









提出者:Visual Geometry Group (VGG), Oxford University
本文链接:https://arxiv.org/abs/1409.1556
简单概括:研究目标是卷积网络深度对图像识别精度的影响,提出了使用小型卷积滤波器的改进模型
关键词: 深层卷积神经网络; VGG16; VGG19
介绍
本文基于现有的卷积神经网络模型基础上,对其模型结构进行优化。本文所做的优化是增加模型深度(Depth),即增加更多的卷积层。而使用3x3的小卷积和可以使得高深度模型中数据的规模不会快速减小(图像上表现为不会过于降低分辨率)。
改进后的模型在图像识别任务上有前所未有的精度,在2014年ImageNet挑战赛中获得了头把交椅。
模型配置
参数架构
输入:224*224*3 RGB 图像
预处理:0均值化
恒定卷积大小:3*3 (步长 s t r i d e = 1 stride=1 stride=1)
恒定池化大小:2*2 (步长 s t r i d e = 2 stride=2 stride=2)
激活函数: R e L U ReLU ReLU 函数
模型结构
VGG 16对应下图D: 13 c o v . + 3 f c 13 cov.+3fc 13cov.+3fcVGG 19对应下图E: 16 c o v . + 3 f c 16cov.+3fc 16cov.+3fc

可视化模型:https://dgschwend.github.io/netscope/#/preset/vgg-16
多层小卷积核的优势
该部分在原文的discussion部分进行讨论,首先要了解多个小卷积核的有效感受野(effective receptive field)堆栈叠加:
- f i e l d ( 2 ∗ c o v . ( 3 ∗ 3 ) ) = f i e l d ( 1 ∗ c o v . ( 5 ∗ 5 ) ) field(2*cov.(3*3))=field(1*cov.(5*5)) field(2∗cov.(3∗3))=field(1∗cov.(5∗5))
- f i e l d ( 3 ∗ c o v . ( 3 ∗ 3 ) ) = f i e l d ( 1 ∗ c o v . ( 7 ∗ 7 ) ) field(3*cov.(3*3))=field(1*cov.(7*7)) field(3∗cov.(3∗3))=field(1∗cov.(7∗7))
以两个3*3卷积核为例,第二次卷积运算的处理对象极为第一次卷积运算的结果矩阵,也就是说第二次3*3卷积核元素乘上的每一个对应元素,都是原始数据矩阵经过第一次3*3卷积核运算的结果。
如图所示,经过两层卷积后的单个元素,其实等效于 5 × 5 5\times5 5×5 矩阵:
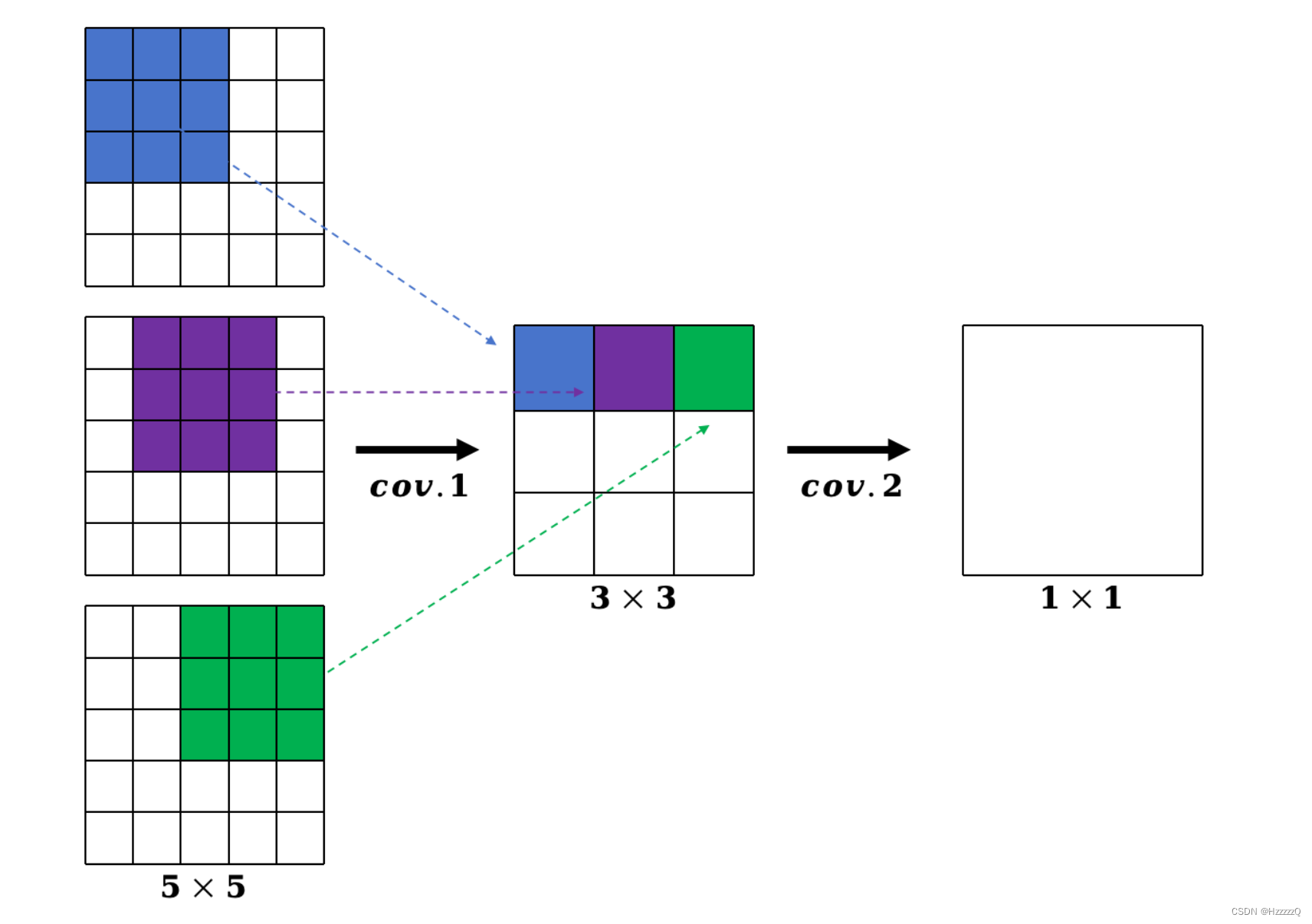
而实验结果证明使用两个 3 ∗ 3 3*3 3∗3 卷积核代替一个 5 ∗ 5 5*5 5∗5 性能更好,原因如下:
- 合并了两个非线性矫正层(非线性激活区域)而不是一个,使得决策函数更具有区别性(网络能够更好地区分不同类别的图像)。
- 减少网络参数:堆栈由 2 ∗ ( 3 2 C 2 ) = 18 C 2 2* (3^2C^2) = 18C^2 2∗(32C2)=18C2 权重进行参数化,而单个 5 × 5 卷积层需要 1 ∗ ( 5 2 C 2 ) = 25 C 2 1*(5^2C^2) = 25C^2 1∗(52C2)=25C2 参数。当堆栈数量更大时这种区别更明显。
而参数数量的减少可以看作是对7×7卷积滤波器施加了正则化(一种用于防止机器学习模型过度拟合的技术)。通过强制 5 × 5 滤波器通过 3 × 3 滤波器进行分解,即中间注入非线性部分,网络不太可能过度拟合训练数据。
VGG训练
参考:https://github.com/machrisaa/tensorflow-vgg
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











