







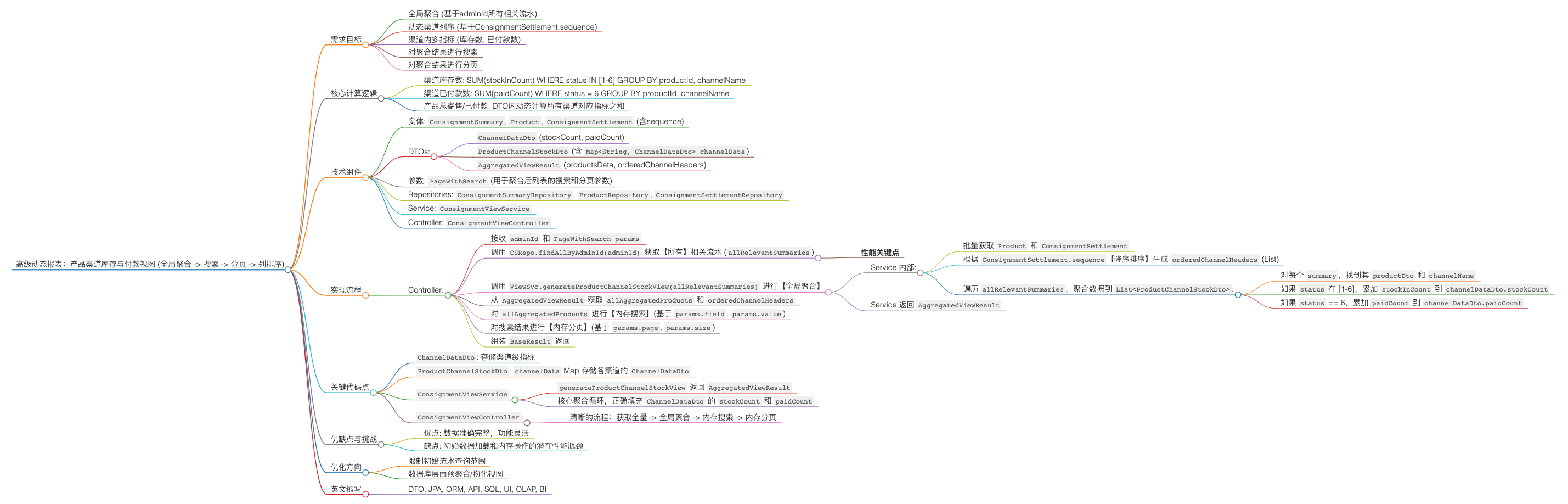
🚀 构建高级动态报表:解密产品渠道库存与付款视图的聚合之路 📊
各位数据爱好者与后端开发者们,大家好!👋 在复杂的业务系统中,我们经常需要从海量的流水数据中提炼出有价值的洞察,并以清晰、可交互的方式呈现给用户。今天,我们将深入一个实战案例:如何将“寄售流水”数据,转换成一个支持搜索、分页、动态列序的“产品渠道库存与付款视图”。
这个视图的核心之一,就是精确计算出每个产品在不同销售渠道下的“库存数”和“已付款数”。我们将揭秘这个计算过程,并展示如何构建这样一个强大的后端服务。
我们将使用 Java、Spring Boot、Spring Data JPA 来实现,并通过 Mermaid 图表清晰展示流程。准备好了吗?一起探索数据聚合的奥秘吧!💡
🎯 报表目标:智能、有序、可交互的库存与付款洞察
我们期望的最终效果是一个动态的报表,用户(管理员)可以看到:
- 全局聚合数据:每个产品的数据(如各渠道库存、各渠道已付款数、总寄售数量、总已付款数量)是基于该管理员名下所有相关流水计算得出的。
- 动态渠道列序:表格中的渠道列会根据其在
ConsignmentSettlement表中的sequence字段进行降序排列(序号大的在前)。 - 渠道内多指标:每个渠道列下,会展示两个子指标:“库存数”和“已付款数”。
- 对聚合结果的搜索:用户可以对聚合后的产品列表进行搜索(例如按产品名称、条形码)。
- 对聚合结果的分页:搜索后的产品列表可以分页展示。
核心计算逻辑详解:
- 渠道库存数 (
channelData.stockCount):- 针对每一个产品,在每一个特定渠道下。
- 累加所有属于该产品和该渠道的
ConsignmentSummary流水记录中,当记录的status(状态)为 1 (入库), 2 (退回), 3 (盘亏), 4 (盘盈), 5 (对账), 或 6 (付款) 之一时,其stockInCount(库存变动数量)字段的值。 - (假设
stockInCount本身带有正负号以表示库存的增减)。
- 渠道已付款数 (
channelData.paidCount):- 针对每一个产品,在每一个特定渠道下。
- 累加所有属于该产品和该渠道的
ConsignmentSummary流水记录中,当记录的status(状态)为 6 (已付款) 时,其paidCount(已付款数量)字段的值。
- 产品总寄售数量 (
ProductChannelStockDto.getTotalConsignmentQuantity()):- 某个产品在所有渠道的“渠道库存数”之和(在DTO中动态计算)。
- 产品总已付款数量 (
ProductChannelStockDto.getTotalProductPaidCount()):- 某个产品在所有渠道的“渠道已付款数”之和(在DTO中动态计算)。
- 产品基础信息(条形码、品名、箱规):从
Product主数据表中获取,以保证数据的准确性。 - 渠道名称及顺序:从
ConsignmentSettlement(寄售结算单) 表中获取,并根据sequence字段排序。
🛠️ 技术栈与核心组件
- 后端:Java, Spring Boot, Spring Data JPA, Lombok
- 核心实体:
ConsignmentSummary:寄售流水总表(含productId,consignmentSettlementId,status,stockInCount,paidCount)。ConsignmentSettlement:寄售结算单表(含id,channelName,sequence)。Product:产品主数据表(含id,jancode,name,carton)。
- DTOs (Data Transfer Objects,数据传输对象):
ChannelDataDto:封装单个渠道的stockCount和paidCount。ProductChannelStockDto:封装单个产品的聚合信息,其channelData字段是一个Map<String, ChannelDataDto>。AggregatedViewResult:服务层返回给Controller的包装对象,包含聚合后的产品数据列表和有序的渠道表头列表。
- 分页与搜索参数封装:
PageWithSearch(继承自BasePage)。 - Repositories:
ConsignmentSummaryRepository,ConsignmentSettlementRepository,ProductRepository。 - Service:
