







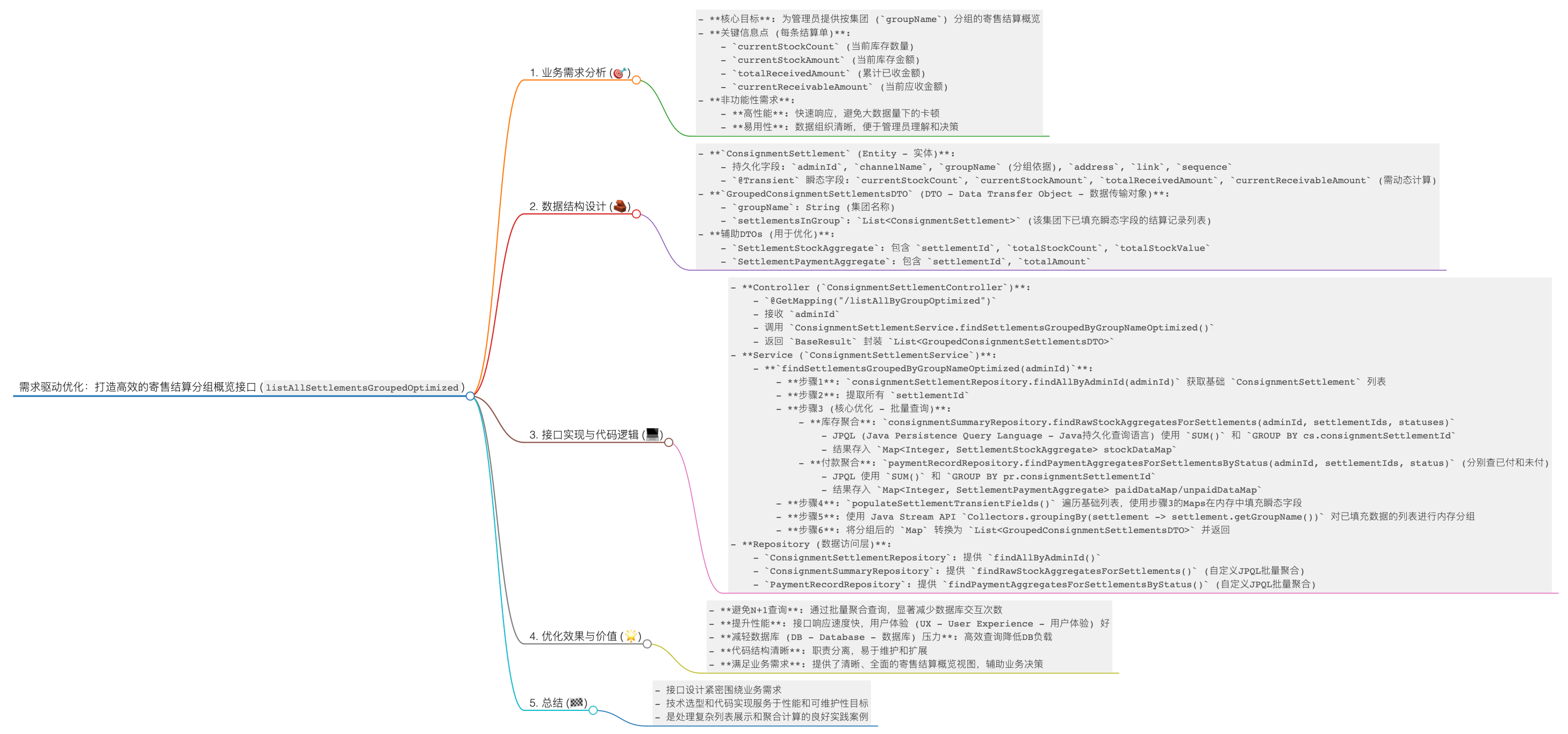
🌟 需求驱动优化:打造高效的寄售结算分组概览接口 (listAllSettlementsGroupedOptimized) 📊
在复杂的企业资源规划 (ERP - Enterprise Resource Planning) 或供应链管理 (SCM - Supply Chain Management) 系统中,寄售业务是一个常见的模块。管理者往往需要从宏观层面快速掌握各个渠道或集团的寄售结算情况,以便进行决策分析。本文将深入探讨一个旨在满足此类需求的接口——listAllSettlementsGroupedOptimized,分析其背后的业务需求、设计思路以及如何通过代码实现性能优化。
🤔 一、需求缘起:为何需要按集团分组的寄售结算概览?
