






程序 = 数据结构 + 算法
1.递归
两个特点:调用自身和结束条件
汉诺塔问题:
# 0为盘中数 1为初始盘子 2为经过的盘子 3为目标盘子’
n 为第n盘子 a为第1个柱子 b为第2个柱子 c为第三个柱子
def hanoi(n , a , b , c):
if n > 0:
hanoi(n-1 , a , c , b)
print("moveing from %s to %s" % (a,c))
hanoi(n-1 , b , a , c)
hanoi(3 , 'A' , 'B' , 'C')
汉诺塔移动次数的递推式为:h(x) = 2h(x - 1) + 1
2.选择排序
关键:有序区和无序区、无序区最小数的位置
一趟排序记录最小的数,放在第一个位置
再一趟排序记录列表无序区最小的数,放在第二个位置上
def select_sort(li):
for i in range(len(li) - 1): # i是第几趟
min_loc = i
for j in range(i+1 , len(li)):
if li[j] < li[min_loc]:
min_loc = j
li[i] , li[min_loc] = li[min_loc] , li[i]
li = [1,4,5,6,4,7,8,9,0]
select_sort(li)
print(li)
3.插入排序
def insert_sort(li):
for i in range(1 , len(li)):
tmp = li[i]
j = i - 1
while j >= 0 and li[j] > tmp:
li[j + 1] = li[j]
j -= 1
li[j + 1] = tmp
li = [1,4,5,6,4,7,8,9,0]
insert_sort(li)
print(li)
4. 快速排序
取一个元素p(第一个元素) , 使元素p归为
列表被p分成两部分 ,左边都比p小,右边都比p大
递归完成排序
def partition(li , left , right):
tmp = li[left]
while left < right:
while left < right and li[right] >= tmp: # 从右边找比tmp小的数
right -= 1 # 往左走一步
li[left] = li[right] #把右边的值写道左边空位上
while left < right and li[left] <= tmp:
left += 1
li[right] = li[left] #把左边的值写道左边空位上
li[left] = tmp #把tmp归位
return left
def quick_sort(li , left , right):
if left < right:
mid = partition(li , left , right)
quick_sort(li , left , mid - 1)
quick_sort(li , mid + 1 , right)
li = [1,4,5,6,4,7,8,9,0]
quick_sort(li , 0 , len(li) - 1)
print(li)
5.链表