ConsignmentViewService(核心聚合与表头排序逻辑)。 - Controller:
ConsignmentViewController(API接口,编排,内存搜索与分页)。
📝 实现步骤概览:聚合为王,智能展示
| 步骤 | 描述 | 关键点 |
|---|---|---|
| 1 | 定义DTOs (ChannelDataDto, ProductChannelStockDto, AggregatedViewResult) | ProductChannelStockDto 内的 channelData Map 存储 ChannelDataDto;AggregatedViewResult 包装最终结果。 |
| 2 | Controller: 获取全局流水 | 根据 adminId 调用 ConsignmentSummaryRepository.findAllByAdminId() 获取所有相关的 ConsignmentSummary。性能关键点! |
| 3 | Service: 执行全局聚合与渠道排序 | ConsignmentViewService.generateProductChannelStockView():- 批量获取 Product 和 ConsignmentSettlement。- 根据 ConsignmentSettlement.sequence 生成有序的渠道表头列表 (orderedChannelHeaders)。- 遍历所有流水,按产品和渠道聚合 stockInCount (status 1-6) 和 paidCount (status 6) 到 ProductChannelStockDto.channelData 中对应的 ChannelDataDto。- 返回 AggregatedViewResult。 |
| 4 | Controller: 内存搜索 | 对返回的 AggregatedViewResult.getProductsData()(即完整的聚合产品列表),根据 PageWithSearch 中的搜索条件进行内存筛选。 |
| 5 | Controller: 内存分页 | 对搜索后的产品列表,根据 PageWithSearch 中的分页参数进行内存分页。 |
| 6 | Controller: 准备并返回响应 | 组装 BaseResult,包含当前页的产品数据、有序的渠道表头以及针对聚合后产品列表的分页信息。 |
🌊 数据处理流程图 (Mermaid)
⏳ 时序图:一次高级报表API请求 (Mermaid Sequence Diagram)
💡 关键代码片段解析
ChannelDataDto.java 和 ProductChannelStockDto.java
// ChannelDataDto.java
public class ChannelDataDto {
private int stockCount = 0; // 渠道库存 (status 1-6 的 stockInCount 之和)
private int paidCount = 0; // 渠道已付款 (status 6 的 paidCount 之和)
// addStock, addPaid 方法
}
// ProductChannelStockDto.java
public class ProductChannelStockDto {
private Integer productId;
private String jancode; /*...*/
private Map<String, ChannelDataDto> channelData = new HashMap<>(); // 核心变化
// addStockToChannel, addPaidToChannel 方法
// getTotalConsignmentQuantity, getTotalProductPaidCount (动态计算产品级总数)
}
ChannelDataDto 使得我们能在每个渠道下清晰地存储多个指标。ProductChannelStockDto 的 channelData Map 现在存储这些更丰富的渠道数据对象。
ConsignmentViewService.java - 核心聚合逻辑中 paidCount 的计算
// ...
public AggregatedViewResult generateProductChannelStockView(List<ConsignmentSummary> summaries) {
// ... (获取渠道名映射: settlementIdToChannelNameMap) ...
