







目录
1 项目介绍
BP算法,全称为反向传播算法(Backpropagation),是训练人工神经网络,尤其是多层感知机(MLP)的一种高效方法。在卷积神经网络(Convolutional Neural Network, CNN)中,BP算法同样发挥着核心作用,用于优化网络权重,从而提高模型在特定任务上的表现,例如图像分类任务,如猫狗识别项目。
猫狗识别项目是一个典型的计算机视觉任务,旨在通过分析图像数据,自动区分图片中的动物是猫还是狗。这个项目不仅展示了深度学习技术在图像识别领域的强大能力,也是初学者入门深度学习的理想实践案例。以下是基于CNN实现猫狗识别项目的简要介绍:
2 项目背景与目标
随着互联网上宠物图片的海量增长,自动分类这些图片的需求应运而生。猫狗识别不仅能够提升用户体验,如在搜索引擎中快速筛选特定类别的图片,还在动物保护、宠物护理等领域具有潜在应用价值。本项目旨在通过构建一个准确、高效的机器学习模型,实现对猫狗图片的自动分类。
3 数据集准备
成功的关键在于高质量的数据集。本项目通常会采用github开源的猫狗图片数据集dogs_cats数据集,它包含张标12500张标记好的猫狗图片。
数据集百度网盘下载地址链接:https://pan.baidu.com/s/1iSQ5gw4M7x52CKyhO6adag?pwd=1221 ,提取码:1221
数据预处理包括图像标准化、尺寸统一、数据增强(如旋转、翻转等)等步骤,以增加模型的泛化能力并减少过拟合风险。
4 神经网络
4.1神经网络结构
可以通过如图进行理解神经网络的基本构成:
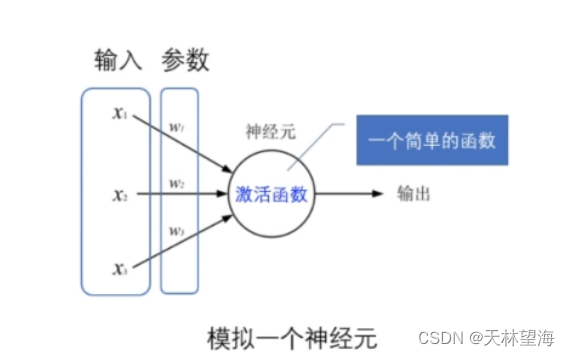
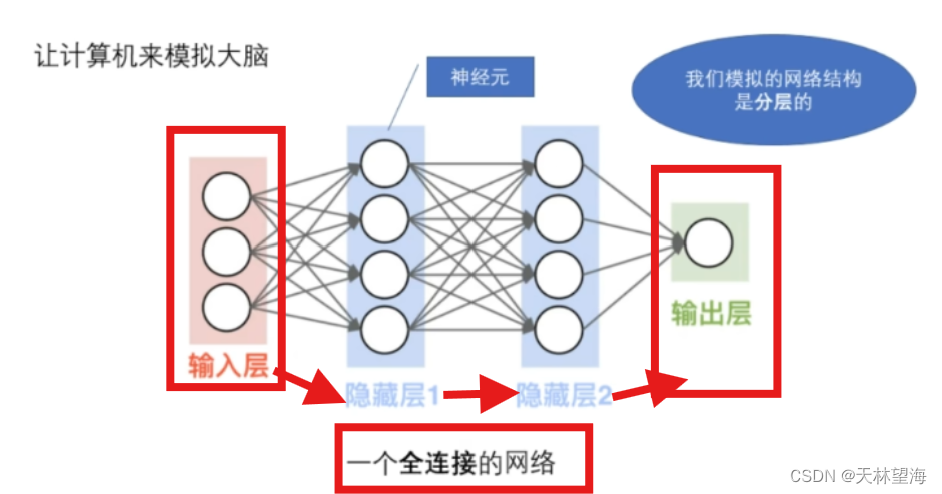
4.2 计算机内图片储存
图片在计算机内是以数字形式储存的,主要通过两种基本的存储方式:点阵存储(位图)和矢量存储。点阵存储(Bitmap or Raster Graphics):这种存储方式是将图片分解成一个由像素(Pixel)组成的网格。每个像素都有自己的颜色值,这些值一起构成整个图像。像素值可以是灰度(从黑到白的连续变化)或彩色(通常是RGB三原色的不同组合)。点阵图像的分辨率固定,放大时会因像素被拉伸而显得模糊。常见的点阵图像格式包括JPEG、PNG、BMP、TIFF等。其中,JPEG是一种有损压缩格式,适合于摄影图片存储,因为它能以较小的文件大小保留较多的视觉细节;PNG则支持透明度,并使用无损压缩,适合图标和需要透明背景的图像;BMP格式未压缩,文件较大,但能完全保留图像质量。矢量存储(Vector Graphics):矢量图像则是使用数学公式和几何形状(如点、线、曲线、多边形等)来描述图像。每个图形元素都定义了其位置、大小、颜色和方向等属性。矢量图像的优点是可以无限缩放而不会损失清晰度,适合于线条图、图标、字体和图形设计等。常见的矢量图像格式有SVG、AI、EPS等。矢量图在打印、标志设计和需要高分辨率输出的场景下更为适用。
RGB表示红,绿,蓝三原色,计算机里所有的颜色都是三原色不同比例组成的,即三色通道;
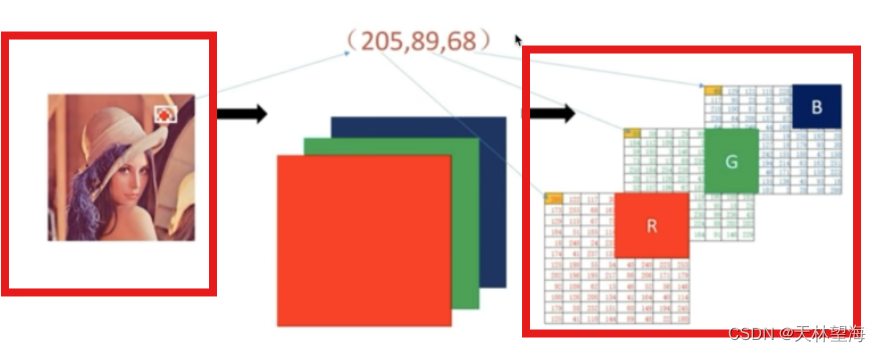
4.3 图像传递
将二维图像经过flatten 展开成一维输入全连接网络中,如图;
