






数组
88. 合并两个有序数组
题目:给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。
请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。
注意:最终,合并后数组不应由函数返回,而是存储在数组 nums1 中。为了应对这种情况,nums1 的初始长度为 m + n,其中前 m 个元素表示应合并的元素,后 n 个元素为 0 ,应忽略。nums2 的长度为 n 。
算法:双指针法:1. 初始化两个指针,p1指向nums1的末尾(m-1)p2指向nums2的末尾(n-1),初始化指针p指向nums1的末尾(n+m-1)。2. 当两个指针都有效时,比较两个指针指向的元素,较大的元素放入nums1的p位置,并将较大元素的指针前移一个位置,同时将p前移一个位置。3. 若nums2还有元素剩余(即p2≥0)则将p2指向的元素放入nums1的p位置,然后将p2和p前移一个位置。
def merge(nums1, m, nums2, n):
"""
Do not return anything, modify nums1 in-place instead.
"""
p1 = m-1
p2 = n-1
p = m+n-1
while p1>=0 and p2 >=0:
if nums1[p1] >= nums2[p2]:
nums1[p] = nums1[p1]
p1 -= 1
p -= 1
else:
nums1[p] = nums2[p2]
p2 -= 1
p -= 1
while p2 >= 0:
nums1[p] = nums2[p2]
p2 -= 1
p -= 127. 移除元素
题目:给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素。元素的顺序可能发生改变。然后返回 nums 中与 val 不同的元素的数量。
假设 nums 中不等于 val 的元素数量为 k,要通过此题,您需要执行以下操作:
• 更改 nums 数组,使 nums 的前 k 个元素包含不等于 val 的元素。nums 的其余元素和 nums 的大小并不重要。
• 返回 k。
算法:双指针法:指针p和q初始位置0,q遍历整个数组,找到不等于val的元素时将其复制到p的位置上同时将p加一,返回p。
def removeElement(nums, val):
p = 0
for q in range(len(nums)):
if nums[q] != val:
nums[p] = nums[q]
p += 1
return p26. 删除有序数组中的重复项
题目:给你一个 非严格递增排列 的数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。然后返回 nums 中唯一元素的个数。
考虑 nums 的唯一元素的数量为 k ,你需要做以下事情确保你的题解可以被通过:
• 更改数组 nums ,使 nums 的前 k 个元素包含唯一元素,并按照它们最初在 nums 中出现的顺序排列。nums 的其余元素与 nums 的大小不重要。
• 返回 k 。
算法:双指针法:指针p初始位置0,指针q初始位置1(因为第一个元素肯定是不重复的),q从1开始遍历整个数组,若未找到与nums[p]不同的元素则接着往下找,一旦找到和nums[p]不同的元素则令p加一再令nums[p]=nums[q],最后返回p+1。
def removeDuplicates(nums):
p = 0
for q in range(1, len(nums)):
if nums[q] != nums[p]:
p += 1
nums[p] = nums[q]
return p+180. 删除有序数组中的的 重复项 II
题目:给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使得出现次数超过两次的元素只出现两次 ,返回删除后数组的新长度。
不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
算法:双指针法:指针p初始位置2,指针q初始位置2(因为前两个元素肯定可以保留),q从2开始遍历整个数组。若nums[q]==nums[p-2](注意由于nums递增因此这种情况等价于nums[p-2],nums[p-1],nums[q]三者相等此时nums[p-1],nums[p-2],nums[p]是不满足条件的组合)则不作处理,q接着向后移动。若nums[q]!=nums[p-2]则令nums[p]=nums[q]然后p += 1。最后返回p。
def removeDuplicates(nums):
p = 2
for q in range(2, len(nums)):
if nums[q] != nums[p-2]:
nums[p] = nums[q]
p += 1
return p189. 轮转数组
题目:给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。
算法:1. 由于转len(nums)次等于没转,因此先取k=k%len(nums)。2. 定义翻转函数(输入翻转片段的头和尾的索引)。3. 将整个数组翻转,将前k个元素翻转,将后len(nums)-k个元素翻转。
def rotate(nums, k):
"""
Do not return anything, modify nums in-place instead.
"""
k = k % len(nums)
def f(start, end):
while start <= end:
nums[start], nums[end] = nums[end], nums[start]
start += 1
end -= 1
f(0, len(nums)-1)
f(0, k-1)
f(k, len(nums)-1)121. 买卖股票的最佳时机
题目:给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票(即一次买入机会一次卖出机会)。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
算法:贪心算法:1. 设最低价和利润的初始值为prices[0]和0。2. 遍历prices,若当前元素小于最低价则令当前元素为最低价,令利润为当前元素减最低价和利润的最大值。
def maxProfit(self, prices: List[int]) -> int:
min_price = prices[0]
profit = 0
for i in prices:
if i < min_price:
min_price = i
profit = max(profit, i - min_price)
return profit122. 买卖股票的最佳时机 II
题目:给你一个整数数组 prices ,其中 prices[i] 表示某支股票第 i 天的价格。
在每一天,你可以决定是否购买和/或出售股票。你在任何时候 最多 只能持有 一股 股票。你也可以先购买,然后在 同一天 出售。
返回 你能获得的 最大 利润 。
算法:贪心算法:只要今天的价格比昨天低则昨天买入今天卖出。
def maxProfit(prices):
profit = 0
for i in range(1, len(prices)):
if prices[i] > prices[i-1]:
profit += prices[i]-prices[i-1]
return profit55. 跳跃游戏 I
题目:给你一个非负整数数组nums,你最初位于数组的第一个下标。数组中的每个元素代表你在该位置可以跳跃的最大长度。判断你是否能够到达最后一个下标,如果可以,返回true;否则,返回false。例如输入nums=[2,3,1,1,4],则先跳1步,从第1个位置到达第2个位置,再跳3步从第2个位置到达第5个位置。
算法:用i从0到len(nums)-1循环,创建变量max_pos记录当前最远可到达位置,若循环到某个i时有i>max_pos则返回False,否则True。
