建非抽象对
象。
2、使用反射创建对象
反射是对于任意一个正在运行的类,都能动态获取到他的属性和方法。反射创建对象分为两种方式,一是使用Class类的new
Instance() 方法,二是使用Constructor类的new Instatnce() 方法。
两者区别在于:
Class.newInstance() 只能够调用无参的构造函数,即默认的构造函数;
Constructor.newInstance() 可以根据传入的参数,调用任意构造构造函数。
3、使用clone方法
要拷贝的对象需要实现Cloneable类,并重写clone()方法。
4、使用反序列化方式
当序列化和反序列化一个对象,jvm会给我们创建一个单独的对象。在反序列化时,jvm创建对象并不会调用任何构造函数。为了反
序列化一个对象,需要让类实现Serializable接口。然后在使用new ObjectInputStream().readObject() 来创建对象。
深拷贝和浅拷贝的区别是什么
当复制一个java对象时,由于对其属性复制后产生的效果不同,而产生了深拷贝与浅拷贝。
对于基本类型,深拷贝和浅拷贝都是一样的,都是对原始数据的复制,修改原始数据,不会对复制数据产生影响。
1、浅拷贝:
被复制对象的所有变量都含有与原来的对象相同的值,而所有的对其他对象的引用仍然指向原来的对象。换言之,浅拷贝仅仅复制所拷
贝的对象,而不复制它所引用的对象
2、深拷贝:
被复制对象的所有变量都含有与原来的对象相同的值.而那些引用其他对象的变量将指向被复制过的新对象.而不再是原有的那些被引
用的对象。换言之,深拷贝把要复制的对象所引用的对象都复制了一遍
如何实现对象克隆?
有两种方式:
1)、实现 Cloneable 接口并重写 Object 类中的 clone()方法
2)、实现 Serializable 接口,通过对象的序列化和反序列化实现克隆,可以实现真正的深度克隆,代码如下:
package chimomo.learning.java.code.clone; import java.io.Serializable; /** * Person. * * @author Created by Chimomo */ public class Person implements Serializable { private static final long serialVersionUID = -9102017020286042305L; private String name; // 姓名 private int age; // 年龄 private Car car; // 座驾 public Person(String name, int age, Car car) { this.name = name; this.age = age; this.car = car; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public Car getCar() { return car; } public void setCar(Car car) { this.car = car; } @Override public String toString() { return "Person [name=" + name + ", age=" + age + ", car=" + car + "]"; } } package chimomo.learning.java.code.clone; import java.io.Serializable; /** * Car. * * @author Created by Chimomo */ public class Car implements Serializable { private static final long serialVersionUID = -5713945027627603702L; private String brand; // 品牌 private int maxSpeed; // 最高时速 public Car(String brand, int maxSpeed) { this.brand = brand; this.maxSpeed = maxSpeed; } public String getBrand() { return brand; } public void setBrand(String brand) { this.brand = brand; } public int getMaxSpeed() { return maxSpeed; } public void setMaxSpeed(int maxSpeed) { this.maxSpeed = maxSpeed; } @Override public String toString() { return "Car[brand=" + brand + ", maxSpeed=" + maxSpeed + "]"; } } package chimomo.learning.java.code.clone; import java.io.ByteArrayInputStream; import java.io.ByteArrayOutputStream; import java.io.ObjectInputStream; import java.io.ObjectOutputStream; /** * @author Created by Chimomo */ public class CloneUtil { private CloneUtil() { throw new AssertionError(); } /** * Clone. * 调用ByteArrayInputStream或ByteArrayOutputStream对象的close方法没有任何意义, * 这两个基于内存的流只要垃圾回收器清理对象时就能够释放资源,这一点不同于对外部资源(如文件流)的释放。 * * @param obj The object. * @param <T> The type. * @return The cloned object. * @throws Exception The exception. */ public static <T> T clone(T obj) throws Exception { ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream(); ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream); objectOutputStream.writeObject(obj); ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(byteArrayOutputStream.toByteArray()); ObjectInputStream objectInputStream = new ObjectInputStream(byteArrayInputStream); return (T) objectInputStream.readObject(); } } package chimomo.learning.java.code.clone; /** * @author Created by Chimomo */ public class CloneTest { public static void main(String[] args) { try { Person p1 = new Person("Chimomo", 18, new Car("Benz", 300)); // 深度克隆。 Person p2 = CloneUtil.clone(p1); // 修改克隆的Person对象p2关联的汽车对象的品牌属性, // 原来的Person对象p1关联的汽车不会受到任何影响, // 因为在克隆Person对象时其关联的汽车对象也被克隆了。 p2.getCar().setBrand("Lamborghini"); System.out.println(p1); } catch (Exception e) { e.printStackTrace(); } } } // Output: /* Person [name=Chimomo, age=18, car=Car[brand=Benz, maxSpeed=300]] */ 基于序列化和反序列化实现的克隆不仅仅是深度克隆,更重要的是通过泛型限定,可以检查出要克隆的对象是否支持序列化,这项检查是编译器完成的,不是在运行时抛出异常,这种是方案明显优于使用Object类的clone方法克隆对象。让问题在编译的时候暴露出来总是优于把问题留到运行时。
JAVA开发设计七大原则
七大原则 1、单一职责原则 基本介绍 对类来说的,即一个类应该只负责一项职责。如类A负责两个不同职责:职责1,职责2。 当职责1需求变更而改变A时,可能造成职责2执行错误,所以需要将类A的粒度分解为Al, A2 代码示例 示例1 1、在Vehicle类的run方法中,违反了单一职责原则,没有解决不同交通工具运行的方式不一样的问题,都实现为了“在公路上运行…” 2、此解决的方案非常的简单,根据交通工具运行方法不同,分解成不同类即可 package principle.SingleResponsibility; public class SingleResponsibility1 { public static void main(String[] args) { Vehicle vehicle = new Vehicle(); vehicle.run("摩托车"); vehicle.run("汽车"); vehicle.run("飞机"); } } /** * 交通工具类 */ class Vehicle { public void run(String vehicle) { System.out.println(vehicle + " 在公路上运行...."); } } 示例2 1、遵守单一职责原则 2、但是这样做的改动很大,即根据不同情况,将类vehicle分解,创建出了各种vehicle,同时修改了客户端(main) 3、 改进:直接修改Vehicle类,改动的代码会比较少===>示例3 public class SingleResponsibility2 { public static void main(String[] args) { RoadVehicle roadVehicle = new RoadVehicle(); roadVehicle.run("摩托车"); roadVehicle.run("汽车"); AirVehicle airVehicle = new AirVehicle(); airVehicle.run("飞机"); } } class RoadVehicle { public void run(String vehicle) { System.out.println(vehicle + "公路运行"); } } class AirVehicle { public void run(String vehicle) { System.out.println(vehicle + "天空运行"); } } class WaterVehicle { public void run(String vehicle) { System.out.println(vehicle + "水中运行"); } } 示例3 1、这种修改方法没有对原来的类做大的修改,只是增加方法 2、 这里虽然没有在类这个级别上遵守单一职责原则,但是在方法级别上,仍然是遵守单一职责,即在交通工具类vehicle规范上,根据各种交通工具的运行方式不同,增加不同的方法 public class SingleResponsibility3 { public static void main(String[] args) { Vehicle2 vehicle2 = new Vehicle2(); vehicle2.run("汽车"); vehicle2.runWater("轮船"); vehicle2.runAir("飞机"); } } class Vehicle2 { public void run(String vehicle) { //各种处理 System.out.println(vehicle + " 在公路上运行...."); //各种处理 } public void runAir(String vehicle) { //各种处理 System.out.println(vehicle + " 在天空上运行...."); //各种处理 } public void runWater(String vehicle) { //各种处理 System.out.println(vehicle + " 在水中行...."); //各种处理 } } 总结和注意事项 1、降低类的复杂度,一个类只负责一项职责。 2、提高类的可读性, 可维护性 3、降低变更引起的风险 4、通常情况下,我们应当遵守单一职责原则,只有逻辑足够简单,才可以在代码级违反单一职责原则,只有类中方法数量足够少,可以在方法级别保持单一职责原则 2、接口隔离原则 基本介绍 1、客户端不应该依赖它不需要的接口,即一个类对另一个类的依赖应该建立在最小的接口上 2、图示 3、 类 A 通过接口 Interface1 依赖类 B,类 C 通过接口 Interface1 依赖类 D,如果接口 Interface1 对于类 A 和类 C来说不是最小接口,那么类 B 和类 D 必须去实现他们不需要的方法。 4、按隔离原则应当这样处理: 将接口 Interface1拆分为独立的几个接口 (这里我们拆分成 3 个接口),类 A 和类 C 分别与他们需要的接口建立依赖关系。也就是采用接口隔离原则 代码示例 示例1 1、类 A 通过接口 Interface1 依赖类 B,类 C 通过接口 Interface1 依赖类 D 2、下列代码没有使用接口隔离原则 public class Segregation1 { public static void main(String[] args) { } } /** * 接口 */ interface Interface1 { void operation1(); void operation2(); void operation3(); void operation4(); void operation5(); } /** * 下列各实现类 */ class B implements Interface1 { @Override public void operation1() { System.out.println("B 实现了 operation1"); } @Override public void operation2() { System.out.println("B 实现了 operation2"); } @Override public void operation3() { System.out.println("B 实现了 operation3"); } @Override public void operation4() { System.out.println("B 实现了 operation4"); } @Override public void operation5() { System.out.println("B 实现了 operation5"); } } class D implements Interface1 { @Override public void operation1() { System.out.println("D 实现了 operation1"); } @Override public void operation2() { System.out.println("D 实现了 operation2"); } @Override public void operation3() { System.out.println("D 实现了 operation3"); } @Override public void operation4() { System.out.println("D 实现了 operation4"); } @Override public void operation5() { System.out.println("D 实现了 operation5"); } } /** * A 类通过接口Interface1 依赖(使用) B类,但是只会用到1,2,3方法 */ class A { public void depend1(Interface1 i) { i.operation1(); } public void depend2(Interface1 i) { i.operation2(); } public void depend3(Interface1 i) { i.operation3(); } } /** * C 类通过接口Interface1 依赖(使用) D类,但是只会用到1,4,5方法 */ class C { public void depend1(Interface1 i) { i.operation1(); } public void depend4(Interface1 i) { i.operation4(); } public void depend5(Interface1 i) { i.operation5(); } } 示例2 改进示例1后 1、 类 A 通过接口 Interface1 依赖类 B,类 C 通过接口 Interface1 依赖类 D,如果接口 Interface1 对于类 A 和类 C来说不是最小接口,那么类 B 和类 D 必须去实现他们不需要的方法 2、将接口 Interface1 拆分为独立的几个接口,类 A 和类 C 分别与他们需要的接口建立依赖关系。也就是采用接口隔离原则 3、 接口 Interface1 中出现的方法,根据实际情况拆分为三个接口 4、图示: A要通过B用到Interface1接口中的1()、2()、3()方法 C要通过D用到Interface1接口中的1()、4()、5()方法 public class Segregation2 { public static void main(String[] args) { A a = new A(); a.depend1(new B()); // A类通过接口去依赖B类 a.depend2(new B()); a.depend3(new B()); C c = new C(); c.depend1(new D()); // C类通过接口去依赖(使用)D类 c.depend4(new D()); c.depend5(new D()); } } // 接口1 interface Interface1 { void operation1(); } // 接口2 interface Interface2 { void operation2(); void operation3(); } // 接口3 interface Interface3 { void operation4(); void operation5(); } class B implements Interface1, Interface2 { @Override public void operation1() { System.out.println("B 实现了 operation1"); } @Override public void operation2() { System.out.println("B 实现了 operation2"); } @Override public void operation3() { System.out.println("B 实现了 operation3"); } } class D implements Interface1, Interface3 { @Override public void operation1() { System.out.println("D 实现了 operation1"); } @Override public void operation4() { System.out.println("D 实现了 operation4"); } @Override public void operation5() { System.out.println("D 实现了 operation5"); } } /** * A 类通过接口Interface1,Interface2 依赖(使用) B类,但是只会用到1,2,3方法 */ class A { public void depend1(Interface1 i) { i.operation1(); } public void depend2(Interface2 i) { i.operation2(); } public void depend3(Interface2 i) { i.operation3(); } } /** * C 类通过接口Interface1,Interface3 依赖(使用) D类,但是只会用到1,4,5方法 */ class C { public void depend1(Interface1 i) { i.operation1(); } public void depend4(Interface3 i) { i.operation4(); } public void depend5(Interface3 i) { i.operation5(); } } 3、依赖倒转原则 基本介绍 1、高层模块不应该依赖低层模块,二者都应该依赖其抽象 2、抽象不应该依赖细节,细节应该依赖抽象 3、依赖倒转(倒置)的中心思想是面向接口编程 4、依赖倒转原则是基于这样的设计理念:相对于细节的多变性,抽象的东西要稳定的多。以抽象为基础搭建的架构比以细节为基础的架构要稳定的多。 在 java 中,抽象指的是接口或抽象类,细节就是具体的实现类 5、使用接口或抽象类的目的是制定好规范,而不涉及任何具体的操作,把展现细节的任务交给他们的实现类去完成 代码示例 示例1 Person接收消息的功能 1、简单,比较容易想到 2、如果我们获取的对象是 微信,短信等等,则新增类,同时Perons也要增加相应的接收方法 3、解决思路:引入一个抽象的接口IReceiver, 表示接收者, 这样Person类与接口IReceiver发生依赖 4、因为Email, WeiXin 等等属于接收的范围,他们各自实现IReceiver 接口就ok, 这样我们就符合依赖倒转原则 public class DependecyInversion { public static void main(String[] args) { Person person = new Person(); person.receive(new Email()); } } class Email { public String getInfo() { return "电子邮件信息: hello,world"; } } /** * 完成Person接收消息的功能 */ class Person { public void receive(Email email ) { System.out.println(email.getInfo()); } } 示例2 改进示例1 1、用到了依赖倒转原则 2、让Email和Weixin继承接口IReceiver,并实现其中的方法规范,这样客户端Person可以接受来自不同类型的消息,Person并不会增加相应的方法(如示例1) 3、Email, WeiXin 等等属于接收的消息范围,他们各自实现IReceiver 接口就ok, 这样我们就符合依赖倒转原则 public class DependecyInversion { public static void main(String[] args) { //客户端无需改变 Person person = new Person(); person.receive(new Email()); person.receive(new WeiXin()); } } /** * 定义接口 */ interface IReceiver { public String getInfo(); } /** * 实现类 */ class Email implements IReceiver { @Override public String getInfo() { return "电子邮件信息: hello,world"; } } //增加微信 class WeiXin implements IReceiver { @Override public String getInfo() { return "微信信息: hello,ok"; } } /** * 客户端 */ class Person { /** * 这里我们是对接口的依赖 * @param receiver */ public void receive(IReceiver receiver ) { System.out.println(receiver.getInfo()); } } 依赖关系传递的三种方式 1、接口传递 2、构造方法传递 3、setter 方式传递 接口传递代码 /** * 电视接口 */ interface ITV { //ITV接口 public void play(); } /** * 开关的接口 */ interface IOpenAndClose { public void open(ITV tv); //抽象方法,接收接口 } /** * 电视接口 */ class ChangHong implements ITV { @Override public void play() { System.out.println("长虹电视机,打开"); } } /** *开关实现接口 */ class OpenAndClose implements IOpenAndClose{ @Override public void open(ITV tv){ tv.play(); } } public class DependencyPass { public static void main(String[] args) { //通过接口传递 ChangHong changHong = new ChangHong(); OpenAndClose openAndClose = new OpenAndClose(); openAndClose.open(changHong); } } 构造方法传递代码 /** * 开关接口 */ interface IOpenAndClose { public void open(); } /** * 电视接口 */ interface ITV { public void play(); } /** * 电视接口 */ class ChangHong implements ITV { @Override public void play() { System.out.println("长虹电视机,打开"); } } class OpenAndClose implements IOpenAndClose{ public ITV tv; //成员 //将电视传入构造器 public OpenAndClose(ITV tv){ this.tv = tv; } @Override public void open(){ //将电视打开 this.tv.play(); } } public class DependencyPass { public static void main(String[] args) { //通过构造器进行依赖传递 ChangHong changHong = new ChangHong(); OpenAndClose openAndClose = new OpenAndClose(changHong); openAndClose.open(); } } setter 方式传递代码 interface IOpenAndClose { public void open(); // 抽象方法 public void setTv(ITV tv); } /** * ITV接口 */ interface ITV { public void play(); } /** * 实现电视接口 */ class ChangHong implements ITV { @Override public void play() { System.out.println("长虹电视机,打开"); } } /** * 开关实现接口 */ class OpenAndClose implements IOpenAndClose { private ITV tv; /** * setter方式将电视注入到开关中,并赋予成员变量tv * @param tv */ @Override public void setTv(ITV tv) { this.tv = tv; } /** * 打开tv(setter方式注入进来的) */ @Override public void open() { this.tv.play(); } } public class DependencyPass { public static void main(String[] args) { //通过setter方法进行依赖传递 ChangHong changHong = new ChangHong(); OpenAndClose openAndClose = new OpenAndClose(); openAndClose.setTv(changHong); openAndClose.open(); } } 总结和注意事项 1、低层模块尽量都要有抽象类或接口,或者两者都有,程序稳定性更好. 2、变量的声明类型尽量是抽象类或接口, 这样我们的变量引用和实际对象间,就存在一个缓冲层,利于程序扩展和优化 3、继承时遵循里氏替换原则 4、里氏替换原则 OOP 中的继承性的思考和说明 1、继承包含这样一层含义:父类中凡是已经实现好的方法,实际上是在设定规范和契约,虽然它不强制要求所有的子类必须遵循这些契约,但是如果子类对这些已经实现的方法任意修改,就会对整个继承体系造成破坏。 2、继承在给程序设计带来便利的同时,也带来了弊端。比如使用继承会给程序带来侵入性,程序的可移植性降低, 增加对象间的耦合性,如果一个类被其他的类所继承,则当这个类需要修改时,必须考虑到所有的子类,并且父类修改后,所有涉及到子类的功能都有可能产生故障 3、问题提出:在编程中,如何正确的使用继承? => 里氏替换原则 基本介绍 1、里氏替换原则(Liskov Substitution Principle)在 1988 年,由麻省理工学院的以为姓里的女士提出的。 2、如果对每个类型为 T1 的对象 o1,都有类型为 T2 的对象 o2,使得以 T1 定义的所有程序 P 在所有的对象 o1 都代换成 o2 时,程序 P 的行为没有发生变化,那么类型 T2 是类型 T1 的子类型。换句话说,所有引用基类的地方必须能透明地使用其子类的对象。 3、在使用继承时,遵循里氏替换原则,在子类中尽量不要重写父类的方法 4、里氏替换原则告诉我们,继承实际上让两个类耦合性增强了,在适当的情况下,可以通过聚合,组合,依赖 来解决问题。 代码示例 示例1 A类中的func1()方法是求两数之差,B类继承了A类之后,不小心重写了A类中的func1(),使其改为了求两数之和,所以在main()方法测试时,得到的结果,在预料之外,如下: /** * A类 */ class A { /** * 返回两个数的差 */ public int func1(int num1, int num2) { return num1 - num2; } } /** * B类继承了A * 增加了一个新功能:完成两个数相加,然后和9求和 */ class B extends A { /** * 这里,重写了A类的方法, 可能是无意识 */ @Override public int func1(int a, int b) { return a + b; } public int func2(int a, int b) { return func1(a, b) + 9; } } //测试 public class Liskov { public static void main(String[] args) { A a = new A(); System.out.println("11-3=" + a.func1(11, 3)); System.out.println("1-8=" + a.func1(1, 8)); System.out.println("-----------------------"); B b = new B(); //这里本意是求出11-3,但求的是11+3,因为B类重写了父类A中的func1() System.out.println("11-3=" + b.func1(11, 3)); //本意是1-8 但求的是1+8,因为B类重写了父类A中的func1() System.out.println("1-8=" + b.func1(1, 8)); //求的是(11+3)+9 System.out.println("11+3+9=" + b.func2(11, 3)); } } 示例2 1、示例1我们发现,我们发现原来运行正常的相减功能发生了错误。原因就是类 B 无意中重写了父类的方法,造成原有功能出现错误。在实际编程中,我们常常会通过重写父类的方法完成新的功能,这样写起来虽然简单,但整个继承体系的复用性会比较差。特别是运行多态比较频繁的时候 2、通用的做法是:原来的父类和子类都继承一个更通俗的基类,原有的继承关系去掉,采用依赖,聚合,组合等关系代替. 此处基类就是Base类 3、改进方案 /** * 创建一个更加基础的基类 */ class Base { //把更加基础的方法和成员写到Base类 } /** * A类 */ class A extends Base { // 返回两个数的差 public int func1(int num1, int num2) { return num1 - num2; } } /** * B类继承了基类Base */ class B extends Base { //如果B需要使用A类的方法,使用组合关系 private A a = new A(); // 返回两个数的和 public int func1(int a, int b) { return a + b; } //其它运算 public int func2(int a, int b) { return func1(a, b) + 9; } //我们仍然想使用A(this.a)的方法 public int func3(int a, int b) { return this.a.func1(a, b); } } public class Liskov { public static void main(String[] args) { A a = new A(); System.out.println("11-3=" + a.func1(11, 3)); System.out.println("1-8=" + a.func1(1, 8)); System.out.println("-----------------------"); B b = new B(); //因为B类不再继承A类,因此调用者,不会再func1是求减法 //调用完成的功能就会很明确 System.out.println("11+3=" + b.func1(11, 3));//这里本意是求出11+3 System.out.println("1+8=" + b.func1(1, 8));// 1+8 System.out.println("11+3+9=" + b.func2(11, 3)); //使用组合仍然可以使用到A类相关方法 System.out.println("11-3=" + b.func3(11, 3));// 这里本意是求出11-3 } } 5、开闭原则 基本介绍 1、开闭原则(Open Closed Principle)是编程中最基础、最重要的设计原则 2、一个软件实体如类,模块和函数应该对扩展开放(对提供方),对修改关闭(对使用方)。用抽象构建框架,用实现扩展细节。 3、当软件需要变化时,尽量通过扩展软件实体的行为来实现变化,而不是通过修改已有的代码来实现变化。 4、编程中遵循其它原则,以及使用设计模式的目的就是遵循开闭原则。 代码示例 示例1 1、类图设计 2、在GraphicEditor类中,drawShape方法绘制图形时,会根据传来的图形中的m_type进行判断为何图形,才进行调用指定的drawXXX()方法进行绘制 /** * 这是一个用于绘图的类 [使用方] */ class GraphicEditor { /** * 接收Shape对象,然后根据type,来绘制不同的图形 */ public void drawShape(Shape s) { if (s.m_type == 1){ drawRectangle(s); }else if (s.m_type == 2){ drawCircle(s); } } //绘制矩形 public void drawRectangle(Shape r) { System.out.println(" 绘制矩形 "); } //绘制圆形 public void drawCircle(Shape r) { System.out.println(" 绘制圆形 "); } } /** * Shape类,基类 */ class Shape { int m_type; } /** * 具体的图形类 */ class Rectangle extends Shape { Rectangle() { super.m_type = 1; } } class Circle extends Shape { Circle() { super.m_type = 2; } } /** *测试 */ public class Ocp { public static void main(String[] args) { //使用看看存在的问题 GraphicEditor graphicEditor = new GraphicEditor(); graphicEditor.drawShape(new Rectangle()); graphicEditor.drawShape(new Circle()); } } 但若我们添加新的类Triangle“三角形” /** * 新增画三角形 */ class Triangle extends Shape { Triangle() { super.m_type = 3; } } 则要绘制时,必须在GraphicEditor类中的drawShape中加上一条判断语句,并且还要新添具体drawTriangle()方法才能绘制三角形,如下 public void drawShape(Shape s) { if (s.m_type == 1){ drawRectangle(s); }else if (s.m_type == 2){ drawCircle(s); } else if (s.m_type == 3){ //此处根据新添的图形,所新添的判断语句 drawTriangle(s); } } //新添,绘制三角形 public void drawTriangle(Shape r) { System.out.println(" 绘制三角形 "); } 由上可以看出要修改的地方很多,不仅仅要在调用者处添加判断else if (s.m_type == 3),还要新添具体的绘制方法drawTriangle() 示例1优缺点 1、优点是比较好理解,简单易操作。 2、 缺点是违反了设计模式的 ocp 原则,即对扩展开放(提供方),对修改关闭(使用方)。即当我们给类GraphicEditor增加新功能的时候,尽量不修改代码,或者尽可能少修改代码。 3、 比如我们这时要新增加一个图形种类三角形,我们需要做如下修改(示例2),修改的地方较多。 示例2 1、根据示例1,我们进行下列改进,并且利用开闭原则。 2、把创建 Shape 类做成抽象类,并提供一个抽象的 draw 方法,让子类去实现即可,这样我们有新的图形种类时,只需要让新的图形类继承 Shape,并实现 draw 方法即可,使用方的代码就不需要修 一>满足了开闭原则。 3、在GraphicEditor类中进行drawShape绘制时,也不用 if else语句进行判断(如示例1),直接调用图形的draw()方法即可。具体实现看下面代码。 /** * 这是一个用于绘图的类 [使用方] */ class GraphicEditor { //接收Shape对象,调用draw方法 public void drawShape(Shape s) { s.draw(); } } /** * Shape类,基类 */ abstract class Shape { int m_type; public abstract void draw();//抽象方法 } class Rectangle extends Shape { Rectangle() { super.m_type = 1; } @Override public void draw() { System.out.println(" 绘制矩形 "); } } class Circle extends Shape { Circle() { super.m_type = 2; } @Override public void draw() { System.out.println(" 绘制圆形 "); } } /** * 新增画三角形 */ class Triangle extends Shape { Triangle() { super.m_type = 3; } @Override public void draw() { System.out.println(" 绘制三角形 "); } } /** * 新增一个图形 */ class OtherGraphic extends Shape { OtherGraphic() { super.m_type = 4; } @Override public void draw() { System.out.println(" 绘制其它图形 "); } } public class Ocp { public static void main(String[] args) { //使用看看存在的问题 GraphicEditor graphicEditor = new GraphicEditor(); graphicEditor.drawShape(new Rectangle()); graphicEditor.drawShape(new Circle()); graphicEditor.drawShape(new Triangle()); graphicEditor.drawShape(new OtherGraphic()); } } 6、迪米特法则 基本介绍 1、一个对象应该对其他对象保持最少的了解。 2、类与类关系越密切,耦合度越大。 3、迪米特法则(Demeter Principle)又叫最少知道原则,即一个类对自己依赖的类知道的越少越好 。也就是说,对于被依赖的类不管多么复杂,都 尽量将逻辑封装在类的内部。对外除了提供的 public 方法,不对外泄露任何信息。 4、迪米特法则还有个更简单的定义:只与直接的朋友通信。 5、直接的朋友:每个对象都会与其他对象有耦合关系,只要两个对象之间有耦合关系,我们就说这两个对象之间是朋友关系。耦合的方式很多,依赖,关联,组合,聚合等。其中,我们称出现成员变量,方法参数,方法返回值中的类为直接的朋友,而出现在局部变量中的类不是直接的朋友。也就是说,陌生的类最好不要以局部变量的形式出现在类的内部。 代码示例 示例1 1、有一个学校,下属有各个学院CollegeManager和总部SchoolManager,现要求打印出学校总部员工 Employee的ID 和学院员工CollegeEmployee的 id,打印在SchoolManager中打印。 2、编程实现上面的功能, 看如下代码演示 /** * 学校总部员工类 */ class Employee { private String id; public void setId(String id) { this.id = id; } public String getId() { return id; } } /** * 学院的员工类 */ class CollegeEmployee { private String id; public void setId(String id) { this.id = id; } public String getId() { return id; } } /** * 管理学院员工的管理类 */ class CollegeManager { //返回学院的所有员工 public List<CollegeEmployee> getAllEmployee() { List<CollegeEmployee> list = new ArrayList<CollegeEmployee>(); for (int i = 0; i < 10; i++) { //这里我们增加了10个员工到 list CollegeEmployee emp = new CollegeEmployee(); emp.setId("学院员工id= " + i); list.add(emp); } return list; } } /** * 学校管理类 * 分析 SchoolManager 类的直接朋友类有Employee(方法返回值)、CollegeManager(方法参数) * CollegeEmployee(局部变量) 不是直接朋友 而是一个陌生类,这样违背了迪米特法则 */ class SchoolManager { //返回学校总部的员工 public List<Employee> getAllEmployee() { List<Employee> list = new ArrayList<Employee>(); for (int i = 0; i < 5; i++) { //这里我们增加了5个员工到 list Employee emp = new Employee(); emp.setId("学校总部员工id= " + i); list.add(emp); } return list; } /** * 该方法完成输出学校总部和学院员工信息(id) */ void printAllEmployee(CollegeManager sub) { /** * 分析问题 * 1. 这里的 CollegeEmployee(局部变量) 不是 SchoolManager的直接朋友 * 2. CollegeEmployee 是以局部变量方式出现在 SchoolManager * 3. 违反了迪米特法则 */ //获取到学院员工 List<CollegeEmployee> list1 = sub.getAllEmployee(); System.out.println("------------学院员工------------"); for (CollegeEmployee e : list1) { System.out.println(e.getId()); } //获取到学校总部员工 List<Employee> list2 = this.getAllEmployee(); System.out.println("------------学校总部员工------------"); for (Employee e : list2) { System.out.println(e.getId()); } } } /** * 客户端 */ public class Demeter1 { public static void main(String[] args) { //创建了一个 SchoolManager 对象 SchoolManager schoolManager = new SchoolManager(); //输出学院的员工id 和 学校总部的员工信息 schoolManager.printAllEmployee(new CollegeManager()); } } 在SchoolManager的打印方法printAllEmployee()中,CollegeEmployee以局部变量(不是直接朋友)的形式出现在了SchoolManager类的内部,违反了迪米特法则 示例2 1、前面设计的问题在于 SchoolManager 中,CollegeEmployee 类并不是 SchoolManager 类的直接朋友 (以局部变量形式出现的) 2、按照迪米特法则,应该避免类中出现这样非直接朋友关系的耦合 3、对代码按照迪米特法则进行改进 4、如下代码演示 /** * 学校总部员工类 */ class Employee { private String id; public void setId(String id) { this.id = id; } public String getId() { return id; } } /** * 学院的员工类 */ class CollegeEmployee { private String id; public void setId(String id) { this.id = id; } public String getId() { return id; } } /** * 管理学院员工的管理类 */ class CollegeManager { //返回学院的所有员工 public List<CollegeEmployee> getAllEmployee() { List<CollegeEmployee> list = new ArrayList<CollegeEmployee>(); for (int i = 0; i < 10; i++) { //这里我们增加了10个员工到 list CollegeEmployee emp = new CollegeEmployee(); emp.setId("学院员工id= " + i); list.add(emp); } return list; } //输出学院员工的信息 public void printEmployee() { //获取到学院员工 List<CollegeEmployee> list1 = getAllEmployee(); System.out.println("------------学院员工------------"); for (CollegeEmployee e : list1) { System.out.println(e.getId()); } } } /** * 学校管理类 */ class SchoolManager { /** * 返回学校总部的员工 */ public List<Employee> getAllEmployee() { List<Employee> list = new ArrayList<Employee>(); for (int i = 0; i < 5; i++) { //这里我们增加了5个员工到 list Employee emp = new Employee(); emp.setId("学校总部员工id= " + i); list.add(emp); } return list; } /** * 该方法完成输出学校总部和学院员工信息(id) */ void printAllEmployee(CollegeManager sub) { /** * 分析问题 * 1. 将输出学院的员工方法,封装到CollegeManager */ sub.printEmployee(); /** * 获取到学校总部员工 */ List<Employee> list2 = this.getAllEmployee(); System.out.println("------------学校总部员工------------"); for (Employee e : list2) { System.out.println(e.getId()); } } } /** * 客户端 */ public class Demeter1 { public static void main(String[] args) { System.out.println("~~~使用迪米特法则的改进~~~"); //创建了一个 SchoolManager 对象 SchoolManager schoolManager = new SchoolManager(); //输出学院的员工id 和 学校总部的员工信息 schoolManager.printAllEmployee(new CollegeManager()); } } 将输出学院的员工方法,封装到了CollegeManager,即CollegeEmployee 没有以局部变量的形式出现在了SchoolManager中,这时符合迪米特法则 小结和注意事项 1、迪米特法则的核心是降低类之间的耦合 2、但是注意:由于每个类都减少了不必要的依赖,因此迪米特法则只是要求降低类间(对象间)耦合关系, 并不是要求完全没有依赖关系 7、合成复用原则 基本介绍 1、在一个新的对象里面使用一些已有的对象,使之成为新对象的一部分;新的对象通过向这些对象的委派达到复用已有功能的目的。 2、原则是尽量使用合成/聚合的方式,而不是使用继承 8、设计原则核心思想 1、找出应用中可能需要变化之处,把它们独立出来,不要和那些不需要变化的代码混在一起。 2、针对接口编程,而不是针对实现编程。 3、为了交互对象之间的松耦合设计而努力
Java中类之间六大关系
一、继承关系
继承指的是一个类(称为子类、子接口)继承另外的一个类(称为父类、父接口)的功能,并可以增加它自己的新功能的能力。 在Java中继承关系通过关键字extends明确标识,在设计时一般没有争议性。在UML类图设计中,继承用一条带空心三角箭头的实线表示,从子类指向父类,或者子接口指向父接口。
二、实现关系
实现指的是一个class类实现interface接口(可以是多个)的功能,实现是类与接口之间最常见的关系。 在Java中此类关系通过关键字implements明确标识,在设计时一般没有争议性。在UML类图设计中,实现用一条带空心三角箭头的虚线表示,从类指向实现的接口。
三、依赖关系
简单的理解,依赖就是一个类A使用到了另一个类B,而这种使用关系是具有偶然性的、临时性的、非常弱的,但是类B的变化会影响到类A。 比如某人要过河,需要借用一条船,此时人与船之间的关系就是依赖。表现在代码层面,为类B作为参数被类A在某个method方法中使用。在UML类图设计中,依赖关系用由类A指向类B的带箭头虚线表示。
四、关联关系
关联体现的是两个类之间语义级别的一种强依赖关系,比如我和我的朋友,这种关系比依赖更强、不存在依赖关系的偶然性、关系也不是临时性的,一般是长期性的,而且双方的关系一般是平等的。关联可以是单向、双向的。表现在代码层面,为被关联类B以类的属性形式出现在关联类A中,也可能是关联类A引用了一个类型为被关联类B的全局变量。 在UML类图设计中,关联关系用由关联类A指向被关联类B的带箭头实线表示,在关联的两端可以标注关联双方的角色和多重性标记。
五、聚合关系
聚合是关联关系的一种特例,它体现的是整体与部分的关系,即has-a的关系。此时整体与部分之间是可分离的,它们可以具有各自的生命周期,部分可以属于多个整体对象,也可以为多个整体对象共享。 比如计算机与CPU、公司与员工的关系等,比如一个航母编队包括海空母舰、驱护舰艇、舰载飞机及核动力攻击潜艇等。表现在代码层面,和关联关系是一致的,只能从语义级别来区分。在UML类图设计中,聚合关系以空心菱形加实线箭头表示。
六、组合关系
组合也是关联关系的一种特例,它体现的是一种contains-a的关系,这种关系比聚合更强,也称为强聚合。它同样体现整体与部分间的关系,但此时整体与部分是不可分的,整体的生命周期结束也就意味着部分的生命周期结束, 比如人和人的大脑。表现在代码层面,和关联关系是一致的,只能从语义级别来区分。在UML类图设计中,组合关系以实心菱形加实线箭头表示。






