






环境准备:
| 类型· | IP | 主机名· | 操作系统 | 内存 | 磁盘 | |
| 主服务器 | 192.168.134.170 | node1 | Centos7.9 | 2G | 系统盘40G,存储盘20G | |
| 备服务器 | 192.168.134.172 | node3 | Centos7.9 | 2G | 系统盘40G,存储盘20G |
一、两台主机设置hosts文件,打通通道。
vim /etc/hosts
内容如下:
192.168.134.170 node1
192.168.134.172 node3
二、设置主备节点之间可以免密登录
备节点
ssh-keygen -f ~/.ssh/id_rsa -P '' -q
ssh-copy-id node1
主节点
ssh-keygen -f ~/.ssh/id_rsa -P '' -q
ssh-copy-id node3三、安装部署DRBD
1、导入elrepo源
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
rpm -Uvh https://www.elrepo.org/elrepo-release-7.el7.elrepo
2、安装扩展源
wget -O /etc/yum.repos.d/epel.repo https://mirrors.aliyun.com/repo/epel-7.repo3、安装软件包、
yum install -y drbd90-utils kmod-drbd904、启动drbd的内核模块
modprobe drbd
echo drbd > /etc/modules-load.d/drbd.conf
lsmod | grep drbd # 显示已经载入系统的模块 ,做检查使用5、修改全局配置文件(两台机器都执行)
vim /etc/drbd.d/global_common.conf
global {
usage-count no; # 版本控制
}
common {
handlers {
pri-on-incon-degr "/usr/lib/drbd/notify-pri-on-incon-degr.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
local-io-error "/usr/lib/drbd/notify-io-error.sh; /usr/lib/drbd/notify-emergency-shutdown.sh; echo o > /proc/sysrq-trigger ; halt -f";
}
startup {
}
options {
}
disk {
on-io-error detach;
}
net {
protocol C; # 指定使用协议C,在common中配置也可以
}
}
6、修改资源文件(两台机器都执行)
vim /etc/drbd.d/nfs.res
resource nfs {
disk /dev/sdb;
device /dev/drbd0;
meta-disk internal;
on node1 {
address 192.168.134.170:8822;
}
on node3 {
address 192.168.134.172:8822;
}
}
7、首次启用资源
(1)创建元数据(两台都要配)
drbdadm create-md nfs
内容如下:
initializing activity log
initializing bitmap (640 KB) to all zero
Writing meta data...
New drbd meta data block successfully created.(2)启用资源(两台都要配)
drbdadm up nfs(3)启动初始化全量同步(在主节点上启动)
drbdadm primary --force nfs # 启动全量同步
drbdadm status # 可以查看同步状态(一段时间后状态才会变化)
nfs role:Primary
disk:UpToDate
node1 role:Secondary
replication:SyncSource peer-disk:Inconsistent done:3.58
nfs role:Primary
disk:UpToDate
node1 role:Secondary
peer-disk:UpToDate
补充:一些常用的命令:(都需要在命令后加上资源名)
| drbdadm cstate | 查看资源的连接状态 |
| drbdadm dstate | 查看资源磁盘状态 |
| drbdadm role | 查看资源角色 |
| drbdadm primary | 提升资源 |
| drbdadm secondary | 降低资源 |
四、测试drbd是否成功启动
1、在主节点上
mkdir /data
ls /dev/drbd
mkfs.xfs /dev/drbd0 # 初始化
meta-data=/dev/drbd0 isize=512 agcount=4, agsize=1310678 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=5242711, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
mount /dev/drbd0 /data # 将磁盘挂载到data目录下
cp /etc/hos* /data/ # 将文件copy入data目录下
umount /data # 卸载data目录
drbdadm secondary nfs # 资源降级2、在备节点上
mkdir /data # 创建data目录
ls /dev/drbd
drbdadm primary nfs # 资源升级
drbdadm status # 查看资源状态
nfs role:Primary
disk:UpToDate
node3 role:Secondary
peer-disk:UpToDate
mount /dev/drbd0 /data # 将磁盘重新挂入data目录
[root@node1 ~]# ls /data # 查看data目录下内容,观察是否同步成功,出现以下情况即同步成功