def canJump(nums):
max_pos = 0
for i in range(0, len(nums)):
if i > max_pos:
return False
max_pos = max(max_pos, i+nums[i])
return True注意for循环中第一步是先判断i>max_pos是否成立,而非先执行赋值语句max_pos = max(max_pos, i+nums[i])。考虑一个特例nums=[0,2],假设显然本函数应该返回False,因为其只能停留在第一个位置,按上面的代码i=1时,max_pos=0,i>max_pos成立因此返回False。假如先执行max_pos的赋值语句则i=1时max_pos=3,返回True。
45. 跳跃游戏 II
题目:给定一个长度为n的0索引整数数组(指数组索引从0开始且数组元素都是整数)nums。每个元素nums[i]表示从索引i向前跳转的最大长度。换句话说,如果你在nums[i]处,你可以跳转到任意nums[i+j]处,其中
• 0 ≤ j ≤ nums[i]
• i+j < n
给定一个必然能到达nums[n-1]的数组,返回到达nums[n-1]的最小跳跃次数。例如输入nums=[2,3,1,1,4],应当返回2(第一步从0位置跳到1位置,第二步从1位置跳到4位置)。
算法:从0位置出发,第一步能走0~2个格子即可到达的位置是前3个格子(第一行红色部分),第二步的起点是这一红色范围内的任何一个位置pos1。从pos1出发能够达到的位置同样是一个范围(如下图第二行红色所示):若pos1=0,则第二步能走0~2个格子即可到达的位置是前3个格子,若pos1=1,则第二步能走0~3个格子即可到达的位置是第2~5个格子,若pos1=2则第二步能走0~1个格子即可到达的位置是第3~4个格子,因此第二步可到达的位置是前5个格子(第二行红色部分),此时可到达位置已经覆盖了整个数组因此最小步数是2。因此求最小跳跃次数即看最少走几步可以覆盖整个数组。
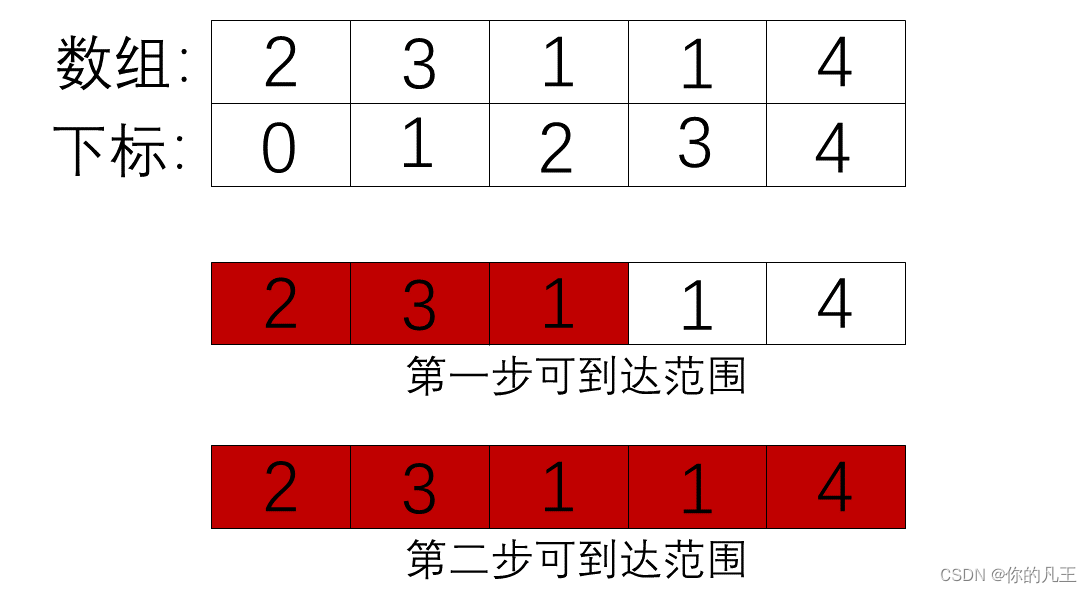
为了实现以上算法,我们创建steps变量记录走了多少步,创建end变量记录每一步所到达的最远位置,创建max_pos变量记录当前可到达的最远位置:
1. 令三者的初始值为0
2. 令i从0到len(nums)-2循环:
• 令max_pos=max(max_pos, i+nums[i]),即到目前为止能够到达的最远位置
• 若i==end则令end=max_pos以及steps=steps+1
3. 返回steps
步骤2中end用于记录每一步所到达的最远位置,i==end表示走完了这一步,因此steps增加1。i代表出发位置,因此其只取到数组的倒数第二个位置(索引是len(nums)-2),因为到了最后一个位置就不用再出发了。
def jump(nums):
steps = 0
end = 0
max_pos = 0
for i in range(0, len(nums)-1):
max_pos = max(max_pos, i+nums[i])
if i == end:
end = max_pos
steps += 1
return steps274. H指数
题目:给你一个整数数组citations,其中citations[i]表示研究者的第i篇论文被引用的次数。计算并返回该研究者的h指数。
根据维基百科上的定义,一名科研人员的h指数是指他至少发表了h篇论文,并且至少有h篇论文被引用次数大于等于h。如果h有多种可能的值,则h指数是其中最大的那个。
算法:首先将citations按降序排序,然后从第一个元素开始判断起每个元素是否大于元素的索引+1,例如前7个元素都大于7则h指数大于等于7。具体算法为:
1. 令h指数的初值h=0
2. 将citations从大到小排列
3. 令i从0到len(citations)-1循环,若citations[i]≥i+1则h=i+1,反之直接中断循环,因为当前i不满足则后续必然不满足
3. 返回h
def hIndex(citations):
h = 0
citations.sort(reverse=True)
for i in range(0, len(citations)):
if citations[i] >= i+1:
h = i+1
else:
break
return h380. O(1)时间插入、删除、获取随机元素
题目:实现RandomizedSet类:
• RandomizedSet()初始化类的对象
• insert方法输入整数值val时若val不存在则向集合中插入该项并返回true否则返回false
• remove方法输入整数值val时若val存在则从集合中移除该项并返回true否则返回false
• getRandom方法随机返回现有集合的一项且每个元素有相同的概率被选中
你必须实现类的所有函数,并满足每个函数的平均时间复杂度为O(1)。
算法:给类定义两个属性nums(列表)和val_to_index(字典),前者用于存储数组元素,后者用于存储数组元素和元素在数组中的索引之间的映射。insert方法的定义较为简单,假如val在nums中则返回False否则在nums结尾添加元素val并在val_to_index中添加val: len(self.nums)-1键值对。remove方法首先判断val是否不在nums中,不在则返回False否则通过val_to_index[val]取出需要移除的nums中的元素的索引,取出最后一个元素的值last_val,将nums需要移除的元素替换为last_val,然后移除nums最后一个元素,再将val_to_index[last_val]的值替换成val_to_index[val]并删除键值对val_to_index[val]。
class RandomizedSet(object):
def __init__(self):
self.nums = []
self.val_to_index = {}
def insert(self, val):
if val in self.nums():
return False
else:
self.nums.append(val)
self.val_to_index[val] = len(self.nums) - 1
return True
def remove(self, val):
if val not in self.nums:
return False
else:
index_to_remove = self.val_to_index[val]
last_val = self.nums[-1]
self.nums[index_to_remove] = last_val
self.nums.pop()
self.val_to_index[last_val] = index_to_remove
self.val_to_index.pop(val)
return True
def getRandom(self):
return random.choice(self.nums)
238. 除自身以外数组的乘积
题目:给你一个整数数组nums,返回数组answer,其中answer[i]等于nums中除nums[i]之外其余各元素的乘积 。
题目数据保证数组nums之中任意元素的全部前缀元素和后缀的乘积都在32位整数范围内。
请不要使用除法,且在O(n)时间复杂度内完成此题。
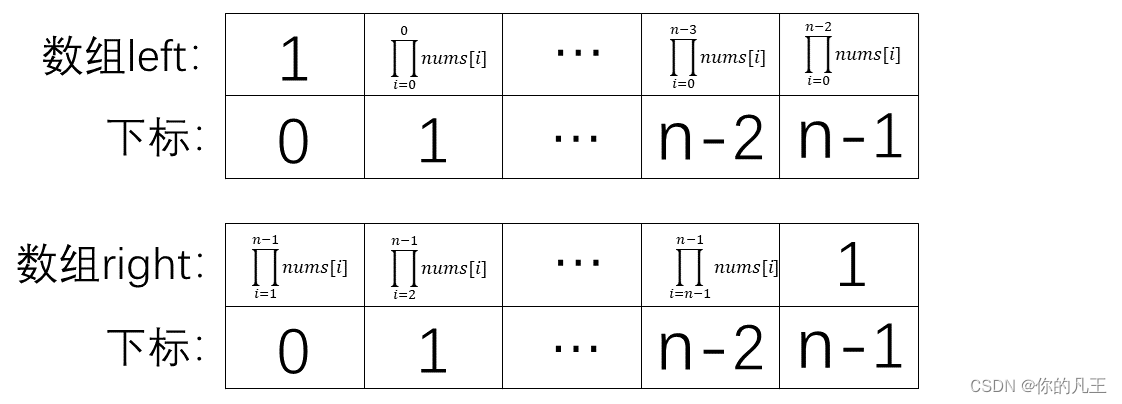
算法:构造如下两个数组left和right,前者第一个元素是1,剩余元素是nums从左往右1个元素、两个元素、...、n-1个元素的累乘,后者前n-1个元素是nums从右往左n-1个元素、n-2个元素、...、1个元素的累乘,最后一个元素是1,两个数组对应位置相乘即可。
def productExceptSelf(nums):
left = [1] * len(nums)
right = [1] * len(nums)
for i in range(1, len(nums)):
left[i] = left[i-1] * nums[i-1]
for i in range(len(nums)-2, -1, -1):