Java集合/泛型面试题
集合框架
Collection接口包含List接口和Set子接口
List接口特点:有序,数据可重复
Set接口特点:无序,数据不可重复
List接口实现类:ArrayList、LinkedList、Vector
ArrayList底层是数组,使用无参构造创建一个ArrayList时,初始化长度为0的空数组。当第一次向集合中添加元素时,扩容长度为10
的数组。当容量不足时,扩容为原来长度的1.5倍扩容+1。扩容本质是容量不足时,新建一个新的更大长度的空数组,然后将
旧数组的元素复制过来。查询效率高,增删效率低
LinkedList底层采用双向链表存储,优点是插入、删除元素效率比较高,缺点是遍历和随机访问元素效率低下。提供了List 接口中没
有定义的方法,专门用于操作表头和表尾元素,可以当作堆栈、队列和双向队列使用。无初始化容量,无扩容,一直添加即可
Vector 与 ArrayList 一样,也是通过数组实现的,不同的是它支持线程的同步,即某一时刻只有一个线程能够写 Vector,避免多线
程同时写而引起的不一致性,但实现同步需要很高的花费,因此,访问它比访问 ArrayList 慢 。创建集合时默认初始化容量为10,2
倍扩容
Set接口实现类:HashSet、TreeSet、LinkedHashSet
HashSet底层采用Hashtable哈希表存储结构,实际是一个HashMap实例,元素都存放在HashMap的key上,而Value都是一个固定
对象。添加元素时,会先调用此对象所在类的hashCode()方法,计算此对象的哈希值,然后判断存储位置上是否已存在元素,没有
就直接存储,有就先通过equals()比较两个元素是否相同,相同则不能被添加。添加速度快,查询速度快,删除速度快,无序
TreeSet底层采用二叉树(红黑树)的存储结构,优点是有序,查询速度比List快(按照内容查询),缺点是查询速度没有HashSet快
LinkedHashSet底层采用哈希表存储结构,同时使用链表维护次序,有序(添加顺序)
Map接口与Collection接口同一级别(集合类顶级接口)
Map接口特点:存储的键值对映射关系,根据key(唯一)可以找到value。第一次添加元素时初始化集合长度默认为16,2倍扩容。
a、以键值对存储数据
b、元素存储顺序是无序的
c、不允许出现重复键
实现类为HashMap、TreeMap、LinkedHashMap
HashMap底层采用Hashtable哈希表存储结构,优点是添加速度快 查询速度快 删除速度快,缺点是key无序
TreeMap底层采用二叉树(红黑树)的存储结构,优点是key有序 查询速度比List快(按照内容查询),缺点是查询速度没有
HashMap快
LinkedHashMap底层采用哈希表存储结构,同时使用链表维护次序,key有序(添加顺序)
HashMap1.7——1.8的区别:
1.7–>数组+链表(拉链)。桶量默认是16,阈值0.75。在put时采用头插法,并且在达到扩容时先resize再put
1.8 -->数组+链表+红黑树。当链表数量超过8时链表转换成红黑树,低于6时又转换为链表。在put时采用尾插法,在达到扩容时,是
先put成功后再resize。put()是尾插法,没有改变原来数据所在链表的一个顺序,所以不会出现链表闭环,但是尾插法,有可
能造成数据的覆盖,导致数据丢失
头插法死锁的产生:
在线程一达到了resize条件,在记住了原hash表的数据和put的数据后准备rehash时,此时线程二强行进来操作,并进行了rehash的
操作,然后线程一继续rehash操作,因为是头插法的缘故,此时的hash表存在的数据和记忆的数据位置刚好相反,再放入就会形成
一个闭环链
HashMap桶量或者每次扩容都是2的幂次:为的是均匀散列
在jdk1.7 里面索引的计算公式为 index =(capacity - 1) & hash(key)
假设 capacity 为 2 二进制表示为 10 capacity-1 为1 二进制表示为 1
假设 capacity 为 4 二进制表示为 100 capacity-1 为3 二进制表示为 11
假设 capacity 为 8 二进制表示为 1000 capacity-1 为7 二进制表示为 111
2^n - 1得出的结果转换为二进制必然是 1111…111这样的,和hashcode做按位与操作的时候,都是由hahscode来决定散列,不会
形成缺口。如果 capacity为9,数据会极端分布,只会是0或者8.数据只会放在这两个桶里面。其他桶不会有数据
HashMap底层原理:
HashMap底层数据结构是数组(位桶)+链表(1.8以前)+红黑树(1.8开始)
put方法添加元素,通过判断hashCode定位数组(位桶)下标,如果该位置没有其他元素的话,那么就将这个元素直接存储。如果有其
他元素的话,会通过equals进行对比key是否相同,相同就覆盖,没有相同的就放到链表尾部。HashMap 最多只允许一条记录的键
为 null,允许多条记录的值为 null
get方法获取元素,先计算哈希值,调用indexFor()方法得到对应位置的链表,然后对链表进行遍历,通过equals找到对应的value返
回。初始数组容量是16,数组元素达到0.75*数组.length,就会扩容为原来的两倍。扩容很耗时,本质是定义新的更大的数组,并将
旧数组内容拷贝到新数组中。
链表长度大于8的时候,链表会转变成红黑树的结构
集合结构图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-E5jM61rb-1653308049329)(C:\Users\纵横\AppData\Roaming\Typora\typora-user-images\image-20210824093730972.png)]
![image-20210815120550148]()
![image-20210815120621207]()
HashMap和HashTable详解
一、HashMap
HashMap原理图:
HashMap中key-value的数据存放结构:
a、位桶数组
transient Node<k,v>[] table;//存储(位桶)的数组</k,v>b、数组元素Node
//Node是单向链表,它实现了Map.Entry接口 static class Node<k,v> implements Map.Entry<k,v> { final int hash; final K key; V value; Node<k,v> next; //构造函数Hash值 键 值 下一个节点 Node(int hash, K key, V value, Node<k,v> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } public final K getKey() { return key; } public final V getValue() { return value; } public final String toString() { return key + = + value; } public final int hashCode() { return Objects.hashCode(key) ^ Objects.hashCode(value); } public final V setValue(V newValue) { V oldValue = value; value = newValue; return oldValue; } //判断两个node是否相等,若key和value都相等,返回true。可以与自身比较为true public final boolean equals(Object o) { if (o == this) return true; if (o instanceof Map.Entry) { Map.Entry<!--?,?--> e = (Map.Entry<!--?,?-->)o; if (Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue())) return true; } return false; }c、红黑树
//红黑树 static final class TreeNode<k,v> extends LinkedHashMap.Entry<k,v> { TreeNode<k,v> parent; // 父节点 TreeNode<k,v> left; //左子树 TreeNode<k,v> right;//右子树 TreeNode<k,v> prev; // needed to unlink next upon deletion boolean red; //颜色属性 TreeNode(int hash, K key, V val, Node<k,v> next) { super(hash, key, val, next); } //返回当前节点的根节点 final TreeNode<k,v> root() { for (TreeNode<k,v> r = this, p;;) { if ((p = r.parent) == null) return r; r = p; } }底层执行原理:
A、添加元素put(K key, V value)
1、程序首先计算该key的hashCode()值
2、然后对该哈希码值进行再哈希
3、然后把哈希值和(数组长度-1)进行按位与操作,得到存储的数组下标
4、如果该位置处没有链表节点,那么就直接把包含<key,value>的节点放入该位置。如果该位置有结点,就对链表进行遍历,看是否
有hash值key值和要放入的节点相同的节点,如果有的话,就替换该节点的value值,如果没有相同的话,就创建节点放入值,并把
该节点插入到链表表尾(尾插法)。HashMap处理“碰撞”增加了红黑树这种数据结构,当碰撞结点较少时,采用链表存储,当较大时
(>8个),采用红黑树(特点是查询时间是O(logn))存储(有一个阀值控制,大于阀值(8个),将链表存储转换成红黑树存储)
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; //如果当前map中无数据,执行resize方法。并且返回n if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; //如果要插入的键值对要存放的这个位置刚好没有元素,那么把他封装成Node对象,放在这个位置上就完事了 if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); //否则的话,说明这上面有元素 else { Node<K,V> e; K k; //如果这个元素的key与要插入的一样,那么就替换一下,也完事。 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; //1.如果当前节点是TreeNode类型的数据,执行putTreeVal方法 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { //还是遍历这条链子上的数据,跟jdk7没什么区别 for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); //2.完成了操作后多做了一件事情,判断,并且可能执行treeifyBin方法,将链表转换为红黑树 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; //判断阈值,决定是否扩容 if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }//计算hash值 static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }二倍扩容:
final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; int oldCap = (oldTab == null) ? 0 : oldTab.length; int oldThr = threshold; int newCap, newThr = 0; if (oldCap > 0) { if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold } else if (oldThr > 0) // initial capacity was placed in threshold newCap = oldThr; else { // zero initial threshold signifies using default newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } if (newThr == 0) { float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACIT (int)ft : Integer.MAX_VALUE); } threshold = newThr; @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; if (oldTab != null) { for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; if (e.next == null) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { // preserve order Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } return newTab; }为何数组的长度是2的n次方:
a、它通过h & (table.length-1)来得到该对象的保存位,而HashMap底层数组的长度总是2的n次方,2^n -1得到的二进制数的每个位
上的值都为1,那么与全部为1的一一个数进行与操作,速度会大大提升
b、当length总是2的n次方时,h& (length-1)运算等价于对length取模,也就是h%length,但是&比%县有更高的效率
c、当数组长度为2的n次幂的时候,不同的key算得的index相同的几率较小,那么数据在数组上分布就比较均匀,也就是说碰擁的几
率小,相对的,查询的时候就不用遍历某个位置上的链表,这样查询效率也就较高了
B、获取元素get(object key)
1、首先通过key的两次hash后的值与数组的长度-1进行与操作,定位到数组的某个位置
2、然后对该列的链表进行遍历,查找节点中的key与获取的key值相同的value值。一般情况下,hashMap的这种查找速度是非常快
的,hash 值相同的元就会造成链表中数据很多,而链表中的数据查找是通过遍历所有链表中的元素进行的,这可能会影响到查找
速度,找到即返回。特别注意:当返回为null时,你不能判断是没有找到指定元素,还是在hashmap中存着一一个value为null的
元素,因为hashmap允许value为null
public V get(Object key) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? null : e.value; } /** * Implements Map.get and related methods * * @param hash hash for key * @param key the key * @return the node, or null if none */ final Node<K,V> getNode(int hash, Object key) { Node<K,V>[] tab;//Entry对象数组 Node<K,V> first,e; //在tab数组中经过散列的第一个位置 int n; K k; /*找到插入的第一个Node,方法是hash值和n-1相与,tab[(n - 1) & hash]*/ //也就是说在一条链上的hash值相同的 if ((tab = table) != null && (n = tab.length) > 0 &&(first = tab[(n - 1) & hash]) != null) { /*检查第一个Node是不是要找的Node*/ if (first.hash == hash && // always check first node ((k = first.key) == key || (key != null && key.equals(k))))//判断条件是hash值要相同,key值要相同 return first; /*检查first后面的node*/ if ((e = first.next) != null) { if (first instanceof TreeNode) return ((TreeNode<K,V>)first).getTreeNode(hash, key); /*遍历后面的链表,找到key值和hash值都相同的Node*/ do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null); } } return null; } HashMap的扩容机制: 当HashMap中的结点个数超过数组大小loadEactor*(加载因子)时,就会进行数组扩容,loadFactor的默认值为0.75.世就是说,默认情况下,数组大小为16,那么当HashMap电结点个数超过16x0.75=12的时候,就把数组的大小和展为2x16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,并放进去,而这是一个非常消耗性能的操作。 多线程下HashMap出现的问题: 1.多线程put操作后,get操作导致死循环导致cpu100%的现象。主要是多线程同时put时,如果同时触发了rehash操作,会导政扩客后的HashMap中的链表中出现循环节点进而使得后面get的时候,会死循环。 2.多线程put操作,导致元素丢失,也是发生在个线程对hashmap 扩容时。二、HashTable
HashMap和HashTable的区别:
a、Hashtable 是线程安全的,方法是Synchronized 的,适合在多线程环境中使用,效率稍低
HashMap不是线程安全的,方法不是Synchronized的,效率稍高,适合在单线程环境下使用,所以在多线程场合下使用的话,
需要手动同步HashMap,Collctions.synchronizedMap()
HashTable的效率比较低的原因:
在线程竞争激烈的情况下HashTable的效率非常低下。因为当一个线程访问HashTable的同步方法时,访问其他同步方法的线程就可
能会进入阻塞或者轮询状态。如线程1使用put进行添加元素,线程2不但不能使用put方法添加元素,并且也不能使用get方法来获取
元素,所以竞争越激烈改率越低
b、HashMap的key和value都可以为null值,HashTable 的key和value都不允许为Null值
c、HashMap中数组的默认大小是16,而且一定是2的倍数,扩容后的数組长度是之前数组长度的2倍
HashTable中数组默认大小是11,扩容后的数组长度是之前数组长度的2倍+1
d、哈希值的使用不同
HashTable直接使用对象的hashCode值int hash = key.hashCode(),而HashMap重新计算hash值,并且用&代替求模
int hash = hash(key.hashcode0); int i= indexFor(hash, table.length); static int hash(Objectx) { int h = x.hashCode(); h += ~(h<<9);h^= (h>>> 14); h+=(h<< 4); h ^= (h>>> 10); returm h; }static int indexFor(int h, int length) { return h & (length-1); //hashmap的表长永远是2^n。 }e、判断是否含有某个键
在HashMap中,null 可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为null,当get()方法返回null值时,既可以
表示HashMap中没有该键,也可以表示该键所对应的值为null。因此,在HashMap中不能用get()方法来判断HashMap中是否存
在某个键,而应该用containsKey()方法来判析。Hashtable的键值都不能为null,所以可以用get()方法来判断是否含有某个键
g、两者父类不同
HashMap是继承自AbstractMap类,而Hashtable是继承自Dictionary类。不过它们都实现了同时实现了map、Cloneable(可
复制)、Serializable(可序列化)这三个接口
h、对外提供的接口不同
Hashtable比HashMap多提供了elments() 和contains() 两个方法
elments() 方法继承自Hashtable的父类Dictionnary。elements() 方法用于返回此Hashtable中的value的枚举
contains()方法判断该Hashtable是否包含传入的value。它的作用与containsValue()一致。事实上,contansValue()就只是调用
了一下contains()方法


HashCode的作用
当我们在set中插入的时候怎么判断是否已经存在该元素呢,可以通过equals方法。但是如果元素太多,用这样的方法就会比较慢。
于是有人发明了哈希算法来提高集合中查找元素的效率。这种方式将集合分成若干个存储区域,每个对象可以计算出一个哈希码,可
以将哈希码分组,每组分别对应某个存储区域,根据一个对象的哈希码就可以确定该对象应该存储的那个区域。
hashCode方法可以这样理解:
它返回的就是根据对象的内存地址换算出的一个值。这样一来,当集合要添加新的元素时,先调用这个元素的hashCode方法,就一
下子能定位到它应该放置的物理位置上。如果这个位置上没有元素,它就可以直接存储在这个位置上,不用再进行任何比较了;如果
这个位置上已经有元素了,就调用它的equals方法与新元素进行比较,相同的话就不存了,不相同就散列其它的地址。这样一来实际
调用equals方法的次数就大大降低了,几乎只需要一两次
解决hash冲突的方法
hash冲突:
就是根据key即经过一个函数f(key)得到的结果的作为地址去存放当前的key-value键值对(这个是hashmap的存值方式),但是却发现
算出来的地址上已经有人先来了
解决方案:
1、开放定址法:
当冲突发生时,使用某种探查(亦称探测)技术在散列表中形成一个探查(测)序列。沿此序列逐个单元地查找,直到找到给定的关键
字,或者碰到一个开放的地址(即该地址单元为空)为止(若要插入,在探查到开放的地址,则可将待插入的新结点存人该地址单
元)。查找时探查到开放的 地址则表明表中无待查的关键字,即查找失败
2、拉链法:(默认)
就是在每个位桶实现的时候,我们采用链表(jdk1.8之后采用链表+红黑树)的数据结构来去存取发生哈希冲突的输入域的关键字
(也就是被哈希函数映射到同一个位桶上的关键字)
3、哈希法:又称散列法、杂凑法以及关键字地址计算法等,相应的表称为哈希表
首先在元素的关键字k和元素的存储位置p之间建立一个对应关系f,使得p=f(k),f称为哈希函数。创建哈希表时,把关键字为k的元素
直接存入地址为f(k)的单元;以后当查找关键字为k的元素时,再利用哈希函数计算出该元素的存储位置p=f(k),从而达到按关键字直
接存取元素的目的。
当关键字集合很大时,关键字值不同的元素可能会映象到哈希表的同一地址上,即 k1≠k2 ,但 H(k1)=H(k2),这种现象称为
冲突,此时称k1和k2为同义词。实际中,冲突是不可避免的,只能通过改进哈希函数的性能来减少冲突
List集合实现类与CopyOnWriteArrayList
知识图解:
ArrayList : 基于数组实现的非线程安全的集合。查询元素快,插入,删除中间元素慢
LinkedList : 基于链表实现的非线程安全的集合。查询元素慢,插入,删除中间元素快
Vector : 基于数组实现的线程安全的集合。线程同步(方法被synchronized修饰),性能比ArrayList差
CopyOnWriteArrayList : 基于数组实现的线程安全的写时复制集合。线程安全(ReentrantLock加锁),性能比Vector高,适合读多
写少的场景
ArrayList : 查询数据快,是因为数组可以通过下标直接找到元素。 写数据慢有两个原因:一是数组复制过程需要时间,二是扩容需
要实例化新数组也需要时间
LinkedList : 查询数据慢,是因为链表需要遍历每个元素直到找到为止。 写数据快有一个原因:除了实例化对象需要时间外,只需要
修改指针即可完成添加和删除元素
注:这里的快和慢是相对的。并不是LinkedList的插入和删除就一定比ArrayList快。明白其快慢的本质:ArrayList快在定位,慢在数
组复制。LinkedList慢在定位,快在指针修改
一、ArrayList
ArrayList在执行查询操作时:
第一步:先判断下标是否越界
第二步:直接通过下标从数组中返回元素
ArrayList在执行顺序添加操作时:
第一步:通过扩容机制判断原数组是否还有空间,若没有则重新实例化一个空间更大的新数组,把旧数组的数据拷贝到新数组中
第二步:在新数组的最后一位元素添加值
ArrayList在执行中间插入操作时:
第一步:先判断下标是否越界
第二步:判断是否需要扩容扩容
第三步:若插入的下标为 i ,则通过复制数组的方式将 i 后面的所有元素,往后移一位
第四步:新数据替换下标为 i 的旧元素
删除也是一样:只是数组往前移了一位,最后一个元素设置为null,等待JVM垃圾回收
二、LinkedList
LinkedList在执行查询操作时:
第一步:先判断元素是靠近头部,还是靠近尾部
第二步:若靠近头部,则从头部开始依次查询判断。和ArrayList的elementData(index)相比当然是慢了很多
LinkedList在插入元素操作时:
第一步:判断插入元素的位置是链表的尾部,还是中间
第二步:若在链表尾部添加元素,直接将尾节点的下一个指针指向新增节点
第三步:若在链表中间添加元素,先判断插入的位置是否为首节点,是则将首节点的上一个指针指向新增节点。否则先获取当前节点
的上一个节点(简称A),并将A节点的下一个指针指向新增节点,然后新增节点的下一个指针指向当前节点
// 查询元素 public E get(int index) { checkElementIndex(index); // 检查是否越界 return node(index).item; } Node<E> node(int index) { if (index < (size >> 1)) { // 类似二分法 Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } } // 插入元素 public void add(int index, E element) { checkPositionIndex(index); // 检查是否越界 if (index == size) // 在链表末尾添加 linkLast(element); else // 在链表中间添加 linkBefore(element, node(index)); } void linkBefore(E e, Node<E> succ) { final Node<E> pred = succ.prev; final Node<E> newNode = new Node<>(pred, e, succ); succ.prev = newNode; if (pred == null) first = newNode; else pred.next = newNode; size++; modCount++; }三、Vector
Vector的数据结构和使用方法与ArrayList差不多。最大的不同就是Vector是线程安全的。从下面的源码可以看出,几乎所有的对数据
操作的方法都被synchronized关键字修饰。synchronized是线程同步的,当一个线程已经获得Vector对象的锁时,其他线程必须等
待直到该锁被释放。从这里就可以得知Vector的性能要比ArrayList低
若想要一个高性能,又是线程安全的ArrayList,可以使用Collections.synchronizedList(list);方法或者使用CopyOnWriteArrayList集
合
public synchronized E get(int index) { if (index >= elementCount) throw new ArrayIndexOutOfBoundsException(index); return elementData(index); } public synchronized boolean add(E e) { modCount++; ensureCapacityHelper(elementCount + 1); elementData[elementCount++] = e; return true; } public synchronized boolean removeElement(Object obj) { modCount++; int i = indexOf(obj); if (i >= 0) { removeElementAt(i); return true; } return false; }四、CopyOnWriteArrayList
它是一个写时复制的容器。当我们往一个容器添加元素的时候,不是直接往当前容器添加,而是先将当前容器进行copy一份,复制
出一个新的容器,然后对新容器里面操作元素,最后将原容器的引用指向新的容器。所以CopyOnWrite容器是一种读写分离的思
想,读和写不同的容器
应用场景:适合高并发的读操作(读多写少)。若写的操作非常多,会频繁复制容器,从而影响性能
CopyOnWriteArrayList 和Vector的区别:
都是线程安全的,不同的是:前者使用ReentrantLock类,后者使用synchronized关键字。ReentrantLock提供了更多的锁投票机
制,在锁竞争的情况下能表现更佳的性能。就是它让JVM能更快的调度线程,才有更多的时间去执行线程。这就是为什么
CopyOnWriteArrayList的性能在大并发量的情况下优于Vector的原因
private E get(Object[] a, int index) { return (E) a[index]; } public boolean add(E e) { final ReentrantLock lock = this.lock; lock.lock(); try { Object[] elements = getArray(); int len = elements.length; Object[] newElements = Arrays.copyOf(elements, len + 1); newElements[len] = e; setArray(newElements); return true; } finally { lock.unlock(); } } private boolean remove(Object o, Object[] snapshot, int index) { final ReentrantLock lock = this.lock; lock.lock(); try { Object[] current = getArray(); int len = current.length; ...... Object[] newElements = new Object[len - 1]; System.arraycopy(current, 0, newElements, 0, index); System.arraycopy(current, index + 1, newElements, index, len - index - 1); setArray(newElements); return true; } finally { lock.unlock(); } }