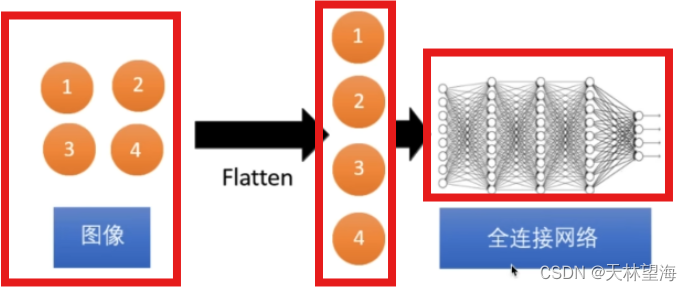
4.4 训练数据
输入一组照片,通过全连接层的处理输出预测值和损失,损失越小越接近真实结果,因此需要找到最好的参数,即让所有的损失和最小,那么如何找到最好的参数呢?我们选用的方法是梯度下降:
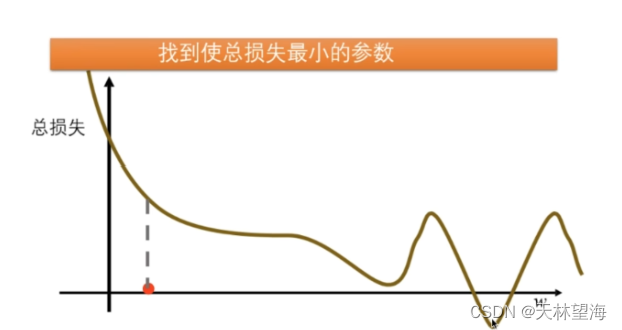
通过梯度下降不断迭代,调整初始参数,找到总损失比较小的最佳参数
5 模型架构设计
猫狗识别项目的核心是构建一个CNN模型。CNN利用卷积层来提取图像特征,池化层来降低维度,以及全连接层来进行分类决策。一个基本的CNN架构可能包括以下层次:
5.1 CNN模型

- 卷积层:使用不同大小的滤波器(kernel)滑动过图像,捕捉边缘、纹理等低级特征。 卷积核在原始图片中起到探测模式的作用。可以发现卷积核的维度比原始图像要小,实现卷积的过程就是开始时,让卷积核从原始图像左上角对齐,对应每个小格子位置相乘,再将所有的结果相加,得到卷积结果矩阵的第一个值;再将卷积核向右移动,遍历原始图像,以此类推
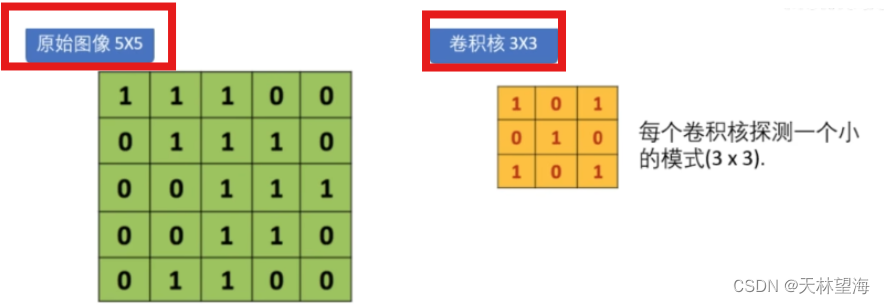 不同的卷积核有不同的效果,而其中的值都是需要学习的参数
不同的卷积核有不同的效果,而其中的值都是需要学习的参数-
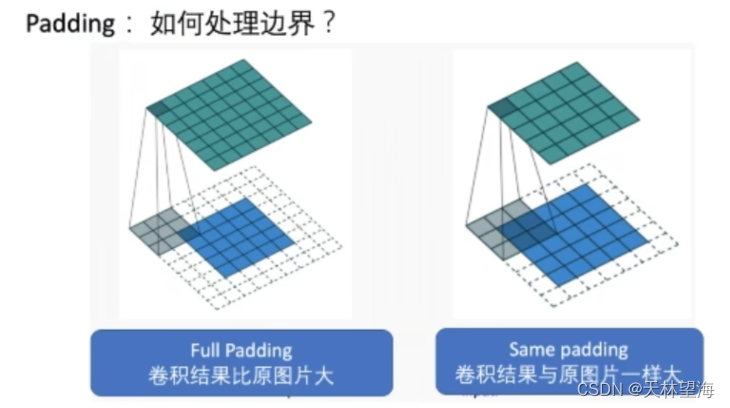
边界处理:有两种边界处理方式,Full Padding和Same Padding,
-
- 激活函数:如ReLU,用来增加网络的非线性。
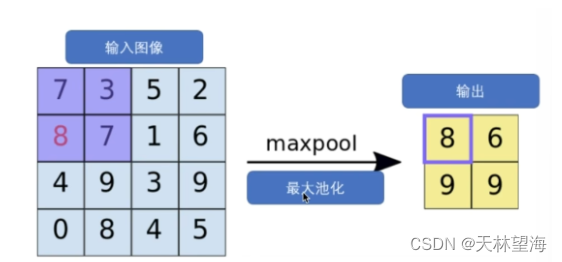
- 最大池化层(如MaxPooling):在每个小区域内最大值取出来组合,起到图像缩放的作用,减少参数。
-
-
Flatten层:将二维图像经过flatten 展开成一维输入全连接层中.
- 全连接层(Dense层):将特征映射到最终的类别输出。
- 输出层:使用Softmax激活函数,输出每个类别的概率分布。
5.2 训练模型代码
CNN_train.py
"""
@Project :BP-CNN猫狗识别
@IDE :PyCharm与Vscode软件均可正常运行
@Python解释器 :Python 312
@tensorflow版本:2.16.1(Windows平台下使用Python3.9~3.12解释器)
@数据集位置 : Project\dogs_cats\data(相对路径)
"""
# 环境配置特别注意,Keras现在作为TensorFlow的高级API集成在内,因此不需要单独安装Keras,只需执行:pip install tensorflow即可
# keras导入方法:keras之前要加tensorflow才能正确引入
# 导入需要的包
from tensorflow.keras.models import Sequential # type: ignore
from tensorflow.keras.layers import Conv2D # type: ignore
from tensorflow.keras.layers import MaxPooling2D # type: ignore
