







目录
(2)广播连接流(BroadcastConnectedStream)
多流转换可以分为“分流”和“合流”两大类。目前分流的操作一般是通过侧输出流(side output)来实现,而合流的算子比较丰富,根据不同的需求可以调用 union 、connect、 join 以及 coGroup 等接口进行连接合并操作。
一、分流
所谓“分流”,就是将一条数据流拆分成完全独立的两条、甚至多条流。
在早期的版本中,DataStream API 中提供了一个.split()方法,专门用来将一条流“切分” 成多个。在 Flink 1.13 版本中,已经弃用了.split()方法,取而代之的是直接用处理函数(processfunction)的侧输出流(side output)。
1、简单实现
只要针对同一条流多次独立调用.filter()
方法进行筛选,就可以得到拆分之后的流了。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource());
// 筛选Mary的浏览行为放入MaryStream流中
SingleOutputStreamOperator<Event> mary = stream.filter(new FilterFunction<Event>() {
@Override
public boolean filter(Event event) throws Exception {
return event.user.equals("Mary");
}
});
// 筛选Bob的浏览行为放入MaryStream流中
SingleOutputStreamOperator<Event> bob = stream.filter(new FilterFunction<Event>() {
@Override
public boolean filter(Event event) throws Exception {
return event.user.equals("Bob");
}
});
// 筛选Mary的浏览行为放入MaryStream流中
SingleOutputStreamOperator<Event> elsePerson = stream.filter(new FilterFunction<Event>() {
@Override
public boolean filter(Event event) throws Exception {
return !event.user.equals("Mary") & !event.user.equals("Bob");
}
});
mary.print("Mary");
bob.print("Bob");
elsePerson.print("else");
env.execute();
}2、使用侧输出流
侧输出流则不受限制,可以任意自定义输出数据,它们就像从“主流”上分叉出的“支流”。尽管看起来主流和支流有所区别,不过实际上它们都是某种类型的 DataStream,所以本质上还是平等的。利用侧输出流就可以很方便地实现分流操作,而且得到的多条 DataStream 类型可以不同,这就给我们的应用带来了极大的便利。
public class SplitStreamByOutputTag {
// 定义输出标签,侧输出流的数据类型为三元组(user, url, timestamp)
private static OutputTag<Tuple3<String, String, Long>> MaryTag = new OutputTag<Tuple3<String, String, Long>>("Mary-pv"){};
private static OutputTag<Tuple3<String,String,Long>> BobTag = new OutputTag<Tuple3<String ,String ,Long>>("Bob-pv"){};
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource());
SingleOutputStreamOperator<Event> processedStream = stream.process(new ProcessFunction<Event, Event>() {
@Override
public void processElement(Event event, Context context, Collector<Event> collector) throws Exception {
if (event.user.equals("Mary")) {
context.output(MaryTag, Tuple3.of(event.user, event.url, event.timestamp));
} else if (event.user.equals("Bob")) {
context.output(BobTag, Tuple3.of(event.user, event.url, event.timestamp));
} else {
collector.collect(event);
}
}
});
processedStream.getSideOutput(MaryTag).print("Mary");
processedStream.getSideOutput(BobTag).print("Bob");
processedStream.print("else");
env.execute();
}
}二、合流
1、联合(Union)
最简单的合流操作,就是直接将多条流合在一起。联合操作要求必须 流中的数据类型必须相同,合并之后的新流会包括所有流中的元素,数据类型不变。对于合流之后的水位线,也是要 以最小的那个为准,这样才可以保证所有流都不会再传来之前的数据。(类似木桶效应)
// 合并两条流
stream1.union(stream2)
.process(new ProcessFunction<Event, String>() { // 查看合并后下游的水位线变化
@Override
public void processElement(Event value, Context ctx, Collector<String> out) throws Exception {
out.collect("水位线:" + ctx.timerService().currentWatermark());
}
})
.print();2、连接(Connect)
连接得到的并不是 DataStream ,而是一个“连接流” 。连接流可以看成是两条流形式上的“统一”,被放在了一个同一个流中; 事实上内部仍保持各自的数据形式不变,彼此之间是相互独立的。要想得到新的 DataStream , 还需要进一步定义一个“同处理”(co-process )转换操作,用来说明对于不同来源、不同类型的数据,怎样分别进行处理转换、得到统一的输出类型。
DataStream<Integer> stream1 = env.fromElements(1,2,3);
DataStream<Long> stream2 = env.fromElements(1L,2L,3L);
// 使用connect 合流:一国两制,允许两种类型不同的流合并,但一次只能合并两条
ConnectedStreams<Integer, Long> connect = stream1.connect(stream2);
SingleOutputStreamOperator<String> map = connect.map(new CoMapFunction<Integer, Long, String>() { // 同处理co-process
@Override
public String map1(Integer integer) throws Exception {
return "Integer:" + integer;
}
@Override
public String map2(Long aLong) throws Exception {
return "Long:" + aLong;
}
});两条流的连接( connect ),与联合( union )操作相比,最大的优势就是可以处理不同类型的流的合并,使用更灵活、应用更广泛。当然它也有限制,就是合并流的数量只能是 2 ,而 union 可以同时进行多条流的合并。
(1)CoProcessFunction
对于连接流 ConnectedStreams 的处理操作,需要分别定义对两条流的处理转换,因此接口中就会有两个相同的方法需要实现,用数字“ 1 ”“2”区分,在两条流中的数据到来时分别调用。我们把这种接口叫作“协同处理函数”(co-process function )。与 CoMapFunction 类似,如果是调用 .flatMap() 就需要传入一个 CoFlatMapFunction ,需要实现 flatMap1() 、 flatMap2() 两个方法;而调用.process() 时,传入的则是一个 CoProcessFunction 。
(2)广播连接流(BroadcastConnectedStream)
关于两条流的连接,还有一种比较特殊的用法: DataStream 调用 .connect() 方法时,传入的参数也可以不是一个 DataStream ,而是一个“广播流”( BroadcastStream ),这时合并两条流得到的就变成了一个“广播连接流”(BroadcastConnectedStream )。这种连接方式往往用在需要动态定义某些规则或配置的场景。因为规则是实时变动的,所以我们可以用一个单独的流来获取规则数据;而这些规则或配置是对整个应用全局有效的,所以不能只把这数据传递给一个下游并行子任务处理,而是要“广播”( broadcast )给所有的并行子任务。而下游子任务收到广播出来的规则,会把它保存成一个状态,这就是所谓的“广播状态”( broadcast state )。
三、基于时间的合流——双流联结(Join)
对于两条流的合并,很多情况我们并不是简单地将所有数据放在一起,而是希望根据某个字段的值将它们联结起来,“配对”去做处理。
1、窗口联结(Window Join)
窗口联结在代码中的实现,首先需要调用 DataStream 的 .join() 方法来合并两条流,得到一个 JoinedStreams ;接着通过 .where() 和 .equalTo() 方法指定两条流中联结的 key ;然后通过 .window() 开窗口,并调用 .apply() 传入联结窗口函数进行处理计算。
stream1.join(stream2)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(<WindowAssigner>)
.apply(<JoinFunction>)处理流程:
两条流的数据到来之后,首先会按照 key 分组、进入对应的窗口中存储;当到达窗口结束 时间时,算子会先统计出窗口内两条流的数据的所有组合,也就是对两条流中的数据做一个笛卡尔积(相当于表的交叉连接,cross join),然后进行遍历,把每一对匹配的数据,作为参数(first,second)传入 JoinFunction 的.join()方法进行计算处理,得到的结果直接输出如图 8-8 所示。所以窗口中每有一对数据成功联结匹配,JoinFunction 的.join()方法就会被调用一次,并输出一个结果。