HashTable和Properties深入分析
一、HashTble
1、Hashtable的定义
我们翻看下源码中对Hashtable的定义如下:
public class Hashtable<K,V> extends Dictionary<K,V> implements Map<K,V>, Cloneable, java.io.Serializable {}从中可以看出HashTable继承Dictionary类,实现Map接口。其中Dictionary类是任何可将键映射到相应值的类(如 Hashtable)的
抽象父类。每个键和每个值都是一个对象。在任何一个 Dictionary 对象中,每个键至多与一个值相关联。Map是"key-value键值
对"接口。
HashTable采用"拉链法"实现哈希表,它定义了几个重要的参数:table、count、threshold、loadFactor、modCount
table:为一个Entry[]数组类型
Entry:代表了“拉链”的节点,每一个Entry代表了一个键值对,哈希表的"key-value键值对"都是存储在Entry数组中的
count:HashTable的大小,注意这个大小并不是HashTable的容器大小,而是他所包含Entry键值对的数量
threshold:Hashtable的阈值,用于判断是否需要调整Hashtable的容量。threshold的值=“容量*加载因子”
loadFactor:加载因子
modCount:用来实现“fail-fast”机制的(也就是快速失败)。所谓快速失败就是在并发集合中,其进行迭代操作时,若有其他线程对
其进行结构性的修改,这时迭代器会立马感知到,并且立即抛出ConcurrentModificationException异常,而不是等到
迭代完成之后才告诉你
Hashtable 和Map 之间关系图:
Hashtable继承于Dictionary类,实现了Map接口。Map是"key-value键值对"接口,Dictionary是声明了操作"键值对"函数接口的抽
象类
2、构造方法
// 默认构造函数。 public Hashtable() // 指定“容量大小”的构造函数 public Hashtable(int initialCapacity) // 指定“容量大小”和“加载因子”的构造函数 public Hashtable(int initialCapacity, float loadFactor) // 包含“子Map”的构造函数 public Hashtable(Map<? extends K, ? extends V> t)上述构造方法中,最核心的其实就是第三个,因为无论是无参构造还是初始化容量构造最后都是调用的第三个,因此有必要看下第三
个方法的源码:
public Hashtable(int initialCapacity, float loadFactor) { //验证初始容量 if (initialCapacity < 0) throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity); //验证加载因子 if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal Load: "+loadFactor); if (initialCapacity==0) initialCapacity = 1; this.loadFactor = loadFactor; //初始化table,获得大小为initialCapacity的table数组 table = new Entry<?,?>[initialCapacity]; //计算阀值 threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1); }Hashtable方法:
synchronized void clear() synchronized Object clone() boolean contains(Object value) synchronized boolean containsKey(Object key) synchronized boolean containsValue(Object value) synchronized Enumeration<V> elements() synchronized Set<Entry<K, V>> entrySet() synchronized boolean equals(Object object) synchronized V get(Object key) synchronized int hashCode() synchronized boolean isEmpty() synchronized Set<K> keySet() synchronized Enumeration<K> keys() synchronized V put(K key, V value) synchronized void putAll(Map<? extends K, ? extends V> map) synchronized V remove(Object key) synchronized int size() synchronized String toString() synchronized Collection<V> values()3、主要方法分析
A、put方法:
将指定
key映射到此哈希表中的指定value。注意这里键key和值value都不可为空。public synchronized V put(K key, V value) { // 确保value不为null if (value == null) { throw new NullPointerException(); } /* * 确保key在table[]是不重复的 * 处理过程: * 1、计算key的hash值,确认在table[]中的索引位置 * 2、迭代index索引位置,如果该位置处的链表中存在一个一样的key,则替换其value,返回旧值 */ Entry tab[] = table; int hash = hash(key); //计算key的hash值 int index = (hash & 0x7FFFFFFF) % tab.length; 迭代,寻找该key,替换 for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { V old = e.value; e.value = value; return old; } } modCount++; if (count >= threshold) { //如果容器中的元素数量已经达到阀值,则进行扩容操作 rehash(); tab = table; hash = hash(key); index = (hash & 0x7FFFFFFF) % tab.length; } // 在索引位置处插入一个新的节点 Entry<K,V> e = tab[index]; tab[index] = new Entry<>(hash, key, value, e); //容器中元素+1 count++; return null; }put方法的整个处理流程:
计算key的hash值,根据hash值获得key在table数组中的索引位置,然后迭代该key处的Entry链表,若该链表中存在一个这个的key
对象,那么就直接替换其value值即可,否则再将该key-value节点插入该index索引位置处。如下:假设我们现在Hashtable的容量
为5,已经存在了(10,10),(13,13),(16,16),(17,17),(21,21)这 5 个键值对,目前他们在Hashtable中的位置如下:
现在,我们插入一个新的键值对,put(16,22),假设key=16的索引为1.但现在索引1的位置有两个Entry了,所以程序会对链表进行迭
代。迭代的过程中,发现其中有一个Entry的key和我们要插入的键值对的key相同,所以现在会做的工作就是将newValue=22替换
oldValue=16,然后返回oldValue=16
然后我们现在再插入一个,put(33,33),key=33的索引为3,并且在链表中也不存在key=33的Entry,所以将该节点插入链表的第一
个位置。
在HashTable的put方法中有两个地方需要注意:
a、HashTable的扩容操作,在put方法中,如果需要向table[]中添加Entry元素,会首先进行容量校验,如果容量已经达到了阀值,
HashTable就会进行扩容处理rehash(),如下:
protected void rehash() { int oldCapacity = table.length; //元素 Entry<K,V>[] oldMap = table; //新容量=旧容量 * 2 + 1 int newCapacity = (oldCapacity << 1) + 1; if (newCapacity - MAX_ARRAY_SIZE > 0) { if (oldCapacity == MAX_ARRAY_SIZE) return; newCapacity = MAX_ARRAY_SIZE; } //新建一个size = newCapacity 的HashTable Entry<K,V>[] newMap = new Entry[]; modCount++; //重新计算阀值 threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1); //重新计算hashSeed boolean rehash = initHashSeedAsNeeded(newCapacity); table = newMap; //将原来的元素拷贝到新的HashTable中 for (int i = oldCapacity ; i-- > 0 ;) { for (Entry<K,V> old = oldMap[i] ; old != null ; ) { Entry<K,V> e = old; old = old.next; if (rehash) { e.hash = hash(e.key); } int index = (e.hash & 0x7FFFFFFF) % newCapacity; e.next = newMap[index]; newMap[index] = e; } } }在这个rehash()方法中我们可以看到容量扩大两倍+1,同时需要将原来HashTable中的元素一一复制到新的HashTable中,这个过程
是比较消耗时间的,同时还需要重新计算hashSeed的,毕竟容量已经变了。这里对阀值啰嗦一下:比如初始值11、加载因子默认
0.75,那么这个时候阀值threshold=8,当容器中的元素达到8时,HashTable进行一次扩容操作,容量 = 8 * 2 + 1 =17,而阀值
threshold=17*0.75 = 13,当容器元素再一次达到阀值时,HashTable还会进行扩容操作,以此类推
2、在计算索引位置index时,HashTable进行了一个与运算过程(hash & 0x7FFFFFFF),为什么需要做一步操作,这么做有什么好
处?
这是因为在计算hash值得时候可能是负数因此采用了和0X7FFFFFFF相与的操作保证为正数,这个涉及到计算机的二进制数存放正数
负数是如何存放的一个逻辑基础知识,正数很容易,负数的存放是采用负数的绝对值取反得到反码然后+1 得到补码然后进行的存
放,因此和0X7FFFFFFF相与可保证只改变符号位而不改变其它位
B、get方法:
首先通过 hash()方法求得 key 的哈希值,然后根据 hash 值得到 index 索引(上述两步所用的算法与 put 方法都相同)。然后迭代
链表,返回匹配的 key 的对应的 value;找不到则返回 null
public synchronized V get(Object key) { Entry tab[] = table; int hash = hash(key); int index = (hash & 0x7FFFFFFF) % tab.length; for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { return e.value; } } return null; }Hashtable 遍历方式:
//1、使用keys() Enumeration<String> en1 = table.keys(); while(en1.hasMoreElements()) { en1.nextElement(); } //2、使用elements() Enumeration<String> en2 = table.elements(); while(en2.hasMoreElements()) { en2.nextElement(); } //3、使用keySet() Iterator<String> it1 = table.keySet().iterator(); while(it1.hasNext()) { it1.next(); } //4、使用entrySet() Iterator<Entry<String, String>> it2 = table.entrySet().iterator(); while(it2.hasNext()) { it2.next(); }
二、Properties
java.util 类 Properties java.lang.Object java.util.Dictionary<K,V> java.util.Hashtable<Object,Object> java.util.Properties它是Hashtable的一个子类,是一个使用比父类使用更多的类,Properties类表示了一个持久的属性集,它是在一个文件中存储键值
对儿的,其中键值对儿以等号分隔。Properties可保存在流中或从流中加载。属性列表中的每个键及其所对应的值都是字符串。
Properties类是线程安全的:多个线程可以共享单个Properties对象而无需进行外部同步。一组属性示例:
foo=bar
fu=baz
一个属性列表可包含另一个属性列表作为它的“默认值”;如果未能在原有的属性列表中搜索到属性键,则搜索第二个属性列表。
如果在“不安全”的 Properties 对象(即包含非 String 的键或值)上调用 store 或 save 方法,则该调用将失败。类似地,如果在“不
安全”的 Properties 对象(即包含非 String 的键)上调用 propertyNames 或 list 方法,则该调用将失败。
除了输入/输出流使用 ISO 8859-1 字符编码外,load(InputStream) / store(OutputStream, String)方法与
load(Reader)/store(Writer, String)的工作方式完全相同。
loadFromXML(InputStream)和 storeToXML(OutputStream, String, String)方法按简单的 XML 格式加载和存储属性。默认使用
UTF-8 字符编码,但如果需要,可以指定某种特定的编码。
示例练习一:如何装载属性文件并列出它当前的一组键和值
思路:传递属性文件的输入流InputStream给load()方法,会将改属性文件中的每个键值对儿添加到Properties实例中;然后条用
list()列出所有属性或者使用getProperty()获取单独的属性。(注意 list() 方法的输出中键-值对的顺序与它们在输入文件中的顺序不一
样。 Properties 类在一个散列表(hashtable,事实上是一个 Hashtable 子类)中储存一组键-值对,所以不能保证顺序。 )
import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.util.Properties; public class PropertiesTest { public static void main(String[] args) { Properties properties = new Properties(); try { properties.load(new FileInputStream("test.properties"));//加载属性文件 properties.list(System.out);//将属性文件中的键值对儿打印到控制台 properties.getProperty("foo"); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } } }示例练习二:如何装载XML版本的属性文件并列出它当前的一组键和值。(只有装载方法有差异,其余完全相同
load(),loadFromXML())
import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.util.Properties; public class PropertiesTest { public static void main(String[] args) { Properties properties = new Properties(); try { properties.loadFromXML(new FileInputStream("test.xml"));//加载属性文件 properties.list(System.out);//将属性文件中的键值对儿打印到控制台 properties.getProperty("foo"); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } } }示例练习三:如何将文件保存到属性文件中
import java.util.*; import java.io.*; public class StoreXML { public static void main(String args[]) throws Exception { Properties prop = new Properties(); prop.setProperty("one-two", "buckle my shoe"); prop.setProperty("three-four", "shut the door"); prop.setProperty("five-six", "pick up sticks"); prop.setProperty("seven-eight", "lay them straight"); prop.setProperty("nine-ten", "a big, fat hen"); //将键值对儿保存到XML文件中 prop.storeToXML(new FileOutputStream("test.xml"), "saveXML"); //将键值对儿保存到普通的属性文件中 prop.store(new FileOutputStream("test.properties"), "saveProperties"); fos.close(); } }将键值对儿保存到XML文件中的输出结果如下:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>Rhyme</comment> <entry key="seven-eight">lay them straight</entry> <entry key="five-six">pick up sticks</entry> <entry key="nine-ten">a big, fat hen</entry> <entry key="three-four">shut the door</entry> <entry key="one-two">buckle my shoe</entry> </properties>将键值对儿保存到普通的属性文件中输出结果如下:
one-two=buckle my shoe three-four=shut the door five-six=pick up sticks seven-eight=lay them straight nine-ten=a big, fat hen注意:从一个XML文件中装载一组属性,其DTD文件如下:
<?xml version="1.0" encoding="UTF-8"?> <!-- DTD for properties --> <!ELEMENT properties ( comment?, entry* ) > <!ATTLIST properties version CDATA #FIXED "1.0"> <!ELEMENT comment (#PCDATA) > <!ELEMENT entry (#PCDATA) > <!ATTLIST entry key CDATA #REQUIRED>在外围
<properties>标签中包装的是一个<comment>标签,后面是任意数量的<entry>标签。对每一个<entry>标签,有一个键属性,输入的内容就是它的值。注意点:路径问题,如下:
import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.util.Properties; /** * 使用Properties读取配置文件 * 资源配置文件: * 使用相对与绝对路径读取 * load(InputStream inStream) load(Reader reader) loadFromXML(InputStream in) * @author Administrator * */ public class Demo03 { /** * @param args * @throws IOException * @throws FileNotFoundException */ public static void main(String[] args) throws FileNotFoundException, IOException { Properties pro=new Properties(); //读取 绝对路径 //pro.load(new FileReader("e:/others/db.properties")); //读取 相对路径 pro.load(new FileReader("src/com/bjsxt/others/pro/db.properties")); System.out.println(pro.getProperty("user", "bjsxt")); } }import java.io.IOException; import java.util.Properties; /** * 使用类相对路径读取配置文件 * bin * @author Administrator * */ public class Demo04 { /** * @param args * @throws IOException */ public static void main(String[] args) throws IOException { Properties pro =new Properties(); //类相对路径的 / bin //pro.load(Demo04.class.getResourceAsStream("/com/bjsxt/others/pro/db.properties")); //"" bin pro.load(Thread.currentThread().getContextClassLoader().getResourceAsStream("com/bjsxt/others/pro/db.properties")); System.out.println(pro.getProperty("user", "bjsxt")); } }关于类路径需要注意一下;举个例子:
import java.io.FileInputStream; import java.io.InputStream; import java.util.Collection; import java.util.Properties; /** * 使用配置文件读取调用者的类 * * @author jiqinlin * */ public class ReflectTest { public static void main(String[] args) throws Exception{ //使用绝对路径,否则无法读取config.properties //InputStream inStream=new FileInputStream("F:\\android\\test\\src\\com\\ljq\\test\\resource\\config.properties"); //ReflectTest.class.getClassLoader().getResourceAsStream(String path): 默认则是从ClassPath根下获取,path不能以’/'开头,最终是由ClassLoader获取资源。 //InputStream inStream = ReflectTest.class.getClassLoader().getResourceAsStream("com/ljq/test/resource/config.properties"); // ReflectTest.class.getResourceAsStream(String path): path不以’/'开头时默认是从此类所在的包下取资源,以’/'开头则是从ClassPath根下获取。 //其只是通过path构造一个绝对路径,最终还是由ClassLoader获取资源。 //InputStream inStream = ReflectTest.class.getResourceAsStream("/com/ljq/test/resource/config.properties"); //config.properties配置文件所在目录是ReflectTest类所在子目录,才可以;否则报空指针异常 InputStream inStream = ReflectTest.class.getResourceAsStream("resource/config.properties"); Properties props=new Properties(); props.load(inStream); inStream.close(); String className=props.getProperty("className"); Collection collection=(Collection)Class.forName(className).newInstance(); collection.add("123"); System.out.println("size="+collection.size()); //size=1 } }config.properties配置文件
className=java.util.HashSetgetResourceAsStream用法大致有以下几种:
第一:要加载的文件和.class文件在同一目录下,例如:com.ljq.test目录下有类ReflectTest.class,同时有资源文件config.properties 那么,应该有如下代码: ReflectTest.class.getResourceAsStream("config.properties"); 第二:在ReflectTest.class目录的子目录下,例如:com.ljq.test下有类ReflectTest.class,同时在com.ljq.test.resource目录下有资源文件config.properties 那么,应该有如下代码: ReflectTest.class.getResourceAsStream("resource/config.properties"); 第三:不在ReflectTest.class目录下,也不在子目录下,例如:com.ljq.test下有类ReflectTest.class ,同时在com.ljq.resource目录下有资源文件config.properties 那么,应该有如下代码: ReflectTest.class.getResourceAsStream("/com/ljq/resource/config.properties"); 总结一下,可能只是两种写法 第一:前面有 “/” ,“/”代表了工程的根目录,例如工程名叫做test,“/”代表了test ReflectTest.class.getResourceAsStream("/com/ljq/resource/config.properties"); 第二:前面没有 “/” ,代表当前类的目录 ReflectTest.class.getResourceAsStream("config.properties"); ReflectTest.class.getResourceAsStream("resource/config.properties"); 最后,总结 getResourceAsStream读取的文件路径只局限在工程的源文件夹中,包括在工程src根目录下,以及类包里面任何位置,但是如果配置文件路径是在除了源文件夹之外的其他文件夹中时,该方法是用不了的。Properties获取数据乱码解决
1.原因
Properties调用load(InputStream)时,读取文件时使用的默认编码为ISO-8859-1;当我们将中文放入到properties文件中,通过
getProperty(key)获取值时,取到得数据是ISO-8859-1格式的,但是ISO-8859-1是不能识别中文的。
2.解决方法
通过getProperty()获取的数据data既然是ISO-8859-1编码的,就通过data.getByte(“iso-8859-1”)获取获取,使用new
String(data.getByte(“iso-8859-1”),”UTF-8”)进行转换。当然properties文件的编码类型需要和new String(Byte[],charset)中的第二个
参数的编码类型相同。
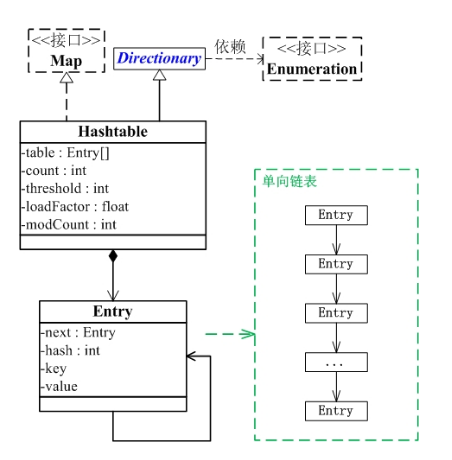
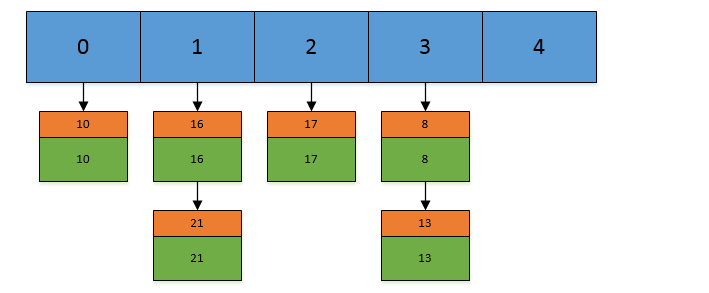
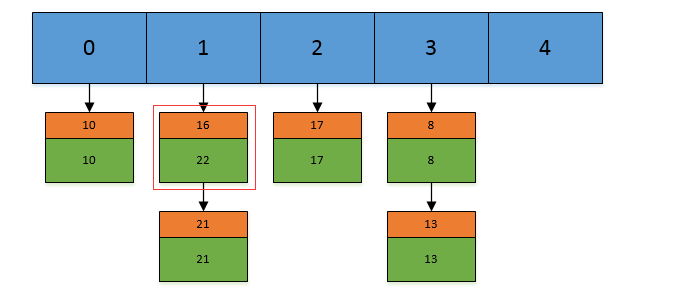
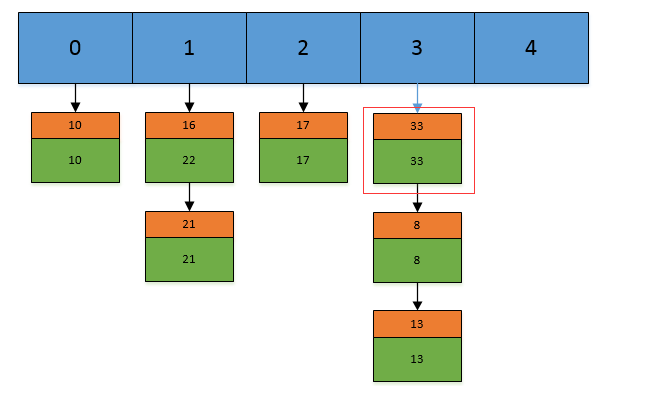
Collections集合工具类
Collections是集合类的一个帮助工具类,不能被实例化。它包含有各种有关集合操作的静态多态方法,用于实现对各种集合的搜索、
排序、线程安全化等操作。此类不能实例化,就像一个工具类,服务于Java的Collection框架
常用方法:
void sort(List) 对List容器内元素进行排序,排序规则按照升序排序
void shuffle(List) 对List容器内的元素进行随机排序
void reverse(List) 对List容器内的元素进行逆序排序
void fill(List,Object) 用一个特定的对象重写整个List容器
int binary(List,Object) 对于顺序的List容器,采用折半查找的方法查找特定对象
ConcurrentHashMap
Segment段 :
ConcurrentHashMap 和 HashMap 思路是差不多的,但是因为它支持并发操作,所以要复杂一些。整个 ConcurrentHashMap 由
一个个 Segment 组成, Segment 代表”部分“或”一段“的意思,所以很多地方都会将其描述为分段锁。注意,行文中,我很多地方用
了“槽”来代表一个segment
线程安全(Segment 继承 ReentrantLock 加锁) :
简单理解就是, ConcurrentHashMap 是一个 Segment 数组, Segment 通过继承ReentrantLock 来进行加锁,所以每次需要加锁
的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全 并行度(默认 16)
concurrencyLevel:
并行级别、并发数、 Segment 数,默认是 16,也就是说 ConcurrentHashMap 有 16 个 Segments,所以理论上, 这个时候,最多
可以同时支持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上。这个值可以在初始化的时候设置为其他值,但是
一旦初始化以后,它是不可以扩容的。再具体到每个 Segment 内部,其实每个 Segment 很像之前介绍的HashMap,不过它要保证
线程安全,所以处理起来要麻烦些
底层原理:
a、加锁底层
1.7是reentrantlock+segment+entry,加锁粒度是分段(segment)加锁
1.8是synchronize+CAS+node,加锁粒度降低为对node节点
b、加锁过程
1.7Put整个过程都是加锁操作的
1.8put拿到节点时先判断,如果为-1则说明在扩容,那么就先一起就行扩容,如果为空则CAS插入,如果失败,那么将锁升级
synchronize插入
内部与外部比较器
TreeSet和TreeMap使用时需要使用比较器,否咋报错:ClassCastException异常
排序规则实现方式:
1、通过自身实现比较规则(内部比较器)
在元素自身实现比较规则时,需要实现Comparable接口中的compareTo()方法,该方法用来定义比较规则
8种数据类型通过comparable()方法实现排序
2、通过比较器指定比较规则(外部比较器)
需要创建比较器,实现Comparator接口中的compare()方法来定义比较规则,在实例化TreeSet时,将比较器对象交给TreeSet来
完成排序。Comparator泛型接口需要定义数据类型,如比较自定义类的对象,则数据类型为自定义类的类型
内部比较器实现:
import java.util.Set; import java.util.TreeSet; //此处实现Comparable接口必须指定泛型类型,方便后续重写compareTo()方法 public class Text5 implements Comparable<Text5>{ private String name; private int age; public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public Text5() { } public Text5(String name, int age) { this.name = name; this.age = age; } //重写compareTo()方法 //***为什么参数没有两个对象?如何实现比较?*** //已解决,自定义类的对象在调用compareTo()方法时传入另一个对象作为参数 //***调用者和参数 @Override public int compareTo(Text5 o) { if (this.age>o.getAge()){ //根据< 或者 >来决定排序方式,比如从小到大 return 1; } if(this.age==o.getAge()){ return this.name.compareTo(o.getName()); } return -1; } //必须重写toString()方法,否则输出内存地址值 @Override public String toString() { return "Text5{" + "name='" + name + '\'' + ", age=" + age + '}'; } //主方法入口 public static void main(String[] args) { //定义TreeSet容器实例 Set<String> q=new TreeSet<>(); q.add("c"); q.add("g"); q.add("k"); q.add("e"); Set<Text5> w = new TreeSet<>(); Text5 u1=new Text5("yang",18); Text5 u2=new Text5("jing",20); Text5 u3=new Text5("da",20); w.add(u1); w.add(u2); w.add(u3); //foreach()方法遍历TreeSet容器q元素 //通过comparableTo()方法进行比较排序,8中数据类型已经在各自包装类的方法中定义了比较方法 for (String tt:q) { System.out.println(tt); } //foreach()方法遍历TreeSet容器w元素 //自定义对象必须使用自定义compareTo()方法重新定义排序规则,否则出现ClassCastException异常 for (Text5 yy:w) { System.out.println(yy); } } }外部比较器实现:
package container_7; //TreeSet容器--通过比较器指定比较规则 import java.util.Comparator; import java.util.Set; import java.util.TreeSet; //自定义类未实现comparable接口,需要重新定义比较器(类) public class Text6 { private String name; private int age; public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public Text6() { } public Text6(String name, int age) { this.name = name; this.age = age; } @Override public String toString() { return "Text6{" + "name='" + name + '\'' + ", age=" + age + '}'; } //主方法入口 public static void main(String[] args) { //TreeSet容器创建实例时,可以传入比较器对象作为参数 Set<Text6> r = new TreeSet<>(new compartor1()); Text6 A=new Text6("yang",18); Text6 B=new Text6("jing",26); Text6 C=new Text6("da",26); r.add(A); r.add(B); r.add(C); for (Text6 u:r) { System.out.println(u); } } } //创建比较器,是一个普通类,实现Comprator接口,泛型根据需要比较的对象的类定义类型 class compartor1 implements Comparator<Text6>{ //重写compare()方法,***注意:不是compareTo()方法 @Override public int compare(Text6 o1, Text6 o2) { if(o1.getAge()>o2.getAge()){ return 1; } if(o1.getAge()==o2.getAge()){ o1.getName().compareTo(o2.getName()); } return -1; //***是否可以使用Integer包装类的comparable接口中compareTo()方法进行比较*** //***不可以使用,为什么呢???*** /* if (o1.getName() != o2.getName()){ o1.getAge().compareTo(o2.getAge()); }*/ } }
泛型
泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型。泛型的本质是参数化类型,也就是说所操作的
数据类型被指定为一个参数。比如我们要写一个排序方法,能够对整型数组、字符串数组甚至其他任何类型的数组进行排序,我们就
可以使用 Java 泛型。
类型擦除:
Java中的泛型基本上都是在编译器这个层次来实现的。在生成的Java字节码中是不包含泛型中的类型信息的。使用泛型的时候加上的
类型参数,会在编译器在编译的时候去掉。这个过程就称为类型擦除。如List和 List类型,在编译之后都会变
成 List。 JVM 看到的只是 List,而由泛型附加的类型信息对 JVM 来说是不可见的。类型擦除的基本过程也比较简单,首先是找到用
来替换类型参数的具体类。这个具体类一般是 Object。如果指定了类型参数的上界的话,则使用这个上界。把代码中的类型参数都
替换成具体的类。
泛型类:
/** * 泛型字符(占位符)可以是任意标识符,一般采用几个标记:E T K V N ? * E: Element 在容器中使用,表示容器中的元素 * T: Type 表示普通的Java类 * K: Key 表示键,例如,Map中的键Key * V: Value 表示值 * N: Number 表示数值类型 * ?: 表示不确定的Java类型 * * 语法结构 * public class 类名<泛型表示符号>{ } * * 创建泛型类对象 * 类名<数据类型> 引用 = new 类名<>(); * * 泛型主要应用于编译阶段,编译后生成的字节码文件.class文件不包含泛型中的类型信息 * 基本类型不能使用泛型 * 不能通过泛型创建参数(不能当做对象声明) * */泛型接口:
/** * 语法结构 * public interface 接口名<泛型表示符>{ } * 创建实现类实例 * 1、接口名<数据类型> 对象名=new 实现类名(); * 2、实现类名 对象名=new 实现类名(); //实现类中已明确泛型类型,实现类无需再写<数据类型> * */非静态泛型方法:
/** * 语法结构 * public <泛型表示符> void 方法名称(泛型表示符 形参名){ } * * public <泛型表示符> 泛型表示符 方法名称(泛型表示符 形参名){ } * * 创建实例对象与类相同 * * 类中变量的值由构造方法传入,方法中的值在调用时由调用者传入。两者不存在必要关系 * */静态泛型方法:
/** * 语法结构 * * public static<泛型表示符> void 方法名称(泛型表示符 形参名){ } * * public static<泛型表示符> 泛型表示符 方法名称(泛型表示符 形参名){ } * * 静态方法无需创建实例对象,可直接通过<类名.静态方法名>调用 * */泛型方法与可变参数:
/** * 语法结构 * * public static<泛型表示符> void 方法名称(泛型表示符... 形参名){ } * * public static<泛型表示符> 泛型表示符 方法名称(泛型表示符... 形参名){ } * * public <泛型表示符> void 方法名称(泛型表示符... 形参名){ } * * public <泛型表示符> 泛型表示符 方法名称(泛型表示符... 形参名){ } * * 静态方法无需创建实例对象,可直接通过<类名.静态方法名>调用 * * 可变参数本质上是一个数组,形参有多个时必须放在形参的最后,一个方法最多只能有一个可变参数 * */无界通配符:
在方法中传入对象作为参数时,若无法确定对象的类型,则使用无界通配符声明,在使用此方法时再给定具体的类型 /** * 泛型表示符用来声明泛型类或泛型方法 * public class 类名<T>{ } * 无界通配符用来使用泛型类或泛型方法 * public void 方法名(类名<?> 形参){ } * * 定义泛型类时,可以使用T声明,代表可以是任意类型的类 * 当使用泛型类对象时,必须明确指定泛型类的类型,当无法指定时,可以使用无界通配符<?>声明泛型对象,在开始使用时再给定具体类型 * 泛型不会考虑继承关系 * */通配符上限限定:
/** * 上限限定表示泛型参数的类型只能是T类及T类的子类或者T接口及T接口的子接口 * 使用与泛型类 * 语法结构 * public class 类名<T extends 父类>{ } //此处定义的类的泛型只能是父类或者其父类的子类 * public void 方法名(类名<? extends 最低类> 形参){ } //对无界通配符的上限进行限定,参数类型只能是父类或者父类的子类 */通配符下限限定:
/** * 下限限定表示泛型参数的类型只能是T类及T类的父类或者T接口及T接口的父接口 * 在方法形参中传入类的对象时使用 * * 语法结构(不适于泛型类) * public void 方法名(类名<? super 最低类>){ } * */
Java中的IO面试题
网络编程5种I/O模型
同步和异步:
同步:同步就是发起一个调用后,被调用者未处理完请求之前,调用不返回
异步: 异步就是发起一个调用后,立刻得到被调用者的回应表示已接收到请求,但是被调用者并没有返回结果,此时我们可以
处理其他的请求,被调用者通常依靠事件,回调等机制来通知调用者其返回结果
同步和异步的最大区别在于异步的话调用者不需要等待处理结果,被调用者会通过回调等机制来通知调用者其返回结果
阻塞和非阻塞
- 阻塞: 阻塞就是发起一个请求,调用者一直等待请求结果返回,也就是当前线程会被挂起,无法从事其他任务,只有当条件就
绪才能继续
- 非阻塞: 非阻塞就是发起一个请求,调用者不用一直等着结果返回,可以先去干其他事情
一个IO操作可以分为两个步骤:发起IO请求和实际的IO操作
a、操作系统的一次写操作分为两步:将数据从用户空间拷贝到系统空间;从系统空间往网卡写
b、一次读操作分为两步:将数据从网卡拷贝到系统空间;将数据从系统空间拷贝到用户空间
阻塞IO和非阻塞IO的区别:
在于第一步,发起IO请求是否会被阻塞,如果阻塞直到完成那么就是传统的阻塞IO,如果不阻塞,那么就是非阻塞IO
同步IO和异步IO的区别:
在于第二个步骤是否阻塞,如果实际的IO读写阻塞请求进程,那么就是同步IO,因此阻塞IO、非阻塞IO、IO复用、信号驱动IO都是
同步IO,如果不阻塞,而是操作系统做完IO两个阶段的操作再将结果返回,那么就是异步IO
编程模型:
1、阻塞I/O模型
阻塞I/O模型通信示意图如下:
当用户调用了recvfrom这个系统调用后,内核就开始准备数据。对于网络I/O来说,很多时候数据还没有到达,这个时候要等足够的
数据到来。而在这个时候,用户的进程会被阻塞,当数据准备好的时候,它就会将数据从内核拷贝到用户内存,然后返回结果,用户
进程这时候才会解除阻塞的状态,重新运行起来。在阻塞I/O模型中,进程阻塞挂起不消耗cpu的资源,及时响应每个操作。适用于
并发量小的网络应用开发。对于并发量大的应用,需要为每一个请求分配一个处理进程,系统开销大
2、非阻塞I/O模型
非阻塞I/O模型通信示意图如下:
在非阻塞I/O模型中,当用户进程发出read操作时,如果内核中的数据还没有准备好,那么它并不会阻塞用户进程,而是立刻返回一
个error。从用户进程角度来讲,发起一个read操作,并不需要等待,而是马上就得到了一个结果。当用户进程判断得到一个error
后,知道内核还没有准备好数据,于是再次发送read操作,一旦内核准备好了数据并且收到了用户进程的调用,他马上就会把数据
拷贝到用户内存,然后返回。在这种模型中,用户进程需要不断的询问内核是否准备好,消耗cpu的资源,适合并发量较小且不需要
及时响应的网络应用开发
3、多路复用I/O模型
多路复用I/O模型示意图如下:
在多路复用I/O模型中,多个进程的I/O可以注册到一个复用器(Selector)上,当用户进程调用这个Selector,如果Selector监听的
所有I/O在内核缓冲区中都没有可读数据,select调用进程就会被阻塞,而当任意I/O在内核缓冲区中有数据时,select调用就会返
回,而后select调用进程可以自己或者通知另外的进程再次发起读取I/O,读取内核中准备好的数据。
多路复用模型相对于非阻塞模型来说,需要2个系统调用(recvfrom和select),但是Selector的优势在于一次能够处理多个连接,
当连接很多的时候优势是很明显的,但是单个连接并不能处理的更快。多路复用模型适合高并发的服务器开发。
4、信号驱动I/O模型
信号驱动I/O模型通信示意图如下:
信号驱动模型是指进程向内核注册一个信号处理函数,然后用户进程返回不阻塞,当内核数据就绪时,返回一个信号给进程,用户进
程便在处理函数中调用I/O读取数据。实际上I/O内核拷贝到用户进程的过程还是阻塞的,这种模式并没有实现真正的阻塞,是一种伪
异步,实际中并不常用
5、异步I/O模型
异步I/O模型通信示意图如下:
用户进程发起aio_read操作后,给内核传递与read相同的描述符、缓冲区指针、缓冲区大小三个参数及文件偏移,告诉内核但整个
操作完成时如何通知我们,然后立刻就可以开始去做其他的事情。从内核的角度来讲,当它收到一个aio_read后,首先它会立刻返
回,所以不会对用户进程产生阻塞,内核会准备等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,内核会给用
户进程发送一个信号,告诉它aio_read操作完成
异步I/O的机制是:告诉内核启动某个操作,并让内核在整个操作完成通知我们,它实现了真正的异步操作,是真正的异步模型,适
合高性能高并发的应用
I/O模型的比较:
根据上述5种IO模型,前4种模型-阻塞IO、非阻塞IO、IO复用、信号驱动IO都是同步I/O模型,因为其中真正的I/O操作(recvfrom)
将阻塞进程,在内核数据copy到用户空间时都是阻塞的
注意:
Java 中的 BIO、NIO和 AIO 理解为是 Java 语言对操作系统的各种 IO 模型的封装
Java中提供的IO有关的API,在文件处理的时候,其实依赖操作系统层面的IO操作实现的
IO多路复用:
IO多路复用,就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序
进行相应的读写操作。
从流程上来看,使用select函数进行IO请求和同步阻塞模型没有太大的区别,甚至还多了添加监视socket,以及调用select函数的额
外操作,效率更差。但是,使用select以后最大的优势是用户可以在一个线程内同时处理多个socket的IO请求。用户可以注册多个
socket,然后不断地调用select读取被激活的socket,即可达到在同一个线程内同时处理多个IO请求的目的。而在同步阻塞模型中,
必须通过多线程的方式才能达到这个目的
IO多路复用方式允许单线程内处理多个IO请求,但是每个IO请求的过程还是阻塞的(在select函数上阻塞),平均时间甚至比同步阻
塞IO模型还要长。如果用户线程只注册自己感兴趣的socket或者IO请求,然后去做自己的事情,等到数据到来时再进行处理,则可以
提高CPU的利用率
由于select函数是阻塞的,因此多路IO复用模型也被称为异步阻塞IO模型。注意,这里的所说的阻塞是指select函数执行时线程被阻
塞,而不是指socket。一般在使用IO多路复用模型时,socket都是设置为NONBLOCK的,不过这并不会产生影响,因为用户发起IO
请求时,数据已经到达了,用户线程一定不会被阻塞
IO多路复用是最常使用的IO模型,但是其异步程度还不够“彻底”,因为它使用了会阻塞线程的select系统调用。因此IO多路复用只能
称为异步阻塞IO,而非真正的异步IO
展示了非阻塞IO如何让你使用一个selector区处理多个连接select、poll、epoll:
Linux支持IO多路复用的系统调用有select、poll、epoll,这些调用都是内核级别的。但select、poll、epoll本质上都是同步I/O,先
是block等待就绪的socket,再是block将数据从内核拷贝到用户内存
select、poll、epoll之间的区别,如下表:
两种I/O多路复用模式:Reactor和Proactor
在这两种模式下的事件多路分离器反馈给程序的信息是不一样的:
1.Reactor模式下说明你可以进行读写(收发)操作了
2.Proactor模式下说明已经完成读写(收发)操作了,具体内容在给定缓冲区中,可以对这些内容进行其他操作了。
Reactor关注的是I/O操作的就绪事件,而Proactor关注的是I/O操作的完成事件
一般地,I/O多路复用机制都依赖于一个事件多路分离器(Event Demultiplexer)。分离器对象可将来自事件源的I/O事件分离出来,并
分发到对应的read/write事件处理器(Event Handler)。
Reactor模式采用同步IO,而Proactor采用异步IO。
在Reactor中,事件分离器负责等待文件描述符或socket为读写操作准备就绪,然后将就绪事件传递给对应的处理器,最后由处理器
负责完成实际的读写工作。
而在Proactor模式中,处理器或者兼任处理器的事件分离器,只负责发起异步读写操作。IO操作本身由操作系统来完成。传递给操作
系统的参数需要包括用户定义的数据缓冲区地址和数据大小,操作系统才能从中得到写出操作所需数据,或写入从socket读到的数
据。事件分离器捕获IO操作完成事件,然后将事件传递给对应处理器。比如,在windows上,处理器发起一个异步IO操作,再由事
件分离器等待IOCompletion事件。典型的异步模式实现,都建立在操作系统支持异步API的基础之上,我们将这种实现称为“系统
级”异步或“真”异步,因为应用程序完全依赖操作系统执行真正的IO工作。
Reactor和Proactor模式的主要区别就是真正的读取和写入操作是有谁来完成的,Reactor中需要应用程序自己读取或者写入数据,
而Proactor模式中,应用程序不需要进行实际的读写过程,它只需要从缓存区读取或者写入即可,操作系统会读取缓存区或者写入缓
存区到真正的IO设备
–>阻塞IO模型
最传统的一种IO模型,即在读写数据过程中会发生阻塞现象。当用户线程发出 IO 请求之后,内核会去查看数据是否就绪,如果没有就绪就会等待数据就绪,而用户线程就会处于阻塞状态,用户线程交出 CPU。当数据就绪之后,内核会将数据拷贝到用户线程,并
返回结果给用户线程,用户线程才解除 block 状态。典型的阻塞 IO 模型的例子为: data = socket.read();如果数据没有就绪,就会
一直阻塞在 read 方法
–>非阻塞IO模型
当用户线程发起一个 read 操作后,并不需要等待,而是马上就得到了一个结果。 如果结果是一个error 时,它就知道数据还没有准
备好,于是它可以再次发送 read 操作。一旦内核中的数据准备好了,并且又再次收到了用户线程的请求,那么它马上就将数据拷贝
到了用户线程,然后返回。所以事实上,在非阻塞 IO 模型中,用户线程需要不断地询问内核数据是否就绪,也就说非阻塞 IO不会交
出 CPU,而会一直占用 CPU。但是对于非阻塞 IO 就有一个非常严重的问题, 在 while 循环中需要不断地去询问内核数据是否就
绪,这样会导致 CPU 占用率非常高,因此一般情况下很少使用 while 循环这种方式来读取数据
–>多路复用模型
多路复用 IO 模型是目前使用得比较多的模型。 Java NIO 实际上就是多路复用 IO。在多路复用 IO模型中,会有一个线程不断去轮询
多个socket 的状态,只有当 socket 真正有读写事件时,才真正调用实际的 IO 读写操作。因为在多路复用 IO 模型中,只需要使用一
个线程就可以管理多个socket,系统不需要建立新的进程或者线程,也不必维护这些线程和进程,并且只有在真正有socket 读写事
件进行时,才会使用IO 资源,所以它大大减少了资源占用。在 Java NIO 中,是通过 selector.select()去查询每个通道是否有到达事
件,如果没有事件,则一直阻塞在那里,因此这种方式会导致用户线程的阻塞。多路复用 IO 模式,通过一个线程就可以管理多个
socket,只有当socket 真正有读写事件发生才会占用资源来进行实际的读写操作。因此,多路复用 IO 比较适合连接数比较多的情
况。 另外多路复用 IO 为何比非阻塞 IO 模型的效率高是因为在非阻塞 IO 中,不断地询问 socket 状态时通过用户线程去进行的,而
在多路复用IO 中,轮询每个 socket 状态是内核在进行的,这个效率要比用户线程要高的多。 不过要注意的是,多路复用 IO 模型是
通过轮询的方式来检测是否有事件到达,并且对到达的事件逐一进行响应。因此对于多路复用 IO 模型来说, 一旦事件响应体很大,
那么就会导致后续的事件迟迟得不到处理,并且会影响新的事件轮询
–>信号驱动IO模型
在信号驱动 IO 模型中,当用户线程发起一个 IO 请求操作,会给对应的 socket 注册一个信号函数,然后用户线程会继续执行,当内
核数据就绪时会发送一个信号给用户线程,用户线程接收到信号之后,便在信号函数中调用 IO 读写操作来进行实际的 IO 请求操
作
–>异步IO模型
异步 IO 模型才是最理想的 IO 模型,在异步 IO 模型中,当用户线程发起 read 操作之后,立刻就可以开始去做其它的事。而另一方
面,从内核的角度,当它受到一个 asynchronous read 之后,它会立刻返回,说明 read 请求已经成功发起了,因此不会对用户线
程产生任何block。然后,内核会等待数据准备完成,然后将数据拷贝到用户线程,当这一切都完成之后,内核会给用户线程发送一
个信号,告诉它read 操作完成了。也就说用户线程完全不需要实际的整个 IO 操作是如何进行的, 只需要先发起一个请求,当接收
内核返回的成功信号时表示 IO 操作已经完成,可以直接去使用数据了。 也就说在异步 IO 模型中, IO 操作的两个阶段都不会阻塞用
户线程,这两个阶段都是由内核自动完成,然后发送一个信号告知用户线程操作已完成。用户线程中不需要再次调用 IO 函数进行具
体的读写。这点是和信号驱动模型有所不同的,在信号驱动模型中,当用户线程接收到信号表示数据已经就绪,然后需要用户线程调
用 IO 函数进行实际的读写操作;而在异步 IO 模型中,收到信号表示 IO 操作已经完成,不需要再在用户线程中调用 IO 函数进行实
际的读写操作。 注意,异步 IO 是需要操作系统的底层支持,在 Java 7 中,提供了 Asynchronous IO
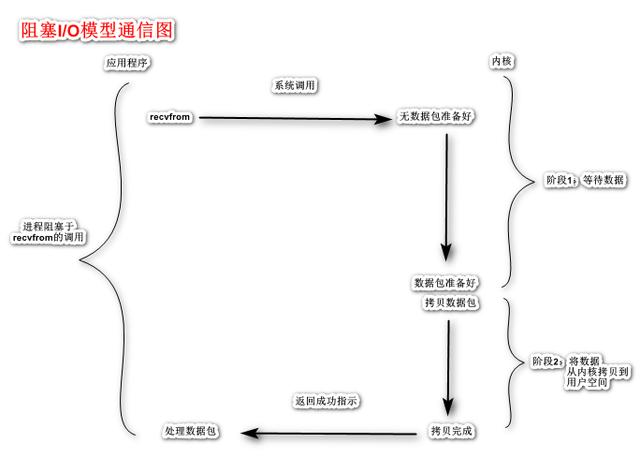
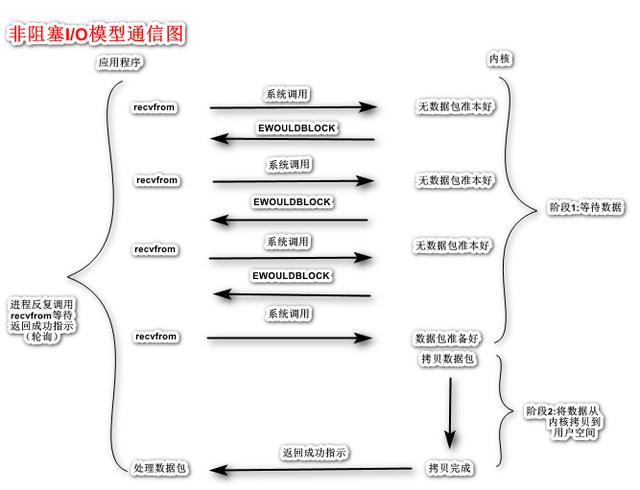
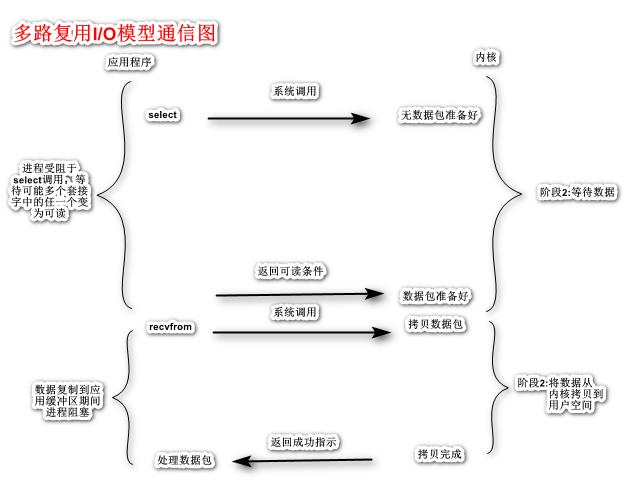

Java BIO
Java中的BIO(Blocking I/O)
同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成
Java中的BIO分为两种:
1、传统 BIO:一请求一应答
2、伪异步 IO:通过线程池固定线程的最大数量,防止资源的耗费
传统的BIO
采用 BIO 通信模型的服务端,通常由一个独立的 Acceptor 线程负责监听客户端的连接
一般通过在while(true) 循环中服务端会调用 accept() 方法等待接收客户端的连接的方式监听请求
监听一旦接收到一个连接请求,就可以建立通信套接字,在这个通信套接字上进行读写操作,此时不能再接收其他客户端连接请求,
只能等待同当前连接的客户端的操作执行完成, 不过可以通过多线程来支持多个客户端的连接
一请求一应答通信模型: 如果要让 BIO 通信模型能够同时处理多个客户端请求,就必须使用多线程(主要原因是socket.accept()、
socket.read()、socket.write() 涉及的三个主要函数都是同步阻塞的),也就是说它在接收到客户端连接请求之后为每个客户端创建
一个新的线程进行链路处理,处理完成之后,通过输出流返回应答给客户端,线程销毁
不过可以通过线程池机制改善,线程池还可以让线程的创建和回收成本相对较低。使用FixedThreadPool可以有效的控制了线程的
最大数量,保证了系统有限的资源的控制,实现了N(客户端请求数量):M(处理客户端请求的线程数量)的伪异步I/O模型(N 可以远远
大于 M)
我们再设想一下当客户端并发访问量增加后这种模型会出现什么问题?
在 Java 虚拟机中,线程是宝贵的资源,线程的创建和销毁成本很高,除此之外,线程的切换成本也是很高的。尤其在 Linux 这样的
操作系统中,线程本质上就是一个进程,创建和销毁线程都是重量级的系统函数。如果并发访问量增加会导致线程数急剧膨胀可能会
导致线程堆栈溢出、创建新线程失败等问题,最终导致进程宕机或者僵死,不能对外提供服务
伪异步 IO:
为了解决同步阻塞I/O面临的一个链路需要一个线程处理的问题,后来有人对它的线程模型进行了优化一一一后端通过一个线程池来
处理多个客户端的请求接入,形成客户端个数M:线程池最大线程数N的比例关系,其中M可以远远大于N.通过线程池可以灵活地调
配线程资源,设置线程的最大值,防止由于海量并发接入导致线程耗尽
采用线程池和任务队列可以实现一种叫做伪异步的 I/O 通信框架,它的模型图如上图所示:
当有新的客户端接入时,将客户端的 Socket 封装成一个Task(该任务实现java.lang.Runnable接口)投递到后端的线程池中进行处
理,JDK的线程池维护一个消息队列和 N 个活跃线程,对消息队列中的任务进行处理
优点: 由于线程池可以设置消息队列的大小和最大线程数,因此,它的资源占用是可控的,无论多少个客户端并发访问,都不会导
致资源的耗尽和宕机
伪异步I/O通信框架采用了线程池实现,因此避免了为每个请求都创建一个独立线程造成的线程资源耗尽问题。不过因为它的底层仍
然是同步阻塞的BIO模型,因此无法从根本上解决问题
BIO总结:
在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型
简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。但
是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的
并发量。