// ... (获取产品信息映射: finalProductIdToProductMap) ...
Map<Integer, ProductChannelStockDto> productViewMap = new LinkedHashMap<>();
final int PAID_STATUS = 6;
final List<Integer> VALID_CHANNEL_STOCK_STATUSES = Arrays.asList(1, 2, 3, 4, 5, 6);
for (ConsignmentSummary summary : summaries) {
// ... (获取或创建 ProductChannelStockDto dto) ...
String channelName = settlementIdToChannelNameMap.get(summary.getConsignmentSettlementId());
if (channelName != null) { // 必须要有有效的渠道名
// 聚合渠道库存 (status 1-6)
if (summary.getStockInCount() != null &&
summary.getStatus() != null &&
VALID_CHANNEL_STOCK_STATUSES.contains(summary.getStatus())) {
dto.addStockToChannel(channelName, summary.getStockInCount());
}
// 聚合【当前渠道】的已付款数量 (status 6)
if (summary.getStatus() != null && summary.getStatus() == PAID_STATUS && summary.getPaidCount() != null) {
dto.addPaidToChannel(channelName, summary.getPaidCount());
}
}
}
// ... (生成 orderedChannelHeaders) ...
return new AggregatedViewResult(new ArrayList<>(productViewMap.values()), orderedChannelHeaders);
}
// ...
paidCount 的计算方式:在遍历每一条 ConsignmentSummary 流水时,如果该条流水的 status 是 6 (已付款) 并且它有关联的 channelName,那么就将这条流水中的 paidCount 值累加到对应产品、对应渠道的 ChannelDataDto 对象的 paidCount 属性上。
📖 常见英文缩写解释
- DTO: Data Transfer Object (数据传输对象) - 用于在层与层之间传递数据的简单对象。
- JPA: Java Persistence API (Java持久化API) - Java EE 和 Java SE 环境中用于对象关系映射 (ORM) 和持久化操作的规范。
- ORM: Object-Relational Mapping (对象关系映射) - 一种编程技术,用于在关系数据库和面向对象编程语言之间转换数据。
- API: Application Programming Interface (应用程序编程接口) - 定义软件组件之间交互方式的一组规则和协议。
- SQL: Structured Query Language (结构化查询语言) - 用于管理关系数据库的标准语言。
- UI: User Interface (用户界面) - 用户与计算机系统交互的界面。
- OLAP: Online Analytical Processing (联机分析处理) - 快速、多维度地分析共享数据的技术。
- BI: Business Intelligence (商业智能) - 将企业中现有的数据转化为知识,帮助企业做出明智的业务经营决策的技术。
🎉 总结与挑战
我们成功构建了一个功能强大的后端服务,它能够将原始流水数据进行全局聚合,生成包含每个产品在各个动态排序渠道下的库存数和已付款数,并支持对最终聚合结果进行搜索和分页。
核心亮点:
- 精确聚合:清晰地计算了每个产品在每个渠道的多个关键指标。
- 动态有序展示:渠道列根据业务定义的顺序动态排列。
- 用户交互友好:支持对最终聚合视图的搜索和分页。
主要挑战与性能考量:
- 初始数据加载:
consignmentSummaryRepository.findAllByAdminId(adminId)是最大的潜在性能瓶颈。如果一个管理员关联的流水数据量巨大,需要重点优化。 - 内存消耗与操作效率:在应用层对大量数据进行聚合、搜索和分页,对内存和CPU有一定要求。
应对策略:
- 优化数据获取:确保
adminId有索引。如果业务允许,考虑在查询初始流水时加入更严格的全局筛选条件(如时间窗口)。 - 数据库层面预聚合:对于数据量极大且性能要求高的场景,考虑使用数据库物化视图或定时任务进行预聚合,将结果存入专门的报表表。
- 评估与监控:上线后持续监控报表接口的性能,根据实际情况调整优化策略。
这个方案为构建复杂的、用户体验良好的动态报表提供了一个坚实的后端基础。希望它能为你处理类似的数据聚合与展示需求带来启发!编码的乐趣在于不断解决挑战,祝你成功!🚀
🧠 思维导图 (Markdown 格式)



















 716
716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