from tensorflow.keras.layers import Dense # type: ignore
from tensorflow.keras.layers import Flatten # type: ignore
from tensorflow.keras.optimizers import SGD # type: ignore
from tensorflow.keras.preprocessing.image import ImageDataGenerator # type: ignore
import tensorflow as tf
tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.ERROR)
# todo:创建一个cnn模型
def define_cnn_model():
# 使用序列模型
model = Sequential()
# 卷积层
model.add(Conv2D(32, (3, 3), activation="relu",
kernel_initializer='he_uniform',
padding="same",
input_shape=(200, 200, 3)))
'''卷积核数量,卷积核维度,激活函数,padding,图片像素200x200'''
# 最大池化层
model.add(MaxPooling2D((2, 2)))
# Flatten 层
model.add(Flatten())
# 全连接层
model.add(Dense(128, activation="relu", kernel_initializer='he_uniform'))
model.add(Dense(1, activation="sigmoid")) # 输出层0,1,sigmoid模型实现输出值0~1之间,分别代表猫狗
# 编译模型
opt = SGD(learning_rate=0.001, momentum=0.9) # 优化器,随机梯度下降,为模型找到最佳的参数
model.compile(optimizer=opt,
loss='binary_crossentropy',
metrics=['accuracy'])
return model
# 打印模型图片
from tensorflow.keras.utils import plot_model # type: ignore
model = define_cnn_model()
plot_model(model,
to_file='cnn_model_basic.png',
dpi=100,
show_shapes=True,
show_layer_names=True)
# 训练模型
def train_cnn_model():
# 实例化模型
model = define_cnn_model()
# 创建图片生成器,产生图片并输入
datagen = ImageDataGenerator(rescale=1.0 / 225.0)
train_it = datagen.flow_from_directory(
'G:\\机器学习\\RobotLearning\\4-BP\\Project\\dogs_cats\\data\\train',
class_mode='binary',