Java NIO
NIO概念:
NIO,有人称之为New I/O,因为它相对于之前的I/O类库是新增的,所以被称为New I/O。但是,由于之前老的 I/O 类库是阻塞
I/O,New I/O类库的目标就是要让Java支持非阻塞 I/O,所以,更多的人喜欢称之为非阻塞 I/ O(Non-block I/O)。
对NIO的非阻塞的理解:
注意,select是阻塞的,无论是通过操作系统的通知(epoll)还是不停的轮询(select,poll),这个函数是阻塞的。所以你可以放心大
胆地在一个while(true)里面调用这个函数而不用担心CPU空转
NIO采用Reactor模式,一个Reactor线程聚合一个多路复用器Selector,它可以同时注册、监听和轮询成百上千个Channel,一个IO
线程可以同时并发处理N个客户端连接,线程模型优化为1:N(N < 进程可用的最大句柄数)或者M : N (M通常为CPU核数 + 1, N
< 进程可用的最大句柄数)
JAVA NIO 不是同步非阻塞I/O吗,为什么说JAVA NIO提供了基于Selector的异步网络I/O?
java nio的io模型是同步非阻塞,这里的同步异步指的是真正io操作(数据内核态用户态的拷贝)是否需要进程参与
而说java nio提供了异步处理,这个异步应该是指编程模型上的异步。基于reactor模式的事件驱动,事件处理器的注册和处理器的执
行是异步的
AIO(Async I/O)里面会更进一步:不但等待就绪是非阻塞的,就连数据从网卡到内存的过程也是异步的。
换句话说,BIO里用户最关心“我要读”,NIO里用户最关心"我可以读了",在AIO模型里用户更需要关注的是“读完了”。
NIO一个重要的特点是:socket主要的读、写、注册和接收函数,在等待就绪阶段都是非阻塞的,真正的I/O操作是同步的(消耗
CPU但性能非常高)。
如何结合事件模型使用NIO非阻塞特性:
BIO模型,之所以需要多线程,是因为在进行I/O操作的时候,一是没有办法知道到底能不能写、能不能读,只能"傻等",即使通过各
种估算,算出来操作系统没有能力进行读写,也没法在socket.read()和socket.write()函数中返回,这两个函数无法进行有效的中
断。所以除了多开线程另起炉灶,没有好的办法利用CPU。
NIO的读写函数可以立刻返回,这就给了我们不开线程利用CPU的最好机会:如果一个连接不能读写(socket.read()返回0或者
socket.write()返回0),我们可以把这件事记下来,记录的方式通常是在Selector上注册标记位,然后切换到其它就绪的连接
(channel)继续进行读写。
我们大概可以总结出NIO是怎么解决掉线程的瓶颈并处理海量连接的:
NIO由原来的阻塞读写(占用线程)变成了单线程轮询事件,找到可以进行读写的网络描述符进行读写。除了事件的轮询是阻塞的
(没有可干的事情必须要阻塞),剩余的I/O操作都是纯CPU操作,没有必要开启多线程。
并且由于线程的节约,连接数大的时候因为线程切换带来的问题也随之解决,进而为处理海量连接提供了可能。
理解异步非阻塞I/O:
很多人喜欢将JDK1.4提供的NIO框架称为异步非阻塞I/O,但是,如果严格按照UNIX网络编程模型和JDK的实现进行区分,实际上它
只能被称为非阻塞I/O,不能叫异步非阻塞I/O。在早期的JDK1.4和1.5 update10版本之前,JDK的Selector基于select/poll模型实
现,它是基于I/O复用技术的非阻塞I/O,不是异步I/O。在JDK1.5 update10和Linux core2.6以上版本,Sun优化了Selctor的实现,
它在底层使用epoll替换了select/poll,上层的API并没有变化,可以认为是JDK NIO的一次性能优化,但是它仍旧没有改变I/O的模
型。
由JDK1.7提供的NIO2.0,新增了异步的套接字通道,它是真正的异步I/O,在异步I/O操作的时候可以传递信号变量,当操作完成之后会回调相关的方法,异步I/O也被称为AIO。
NIO类库支持非阻塞读和写操作,相比于之前的同步阻塞读和写,它是异步的,因此很多人习惯于称NIO为异步非阻塞I/O,包括很多
介绍NIO编程的书籍也沿用了这个说法。为了符合大家的习惯,我们也将NIO称为异步非阻塞I/O或者非阻塞I/O。
Java NIO的核心组成
a、通道(Channel) 和 缓冲区(Buffer)
基本上,所有的 IO 在NIO 中都从一个Channel 开始。Channel 有点像流。 数据可以从Channel读到Buffer中,也可以从Buffer 写到
Channel中。这里有个图示:
b、多路复用器(Selector)
Selector允许单线程处理多个Channel。如果你的应用打开了多个连接(通道),但每个连接的流量都很低,使用Selector就会很方
便。例如,在一个聊天服务器中。
这是在一个单线程中使用一个Selector处理3个Channel的图示:
要使用Selector,得向Selector注册Channel,然后调用它的select()方法。这个方法会一直阻塞到某个注册的通道有事件就绪。一旦
这个方法返回,线程就可以处理这些事件,事件的例子有如新连接进来,数据接收等。
总结:
a、事件驱动模型
b、避免多线程
c、单线程处理多任务
d、非阻塞I/O,I/O读写不再阻塞,而是返回0
e、基于block的传输,通常比基于流的传输更高效
f、更高级的IO函数,zero-copy
g、IO多路复用大大提高了Java网络应用的可伸缩性和实用性
IO 的各种流是阻塞的。这意味着,当一个线程调用 read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。 NIO 的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取。而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。 非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。 线程通常将非阻塞 IO 的空闲时间用于在其它通道上执行 IO 操作,所以一个单独的线程现在可以管理多个输入和输出通道(channel)。
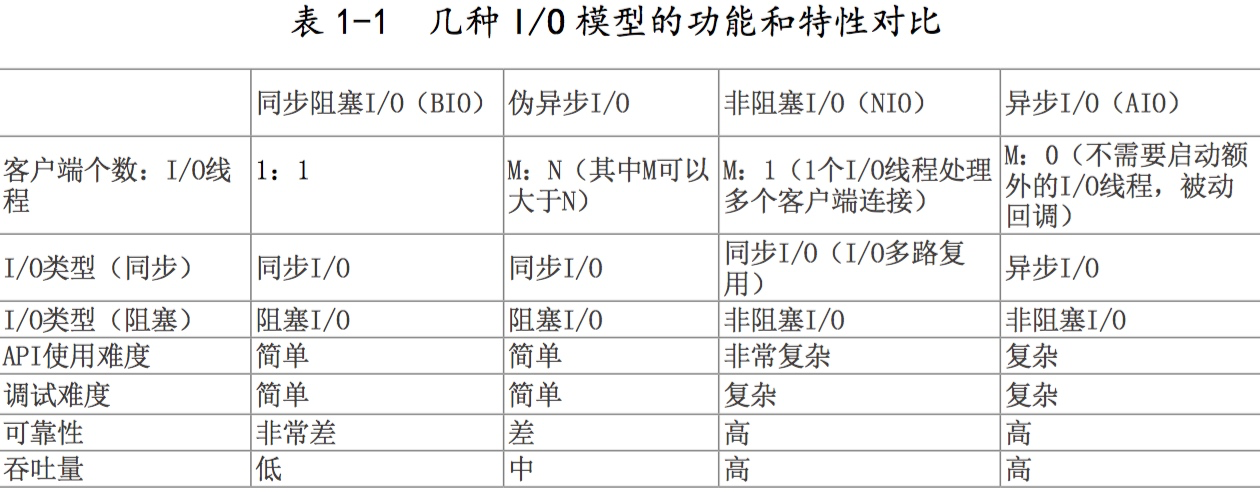
Java AIO
BIO、NIO、AIO
从编程语言层面
BIO | NIO | AIO 以Java的角度,理解如下:
- BIO,同步阻塞式IO,简单理解:一个线程处理一个连接,发起和处理IO请求都是同步的
- NIO,同步非阻塞IO,简单理解:一个线程处理多个连接,发起IO请求是非阻塞的但处理IO请求是同步的
- AIO,异步非阻塞IO,简单理解:一个有效请求一个线程,发起和处理IO请求都是异步的
BIO
在JDK1.4之前,用Java编写网络请求,都是建立一个ServerSocket,然后,客户端建立Socket时就会询问是否有线程可以处理,如果
没有,要么等待,要么被拒绝。即:一个连接,要求Server对应一个处理线程
NIO
在Java里的由来,在JDK1.4及以后版本中提供了一套API来专门操作非阻塞I/O,我们可以在java.nio包及其子包中找到相关的类和接
口。由于这套API是JDK新提供的I/O API,因此,也叫New I/O,这就是包名nio的由来。这套API由三个主要的部分组成:缓冲区
(Buffers)、通道(Channels)和非阻塞I/O的核心类组成。在理解NIO的时候,需要区分,说的是New I/O还是非阻塞IO,New I/O
是Java的包,NIO是非阻塞IO概念。这里讲的是后面一种
NIO本身是基于事件驱动思想来完成的,其主要想解决的是BIO的大并发问题: 在使用同步I/O的网络应用中,如果要同时处理多个
客户端请求,或是在客户端要同时和多个服务器进行通讯,就必须使用多线程来处理。也就是说,将每一个客户端请求分配给一个线
程来单独处理。这样做虽然可以达到我们的要求,但同时又会带来另外一个问题。由于每创建一个线程,就要为这个线程分配一定的
内存空间(也叫工作存储器),而且操作系统本身也对线程的总数有一定的限制。如果客户端的请求过多,服务端程序可能会因为不
堪重负而拒绝客户端的请求,甚至服务器可能会因此而瘫痪
NIO基于Reactor,当socket有流可读或可写入socket时,操作系统会相应的通知引用程序进行处理,应用再将流读取到缓冲区或写
入操作系统
也就是说,这个时候,已经不是一个连接就要对应一个处理线程了,而是有效的请求,对应一个线程,当连接没有数据时,是没有工
作线程来处理的
BIO和NIO的区别:
NIO即New IO,这个库是在JDK1.4中才引入的。NIO和BIO有相同的作用和目的,但实现方式不同,NIO 主要用到的是块,所以NIO
的效率要比BIO高很多。在Java API中提供了两套NIO,一套是针对标准输入输出NIO,另一套就是网络编程NIO。
NIO 主要有三大核心部分: Channel(通道), Buffer(缓冲区), Selector。
传统BIO基于字节流和字符流进行操作,而NIO基于Channel和Buffer(缓冲区)进行操作,数据总是从通道读取到缓冲区中,或者从缓
冲区写入到通道中。Selector(选择区)用于监听多个通道的事件(比如:连接打开,数据到达)。因此,单个线程可以监听多个数据
通道。 NIO 和传统 IO 之间第一个最大的区别是, BIO 是面向流的, NIO 是面向缓冲区的。
NIO:是同步的非阻塞的I/O,引入了缓存区和多路转换(selector)。
缓存区:当数据到达时,如果当前套接字被其他线程占用,会将数据预先写到缓存区,由缓存区交给线程。因此线程无需阻塞等待的
I/O。BIO则必须等待IO使用者释放后再使用
多路复用器:一个线程就可以处理多个客户端的IO请求(需要不停的询问通信套接字是否就绪)
缺点:需要不停的询问I/O是否就绪,引起不必要的CPU资源的浪费
本质:NIO在socket读、写、注册和接收函数,在等待就绪阶段都是非阻塞的,真正的IO操作是同步阻塞的(消耗cpu,单性能非常
高),而IO在等待时是阻塞的
AIO
与NIO不同,操作系统负责处理内核区/用户区的内存数据迁移和真正的IO操作,应用程序只须直接调用API的read或write方法即可。这两种方法均为异步的,对于读操作而言,当有流可读取时,操作系统会将可读的流传入read方法的缓冲区,并通知应用程序;对于写操作而言,当操作系统将write方法传递的流写入完毕时,操作系统主动通知应用程序。
即可以理解为,read/write方法都是异步的,完成后会主动调用回调函数。
在JDK1.7中,这部分内容被称作NIO.2,主要在java.nio.channels包下增加了下面四个异步通道:
- AsynchronousSocketChannel
- AsynchronousServerSocketChannel
- AsynchronousFileChannel
- AsynchronousDatagramChannel
其中的read/write方法,会返回一个带回调函数的对象,当执行完读取/写入操作后,直接调用回调函数。
IO流类体系
IO流分类:
按类型:字节流、字符流
按功能:节点流,如文件流
处理流,如缓冲流
按流向:输入流、输出流
a、InputStream/Reader:所有的输入流的基类,前者是字节输入流,后者是字符输入流
b、OutputStream/Writer:所有输出流的基类,前者是字节输出流,后者是字符输出流
1、InputStream/OutputStream :
字节流的抽象类
2、Reader/Writer :
字符流的抽象类
3、FileInputStream/FileOutputStream :
节点流,以字节为单位直接操作“文件”
4、ByteArrayInputStream/ByteArrayOutputStream :
节点流,以字节为单位直接操作“字节数组对象”
5、DataInputStream/DataOutputStream:
数据流,可操纵数据类型
6、ObjectInputStream/ObjectOutputStream :
处理流,以字节为单位直接操作“对象”
7、DateInputStream/DateOutputStream :
处理流,以字节为单位直接操作“基本数据类型与字符串类型”
8、FileReader/FileWriter :
节点流:以字符为单位直接操作“文本文件”,注意:只能读写文本文件
9、BufferedReader/BufferedWriter :
处理流:将Reader/Writer对象进行包装,增加缓存功能,提高读写效率
10、BufferedInputStream/BufferedOutputStream :(缓冲字节流)
处理流,将InputStream/OutputStream对象进行包装,增加缓存功能,提高读写效率
11、InputStreamReader/OutputStreamWriter :
处理流:将字节流对象转化成字符流对象
12、PrintWriter :
处理流:将OutputStream进行包装,可以方便的输出字符,更加灵活
Buffer、Channel、Selector
Buffer缓冲区:
Buffer,故名思意, 缓冲区,实际上是一个容器,是一个连续数组。 Channel 提供从文件、网络读取数据的渠道,但是读取或写入
的数据都必须经由 Buffer
客户端发送数据时,必须先将数据存入 Buffer 中,然后将Buffer 中的内容写入通道。服务端这边接收数据必须通过 Channel 将数据
读入到 Buffer 中,然后再从 Buffer 中取出数据来处理。在 NIO 中, Buffer 是一个顶层父类,它是一个抽象类,常用的 Buffer 的子
类有:ByteBuffer、 IntBuffer、 CharBuffer、 LongBuffer、DoubleBuffer、 FloatBuffer、ShortBuffer
Java IO 面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中
的数据。如果需要前后移动从流中读取的数据, 需要先将它缓存到一个缓冲区。 NIO 的缓冲导向方法不同。数据读取到一个它稍后
处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所有您需要
处理的数据。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据
Channel通道:
Channel和IO中的Stream(流)是差不多一个等级的。只不过Stream是单向的,譬如:InputStream,OutputStream,而Channel是双
向的,既可以用来进行读操作,又可以用来进行写操作。NIO 中的 Channel 的主要实现有:
1、FileChannel
2、DatagramChannel
3、SocketChannel
4、ServerSocketChannel
这里看名字就可以猜出个所以然来:分别可以对应文件 IO、 UDP 和 TCP(Server 和 Client)
Selector多路复用器
Selector类是NIO的核心类,Selector 能够检测多个注册的通道上是否有事件发生,如果有事件发生,便获取事件然后针对每个事件
进行相应的响应处理。这样一来,只是用一个单线程就可以管理多个通道,也就是管理多个连接。这样使得只有在连接真正有读写事
件发生时,才会调用函数来进行读写,就大大地减少了系统开销,并且不必为每个连接都创建一个线程,不用去维护多个线程,并且
避免了多线程之间的上下文切换导致的开销
网络编程面试题
Java反射面试题
反射概念与作用
反射概念:
反射机制是在运行时,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法。
在java中,只要给定类的名字,就可以通过反射机制来获得类的所有信息。这种动态获取的信息以及动态调用对象的方法的功能称为
Java语言的反射机制
反射作用:
反射就是把java类中的各种成分映射成一个个的 Java对象。例如:一个类有:成员变量、方法、构造方法、包等等信息,利用反射技
术可以对一个类进行解剖,把个个组成部分映射成一个个对象
Class类
某种意义上来说,java有两种对象:实例对象和Class对象。每个类的运行时的类型信息就是用Class对象表示的。它包含了与类有关
的信息。其实我们的实例对象就通过Class对象来创建的。Java使用Class对象执行其RTTI(运行时类型识别,Run-Time Type
Identification),多态是基于RTTI实现的
每一个类都有一个Class对象,每当编译一个新类就产生一个Class对象,基本类型 (boolean, byte, char, short, int, long, float, and
double)有Class对象,数组有Class对象,就连关键字void也有Class对象(void.class)
Class类没有公共的构造方法,Class对象是在类加载的时候由Java虚拟机以及通过调用类加载器中的 defineClass 方法自动构造的,
因此不能显式地声明一个Class对象
一个类被加载到内存并供我们使用需要经历如下三个阶段:
a、加载,这是由类加载器(ClassLoader)执行的。通过一个类的全限定名来获取其定义的二进制字节流(Class字节码),将这个
字节流所代表的静态存储结构转化为方法去的运行时数据接口,根据字节码在java堆中生成一个代表这个类的java.lang.Class对象。
b、链接。在链接阶段将验证Class文件中的字节流包含的信息是否符合当前虚拟机的要求,为静态域分配存储空间并设置类变量的初
始值(默认的零值),并且如果必需的话,将常量池中的符号引用转化为直接引用
c、初始化。到了此阶段,才真正开始执行类中定义的java程序代码。用于执行该类的静态初始器和静态初始块,如果该类有父类的
话,则优先对其父类进行初始化。
所有的类都是在对其第一次使用时,动态加载到JVM中的(懒加载)。当程序创建第一个对类的静态成员的引用时,就会加载这个
类。使用new创建类对象的时候也会被当作对类的静态成员的引用。因此java程序程序在它开始运行之前并非被完全加载,其各个类
都是在必需时才加载的。这一点与许多传统语言都不同。动态加载使能的行为,在诸如C++这样的静态加载语言中是很难或者根本不
可能复制的。
在类加载阶段,类加载器首先检查这个类的Class对象是否已经被加载。如果尚未加载,默认的类加载器就会根据类的全限定名查
找.class文件。在这个类的字节码被加载时,它们会接受验证,以确保其没有被破坏,并且不包含不良java代码。一旦某个类的Class
对象被载入内存,我们就可以它来创建这个类的所有对象
获取Class对象方式:
1)Class.forName(“类全限定名”)
2)类名.class
3)对象名.getClass()
4)基本类型的包装类,可以调用包装类的Type属性来获得该包装类的Class对象
实现Java反射所需类
1)Class:表示正在运行的Java应用程序中的类和接口
注意: 所有获取对象的信息都需要Class类来实现
2)Field:提供有关类和接口的属性信息,以及对它的动态访问权限
3)Constructor:提供关于类的单个构造方法的信息以及它的访问权限
4)Method:提供类或接口中某个方法的信息
反射机制的优缺点
优点:
1)能够运行时动态获取类的实例,提高灵活性
2)与动态编译结合
Class.forName(‘com.mysql.jdbc.Driver.class’);//加载MySQL的驱动类
缺点:
1)使用反射性能较低,需要解析字节码,将内存中的对象进行解析
解决方案:
a、通过setAccessible(true)关闭JDK的安全检查来提升反射速度
b、多次创建一个类的实例时,有缓存会快很多
c、ReflflectASM工具类,通过字节码生成的方式加快反射速度
e、相对不安全,破坏了封装性(因为通过反射可以获得私有方法和属性)
利用反射动态创建对象实例
Class 对象的 newInstance()
a、使用 Class 对象的 newInstance()方法来创建该 Class 对象对应类的实例,但是这种方法要求该Class对象对应的类有默认的空构
造器。
b、先使用 Class 对象获取指定的 Constructor 对象,再调用 Constructor 对象的 newInstance()方法来创建 Class 对象对应类的实
例,通过这种方法可以选定构造方法创建实例。
Java序列化面试题
什么是java序列化,如何实现java序列化?
序列化概念:
序列化就是一种用来处理对象流的机制,所谓对象流也就是将对象的内容进行流化。可以对流化后的对象进行读写操作,也可将流化
后的对象传输于网络之间。序列化是为了解决在对对象流进行读写操作时所引发的问题。
序列化的实现:
将需要被序列化的类实现Serializable接口,该接口没有需要实现的方法,Serializable只是为了标注该对象是可被序列化的,然后使
用一个输出流(如:FileOutputStream)来构造一个ObjectOutputStream(对象流)对象,接着,使用ObjectOutputStream对象的
writeObject(Objectobj)方法就可以将参数为obj的对象写出(即保存其状态),要恢复的话则用输入流
保存(持久化)对象及其状态到内存或者磁盘
Java 平台允许我们在内存中创建可复用的 Java 对象,但一般情况下,只有当 JVM 处于运行时,这些对象才可能存在,即,这些对象
的生命周期不会比 JVM 的生命周期更长。 但在现实应用中,就可能要求在JVM停止运行之后能够保存(持久化)指定的对象,并在将来
重新读取被保存的对象。Java 对象序列化就能够帮助我们实现该功能
序列化对象以字节数组保持–静态成员不保存
使用 Java 对象序列化, 在保存对象时,会把其状态保存为一组字节,在未来, 再将这些字节组装成对象。必须注意地是, 对象序
列化保存的是对象的”状态”,即它的成员变量。由此可知,对象序列化不会关注类中的静态变量。
序列化用户远程对象传输
除了在持久化对象时会用到对象序列化之外,当使用 RMI(远程方法调用),或在网络中传递对象时,都会用到对象序列化。 Java序列
化API为处理对象序列化提供了一个标准机制,该API简单易用。
Serializable 实现序列化
在 Java 中, 只要一个类实现了 java.io.Serializable 接口,那么它就可以被序列化。ObjectOutputStream 和 ObjectInputStream 对
对象进行序列化及反序列化通过 ObjectOutputStream 和 ObjectInputStream 对对象进行序列化及反序列化。想将父类对象也序列
化,就需要让父类也实现 Serializable 接口
序列化 ID
虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,一个非常重要的一点是两个类的序列化 ID 是否一致(就是
privatestatic final long serialVersionUID
Transient 关键字阻止该变量被序列化到文件中
1、在变量声明前加上 Transient 关键字,可以阻止该变量被序列化到文件中,在被反序列化后, transient 变量的值被设为初始
值,如 int 型的是 0,对象型的是 null。
2、服务器端给客户端发送序列化对象数据,对象中有一些数据是敏感的,比如密码字符串等,希望对该密码字段在序列化时,进行
加密,而客户端如果拥有解密的密钥,只有在客户端进行反序列化时,才可以对密码进行读取,这样可以一定程度保证序列化对
象的数据安全。
Java注解面试题
注解概念
Annotation(注解)是 Java 提供的一种对元程序中元素关联信息和元数据(metadata)的途径和方法。 Annatation(注解)是一个接
口,程序可以通过反射来获取指定程序中元素的 Annotation对象,然后通过该 Annotation 对象来获取注解中的元数据信息。
4种标准元注解
元注解的作用是负责注解其他注解。 Java5.0 定义了 4 个标准的 meta-annotation 类型,它们被用来提供对其它 annotation 类型作
说明。
@Target:修饰的对象范围
@Target说明了Annotation所修饰的对象范围: Annotation可被用于 packages、types(类、接口、枚举、Annotation 类型)、类
型成员(方法、构造方法、成员变量、枚举值)、方法参数和本地变量(如循环变量、catch 参数)。在 Annotation 类型的声明中
使用了 target可更加明晰其修饰的目标
@Retention:定义被保留的时间长短
Retention 定义了该 Annotation 被保留的时间长短:表示需要在什么级别保存注解信息,用于描述注解的生命周期(即:被描述的
注解在什么范围内有效),取值(RetentionPoicy)由:
a、SOURCE:在源文件中有效(即源文件保留)
b、CLASS:在 class 文件中有效(即 class 保留)
c、RUNTIME:在运行时有效(即运行时保留)
@Documented:描述-javadoc
@ Documented 用于描述其它类型的 annotation 应该被作为被标注的程序成员的公共 API,因此可以被例如 javadoc 此类的工具文
档化。
@Inherited:阐述了某个被标注的类型是被继承的
@Inherited 元注解是一个标记注解,,阐述了某个被标注的类型是被继承的。如果一个使用了@Inherited 修饰的 annotation 类型
被用于一个 class,则这个 annotation 将被用于该class 的子类。
JAVA 并发知识库
并发与并行
并发:一个处理器同时处理多个任务
并行:多个处理器或者是多核的处理器同时处理多个不同的任务
前者是逻辑上的同时发生(simultaneous),而后者是物理上的同时发生
来个比喻:并发和并行的区别就是一个人同时吃三个馒头和三个人同时吃三个馒头
进程与线程
进程:
一个在内存中运行的应用程序。每个进程都有自己独立的一块内存空间,一个进程可以有多个线程,比如在Windows系统中,一个
运行的xx.exe就是一个进程
线程:
进程中的一个执行任务(控制单元),负责当前进程中程序的执行。一个进程至少有一个线程,一个进程可以运行多个线程,多个线
程可共享数据。
与进程不同的是同类的多个线程共享进程的堆和方法区资源,但每个线程有自己的程序计数器、虚拟机栈和本地方法栈,所以系统在
产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。
区别:
a、根本区别:进程是操作系统资源分配的基本单位,而线程是处理器任务调度和执行的基本单位
b、资源开销:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进
程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小。
c、包含关系:如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线(线程)共同完成的;线程是进程的一部分,所
以线程也被称为轻权进程或者轻量级进程。
d、内存分配:同一进程的线程共享本进程的地址空间和资源,而进程之间的地址空间和资源是相互独立的
e、影响关系:一个进程崩溃后,在保护模式下不会对其他进程产生影响,但是一个线程崩溃整个进程都死掉。所以多进程要比多线
程健壮。
f、执行过程:每个独立的进程有程序运行的入口、顺序执行序列和程序出口。但是线程不能独立执行,必须依存在应用程序中,由
应用程序提供多个线程执行控制,两者均可并发执行
JVM角度的线程和进程:
一个进程中可以有多个线程,多个线程共享进程的堆和方法区 (JDK1.8 之后的元空间)资源,但是每个线程有自己的程序计数器、虚
拟机栈和本地方法栈
程序计数器为什么是线程私有:
程序计数器主要有下面两个作用:
1、字节码解释器通过改变程序计数器来依次读取指令,从而实现代码的流程控制,如:顺序执行、选择、循环、异常处理。
2、在多线程的情况下,程序计数器用于记录当前线程执行的位置,从而当线程被切换回来的时候能够知道该线程上次运行位置
程序计数器私有主要是为了线程切换后能恢复到正确的执行位置
虚拟机栈和本地方法栈为什么是线程私有:
虚拟机栈:每个 Java 方法在执行的同时会创建一个栈帧用于存储局部变量表、操作数栈、常量池引用等信息。从方法调用直至执行
完成的过程,就对应着一个栈帧在 Java 虚拟机栈中入栈和出栈的过程
本地方法栈:和虚拟机栈所发挥的作用非常相似,区别是: 虚拟机栈为虚拟机执行 Java 方法 (也就是字节码)服务,而本地方法栈
则为虚拟机使用到的 Native 方法服务。 在 HotSpot 虚拟机中和 Java 虚拟机栈合二为一
所以,为了保证线程中的局部变量不被别的线程访问到,虚拟机栈和本地方法栈是线程私有的
堆和方法区:
堆和方法区是所有线程共享的资源,其中堆是进程中最大的一块内存,主要用于存放新创建的对象 (所有对象都在这里分配内存),方
法区主要用于存放已被加载的类信息、常量、静态变量、即时编译器编译后的代码等数据

实现线程三种方式
继承Thread类
实现Runnable接口
实现Callable接口通过FutureTask包装器来创建Thread线程
Callable 接口类似于 Runnable,从名字就可以看出来了,但是 Runnable 不会返回结果,并且无法抛出返回结果的异常,而
Callable 功能更强大一些,被线程执行后,可以返回值,这个返回值可以被 Future 拿到,也就是说,Future 可以拿到异步执行任务
的返回值。可以认为是带有回调的 Runnable。
Future 接口表示异步任务,是还没有完成的任务给出的未来结果。所以说 Callable用于产生结果,Future 用于获取结果。
synchronized和Lock的区别?
1、synchronized是Java关键字,是内置语言实现;而Lock是一个接口
2、synchronized可以给类、方法、代码块加锁;而Lock只能给代码块加锁
3、synchronized不需要手动获得和释放锁,发生异常会自动释放锁;而Lock需要开发者手动加锁和释放锁
线程生命周期
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-B746fTSM-1653308049336)(C:\Users\纵横\AppData\Roaming\Typora\typora-user-images\image-20210825100427536.png)]新生状态:
用new关键字建立一个线程对象后,该线程对象就处于新生状态。
处于新生状态的线程有自己的内存空间,通过调用start进入就绪状态
就绪状态:
处于就绪状态线程具备了运行条件,但还没分配到CPU,处于线程就绪队列,等待系统为其分配CPU
当系统选定一个等待执行的线程后,它就会从就绪状态进入执行状态,该动作称之为“cpu调度”。
运行状态:
在运行状态的线程执行自己的run方法中代码,直到等待某资源而阻塞或完成任务而死亡。
如果在给定时间片内没执行结束,就会被系统给换下来回到等待执行状态。
阻塞状态:
处于运行状态的线程在某些情况下,如执行了sleep(睡眠)方法,或等待I/O设备等资源,将让出CPU并暂时停止自己的运行,进入
阻塞状态。
在阻塞状态的线程不能进入就绪队列。只有当引起阻塞的原因消除时,如睡眠时间已到,或等待的I/O设备空闲下来,线程便转入就
绪状态,重新到就绪队列中排队等待,被系统选中后从原来停止的位置开始继续运行。
阻塞状态是指线程因为某种原因放弃了 cpu 使用权,也即让出了 cpu timeslice,暂时停止运行。直到线程进入可运行(runnable)状
态,才有机会再次获得 cpu timeslice 转到运行(running)状态。阻塞的情况分三种:
a、等待阻塞(o.wait->等待对列)
运行(running)的线程执行 o.wait()方法, JVM 会把该线程放入等待队列(waitting queue)中
b、同步阻塞(lock->锁池)
运行(running)的线程在获取对象的同步锁时,若该同步锁被别的线程占用,则 JVM 会把该线程放入锁池(lock pool)中
c、其他阻塞(sleep/join)
运行(running)的线程执行Thread.sleep(long ms)或 t.join()方法,或者发出了I/O请求时,JVM会把该线程置为阻塞状态。当sleep()状
态超时、join()等待线程终止或者超时、或者 I/O处理完毕时,线程重新转入可运行(runnable)状态
死亡状态:
死亡状态是线程生命周期中最后一个阶段。线程死亡原因有三个。一个是正常运行的线程完成了它的全部工作;另一个是线程被强制
性地终止,如通过执行stop方法来终止一个线程[不推荐使用】,三是线程抛出未捕获的异常
Interrupt 方法结束线程 :
A、线程处于阻塞状态
如使用了 sleep,同步锁的 wait,socket 中的 receiver,accept 等方法时,会使线程处于阻塞状态。当调用线程的interrupt()方法时,会
抛出 InterruptException 异常。阻塞中的那个方法抛出这个异常,通过代码捕获该异常,然后 break 跳出循环状态,从而让我们有
机会结束这个线程的执行。 通常很多人认为只要调用 interrupt 方法线程就会结束,实际上是错的, 一定要先捕获
InterruptedException 异常之后通过 break 来跳出循环,才能正常结束 run 方法
B、线程未处于阻塞状态
使用 isInterrupted()判断线程的中断标志来退出循环。当使用interrupt()方法时,中断标志就会置 true,和使用自定义的标志来控制
循环是一样的道理
4 种线程池
线程是稀缺资源,它的创建与销毁是一个相对偏重且耗资源的操作,而Java线程依赖于内核线程,创建线程需要进行操作系统状态切
换。为避免资源过度消耗需要设法重用线程执行多个任务。线程池就是一个线程缓存,负责对线程进行统一分配、调优与监控。(数
据库连接池也是一样的道理)
线程池优势?
1、重用存在的线程,减少线程创建、消亡的开销,提高性能、提高响应速度
2、当任务到达时,任务可以不需要等到线程创建就能立即执行
3、提高线程的可管理性,可统一分配,调优和监控
Java里面线程池的顶级接口是Executor,但是严格意义上讲Executor并不是一个线程池,而只是一个执行线程的工具。真正的线程池
接口是 ExecutorService
1、new CachedThreadPool
创建一个可根据需要创建新线程的线程池,但是在以前构造的线程可用时将重用它们。对于执行很多短期异步任务的程序而言,这些
线程池通常可提高程序性能。 调用 execute 将重用以前构造的线程(如果线程可用)。如果现有线程没有可用的,则创建一个新线
程并添加到池中。终止并从缓存中移除那些已有 60 秒钟未被使用的线程。 因此,长时间保持空闲的线程池不会使用任何资源。
2、new FixedThreadPool
创建一个可重用固定线程数的线程池,以共享的无界队列方式来运行这些线程。在任意点,在大多数 Threads 线程会处于处理任务
的活动状态。如果在所有线程处于活动状态时提交附加任务,则在有可用线程之前,附加任务将在队列中等待。如果在关闭前的执行
期间由于失败而导致任何线程终止,那么一个新线程将代替它执行后续的任务(如果需要)。在某个线程被显式地关闭之前,池中的
线程将一直存在。
3、new ScheduledThreadPool
创建一个线程池,它可安排在给定延迟后运行命令或者定期地执行。
4、new SingleThreadExecutor
Executors.newSingleThreadExecutor()返回一个线程池(这个线程池只有一个线程) ,这个线程池可以在线程死后(或发生异常时)
重新启动一个线程来替代原来的线程继续执行下去
线程池执行原理:
1、如果线程池中的线程数量少于corePoolSize,就创建新的核心线程来执行新添加的任务
2、如果线程池中的线程数量大于等于corePoolSize,但队列workQueue未满,则将新添加的任务放到队列workQueue中
3、如果线程池中的线程数量大于等于corePoolSize,且队列workQueue已满,但线程池中的线程数量小于maximumPoolSize,则
会创建新的非核心线程来处理被添加的任务
4、如果线程池中的线程数量等于了maximumPoolSize,就用RejectedExecutionHandler来执行拒绝策略。会抛出异常,一般的拒
绝策略是RejectedExecutionException
线程池刚创建时,里面没有一个线程。任务队列是作为参数传进来的。不过,就算队列里面有任务,线程池也不会马上执行它们。
1、当调用 execute() 方法添加一个任务时,线程池会做如下判断:
2、
a) 如果正在运行的线程数量小于 corePoolSize,那么马上创建线程运行这个任务;
b) 如果正在运行的线程数量大于或等于 corePoolSize,那么将这个任务放入队列;
c) 如果这时候队列满了,而且正在运行的线程数量小于 maximumPoolSize,那么还是要创建非核心线程立刻运行这个任务;
d) 如果队列满了,而且正在运行的线程数量大于或等于 maximumPoolSize,那么线程池会抛出异常 RejectExecutionException。
3、 当一个线程完成任务时,它会从队列中取下一个任务来执行。
4、当一个线程无事可做,超过一定的时间(keepAliveTime)时,线程池会判断,如果当前运行的线程数大于 corePoolSize,那么
这个线程就被停掉。所以线程池的所有任务完成后,它最终会收缩到 corePoolSize 的大小。
线程池的五种状态:
和一个正常的线程的生命周期区别开,这个是线程池里线程的状态
1、Running,能接受新任务以及处理已添加的任务
2、Shutdown,不接受新任务,可以处理已经添加的任务,也就是不能再调用execute或者submit了
3、Stop,不接受新任务,不处理已经添加的任务,并且中断正在处理的任务
4、Tidying,所有的任务已经终止,CTL记录的任务数量为0,CTL负责记录线程池的运行状态与活动线程数量
5、Terminated,线程池彻底终止,则线程池转变为terminated的状态
如图所示,从running状态转换为 shutdown,调用 shutdown()方法;如果调用shutdownNow()方法,就直接会变成stop。
terminated()是钩子函数,默认是什么也不做的,我们可以重写,然后决定结束之前要做一些别的处理逻辑。这个钩子函数,就是模
板模式的方法。
Executors工具类的不同方法按照我们的需求创建了不同的线程池,来满足业务的需求。
Executor接口对象能执行我们的线程任务。
ExecutorService接口继承了 Executor 接口并进行了扩展,提供了更多的方法我们能获得任务执行的状态并且可以获取任务的返回
值。
使用 ThreadPoolExecutor 可以创建自定义线程池。
Future 表示异步计算的结果,他提供了检查计算是否完成的方法,以等待计算的完成,并可以使用 get()方法获取计算的结果。


线程池拒绝策略
CallerRunsPolicy:调用者运行策略
这种策略不会抛弃任务,也不抛出异常,而是将某些任务回退给调用者,从而降低新任务的流量。
AbortPolicy:终止策略
抛异常。前面已经试过了,这个是默认的拒绝策略。
DiscardPolicy:丢弃任务
可以看到,源码里就是是什么也不做。如果场景中允许任务丢失,这个是最好的策略。
DiscardOldestPolicy:抛弃队列中等待最久的任务
抛弃队列中等待最久的任务,然后把当前的任务加入队列中,尝试再次提交当前任务。
源码里也就是利用队列操作,进行一次出队操作,然后重新调用 execute 方法。
线程池中的线程已经用完了,无法继续为新任务服务,同时,等待队列也已经排满了,再也塞不下新任务了。这时候我们就需要拒绝
策略机制合理的处理这个问题。
JDK 内置的拒绝策略如下:
1、AbortPolicy :直接抛出异常,阻止系统正常运行
2、CallerRunsPolicy :只要线程池未关闭,该策略直接在调用者线程中,运行当前被丢弃的任务。显然这样做不会真的丢弃任务,
但是,任务提交线程的性能极有可能会急剧下降
3、DiscardOldestPolicy :丢弃最老的一个请求,也就是即将被执行的一个任务,并尝试再次提交当前任务
4、DiscardPolicy :该策略默默地丢弃无法处理的任务,不予任何处理。如果允许任务丢失,这是最好的一种方案
5、以上内置拒绝策略均实现了 RejectedExecutionHandler 接口,若以上策略仍无法满足实际需要,完全可以自己扩展
RejectedExecutionHandler 接口
阻塞队列
线程池里的 BlockingQueue,阻塞队列,事实上在消费者生产者问题里的管程法实现,我们的策略也是类似阻塞队列的,用它来做
一个缓存池的作用。
阻塞队列:任意时刻,不管并发有多高,永远保证只有一个线程能够进行队列的入队或出队操作。也就意味着他是能够保证线程安全
的。
另外,阻塞队列分为有界和无界队列,理论上来说一个是队列的size有固定,另一个是无界的。对于有界队列来说,如果队列存满,
只能出队了,入队操作就只能阻塞。
在 juc 包里,阻塞队列的实现有很多:
1、ArrayBlockingQueue:有界阻塞队列
用数组实现的有界阻塞队列。此队列按照先进先出(FIFO)的原则对元素进行排序。 默认情况下不保证访问者公平的访问队列,所
谓公平访问队列是指阻塞的所有生产者线程或消费者线程,当队列可用时,可以按照阻塞的先后顺序访问队列,即先阻塞的生产者线
程,可以先往队列里插入元素,先阻塞的消费者线程,可以先从队列里获取元素。通常情况下为了保证公平性会降低吞吐量。我们可
以使用以下代码创建一个公平的阻塞队列
2、LinkedBlockingQueue:链表结构(大小默认值为Integer.MAX_VALUE)的阻塞队列
基于链表的阻塞队列,同 ArrayListBlockingQueue 类似,此队列按照先进先出(FIFO)的原则对元素进行排序。而
LinkedBlockingQueue之所以能够高效的处理并发数据,还因为其对于生产者端和消费者端分别采用了独立的锁来控制数据同步,
这也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。
LinkedBlockingQueue 会默认一个类似无限大小的容量(Integer.MAX_VALUE)
3、PriorityBlockingQueue:支持优先级排序的无界阻塞队列
是一个支持优先级的无界队列。默认情况下元素采取自然顺序升序排列。 可以自定义实现compareTo()方法来指定元素进行排序规
则,或者初始化 PriorityBlockingQueue 时,指定构造参数 Comparator 来对元素进行排序。需要注意的是不能保证同优先级元素
的顺序。
4、DelayQueue:使用优先级队列实现的延迟无界阻塞队列
是一个支持延时获取元素的无界阻塞队列。队列使用 PriorityQueue 来实现。队列中的元素必须实现 Delayed 接口,在创建元素时
可以指定多久才能从队列中获取当前元素。只有在延迟期满时才能从队列中提取元素。我们可以将 DelayQueue 运用在以下应用场
景:
缓存系统的设计:可以用 DelayQueue 保存缓存元素的有效期,使用一个线程循环查询DelayQueue,一旦能从 DelayQueue 中获
取元素时,表示缓存有效期到了。
定时任务调度:使用DelayQueue保存当天将会执行的任务和执行时间,一旦从DelayQueue中获取到任务就开始执行,从比如
TimerQueue就是使用 DelayQueue实现的
5、SynchronousQueue:不存储元素的阻塞队列,相当于只有一个元素
是一个不存储元素的阻塞队列。每一个 put 操作必须等待一个 take 操作,否则不能继续添加元素。SynchronousQueue 可以看成是
一个传球手,负责把生产者线程处理的数据直接传递给消费者线程。队列本身并不存储任何元素,非常适合于传递性场景,比如在一
个线程中使用的数据,传递给另 外 一 个 线 程 使 用 , SynchronousQueue 的 吞 吐 量 高 于 LinkedBlockingQueue 和
ArrayBlockingQueue。
6、LinkedTransferQueue:链表组成的无界阻塞队列
是一个由链表结构组成的无界阻塞TransferQueue队列。相对于其他阻塞队列,LinkedTransferQueue多了tryTransfer和transfer方
法。
transfer方法:如果当前有消费者正在等待接收元素(消费者使用 take()方法或带时间限制的poll()方法时),transfer方法可以把生
产者传入的元素立刻 transfer(传输)给消费者。如果没有消费者在等待接收元素,transfer方法会将元素存放在队列的tail节点,并
等到该元素被消费者消费了才返回。
tryTransfer方法。则是用来试探下生产者传入的元素是否能直接传给消费者。如果没有消费者等待接收元素,则返回 false。和
transfer 方法的区别是 tryTransfer 方法无论消费者是否接收,方法立即返回。而 transfer 方法是必须等到消费者消费了才返回。对
于带有时间限制的 tryTransfer(E e, long timeout, TimeUnit unit)方法,则是试图把生产者传入的元素直接传给消费者,但是如果没
有消费者消费该元素则等待指定的时间再返回,如果超时还没消费元素,则返回 false,如果在超时时间内消费了元素,则返回
true。
7、LinkedBlockingDeque:链表组成的双向阻塞队列
是一个由链表结构组成的双向阻塞队列。所谓双向队列指的你可以从队列的两端插入和移出元素。双端队列因为多了一个操作队列的
入口,在多线程同时入队时,也就减少了一半的竞争。相比其他的阻塞队列, LinkedBlockingDeque 多了 addFirst, addLast,
offerFirst, offerLast,peekFirst, peekLast 等方法,以 First 单词结尾的方法,表示插入,获取(peek)或移除双端队列的第一
个元素。以 Last 单词结尾的方法,表示插入,获取或移除双端队列的最后一个元素。另外插入方法 add 等同于 addLast,移除方法
remove 等效于 removeFirst。但是 take 方法却等同于 takeFirst,不知道是不是 Jdk 的bug,使用时还是用带有 First 和 Last 后缀
的方法更清楚。在初始化 LinkedBlockingDeque 时可以设置容量防止其过渡膨胀。另外双向阻塞队列可以运用在“工作窃取”模式
中。 ArrayBlockingQueue fairQueue = new ArrayBlockingQueue(1000,true);
对于 BlockingQueue 来说,核心操作主要有几类:插入、删除、查找
其中的四种异常策略:
抛异常:如果阻塞队列满,再往队列里 add 插入元素会抛 IllegalStateException:Queue full,如果阻塞队列空,再 remove 就会抛
NoSuchElementException
特殊值:offer 方法:成功 true,失败 false,poll 方法,成功就返回元素,没有就返回 null
阻塞:阻塞队列满的时候,生产者线程继续 put 元素,队列就会阻塞直到可以 put 数据或者响应中断然后退出,阻塞队列空的时
候,消费者线程继续 take 元素,队列就会一直阻塞直到有元素可以 take
超时退出:阻塞队列满的时候,会阻塞生产者线程且超时退出,空的时候会阻塞消费者线程且超时退出
那么使用的时候,增删的方法按对应的同一组使用比较合理。(其实这个策略的设计对应的在单线程集合里也有,那就是Deque接口
的实现类 LinkedList 使用的时候,不同的增删方法策略不同)
插入操作
1、public abstract boolean add(E paramE):将指定元素插入此队列中(如果立即可行且不会违反容量限制),成功时返回true,
如果当前没有可用的空间,则抛出 IllegalStateException。如果该元素是 NULL,则会抛出 NullPointerException 异常。
2、public abstract boolean offer(E paramE):将指定元素插入此队列中(如果立即可行且不会违反容量限制),成功时返回
true,如果当前没有可用的空间,则返回 false。
3、public abstract void put(E paramE) throws InterruptedException:将指定元素插入此队列中,将等待可用的空间(如果有必
要)
4、offer(E o, long timeout, TimeUnit unit):可以设定等待的时间,如果在指定的时间内,还不能往队列中加入 BlockingQueue,
则返回失败。
获取数据操作:
1、poll(time):取走 BlockingQueue 里排在首位的对象,若不能立即取出,则可以等 time 参数规定的时间,取不到时返回 null;
2、poll(long timeout, TimeUnit unit): 从 BlockingQueue 取出一个队首的对象, 如果在指定时间内, 队列一旦有数据可取, 则
立即返回队列中的数据。否则直到时间超时还没有数据可取,返回失败。
3、take():取走 BlockingQueue 里排在首位的对象,若 BlockingQueue 为空,阻断进入等待状态直到 BlockingQueue 有新的数据被加
入。
4、drainTo():一次性从 BlockingQueue 获取所有可用的数据对象(还可以指定获取数据的个数),通过该方法,可以提升获取数据
效率;不需要多次分批加锁或释放锁。