right[i] = right[i+1] * nums[i+1]
result = [1] * len(nums)
for i in range(0, len(nums)):
result[i] = left[i] * right[i]
return result134. 加油站
题目:在一条环路上有n个加油站,其中第i个加油站有汽油gas[i]升。你有一辆油箱容量无限的的汽车,从第i个加油站开往第i+1个加油站需要消耗汽油cost[i]升。你从其中的一个加油站出发,开始时油箱为空。
给定两个整数数组gas和cost,如果你可以按顺序绕环路行驶一周,则返回出发时加油站的编号,否则返回-1 。测试用例如果存在解,则保证它是唯一的。
示例:输入gas = [1,2,3,4,5],cost = [3,4,5,1,2],输出3。解释:从 3 号加油站(索引为 3 处)出发,可获得 4 升汽油。此时油箱有 = 0 + 4 = 4 升汽油,开往 4 号加油站,此时油箱有 4 - 1 + 5 = 8 升汽油,开往 0 号加油站,此时油箱有 8 - 2 + 1 = 7 升汽油,开往 1 号加油站,此时油箱有 7 - 3 + 2 = 6 升汽油,开往 2 号加油站,此时油箱有 6 - 4 + 3 = 5 升汽油,开往 3 号加油站,你需要消耗 5 升汽油,正好足够你返回到 3 号加油站。
算法:判断是否存在环绕一周的可能是容易的,只需用环绕一周的总加油量减总耗油量是否小于0来判断。能环绕一周的情况下找到可行的起点,则需要使用for循环遍历加油站,从0站开始遍历(设起点start=0),用cur记录当前剩余油量,若到达某站i时cur<0则说明从start开始到不了第i+1站,此时在循环内将起点变更为start=i+1并取cur=0,继续向下循环,直到找到能够到达最后一个剩余所有站并从第n-1站到达第0站的起点。
def canCompleteCircuit(gas, cost):
n = len(gas)
start = 0 # 初始起点
total_sum = 0 # 从起点到当前加油站的总剩余油量
cur_sum = 0 # 当前油量
total_sum = sum(gas) - sum(cost)
if total_sum < 0:
return -1
for i in range(n):
cur_sum += gas[i] - cost[i]
if cur_sum < 0: # 如果当前油量小于0,说明无法到达下一个加油站,更新起点
start = i + 1
cur_sum = 0
return start双指针
125. 验证回文串
题目:如果在将所有大写字符转换为小写字符、并移除所有非字母数字字符之后,短语正着读和反着读都一样。则可以认为该短语是一个 回文串 。字母和数字都属于字母数字字符。给你一个字符串s,如果它是 回文串 ,返回true;否则,返回false。
算法:先将字符串转换成小写,然后使用双指针法,定义两个指针left和right分别从从左往右、从右往左相向移动,遇到不是字母也不是数字的字符就跳过,若left和right位置上的字符不相等则不是回文串,在left≥right时停止算法。
def isPalindrome(s):
s = s.lower()
left, right = 0, len(s)-1
while left < right:
if not s[left].isalnum():
left += 1
continue
if not s[right].isalnum():
right -= 1
continue
if s[left] != s[right]:
return False
left += 1
right -= 1
return True注意上面的算法中判断当前字符是否为数字或字母后用到了continue,即跳过本循环剩下的所有语句直接进入下次循环,这里的continue必须要有,因为字符串s中可能包含连着的两个非字母数字字符(假设是!&),假如当前left位置上的字符是!,则left增加1,s[left]变成&,程序接着向下运行,用到s[left]和s[right]比较,就会产生错误,因为我们仅考虑s的数字和字母部分。
也可以不按上面的方式跳过非数字和字母的字符,而在循环开始前就直接去掉非字母和数字的字符得到一个新字符串赋值给s(用isalnum方法删除字符,再将结果用join方法连接成仅含数字和字母的字符串)。
392. 判断子序列
题目:给定字符串s和t,判断s是否为t的子序列。
字符串的一个子序列是原始字符串删除一些字符而不改变剩余字符相对位置形成的新字符串。(例如'ace'是'abcde'的一个子序列,而'aec'不是)。
算法:我们定义两个指针i和j,分别用来遍历s和t,一开始两个指针都在0处,然后i不动,增加t直到找到满足s[i]==t[j]的j或者j达到len(t)-1,当s[i]==t[j]时令i=i+1,表示开始判断下一个s中的字符是否在t中,但是j不能回头(即不能取判断上一个i时取过的值),因此我们的程序中t是仅增加的而不是对每个i都遍历range(0,len(t))的。由于仅在s[i]==t[j]时i才能增加,因此若最终i==len(s)则表示s是t的子序列,否则不是。
def isSubsequence(s, t):
i, j = 0, 0
while i < len(s) and j < len(t):
if s[i] == t[j]:
i += 1
j += 1
result = i == len(s)
return result167. 两数之和II-输入有序数组
题目:给你一个下标从1开始的整数数组numbers,该数组已按非递减顺序排列,请你从数组中找出满足相加之和等于目标数 target的两个数。如果设这两个数分别是numbers[index1]和numbers[index2],则1≤index1<index2≤numbers.length。
以长度为2的整数数组[index1,index2]的形式返回这两个整数的下标index1和index2。
你可以假设每个输入只对应唯一的答案,而且你不可以重复使用相同的元素。
你所设计的解决方案必须只使用常量级的额外空间。
算法:我们定义两个指针left和right,分别用来从左往右和从右往左试出index1和index2,二者初值为0和len(numbers)-1,若numbers[left]+numbers[right]<target,则left=left+1,若numbers[left]+numbers[right]>target,则right=right-1,若numbers[left]+numbers[right]=target,则得到答案,若找不到这样的索引组合,则返回-1。
def twoSum(numbers, target):
left, right = 0, len(numbers)-1
while left < right:
total = numbers[left] + numbers[right]
if total < target:
left += 1
elif total > target:
right -=1
else:
return [left+1, right+1]
return [-1, -1]11. 盛水最多的容器
题目:给定一个长度为 n 的整数数组 height。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]),找出其中的两条垂线,使得它们与 x 轴共同构成的容器可以容纳最多的水。返回容器可以储存的最大水量。
示例:输入[1,8,6,2,5,4,6,3,7],输出49。
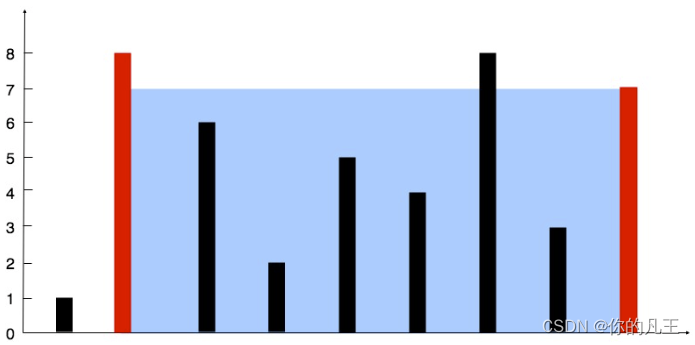
算法:定义两个指针left和right,二者初始位置为0和len(height)-1,将left向右或right向左移动来计算二者形成的容器的容积,当left处高度低于right处高度时,将left向右移动一位(因为容积受制于较低的一边,移动高的容积也不会增加),反之将right向左移动一位,二者高度相等则随便移动哪一个。
def maxArea(height):
left, right = 0, len(height)-1
max_water = 0