想象一下,您是一家大型企业的寄售业务负责人,旗下有数十个甚至上百个不同的寄售渠道,这些渠道可能归属于不同的业务集团(例如,按地区划分的华东集团、华北集团,或按客户类型划分的KA集团、中小客户集团等)。每天,您都需要关注:
- 各集团的整体表现如何? 哪个集团的库存周转最快?哪个集团的回款情况最好?
- 具体到每个结算渠道:
- 当前还有多少货在渠道手上?(
currentStockCount- 当前库存数量) - 这些货值多少钱?(
currentStockAmount- 当前库存金额) - 这个渠道累计已经给我们付了多少钱了?(
totalReceivedAmount- 累计已收金额) - 还有多少钱是这个渠道欠着我们的?(
currentReceivableAmount- 当前应收金额)
- 当前还有多少货在渠道手上?(
- 数据获取效率:我不想等半天才能看到这些数据,系统必须快速响应!
如果系统只能提供一个长长的、未分组的结算单列表,或者需要用户手动逐条去查询每个渠道的详细库存和财务数据,那无疑是低效且令人沮丧的。
因此,核心需求浮出水面:
为管理员提供一个按“集团名称 (
groupName)”分组的寄售结算 (ConsignmentSettlement) 概览视图,其中每条结算记录都需要清晰展示其当前的库存数量、库存金额、累计已收金额和当前应收金额,并且整个视图的加载必须高效。
这就是 listAllSettlementsGroupedOptimized 接口诞生的使命。
📝 二、需求转化为数据结构:实体与DTO的设计
为了满足上述需求,我们需要定义合适的数据结构。
-
ConsignmentSettlement(寄售结算实体): 这是核心业务对象。// package com.productQualification.api.entity; // ... imports ... @Entity @Data @Table(name = "consignment_settlement") @ApiModel(value = "寄售库存结算实体类") public class ConsignmentSettlement extends BaseEntity { @ApiModelProperty(value = "管理员id") private Integer adminId; @ApiModelProperty(value = "渠道名") @Column(name = "channel_name") private String channelName; @ApiModelProperty(value = "归属集团") @Column(name = "group_name") private String groupName; // 分组的关键字段 // ... 其他持久化字段如 address, link, sequence ... // 👇 这些是需要动态计算的瞬态字段 @ApiModelProperty(value = "当前库存数量") @Transient private Integer currentStockCount; @ApiModelProperty(value = "当前库存金额") @Transient private BigDecimal currentStockAmount; @ApiModelProperty(value = "累计收货金额") // 语义上更接近“累计已付/已收金额” @Transient private BigDecimal totalReceivedAmount; @ApiModelProperty(value = "当前应收金额") @Transient private BigDecimal currentReceivableAmount; }关键点在于
groupName字段用于分组,以及四个@Transient标记的字段,它们的值不直接存储在consignment_settlement表中,需要通过关联查询计算。 -
GroupedConsignmentSettlementsDTO(分组结算DTO): 这是接口最终返回的数据结构中的元素。// package com.productQualification.api.entity; // ... imports ... @Data @NoArgsConstructor @AllArgsConstructor @ApiModel(value = "GroupedConsignmentSettlementsDTO", description = "按groupName分组的寄售结算数据DTO") public class GroupedConsignmentSettlementsDTO { @ApiModelProperty(value = "集团名称 (groupName)") private String groupName; // 分组的依据 @ApiModelProperty(value = "该集团下的所有寄售结算记录列表 (已填充瞬态字段)") private List<ConsignmentSettlement> settlementsInGroup; }它清晰地表达了“一个集团名称”对应“一组已填充完整信息的结算记录”。
-
SettlementStockAggregate&SettlementPaymentAggregate(聚合数据DTO): 这两个DTO是性能优化的辅助工具,用于承载从数据库批量查询的聚合结果,避免N+1查询。// SettlementStockAggregate.java // ... (包含 settlementId, totalStockCount, totalStockValue) // SettlementPaymentAggregate.java // ... (包含 settlementId, totalAmount)
🚀 三、接口实现:从Controller到Service的优化之旅
3.1 Controller层:请求入口
// package com.productQualification.api.controller.consignmentSettlement;
// ... imports ...
@RestController
@RequestMapping("/api/consignmentSettlement")
public class ConsignmentSettlementController {
@Autowired
private ConsignmentSettlementService consignmentSettlementService;
// ... logger and constants ...