batch_size=64, # 一次产生并输入64张图片
target_size=(200, 200) # 缩放图片为200x200,和输入图片大小相同
)
# 训练模型
model.fit(train_it,
steps_per_epoch=len(train_it),
epochs=20,
verbose=1)
# 把模型保存到文件夹
model.save("G:\\机器学习\\RobotLearning\\4-BP\\Data_clean\\basic_cnn_result.h5")
if __name__ == "__main__":
train_cnn_model()
5.3 测试(预测)模型代码
CNN_predict.py
"""
@Project :BP-CNN猫狗识别
@IDE :适用PyCharm与Vscode软件平稳运行
@Python解释器 :Python 312
@tensorflow版本:2.16.1(Windows平台下使用Python3.9~3.12解释器)
@数据集位置 : Project\dogs_cats\data(相对路径)
"""
import os, random
import numpy as np
from PIL import Image
from tensorflow.keras.models import load_model # type: ignore
# 模型地址
model_path = 'G:\\机器学习\\RobotLearning\\4-BP\\Data_clean\\basic_cnn_result.h5'
# 载入模型
model = load_model(model_path)
# 定义函数读取测试文件夹中的照片
def read_random_image():
folder = r'G:\\机器学习\\RobotLearning\\4-BP\\Project\\dogs_cats\\data\\test\\'
file_path = folder + random.choice(os.listdir(folder))
print(file_path)
pil_im = Image.open(file_path, 'r')
return pil_im
# 对一个使用模型对读取出的图片进行预测
def get_predict(pil_im, model):
# 对图片进行缩放
pil_im = pil_im.resize((200, 200))
# 将格式转换为 numpy array 格式
array_im = np.asarray(pil_im)
array_im = np.expand_dims(array_im, axis=0)
# 对图片进行预测
result = model.predict(array_im)
if result[0][0] > 0.5:
print("本次预测结果是:狗")
else:
print("本次预测结果是:猫")
pil_im = read_random_image()
get_predict(pil_im, model)
pil_im.show(np.asarray(pil_im)) # 显示随机选取的照片
最后,使用save方法把训练好的模型保存到指定路径下的h5文件格式中
