









关键词:二叉树编号,遍历(BFS / DFS / 递归),
目录
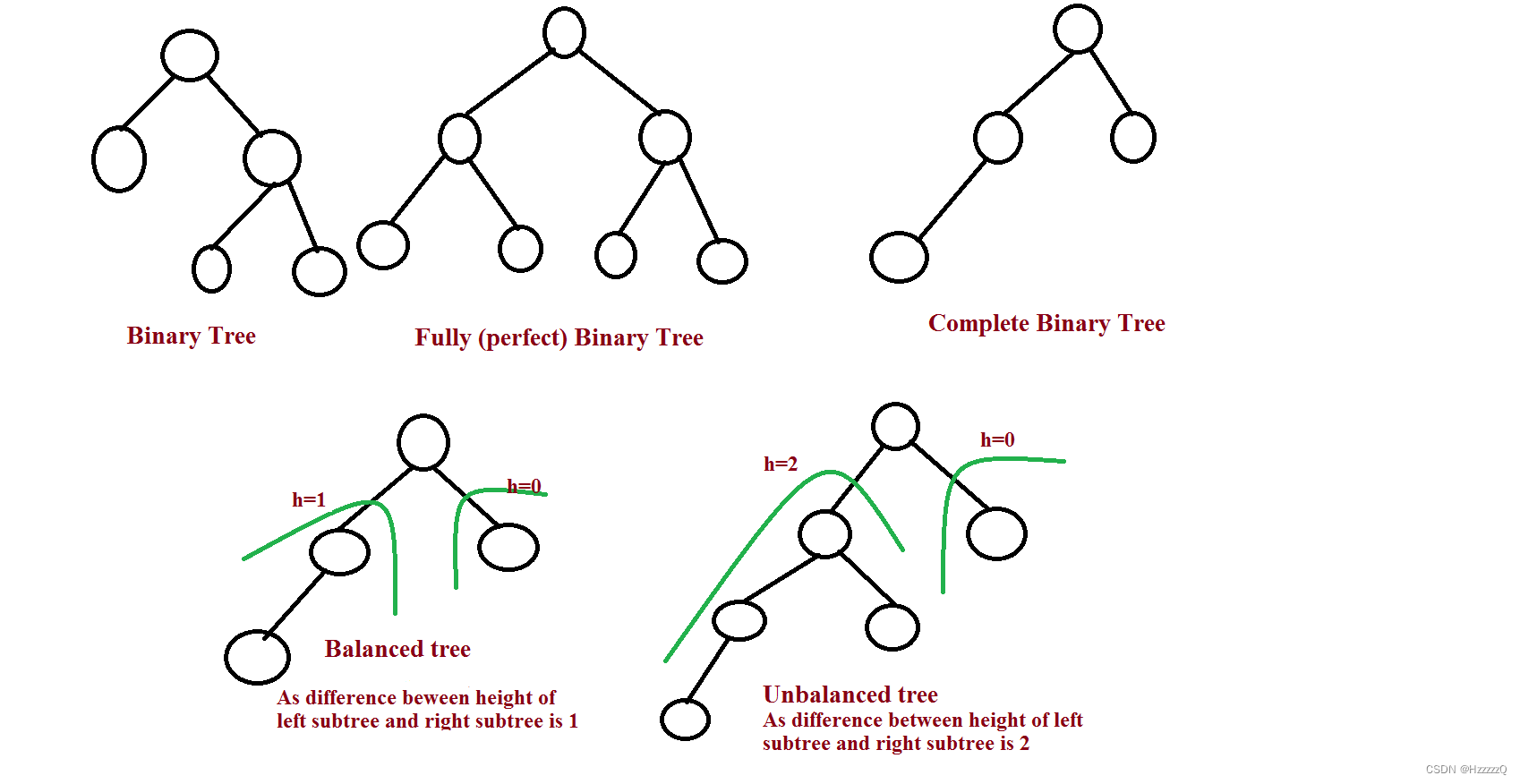
一、初识二叉树
Binary Tree is defined as a tree data structure where each node has at most 2 children. Since each element in a binary tree can have only 2 children, we typically name them the left and right child.