2、间隔联结(Interval Join)
间隔联结的思路就是针对一条流的每个数据,开辟出其时间戳前后的一段时间间隔,看这期间是否有来自另一条流的数据匹配。间隔联结具体的定义方式是:我们给定两个时间点,分别叫作间隔的“上界”( upperBound )和“下界”( lowerBound );于是对于一条流(不妨叫作 A )中的任意一个数据元素 a,就可以 开辟一段时间间隔:[a.timestamp + lowerBound, a.timestamp + upperBound]。我们就把这段时间作为可以匹配另一条流数据的“窗口”范围。所以对于另一条流(不妨叫 B)中的数据元素 b,如果它的时间戳落在了这个区间范围内,a 和 b 就可以成功配对,进而进行计算输出结果。
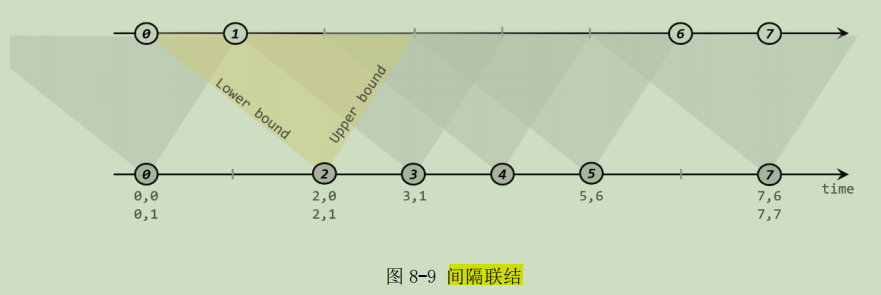
orderStream.keyBy(data -> data.f0)
.intervalJoin(clickStream.keyBy(data -> data.user))
.between(Time.seconds(-5), Time.seconds(10))
.process(new ProcessJoinFunction<Tuple3<String, String, Long>, Event, String>() {
@Override
public void processElement(Tuple3<String, String, Long> left, Event right, Context ctx, Collector<String> out) throws Exception {
out.collect(right + " => " + left);
}
}).print();3、窗口同组联结(Window CoGroup)
它的用法跟 window join 非常类似,也是将两条流合并之后开窗处理匹配的元素,调用时只需要将.join()换为.coGroup()就可以了。
stream1
.coGroup(stream2)
.where(r -> r.f0)
.equalTo(r -> r.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.apply(new CoGroupFunction<Tuple2<String, Long>, Tuple2<String, Long>, String>() {
@Override
public void coGroup(Iterable<Tuple2<String, Long>> iter1, Iterable<Tuple2<String, Long>> iter2, Collector<String> collector) throws Exception {
collector.collect(iter1 + "=>" + iter2);
}
}).print();














 3447
3447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