while left < right:
cur_height = min(height[left], height[right])
cur_water = cur_height * (right-left)
max_water = max(max_water, cur_water)
if height[left] < height[right]:
left += 1
else:
right -= 1
return max_water15. 三数之和
题目:给你一个整数数组 nums,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i!=j、i!=k 且 j!=k ,同时还满足 nums[i] + nums[j] + nums[k] == 0。请你返回所有和为 0 且不重复的三元组。注意答案中不可以包含重复的三元组(指答案中不能包含两个元素相同(不考虑出现顺序的情况下)的长度3的数组,但是答案中的每个数组中的元素可以是相容的,如[-1,-1,2]和[0,0,0]都是合规的数组)。
算法:首先对nums从小到大排序。要求解的答案是三元组,我们也将三元组中的数按从小到大的顺序排列,假设第一个是i,我们用遍历法考虑所有i的取值,对每个固定的i,定义两个指针left和right,二者初始位置为i+1和len(nums)-1,将left向右或right向左移动来寻找满足条件的left和right。找到一组解后需要跳过重复的元素以避免重复结果。
def threeSum(nums: List[int]) -> List[List[int]]:
nums.sort()
n = len(nums)
results = []
for i in range(n - 2):
if i > 0 and nums[i] == nums[i - 1]: # 跳过重复元素(注意是从i=1才开始跳的)
continue
left, right = i + 1, n - 1
while left < right:
total = nums[i] + nums[left] + nums[right]
if total < 0:
left += 1
elif total > 0:
right -= 1
else:
result.append([nums[i], nums[left], nums[right]])
while left < right and nums[left] == nums[left + 1]: # 跳过重复元素
left += 1
while left < right and nums[right] == nums[right - 1]:
right -= 1
left += 1
right -= 1
return results滑动窗口
209. 长度最小的子数组
题目:给定一个含有 n 个正整数的数组和一个正整数 target,找出该数组中满足其总和大于等于 target 的长度最小的子数组,并返回其长度。如果不存在符合条件的子数组,返回0。
算法:用双指针维护一个滑动窗口,窗口的左右边界由 left 和 right 指针确定。用right遍历range(0,len(nums)),当窗口内的和小于target时,不断将右指针向右移动,以扩大窗口;当窗口内的和大于或等于target时,尝试将左指针向右移动,以缩小窗口,并在此过程中更新最小长度,最后返回最小长度即可。
def minSubArrayLen(target, nums):
left, cur_sum, min_len = 0, 0, len(nums) + 1
for right in range(0, len(nums)):
cur_sum += nums[right]
while cur_sum >= target:
min_len = min(min_len, right-left+1)
cur_sum -= nums[left]
left += 1
if min_len < len(nums) + 1:
return min_len
else:
return 03. 无重复字符的最长子串
题目:给定一个字符串s,请你找出其中不含有重复字符的最长子串的长度。如s='abcabcbb',其输出3(无重复字符的最长子串是'abc')。
算法:用双指针维护一个滑动窗口,窗口的左右边界由 left 和 right 指针确定,二者初值为0,并维护一个集合char_set记录当前窗口内的字符串包含哪些字符。假如s(right)∉char_set则将其加入char_set中,并将right右移一位,假如s(right)∈char_set则将s(left)从char_set中去掉并将left左移一位直到满足s(right)∉char_set再将right右移,如此进行下去直到right=len(s)-1。这一过程中一直记录不含重复元素的子串(通过s(right)∉char_set来判断)的长度,最终结果为最长的长度。
def lengthOfLongestSubstring(s):
if not s:
return 0
char_set = set()
max_len = 0
left, right = 0, 0
for right in range(0, len(s)):
while s[right] in char_set:
char_set.remove(s[left])
left += 1
char_set.add(s[right])
max_len = max(max_len, right - left + 1)
return max_len矩阵
36. 有效的数独
题目:请你判断一个 9×9 的数独是否有效。只需要根据以下规则,验证已经填入的数字是否有效即可:
1. 数字1-9在每行只能出现一次
2. 数字1-9在每列只能出现一次
3. 数字1-9在每一个以粗实线分隔的3×3宫内只能出现一次
注意:
1. 一个有效的数独(部分已被填充)不一定是可解的
2. 只需要根据以上规则,验证已经填入的数字是否有效即可
3. 空白格用'.'表示
例:
输入board =
[['5', '3', '.', '.', '7', '.', '.', '.', '.'],
['6', '.', '.', '1', '9', '5', '.', '.', '.'],
['.', '9', '8', '.', '.', '.', '.', '6', '.'],
['8', '.', '.', '.', '6', '.', '.', '.', '3'],
['4', '.', '.', '8', '.', '3', '.', '.', '1'],
['7', '.', '.', '.', '2', '.', '.', '.', '6'],
['.', '6', '.', '.', '.', '.', '2', '8', '.'],
['.', '.', '.', '4', '1', '9', '.', '.', '5'],
['.', '.', '.', '.', '8', '.', '.', '7', '9']]
输出:true
算法:我们用i, j遍历矩阵的9个行和9个列,同时维护三个大集合用于对应数独有效的三个标准,每个大集合对应九个小集合表示每一行/列/宫,记录遍历过程中出现过的数字,若遍历到之前出现过的数字则返回False否则将遍历到的数字加入对应的小集合中。
def isValidSudoku(board):
rows = [set() for x in range(0,9)]
cols = [set() for x in range(0,9)]
boxs = [set() for x in range(0,9)]
for i in range(0, 9):
for j in range(0,9):
num = board[i][j]
if num != '.':
num = int(num)
k = i // 3 * 3 + j // 3
if num in rows[i]:
return False
else:
rows[i].add(num)
if num in cols[j]:
return False
else:
cols[j].add(num)
if num in boxs[k]:
return False
else:
boxs[k].add(num)
return True以上程序中首先用列表推导式以列表形式创建三个大集合,每个大集合的每个元素是一个空集合对象,如大集合1的第i个元素用于存储目前为止第i+1行出现的所有不同元素,k用于根据i, j判断元素在哪个宫。
54. 螺旋矩阵
题目:给你一个 m 行 n 列的矩阵 matrix,请按照顺时针螺旋顺序,返回矩阵中的所有元素。
例:输入
matrix =
[[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
,输出
[1, 2, 3, 6, 9, 8, 7, 4, 5]
算法:定义矩阵matrix的副本aux,以及存储结果的列表result,算子oper指示下一步的操作,ele_num表示aux矩阵的元素是否全部被处理完,函数fun_ele_num用于输入矩阵返回其元素个数是否为0。首先将aux的第一行从左往右放入result,然后在aux中将其第一行删除,然后再将aux的最右边一列从上往下放入result,再在aux中将其最右边一列删除,然后再将aux的最后一行从右往左放入result,再在aux中将其最后一行删除,再将aux的最左边一行从下往上放入result再在aux中将其最左边一列删除,如此反复这四步直至ele_num变成0。
def spiralOrder(matrix):
aux = matrix
result = []
oper = 1
ele_num = 1
def fun_ele_num(x):
if len(x) == 0:
return 0
else:
return min(len(x), len(x[0]))
while ele_num != 0:
if oper == 1: # 遍历最上边的行
result.extend(aux[0])
aux.pop(0)
oper = 2
ele_num = fun_ele_num(aux)
if oper == 2 and ele_num != 0: # 遍历最右边的列
for i in range(0, len(aux)):
result.append(aux[i][len(aux[0]) - 1])
for i in range(0, len(aux)):
aux[i].pop(len(aux[i]) - 1)
oper = 3
ele_num = fun_ele_num(aux)
if oper == 3 and ele_num != 0: # 遍历最下边的行
result.extend(aux[len(aux) - 1][::-1])
aux.pop(len(aux) - 1)
oper = 4
ele_num = fun_ele_num(aux)
if oper == 4 and ele_num != 0: # 遍历最左边的列
for i in range(len(aux) - 1, -1, -1):
result.append(aux[i][0])
for i in range(len(aux) - 1, -1, -1):
aux[i].pop(0)
oper = 1
ele_num = fun_ele_num(aux)
return result48. 旋转图像
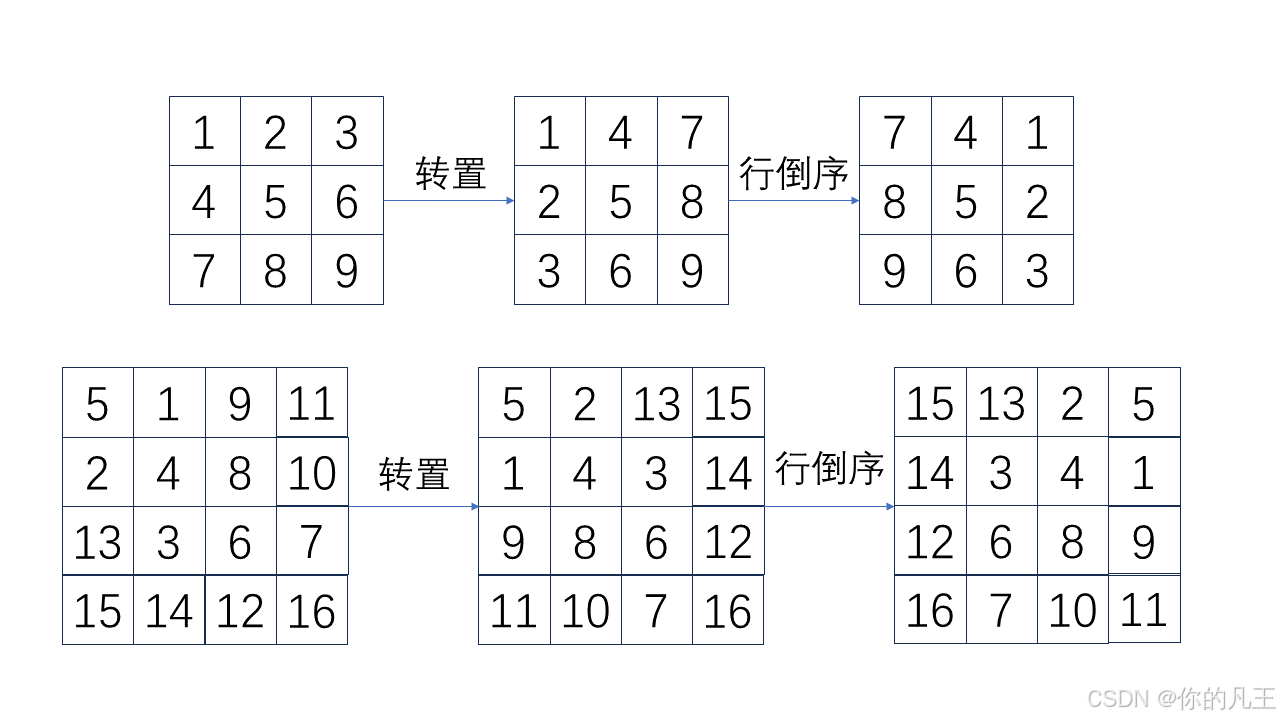
题目:给定一个n×n的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。
你必须在原地旋转图像,这意味着你需要直接修改输入的二维矩阵。不要使用另一个矩阵来旋转图像。
解法:首先将矩阵转置,然后将矩阵每行倒序。
def rotate(matrix):
for i in range(0, len(matrix)): # 转置
for j in range(i+1, len(matrix)):
matrix[i][j], matrix[j][i] = matrix[j][i], matrix[i][j]
for i in range(0, len(matrix)): # 每行倒序
matrix[i].reverse()
return matrix73. 矩阵置零
题目:给定一个m×n的矩阵,如果一个元素为0,则将其所在行和列的所有元素都设为0。请使用原地算法。
解法:用第一行和第一列来标记其他行和列中0元素的列索引和行索引。首先定义两个布尔值对象用于指示第一行和第一列中是否有0元素,然后遍历矩阵两轮,第一次遍历(从第一行第一列开始)中,将任意0元素所在的列对应的第一行元素设为0,将任意0元素所在的行对应的第一列元素设为0,这样就得到所有0元素的行列指标。
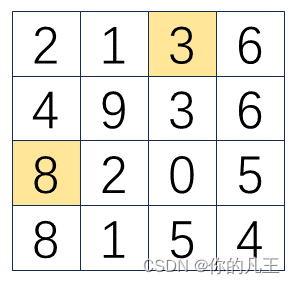
然后进行第二轮遍历(从第二行第二列开始),通过元素索引对应的第一行第一列元素的值是否为0判断其是否置为0。最后根据布尔值对象决定是否将矩阵第一行第一列令为0。
def setZeroes(matrix):
zero_row = False
zero_col = False
for i in range(0, len(matrix)):
for j in range(0, len(matrix[0])):
if matrix[i][j] == 0:
if i == 0:
zero_row = True
if j == 0:
zero_col = True
matrix[i][0] = 0
matrix[0][j] = 0
for i in range(1, len(matrix)):
for j in range(1, len(matrix[0])):
if matrix[i][0] == 0 or matrix[0][j] == 0:
matrix[i][j] = 0
if zero_col:
for i in range(0, len(matrix)):
matrix[i][0] = 0
if zero_row:
for j in range(0, len(matrix[0])):
matrix[0][j] = 0
return matrix289. 生命游戏
题目:根据百度百科, 生命游戏,简称为生命,是英国数学家约翰·何顿·康威在 1970 年发明的细胞自动机。给定一个包含m×n个格子的面板,每一个格子都可以看成是一个细胞。每个细胞都具有一个初始状态: 1 即为 活细胞(live),或 0 即为 死细胞(dead)。每个细胞与其八个相邻位置(水平,垂直,对角线)的细胞都遵循以下四条生存定律:
1. 如果活细胞周围八个位置的活细胞数少于两个,则该位置活细胞死亡;
2. 如果活细胞周围八个位置有两个或三个活细胞,则该位置活细胞仍然存活;
3. 如果活细胞周围八个位置有超过三个活细胞,则该位置活细胞死亡;
4. 如果死细胞周围正好有三个活细胞,则该位置死细胞复活;
下一个状态是通过将上述规则同时应用于当前状态下的每个细胞所形成的,其中细胞的出生和死亡是同时发生的。给你m×n网格面板 board 的当前状态,返回下一个状态。
算法:首先定义函数get_neighbors用于对给定的矩阵X和索引计算此索引周围8个位的存活细胞数(由于不一定每个细胞周围都有8个格子因此分类情况较多,需要考虑索引位置的水平/垂直/对角线位置是否存在),然后遍历矩阵board,根据每个位置的存活细胞数来决定其下一步存活或死亡。
def gameOfLife(board):
def get_neighbors(X, i, j):
y = 0
if i - 1 >= 0: # 当前位置的前一行是否存在
if j - 1 >= 0: # 当前位置的前一行、前一列是否存在(左上角位置)
y += X[i - 1][j - 1]
y += X[i - 1][j]
if j + 1 < len(X[0]): # 当前位置的前一行、后一列是否存在(右上角位置)
y += X[i - 1][j + 1]
if j - 1 >= 0: # 当前位置的同一行、前一列是否存在(左边位置)
y += X[i][j - 1]
if j + 1 < len(X[0]): # 当前位置的同一行、后一列是否存在(右边位置)
y += X[i][j + 1]
if i + 1 < len(X): # 当前位置的后一行是否存在