二叉树是一种特殊的数据结构,以树为基础,每个节点有且只有两个子节点。
二叉树(Binary Tree)要么为空,要么由根节点(root)、左子树(left subtree)和右子树(right subtree)组成,而左右子树分别也都是二叉树;计算机内的树“倒置”——根在上,叶子在下。
树和二叉树唯一的区别是每个节点不一定只有两棵子树 。不管是树还是二叉树,每个非根节点都有一个父节点(father)。
二、二叉树的编号
二叉树通常按照先行后列的顺序编号。因为二叉树具有每个节点有且只有两个子节点的性质,所以对于完全二叉树,有很漂亮的编号性质:
对于一个节点k,其左子节点和右子节点的编号分别是2k和2k+1
使用二叉树编号解决问题一道非常典型的例题是 小球下落(Dropping Balls,Uva 679),问题大概就是对于一个某深度的完全二叉树先行后列编号, 每个节点有个开关控制关闭时小球落到左子节点、打开时小球落到右子节点,初始都是关闭。小球每经过一个节点(之后),开关状态变化一次,问第I个小球最后落到哪一个编号的叶子中。二叉树深度D和小球个数I都是人为输入的。
第一种方法是模拟整个小球下落的过程,得出最后一个小球的状态。所以需要定义一个巨大的数组来存储所有节点的开关状态,同时有一个小结论(很容易推出来)就是完全二叉树节点总数等于(2^深度)-1个,所以可以如下定义:
const int maxd=20;
int s[1<<maxed]; //最大节点个数为(2^maxd)-1,存储每一个节点开关状态使用位运算的左移运算符,达到2^n的效果。下面是整个处理过程:
//已输入D(深度)和I(小球个数)
memset(s,0,sizeof(s)); //开关初始化
int k,n=(1<<D)-1; //n是最大节点编号,k是当前节点编号
for(int i=0;i<I;i++){ //开始逐个小球掉落
k=1;
while(1){
s[k]=!s[k]; //开关状态改变,因为初始定义0为打开,所以该行放在小球选择路径之前
k=s[k]?k*2:k*2+1; //开关为1向左,为1则向右
if(k>n)
break; //更为普遍的判断遍历结束的方法
}
}
//那么“出界”前的叶子编号就是 k/2 这种方法的弊端很明显,就是运算量太大,如果深度或小球多一点,计算成本将指数倍增长。
第二种方法是直接模拟最后一个小球的路线。这种方法的原理是,因为每个小球落到一个节点上,只有左子树和右子树两个选择,而选择哪一个取决于小球是第几个到该节点的——开关位置随着每下来一个小球变化一次,所以可以使用奇偶性判断路径。
当到达某小球I到达编号为k的节点时,I如果是奇数,就是向左走的第(I+1)/2个小球;偶数时,就是向右走的第I/2个小球。模拟过程如下:
int k=1;
for(int i=0;i<D-1;i++){
//因为最后一个节点不需要分流,所以只需要算D-1层
if(I%2){
k=k*2;
I=(I+1)/2;
}
else{
k=k*2+1;
I=I/=2;
}
}
//此时k即为最后落到的叶子节点编号所以在盲目模拟之前,可以简单找一下数学规律,有时可以大幅减小复杂度。
三、二叉树的层次遍历
“层次遍历”指的就是从上到下、从左到右的元素遍历,不是按照枝叶关系发展而是按照简单的横竖关系遍历整个树(并输出)。该知识点有典型例题 树的层次遍历(Trees on the level,Duke 1993,Uva 122),该题输入为“(节点数值,节点路径)”形式,其中节点路径值由大写字母L/R的组合构成。
由于将二叉树存储在数组中,即使使用高精度也会导致数组开不下,所以使用动态内存的链表,二叉树节点结构体可以如下定义:
struct Node{
bool have_valued; //是否被赋值过
int v; //节点值
Node *left,*right; //左右子节点的指针
Node():have_valued(false),left(NULL),right(NULL){} //构造函数
};
Node* root; //二叉树的根节点输入时调用输入函数,使用循环不断读入节点,此处字符串处理非常灵活:
char s[maxn]; //用于保存读入节点
bool read_input(){
failed=false; //用于判断是否给同一个节点重复赋值
root=newnode(); //创建根节点(该函数具体实现在下文)
while(1){
if(scanf("%s",s)!=1)
return false; //整个输入结束
if(!strcmp(s,"()"))
break; //结束标志,结束读取退出循环
int v;
sscanf(&s[1],"%d",&v); //读入节点数值
addnode(v,strchr(s,',')+1); //查找逗号位置,使用逗号后面的内容插入新节点
//addnode函数具体实现在下文
}
return true;