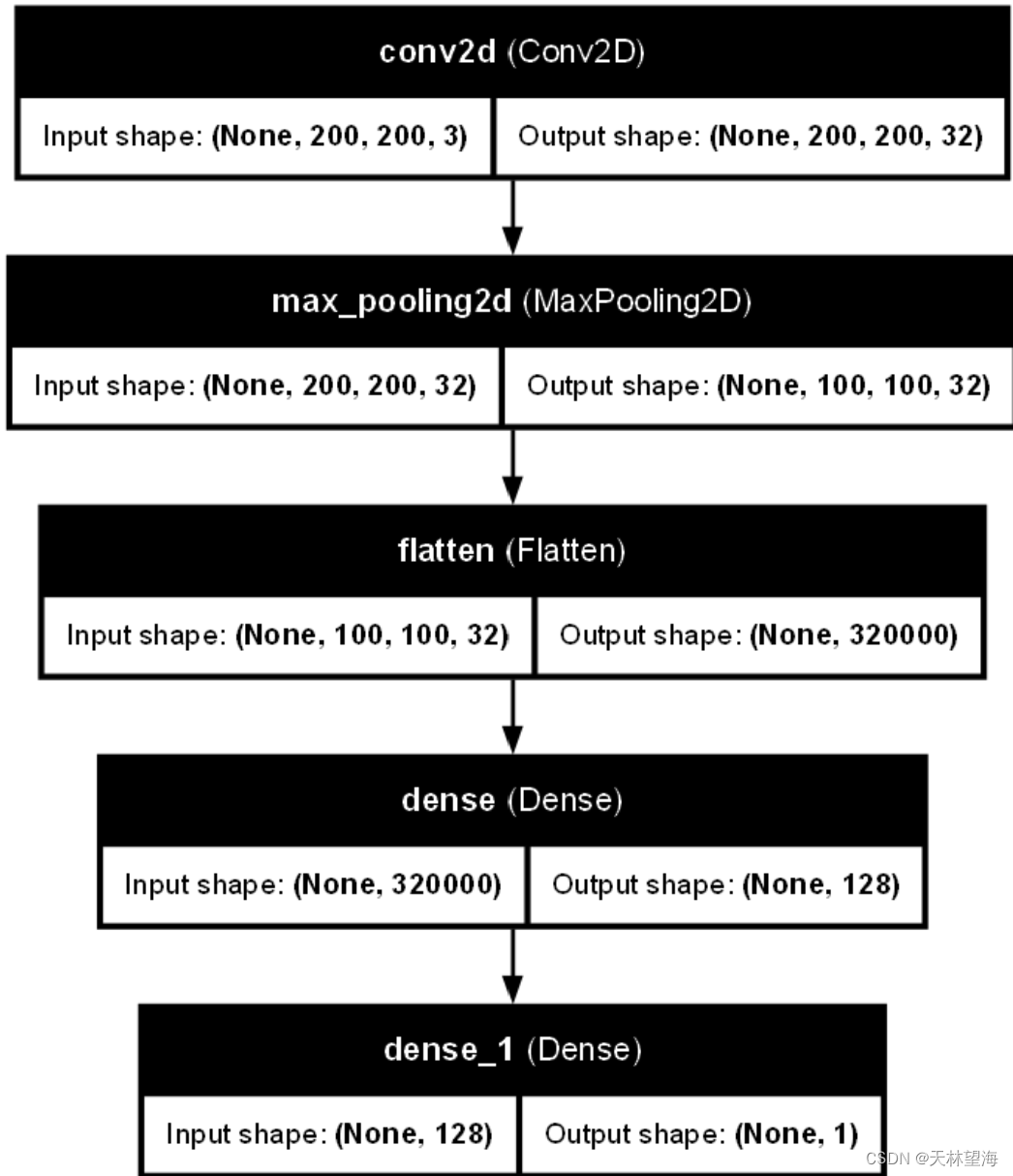
5.4 代码调试运行中问题
#安装tensorflow:
使用 pip 安装:打开命令提示符或Pycharm或者Vscode的终端均可,选择好固定版本的Python解释器,运行以下命令安装 TensorFlow CPU 版本,现在安装默认是最新版本tensorflow-2.16.1,使用这个版本存在一些问题,我已经在代码中解决,
pip install tensorflow# 环境配置特别注意,Keras现在作为TensorFlow的高级API集成在内,因此不需要单独安装Keras,只需执行:pip install tensorflow即可
# keras导入方法:keras之前要加tensorflow才能正确引入
Tensorflow与Python、CUDA、cuDNN的版本对应表(适用Windows平台下,以下给出),LInux和Mac操作系统下的见转自博主文章链接:Tensorflow与Python、CUDA、cuDNN的版本对应表_tensorflow版本对应python3.11-CSDN博客
Windows-CPU
| Version | Python version | Compiler | Build tools |
|---|---|---|---|
| tensorflow-2.16.1 | 3.9-3.12 | MSVC 2019 | Bazel 6.5.0 |
| tensorflow-2.15.0 | 3.9-3.11 | MSVC 2019 | Bazel 6.1.0 |
| tensorflow-2.14.0 | 3.9-3.11 | MSVC 2019 | Bazel 6.1.0 |
| tensorflow-2.12.0 | 3.8-3.11 | MSVC 2019 | Bazel 5.3.0 |
| tensorflow-2.11.0 | 3.7-3.10 | MSVC 2019 | Bazel 5.3.0 |
| tensorflow-2.10.0 | 3.7-3.10 | MSVC 2019 | Bazel 5.1.1 |
| tensorflow-2.9.0 | 3.7-3.10 | MSVC 2019 | Bazel 5.0.0 |
| tensorflow-2.8.0 | 3.7-3.10 | MSVC 2019 | Bazel 4.2.1 |
| tensorflow-2.7.0 | 3.7-3.9 | MSVC 2019 | Bazel 3.7.2 |
| tensorflow-2.6.0 | 3.6-3.9 | MSVC 2019 | Bazel 3.7.2 |
| tensorflow-2.5.0 | 3.6-3.9 | MSVC 2019 | Bazel 3.7.2 |
| tensorflow-2.4.0 | 3.6-3.8 | MSVC 2019 | Bazel 3.1.0 |
| tensorflow-2.3.0 | 3.5-3.8 | MSVC 2019 | Bazel 3.1.0 |
| tensorflow-2.2.0 | 3.5-3.8 | MSVC 2019 | Bazel 2.0.0 |