if j - 1 >= 0: # 当前位置的后一行、前一列是否存在(左下角位置)
y += X[i + 1][j - 1]
y += X[i + 1][j]
if j + 1 < len(X[0]): # 当前位置的后一行、后一列是否存在(右下角位置)
y += X[i + 1][j + 1]
return y
next_board = [[0] * len(board[0]) for _ in range(len(board))]
for i in range(len(board)):
for j in range(len(board[0])):
count = get_neighbors(board, i, j)
if board[i][j] == 1:
if count < 2 or count > 3:
next_board[i][j] = 0
else:
next_board[i][j] = 1
else:
if count == 3:
next_board[i][j] = 1
for i in range(len(board)):
for j in range(len(board[0])):
board[i][j] = next_board[i][j]哈希表(字典)
383. 赎金信
题目:给你两个字符串:ransomNote 和 magazine ,判断 ransomNote 能不能由 magazine 里面的字符构成。如果可以,返回 true ;否则返回 false 。magazine 中的每个字符只能在 ransomNote 中使用一次。
例:输入ransomNote='a',magzine='b',输出false。输入ransomNote='aa',magzine='ab',输出false。输入ransomNote='aa',magzine='aab',输出true。
算法:首先创建一个字典char_count记录magzine中每个字符出现的次数,然后遍历ransomNote的每个字符,若字符在char_count中且剩余次数大于0则剩余次数减1,否则返回false。全部检查完毕后返回true。
def canConstruct(ransomNote, magazine):
char_count = {}
for i in magazine:
if i in char_count.keys():
char_count[i] += 1
else:
char_count[i] = 1
for i in ransomNote:
if i in char_count.keys() and char_count[i] > 0:
char_count[i] -= 1
else:
return False
return True205. 同构字符串
题目:给定两个字符串 s 和 t ,判断它们是否是同构的。
如果 s 中的字符可以按某种映射关系替换得到 t ,那么这两个字符串是同构的。每个出现的字符都应当映射到另一个字符,同时不改变字符的顺序。不同字符不能映射到同一个字符上,相同字符只能映射到同一个字符上,字符可以映射到自己本身。
例:输入s='egg',t='add',输出true。输入s='foo',t='bar',输出false。输入s='paper',t='title',输出true。
算法:题目规定的字符串同构即定义两个字符串对应位置的映射(s[i]映射到t[i],t[i]映射到s[i]),则这个映射是两个字符串元素的集合之间的双射,且两个字符串的长度相等。首先定义两个字典s_to_t和t_to_s分别记录s到t的映射和t到s的映射,前者的键是s的元素值是t的元素,后者反之。用i遍历range(0,len(s)),令s_to_t[s[i]]=t[i]以及t_to_s[t[i]]=s[i]得到两个字典。再用i遍历range(0,len(s)),若s[i]是s_to_t的键但其值不是t[i]或t[i]是t_to_s的键但其值不是s[i]则返回false。
def isIsomorphic(s, t):
if len(s) != len(t):
return False
s_to_t = {}
t_to_s = {}
for i in range(0, len(s)): # 映射字典
s_to_t[s[i]] = t[i]
t_to_s[t[i]] = s[i]
for i in range(0,len(s)): # 检查是否为双射
if s_to_t[s[i]] != t[i]:
return False
if t_to_s[t[i]] != s[i]:
return False
return True290. 单词规律
题目:给定一种规律 pattern 和一个字符串 s,判断 s 是否遵循相同的规律。
这里的遵循指完全匹配,例如pattern 里的每个字母和字符串 s 中的每个非空单词之间存在着双向连接的对应规律。
例:输入pattern='abba',s='dog cat cat dog',输出true。输入pattern='abba',s='dog cat cat fish',输出false。输入pattern='aaaa',s='dog cat cat dog',输出false。
算法:首先,将字符串s拆分成单词列表words,并检查pattern的长度是否与words的长度相同。如果不同,直接返回false。然后创建两个字典,一个用于存储 pattern 中的字符到 words 中单词的映射(pattern_to_word),另一个用于存储 words 中单词到 pattern 中字符的映射(word_to_pattern)。用i遍历range(0,len(pattern)),检查每个字符和单词的映射关系是否一致。如果某个字符或单词已经存在于对应的字典中,但映射关系与当前不同,则返回false。如果遍历完成后没有发现不匹配的映射关系,则返回true。
def wordPattern(pattern, s):
s = s.split()
if len(s) != len(pattern):
return False
p_to_s = {}
s_to_p = {}
for i in range(0, len(s)):
p_to_s[pattern[i]] = s[i]
s_to_p[s[i]] = pattern[i]
for i in range(0, len(s)):
if p_to_s[pattern[i]] != s[i]:
return False
if s_to_p[s[i]] != pattern[i]:
return False
return True242. 有效的字母异位词
题目:给定两个字符串s和t,编写一个函数来判断t是否是s的字母异位词。
注:若s和t中每个字符出现的次数都相同,则称s和t互为字母异位词。
例:输入s='anagram'和t='nagaram'输出true。输入s='rat'和t='car'输出false。
算法:构造两个字典dict_s和dict_t分别用于记录s中每个字符出现的次数和t中每个字符出现的次数,若二者键的长度不同则返回false。用i遍历range(0,dict_s.keys()),若dict_s[i]≠dict_t[i]则返回false,若dict_t[i]≠dict_s[i]则返回false,遍历完成后返回true。
def isAnagram(s, t):
if len(s) != len(t):
return False
dict_s, dict_t = {}, {}
for i in range(0, len(s)):
if s[i] not in dict_s.keys():
dict_s[s[i]] = 1
else:
dict_s[s[i]] += 1
if t[i] not in dict_t.keys():
dict_t[t[i]] = 1
else:
dict_t[t[i]] += 1
if len(dict_s.keys()) != len(dict_t.keys()):
return False
for i in dict_s.keys():
if (i not in dict_t.keys()) or (i in dict_t.keys() and dict_s[i] != dict_t[i]):