线程控制
join ():
阻塞指定线程等到另一个线程完成以后再继续执行
sleep ():
使线程停止运行一段时间,让出CPU,将处于阻塞状态
如果调用了sleep方法之后,没有其他等待执行的线程,这个时候当前线程不会马上恢复执行!
实际开发中经常使用Thread.sleep()来模拟线程切换,暴露线程安全问题。
yield ():
让当前正在执行线程暂停,不是阻塞线程,而是将线程转入就绪状态
如果调用了yield方法之后,没有其他等待执行的线程,这个时候当前线程就会马上恢复执行!
setDaemon():
可以将指定的线程设置成后台线程
创建后台线程的线程结束时,后台线程也随之消亡
只能在线程启动之前把它设为后台线程
interrupt():
并没有直接中断线程,而是需要被中断线程自己处理
stop():
结束线程,不推荐使用
wait()和sleep()的区别
1、Sleep是线程中的方法,而wait是Object的方法
2、Sleep不会释放锁,wait会释放锁,而且会加入等待队列
3、Sleep方法不需要依赖synchronized,wait需要依赖同步器synchronized
4、Sleep不需要唤醒,wait需要notify唤醒
5、sleep()方法导致了程序暂停执行指定的时间,让出 cpu 该其他线程,但是他的监控状态依然保持者,当指定的时间到了又会自动
恢复运行状态
线程同步
当多个线程访问同一个数据时,容易出现线程安全问题。需要让线程同步,保证数据安全。
线程同步(thread synchronized):
当两个或两个以上线程访问同一资源时,需要某种方式来确保资源在某一时刻只被一个线程使用
线程同步的实现方案:
- 同步代码块锁
synchronized (obj){ }
使用synchronized关键字加上一个锁对象来定义一段代码,这就叫同步代码块。
多个同步代码块如果使用相同的锁对象,那么他们就是同步的。
- 同步方法锁
private synchronized void makeWithdrawal(int amt) {}
同步非静态方法:就是同步代码块,同步锁对象是this
同步静态方法:就是同步代码块,同步锁对象是类的class对象
- Lock锁
ReentrantLock、ReentrantReadWriteLock
- volatile+CAS无锁化方案
死锁
死锁产生的原因:
1、多个线程共享多个资源
2、多个线程都需要其他线程的资源,每个线程又不愿或者无法放弃自己的资源(锁的开关无法人为控制)
Lock锁
Lock锁方法:
a、lock()
首先lock()方法是平常使用得最多的一个方法,就是用来获取锁。如果锁已被其他线程获取,则进行等待。
如果采用Lock,必须主动去释放锁,并且在发生异常时,不会自动释放锁。因此一般来说,使用Lock必须在try{}catch{}块中进行,
并且将释放锁的操作放在finally块中进行,以保证锁一定被被释放,防止死锁的发生
b、tryLock()
tryLock()方法是有返回值的,它表示用来尝试获取锁,如果获取成功,则返回true,如果获取失败(即锁已被其他线程获取),则返
回false,也就说这个方法无论如何都会立即返回。拿不到锁时不会一直在那等待
c、tryLock(long time, TimeUnit unit)
tryLock(long time, TimeUnit unit)方法和tryLock()方法是类似的,只不过区别在于这个方法在拿不到锁时会等待一定的时间,在时
间期限之内如果还拿不到锁,就返回false。如果一开始拿到锁或者在等待期间内拿到了锁,则返回true
d、lockInterruptibly()
lockInterruptibly()方法比较特殊,当通过这个方法去获取锁时,如果线程正在等待获取锁,则这个线程能够响应中断,即中断线程
的等待状态。也就使说,当两个线程同时通过lock.lockInterruptibly()想获取某个锁时,假若此时线程A获取到了锁,而线程B只有在
等待,那么对线程B调用threadB.interrupt()方法能够中断线程B的等待过程

ReetrantLock
ReentrantLock,意思是“可重入锁”。ReentrantLock是唯一实现了Lock接口的非内部类,并且ReentrantLock提供了更多的方法。
ReentrantLock锁在同一个时间点只能被一个线程锁持有;
而可重入的意思是,ReentrantLock锁,可以被单个线程多次获取。
ReentrantLock分为“公平锁”和“非公平锁”。它们的区别体现在获取锁的机制上是否公平。“锁”是为了保护竞争资源,防止多个线程同
时操作线程而出错,ReentrantLock在同一个时间点只能被一个线程获取(当某线程获取到“锁”时,其它线程就必须等待);
ReentraantLock是通过一个FIFO的等待队列来管理获取该锁所有线程的。在“公平锁”的机制下,线程依次排队获取锁;而“非公平
锁”在锁是可获取状态时,不管自己是不是在队列的开头都可以获取锁。
ReentantLock继承接口Lock并实现了接口中定义的方法,他是一种可重入锁,除了能完成synchronized所能完成的所有工作外,还
提供了诸如可响应中断锁、可轮询锁请求、定时锁等避免多线程死锁的方法
ReentrantLock实现了Lock接口,内部有三个类,Sync、fairSync、NonfairSync,其中Sync是抽象类型。FairSync是公平抢占、
NonFairSync是非公平抢占(默认)
当我们调用ReentrantLock的lock方法时,实际上是调用了NonFairSync的lock的方法,首先用CAS操作,尝试抢占锁,成功则执
行;失败则调用acquire模板方法等待抢占
acquire方法实际上是调用的AbstractqueuedSynchronize的acquire方法,它是一套锁抢占的模板,总体原理是先去获取锁,获取不
成功的话会进入CLH队列中(公平的自旋锁,轮询是否释放锁),表示等待抢占,进入时还会再次执行获得锁的操作,如果失败,调
用LockSupport.park将线程挂起。在持有锁的那个线程(CLH的头节点)unlock时,会唤醒CLH头节点的下个节点的线程,调用的是
unPark
Acquire方法内部先使用的是tryAcquire方法获取锁,此方法在NonfairSync类中,其实就是使用了NonFairTryAcquire
具体实现是:首先判断锁的状态是否为0如果为零返回true,若果不是,在判断占用锁的线程是否为当前线程如果是的话会增加锁的
状态值,并返回true,如果都不是返回false;获得锁成功会将这个节点设置为头节点。原来的头节点会把它的next变量设置为
NULL,在下次GC是会被清理掉
这就是为什么同一线程可重入锁的原因
FairSync和NonFairSync的区别在于FairSync中多了个hasQueuePredecessors的方法,会先判断CLH中是否存在节点,如果存在会
先排队;而NonFairSync则是无视是否存在节点名直接竞争抢占
Lock 接口的主要方法:
1、void lock(): 执行此方法时, 如果锁处于空闲状态, 当前线程将获取到锁。相反, 如果锁已经被其他线程持有, 将禁用当前线程, 直到
当前线程获取到锁
2、boolean tryLock(): 如果锁可用,则获取锁,并立即返回 true,否则返回 false。该方法和lock()的区别在于,tryLock()只是"试
图"获取锁,如果锁不可用,不会导致当前线程被禁用,当前线程仍然继续往下执行代码。而 lock()方法则是
一定要获取到锁, 如果锁不可用, 就一直等待,在未获得锁之前,当前线程并不继续向下执行
3、void unlock():执行此方法时,当前线程将释放持有的锁。锁只能由持有者释放,如果线程并不持有锁,却执行该方法,可能导
致异常的发生
4、Condition newCondition(): 条件对象,获取等待通知组件。该组件和当前的锁绑定,当前线程只有获取了锁,才能调用该组件
的 await()方法,而调用后,当前线程将缩放锁
5、getHoldCount() : 查询当前线程保持此锁的次数,也就是执行此线程执行 lock 方法的次数
6、getQueueLength(): 返回正等待获取此锁的线程估计数,比如启动 10 个线程, 1 个线程获得锁,此时返回的是 1
7、getWaitQueueLength: (Condition condition)返回等待与此锁相关的给定条件的线程估计数。比如 10 个线程,用同一个
condition 对象,并且此时这 10 个线程都执行了condition 对象的 await 方法,那么此时执行此方法
返回 10
8、hasWaiters(Condition condition): 查询是否有线程等待与此锁有关的给定条件9、hasQueuedThread(Thread thread): 查询给定线程是否等待获取此锁
10、hasQueuedThreads(): 是否有线程等待此锁
11、isFair(): 该锁是否公平锁
12、isHeldByCurrentThread(): 当前线程是否保持锁锁定,线程的执行 lock 方法的前后分别是 false 和 true
13、isLock(): 此锁是否有任意线程占用
14、lockInterruptibly():如果当前线程未被中断,获取锁tryLock():尝试获得锁,仅在调用时锁未被线程占用,获得锁
tryLock(long timeout TimeUnit unit): 如果锁在给定等待时间内没有被另一个线程保持,则获取该
锁
ReetrantReadWriteLock
实现了ReadWriteLock接口,该类中包括两个内部类ReadLock和WriteLock,这两个内部类实现了Lock接口。
ReentrantReadWriteLock里面提供了很多丰富的方法,不过最主要的有两个方法:readLock()和writeLock()用来获取读锁和写锁。
重量级锁Synchronized
Synchronized的作用:
在JDK1.5之前都是使用synchronized关键字保证同步的,Synchronized的作用相信大家都已经非常熟悉了;
它可以把任意一个非NULL的对象当作锁。
a、作用于方法时,锁住的是对象的实例(this)
b、当作用于静态方法时,锁住的是Class实例,又因为Class的相关数据存储在永久代PermGen(jdk1.8则是metaspace),永久代
是全局共享的,因此静态方法锁相当于类的一个全局锁,会锁所有调用该方法的线程
c、synchronized作用于一个对象实例时,锁住的是所有以该对象为锁的代码块
Synchronized的实现:
实现如下图所示
它有多个队列,当多个线程一起访问某个对象监视器的时候,对象监视器会将这些线程存储在不同的容器中。
a、ContentionList:竞争队列,所有请求锁的线程首先被放在这个竞争队列中
b、EntryList:ContentionList中那些有资格成为候选资源的线程被移动到EntryList中
c、WaitSet:那些调用wait方法被阻塞的线程被放置在这里
d、OnDeck:任意时刻,最多只有一个线程正在竞争锁资源,该线程被成为OnDeck
e、Owner:当前已经获取到所资源的线程被称为Owner
f、!Owner:当前释放锁的线程
实现:
1、JVM 每次从队列的尾部取出一个数据用于锁竞争候选者(OnDeck),但是并发情况下,ContentionList 会被大量的并发线程进
行 CAS 访问,为了降低对尾部元素的竞争, JVM 会将一部分线程移动到 EntryList 中作为候选竞争线程
2、Owner 线程会在 unlock 时,将 ContentionList 中的部分线程迁移到 EntryList 中,并指定EntryList 中的某个线程为 OnDeck 线
程(一般是最先进去的那个线程)
3、Owner线程并不直接把锁传递给 OnDeck 线程,而是把锁竞争的权利交给 OnDeck,OnDeck 需要重新竞争锁。这样虽然牺牲了
一些公平性,但是能极大的提升系统的吞吐量,在JVM中,也把这种选择行为称之为“竞争切换”
4、OnDeck 线程获取到锁资源后会变为 Owner 线程,而没有得到锁资源的仍然停留在 EntryList中。如果Owner线程被 wait 方法阻
塞,则转移到WaitSet 队列中,直到某个时刻通过 notify或者notifyAll唤醒,会重新进去EntryList中
5、处于 ContentionList、 EntryList、 WaitSet 中的线程都处于阻塞状态,该阻塞是由操作系统来完成的(Linux 内核下采用
pthread_mutex_lock 内核函数实现的)
6、Synchronized 是非公平锁。 Synchronized 在线程进入 ContentionList 时, 等待的线程会先尝试自旋获取锁,如果获取不到就
进入 ContentionList,这明显对于已经进入队列的线程是不公平的,还有一个不公平的事情就是自旋获取锁的线程还可能直接抢
占 OnDeck 线程的锁资源
7、每个对象都有个 monitor 对象, 加锁就是在竞争 monitor 对象,代码块加锁是在前后分别加上 monitorenter 和 monitorexit
指令来实现的,方法加锁是通过一个标记位来判断的
8、synchronized 是一个重量级操作,需要调用操作系统相关接口,性能是低效的,有可能给线程加锁消耗的时间比有用操作消耗的
时间更多
9、Java1.6, synchronized 进行了很多的优化, 有适应自旋、锁消除、锁粗化、轻量级锁及偏向锁等,效率有了本质上的提高。在
之后推出的 Java1.7 与 1.8 中,均对该关键字的实现机理做了优化。引入了偏向锁和轻量级锁。都是在对象头中有标记位,不需要
经过操作系统加锁
10、锁可以从偏向锁升级到轻量级锁,再升级到重量级锁。这种升级过程叫做锁膨胀
11、JDK 1.6 中默认是开启偏向锁和轻量级锁,可以通过-XX:-UseBiasedLocking 来禁用偏向锁
Synchronized是非公平锁:
Synchronized在线程进入ContentionList时,等待的线程会先尝试自旋获取锁,如果获取不到就进入ContentionList,这明显对于已
经进入队列的线程是不公平的,还有一个不公平的事情就是自旋获取锁的线程还可能直接抢占OnDeck线程的锁资源
Synchronized同步锁和Lock锁区别
区别 同步锁synchronized Lock锁 可重入性 可重入锁 可重入锁 锁级别 是一个关键字,JVM级别的锁 是一个接口,JDK级别的锁 锁方案 取决于JVM底层的实现,不灵活 可以提供多种锁方案供选择,更灵活 异常处理 发生异常会自动释放锁 发生异常不会自动释放锁,需要在finally中释放锁 隐式/显式 隐式锁 显式锁 独占/共享 独占锁 ReentrantLock、WriteLock 独占锁 ReadLock 共享锁 响应中断 不可响应中断,没有得到锁的线程会一直等待下去,直到获取到锁 等待的线程可以响应中断,提前结束等待 上锁内容 可以锁方法、可以锁代码块 只可以锁代码块 获取锁状态 不知道是否获取锁 可以知道是否获取锁(tryLock的返回值) 性能高低 重量级锁,性能低(难道坐以待毙吗?改一下虚拟机底层如何??) 轻量级锁,性能高,尤其是竞争资源非常激烈时
各类锁概念
锁的概念:
同步访问共享数据时,为了保证数据操作的原子性,需要使用锁进行访问控制。锁,本质上是一个访问权限的标记。
在程序的世界里,有各种形式的数据,它们以各种形式被访问和存储。CPU 寄存器组,一级、二级缓存,内存,磁盘,设备缓存,
而从进程的角度来说,变量,栈,堆,数据库,还有各种各样的缓存。
存在数据的地方,就存在访问控制!
锁,可以有多种实现策略,只要满足标记修改的原子性,及标记本身的可见性。
共享锁&排他锁:
共享锁用于不更改数据的只读、查询等操作,如 SELECT 语句,读文件等。获取共享锁的事务只能读数据,不能修改数据。
排它锁用于数据的修改,比如 INSERT,UPDATE,或 DELETE,同一资源在同一时间只能有一个用户获得排它锁。
乐观锁&悲观锁:
乐观锁是一种策略,是指在操作数据时,以乐观的态度开启每次事务,认为该次操作不会遭遇冲突,也就是在操作数据时,不加锁,
在进行数据更新的提交时,再去判断是否有数据冲突
比如在数据库操作时,先给数据表加一个版本字段,每次更新会将记录的版本号加1。事务开始时,先查询并保存记录的版本,在事
务提交时,比较该记录版本与当前记录版本是否一致,如果一致,说明没有冲突,可以直接提交;如果版本不一致,说明发生了冲
突
数据库本身并不支持乐观锁,可以通过上层框架实现,比如 Hibernate。 Java 中的乐观锁基本都是通过 CAS (Compare and Set)
操作实现的,CAS是一种更新的原子操作,比较当前值跟传入值是否一样,一样则更新,否则失败
public final boolean compareAndSet(V expectedValue, V newValue) { return VALUE.compareAndSet(this, expectedValue, newValue); }悲观锁与乐观锁的思路相反,每次操作都要先获取响应的锁。共享锁和排它锁是悲观锁范畴下的不同实现
在数据库中,还可以根据数据的范围大小,分为行锁,表锁,数据库锁等
公平锁&非公平锁:
顾名思义,公平锁讲究的是先来后到,先进入等待队列的用户,会先获得锁。而非公平锁,如果一个线程对锁发起了请求,需要等
待,但在尚未将其放入等待队列之前,锁可用了,这时该线程会获得锁
非公平锁性能高于公平锁性能的原因:
在恢复一个被挂起的线程与该线程真正运行之间存在着严重的延迟。相当于人从被叫醒要完全醒过来需要时间。
假设线程A持有一个锁,并且线程B请求这个锁。由于锁被A持有,因此B将被挂起。当A释放锁时,B将被唤醒,因此B会再次尝试获
取这个锁。与此同时,如果线程C也请求这个锁,那么C很可能会在B被完全唤醒之前获得、使用以及释放这个锁。这样就是一种双赢
的局面:B获得锁的时刻并没有推迟,C更早的获得了锁,并且吞吐量也提高了
可重入锁&不可重入锁:
可重入就意味着,线程可以进入任何一个它已经拥有的锁所同步着的代码块。Java 中的 ReentrantLock 和 synchronized 都是可重
入的锁。
不可重入锁的代码示例:
public class Lock{ private boolean isLocked = false; public synchronized void lock() throws InterruptedException{ while(isLocked){ wait(); } isLocked = true; } public synchronized void unlock(){ isLocked = false; notify(); } }如果再同一个方法里,连续调用两次 lock() 方法,会发生死锁
可重入锁的代码示例:
public class Lock{ boolean isLocked = false; Thread lockedBy = null; int lockedCount = 0; public synchronized void lock() throws InterruptedException{ Thread thread = Thread.currentThread(); while(isLocked && lockedBy != thread){ wait(); } isLocked = true; lockedCount++; lockedBy = thread; } public synchronized void unlock(){ if(Thread.currentThread() == this.lockedBy){ lockedCount--; if(lockedCount == 0){ isLocked = false; notify(); } } } }自旋锁:
自旋锁原理非常简单,如果持有锁的线程能在很短时间内释放锁资源,那么那些等待竞争锁的线程就不需要做内核态和用户态之间的
切换进入阻塞挂起状态,它们只需要等一等(自旋),等持有锁的线程释放锁后即可立即获取锁,这样就避免用户线程和内核的切换
的消耗
但是线程自旋是需要消耗cup的,说白了就是让cup在做无用功,线程不能一直占用cup自旋做无用功,所以需要设定一个自旋等待的
最大时间。
如果持有锁的线程执行的时间超过自旋等待的最大时间扔没有释放锁,就会导致其它争用锁的线程在最大等待时间内还是获取不到
锁,这时争用线程会停止自旋进入阻塞状态。
自旋锁的优缺点:
自旋锁尽可能的减少线程的阻塞,这对于锁的竞争不激烈,且占用锁时间非常短的代码块来说性能能大幅度的提升,因为自旋的消耗
会小于线程阻塞挂起操作的消耗!
但是如果锁的竞争激烈,或者持有锁的线程需要长时间占用锁执行同步块,这时候就不适合使用自旋锁了,因为自旋锁在获取锁前一
直都是占用cpu做无用功,占着XX不XX,线程自旋的消耗大于线程阻塞挂起操作的消耗,其它需要cup的线程又不能获取到cpu,造
成cpu的浪费。
自旋锁时间阈值:
自旋锁的目的是为了占着CPU的资源不释放,等到获取到锁立即进行处理。但是如何去选择自旋的执行时间呢?如果自旋执行时间太
长,会有大量的线程处于自旋状态占用CPU资源,进而会影响整体系统的性能。因此自旋的周期选的额外重要!
JVM对于自旋周期的选择,jdk1.5这个限度是一定的写死的,在1.6引入了适应性自旋锁,适应性自旋锁意味着自旋的时间不在是固定
的了,而是由前一次在同一个锁上的自旋时间以及锁的拥有者的状态来决定,基本认为一个线程上下文切换的时间是最佳的一个时
间,同时JVM还针对当前CPU的负荷情况做了较多的优化
a、如果平均负载小于CPUs则一直自旋
b、如果有超过(CPUs/2)个线程正在自旋,则后来线程直接阻塞
c、如果正在自旋的线程发现Owner发生了变化则延迟自旋时间(自旋计数)或进入阻塞
d、如果CPU处于节电模式则停止自旋
e、自旋时间的最坏情况是CPU的存储延迟(CPU A存储了一个数据,到CPU B得知这个数据直接的时间差)
f、自旋时会适当放弃线程优先级之间的差异
自旋锁的开启:
JDK1.6中-XX:+UseSpinning开启
JDK1.7后,去掉此参数,由jvm控制
偏向锁
Java偏向锁(Biased Locking)是Java6引入的一项多线程优化。
偏向锁,顾名思义,它会偏向于第一个访问锁的线程,如果在运行过程中,同步锁只有一个线程访问,不存在多线程争用的情况,则
线程是不需要触发同步的,这种情况下,就会给线程加一个偏向锁。
如果在运行过程中,遇到了其他线程抢占锁,则持有偏向锁的线程会被挂起,JVM会消除它身上的偏向锁,将锁恢复到标准的轻量级
锁。它通过消除资源无竞争情况下的同步原语,进一步提高了程序的运行性能。
偏向锁的实现:
偏向锁获取过程:
a、访问Mark Word中偏向锁的标识是否设置成1,锁标志位是否为01,确认为可偏向状态
b、如果为可偏向状态,则测试线程ID是否指向当前线程,如果是,进入步骤5,否则进入步骤c
c、如果线程ID并未指向当前线程,则通过CAS操作竞争锁。如果竞争成功,则将Mark Word中线程ID设置为当前线程ID,然后执行
e;如果竞争失败,执行d
d、如果CAS获取偏向锁失败,则表示有竞争。当到达全局安全点(safepoint)时获得偏向锁的线程被挂起,偏向锁升级为轻量级
锁,然后被阻塞在安全点的线程继续往下执行同步代码。(撤销偏向锁的时候会导致stop the word)
e、执行同步代码
注意:第四步中到达安全点safepoint会导致stop the word,时间很短
偏向锁的释放:
偏向锁的撤销在上述第四步骤中有提到。偏向锁只有遇到其他线程尝试竞争偏向锁时,持有偏向锁的线程才会释放锁,线程不会主动
去释放偏向锁。偏向锁的撤销,需要等待全局安全点(在这个时间点上没有字节码正在执行),它会首先暂停拥有偏向锁的线程,判
断锁对象是否处于被锁定状态,撤销偏向锁后恢复到未锁定(标志位为“01”)或轻量级锁(标志位为“00”)的状态
偏向锁的适用场景:
始终只有一个线程在执行同步块,在它没有执行完释放锁之前,没有其它线程去执行同步块,在锁无竞争的情况下使用,一旦有了竞
争就升级为轻量级锁,升级为轻量级锁的时候需要撤销偏向锁,撤销偏向锁的时候会导致stop the word操作
在有锁的竞争时,偏向锁会多做很多额外操作,尤其是撤销偏向所的时候会导致进入安全点,安全点会导致stw,导致性能下降,这
种情况下应当禁用
查看停顿–安全点停顿日志
要查看安全点停顿,可以打开安全点日志,通过设置JVM参数 -XX:+PrintGCApplicationStoppedTime 会打出系统停止的时间,添加
-XX:+PrintSafepointStatistics -XX:PrintSafepointStatisticsCount=1 这两个参数会打印出详细信息,可以查看到使用偏向锁导致的停
顿,时间非常短暂,但是争用严重的情况下,停顿次数也会非常多;
注意:安全点日志不能一直打开:
a、安全点日志默认输出到stdout,一是stdout日志的整洁性,二是stdout所重定向的文件如果不在/dev/shm,可能被锁
b、对于一些很短的停顿,比如取消偏向锁,打印的消耗比停顿本身还大
c、安全点日志是在安全点内打印的,本身加大了安全点的停顿时间
所以安全日志应该只在问题排查时打开。
如果在生产系统上要打开,再再增加下面四个参数:
-XX:+UnlockDiagnosticVMOptions -XX: -DisplayVMOutput -XX:+LogVMOutput -XX:LogFile=/dev/shm/vm.log
打开Diagnostic(只是开放了更多的flag可选,不会主动激活某个flag),关掉输出VM日志到stdout,输出到独立文件,/dev/shm目
录(内存文件系统)。
此日志分三部分:
第一部分是时间戳,VM Operation的类型
第二部分是线程概况,被中括号括起来total: 安全点里的总线程数
initially_running: 安全点时开始时正在运行状态的线程数
wait_to_block: 在VM Operation开始前需要等待其暂停的线程数
第三部分是到达安全点时的各个阶段以及执行操作所花的时间,其中最重要的是vmop
- spin: 等待线程响应safepoint号召的时间;
- block: 暂停所有线程所用的时间;
- sync: 等于 spin+block,这是从开始到进入安全点所耗的时间,可用于判断进入安全点耗时;
- cleanup: 清理所用时间;
- vmop: 真正执行VM Operation的时间。
可见,那些很多但又很短的安全点,全都是RevokeBias, 高并发的应用会禁用掉偏向锁。
jvm开启/关闭偏向锁
开启偏向锁:-XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0
关闭偏向锁:-XX:-UseBiasedLocking

锁升级
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-D1pgNbM8-1653308049337)(C:\Users\纵横\AppData\Roaming\Typora\typora-user-images\image-20210825114156545.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vKj2oDE7-1653308049338)(C:\Users\纵横\AppData\Roaming\Typora\typora-user-images\image-20210825114220209.png)]
锁的状态有无锁、偏向锁、轻量级锁、重量级锁。锁的状态会随着锁的竞争升级,这是一个不可逆的过程
代码进入同步块的时候,首先在栈帧中创建一个锁记录(Lock Record),锁记录是一个数据结构。锁对象的Mark Word会被复制到
锁记录中,此时锁记录中称为Displaced Mark Word。
一开始是无锁状态,对象锁的对象头Mark Word中的锁标记是01,是否偏向锁的位置上是0。当锁对象第一次被线程获取的时候,锁
对象的Mark Word中的是否偏向锁的位置上变为1,锁标记仍为01。通过使用CAS操作将当前线程的线程ID设置到锁对象的Mark
Word中,如果设置成功了,那么当前线程得到了这个锁对象了,可以执行同步代码块的代码,以后每次进入这个锁相关的同步块
时,都可以不再使用任何操作(比如lock,cas之类),此时处于偏向锁状态。当有另一个线程尝试获取偏向锁时,偏向模式宣告结
束。根据锁对象目前是否处于锁定状态,撤销偏向后恢复到未锁定状态或者轻量级锁定的状态
当有一条线程尝试获取处于轻量级锁的锁对象时,首先在栈帧中创建锁记录,然后将锁对象的Mark Word复制到锁记录中,然后使
用CAS操作(一般是10次)把锁对象的Mark Word设置为指向锁记录的指针,如果设置成功(后面的自旋次数相应提高,这就是适
应性自旋),那么这个线程就拥有该对象的锁,并且对象的Mark Word的锁标志位变为了00。如果设置失败,那么首先检查对象的
Mark Word是否指向当前线程的栈帧,如果是则说明当前线程已经拥有这个对象的锁,可以直接进入同步块执行,否则说明则这个
锁对象已经被其他线程占用了。那么轻量级锁膨胀为重量级锁。锁对象的Mark Word中锁标志变为10,Mark Word指向重量级锁,
后面等待锁的线程也进入阻塞状态
轻量级锁的解锁过程通过CAS操作进行。如果锁对象的Mark Word仍指向线程的锁记录,那么通过CAS操作把对象的Mark Word与线
程中复制得来的Displaced Mark Word替换回来。如果替换成功,那么解锁成功;否则在释放锁的同时,要唤醒阻塞的线程
锁优化
减少锁持有时间:
只用在有线程安全要求的程序上加锁
减小锁粒度:
将大对象(这个对象可能会被很多线程访问),拆成小对象,大大增加并行度,降低锁竞争。降低了锁的竞争,偏向锁,轻量级锁成
功率才会提高。最最典型的减小锁粒度的案例就是ConcurrentHashMap
锁分离:
最常见的锁分离就是读写锁 ReadWriteLock,根据功能进行分离成读锁和写锁,这样读读不互斥,读写互斥,写写互斥,即保证了
线程安全,又提高了性能,具体也请查看[高并发 Java 五]JDK并发包 1。读写分离思想可以延伸,只要操作互不影响,锁就可以分
离。比如LinkedBlockingQueue 从头部取出,从尾部放数据
锁粗化:
通常情况下,为了保证多线程间的有效并发,会要求每个线程持有锁的时间尽量短,即在使用完公共资源后,应该立即释放锁。但
是,凡事都有一个度, 如果对同一个锁不停的进行请求、同步和释放,其本身也会消耗系统宝贵的资源,反而不利于性能的优化 。
锁消除:
锁消除是在编译器级别的事情。 在即时编译器时,如果发现不可能被共享的对象,则可以消除这些对象的锁操作,多数是因为程序
员编码不规范引起
线程通信方式
由于java的CAS同时具有 volatile 读和volatile写的内存语义,因此Java线程之间的通信现在有了下面四种方式:
1、A线程写volatile变量,随后B线程读这个volatile变量。
2、A线程写volatile变量,随后B线程用CAS更新这个volatile变量。
3、A线程用CAS更新一个volatile变量,随后B线程用CAS更新这个volatile变量。
4、A线程用CAS更新一个volatile变量,随后B线程读这个volatile变量。
concurrent包的源代码实现通用化的实现模式:
1、首先,声明共享变量为volatile
2、然后,使用CAS的原子条件更新来实现线程之间的同步
3、同时,配合以volatile的读/写和CAS所具有的volatile读和写的内存语义来实现线程之间的通信
AQS,非阻塞数据结构和原子变量类(java.util.concurrent.atomic包中的类),这些concurrent包中的基础类都是使用这种模式来
实现的,而concurrent包中的高层类又是依赖于这些基础类来实现的。从整体来看,concurrent包的实现示意图如下:

CAS
CAS机制是为了实现原子性操作的,是实现原子操作的其中一种方式,可用于在多线程编程中实现不被打断的数据交换操作,从而避免多线程同时改写某一数据时由于执行顺序不确定性以及中断的不可预知性产生的数据不一致问题。 该操作通过将内存中的值与指定数据进行比较,当数值一样时将内存中的数据替换为新的值。现代的大多数CPU都实现了CAS,它是一种无锁(lock-free),且非阻塞的一种算法,用来保持数据的一致性。
什么是原子操作?如何实现原子操作?
假定有两个操作A和B(A和B可能都很复杂),如果从执行A的线程来看,当另一个线程执行B时,要么将B全部执行完,要么完全不执行B,那么A和B对彼此来说是原子的。实现原子操作可以使用锁,锁机制,满足基本的需求是没有问题的了,但是有的时候我们的需求并非这么简单,我们需要更有效,更加灵活的机制,synchronized关键字是基于阻塞的锁机制,也就是说当一个线程拥有锁的时候,访问同一资源的其它线程需要等待,直到该线程释放锁,这里会有些问题:首先,如果被阻塞的线程优先级很高很重要怎么办?其次,如果获得锁的线程一直不释放锁怎么办?(这种情况是非常糟糕的)。还有一种情况,如果有大量的线程来竞争资源,那CPU将会花费大量的时间和资源来处理这些竞争,同时,还有可能出现一些例如死锁之类的情况,最后,其实锁机制是一种比较粗糙,粒度比较大的机制,相对于像计数器这样的需求有点儿过于笨重。
实现原子操作还可以使用当前的处理器基本都支持CAS()的指令,只不过每个厂家所实现的算法并不一样,每一个CAS操作过程都包含三个运算符:一个内存地址V,一个期望的值A和一个新值B,操作的时候如果这个地址上存放的值等于这个期望的值A,则将地址上的值赋为新值B,否则不做任何操作。
CAS的基本思路就是,如果这个地址上的值和期望的值相等,则给其赋予新值,否则不做任何事儿,但是要返回原值是多少。循环CAS就是在一个循环里不断的做cas操作,直到成功为止。
CAS实现原子操作的三大问题:
1、ABA问题
因为CAS需要在操作值的时候,检查值有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是A,变成了B,又变成了
A,那么使用CAS进行检查时会发现它的值没有发生变化,但是实际上却变化了
ABA问题的解决思路就是使用版本号。在变量前面追加上版本号,每次变量更新的时候把版本号加1,那么A→B→A就会变成
1A→2B→3A。举个通俗点的例子,你倒了一杯水放桌子上,干了点别的事,然后同事把你水喝了又给你重新倒了一杯水,你回来看
水还在,拿起来就喝,如果你不管水中间被人喝过,只关心水还在,这就是ABA问题
如果你是一个讲卫生讲文明的小伙子,不但关心水在不在,还要在你离开的时候水被人动过没有,因为你是程序员,所以就想起了放
了张纸在旁边,写上初始值0,别人喝水前麻烦先做个累加才能喝水
2、循环时间长开销大
自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销
3、只能保证一个共享变量的原子操作
当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操
作的原子性,这个时候就可以用锁
还有一个取巧的办法,就是把多个共享变量合并成一个共享变量来操作。比如,有两个共享变量i=2,j=a,合并一下ij=2a,然后用
CAS来操作ij。从Java 1.5开始,JDK提供了AtomicReference类来保证引用对象之间的原子性,就可以把多个变量放在一个对象里来
进行CAS操作
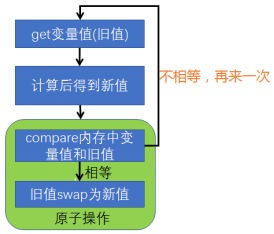
volatile
简介:
volatile是Java提供的一种轻量级的同步机制。Java 语言包含两种内在的同步机制:同步块(或方法)和 volatile 变量,相比于
synchronized(synchronized通常称为重量级锁),volatile更轻量级,因为它不会引起线程上下文的切换和调度。但是volatile 变
量的同步性较差(有时它更简单并且开销更低),而且其使用也更容易出错
Java的内存模型JMM以及共享变量的可见性:
JMM决定一个线程对共享变量的写入何时对另一个线程可见,JMM定义了线程和主内存之间的抽象关系:共享变量存储在主内存
(Main Memory)中,每个线程都有一个私有的本地内存(Local Memory),本地内存保存了被该线程使用到的主内存的副本拷贝,
线程对变量的所有操作都必须在工作内存中进行,而不能直接读写主内存中的变量
对于普通的共享变量来讲,线程A将其修改为某个值发生在线程A的本地内存中,此时还未同步到主内存中去;而线程B已经缓存了
该变量的旧值,所以就导致了共享变量值的不一致。解决这种共享变量在多线程模型中的不可见性问题,较粗暴的方式自然就是加
锁,但是此处使用synchronized或者Lock这些方式太重量级了,比较合理的方式其实就是volatile
需要注意的是,JMM是个抽象的内存模型,所以所谓的本地内存,主内存都是抽象概念,并不一定就真实的对应cpu缓存和物理内存
volatile变量的特性:
1、保证可见性,不保证原子性
(1)当写一个volatile变量时,JMM会把该线程本地内存中的变量强制刷新到主内存中去
(2)这个写会操作会导致其他线程中的volatile变量缓存无效
2、禁止指令重排
重排序是指编译器和处理器为了优化程序性能而对指令序列进行排序的一种手段。重排序需要遵守一定规则:
a、重排序操作不会对存在数据依赖关系的操作进行重排序。
比如:a=1;b=a; 这个指令序列,由于第二个操作依赖于第一个操作,所以在编译时和处理器运行时这两个操作不会被重排序。
b、重排序是为了优化性能,但是不管怎么重排序,单线程下程序的执行结果不能被改变
比如:a=1;b=2;c=a+b这三个操作,第一步(a=1)和第二步(b=2)由于不存在数据依赖关系, 所以可能会发生重排序,但是c=a+b这
个操作是不会被重排序的,因为需要保证最终的结果一定是c=a+b=3。
重排序在单线程下一定能保证结果的正确性,但是在多线程环境下,可能发生重排序,影响结果,下例中的1和2由于不存在数据依
赖关系,则有可能会被重排序,先执行status=true再执行a=2。而此时线程B会顺利到达4处,而线程A中a=2这个操作还未被执行,
所以b=a+1的结果也有可能依然等于2。
public class TestVolatile{ int a = 1; boolean status = false; //状态切换为true public void changeStatus{ a = 2; //1 status = true; //2 } //若状态为true,则为running public void run(){ if(status){ //3 int b = a + 1; //4 System.out.println(b); } } }使用volatile关键字修饰共享变量便可以禁止这种重排序。若用volatile修饰共享变量,在编译时,会在指令序列中插入内存屏障来禁
止特定类型的处理器重排序,volatile禁止指令重排序也有一些规则:
a、当程序执行到volatile变量的读操作或者写操作时,在其前面的操作的更改肯定全部已经进行,且结果已经对后面的操作可见;
在其后面的操作肯定还没有进行
b、在进行指令优化时,不能将对volatile变量访问的语句放在其后面执行,也不能把volatile变量后面的语句放到其前面执行
即执行到volatile变量时,其前面的所有语句都执行完,后面所有语句都未执行。且前面语句的结果对volatile变量及其后面语句
可见
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义:
1、保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的
2、禁止进行指令重排序
volatile和synchronized的区别:
a、volatile本质是在告诉jvm当前变量在寄存器(工作内存)中的值是不确定的,需要从主存中读取;synchronized则是锁定当前变
量,只有当前线程可以访问该变量,其他线程被阻塞住
b、volatile仅能使用在变量级别;synchronized则可以使用在变量、方法、和类级别的
c、volatile仅能实现变量的修改可见性,并不能保证原子性;synchronized则可以保证变量的修改可见性和原子性
d、volatile不会造成线程的阻塞;synchronized可能会造成线程的阻塞
e、volatile标记的变量不会被编译器优化;synchronized标记的变量可以被编译器优化

