







故障转移
创建一个sink组,组内有多个sink,采用故障转移的方式,在配置信息里设置优先级,优先级高的sink作为主要拉取数据的sink。当拉取数据的sink挂掉后,下一个优先级高的会顶替它,在一定程度上相当于flume的高可用。
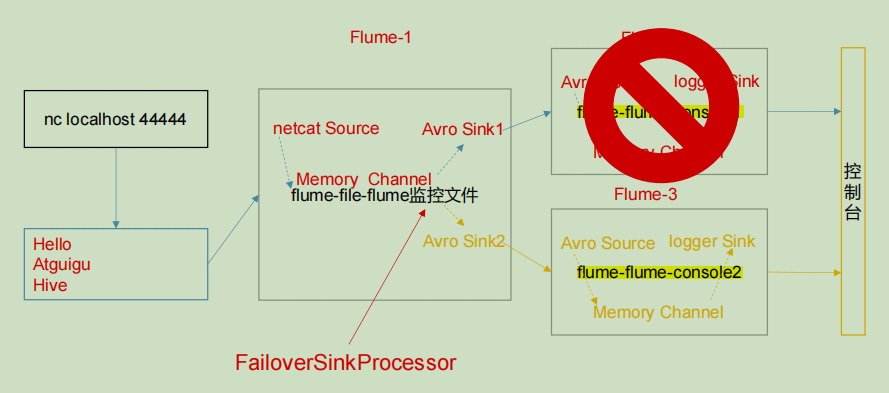
flume1的配置信息:
# Name the components on this agent
a1.sources = r1
a1.channels = c1
a1.sinkgroups = g1
a1.sinks = k1 k2
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
a1.sinkgroups.g1.processor.type = failover
a1.sinkgroups.g1.processor.priority.k1 = 5
a1.sinkgroups.g1.processor.priority.k2 = 10
a1.sinkgroups.g1.processor.maxpenalty = 10000
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop102
a1.sinks.k1.port = 4141
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hadoop102
a1.sinks.k2.port = 4142
# Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1flume2的配置信息:
# Name the components on this agent
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# Describe/configure the source
a2.sources.r1.type = avro
a2.sources.r1.bind = hadoop102
a2.sources.r1.port = 4141
# Describe the sink
a2.sinks.k1.type = logger
# Describe the channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1flume3的配置信息和flume2的配置信息基本一样,就是要改a2为a3,端口号和channel也要改
负载均衡
负载均衡采用轮巡的方式对source的数据进行拉取,但在操作实际案例中会发现,如果可能会发生同一个sink多次拉取到数据,而组内其他sink一直拉不到数据的情况,这是为什么呢?
这是因为负载均衡的轮巡是sink在轮巡,而不是channel在轮巡。
例如,sink组内有3个sink,sink1能一直从channel那里拉数据,sink2和sink3一直拉取不到数据,这是因为客户端发数据的频率刚好对上了sink1的拉数据频率,而其他sink刚好错过发数据的时机。导致每一次客户端发数据,3个sink轮巡拉取,首先被sink1拉走了,剩下的sink拉不到,等到客户端再次发数据,sink1处理完拉走的数据,又可以拉数据了,然后又把数据抢走了,剩下的sink还是拉不到数据。
但如果是发数据的一方主动轮巡,则结果是每个sink一人一条数据。
这部分要改的配置信息只有flume1,把 processor.type 按如下改动:
a1.sinkgroups.g1.processor.type =load_balance
a1.sinkgroups.g1.processor.backoff=true总结
1.在实际操作时要弄清楚不同agent的名字,不要搞混,否则agent之间无法正常通信。
2.使用netcat监控端口数据时,要根据情况改变指令,例如从nc localhost 44444改为nc hadoop102 44444。
3.先起服务端,再起客户端。如果所有flume之间通信成功,服务端会打印日志信息。如果没有看到日志打印信息,基本可以判断通信失败,重新检查配置信息、启动命令等步骤。















 499
499











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