}使用以上字符串函数的基础是C语言字符串的灵活性——任意“指向字符的指针”可以看成字符串,该字符串一直在内存中遇到尾零结束。而sscanf函数中第一个参数“&s[1]”看似只是取了数组第二个元素的指针,其实表示从数组第二个元素开始到数组末尾(字符串方式赋值会自带尾零)的一个子字符串,也就是说sscanf函数的字符串来源就是这个子字符串。根据输入第一个符号是括号,用这个方法跳过了括号直接读取到了节点数据,给了本节点的v。
其次是strchr函数,返回值为指针。strchr(s,',')返回的是s字符串中第一个字符逗号的指针,而strchr(s,','+1)返回的则是逗号后面的字符的指针。用这种方法就可以很好的处理输入格式。
这里就来到函数 newnode(),该函数作用就是为本节点指针申请动态内存(如果没有这个函数,定义的仅仅是一堆结构体指针而已,没有分配具体的空间)。函数很简单,具体实现如下:
*Node newnode(){
return new(nothrow) Node(); //new运算符+构造函数
}这里使用构造函数的意义是分配了内存的第一时间给数据成员赋初值。接下来是addnode函数,该函数将根据给的路径(可以称作“移动序列”)寻找,如果找不到则按路径创建新节点:
void addnode(int v,char*s){ //s代表路径
int n=strlen(s);
Node* u=root; //定义移动变量,从根节点开始往下走
for(int i=0;i<n;i++){
if(s[i]=='L'){
if(u->left==NULL)
u->left=newnode(); //节点不存在?新建!
u=u->left; //移动
}
else if(s[i]=='R'){
if(u->right==NULL)
u->right=newnode();
u=u->right;
}
if(u->have_value)
failed=true; //已经赋过值,说明输入错误
u->v=v;
u->have_value=true; //标记已赋值
}以上是输入和二叉树的建立,接下来是按层次顺序遍历整棵树。此处有一个好方法——使用队列。初始时只有一个节点,然后每次取出(front+pop)队首节点,把队首节点的两个左右子节点放进队列。(自己想象一下,可以顺序遍历整个数组):
bool bfs(vector<int>& ans){ //参数为诶输出序列
queue<Node*> q;
ans.clear();
q.push(root); //初始化时仅有一个根节点
while(!q.empty()){
Node* u=q.front();
q.pop(); //取出队首元素
if(!u->have_valude)
return false; //该元素竟未被赋值,表明输入有误
ans.push_back(u->v); //增加到输出序列尾部
if(u->left!=NULL)
q.push(u->left); //放左节点
if(u->right!=NULL)
q.push(u->right);//放右节点
}
return true;
}至此遍历完成。可以把使用队列实现层次遍历的方法称为宽度优先遍历(Breadth-First Search,BFS),在后续显示图和隐式图算法中有重要应用。
虽然以上程序有一个小问题——申请的动态内存没有释放,造成内存泄露(即有些内存被浪费)。作为竞赛可以不处理,也可以使用一个内存池(静态数组+空闲列表),具体在《算法竞赛入门经典》P154~155,有兴趣自行查阅。
四、二叉树的递归遍历
二叉树的递归遍历分为三种——先序遍历、中序遍历和后序遍历:
先序遍历:PreOrder(T)=T+PreOrder(T的左子树)+PreOrder(T的右子树)
中序遍历:InOrder(T)=InOrder(T的左子树)+T+InOrder(T的右子树)
后序遍历:PostOrder(T)=PostOrder(T的左子树)+PostOrder(T的右子树)+T
这三种遍历都是深度优先遍历(Depth-First Search,DFS),优先往深处访问(不同于BFS使用队列性质优先拉长宽度)。典型例题有 树(Tree,Uva 548),讲的大概是给一棵节点带权重的二叉树先后进行中序和后序遍历,找一个叶子使其到根部路径的权和最小(多解则取叶子本身小的)。两行输入,第一行为中序遍历,第二行为后序遍历。
这里需要抓住的最重要的条件是:
二叉树后序遍历结果的第一个字符就是根(root)
而题中有了后序遍历和中序遍历的两个结果,则可以在中序遍历中相应找到root,从而找出左右子树的节点列表,就可以知道左右子树的中序和后序遍历了。
所以解题步骤分为两步:第一步是构造二叉树;第二步是再执行一次递归遍历,找到最优解。
以下是本题代码,首先做一下准备工作,定义一些存放数据的容器:
//因为各个节点权重不同且都是正整数,直接用权值作为节点编号
const int maxv=10000+10;
int in_order[maxv],post_order[maxv],lch[maxv],rch[maxv];其中in_order存储的是读入的中序遍历的序列,post_order存储的是读入的后序遍历的序列;lch存储的是某一个节点的左节点,rch存储的是某一个节点的右节点。以下是输入的数据处理函数,调用一次处理一个字符串:
//返回值为读取是否有问题
bool read_list(int* a)
{
string line;
if(!getline(cin,line))
return false;
stringstream ss(line); //字符串流
n=0; //n位全局变量,此处用作计数单位
int x;
while(ss>>x)
a[n++]=x;
return n>0;
}可以说使用字符串流是算法竞赛中非常重要且方便的方法。输入后数据全部存储在了in_order和post_order数组中,所以下一步就是将递归遍历的两个数组数据存放到树状结构数组lch和rch中:
//把in_order[L1~R1]和post_order[L2~R2]建立成小二叉树,返回小树根
int build(int L1,int R1,int L2,int R2)
{
if(L1>R1)
return 0; //空树
int root =post_order[R2];
int p=L1;
while(in_order[p]!=root)
p++; //计算左子树节点的个数
int cnt=p-L1; //左子树节点个数
//开始递归
lch[root]=build(L1,p-1,L2,L2+cnt-1); //本节点的左子树递归
rch[root]=build(p+1,P1,L2+cnt,R2-1); //本节点的右子树递归
return root;
}以上递归可能有点难以理解——相当于是每进入递归都是在处理一个小的二叉树(本来也是原节点的一棵子树),且传入递归的参数都已经经过处理使其可以按照一棵完整的树继续往下处理递归(这里的参数指L1,L2,R1,R2,可以这样递归是因为在递归遍历中一棵树的完整部分都在相邻连接的位置)。递归开始之前要判断是否可以继续,也就是函数第一行的if语句,当上一次已经到叶子节点,L1和p的数值一致,所以传到递归中的L1<R1,构成了退出条件。
接着还是使用遍历找出最优的路径。这里首先需要定义两个全局变量来存储目前为止的最优解和对应的权和:
int best,best_sum;仍然使用递归函数找出最优解:
void dfs(int u,int sum){
sum+=u;
if(!lch[u]&&!rch[u]){
//叶子
if(sum<best_sum||(sum==best_sum&&u<best)){
best=u;
best_sum=sum;
}
}
if(lch[u])
dfs(lch[u],sum); //左子树不是零,则继续进入左子树递归
if(rch[u])
dfs(rch[u],sum);
}注意在递归中sum仅仅作为参数传递,两次第一次递归不会改变sum值从而影响第二次递归。下面是主函数,涉及各种函数的协调调用:
int main(){
while(read_list(in_order))
read_list(post_order);
build(0,n-1,0,n-1); //建树,一开始默传参认全数组、
best_sum=1000000000; //定为很大的数,下面找小数替换
dfs(post_order[n-1],0);//post_order[n-1]为根节点(根据后序遍历的性质)
cout<<best<<"\n";
}
return 0;
}经典例题 下落的树叶(The Falling Leaves,Uva 699),本题难点在于题目意思较难理解,说一个二叉树每个节点都有一个水平位置标识,该节点的左子节点水平位置为该节点-1,右子节点为+1。用先序递归的方法输入所有节点数据(-1表示空树),从左到右输出每个水平位置的所有节点值之和。直接定义递归函数处理输入即可,可以在输入的同时统计每个水平位置的节点值。核心代码如下:
//输入并统计一棵子树,树根水平位置为p
void build(int p)
{ //注意这里的p是水平位置而不是权值
int v;
cin>>v;
if(v==-1)
return ; //空树
sum[p]+=v; //统计水平位置权值
build(p-1); //进入左子树递归
build(p+1); //进入右子树递归
}
//只执行一次的递归开始函数
bool init()
{
int v;
cin>>v;
if(v==-1)
return false;
memset(sum,0.sizeof(sum)); //初始将sum清零
int pos=maxn/2; //树根的水平位置
sum[pos]=v;
build(pos-1);
build(pos+1);
}main函数中将init函数作为while循环的条件,输出时只需在sum数组中从左到右找出第一个不是零的开始输出即可(因为sum存储不是满存储,整棵树的root存放在最中间位置,大致呈堆成的形状分布存储)。
















 1205
1205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