并发编程的原子性、可见性、有序性
1、原子性
定义: 即一个操作或者多个操作 要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。原子性是拒绝多线程操作的,不论是多核还是单核,具有原子性的量,同一时刻只能有一个线程来对它进行操作。简而言之,在整个操作过程中不会被线程调度器中断的操作,都可认为是原子性。例如 a=1是原子性操作,但是a++和a +=1就不是原子性操作。Java中的原子性操作包括:
(1)基本类型的读取和赋值操作,且赋值必须是值赋给变量,变量之间的相互赋值不是原子性操作。
(2)所有引用reference的赋值操作
(3)java.concurrent.Atomic.* 包中所有类的一切操作
原子操作(atomic operation)意为”不可被中断的一个或一系列操作” 。处理器使用基于对缓存加锁或总线加锁的方式来实现多处理器之间的原子操作。在 Java 中可以通过锁和循环 CAS 的方式来实现原子操作。 CAS 操作——Compare & Set,或是 Compare & Swap,现在几乎所有的 CPU 指令都支持 CAS的原子操作。 原子操作是指一个不受其他操作影响的操作任务单元。原子操作是在多线程环境下避免数据不一致必须的手段。int++并不是一个原子操作,所以当一个线程读取它的值并加 1 时,另外一个线程有可能会读到之前的值,这就会引发错误。 为了解决这个问题,必须保证增加操作是原子的,在 JDK1.5 之前我们可以使用同步技术来做到这一点。到 JDK1.5,java.util.concurrent.atomic 包提供了 int 和long 类型的原子包装类,它们可以自动的保证对于他们的操作是原子的并且不需要使用同步。 java.util.concurrent 这个包里面提供了一组原子类。其基本的特性就是在多线程环境下,当有多个线程同时执行这些类的实例包含的方法时,具有排他性,即当某个线程进入方法,执行其中的指令时,不会被其他线程打断,而别的线程就像自旋锁一样,一直等到该方法执行完成,才由 JVM 从等待队列中选择一个另一个线程进入,这只是一种逻辑上的理解。
原子类:AtomicBoolean,AtomicInteger,AtomicLong,AtomicReference
原子数组:AtomicIntegerArray,AtomicLongArray,AtomicReferenceArray
原子属性更新器:AtomicLongFieldUpdater,AtomicIntegerFieldUpdater,AtomicReferenceFieldUpdater
解决 ABA 问题的原子类:AtomicMarkableReference(通过引入一个 boolean来反映中间有没有变过),AtomicStampedReference(通过引入一个 int 来累加来反映中间有没有变过)2.可见性
定义:指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。在多线程环境下,一个线程对共享变量的操作对其他线程是不可见的。Java提供了volatile来保证可见性,当一个变量被volatile修饰后,表示着线程本地内存无效,当一个线程修改共享变量后他会立即被更新到主内存中,其他线程读取共享变量时,会直接从主内存中读取。当然,synchronize和Lock都可以保证可见性。synchronized和Lock能保证同一时刻只有一个线程获取锁然后执行同步代码,并且在释放锁之前会将对变量的修改刷新到主存当中。因此可以保证可见性。
3.有序性
定义:即程序执行的顺序按照代码的先后顺序执行。Java内存模型中的有序性可以总结为:如果在本线程内观察,所有操作都是有序的;如果在一个线程中观察另一个线程,所有操作都是无序的。前半句是指“线程内表现为串行语义”,后半句是指“指令重排序”现象和“工作内存主主内存同步延迟”现象。
在Java内存模型中,为了效率是允许编译器和处理器对指令进行重排序,当然重排序不会影响单线程的运行结果,但是对多线程会有影响。Java提供volatile来保证一定的有序性。最著名的例子就是单例模式里面的DCL(双重检查锁)。另外,可以通过synchronized和Lock来保证有序性,synchronized和Lock保证每个时刻是有一个线程执行同步代码,相当于是让线程顺序执行同步代码,自然就保证了有序性。
notify()和notifyAll()有什么区别?
notify可能会导致死锁,而notifyAll则不会任何时候只有一个线程可以获得锁,也就是说只有一个线程可以运行synchronized 中的代码使用notifyall,可以唤醒所有处于wait状态的线程,使其重新进入锁的争夺队列中,而notify只能唤醒一个。 wait() 应配合while循环使用,不应使用if,务必在wait()调用前后都检查条件,如果不满足,必须调用notify()唤醒另外的线程来处理,自己继续wait()直至条件满足再往下执行。 notify() 是对notifyAll()的一个优化,但它有很精确的应用场景,并且要求正确使用。不然可能导致死锁。正确的场景应该是 WaitSet中等待的是相同的条件,唤醒任一个都能正确处理接下来的事项,如果唤醒的线程无法正确处理,务必确保继续notify()下一个线程,并且自身需要重新回到WaitSet中
为什么wait, notify 和 notifyAll这些方法不在thread类里面?
明显的原因是JAVA提供的锁是对象级的而不是线程级的,每个对象都有锁,通过线程获得。如果线程需要等待某些锁那么调用对象中的wait()方法就有意义了。如果wait()方法定义在Thread类中,线程正在等待的是哪个锁就不明显了。简单的说,由于wait,notify和notifyAll都是锁级别的操作,所以把他们定义在Object类中因为锁属于对象 。
为什么wait和notify方法要在同步块中调用?
1. 只有在调用线程拥有某个对象的独占锁时,才能够调用该对象的wait(),notify()和notifyAll()方法。 2. 如果你不这么做,你的代码会抛出IllegalMonitorStateException异常。 3. 还有一个原因是为了避免wait和notify之间产生竞态条件。 wait()方法强制当前线程释放对象锁。这意味着在调用某对象的wait()方法之前,当前线程必须已经获得该对象的锁。因此,线程必须在某个对象的同步方法或同步代码块中才能调用该对象的wait()方法。在调用对象的notify()和notifyAll()方法之前,调用线程必须已经得到该对象的锁。因此,必须在某个对象的同步方法或同步代码块中才能调用该对象的notify()或notifyAll()方法。调用wait()方法的原因通常是,调用线程希望某个特殊的状态(或变量)被设置之后再继续执行。调用notify()或notifyAll()方法的原因通常是,调用线程希望告诉其他等待中的线程:"特殊状态已经被设置"。这个状态作为线程间通信的通道,它必须是一个可变的共享状态(或变量)。
Java中interrupted 和 isInterruptedd方法的区别?
interrupted()和isInterrupted()的主要区别是前者会将中断状态清除而后者不会。Java多线程的中断机制是用内部标识来实现的,调用Thread.interrupt()来中断一个线程就会设置中断标识为true。当中断线程调用静态方法Thread.interrupted()来检查中断状态时,中断状态会被清零。而非静态方法isInterrupted()用来查询其它线程的中断状态且不会改变中断状态标识。简单的说就是任何抛出InterruptedException异常的方法都会将中断状态清零。无论如何,一个线程的中断状态有有可能被其它线程调用中断来改变 。
SynchronizedMap和ConcurrentHashMap有什么区别?
SynchronizedMap()和Hashtable一样,实现上在调用map所有方法时,都对整个map进行同步。而ConcurrentHashMap的实现却更加精细,它对map中的所有桶加了锁。所以,只要有一个线程访问map,其他线程就无法进入map,而如果一个线程在访问ConcurrentHashMap某个桶时,其他线程,仍然可以对map执行某些操作。所以,ConcurrentHashMap在性能以及安全性方面,明显比Collections.synchronizedMap()更加有优势。同时,同步操作精确控制到桶,这样,即使在遍历map时,如果其他线程试图对map进行数据修改,也不会抛出ConcurrentModificationException
什么是线程安全
线程安全就是说多线程访问同一代码,不会产生不确定的结果。在多线程环境中,当各线程不共享数据的时候,即都是私有(private)成员,那么一定是线程安全的。但这种情况并不多见,在多数情况下需要共享数据,这时就需要进行适当的同步控制了。线程安全一般都涉及到synchronized, 就是一段代码同时只能有一个线程来操作 不然中间过程可能会产生不可预制的结果。如果你的代码所在的进程中有多个线程在同时运行,而这些线程可能会同时运行这段代码。如果每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的。
Java线程池中submit() 和 execute()方法有什么区别?
两个方法都可以向线程池提交任务,execute()方法的返回类型是void,它定义在Executor接口中, 而submit()方法可以返回持有计算结果的Future对象,它定义在ExecutorService接口中,它扩展了Executor接口,其它线程池类像ThreadPoolExecutor和ScheduledThreadPoolExecutor都有这些方法 。
简述一下你对线程池的理解
如果问到了这样的问题,可以展开的说一下线程池如何用、线程池的好处、线程池的启动策略)合理利用线程池能够带来三个好处。 第一:降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。 第二:提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。 第三:提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控
JAVA 后台线程
1. 定义:守护线程--也称“服务线程”, 他是后台线程, 它有一个特性,即为用户线程 提供 公共服务, 在没有用户线程可服务时会自动离开。 2. 优先级:守护线程的优先级比较低,用于为系统中的其它对象和线程提供服务。 3. 设置:通过 setDaemon(true)来设置线程为“守护线程”;将一个用户线程设置为守护线程的方式是在 线程对象创建 之前 用线程对象的setDaemon 方法。 4. 在 Daemon 线程中产生的新线程也是 Daemon 的。 5. 线程则是 JVM 级别的,以 Tomcat 为例,如果你在 Web 应用中启动一个线程,这个线程的生命周期并不会和 Web 应用程序保持同步。也就是说,即使你停止了 Web 应用,这个线程依旧是活跃的。 6. example: 垃圾回收线程就是一个经典的守护线程,当我们的程序中不再有任何运行的Thread,程序就不会再产生垃圾,垃圾回收器也就无事可做, 所以当垃圾回收线程是 JVM 上仅剩的线程时,垃圾回收线程会自动离开。它始终在低级别的状态中运行,用于实时监控和管理系统中的可回收资源。 7. 生命周期:守护进程(Daemon)是运行在后台的一种特殊进程。它独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。也就是说守护线程不依赖于终端,但是依赖于系统,与系统“同生共死”。当 JVM 中所有的线程都是守护线程的时候, JVM 就可以退出了;如果还有一个或以上的非守护线程则 JVM 不会退出 java中的线程分为两种:守护线程(Daemon)和用户线程(User) 任何线程都可以设置为守护线程和用户线程,通过方法 Thread.setDaemon(boolon);true 则把该线程设置为守护线程,反之则为用户线程。 Thread.setDaemon() 必须在 Thread.start()之前调用,否则运行时会抛出异常。 两者的区别: 唯一的区别是判断虚拟机(JVM)何时离开,Daemon 是为其他线程提供服务,如果全部的 User Thread 已经撤离,Daemon 没有可服务的线程,JVM 撤离。也可 以理解为守护线程是 JVM 自动创建的线程(但不一定),用户线程是程序创建的线程;比如 JVM 的垃圾回收线程是一个守护线程,当所有线程已经撤离,不再产 生垃圾,守护线程自然就没事可干了,当垃圾回收线程是 Java 虚拟机上仅剩的线程时,Java 虚拟机会自动离开。 扩展: Thread Dump 打印出来的线程信息,含有 daemon 字样的线程即为守护进程,可能会有:服务守护进程、编译守护进程、windows 下的监听 Ctrl+break的守护进程、Finalizer 守护进程、引用处理守护进程、GC 守护进程。
Condition 类和 Object 类锁方法区别区别
1. Condition 类的 awiat 方法和 Object 类的 wait 方法等效 2. Condition 类的 signal 方法和 Object 类的 notify 方法等效 3. Condition 类的 signalAll 方法和 Object 类的 notifyAll 方法等效 4. ReentrantLock 类可以唤醒指定条件的线程,而 object 的唤醒是随机的
线程基本方法
线程相关的基本方法有 wait, notify, notifyAll, sleep, join, yield 等。
- sleep():强迫一个线程睡眠N毫秒。
- isAlive(): 判断一个线程是否存活。
- join(): 等待线程终止。
- activeCount(): 程序中活跃的线程数。
- enumerate(): 枚举程序中的线程。
- currentThread(): 得到当前线程。
- isDaemon(): 一个线程是否为守护线程。
- setDaemon(): 设置一个线程为守护线程。 (用户线程和守护线程的区别在于,是否等待主线程依赖于主线程结束而结束) 9. setName(): 为线程设置一个名称。
- wait(): 强迫一个线程等待。
11.notify(): 通知一个线程继续运行。- setPriority(): 设置一个线程的优先级。
- getPriority()::获得一个线程的优先级。
上下文切换的活动
1.挂起一个进程,将这个进程在 CPU 中的状态(上下文)存储于内存中的某处。 2.在内存中检索下一个进程的上下文并将其在 CPU 的寄存器中恢复。 3.跳转到程序计数器所指向的位置(即跳转到进程被中断时的代码行),以恢复该进程在程序中。
引起线程上下文切换的原因
1. 当前执行任务的时间片用完之后,系统 CPU 正常调度下一个任务; 2. 当前执行任务碰到 IO 阻塞,调度器将此任务挂起,继续下一任务; 3. 多个任务抢占锁资源,当前任务没有抢到锁资源,被调度器挂起,继续下一任务; 4. 用户代码挂起当前任务,让出 CPU 时间; 5. 硬件中断;
死锁、活锁、饥饿
死锁:是指两个或两个以上的进程(或线程)在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。
产生死锁的必要条件:
1、互斥条件:所谓互斥就是进程在某一时间内独占资源。
2、请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
3、不剥夺条件:进程已获得资源,在末使用完之前,不能强行剥夺。
4、循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。活锁:任务或者执行者没有被阻塞,由于某些条件没有满足,导致一直重复尝试,失败,尝试,失败。
活锁和死锁的区别在于,处于活锁的实体是在不断的改变状态,所谓的“活”, 而处于死锁的实体表现为等待;活锁有可能自行解开,死锁则不能。
饥饿:一个或者多个线程因为种种原因无法获得所需要的资源,导致一直无法执行的状态。
Java 中导致饥饿的原因:
1、高优先级线程吞噬所有的低优先级线程的 CPU 时间。
2、线程被永久堵塞在一个等待进入同步块的状态,因为其他线程总是能在它之前持续地对该同步块进行访问。
3、线程在等待一个本身也处于永久等待完成的对象(比如调用这个对象的 wait 方 法),因为其他线程总是被持续地获得唤醒。
Java 中你怎样唤醒一个阻塞的线程?
在Java发展史上曾经使用suspend()、resume()方法对于线程进行阻塞唤醒,但随之出现很多问题,比较典型的还是死锁问题。解决方案可以使用以对象为目标的阻塞,即利用 Object 类的 wait()和 notify()方法实现线程阻塞。首先,wait、notify 方法是针对对象的,调用任意对象的 wait()方法都将导致线程阻塞,阻塞的同时也将释放该对象的锁,相应地,调用任意对象的 notify()方法则将随机解除该对象阻塞的线程,但它需要重新获取改对象的锁,直到获取成功才能往下执行;其次,wait、notify方法必须在 synchronized 块或方法中被调用,并且要保证同步块或方法的锁对象与调用 wait、notify 方法的对象是同一个,如此一来在调用 wait 之前当前线程就已经成功获取某对象的锁,执行 wait 阻塞后当前线程就将之前获取的对象锁释放。
在 Java 中 CycliBarriar 和 CountdownLatch 有什么区别?
CyclicBarrier可以重复使用,而CountdownLatch不能重复使用。Java的concurrent包里面的CountDownLatch其实可以把它看作一个计数器,只不过这个计数器的操作是原子操作,同时只能有一个线程去操作这个计数器,也就是同时只能有一个线程去减这个计数器里面的值。你可以向 CountDownLatch 对象设置一个初始的数字作为计数值,任何调用这个对象上的 await()方法都会阻塞,直到这个计数器的计数值被其他的线程减为 0 为止。所以在当前计数到达零之前,await 方法会一直受阻塞。之后,会释放所有等待的线程,await 的所有后续调用都将立即返回。这种现象只出现一次——计数无法被重置。如果需要重置计数,请考虑使用 CyclicBarrier。 CountDownLatch 的一个非常典型的应用场景是:有一个任务想要往下执行,但必须要等到其他的任务执行完毕后才可以继续往下执行。假如我们这个想要继续往下执行的任务调用一个 CountDownLatch 对象的 await()方法,其他的任务执行完自己的任务后调用同一个CountDownLatch 对象上的 countDown()方法,这个调用 await()方法的任务将一直阻塞等待,直到这个 CountDownLatch 对象的计数值减到 0 为止。 CyclicBarrier 一个同步辅助类,它允许一组线程互相等待,直到到达某个公共屏障点 (common barrier point)。在涉及一组固定大小的线程的程序中,这些线程必须不时地互相等待,此时 CyclicBarrier 很有用。因为该 barrie在释放等待线程后可以重用,所以称它为循环 的barrier。
Java 中用到的线程调度算法是什么?
计算机通常只有一个 CPU,在任意时刻只能执行一条机器指令,每个线程只有获得CPU 的使用权才能执行指令.所谓多线程的并发运行,其实是指从宏观上看,各个线程轮流获得 CPU 的使用权,分别执行各自的任务.在运行池中,会有多个处于就绪状态的线程在等待 CPU,JAVA 虚拟机的一项任务就是负责线程的调度,线程调度是指按照特定机制为多个线程分配 CPU 的使用权. 有两种调度模型:分时调度模型和抢占式调度模型。分时调度模型是指让所有的线程轮流获得 cpu 的使用权,并且平均分配每个线程占用的CPU 的时间片这个也比较好理解。 java 虚拟机采用抢占式调度模型,是指优先让可运行池中优先级高的线程占用CPU,如果可运行池中的线程优先级相同,那么就随机选择一个线程,使其占用CPU。处于运行状态的线程会一直运行,直至它不得不放弃 CPU。
JVM面试题
JVM执行java代码过程
Java代码是格式为 .java类型的文件,被JVM运行前需要经历编译阶段成为 .class格式文件。当JVM执行 .class文件时会通过字节码执
行引擎执行加载到内存中的类,当这个类被使用时,就会被加载。一个类从加载到使用,一般会经历下面的这个过程:
加载 -› 验证 -› 准备 -› 解析 -› 初始化 -› 使用 -› 卸载
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YL9czSPg-1653308049338)(C:\Users\纵横\AppData\Roaming\Typora\typora-user-images\image-20210816194827922.png)]
![image-20210816194928847]()
JVM虚拟机组成及内存模型
Java虚拟机在执行Java程序的过程中会把它管理的内存划分为若干个不同的数据区域:
1、类加载器:负责把class文件装载到内存中
2、执行引擎:对JVM指令进行解析,翻译成机器码
3、本地方法库:就是一个Java调用非Java代码的接口,一个native方法是指该方法的实现由非Java语言实现,比如用C或C++ 实现。
4、本地方法接口:允许Java代码使用以其他语言编写的native本地方法库
5、垃圾回收器:回收无用对象占用的内存空间
6、运行时数据区:JVM的核心区域,程序运行时的工作区域。JVM运行时数据区共分为虚拟机栈、堆、方法区、程序计数器、本地方
法栈五个部分
a、方法区:即永久代,存放虚拟机加载的类信息、静态变量、常量等数据。是各个线程共享的内存区域,在JDK8中,元空间取代了
方法区,元空间在本地内存区域开辟空间实现方法区,永久代在运行时数据区开辟空间实现方法区,原因是永久代的元
数据信息每次fullgc的时候可能被收集,为永久代分配多少空间很难确定
b、程序计数器:是一块较小的内存空间,它的作用可以看作是当前线程所执行的字节码的行号指示器,每个线程都有一个独立的程
序计数器,每个线程之间的计数器互不影响,独立存储,是线程私有内存,如果正在执行Native方法,那么计数器
为空
c、Java虚拟机栈:同样也是属于线程私有区域,每个线程在创建的时候都会创建一个虚拟机栈,生命周期和线程一致,线程退出
时,线程的虚拟机栈也回收,虚拟机内部保持一个个栈帧,每次方法调用都会进行压栈,JVM堆栈帧的操作只有出
栈和压栈两种,方法调用结束会进行出栈操作,该区域存储着局部变量表、编译期间可知的各种基本数据类型、对
象引用、方法出口等信息
d、本地方法栈与虚拟机栈类似,本地方法栈是在调用本地方法使用的栈,每个线程都有一个本地方法栈
e、Java堆:Java中的堆分为两个不同给区域:新生代和老年代,Java堆是被所有线程共享的一块内存区域,唯一目的就是存放实例
对象,几乎所有的实例对象都在这里分配内存,如果堆中没有内存完成实例分配,并且堆也无法在扩展时会抛出
OutOfMemoryError异常。
Java8和Java7的JVM最大的区别就是在1.8中方法区是由元空间来实现的,常量池移到堆中,1.8不存在方法区,将方法区的实现移除
了,而是在本地内存中加入元空间
虚拟机组成:
内存模型:
![image-20210721204840513]()
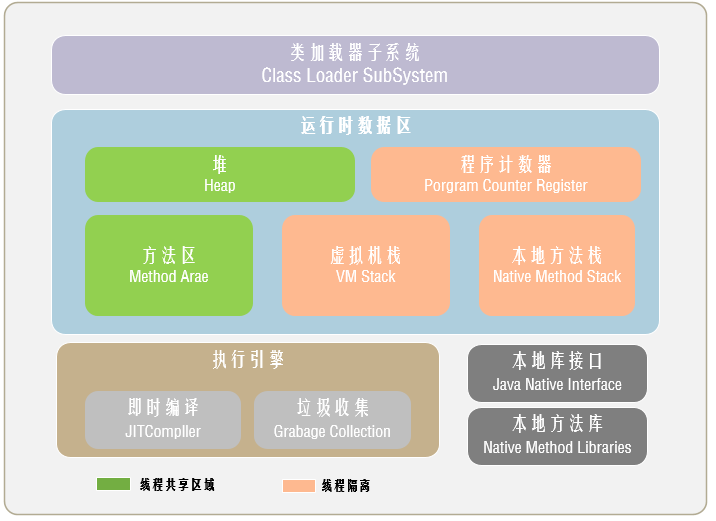

GC垃圾回收机制
在程序运行中,需要占用内存,及时把不在使用的对象占用的内存释放出来,这就是GC要做的事
1、JVM中,程序计数器、虚拟机栈、本地方法栈都是随线程而生随线程而灭的,栈帧随着方法的进入和退出做入栈和出栈操作,实
现了自动的内存清理,因此,我们的垃圾回收主要集中于Java堆和方法区中,在程序运行期间,这部分内存的分配都是动态的
2、需要回收的对象就是已经没有存活的对象,判断一个对象是否存活常用的方法有两种:引用计数法和可达性分析法
a、引用计数法:
每个对象有一个引用计数属性,新增一个引用时计数加1,引用释放时计数减1,计数为0时进行回收。这个方法简单,无法解决对象
相互循环引用的问题
b、可达性分析:
通过判断对象的引用链是否可达决定对象是否要被回收。通过从GC Roots开始向下搜索,搜索所走过的路径称为引用链。当一个对
象到GC Roots没有任何引用链相连时,则证明次对象是不可达的。即认为它不可用
3、目前GC的主流回收算法是分代收集算法,这是一种组合的回收机制。将不同生命周期的对象分配到堆中的不同区域,采用不同的
垃圾回收算法,提高JVM垃圾回收效率
对象生命周期被分为年轻代和年老代:
a、其中年轻代分为Eden区和Survivor From、Survivor To区
b、对象刚被创建的时候,存放在Eden区,Eden区满了后就会触发Minor GC,将可用对象复制到Survivor From区,并将Eden区清
空,这样Eden区又可以存放新创建的对象
c、当Eden再次满的时候,就会再次触发Minor GC,将可用对象存入Survivor To区,并清除Eden区和Survivor From区,下一次
Minor GC再将可用对象存入Survivor From区,如此往复循环
d、每次Minor GC存活下来的对象年龄+1,年龄增加到一定程度的对象,将会被放到年老代
e、年老代是通过Major GC或Full GC进行回收的。Major GC只对年轻代进行回收而Full GC是对整个堆进行回收的
4、GC触发机制(清理垃圾)
a、程序调用system.gc时
b、系统自身决定GC触发的时机
5、Full GC触发条件(清理整个堆内存)
a、老年代、方法区内存不足
b、新生代内存设置过大(老年代内存不足)或过小(GC次数频繁,小号系统性能;大量对象进入老年代,占据空间,诱发Full
GC)
c、survivor设置过大(eden过小,增加了GC频率)或过小(直接从eden达到了老年代)
6、Minor GC触发条件(GC年轻代空间,复制算法)
当Eden区满时,进行Minor GC然后会将存活下来的对象放入From survivor区中(Object header对象头中有个分代年龄,存活分
代年龄就会+1)。当From survivor 满时,还存活的对象会放入To survivor区中。当To survivor满时,再Minnor GC将存活的对象
转到空的From survivor中。无法放入survivor的对象会放入老年代中,经过多次Minor GC 之后,默认15次还存活的对象会放入老年
代。这里用到了GC的复制算法。
垃圾收集器
Java 堆内存被划分为新生代和年老代两部分,新生代主要使用复制和标记-清除垃圾回收算法;年老代主要使用标记-整理垃圾回收算
法
Serial收集器(单线程、复制算法):
Serial(英文连续) 是最基本垃圾收集器,使用复制算法,曾经是JDK1.3.1 之前新生代唯一的垃圾收集器。 Serial 是一个单线程的收
集器,它不但只会使用一个 CPU 或一条线程去完成垃圾收集工作,并且在进行垃圾收集的同时,必须暂停其他所有的工作线程,直
到垃圾收集结束。Serial 垃圾收集器虽然在收集垃圾过程中需要暂停所有其他的工作线程,但是它简单高效,对于限定单个 CPU 环
境来说,没有线程交互的开销,可以获得最高的单线程垃圾收集效率,因此 Serial垃圾收集器依然是 java 虚拟机运行在 Client 模式
下默认的新生代垃圾收集器
ParNew收集器(Serial+多线程):
ParNew 垃圾收集器其实是 Serial 收集器的多线程版本,也使用复制算法,除了使用多线程进行垃圾收集之外,其余的行为和 Serial
收集器完全一样, ParNew 垃圾收集器在垃圾收集过程中同样也要暂停所有其他的工作线程。
ParNew 收集器默认开启和 CPU 数目相同的线程数,可以通过-XX:ParallelGCThreads 参数来限制垃圾收集器的线程数。
ParNew 虽然是除了多线程外和Serial 收集器几乎完全一样,但是ParNew垃圾收集器是很多 java虚拟机运行在 Server 模式下新生代
的默认垃圾收集器。
Parallel Scavenge收集器(多线程复制算法、高效):
Parallel Scavenge 收集器也是一个新生代垃圾收集器,同样使用复制算法,也是一个多线程的垃圾收集器, 它重点关注的是程序达
到一个可控制的吞吐量(Thoughput, CPU 用于运行用户代码的时间/CPU 总消耗时间,即吞吐量=运行用户代码时间/(运行用户代
码时间+垃圾收集时间)),高吞吐量可以最高效率地利用 CPU 时间,尽快地完成程序的运算任务,主要适用于在后台运算而不需要
太多交互的任务。 自适应调节策略也是 ParallelScavenge 收集器与 ParNew 收集器的一个重要区别
Serial Old收集器(单线程标记整理算法)
Serial Old 是 Serial 垃圾收集器年老代版本,它同样是个单线程的收集器,使用标记-整理算法,这个收集器也主要是运行在 Client
默认的java 虚拟机默认的年老代垃圾收集器。在 Server 模式下,主要有两个用途:
1、在 JDK1.5 之前版本中与新生代的 Parallel Scavenge 收集器搭配使用
新生代 Parallel Scavenge 收集器与 ParNew 收集器工作原理类似,都是多线程的收集器,都使用的是复制算法,在垃圾收集过程中
都需要暂停所有的工作线程。
Parallel Old收集器(多线程标记整理算法)
Parallel Old 收集器是Parallel Scavenge的年老代版本,使用多线程的标记-整理算法,在 JDK1.6才开始提供。在 JDK1.6 之前,新生
代使用 ParallelScavenge 收集器只能搭配年老代的 Serial Old 收集器,只能保证新生代的吞吐量优先,无法保证整体的吞吐量,
Parallel Old 正是为了在年老代同样提供吞吐量优先的垃圾收集器, 如果系统对吞吐量要求比较高,可以优先考虑新生代Parallel
Scavenge和年老代 Parallel Old 收集器的搭配策略
CMS收集器(多线程标记整理算法):
Concurrent mark sweep(CMS)收集器是一种年老代垃圾收集器,其最主要目标是获取最短垃圾回收停顿时间, 和其他年老代使用
标记-整理算法不同,它使用多线程的标记-清除算法。最短的垃圾收集停顿时间可以为交互比较高的程序提高用户体验。CMS 工作机
制相比其他的垃圾收集器来说更复杂。整个过程分为以下 4 个阶段:
1、初始标记
只是标记一下 GC Roots 能直接关联的对象,速度很快,仍然需要暂停所有的工作线程
2、并发标记
进行 GC Roots 跟踪的过程,和用户线程一起工作,不需要暂停工作线程
3、重新标记
为了修正在并发标记期间,因用户程序继续运行而导致标记产生变动的那一部分对象的标记记录,仍然需要暂停所有的工作线程
4、并发清除
清除 GC Roots 不可达对象,和用户线程一起工作,不需要暂停工作线程。由于耗时最长的并发标记和并发清除过程中,垃圾收集线
程可以和用户现在一起并发工作, 所以总体上来看CMS 收集器的内存回收和用户线程是一起并发地执行。
G1收集器:
Garbage first 垃圾收集器是目前垃圾收集器理论发展的最前沿成果,相比与 CMS 收集器, G1 收集器两个最突出的改进是:
1、基于标记-整理算法,不产生内存碎片
2、可以非常精确控制停顿时间,在不牺牲吞吐量前提下,实现低停顿垃圾回收。G1 收集器避免全区域垃圾收集,它把堆内存划分
为大小固定的几个独立区域,并且跟踪这些区域的垃圾收集进度,同时在后台维护一个优先级列表,每次根据所允许的收集时
间, 优先回收垃圾最多的区域。区域划分和优先级区域回收机制,确保 G1 收集器可以在有限时间获得最高的垃圾收集效率
垃圾回收算法
常用算法:
标记-清除算法(mark-sweep)、复制算法(copying)以及标记整理算法、分代收集算法
root对象:
a、被栈中的变量(栈中存的是对象的引用)所引用的对象
b、被static修饰的变量所引用的对象
可访问对象:
如果栈中有一个变量a引用了一个对象,那么该对象是可访问的,如果该对象中的某一个字段引用了另一个对象b,那么b也是可访问
的。可访问的对象也称之为live对象
基本概念:
a、mutator和collector:这两个名词经常在垃圾收集算法中出现,collector指的就是垃圾收集器,而mutator是指除了垃圾收集器
之外的部分,比如说我们应用程序本身。mutator的职责一般是NEW(分配内存),READ(从内存中读取内容),WRITE(将内容写入内存),
而collector则就是回收不再使用的内存来供mutator进行NEW操作的使用。
b、mutator roots(mutator根对象):mutator根对象一般指的是分配在堆内存之外,可以直接被mutator直接访问到的对象,一般
是指静态/全局变量以及Thread-Local变量(在Java中,存储在java.lang.ThreadLocal中的变量和分配在栈上的变量 - 方法内部的临时
变量等都属于此类).
c、可达对象的定义:从mutator根对象开始进行遍历,可以被访问到的对象都称为是可达对象。这些对象也是mutator(你的应用程
序)正在使用的对象。
标记清除算法:
顾名思义,标记-清除算法分为两个阶段,标记(mark)和清除(sweep).
在标记阶段,collector从mutator根对象开始进行遍历,对从mutator根对象可以访问到的对象都打上一个标识,一般是在对象的
header中,将其记录为可达对象。
而在清除阶段,collector对堆内存(heap memory)从头到尾进行线性的遍历,如果发现某个对象没有标记为可达对象-通过读取对象
的header信息,则就将其回收。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PtuOR4YB-1653308049339)(C:\Users\纵横\AppData\Roaming\Typora\typora-user-images\image-20210825142842823.png)]
在Mark阶段,从根对象1可以访问到B对象,从B对象又可以访问到E对象,所以B,E对象都是可达的。同理,F,G,J,K也都是可达对象。
到了Sweep阶段,所有非可达对象都会被collector回收。同时,Collector在进行标记和清除阶段时会将整个应用程序暂停
(mutator),等待标记清除结束后才会恢复应用程序的运行,这也是Stop-The-World这个单词的来历。
主要不足有两个:
a、效率问题,标记和清除两个过程的效率都不高
b、空间问题,标记清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致以后在程序运行过程中需要分配较大对象时,
无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。 标记—清除算法的执行过程如下图所示。
复制算法:
将内存容量分成大小相等的两块,每次只使用其中一块,当一块用完时,将还存活的对象复制到另一块去,然后把之前使用满的那块空间一次性清理掉,如此反复。
优点:内存分配的时候不用考虑内存碎片问题,只移动堆顶指针,按顺序分配即可,简单高效。
缺点:内存空间浪费大,每次只能使用当前 能够使用 内存空间的一半;当对象存活率较高时,需要有大量的复制操作,效率低。
标记整理算法:
标记整理是在标记-清除上改进得来,前面说到标记-清除内存碎片的问题,在标记-整理中有解决。同样有标记阶段,标记出所有需要
回收的对象,但是不会直接清理,而是将存活的对象向一端移动,在移动过程中清理掉可回收对象。
优点:解决了之前内存碎片的问题,特别是在存活率高的时候,效率远高于复制算法。
分代收集算法:
根据内存对象的存活周期不同,将内存划分成几块,java虚拟机中一般将内存划分成新生代和老年代,当新建对象时一般在新生代中
分配内存,在新生代垃圾收集器回收几次后仍然存活的对象,将被移动到老年代,或者当大的对象在新生代中无法分配到足够连续的
内存空间时也会直接分配到老年代
1、新生代
采用复制标记-清除算法收集垃圾,在新生代中存在大量短生命周期的对象,所以不需要讲新生代容量等量化分,而是将新生代划分
为Eden、survivor from、survivor to 三部分,其中新生代内存容量的默认比例是8:1:1。survivor from和survivor to区域中总有
一个是空白的,只有Eden和其中一个survior也就是总容量的90%会被用来为新对象的撞见分配内存。这样内存浪费就少了。当新生
代的内存空间分配不足时,仍然存活的对象会被分配到空白的survior内存区域中。Eden和非空白的survivor会被标记回收,两个
survivor交换使用
jvm对新生代的垃圾回收称为Minor GC,次数频繁,每次回收时间也短
-Xmn 设置新生代内存大小
2、老年代
老年代存活率一般比较高,所以采用标记-整理算法进行垃圾收集效率会比较高。
jvm对老年代垃圾回收称为MajorGC/Full GC,次数相对比较少,每次回收的时间也比较长。
当新生代中无足够空间为对象分配内存,老年代内存也无法回收到足够的空间时,堆会产生OOM异常。
内存堆分代
堆是被线程共享的一块内存区域, 创建的对象和数组都保存在 Java 堆内存中,也是垃圾收集器进行垃圾收集的最重要的内存区域。
由于现代VM 采用分代收集算法, 因此 Java 堆从 GC 的角度还可以细分为: 新生代(Eden 区、 From Survivor 区和 To Survivor 区)和
老年代
新生代是用来存放新生的对象。一般占据堆的1/3空间。由于频繁创建对象,所以新生代会频繁触发MinorGC 进行垃圾回收。新生代
又分为 Eden区、 ServivorFrom、 ServivorTo 三个区
Eden 区:
Java 新对象的出生地(如果新创建的对象占用内存很大,则直接分配到老年代)。当 Eden区内存不够的时候就会触发 MinorGC,
对新生代区进行一次垃圾回收
ServivorFrom :
上一次 GC 的幸存者,作为这一次 GC 的被扫描者
ServivorTo :
保留了一次 MinorGC 过程中的幸存者
MinorGC 的过程(复制->清空->互换):
老年代主要存放应用程序中生命周期长的内存对象
老年代的对象比较稳定,所以 MajorGC 不会频繁执行。在进行 MajorGC 前一般都先进行了一次 MinorGC,使得有新生代的对象晋
身入老年代,导致空间不够用时才触发。当无法找到足够大的连续空间分配给新创建的较大对象时也会提前触发一次 MajorGC 进行
垃圾回收腾出空间。老年代是内存的永久保存区域,主要存放 Class 和 Meta(元数据)的信息,Class 在被加载的时候被放入永久
区域, 它和存放实例的区域不同,GC不会在主程序运行期对永久区域进行清理。所以这也导致了永久代的区域会随着加载的 Class
的增多而胀满,最终抛出 OOM 异常
元数据区:
在 Java8 中, 永久代已经被移除,被一个称为“元数据区”(元空间)的区域所取代。元空间的本质和永久代类似,元空间与永久代之
间最大的区别在于: 元空间并不在虚拟机中,而是使用本地内存。因此,默认情况下,元空间的大小仅受本地内存限制。 类的元数
据放入nativememory,字符串池和类的静态变量放入 java 堆中, 这样可以加载多少类的元数据就不再由MaxPermSize 控制, 而
由系统的实际可用空间来控制
内存泄漏
java导致内存泄露的原因很明确:长生命周期的对象持有短生命周期对象的引用就很可能发生内存泄露,尽管短生命周期对象已经不
再需要,但是因为长生命周期对象持有它的引用而导致不能被回收,这就是java中内存泄露的发生场景
1、集合类,集合类仅仅有添加元素的方法,而没有相应的删除机制,导致内存被占用。这一点其实也不明确,这个集合类如果仅仅
是局部变量,根本不会造成内存泄露,在方法栈退出后就没有引用了会被jvm正常回收。而如果这个集合类是全局性的变量(比
如类中的静态属性,全局性的map等即有静态引用或final一直指向它),那么没有相应的删除机制,很可能导致集合所占用的内
存只增不减,因此提供这样的删除机制或者定期清除策略非常必要
2、单例模式。不正确使用单例模式是引起内存泄露的一个常见问题,单例对象在被初始化后将在JVM的整个生命周期中存在(以静
态变量的方式),如果单例对象持有外部对象的引用,那么这个外部对象将不能被jvm正常回收,导致内存泄露
3、静态集合HashMap、Vector等的使用最容易出现内存泄漏,这些静态变量的生命周期和应用程序一致,所有的对象都不能被释
放
4、各种数据连接、网络连接、io连接等没有显示的调用close关闭,不能被GC回收导致内存泄漏
5、监听器的使用,在释放的对象没有删除相应的监听器也可能导致内存泄漏
注意事项:在代码复审的时候关注长生命周期对象:全局性的集合、单例模式的使用、类的static变量等等。在Java的实现过程中,
也要考虑其对象释放,最好的方法是在不使用某对象时,显式地将此对象赋空。最好遵循谁创建谁释放的原则
类加载机制
JVM 类加载过程分为五个部分:加载、验证、准备、解析、初始化
加载过程:
a、通过一个类的全限定名来获取定义此类的二进制字节流
b、将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构
c、在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口
注意这里不一定非得要从一个 Class 文件获取,这里既可以从 ZIP 包中读取(比如从 jar 包和 war 包中读取),也可以在运行时计算
生成(动态代理),也可以由其它文件生成(比如将 JSP 文件转换成对应的 Class 类)
验证过程:
这一阶段的主要目的是为了确保 Class 文件的字节流中包含的信息是否符合当前虚拟机的要求,并且不会危害虚拟机自身的安全
a、文件格式验证
b、元数据验证
c、字节码验证
d、符号引用验证
准备过程:
准备阶段是正式为类变量分配内存并设置类变量的初始值阶段,即在方法区中分配这些变量所使用的内存空间
解析过程:
解析阶段是指虚拟机将常量池中的符号引用替换为直接引用的过程。符号引用就是 class 文件中的常量池项目类型,如:
CONSTANT_Class_info、CONSTANT_Field_info、CONSTANT_Method_info等类型。
–>符号引用
符号引用与虚拟机实现的布局无关, 引用的目标并不一定要已经加载到内存中。 各种虚拟机实现的内存布局可以各不相同,但是它
们能接受的符号引用必须是一致的,因为符号引用的字面量形式明确定义在 Java 虚拟机规范的 Class 文件格式中
–>直接引用
直接引用可以是指向目标的指针,相对偏移量或是一个能间接定位到目标的句柄。如果有了直接引用,那引用的目标必定已经在内存
中存在
初始化 :
根据程序员通过程序编码指定的主观计划去初始化类变量和其他资源,更直接的表述为:初始化阶段就是执行类构造器()
方法的过程
类构造器 :
初始化阶段是执行类构造器方法的过程。 方法是由编译器自动收集类中的类变量的赋值操作和静态语句块中的语句合并而成的。虚
拟机会保证子方法执行之前,父类的方法已经执行完毕, 如果一个类中没有对静态变量赋值也没有静态语句块,那么编译器可以不
为这个类生成()方法。注意以下几种情况不会执行类初始化:
a、通过子类引用父类的静态字段,只会触发父类的初始化,而不会触发子类的初始化
b、定义对象数组,不会触发该类的初始化
c、常量在编译期间会存入调用类的常量池中,本质上并没有直接引用定义常量的类,不会触发定义常量所在的类
d、通过类名获取 Class 对象,不会触发类的初始化
e、通过 Class.forName 加载指定类时,如果指定参数 initialize为false时,也不会触发类初始化,其实这个参数是告诉虚拟机,是
否要对类进行初始化
f、通过 ClassLoader 默认的 loadClass 方法,也不会触发初始化动作
类加载过程是由类加载器完成的,类加载器包括:
启动类加载器(BootStrap Class Loader):
负责加载 JAVA_HOME\lib 目录中的, 或通过-Xbootclasspath 参数指定路径中的, 且被虚拟机认可(按文件名识别, 如 rt.jar)的
类
扩展类加载器(Extension ClassLoader):
负责加载 JAVA_HOME\lib\ext 目录中的,或通过 java.ext.dirs 系统变量指定路径中的类库
应用程序类加载器(Application ClassLoader):
负责加载用户路径(classpath)上的类库。JVM通过双亲委派模型进行类的加载,当然我们也可以通过继承java.lang.ClassLoader
实现自定义的类加载器
用户自定义类加载器(java.lang.ClassLoader 的子类)
双亲委派模型工作过程:
如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次
的类加载器都是如此,一次所有的类加载请求最终都应该传送到最顶层的启动类加载器中,只有当父类加载器反馈自己无法完成这个
加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会区尝试自己去完成加载
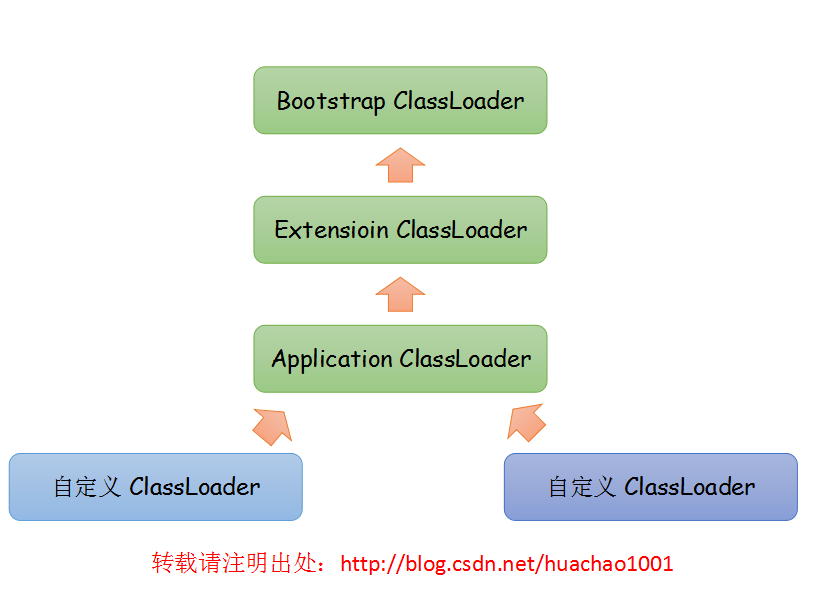
JVM调优
JVM工作机制:
Javac执行原理:
JVM结构:
JVM共享数据空间:
何时进行JVM调优:
遇到以下情况,就需要考虑进行JVM调优了:
- Heap内存(老年代)持续上涨达到设置的最大内存值;
- Full GC 次数频繁;
- GC 停顿时间过长(超过1秒);
- 应用出现OutOfMemory 等内存异常;
- 应用中有使用本地缓存且占用大量内存空间;
- 系统吞吐量与响应性能不高或下降。
JVM调优的基本原则:
JVM调优是一个手段,但并不一定所有问题都可以通过JVM进行调优解决,因此,在进行JVM调优时,我们要遵循一些原则:
- 大多数的Java应用不需要进行JVM优化;
- 大多数导致GC问题的原因是代码层面的问题导致的(代码层面);
- 上线之前,应先考虑将机器的JVM参数设置到最优;
- 减少创建对象的数量(代码层面);
- 减少使用全局变量和大对象(代码层面);
- 优先架构调优和代码调优,JVM优化是不得已的手段(代码、架构层面);
- 分析GC情况优化代码比优化JVM参数更好(代码层面);
通过以上原则,我们发现,其实最有效的优化手段是架构和代码层面的优化,而JVM优化则是最后不得已的手段,也可以说是对服务器配置的最后一次“压榨”。
JVM调优目标:
调优的最终目的都是为了令应用程序使用最小的硬件消耗来承载更大的吞吐。jvm调优主要是针对垃圾收集器的收集性能优化,令运行在虚拟机上的应用能够使用更少的内存以及延迟获取更大的吞吐量。
- 延迟:GC低停顿和GC低频率;
- 低内存占用;
- 高吞吐量;
其中,任何一个属性性能的提高,几乎都是以牺牲其他属性性能的损为代价的,不可兼得。具体根据在业务中的重要性确定。
JVM调优量化目标:
下面展示了一些JVM调优的量化目标参考实例:
- Heap 内存使用率 <= 70%;
- Old generation内存使用率<= 70%;
- avgpause <= 1秒;
- Full gc 次数0 或 avg pause interval >= 24小时 ;
注意:不同应用的JVM调优量化目标是不一样的。
JVM调优的步骤:
一般情况下,JVM调优可通过以下步骤进行:
- 分析GC日志及dump文件,判断是否需要优化,确定瓶颈问题点;
- 确定JVM调优量化目标;
- 确定JVM调优参数(根据历史JVM参数来调整);
- 依次调优内存、延迟、吞吐量等指标;
- 对比观察调优前后的差异;
- 不断的分析和调整,直到找到合适的JVM参数配置;
- 找到最合适的参数,将这些参数应用到所有服务器,并进行后续跟踪。
以上操作步骤中,某些步骤是需要多次不断迭代完成的。一般是从满足程序的内存使用需求开始的,之后是时间延迟的要求,最后才是吞吐量的要求,要基于这个步骤来不断优化,每一个步骤都是进行下一步的基础,不可逆行之。
查看GC日志:
新生代使用的是PS Young Generation回收器,也就是Parallel Scavenge回收器,特点是使用复制算法的多线程serial回收器,跟perNew区别是更注重程序的吞吐量,吞吐量是要尽量保证系统运行时间,减少垃圾回收时间。在回收时会暂停所有的用户线程。老年代使用的是PS Old Generation回收器,也就是Parallel Scavenge的年老代版本,使用的是标记整理算法。其他特点见新生代。
调优命令:
参数 说明 实例 -Xms 初始堆大小,默认物理内存的1/64 -Xms512M -Xmx 最大堆大小,默认物理内存的1/4 -Xms2G -Xmn 新生代内存大小,官方推荐为整个堆的3/8 -Xmn512M -Xss 线程堆栈大小,jdk1.5及之后默认1M,之前默认256k -Xss512k -XX:NewRatio=n 设置新生代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4 -XX:NewRatio=3 -XX:SurvivorRatio=n 年轻代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:8,表示Eden:Survivor=8:1:1,一个Survivor区占整个年轻代的1/8 -XX:SurvivorRatio=8 -XX:PermSize=n 永久代初始值,默认为物理内存的1/64 -XX:PermSize=128M -XX:MaxPermSize=n 永久代最大值,默认为物理内存的1/4 -XX:MaxPermSize=256M -verbose:class 在控制台打印类加载信息 -verbose:gc 在控制台打印垃圾回收日志 -XX:+PrintGC 打印GC日志,内容简单 -XX:+PrintGCDetails 打印GC日志,内容详细 -XX:+PrintGCDateStamps 在GC日志中添加时间戳 -Xloggc:filename 指定gc日志路径 -Xloggc:/data/jvm/gc.log -XX:+UseSerialGC 年轻代设置串行收集器Serial -XX:+UseParallelGC 年轻代设置并行收集器Parallel Scavenge -XX:ParallelGCThreads=n 设置Parallel Scavenge收集时使用的CPU数。并行收集线程数。 -XX:ParallelGCThreads=4 -XX:MaxGCPauseMillis=n 设置Parallel Scavenge回收的最大时间(毫秒) -XX:MaxGCPauseMillis=100 -XX:GCTimeRatio=n 设置Parallel Scavenge垃圾回收时间占程序运行时间的百分比。公式为1/(1+n) -XX:GCTimeRatio=19 -XX:+UseParallelOldGC 设置老年代为并行收集器ParallelOld收集器 -XX:+UseConcMarkSweepGC 设置老年代并发收集器CMS -XX:+CMSIncrementalMode 设置CMS收集器为增量模式,适用于单CPU情况
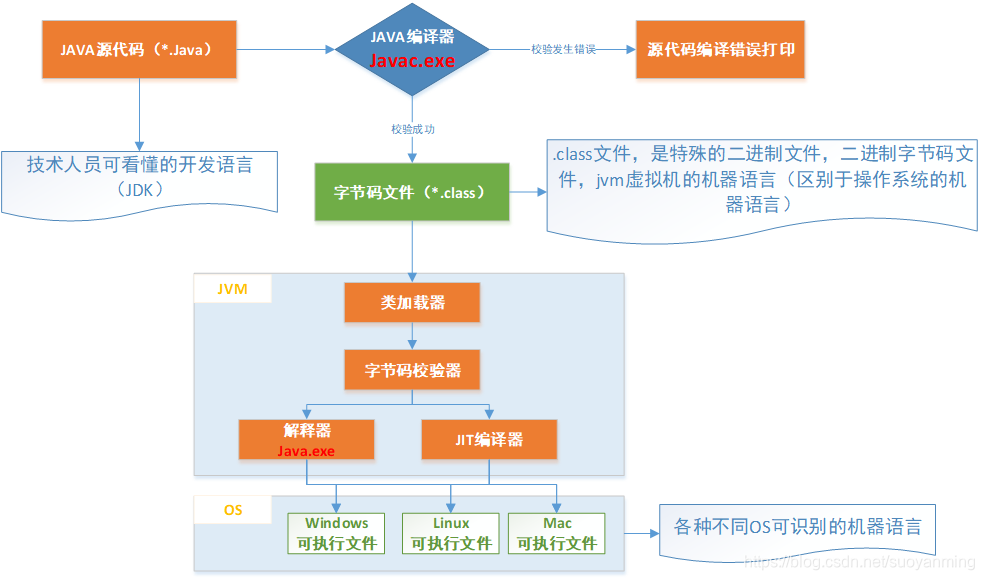
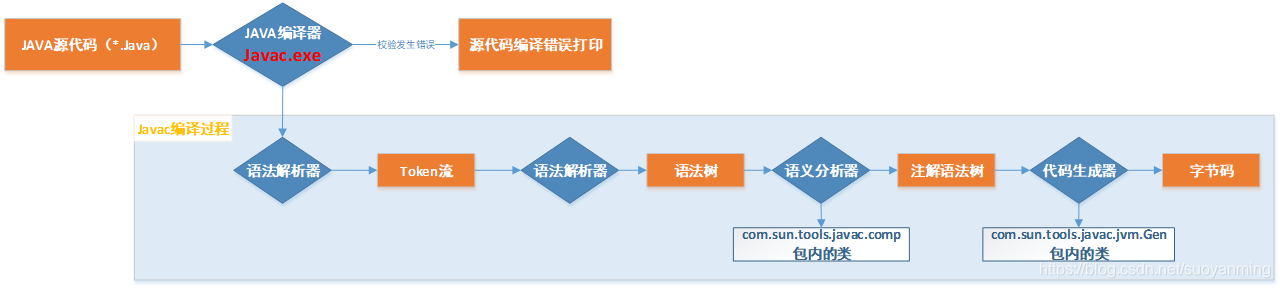
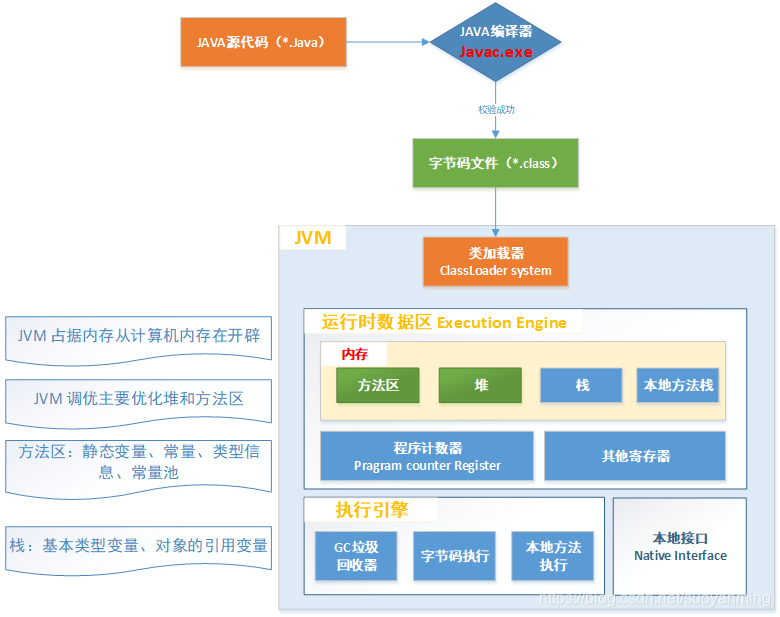