@GetMapping("/listAllByGroupOptimized")
@ApiOperation("获取当前管理员的所有寄售结算信息(按groupName分组,优化版)")
public BaseResult listAllSettlementsGroupedOptimized(
@EffectiveAdminId(toolType = CONSIGNMENT_TOOL_TYPE) Integer adminId) {
try {
// 核心逻辑委托给 Service 层
List<GroupedConsignmentSettlementsDTO> groupedResult =
consignmentSettlementService.findSettlementsGroupedByGroupNameOptimized(adminId);
return BaseResult.success("查询成功", groupedResult);
} catch (Exception e) {
log.error("获取按groupName分组的寄售结算信息失败 (优化版): adminId={}, error={}", adminId, e.getMessage(), e);
return BaseResult.failure(BaseResult.FAILURE, "查询失败:" + e.getMessage());
}
}
}
Controller层非常简洁,它接收请求,通过 @EffectiveAdminId 获取当前操作员ID,然后将核心处理逻辑全权交给 ConsignmentSettlementService。
3.2 Service层:满足需求的核心与优化
ConsignmentSettlementService 中的 findSettlementsGroupedByGroupNameOptimized 方法是实现需求并进行优化的关键。
核心步骤与代码片段分析:
-
获取基础结算数据 (Step 1):
// ConsignmentSettlementService.java @Transactional(readOnly = true) public List<GroupedConsignmentSettlementsDTO> findSettlementsGroupedByGroupNameOptimized(Integer adminId) { log.info("优化版 Service - 获取按 groupName 分组的寄售结算: adminId={}", adminId); // 1. 获取该管理员下的所有 ConsignmentSettlement 记录 List<ConsignmentSettlement> allSettlementsFromDB = consignmentSettlementRepository.findAllByAdminId(adminId); if (CollectionUtils.isEmpty(allSettlementsFromDB)) { log.info("管理员ID: {} 下没有找到任何寄售结算记录。", adminId); return Collections.emptyList(); } // ... }首先,通过
ConsignmentSettlementRepository从数据库获取指定adminId下的所有ConsignmentSettlement记录。此时,这些对象的瞬态字段(如currentStockCount)还是空的。 -
收集ID用于批量查询 (Step 2):
// ConsignmentSettlementService.java (continued) // 2. 收集所有 ConsignmentSettlement ID 用于批量查询瞬态数据 List<Integer> allSettlementIds = allSettlementsFromDB.stream() .map(ConsignmentSettlement::getId) .filter(Objects::nonNull).distinct().collect(Collectors.toList()); // 处理所有 settlement ID 都为 null 的边缘情况 (略)提取所有
ConsignmentSettlement的ID,这些ID将用于后续的批量聚合查询。 -
批量查询聚合数据 (Step 3 - 🚀 性能优化的核心):
这是解决N+1查询,满足“高效”需求的关键。- 库存聚合数据:
这里调用了// ConsignmentSettlementService.java (continued) Map<Integer, SettlementStockAggregate> stockDataMap = new HashMap<>(); // 调用 ConsignmentSummaryRepository 的批量查询方法 List<Object[]> rawStockAggregates = consignmentSummaryRepository.findRawStockAggregatesForSettlements( adminId, allSettlementIds, STOCK_CALCULATION_STATUSES); for (Object[] row : rawStockAggregates) { Integer settlementId = (Integer) row[0]; Long sumStockInCount = (row[1] != null) ? ((Number) row[1]).longValue() : 0L; // ... (处理 sumStockValue 的类型转换和精度) ... BigDecimal sumStockValue = ...; // 假设已处理好 stockDataMap.put(settlementId, new SettlementStockAggregate(settlementId, sumStockInCount, sumStockValue)); }ConsignmentSummaryRepository的findRawStockAggregatesForSettlements方法。该方法(如下所示)通过一个JPQL查询,在数据库层面就完成了对指定settlementIds的库存数量和库存金额的聚合。// ConsignmentSummaryRepository.java @Query("SELECT " + "cs.consignmentSettlementId, " + "SUM(cs.stockInCount), " + // 计算总库存数量 "SUM(cs.stockInCount * cs.currentSettlementPrice) " + // 计算总库存金额 "FROM ConsignmentSummary cs " + "WHERE cs.adminId = :adminId AND cs.consignmentSettlementId IN :settlementIds AND cs.status IN :statuses " + "GROUP BY cs.consignmentSettlementId") // 按结算ID分组 List<Object[]> findRawStockAggregatesForSettlements(...); - 付款聚合数据 (已付/未付):
