






本博客为山东大学软件学院2024创新实训,25组可视化课程知识问答系统(VCR)的个人博客,记载个人任务进展
数据爬取与存储
数据爬取与存储是数据处理和分析的前置步骤,包括爬虫的部署、状态监控以及数据存储等多个关键环节。
1. 部署爬虫:将爬虫部署到服务器上,确保能够持续稳定地爬取数据。
部署爬虫到服务器是确保数据爬取持续性和稳定性的关键步骤。首先,选择合适的服务器环境至关重要。服务器应具备稳定的网络连接、足够的计算资源和存储空间,以支持爬虫程序的长时间运行和大量数据的处理。此外,服务器的地理位置和网络带宽也会影响到爬取数据的速度和效率。
在部署过程中,还需考虑爬虫程序的配置和管理。这包括设置合适的爬取频率、处理可能的网络中断或服务器故障等异常情况,以及确保爬虫程序能够自动更新和维护。为了实现这些功能,可能需要编写额外的监控和恢复脚本,或者使用专业的爬虫管理平台。
另外,安全性也是部署爬虫时需要考虑的重要因素。由于爬虫程序可能会暴露服务器的IP地址和访问模式,因此需要采取适当的安全措施,如使用代理IP、加密通信等,以防止被目标网站封锁或遭受恶意攻击。
设置服务器环境
在服务器上,需要安装Python、pip以及你的爬虫所依赖的库(如requests和beautifulsoup4)。你可以使用apt(对于Debian/Ubuntu)或yum(对于CentOS)等包管理器来安装Python,然后使用pip来安装依赖库。
将爬虫上传到服务器
使用scp工具将你的爬虫脚本上传到服务器。
监控和日志记录
为了监控爬虫的运行状态并排查问题,可以使用日志记录功能。此外,使用监控工具来收集和分析爬虫的性能指标。
2. 监控爬虫状态:实时监控爬虫的运行状态,包括爬取速度、成功与失败次数等。
实时监控爬虫状态对于确保数据爬取的连续性和质量至关重要。通过监控,可以及时发现并处理爬虫程序在运行过程中遇到的问题,如网络延迟、目标网站结构变更等。
监控的关键指标包括爬取速度、成功与失败次数等。爬取速度可以反映爬虫程序的性能和效率,而成功与失败次数则可以帮助识别潜在的问题和瓶颈。例如,如果失败次数显著增加,可能意味着目标网站的结构发生了变化,或者爬虫程序遇到了其他障碍。
为了实现实时监控,可以使用日志记录、状态检查和警报系统等工具。日志记录可以帮助追踪爬虫程序的详细活动,包括访问的页面、提取的数据以及遇到的错误等。状态检查可以定期评估爬虫程序的运行状态,并在必要时触发警报。警报系统则可以在出现异常情况时及时通知管理人员,以便迅速采取措施解决问题。
要实现实时监控爬虫的运行状态,我们可以创建一个简单的监控器类,它负责跟踪爬虫的性能指标,并可以定期输出或更新这些指标。以下是一个基于Python的示例,其中包含了一个CrawlerMonitor类,该类使用threading库来异步更新状态,并使用time库来模拟爬虫的爬取过程。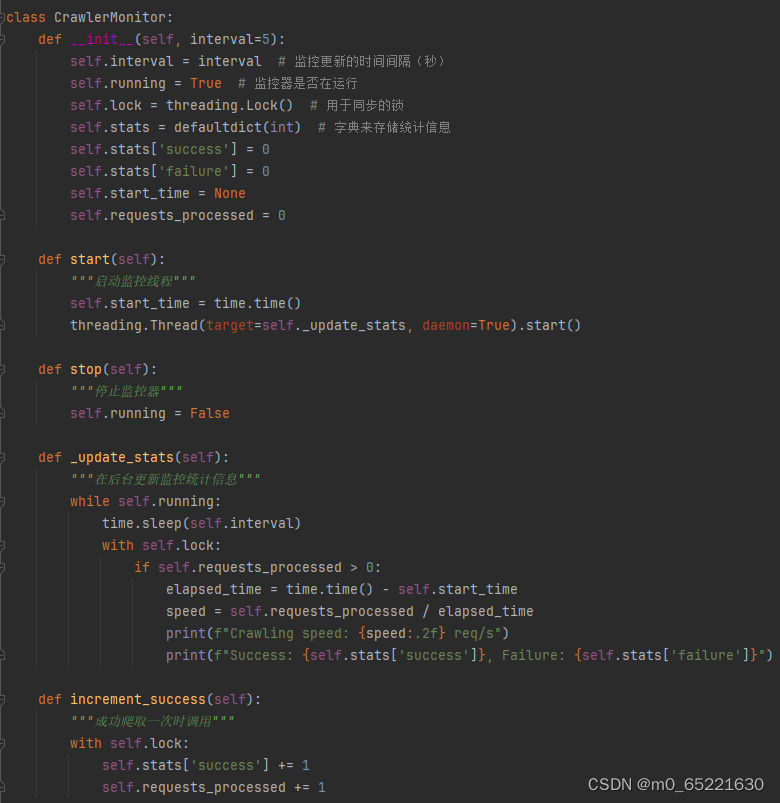