程序使用的内存和堆大小
可以通过 java.lang.Runtime 类中与内存相关方法来获取剩余的内存,总内存及最大堆内存。通过这些方法你也可以获取到堆使用的
百分比及堆内存的剩余空间。
Runtime.freeMemory() 方法返回剩余空间的字节数
Runtime.totalMemory()方法总内存的字节数
Runtime.maxMemory() 返回最大内存的字节数
新生代与复制算法
目前大部分 JVM 的 GC 对于新生代都采取 Copying 算法,因为新生代中每次垃圾回收都要回收大部分对象,即要复制的操作比较
少,但通常并不是按照 1:1 来划分新生代。一般将新生代划分为一块较大的 Eden 空间和两个较小的 Survivor 空间(From Space,
To Space),每次使用Eden 空间和其中的一块 Survivor 空间,当进行回收时,将该两块空间中还存活的对象复制到另一块 Survivor
空间中
老年代与标记复制算法
老年代因为每次只回收少量对象,因而采用 Mark-Compact 算法
a、JAVA 虚拟机提到过的处于方法区的永生代(Permanet Generation), 它用来存储 class 类,常量,方法描述等。对永生代的回收
主要包括废弃常量和无用的类
b、对象的内存分配主要在新生代的 Eden Space 和 Survivor Space 的 From Space(Survivor 目前存放对象的那一块),少数情况会
直接分配到老生代
c、当新生代的 Eden Space 和 From Space 空间不足时就会发生一次 GC,进行 GC 后, EdenSpace 和 From Space 区的存活对象
会被挪到 To Space,然后将 Eden Space 和 FromSpace 进行清理
d、如果 To Space 无法足够存储某个对象,则将这个对象存储到老生代
e、在进行 GC 后,使用的便是 Eden Space 和 To Space 了,如此反复循环
f、当对象在 Survivor 区躲过一次 GC 后,其年龄就会+1。 默认情况下年龄到达 15 的对象会被移到老生代中
堆和栈的区别
栈是运行时单位,代表着逻辑,内含基本数据类型和堆中对象引用,所在区域连续,没有碎片;堆是存储单位,代表着数据,可被多
个栈共享(包括成员中基本数据类型、引用和引用对象),所在区域不连续,会有碎片
1、功能不同
栈内存用来存储局部变量和方法调用,而堆内存用来存储Java中的对象。无论是成员变量,局部变量,还是类变量,它们指向的对象
都存储在堆内存中
2、共享性不同
栈内存是线程私有的。堆内存是所有线程共有的
3、异常错误不同
如果栈内存或者堆内存不足都会抛出异常
栈空间不足:java.lang.StackOverFlowError
堆空间不足:java.lang.OutOfMemoryError
4、空间大小
栈的空间大小远远小于堆的
对象分配规则
1、对象优先分配在Eden区,如果Eden区没有足够的空间时,虚拟机执行一次Minor GC
2、大对象直接进入老年代(大对象是指需要大量连续内存空间的对象)。这样做的目的是避免在Eden区和两个Survivor区之间发生
大量的内存拷贝(新生代采用复制算法收集内存)
3、长期存活的对象进入老年代。虚拟机为每个对象定义了一个年龄计数器,如果对象经过了1次Minor GC那么对象会进入Survivor
区,之后每经过一次Minor GC那么对象的年龄加1,知道达到阀值15次对象进入老年区
4、动态判断对象的年龄。如果Survivor区中相同年龄的所有对象大小的总和大于Survivor空间的一半,年龄大于或等于该年龄的对
象可以直接进入老年代
5、空间分配担保。每次进行Minor GC时,JVM会计算Survivor区移至老年区的对象的平均大小,如果这个值大于老年区的剩余值大
小则进行一次Full GC,如果小于检查HandlePromotionFailure设置,如果true则只进行Monitor GC,如果false则进行Full GC
Java对象结构及创建过程
对象结构:
Java对象由三个部分组成:对象头、实例数据、对齐填充
对象头:由两部分组成,第一部分存储对象自身的运行时数据:哈希码、GC分代年龄、锁标识状态、线程持有的锁、偏向线程
ID(一般占32/64 bit)。第二部分是指针类型,指向对象的类元数据类型(即对象代表哪个类)。如果是数组对象,则对象
头中还有一部分用来记录数组长度
实例数据:用来存储对象真正的有效信息(包括父类继承下来的和自己定义的)
对齐填充:JVM要求对象起始地址必须是8字节的整数倍(8字节对齐 )
创建过程:
1、JVM遇到一条新建对象的指令时首先去检查这个指令的参数是否能在常量池中定义到一个类的符号引用。然后加载这个类(类加
载过程在后边讲)
2、为对象分配内存。一种办法“指针碰撞”、一种办法“空闲列表”,最终常用的办法“本地线程缓冲分配(TLAB)”
3、将除对象头外的对象内存空间初始化为0
4、对对象头进行必要设置
Mysql面试题
Mysql中的数据类型
分类 类型名称 说明 整数类型 tinyInt 很小的整数(8位二进制) smallint 小的整数(16位二进制) mediumint 中等大小的整数(24位二进制) int(integer) 普通大小的整数(32位二进制) 小数类型 float 单精度浮点数 double 双精度浮点数 decimal(m,d) 压缩严格的定点数 日期类型 year YYYY 1901~2155 time HH:MM:SS -838:59:59~838:59:59 date YYYY-MM-DD 1000-01-01~9999-12-3 datetime YYYY-MM-DD HH:MM:SS 1000-01-01 00:00:00~ 9999-12-31 23:59:59 timestamp YYYY-MM-DD HH:MM:SS 19700101 00:00:01 UTC~2038-01-19 03:14:07UTC 文本、二进制类型 CHAR(M) M为0~255之间的整数 VARCHAR(M) M为0~65535之间的整数 TINYBLOB 允许长度0~255字节 BLOB 允许长度0~65535字节 MEDIUMBLOB 允许长度0~167772150字节 LONGBLOB 允许长度0~4294967295字节 TINYTEXT 允许长度0~255字节 TEXT 允许长度0~65535字节 MEDIUMTEXT 允许长度0~167772150字节 LONGTEXT 允许长度0~4294967295字节 VARBINARY(M) 允许长度0~M个字节的变长字节字符串 BINARY(M) 允许长度0~M个字节的定长字节字符串
缓冲池Buffer pool
mysql中对于使用Innodb作为存储引擎的表来说,数据都是以页的形式存储在表空间里,我们知道磁盘访问速度很慢,所以为了提高
速度,当访问某个页上面的数据时。先将这个页加载到内存中缓存起来,就可以对数据进行读写操作了,下次再访问就不需要再次去
磁盘里找了,提高效率。这个内存就是buffer pool 缓存池
Buffer pool组成:
buffer pool中包含了insert buffer、索引和数据、锁信息等
buffer pool默认的缓存页和磁盘页大小一样为16k,为了更好的管理这些页,给每个页设置一个控制信息块,每个页对应一个控制
块,这个控制块记录了该页所属的表空间号页号,缓存页在buffer pool中的地址等信息结构如下:
1、free 链表
free链表是记录那些空闲的缓存页的,把空闲的缓存页对应的控制块作为一个节点插入到free链表中,每当从磁盘中加载一个页到内
存中的时候,就从这个链表中取出一个空闲缓存页,先将磁盘中的这个页的信息(表空间号、页号)写入到这个空闲缓存页所对应的控
制块中,然后将这个节点从链表中pop出,表示这个页已经被使用了
2、flush链表
如果对一个缓存页上的某个数据进行修改,那么缓存页和磁盘页上的数据就不一样了,这个页就称之为脏页,那么如何处理脏页呢?
最简单的办法就一旦产生脏页,就将数据同步到磁盘上,但是缺点是产生大量的磁盘io,所以每次修改缓存页里的数据时,不着急每
次都同步数据,而是在未来的某个时间点进行刷盘
如果不立刻同步数据到磁盘的话,那么buffer pool中的缓存页有的是脏页有的不是脏页,如何判断哪些是脏页哪些不是呢?flush链
表就是来干这个事的
Innodb修改数据的时候是write ahead log 机制,即先写log再写数据,目的是为了保证操作的持久化,大概是先将对数据的改动写
入到 log buffer 中,然后再在内存中记录数据的变化。写入 log buffer 后就会将这个缓存页对应的控制块加入到 flush链表上,表示
这个页 就是一个脏页了,后面刷新脏页的时候就知道哪些页是脏页了。lush链表结构如下:
3、LRU链表
buffer pool大小是有限制的,如果内存不够用了,那么应该淘汰一些不怎么经常被访问的缓存页,把这些就的缓存页从buffer pool
中删除,再加载新的页到buffer pool中。那么如何计算哪些页最近频繁使用哪些页最近很少使用呢?LRU链表就是这个作用
4、刷新脏页到磁盘
之前提过缓冲池中产生了脏页,那么是如果将脏页同步到磁盘中的呢?分几种情况:
a、redolog日志满了,那么系统会停止所有更新操作,checkpoint往前推进,对应的所有脏页要flush到磁盘上
b、buffer pool 不够用了,那么要先将脏页写入到磁盘。如果没有可用的缓存页了,那么会将LRU链表尾部淘汰一些页,如果这些页
是脏页,那么就刷新到磁盘变成干净的页才能被复用
c、系统空闲的时候,后台进程会刷新脏页
5、double write
上文说的是刷新脏页的时间点,那么具体是怎么刷新的呢?
mysql数据页大小16k,但是磁盘文件一个页大小4k那么将16k的文件写入到磁盘里,肯定不是一次就写完的,如果写入过程中数据
库了突然断电,可能造成写入不完整,造成数据页损坏。这样情况下,即使有redolog 也无法恢复数据了,因为redelog中记录的是
对页修改,如果数据页损坏了,就无法通过redolog恢复了
所以为了保证数据页正确的写入,引入了 double write机制:
double write分两部分:一个是内存中的 doublewrite buffer(2M) 和磁盘中共享表空间里的128个连续的页也是2M,脏页从flush链
表刷新时,先使用调用memcopy方法,将脏页拷贝到doublewrite buffer中,然后分两次每次1m将doublewrite buffer刷新到磁盘
的doublewrite区 ,之后再掉调用fsync方法同步到磁盘中
6、redolog刷新到磁盘
上文提到更新操作是 wal 先写日志再写内存,为了保证事务的持久性 log buffer里的 redolog 必须要刷新到磁盘里,刷新的机会点
有4种情况:
a、log buffer 存储空间不足时,log buffer 空间是有限的,当 redelog 日志量超过 log buffer 总容量的一半时,就需要将这些日志
刷新到磁盘上
b、事务提交时
c、后台线程刷新
d、正常关闭服务时


MyISAM和InnoDB存储引擎
a、InnoDB支持事务,MyISAM不支持,对于InnoDB每一条SQL语言都默认封装成事务,自动提交,这样会影响速度,所以最好把
多条SQL语言放在begin和commit之间,组成一个事务
b、InnoDB支持外键,而MyISAM不支持。对一个包含外键的InnoDB表转为MYISAM会失败
c、InnoDB是聚集索引,使用B+Tree作为索引结构,数据文件是和(主键)索引绑在一起的(表数据文件本身就是按B+Tree组织的
一个索引结构),必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到
数据。因此,主键不应该过大,因为主键太大,其他索引也都会很大
MyISAM是非聚集索引,也是使用B+Tree作为索引结构,索引和数据文件是分离的,索引保存的是数据文件的指针。主键索引和
辅助索引是独立的。
d、InnoDB不保存表的具体行数,执行select count(*) from table时需要全表扫描。而MyISAM用一个变量保存了整个表的行数,执
行上述语句时只需要读出该变量即可,速度很快(注意不能加有任何WHERE条件)
e、InnoDB支持表、行(默认)级锁,而MyISAM支持表级锁
f、InnoDB的主键索引的叶子节点存储着行数据,因此主键索引非常高效。MyISAM索引的叶子节点存储的是行数据地址,需要再寻
址一次才能得到数据
g、InnoDB非主键索引的叶子节点存储的是主键和其他带索引的列数据,因此查询时做到覆盖索引会非常高效
MyISAM Innodb 存储结构 每张表被存放在三个文件:frm-表格定义、MYD(MYData)-数据文件、MYI(MYIndex)-索引文件 所有的表都保存在同一个数据文件中(也可能是多个文件,或者是独立的表空间文件),InnoDB表的大小只受限于操作系统文件的大小,一般为2GB 存储空间 MyISAM可被压缩,存储空间较小 InnoDB的表需要更多的内存和存储,它会在主内存中建立其专用的缓冲池用于高速缓冲数据和索引 可移植性、备份及恢复 由于MyISAM的数据是以文件的形式存储,所以在跨平台的数据转移中会很方便。在备份和恢复时可单独针对某个表进行操作 免费的方案可以是拷贝数据文件、备份 binlog,或者用 mysqldump,在数据量达到几十G的时候就相对痛苦了 文件格式 数据和索引是分别存储的,数据 .MYD,索引.MYI数据和索引是集中存储的, .ibd记录存储顺序 按记录插入顺序保存 按主键大小有序插入 外键 不支持 支持 事务 不支持 支持 锁支持(锁是避免资源争用的一个机制,MySQL锁对用户几乎是透明的) 表级锁定 行级锁定、表级锁定,锁定力度小并发能力高 SELECT MyISAM更优 INSERT、UPDATE、DELETE InnoDB更优 select count(*) myisam更快,因为myisam内部维护了一个计数器,可以直接调取。 索引的实现方式 B+树索引,myisam 是堆表 B+树索引,Innodb 是索引组织表 哈希索引 不支持 支持 全文索引 支持 不支持 InnoDB引擎的4大特性
1、插入缓冲(insert buffer)
只对于非聚集索引(非唯一)的插入和更新有效,对于每一次的插入不是写到索引页中,而是先判断插入的非聚集索引页是否在缓冲
池中,如果在则直接插入;若不在,则先放到Insert Buffer 中,再按照一定的频率进行合并操作,再写回disk。这样通常能将多个插
入合并到一个操作中,目的还是为了减少随机IO带来性能损耗
使用插入缓冲的条件:
a、 非聚集索引
b、非唯一索引
2、双写机制(double write)
在InnoDB将BP中的Dirty Page刷(flush)到磁盘上时,首先会将(memcpy函数)Page刷到InnoDB tablespace的一个区域中,我
们称该区域为Double write Buffer(大小为2MB,每次写入1MB,128个页,每个页16k,其中120个页为后台线程的批量刷Dirty
Page,还有8个也是为了前台起的sigle Page Flash线程,用户可以主动请求,并且能迅速的提供空余的空间)。在向Double write
Buffer写入成功后,第二步、再将数据分别刷到一个共享空间和真正应该存在的位置。
MySQL可以根据redolog进行恢复,而mysq在恢复的过程中是检查page的checksum,checksum就是pgae的最后事务号,发生
partial page write问题时,DageR经损坏,找不到该page中的事务号就无法恢复
具体的流程如下图所示:
在不同的写入阶段,操作系统crash后,double write带来的保护机制:
阶段一:copy过程中,操作系统crash,重启之后,脏页未刷到磁盘,但更早的数据并没有发生损坏,重新写入即可
阶段二:write到共享表空间过程中,操作系统crash,重启之后,脏页未刷到磁盘,但更早的数据并没有发生损坏,重新写入即可
阶段三:write到独立表空间过程中,操作系统crash,重启之后,发现:
a、数据文件内的页损坏:头尾checksum值不匹配(即出现了partial page write的问题)。从共享表空间中的doublewrite
segment内恢复该页的一个副本到数据文件,再应用redo log
b、若页自身的checksum匹配,但与doublewrite segment中对应页的checksum不匹配,则统一可以通过apply redo log来恢复。
阶段X:recover过程中,操作系统crash,重启之后,innodb面对的情况同阶段三一样(数据文件损坏,但共享表空间内有副本),
再次应用redo log即可
3、自适应哈希索引(ahi)
哈希算法是一种非常快的查找方法,在一般情况(没有发生hash冲突)下这种查找的时间复杂度为O(1)。InnoDB存储引擎会监控对
表上辅助索引页的查询。如果观察到建立hash索引可以提升性能,就会在缓冲池建立hash索引,称之为自适应哈希索引(Adaptive
Hash Index,AHI)
自适应哈希索引由innodb_adaptive_hash_index 变量启用,AHI是通过缓冲池的B+ Tree构造而来,使用索引键的前缀来构建哈希索
引,前缀可以是任意长度。InnoDB存储引擎会自动根据访问的频率和模式来自动地为某些热点页建立hash索引。加快索引读取的效
果,相当于索引的索引,帮助InnoDB快速读取索引页
根据InnoDB官方文档说明,启用了AHI后,读写的速度会提升2倍,辅助索引的连接操作性能可以提高5倍
4、预读(read ahead)
预读(read-ahead)操作是一种IO操作,用于异步将磁盘的页读取到buffer pool中,预料这些页会马上被读取到。预读请求的所有页
集中在一个范围内。InnoDB使用两种预读算法:
a、Linear read-ahead:线性预读技术预测在buffer pool中被访问到的数据它临近的页也会很快被访问到。能够通过调整被连续访
问的页的数量来控制InnoDB的预读操作,使用参数 innodb_read_ahead_threshold配置,添加这个参数前,InnoDB会在读取到当
前区段最后一页时才会发起异步预读请求
innodb_read_ahead_threshold 这个参数控制InnoDB在检测顺序页面访问模式时的灵敏度。如果在一个区块顺序读取的页数大于或
者等于 innodb_read_ahead_threshold 这个参数,InnoDB启动预读操作来读取下一个区块。innodb_read_ahead_threshold参数
值的范围是 0-64,默认值为56. 这个值越高则访问默认越严格。比如,如果设置为48,在当前区块中当有48个页被顺序访问时,
InnoDB就会启动异步的预读操作,如果设置为8,则仅仅有8个页被顺序访问就会启动异步预读操作。你可以在MySQL配置文件中设
置这个值,或者通过SET GLOBAL 语句动态修改(需要有set global 权限)。
b、Random read-ahead: 随机预读通过buffer pool中存中的来预测哪些页可能很快会被访问,而不考虑这些页的读取顺序。如果发
现buffer pool中存中一个区段的13个连续的页,InnoDB会异步发起预读请求这个区段剩余的页。通过设置
innodb_random_read_ahead 为 ON开启随机预读特性
通过 SHOW INNODB ENGINE STATUS 命令输出的统计信息可以帮助你评估预读算法的效果,统计信息包含了下面几个值:
//通过预读异步读取到buffer pool的页数 innodb_buffer_pool_read_ahead //预读的页没被使用就被驱逐出buffer pool的页数,这个值与上面预读的页数的比值可以反应出预读算法的优劣 innodb_buffer_pool_read_ahead_evicted //由InnoDB触发的随机预读次数 innodb_buffer_pool_read_ahead_rnd
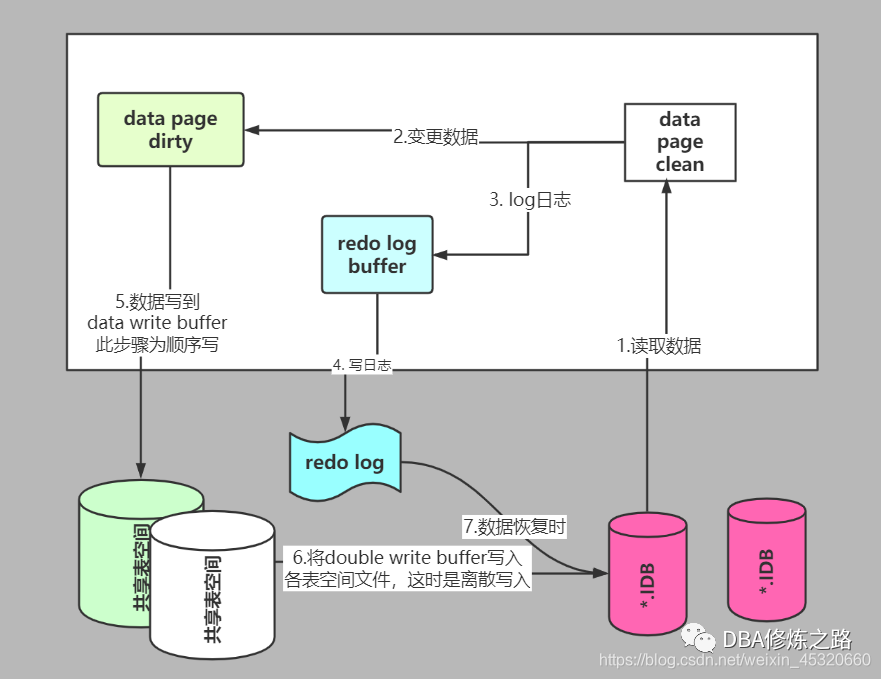
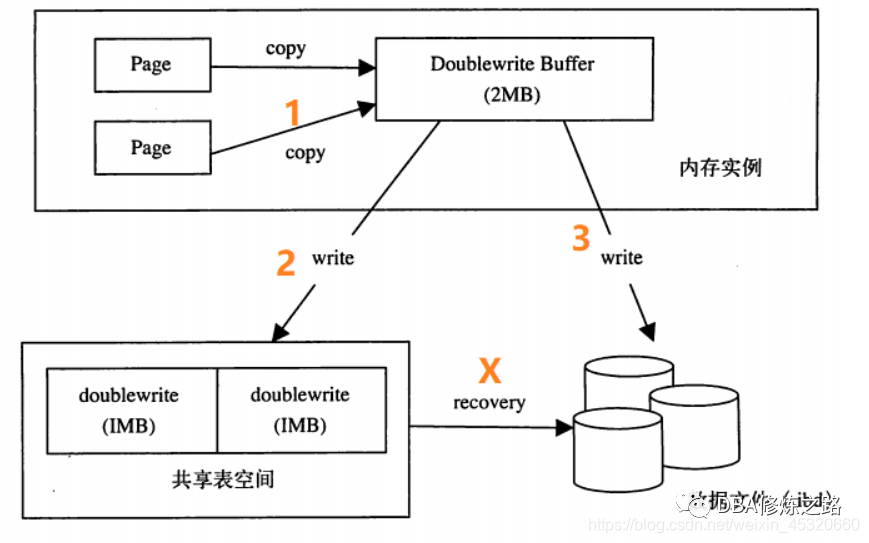
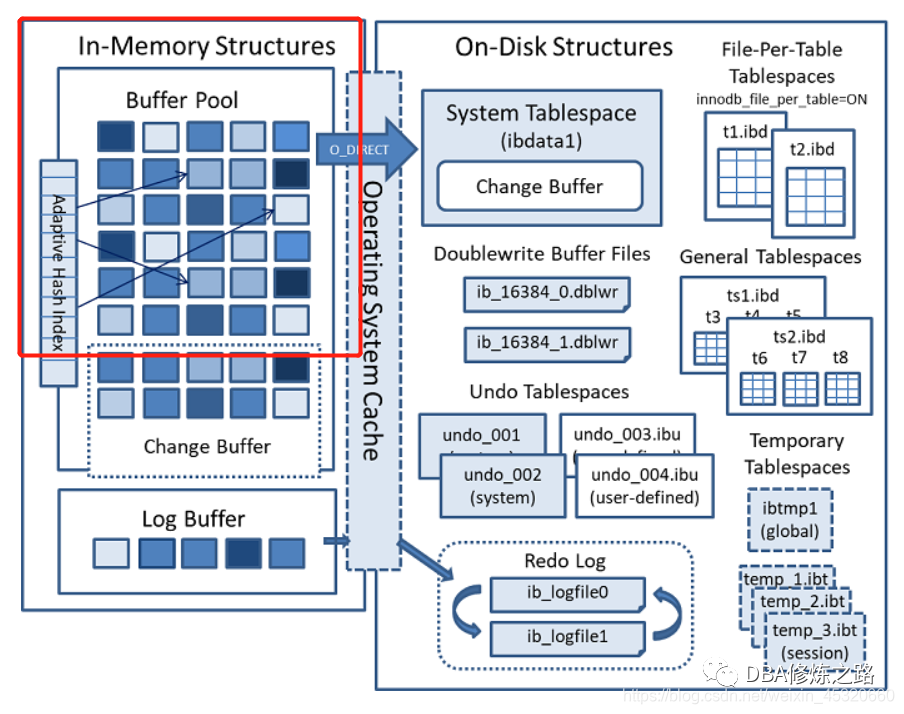
索引
索引概念:
MySQL官方对索引的定义为:索引(index)是帮助MySQL高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满
足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法,这种数
据结构就是索引。如下图所示:
左边是数据表,一共有两列七行记录,最左边的
0x07格式的数据是物理地址(注意逻辑上相邻的记录在磁盘上也并不是一定物理相邻的)。为了加快 Col 2 的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据的物理地址
的指针,这样就可以运用二叉查找快速获取到对应的数据了
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上。建立索引是数据库中用来提高
性能的最常用的方式
索引的基本原理:
索引用来快速地寻找那些具有特定值的记录。如果没有索引,一般来说执行查询时遍历整张表
索引的原理很简单,就是把无序的数据变成有序的查询
1、把创建了索引的列的内容进行排序
2、对排序结果生成倒排表
3、在倒排表内容上拼上数据地址链
4、在查询的时候,先拿到倒排表内容,再取出数据地址链,从而拿到具体数据
什么时候建立索引:
索引是应用程序设计和开发的一个重要方面。若索引太多,应用程序的性能可能会受到影响。而索引太少,对查询性能又会产生影
响,要找到一个平衡点,这对应用程序的性能至关重要。一些开发人员总是在事后才想起添加索引----我一直认为,这源于一种错误
的开发模式。如果知道数据的使用,那么从一开始就应该在需要处添加索引。开发人员往往对数据库的使用停留在应用的层面,比如
编写SQL语句、存储过程之类,甚至可能不知道索引的存在,或认为事后让相关DBA加上即可。DBA往往不够了解业务的数据流,而
添加索引需要通过监控大量的SQL语句进而从中找到问题,这个步骤所需的时间肯定是远大于初始添加索引所需的时间,并且可能会
遗漏一部分的索引。当然索引也并不是越多越好,我曾经遇到过这样一个问题:某台MySQL服务器 iostat 显示磁盘使用率一直处于
100%,经过分析后发现是由于开发人员添加了太多的索引,在删除一些不必要的索引之后,磁盘使用率马上下降为20%。可见索引
的添加也是非常有技术含量的
1、选择唯一性索引,唯一性索引的值是唯一的,可以更快速的通过该索引来确定某条记录
2、为经常需要排序、分组和联合操作的字段建立索引
3、为常用作为查询条件的字段建立索引
4、限制索引的数目:越多的索引,会使更新表变得很浪费时间。尽量使用数据量少的索引
5、如果索引的值很长,那么查询的速度会受到影响。尽量使用前缀来索引
6、如果索引字段的值很长,最好使用值的前缀来索引
7、删除不再使用或者很少使用的索引
8、最左前缀匹配原则,非常重要的原则
9、尽量选择区分度高的列作为索引区分度的公式是表示字段不重复的比例
10、索引列不能参与计算,保持列“干净”:带函数的查询不参与索引
11、尽量的扩展索引,不要新建索引
建立索引的优劣:
优势:
- 类似于书籍的目录索引,提高数据检索的效率,降低数据库的IO成本
- 通过索引对数据进行排序,降低数据排序的成本,降低CPU的消耗
劣势:
- 实际上索引也是一张表,该表中保存了主键与索引字段,并指向实体类的记录,所以索引列也是要占用空间的
- 虽然索引提高了查询效率,同时也降低了表更新的速度,如对表进行INSERT、UPDATE、DELETE。因为更新表时,MySQL不仅
- 要保存数据,还要保存一下索引列的字段,都会调整因为更新所带来的键值变化后的索引信息
索引类型:
Mysql目前主要有以下几种索引类型:FULLTEXT,HASH,BTREE,RTREE
1、FULLTEXT
即为全文索引,目前只有MyISAM引擎支持。其可以在CREATE TABLE ,ALTER TABLE ,CREATE INDEX 使用,不过目前只有
CHAR、VARCHAR ,TEXT 列上可以创建全文索引。全文索引并不是和MyISAM一起诞生的,它的出现是为了解决WHERE name
LIKE “%word%"这类针对文本的模糊查询效率较低的问题
2、HASH
由于HASH的唯一(几乎100%的唯一)及类似键值对的形式,很适合作为索引。
HASH索引可以一次定位,不需要像树形索引那样逐层查找,因此具有极高的效率。但是,这种高效是有条件的,即只在“=”和“in”条件
下高效,对于范围查询、排序及组合索引仍然效率不高
3、BTREE
BTREE索引就是一种将索引值即数据按一定的算法,存入一个树形的数据结构中(二叉树),每次查询都是从树的入口root开始,依
次遍历node,获取leaf。这是MySQL里默认和最常用的索引类型
4、RTREE
RTREE在MySQL很少使用,仅支持geometry数据类型,支持该类型的存储引擎只有MyISAM、BDb、InnoDb、NDb、Archive几
种。相对于BTREE,RTREE的优势在于范围查找
索引种类:
1、普通索引
基本的索引类型,没有唯一性的限制,允许为NULL值
可以通过ALTER TABLE table_name ADD INDEX index_name (column); 创建普通索引
可以通过ALTER TABLE table_name ADD INDEX index_name(column1, column2, column3); 创建组合索引
2、单值索引(单列索引)
单值索引即一个索引只包含单个列,一个表中可以有多个单列索引;语法如下:
CREATE TABLE customer ( id INT(10) UNSIGNED AUTO_INCREMENT, customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id), KEY (customer_name) ); CREATE INDEX idx_customer_name ON customer(customer_name); DROP INDEX idx_customer_name ;3、主键索引
数据列不允许重复,不允许为NULL,一个表只能有一个主键
CREATE TABLE customer ( id INT(10) UNSIGNED AUTO_INCREMENT, customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id) ); CREATE TABLE customer2 ( id INT(10) UNSIGNED, customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id) ); ALTER TABLE customer add PRIMARY KEY customer(customer_no); ALTER TABLE customer drop PRIMARY KEY ;4、唯一索引:
数据列不允许重复,允许为NULL值,一个表允许多个列创建唯一索引
- 可以通过
ALTER TABLE table_name ADD UNIQUE (column);创建唯一索引- 可以通过
ALTER TABLE table_name ADD UNIQUE (column1,column2);创建唯一组合索引CREATE TABLE customer ( id INT(10) UNSIGNED AUTO_INCREMENT, customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id), KEY (customer_name), UNIQUE (customer_no) ); CREATE UNIQUE INDEX idx_customer_no ON customer(customer_no); DROP INDEX idx_customer_no on customer ;5、复合索引(联合索引):
复合索引即一个索引中包含多个列,在数据库操作期间,复合索引所需要的开销更小(相对于相同的多个列建立单值索引)
CREATE TABLE customer ( id INT(10) UNSIGNED AUTO_INCREMENT, customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id), KEY (customer_name), UNIQUE (customer_name), KEY (customer_no,customer_name) ); CREATE INDEX idx_no_name ON customer(customer_no,customer_name); DROP INDEX idx_no_name on customer ;
6、 最左前缀匹配:带头大哥不能死,中间兄弟不能断
B+树的数据项是复合的数据结构,比如 (name,age,sex) 的时候,b+树是按照从左到右的顺序来建立搜索树的
比如当 (张三,20,F) 这样的数据来检索的时候,b+树会优先比较 name来确定下一步的所搜方向,如果 name 相同再依次比较 age 和
sex,最后得到检索的数据;
但当 (20,F) 这样的没有 name 的数据来的时候,b+ 树就不知道第一步该查哪个节点,因为建立搜索树的时候 name 就是第一个比较
因子,必须要先根据 name 来搜索才能知道下一步去哪里查询 —> 所以三个联合索引一个都不会走, 直接全局扫描
比如当 (张三, F) 这样的数据来检索时,b+ 树可以用 name 来指定搜索方向,但下一个字段 age 的缺失,所以只能把名字等于张三的
数据都找到,然后再匹配性别是 F 的数据了, 这个是非常重要的性质,即索引的最左匹配特性。(这种情况无法用到联合索引)–>
张三列的索引可以利用上, 由于中间兄弟断掉了, 所以F的索引也不会使用到
7、覆盖索引:
覆盖索引(covering index)的原理很简单,就像你拿到了一本书的目录,里头有标题和对应的页码,当你想知道第267页的标题是
什么的时候,完全没有必要翻到267页去看,而是直接看目录
同理,当你要select的字段,已经在索引树里面存储,那就不需要再去检索数据库,直接拿来用就行了
你给a、b、c三个字段建了复合索引,那么对于下面这条sql,就可以走覆盖索引:
select b, c from demo_table where a = "xxx";8、 聚簇索引(聚集索引):
聚簇索引就是将数据存储与索引放到了一块,找到索引也就找到了数据
InnoDB的聚簇索引实际上是在同一个BTree结构中同时存储了索引和整行数据,通过该索引查询可以直接获取查询数据行
聚簇索引不是一种单独的索引类型,而是一种数据的存储方式,聚簇索引的顺序,就是数据在硬盘上的物理顺序
在 MySQL 通常聚簇索引是主键的同义词,每张表只包含一个聚簇索引(其他数据库不一定)
9、辅助索引(二级索引、非聚簇索引):
非聚簇索引就是将数据存储于索引分开结构,索引结构的叶子节点指向了数据的对应行,MyISAM通过key_buffer把索引先缓存到内
存中,当需要访问数据时(通过索引访问数据),在内存中直接搜索索引,然后通过索引找到磁盘相应数据(这一步称为回表查
询),这也就是为什么索引不在key buffer命中时,速度慢的原因
10、全文索引
是目前搜索引擎使用的一种关键技术
可以通过
ALTER TABLE table_name ADD FULLTEXT (column);创建全文索引11、聚集索引
聚集索引:指索引项的排序方式和表中数据记录排序方式一致的索引
也就是说聚集索引的顺序就是数据的物理存储顺序。它会根据聚集索引键的顺序来存储表中的数据,即对表的数据按索引键的顺序进
行排序,然后重新存储到磁盘上。因为数据在物理存放时只能有一种排列方式,所以一个表只能有一个聚集索引
12、非聚集索引: 索引顺序与物理存储顺序不同
13、稠密索引
稠密索引:每个索引键值都对应有一个索引项
稠密索引能够比稀疏索引更快的定位一条记录。但是,稀疏索引相比于稠密索引的优点是:它所占空间更小,且插入和删除时的维护
开销也小。
14、稀疏索引
稀疏索引:相对于稠密索引,稀疏索引只为某些搜索码值建立索引记录;在搜索时,找到其最大的搜索码值小于或等于所查找记录的
搜索码值的索引项,然后从该记录开始向后顺序查询直到找到为止。
索引设计原则:
索引的设计可以遵循一些已有的原则,创建索引的时候尽量考虑是否符合这些原则,便于提升索引的使用效率,更高效地使用索引:
1、对查询次数频次较高,且数据量较大的表建立索引
2、索引字段的选择,最佳候选列应当从where子句的条件中提取,如果where子句中的组合比较多,那么应当挑选最常用、过滤效
果最好的列的组合
3、使用唯一索引,区分度高、使用效率越高
4、索引可以有效的提升查询数据的效率 , 但索引数量并不是多多益善 , 索引越多 , 维护索引的代价自然也就水涨船高 . 对于插入, 更
新, 删除 等 DML 操作比较繁琐的表来说 , 索引过多 , 会引入相当高的维护代价 , 降低 DML 操作的效率 , 增加相应操作的时间消耗
, 另外索引过多的话 , MySQL也会犯 选择困难症 , 虽然最终仍然会找到一个可用的索引 , 但无疑提高了索引的代价
5、使用段索引 , 索引创建之后也是使用硬盘来存储的 , 因此提高索引访问的 I/O 效率 , 也可以提高总体的访问效率 . 假如构成索引的
字段总长度比较短 , 那么在给定大小的存储块内 , 可以存储更多的索引值 , 相应的可以有效地提升MySQL访问索引的 I/O 效率
6、利用最左前缀的原则 , N个列组合而成的组合索引 , 那么相当于是创建了N 个索引 。如果查询时where 子句使用了组成该索引的
前几个字段 , 那么这条查询SQL可以利用组合索引来提升查询效率
百万级别或以上的数据如何删除:
关于索引:由于索引需要额外的维护成本,因为索引文件是单独存在的文件,所以当我们对数据的增加、修改、删除都会产生额外的
对索引文件的操作,这些操作需要消耗额外的IO,会降低增/改/删的执行效率。所以,在我们删除数据库百万级别数据的时候,查询
MySQL官方手册得知删除数据的速度和创建的索引数量是成正比的
1、所以我们想要删除百万数据的时候可以先删除索引(此时大概耗时三分多钟)
2、然后删除其中无用数据(此过程需要不到两分钟)
3、删除完成后重新创建索引(此时数据较少了)创建索引也非常快,约十分钟左右
4、与之前的直接删除绝对是要快速很多,更别说万一删除中断,一切删除会回滚。那更是坑了


