






本博客为山东大学软件学院2024创新实训,25组可视化课程知识问答系统(VCR)的个人博客,记载个人任务进展
爬虫编写与测试的详细实现:爬取百度百科的计算机网络及关联词条
在编写爬虫之前,我们首先要明确需求。本次爬虫的主要目标是:
- 爬取“计算机网络”词条的标题和正文内容。
- 爬取与“计算机网络”相关联的其他词条的链接、标题和简要描述。
为了实现上述需求,我们选择Python作为编程语言来编写爬虫。
1.编写爬虫代码
本实验选择Python作为编程语言,利用其丰富的库和框架进行爬虫开发。首先,构建爬虫的基本结构,包括定义爬虫的入口点、设置请求队列、编写解析器等。凭借高效的数据流控制和可扩展性,处理大规模网页数据的爬取。
使用了BeautifulSoup库来解析HTML文档,提取目标数据。BeautifulSoup提供了灵活的解析方式和简洁的API,能够轻松应对复杂的网页结构。编写了一个能够自动爬取指定网站数据的爬虫程序。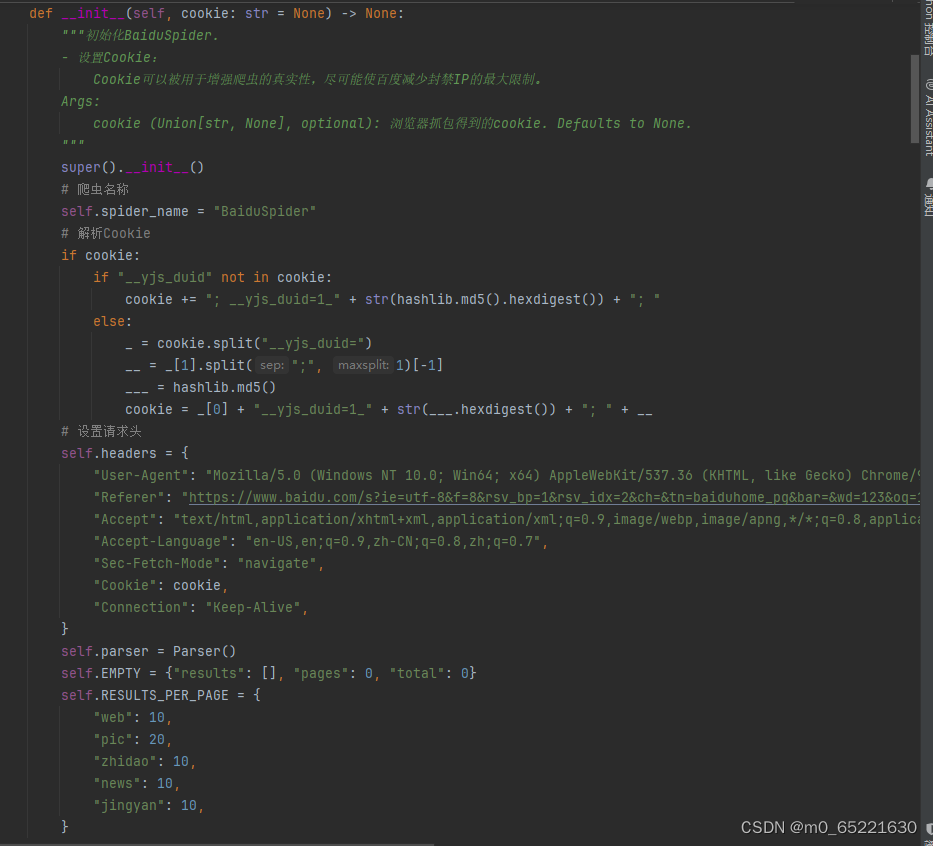
之后按照不同的规则对目标数据进行筛选,爬取
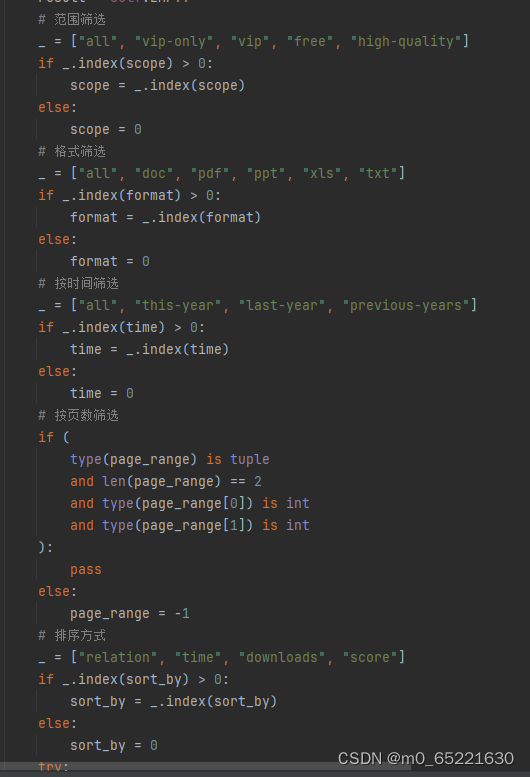
2.本地测试
在本地环境中运行爬虫代码是确保其稳定性和准确性的关键步骤。我们将编写好的爬虫代码部署到本地计算机上,并配置好相关的依赖库和环境变量。然后,通过运行爬虫程序来测试其是否能够正确地爬取目标网站的数据。
在测试过程中,我们关注了几个关键指标:爬虫的运行速度、数据爬取的准确性以及是否存在异常错误。通过多次运行爬虫程序并观察这些指标的变化,我们可以初步评估爬虫的稳定性和准确性。
3.调试与优化
根据本地测试的结果,我们对爬虫代码进行了调试和优化。首先,我们针对爬虫运行速度慢的问题进行了优化,通过调整Scrapy的请求并发数和延迟时间等参数来提高爬虫的爬取效率。其次,我们针对数据爬取不准确的问题进行了调试,通过检查BeautifulSoup的解析逻辑和网页结构的变化来修正解析错误。最后,我们针对异常错误进行了处理,通过添加异常捕获和日志记录等机制来提高爬虫的健壮性。
在调试和优化过程中,我们不断迭代和改进爬虫代码,直到其能够稳定地爬取目标网站的数据。同时,我们还对爬虫程序进行了充分的测试,以确保其在各种情况下都能够正常运行。















 637
637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