CrawlerMonitor类负责管理爬虫的性能统计。start方法启动一个守护线程来定期更新并打印统计信息,stop方法用于停止监控。increment_success和increment_failure方法分别在爬虫成功或失败时调用,以更新相应的统计信息。
在simulate_crawler函数中,模拟了一个简单的爬虫,它会周期性地增加成功或失败的计数。可以将这个模拟部分替换为实际的爬虫代码。
最后,在主函数中,创建了一个CrawlerMonitor实例,并启动它。然后模拟爬虫的运行,并等待一段时间以确保有足够的数据进行统计。最后,停止监控器并打印一条消息表明模拟结束。
3. 数据存储:将爬取到的数据存储到数据库中,包括标题、内容、来源、时间戳等信息。
数据存储是数据爬取流程中的最后一步,也是至关重要的一环。选择合适的数据库系统对于确保数据的完整性、安全性和可访问性至关重要。
在存储数据时,需要考虑数据的结构和索引设计。合理的数据库表结构和索引可以显著提高查询性能和数据处理速度。例如,可以为经常用于查询的字段创建索引,以减少查询时间。
此外,还需要考虑数据的备份和恢复策略。定期备份数据库可以确保在发生硬件故障或其他意外情况时能够恢复数据。同时,为了应对可能的数据损坏或丢失情况,还应制定灾难恢复计划。
最后,数据的安全性也是存储过程中需要重点关注的问题。应采取适当的安全措施来保护数据库免受未经授权的访问和恶意攻击。这包括使用强密码、限制对数据库的远程访问、定期更新和修补安全漏洞等。
综上所述,数据爬取与存储是一个复杂而细致的过程,涉及多个关键环节和技术挑战。通过精心规划、合理配置和持续监控,可以确保爬虫程序的稳定运行和数据的安全存储,从而为后续的数据分析和应用提供坚实的基础。
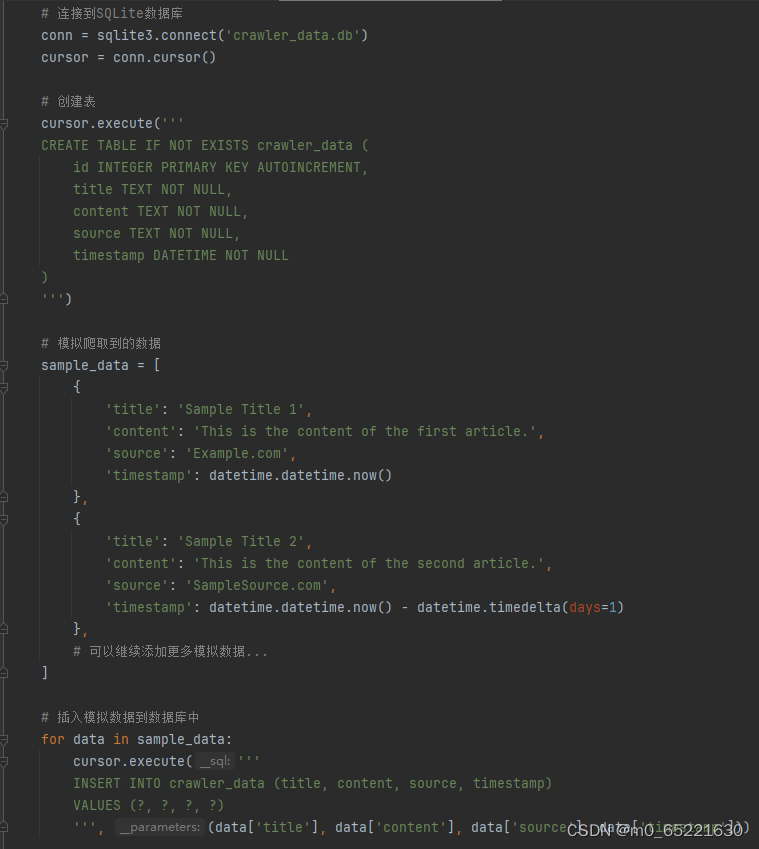
首先连接到SQLite数据库。然后,创建一个名为crawler_data的表,该表包含id、title、content、source和timestamp字段。
接下来,创建了一个包含模拟爬取数据的列表sample_data。这个列表中的每个字典都代表一条爬取到的数据,包含标题、内容、来源和时间戳。
然后,使用一个循环将这些模拟数据插入到数据库中。每次插入后,都通过conn.commit()提交事务,以确保数据被永久保存到数据库中。
最后,执行一个查询来检索并打印数据库中的所有数据,以验证数据已成功插入。完成后,关闭数据库连接。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