类似地,调用// ConsignmentSettlementService.java (continued) // 已付款 Map<Integer, SettlementPaymentAggregate> paidDataMap = paymentRecordRepository.findPaymentAggregatesForSettlementsByStatus( adminId, allSettlementsIds, PaymentRecordService.PAYMENT_STATUS_PAID).stream() .collect(Collectors.toMap(SettlementPaymentAggregate::getSettlementId, Function.identity(), (o1, o2) -> o1)); // 未付款 Map<Integer, SettlementPaymentAggregate> unpaidDataMap = paymentRecordRepository.findPaymentAggregatesForSettlementsByStatus( adminId, allSettlementIds, PaymentRecordService.PAYMENT_STATUS_UNPAID).stream() .collect(Collectors.toMap(SettlementPaymentAggregate::getSettlementId, Function.identity(), (o1, o2) -> o1));PaymentRecordRepository的findPaymentAggregatesForSettlementsByStatus方法。
这两个批量查询将数据库交互次数降至最低,极大地提升了性能。// PaymentRecordRepository.java @Query("SELECT new com.productQualification.api.entity.SettlementPaymentAggregate(" + "pr.consignmentSettlementId, SUM(pr.totalAmount)) " + // 计算总金额 "FROM PaymentRecord pr " + "WHERE pr.adminId = :adminId AND pr.consignmentSettlementId IN :settlementIds AND pr.status = :status " + "GROUP BY pr.consignmentSettlementId") // 按结算ID分组 List<SettlementPaymentAggregate> findPaymentAggregatesForSettlementsByStatus(...);
- 库存聚合数据:
-
填充瞬态字段 (Step 4):
// ConsignmentSettlementService.java (continued) // 4. 遍历原始的 allSettlementsFromDB 列表,使用批量获取的数据填充瞬态字段 for (ConsignmentSettlement settlement : allSettlementsFromDB) { populateSettlementTransientFields(settlement, stockDataMap, paidDataMap, unpaidDataMap); }populateSettlementTransientFields方法(代码略,已在之前分析中提供)负责从上一步构建的Map中取出对应settlementId的聚合数据,并设置到ConsignmentSettlement对象的瞬态字段上。这个过程在内存中进行,非常快速。 -
内存中分组 (Step 5):
// ConsignmentSettlementService.java (continued) // 5. **关键改动**:直接对已经填充好瞬态字段的 allSettlementsFromDB 列表进行分组 Map<String, List<ConsignmentSettlement>> groupedSettlements = allSettlementsFromDB.stream() .collect(Collectors.groupingBy( settlement -> StringUtils.defaultIfBlank(settlement.getGroupName(), "未指定分组") // 按 groupName 分组 ));现在,
allSettlementsFromDB列表中的每个ConsignmentSettlement都包含了完整的业务数据(包括动态计算的瞬态字段)。使用Java Stream API的groupingBy操作符,在内存中高效地按groupName进行分组。 -
转换为DTO并返回 (Step 6):
// ConsignmentSettlementService.java (continued) // 6. 将分组结果转换为 DTO 列表 List<GroupedConsignmentSettlementsDTO> resultList = groupedSettlements.entrySet().stream() .map(entry -> new GroupedConsignmentSettlementsDTO(entry.getKey(), entry.getValue())) .sorted(Comparator.comparing(GroupedConsignmentSettlementsDTO::getGroupName, Comparator.nullsLast(String::compareToIgnoreCase))) // 可选排序 .collect(Collectors.toList()); log.info("优化版 Service - 为管理员ID: {} 成功获取并按groupName分组了 {} 个组的寄售结算信息。", adminId, resultList.size()); return resultList;最后,将分组后的
Map转换为用户期望的List<GroupedConsignmentSettlementsDTO>格式。
🌊 四、接口逻辑流程:Mermaid 流程图
🔄 五、交互时序:Mermaid Sequence Diagram
💡 六、总结:需求驱动,代码落地
listAllSettlementsGroupedOptimized 接口的设计和实现清晰地展示了如何从业务需求出发,通过合理的数据结构设计和巧妙的查询优化,最终交付一个既满足功能又具备高性能的解决方案。
- 满足了核心业务需求:按集团分组展示,并提供了关键的动态汇总指标。
- 解决了性能瓶颈:通过批量查询和数据库层面的聚合,有效避免了N+1问题,保证了接口的快速响应。
- 代码结构清晰:Controller, Service, Repository各司其职,业务逻辑和数据访问分离。
这个接口的设计思路对于处理类似“主列表 + 多个动态计算/聚合字段 + 分组展示”的场景具有很好的参考价值。记住,深刻理解需求并选择合适的技术方案,是打造优秀软件产品的基石。🚀
🧠 七、Markdown 思维导图



















 714
714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