链表是由一系列节点组成的元素集合。每个节点包含两部分,数据或 item 和指向下一个节点的指针 next 。通过节点之间的相互连接,最终串联成一个链表。
class Node(object):
def __init__(sellf, item):
self.item = item
self.next = None
a = Node(1) 传入
b = Node(2)
c = Node(3)
a.next = b
b.next = c
print(a.next.next.next.item) 读取可自由选择
6.堆排序
二叉树中· 父节点和左孩子的节点编号下标关系为 2i+1
父节点和右孩子的节点编号下标关系为 2i+2
满二叉树:一个二叉树,如果每一层的节点数都达到最大值,则这个二叉树就是满二叉树
完全二叉树:叶节点只能出现在最下层的次下层,并且最下面一层的结点都集中在该层最左边的若干位置的二叉树
heapq 内置方法
import heapq
创建堆:
直接创建:heapq.heapify(list)
添加至堆:heapq.heappush()
合并堆:
heapq.merge()
访问堆内容:
删除堆中最小元素并加入一个元素:heapq.heaprepalce(删除,加入)
获取堆中的最大范围值:heapq.nlargest(个数, list)
获取堆中的最小范围值:heapq.nsmallest(个数, list)
最大最小可以通过接受key参数,用于dict或其他数据类型使用
堆:是一种特殊的完全二叉树结构
大根堆:一颗完全二叉树,满足任一节点都比其孩子节点大
小根堆:一颗完全二叉树,满足任一节点都比其孩子节点小
向下调整:根节点的左右子树都是堆时,可以通过一次向下的调整来将其变成一个堆。
堆排序的 topk 应用
def sift(li, low, high):
i = low
j = 2 * i+ 1
tmp = li[low]
while j<= high:
if j + 1 <= high and li[j+1] < li[j]:
j = j + 1
if li[j] < tmp:
li[i] = li[j]
i = j
j = 2 * i + 1
else:
break
li[i] = tmp
def topk(li , k):
heap = li[0:k]
for i in range((k-1)//2, -1, -1):
sift(heap, i, k-1)
for i in range(k-1, -1, -1):
heap[0], heap[i] = heap[i], heap[0]
sift(heap, 0, i - 1)
return heap
import random
li = list(range(1000))
random.shuffle(li)
print(topk(li, 200))
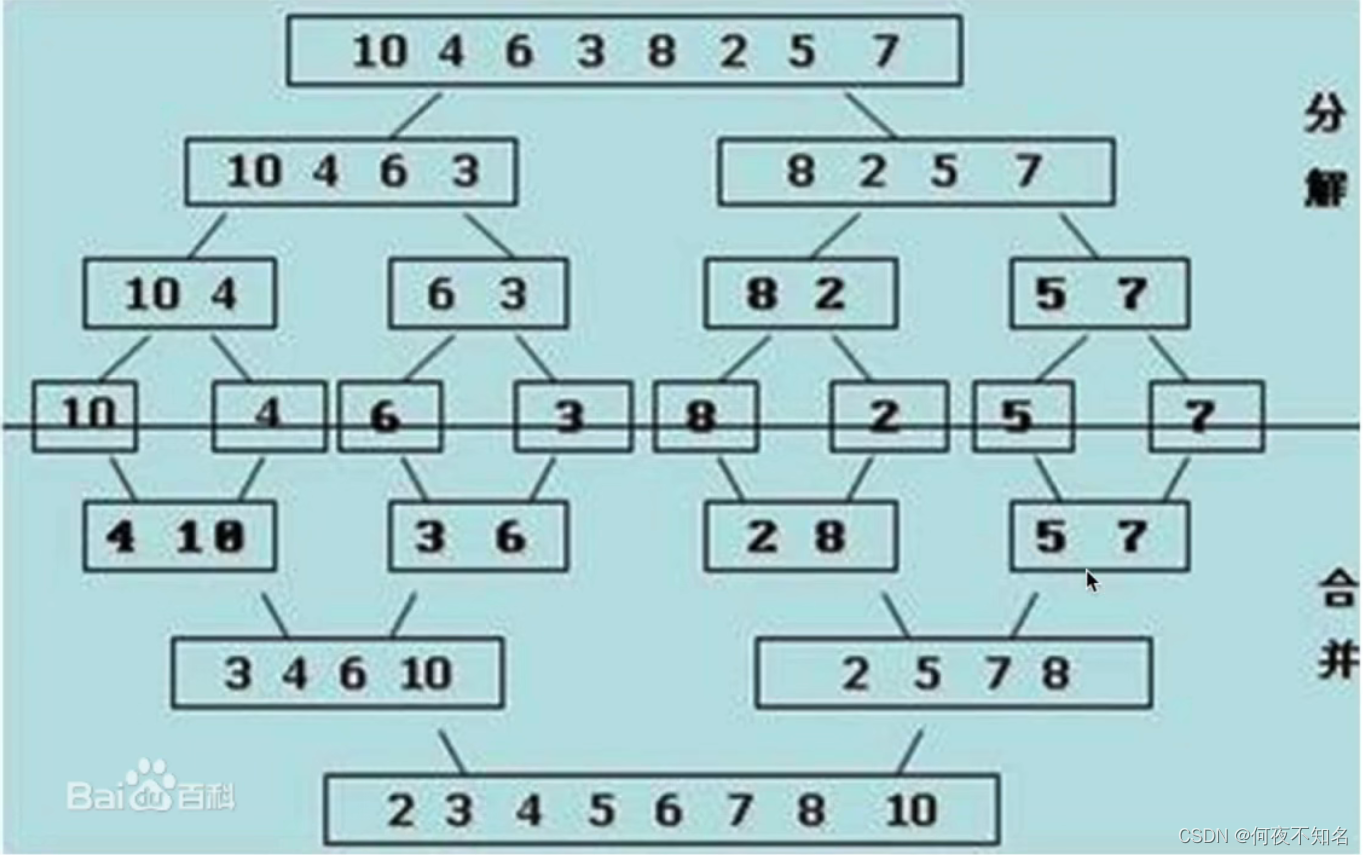
7.归并排序
- 分解:将列表越分越小, 直至分成一个元素
- 终止条件:一个元素是有序的
- 合并:将两个有序列表归并,列表越来越大















 408
408











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