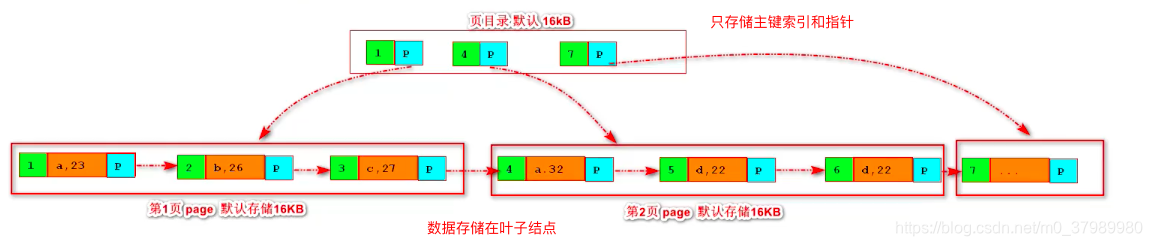
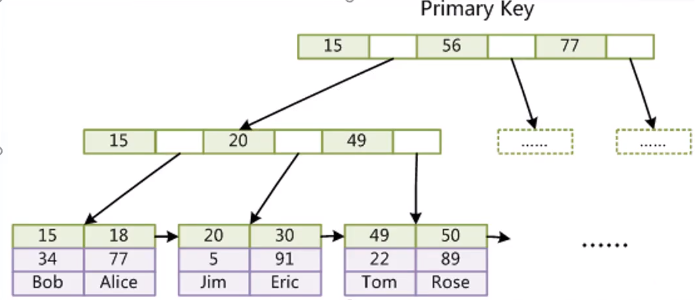
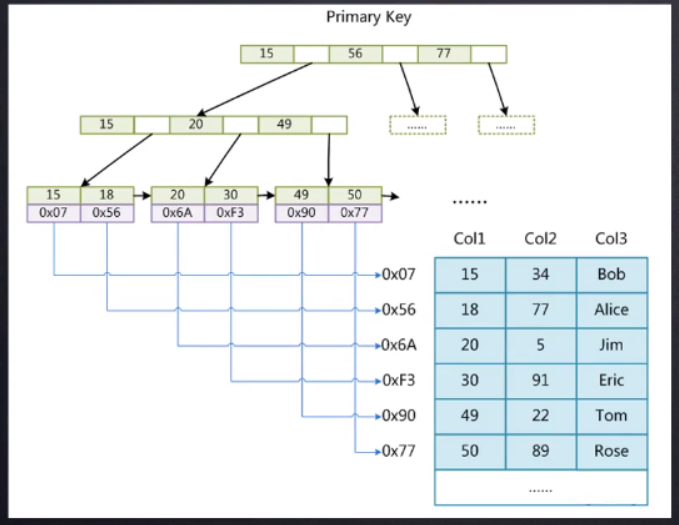




索引底层数据结构
索引就是一种用于快速查找数据的数据结构,是帮助MySQL高效获取数据的排好序的数据结构,有无索引的区别:
假设我们有一个表t,它有俩字段,Col1和Col2,如下:
a、不加索引
不加索引的情况下,SQL: select * from t where t.col2=89 ,需要从表的第一行一行行遍历比对col2的值是否等于89,这样需要比
对6次才能查到。这只是只有几行记录的表,那如果是百万级千万级的表呢?是不是就比较的次数就更多了,那还不得慢死
b、加索引
如果col2这列加了索引,mysql内部会维护一个数据结构。假设mysql用的数据结构是红黑树(右子树的元素大于根节点,左子树的
元素小于根节点)的数据结构建立索引,那就像上图右边那样。这样的话,刚才的那条SQL是不是只需要2次磁盘IO就查到了,是不
是快很多了
这就是索引的好处。索引使用比较巧妙的数据结构,利用数据结构的特性来大大减少查找遍历次数。
底层为什么使用B+树?
使用二叉树时,当数据列数据递增时,二叉树与链表类似,每次查询数据时都需要所有的树节点依次访问,效率低
使用红黑树时,当数据量非常大时,树的层数会非常多,查询时磁盘I/O次数多,查询效率慢
非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
叶子节点包含所有索引字段
叶子节点用指针连接,提高区间访问的性能(实际上叶子节点间的指针是双向的,图有问题)
和B-Tree有啥区别?非叶子节点没有数据,数据都挪到叶子节点,叶子节点之间还有指针,非叶子节点之间跟原来一样没有指针。
为啥data元素挪到叶子节点?非叶子节点只存储索引元素,叶子节点存储了一份完整表的所有行的索引字段,data元素是每个索引元素对应要查找的行记录的位置或行数据,这样非叶子节点的每个节点就可以存储更多的索引元素(等会会有一个大致的估算)。实际上非叶子节点存储的是一些冗余索引,看一下上图,15/20/49,选择的是整张表的哪些数据作为索引?选择的是处于中间位置的,因为它要用到B+Tree一些比大小去查找,B+Tree本质可以叫做多叉平衡树,单看B+Tree的某一小块他还是一个二叉树。
还有一个特点,某一个节点的元素处于一个递增的顺序,会提取叶子节点的一些处于中间位置的数据作为冗余索引,查找的时候从根节点开始查找,先把根节点加载到内存里去,然后在内存里去比对。
比如要查找索引为30的数据,先在根节点跟15去比较,大于15,然后小于56,然后从他俩中间的指针查找下一个节点把它load到内存,再在内存里去比对,大于15,大于20,然后小于49,就根据20和49之间的指针找到下一个节点,然后load到内存,去比对,不等于20下一个30,相等,OK了。
mysql为什么把节点大小设置为16K,而不是更大?
假设索引字段类型是Bigint,8bit,每两个元素之间存的是下一个节点的地址,mysql分配的是6bit,也就是说一个索引后面配对一个节点地址,成对出现,可以算一下16K的节点可以存多少对也就是多少个索引,8b+6b=14b,16K /14b=1170个索引,叶子节点有索引有data元素,假设占1K,那一个节点就放16K/1K=16个元素,假设树高是3,所有节点都放满,能放多少数据?可以算一下,1170117016=21902400,2千多万,mysql设置16K的大小,数据就可以存2千多万就已经足够了吧,既能保证一次磁盘IO不要Load太多的数据 又能保证一次load的性能,即便表的数据在几千万的数量也能保证树的高度在一个可控的范围。
可以看一下几千万的数据表是不是加了索引几十毫秒几百毫秒就出结果了,所以就解释了几千万的表精确的使用索引后他的性能依旧比较高。
树的高度只有3的情况下就能存储2千多万的数据,即便某一个索引在叶子节点,那也就2、3次磁盘IO就能查找到,当然很快了。而且mysql底层的索引他的根节点,是常驻内存的,直接就放到内存的,查找叶子节点,一个2千万的数据放到B+Tree上面,要查找叶子节点,就只需要2次磁盘IO就搞定了,在内存里比对的时间基本可以忽略。
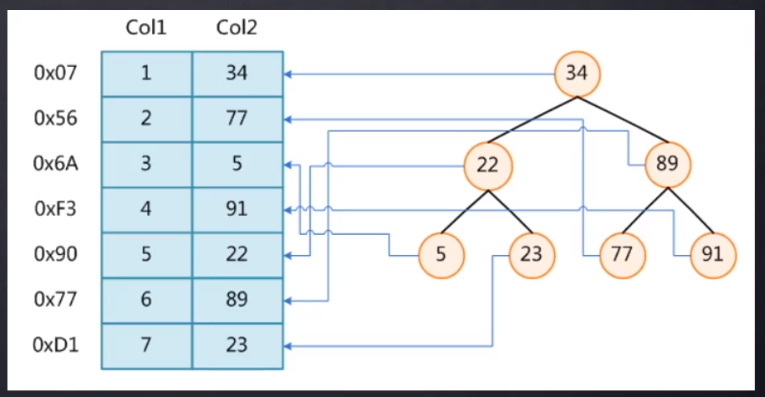
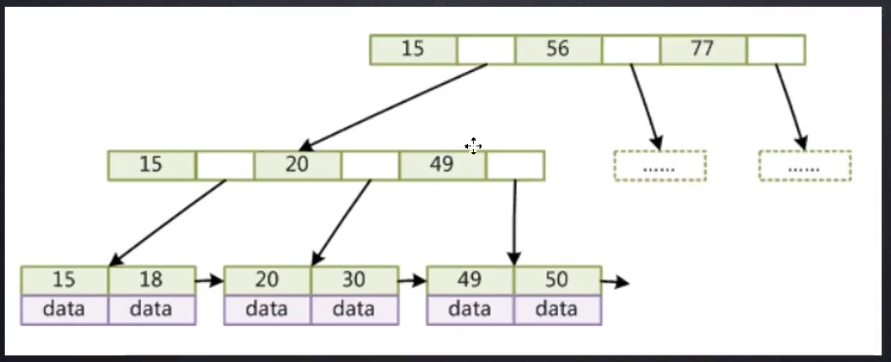
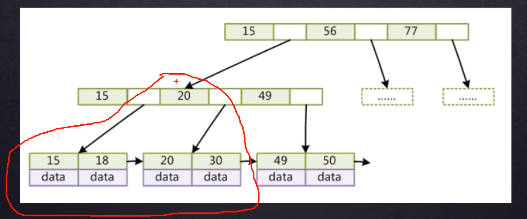
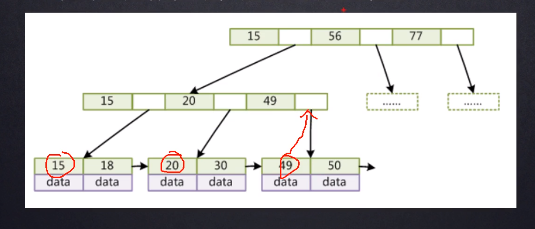
执行计划
SQL执行过程和优化器:
1、客户端发送一条查询给服务器
2、服务器先检查查询缓存,如果命中缓存则立刻返回存储在缓存中的结果,否则进入下一阶段。
3、服务器端进行SQL解析、预处理,再由优化器生成对应的执行计划。
4、MYSQL根据优化器生成的执行计划调用存储引擎的API来执行查询
5、将结果返回给客户端
对于mysql来说,底层的存储引擎主要的工作就是对数据的磁盘文件进行操作,上层的sql解析等操作主要放在服务器层,服务器层根据sql进行优化和解析生成执行计划,最后存储引擎根据执行计划来调用数据
优化器主要有:
a、rbo:基于规则的优化器
b、cbo:基于代价的优化器性能分析
EXPLAIN执行计划:
- 表的读取顺序
- 数据读取操作的操作类型
- 哪些索引可以被使用
- 哪些索引被实际使用
- 表之间的引用
- 每张表有多少行被优化器查询
| id | select_type | table | type| possible_keys | key | key_len | ref| rows |Extra |① id
Select查询的序列号,包含一组数字,表示查询中执行select或操作表的顺序
id相同的时候:执行顺序自上向下
id不同:如果是子查询,id序号会递增,id值越大优先级越高,越先被执行
id有相同又有不同:id如果相同,可以认为是一组,从上往下顺序执行;在所有组中,id值越大,优先级越高,越先执行
当我们知道了表的执行顺序有什么用?
最常用的,在日常工作中遵循小表驱动大表的原则,到时候就可以观察sql加载表的顺序是不是你所想的先加载小表再加载大表
② select type
这一列表示查询中每个select子句的类型,是简单还是复杂SELECT
(1) SIMPLE
简单SELECT,查询中不包含UNION或子查询等
(2) PRIMARY
查询中若包含子查询,最外层的查询被标记为primary
(3) UNION
- 若第二个select出现在UNION之后,则被标记为UNION
- 若union包含在from子句的子查询中,外层SELECT被标记为DERIVED
(4) DEPENDENT UNION
UNION中的第二个或后面的SELECT语句,取决于外面的查询
(5) UNION RESULT
用来从UNION的匿名临时表检索结果的SELECT被称为UNION RESULT
(6) SUBQUERY
包含在SELECT列表中的子查询中的SELECT(换句话说,不在FROM子句中)
(7) DEPENDENT SUBQUERY
(子查询中的第一个SELECT,依赖于外部查询)
(8) DERIVED
在from列表中包含的子查询被标记为DERIVED(衍生),mysql会递归执行这些子查询,把结果放在临时表中,服务器内部称其为派生
表,因为该临时表是从子查询中派生来的
注意看table项,derived2表示由id为2的查询衍生出的虚表
(9) UNCACHEABLE SUBQUERY
(一个子查询的结果不能被缓存,必须重新评估外链接的第一行)
③ type
对表访问方式,表示MySQL在表中找到所需行的方式,又称“访问类型”
越向右性能越好
system>const>eq_ref>ref>range>index>all
一般来说要保证查询至少达到range级别,最好能达到ref
(1) system
表只有一行记录,是const的特例类型,平时不会出现,可以忽略不计,一般系统表只有一行记录
(2) constant
通常情况下,如果将一个主键放置到where后面作为条件查询,mysql优化器就能把这次查询优化转化为一个常量。至于如何转化以
及何时转化,这个取决于优化器。
可以看到,在子查询中,id为主键,通过主键索引只用查找一次就能查到对应的值,所以是constant
对于子查询查询出的衍生表d1里面只有一行数据,所以外面查询的类型为system
(3) eq_ref
唯一索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见主键或唯一索引扫描,他会将他们与某个参考值做比较
ref_eq 与 ref相比牛的地方是,它知道这种类型的查找结果集只有一个,什么情况下结果集只有一个呢?那便是使用了主键或者唯一
性索引进行查找的情况,比如根据学号查找某一学校的一名同学,在没有查找前我们就知道结果一定只有一个,所以当我们首次查找
到这个学号,便立即停止了查询。这种连接类型每次都进行着精确查询,无需过多的扫描,因此查找效率更高,当然列的唯一性是需
要根据实际情况决定的
(4) ref
非唯一性索引扫描,返回匹配某个单独值的所有行。本质上也是一种索引访问,返回匹配某值(某条件)的多行值,属于查找和扫描
的混合体。
出现该ref的条件是: 查找条件列使用了索引而且不为主键和unique。其实,意思就是虽然使用了索引,但该索引列的值并不唯一,
有重复。这样即使使用索引快速查找到了第一条数据,仍然不能停止,要进行目标值附近的小范围扫描。但它的好处是它并不需要扫
全表,因为索引是有序的,即便有重复值,也是在一个非常小的范围内扫描
(5) range
只检索给定范围的行,使用一个索引来检索行,可以在key列中查看使用的索引,一般出现在where语句的条件中,如使用
between、>、<、in等查询。
range指的是有范围的索引扫描,相对于index的全索引扫描,它有范围限制,因此要优于index。关于range比较容易理解,需要记
住的是出现了range,则一定是基于索引的。同时除了显而易见的between,and以及’>’,’<'外,in和or也是索引范围扫描
这种扫描比全表扫描好,因为他只需要开始于索引的某一点,而结束于另一点,不用扫描全部索引
(6) index
全索引扫描,这种连接类型只是另外一种形式的全表扫描,只不过它的扫描顺序是按照索引的顺序
index和ALL的区别:index只遍历索引树,通常比ALL快,因为索引文件通常比数据文件小。虽说index和ALL都是全表扫描,但是
index是从索引中读取,ALL是从磁盘中读取。
这种扫描根据索引然后回表取数据,和all相比,他们都是取得了全表的数据,而且index要先读索引而且要回表随机取数据,因此
index不可能会比all快(取同一个表数据),但为什么官方的手册将它的效率说的比all好,唯一可能的原因在于,当使用了覆盖索引
的时候不需要再回表查询
(7) all
这便是所谓的“全表扫描”,如果是展示一个数据表中的全部数据项,倒是觉得也没什么,如果是在一个查找数据项的sql中出现了all类型,那通常意味着你的sql语句处于一种最原生的状态,有很大的优化空间
all是一种非常暴力和原始的查找方法,非常的耗时而且低效。用all去查找数据就好比这样的一个情形:S学校有俩万人,我告诉你你
给我找到小明,然后你怎么做呢!你当然是把全校俩万人挨个找一遍,即使你很幸运第一个人便找到了小明,但是你仍然不能停下,
因为你无法确认是否有另外一个小明存在,直到你把俩万人找完为止。所以,基本所有情况,我们都要避免这样类型的查找,除非你
不得不这样做
④ possible_keys & keys
possible_keys:可能用到的索引
keys :实际使用到的索引
查询中若使用到了覆盖索引则只出现在keys中
⑤ key_len
表示索引中所使用的字节数,可通过该列计算查询中使用的索引长度。在不损失精确性的情况下,长度越短越好。key_len显示的值
为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,并不是通过表内检索出的
表示索引中使用的字节数
key_len和精确不能共得
⑥ ref
这一列显示了在key列记录的索引中,表查找值所用到的列或常量,常见的有: const(常量),字段名等。一般是查询条件或关联条件
中等号右边的值,如果是常量那么ref列是const,非常量的话ref列就是字段名
col1匹配t2表的col1
col2匹配一个常量,即ac
⑦ rows
根据表统计信息及索引选用情况,大致估算出找到所需的记录所需读取的行数
⑧ extra
包含不适合在其他列中显示但是十分重要的额外信息
(1) Using filesort(坏)
文件内排序,看到这个的时候,查询就需要优化了
Using filesort表明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取
(2) Using temporary(坏)
使用了临时表保存中间结果,Mysql在对查询结果排序的时候使用了临时表,常见于排序order by和分组查询group by
需要先把数据放到临时表,使用完再把临时表删除
非常危险,“十死无生”,急需优化
(3) Using index(好)
表明相应的select操作中使用了覆盖索引,避免访问表的额外数据行,效率不错
如果同时出现了Using where,表明索引被用来执行索引键值的查找
如果没有同时出现Using where,表明索引用来读取数据而非执行查找动作。
(4) Using where















MySQL各种常用的函数
一、数字函数
1、ABS(x) 返回x的绝对值
2、AVG(expression) 返回一个表达式的平均值,expression 是一个字段
3、CEIL(x)/CEILING(x) 返回大于或等于 x 的最小整数
4、FLOOR(x) 返回小于或等于 x 的最大整数
5、EXP(x) 返回 e 的 x 次方
6、GREATEST(expr1, expr2, expr3, …) 返回列表中的最大值
7、LEAST(expr1, expr2, expr3, …) 返回列表中的最小值
8、LN 返回数字的自然对数
9、LOG(x) 返回自然对数(以 e 为底的对数)
10、MAX(expression)返回字段 expression 中的最大值
11、MIN(expression)返回字段 expression 中的最大值
12、POW(x,y)/POWER(x,y)返回 x 的 y 次方
13、RAND()返回 0 到 1 的随机数
14、ROUND(x)返回离 x 最近的整数
15、SIGN(x)返回 x 的符号,x 是负数、0、正数分别返回 -1、0 和 1
16、SQRT(x)返回x的平方根
17、SUM(expression)返回指定字段的总和
18、TRUNCATE(x,y)返回数值 x 保留到小数点后 y 位的值(与 ROUND 最大的区别是不会进行四舍五入)
二、字符串函数
1、返回字符串 s 的第一个字符的 ASCII 码
2、LENGTH/CHAR_LENGTH(s)/CHARACTER_LENGTH(s)返回字符串 s 的字符数
3、CONCAT(s1,s2…sn)字符串 s1,s2 等多个字符串合并为一个字符串
4、FIND_IN_SET(s1,s2)返回在字符串s2中与s1匹配的字符串的位置
5、FORMAT(x,n)函数可以将数字 x 进行格式化 “#,###.##”, 将 x 保留到小数点后 n 位,最后一位四舍五入
6、INSERT(s1,x,len,s2)字符串 s2 替换 s1 的 x 位置开始长度为 len 的字符串
7、LOCATE(s1,s)从字符串 s 中获取 s1 的开始位置
8、LCASE(s)/LOWER(s)将字符串 s 的所有字母变成小写字母
9、UCASE(s)/UPPER(s)将字符串 s 的所有字母变成大写字母
10、TRIM(s)去掉字符串 s 开始和结尾处的空格
11、LTRIM(s)去掉字符串 s 开始处的空格
12、RTRIM(s)去掉字符串 s 结尾处的空格
13、SUBSTR(s, start, length)从字符串 s 的 start 位置截取长度为 length 的子字符串
14、SUBSTR/SUBSTRING(s, start, length)从字符串 s 的 start 位置截取长度为 length 的子字符串
15、POSITION(s1 IN s)从字符串 s 中获取 s1 的开始位置
16、REPEAT(s,n)将字符串 s 重复 n 次
17、REVERSE(s)将字符串s的顺序反过来
18、STRCMP(s1,s2)比较字符串 s1 和 s2,如果 s1 与 s2 相等返回 0 ,如果 s1>s2 返回 1,如果 s1<s2 返回 -1
三、日期函数
1、CURDATE()/CURRENT_DATE()返回当前日期
2、CURRENT_TIME()/CURTIME()返回当前时间
3、CURRENT_TIMESTAMP()返回当前日期和时间
4、ADDDATE(d,n)计算起始日期 d 加上 n 天的日期
5、ADDTIME(t,n)时间 t 加上 n 秒的时间
6、DATE()从日期或日期时间表达式中提取日期值
7、DAY(d)返回日期值 d 的日期部分
8、DATEDIFF(d1,d2)计算日期 d1->d2 之间相隔的天数
9、DATE_FORMAT按表达式 f的要求显示日期 d
10、DAYNAME(d)返回日期 d 是星期几,如 Monday,Tuesday
11、DAYOFMONTH(d)计算日期 d 是本月的第几天
12、DAYOFWEEK(d)日期 d 今天是星期几,1 星期日,2 星期一,以此类推
13、DAYOFYEAR(d)计算日期 d 是本年的第几天
14、EXTRACT(type FROM d)从日期 d 中获取指定的值,type 指定返回的值
15、DAYOFWEEK(d)日期 d 今天是星期几,1 星期日,2 星期一,以此类推
16、UNIX_TIMESTAMP()得到时间戳
17、FROM_UNIXTIME()时间戳转日期
四、高级函数
1、IF(expr,v1,v2)如果表达式 expr 成立,返回结果 v1;否则,返回结果 v2
2、CONV(x,f1,f2)返回 f1 进制数变成 f2 进制数
3、CURRENT_USER()/SESSION_USER()/SYSTEM_USER()/USER()返回当前用户
4、DATABASE()返回当前数据库名
5、VERSION()返回数据库的版本号
Mysql事务
事务是用来维护数据库完整性的,它能够保证一系列的MySQL操作要么全部执行,要么全不执行。举一个例子来进行说明,例如转
账操作:A账户要转账给B账户,那么A账户上减少的钱数和B账户上增加的钱数必须一致,也就是说A账户的转出操作和B账户的转入
操作要么全部执行,要么全不执行;如果其中一个操作出现异常而没有执行的话,就会导致账户A和账户B的转入转出金额不一致的
情况,为而事实上这种情况是不允许发生的,所以为了防止这种情况的发生,需要使用事务处理。
事务的概念:
事务(Transaction)指的是一个操作序列,该操作序列中的多个操作要么都做,要么都不做,是一个不可分割的工作单位,是数据
库环境中的逻辑工作单位,由DBMS中的事务管理子系统负责事务的处理。
目前常用的存储引擎有InnoDB(MySQL5.5以后默认的存储引擎)和MyISAM(MySQL5.5之前默认的存储引擎),其中InnoDB支持
事务处理机制,而MyISAM不支持。
事务的特性:
事务处理可以确保除非事务性序列内的所有操作都成功完成,否则不会永久更新面向数据的资源。通过将一组相关操作组合为一个要
么全部成功要么全部失败的序列,可以简化错误恢复并使应用程序更加可靠。
但并不是所有的操作序列都可以称为事务,这是因为一个操作序列要成为事务,必须满足事务的原子性(Atomicity)、一致性
(Consistency)、隔离性(Isolation)和持久性(Durability)。这四个特性简称为ACID特性。
a、原子性 :
原子是自然界最小的颗粒,具有不可再分的特性。事务中的所有操作可以看做一个原子,事务是应用中不可再分的最小的逻辑执行
体。
使用事务对数据进行修改的操作序列,要么全部执行,要么全不执行。通常,某个事务中的操作都具有共同的目标,并且是相互依赖
的。如果数据库系统只执行这些操作中的一部分,则可能会破坏事务的总体目标,而原子性消除了系统只处理部分操作的可能性。
b、一致性 :
一致性是指事务执行的结果必须使数据库从一个一致性状态,变到另一个一致性状态。当数据库中只包含事务成功提交的结果时,数
据库处于一致性状态。一致性是通过原子性来保证的。
例如:在转账时,只有保证转出和转入的金额一致才能构成事务。也就是说事务发生前和发生后,数据的总额依然匹配。
c、隔离性 :
隔离性是指各个事务的执行互不干扰,任意一个事务的内部操作对其他并发的事务,都是隔离的。也就是说:并发执行的事务之间既
不能看到对方的中间状态,也不能相互影响。
例如:在转账时,只有当A账户中的转出和B账户中转入操作都执行成功后才能看到A账户中的金额减少以及B账户中的金额增多。并
且其他的事务对于转账操作的事务是不能产生任何影响的。
d、持久性 :
持久性指事务一旦提交,对数据所做的任何改变,都要记录到永久存储器中,通常是保存进物理数据库,即使数据库出现故障,提交
的数据也应该能够恢复。但如果是由于外部原因导致的数据库故障,如硬盘被损坏,那么之前提交的数据则有可能会丢失。
事务并发问题:
a、脏读:当事务A对数据进行了修改,而这种修改还没有提交到数据库中,此时事务B访问并使用了这个数据产生脏读
b、不可重复读:当事务A读取了一个数据,事务A还没有结束,此时事务B也访问并修改了这个数据并提交,当事务A再次读取此数
据时,事务A两次读取到的数据不同,产生不可重复读问题
d、幻读:当事务A读取某个范围内数据时,事务B在此范围内插入了数据,此时事务A再次读取此范围内数据时产生了幻读
不可重复读和幻读的区别:
不可重复读指读到了已经提交的事务的更改数据(修改),幻读是指读到了其他已经提交事务的新增数据
不可重复读的重点是修改,幻读的重点在于新增或者删除。
不可重复读和幻读解决方案:
解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表
不可重复读时防止读到更改数据,只需对操作的数据添加行级锁,防止操作中的数据发生变化
幻读时防止读到新增数据,往往需要添加表级锁,将整张表锁定,防止新增数据(oracle采用多版本数据的方式实现)
事务隔离级别:
隔离级别 脏读 不可重复读 幻影读 读未提交 read-uncommitted √ √ √ 读已提交read-committed × √ √ 可重复读repeatable-read × × √ 串行化serializable × × × a、最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读
b、允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生
c、对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生
d、最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该
级别可以防止脏读、不可重复读以及幻读
这里需要注意的是:Mysql 默认采用的 REPEATABLE_READ隔离级别 Oracle 默认采用的 READ_COMMITTED隔离级别
事务管理方式:
编程式事务和声明式事务
Mysql中的锁
隔离级别与锁的关系:
在Read Uncommitted级别下,读取数据不需要加共享锁,这样就不会跟被修改的数据上的排他锁冲突
在Read Committed级别下,读操作需要加共享锁,但是在语句执行完以后释放共享锁
在Repeatable Read级别下,读操作需要加共享锁,但是在事务提交之前并不释放共享锁,也就是必须等待事务执行完毕以后才释放
共享锁
SERIALIZABLE 是限制性最强的隔离级别,因为该级别锁定整个范围的键,并一直持有锁,直到事务完成
按照锁的粒度分数据库锁有哪些?锁机制与InnoDB锁算法
在关系型数据库中,可以按照锁的粒度把数据库锁分为行级锁(INNODB引擎)、表级锁(MYISAM引擎)和页级锁(BDB引擎 )
MyISAM和InnoDB存储引擎使用的锁:
MyISAM采用表级锁(table-level locking)
InnoDB支持行级锁(row-level locking)和表级锁,默认为行级锁
行级锁,表级锁和页级锁对比:
行级锁:

















 70万+
70万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