| tensorflow-2.1.0 | 3.5-3.7 | MSVC 2019 | Bazel 0.27.1-0.29.1 |
| tensorflow-2.0.0 | 3.5-3.7 | MSVC 2017 | Bazel 0.26.1 |
| tensorflow-1.15.0 | 3.5-3.7 | MSVC 2017 | Bazel 0.26.1 |
| tensorflow-1.14.0 | 3.5-3.7 | MSVC 2017 | Bazel 0.24.1-0.25.2 |
| tensorflow-1.13.0 | 3.5-3.7 | MSVC 2015 update 3 | Bazel 0.19.0-0.21.0 |
| tensorflow-1.12.0 | 3.5-3.6 | MSVC 2015 update 3 | Bazel 0.15.0 |
| tensorflow-1.11.0 | 3.5-3.6 | MSVC 2015 update 3 | Bazel 0.15.0 |
| tensorflow-1.10.0 | 3.5-3.6 | MSVC 2015 update 3 | Cmake v3.6.3 |
| tensorflow-1.9.0 | 3.5-3.6 | MSVC 2015 update 3 | Cmake v3.6.3 |
| tensorflow-1.8.0 | 3.5-3.6 | MSVC 2015 update 3 | Cmake v3.6.3 |
| tensorflow-1.7.0 | 3.5-3.6 | MSVC 2015 update 3 | Cmake v3.6.3 |
| tensorflow-1.6.0 | 3.5-3.6 | MSVC 2015 update 3 | Cmake v3.6.3 |
| tensorflow-1.5.0 | 3.5-3.6 | MSVC 2015 update 3 | Cmake v3.6.3 |
| tensorflow-1.4.0 | 3.5-3.6 | MSVC 2015 update 3 | Cmake v3.6.3 |
| tensorflow-1.3.0 | 3.5-3.6 | MSVC 2015 update 3 | Cmake v3.6.3 |
| tensorflow-1.2.0 | 3.5-3.6 | MSVC 2015 update 3 | Cmake v3.6.3 |
| tensorflow-1.1.0 | 3.5 | MSVC 2015 update 3 | Cmake v3.6.3 |
| tensorflow-1.0.0 | 3.5 | MSVC 2015 update 3 | Cmake v3.6.3 |
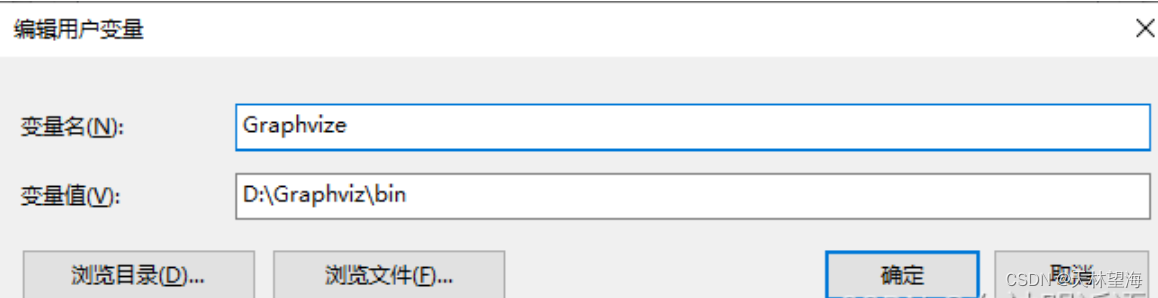
#pydot和graphviz的包下载问题,解决办法:
pip install pydot然后第二个包要去官网下载:https://graphviz.gitlab.io/download/ 官网,下载之后配置一下

















 689
689











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