host.conf hostname hosts hosts.allow hosts.deny
五、启动服务
yum install keepalived -y
vim /etc/keepalived/keepalived.confsystemctl start drbd
systemctl enable drbd六·、安装nfs
yum -y install rpcbind nfs-utils # 安装nfs
vim /etc/exports # 编辑文件
cat /etc/exports
/data 192.168.0.0/16(rw,sync,no_root_squash,no_all_squash)
systemctl restart rpcbind nfs-server # 重启应用
systemctl enable nfs-server
showmount -e localhost
七、安装并且修改keepalived的配置文件
yum install -y keepalived
vim /etc/keepalived/keepalived.conf
内容如下:
! Configuration File for keepalived
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_NFS1
}
vrrp_script check_nfs {
script "killall -0 nfsd" # 使用killall命令
#script "/etc/keepalived/check_nfs.sh"
interval 2
weight -30
}
vrrp_instance VI_1 {
state MASTER
# nopreempt
interface ens33
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
track_script {
check_nfs
}
virtual_ipaddress {
192.168.134.100/24
}
notify_stop /etc/keepalived/notify_stop.sh # 写脚本控制故障切换等
notify_master /etc/keepalived/notify_master.sh
notify_backup /etc/keepalived/notify_backup.sh
}
脚本内容如下:
cat notify_stop.sh
#!/bin/bash
time=$(date +"%F %T") # 指定时间
log_dir=/etc/keepalived/logs # 日志位置
logname=notify_stop
res_name=nfs
[ -d ${log_dir} ] || mkdir -p ${log_dir} # 测试目录是否存在,不存在那么创建目录
echo -e "$time ---------${logname}--------\n" >> ${log_dir}/${logname}.log
systemctl stop nfs-server >> ${log_dir}/${logname}.log # 停止nfs服务
umount /data >> ${log_dir}/${logname}.log # 卸载挂载点
drbdadm secondary ${res_name} >> ${log_dir}/${logname}.log # 资源降级
echo -e "\n" >> ${log_dir}/${logname}.log
cat notify_master.sh
#!/bin/bash
time=$(date +"%F %T")
log_dir=/etc/keepalived/logs
logname=notify_master
res_name=nfs
[ -d ${log_dir} ] || mkdir -p ${log_dir}
echo -e "$time ---------${logname}--------\n" >> ${log_dir}/${logname}.log
drbdadm primary ${res_name} >> ${log_dir}/${logname}.log
mount /dev/drbd0 /data >> ${log_dir}/${logname}.log
systemctl start nfs-server >> ${log_dir}/${logname}.log
echo -e "\n" >> ${log_dir}/${logname}.log
cat notify_backup.sh
#!/bin/bash
time=$(date +"%F %T")
log_dir=/etc/keepalived/logs
logname=notify_backup
res_name=nfs
[ -d ${log_dir} ] || mkdir -p ${log_dir}
echo -e "$time ---------${logname}--------\n" >> ${log_dir}/${logname}.log
systemctl stop nfs-server >> ${log_dir}/${logname}.log
umount /data >> ${log_dir}/${logname}.log
drbdadm secondary ${res_name} >> ${log_dir}/${logname}.log
echo -e "\n" >> ${log_dir}/${logname}.log
最后重启keepalived,进行最终结果测试。
systemctl restart keepalived.service八、测试结果
1、查看vip(是否可以漂移)
master

backup:
![]()
当master出现故障,


2、查看资源的角色(一主一从)


3、查看挂载(只会在一端过滤)

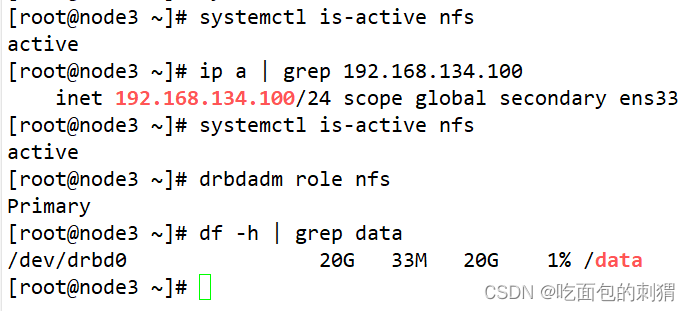
4、nfs测试:关闭主节点,查看备节点此时情况(ip实现漂移,资源重新挂载,资源角色切换)
















 770
770











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