return False
for i in dict_t.keys():
if (i not in dict_s.keys()) or (i in dict_s.keys() and dict_s[i] != dict_t[i]):
return False
return True202. 快乐数
题目:编写一个算法来判断一个数 n 是不是快乐数。
快乐数定义为:1. 对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。2. 然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。3. 如果这个过程 结果为 1,那么这个数就是快乐数。
如果 n 是快乐数就返回 true ;不是,则返回 false 。
算法:创建一个空集合seen用于记录每次将数字替换为各位置上数字的平方和的过程中得到的结果,n不断地变换过程中,假如数字既不等于1也不在seen中,则继续进行变换,变换的方式是将当前的数字不断除以10取余数并将余数的平方和累加,直到除尽。
def isHappy(n):
seen= set()
while n != 1 and n not in seen:
seen.add(n)
n_sum = 0
while n > 0:
temp = n % 10
n_sum += temp**2
n //= 10
n = n_sum
return n==1219. 存在重复元素II
题目:给你一个整数数组 nums 和一个整数 k ,判断数组中是否存在两个 不同的索引 i 和 j ,满足 nums[i] == nums[j] 且 abs(i - j) <= k 。如果存在,返回 true ;否则,返回 false 。
算法:创建一个空列表seen用于记录遍历过程中离当前元素最近的k个元素,用i遍历nums,若i在seen中则表示距离它最近的k个元素中有与之取值相同的元素,因此返回true,然后给集合seen添加元素i,此时若seen元素个数大于k,则移除其第一个元素。遍历结束后返回false。
def containsNearbyDuplicate(nums, k):
seen = []
for num in nums:
if num in seen:
return True
seen.append(num)
if len(seen) > k:
seen.pop(0)
return False49. 字母异位词分组
题目:给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列源单词的所有字母得到的一个新单词。
例:输入strs=['eat', 'tea', 'tan', 'ate', 'nat', 'bat'],输出[['bat'], ['nat','tan'], ['eat','tea','ate']]。
算法:创建一个空字典char_strs,键是每个单词按字母顺序排列后的字符串,值是容纳键的异位词的列表。用word遍历strs列表的每一个元素(单词),将其变成按字母顺序排列后的字符串char_sorted后以char_strs[char_strs].append(word)的方式加入字典char_strs中,再返回char_strs.values()即可。
def groupAnagrams(strs):
char_dict = {}
for word in strs:
word_sorted = ''.join(sorted(word)) # 将word字符串按字母顺序排列形成新的字符串
if word_sorted not in char_dict.keys():
char_dict[word_sorted] = []
char_dict[word_sorted].append(word) # 将word字符串加入字典对应的值中
return char_dict.values()128. 最长连续序列
题目:给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
请你设计并实现时间复杂度为 O(n) 的算法解决此问题。
例:输入nums=[100, 4, 200, 1, 3, 2],最长的数字连续序列是[1, 2, 3, 4],因此输出4。
算法:如下
def longestConsecutive(nums):
nums=set(nums)
longest_len = 0
for i in nums:
if i-1 not in nums:
cur_len = 1
while i + 1 in nums:
i += 1
cur_len += 1
longest_len = max(longest_len, cur_len)
return longest_len区间
228. 汇总区间
题目:给定一个无重复元素的有序整数数组nums。返回恰好覆盖数组中所有数字的最小有序区间范围列表。也就是说nums的每个元素都恰好被某个区间范围所覆盖,并且不存在属于某个范围但不属于nums的数字x。
列表中的每个区间范围[a,b]应该按如下格式输出:
·1. 'a->b',如果a != b
·2. 'a',如果 a == b
例:输入nums=[0,1,2,4,5,7],输出['0->2','4->5','7']。
算法:使用两个指针 start 和 end 来追踪当前区间的起始和末尾。遍历数组,如果当前元素与前一个区间末尾连续,我们就更新区间末尾end = current element;否则,我们将前一个区间[start, end]加入结果列表,并更新 start 和 end 为当前元素。最后,我们还需要处理最后一个区间,并将其加入结果列表。
这个解决方案的时间复杂度是 O(N),其中 N 是数组 nums 的长度,因为我们只需要遍历数组一次。空间复杂度是 O(K),其中 K 是结果列表的长度,因为我们需要存储每个区间的表示。
def summaryRanges(nums):
if not nums:
return []
n = len(nums)
start, end = nums[0], nums[0] # 双指针,初始时都指向数组的第一个元素
res = [] # 存储结果的列表
for i in range(1, n):
if nums[i] == end + 1: # 当前元素与前一个区间末尾连续
end = nums[i] # 更新区间末尾
else: # 当前元素与前一个区间末尾不连续
if start == end: # 如果区间只有一个元素
res.append(str(start))
else: # 如果区间有多个元素
res.append(''.join([str(start),'->',str(end)]))
start = end = nums[i] # 更新区间起始和末尾
# 处理最后一个区间
if start == end:
res.append(str(start))
else:
res.append(''.join([str(start),'->',str(end)]))
return res56. 合并区间
题目:以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] 。请你合并所有重叠的区间,并返回一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间。
例:输入intervals=[[1,3],[2,6],[8,10],[15,18]],输出[[1,6],[8,10],[15,18]]。
算法:1. 将intervals从小到大排序。2. 用result存储结果,初值取为result=[[intervals[0]],用interval遍历intervals,若interval[0]<results[-1][1]则合并interval和results[-1],否则将interval加入result中。
def merge(intervals):
if not intervals:
return []
intervals.sort()
result = [intervals[0]]
for interval in intervals[1:]:
if interval[0] <= result[-1][1]:
result[-1][1] = max(interval[1], result[-1][1])
else:
result.append(interval)
return result57. 插入区间
题目:给你一个无重叠的,按照区间起始端点排序的区间列表 intervals,其中 intervals[i] = [starti, endi] 表示第 i 个区间的开始和结束,并且 intervals 按照 starti 升序排列。同样给定一个区间 newInterval = [start, end] 表示另一个区间的开始和结束。
在 intervals 中插入区间 newInterval,使得 intervals 依然按照 starti 升序排列,且区间之间不重叠(如果有必要的话,可以合并区间)。
返回插入之后的 intervals。
注意 你不需要原地修改 intervals。你可以创建一个新数组然后返回它。
例:输入intervals = [[1,3],[6,9]],newInterval = [2,5],输出[[1,5],[6,9]]。输入intervals = [[1,2],[3,5],[6,7],[8,10],[12,16]],newInterval = [4,8],输出[[1,2],[3,10],[12,16]](因为[4,8]与重叠[3,5],[6,7],[8,10])。
算法:1. 初始化一个空的结果列表result。2. 遍历intervals列表,找到第一个与newInterval不重叠的区间,即第一个区间的结束值大于newInterval的开始值。在这个过程中,将所有与newInterval不重叠且右端点小于newInterval左端点的区间加入到result列表中。3. 当找到与newInterval重叠的区间时,开始合并这些区间。通过更新newInterval的开始值和结束值,使其包含所有重叠的区间。4. 将合并后的newInterval加入到result列表中。5. 最后,将intervals列表中剩余的区间(即不与newInterval重叠且左端点大于newInterval右端点的区间)加入result列表中,返回result。
def insert(intervals, newInterval):
result = []
# 将小于newInterval的区间加入结果列表
i = 0
while i < len(intervals) and intervals[i][1] < newInterval[0]:
result.append(intervals[i])
i += 1
# 合并与newInterval重叠的区间
while i < len(intervals) and intervals[i][0] <= newInterval[1]:
newInterval[0] = min(newInterval[0], intervals[i][0])
newInterval[1] = max(newInterval[1], intervals[i][1])
i += 1
# 将newInterval加入结果列表
result.append(newInterval)
# 将剩余的区间加入结果列表
while i < len(intervals):
result.append(intervals[i])
i += 1
return result452. 用最少数量的箭引爆气球
题目:有一些球形气球贴在一堵用 XY 平面表示的墙面上。墙面上的气球记录在整数数组 points ,其中points[i] = [xstart, xend] 表示水平直径在 xstart 和 xend之间的气球。你不知道气球的确切 y 坐标。
一支弓箭可以沿着 x 轴从不同点 完全垂直 地射出。在坐标 x 处射出一支箭,若有一个气球的直径的开始和结束坐标为xstart,xend, 且满足 xstart ≤ x ≤ xend,则该气球会被 引爆 。可以射出的弓箭的数量 没有限制 。 弓箭一旦被射出之后,可以无限地前进。
给你一个数组points,返回引爆所有气球所必须射出的 最小 弓箭数 。
例:输入points = [[10,16],[2,8],[1,6],[7,12]],输出2(在x=6处射出箭,击破气球[2,8]和[1,6],在x=11处射出箭,击破气球[10,16]和[7,12])。输入points = [[1,2],[2,3],[3,4],[4,5]],输出2(在x=2处射出箭,击破气球[1,2]和[2,3],在x=4处射出箭,击破气球[3,4]和[4,5])。
算法:1. 按每个元素的第二个元素对points排序。2. 定义当前用掉了多少支箭和当前箭的射出位置,初值为num_arrow=1和pos_shoot=points[0][1],即第一支箭从第一个气球的最右端射出。3. 遍历每个气球i,若气球的左侧大于pos_shoot(即当前箭射不到当前气球),此时需要再从当前气球的右端位置射出一支箭来射中当前气球,因此num_arrow+=1,pos_shoot=i[1]。
def findMinArrowShots(points):
def f(x):
return x[1]
points.sort(key=f)
num_arrow = 1
pos_shoot = points[0][1]
for i in points:
if i[0] > pos_shoot:
num_arrow += 1
pos_shoot = i[1]
return num_arrow栈
20. 有效的括号
题目:给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
1. 左括号必须使用相同类型的有括号闭合。
2. 左括号必须以正确的顺序闭合。
3. 每个右括号都有一个对应的相同类型的左括号。
算法:定义一个栈stack=[]和一个字典mapping,字典用来存储每个右括号对应的左括号(键是各种右括号,值是对应的左括号)。然后,我们遍历输入的字符串 s,如果字符是右括号,则检查栈顶元素(stack最右边的元素)是否与之匹配(检查的同时删除栈顶元素),如果不匹配或栈为空,则返回 False;如果字符是左括号,则将其放入栈中。最后,我们检查栈是否为空,如果为空,则所有括号都匹配成功,返回 True,否则返回 False。
def isValid(s):
stack = []
dict_s = {')':'(', '}':'{', ']':'['}
for i in s:
if i in dict_s.keys():
if not stack or stack.pop() != dict_s[i]:
return False
else:
stack.append(i)
if not stack:
return True
else:
return False71. 简化路径
题目:给你一个字符串 path ,表示指向某一文件或目录的 Unix 风格 绝对路径 (以 '/' 开头),请你将其转化为更加简洁的规范路径。
在 Unix 风格的文件系统中,一个点(.)表示当前目录本身;此外,两个点 (..) 表示将目录切换到上一级(指向父目录);两者都可以是复杂相对路径的组成部分。任意多个连续的斜杠(即,'//')都被视为单个斜杠 '/' 。 对于此问题,任何其他格式的点(例如,'...')均被视为文件/目录名称。
请注意,返回的 规范路径 必须遵循下述格式:
1. 始终以斜杠'/'开头。
2. 两个目录名之间必须只有一个斜杠'/'。
3. 最后一个目录名(若存在)不能以'/'结尾。
4. 此外路径仅包含从根目录到目标文件或目录的路径上的目录(即不含'.'或'..')。
返回简化后得到的 规范路径 。
例:输入path = "/home/",输出"/home"。输入path = "/home/",输出"/home"。输入path = "/a/./b/../../c/",输出"/c"(注意此路径最开始的/表示根目录,然后进入根目录下的文件夹a,然后.停留在当前目录即文件夹a中,然后进入文件夹a下的文件夹b,然后..从文件夹b返回上级文件夹a中,再..从文件夹a返回根目录,再从根目录进入下属的文件夹c中)。
算法:1. 定义栈stack=[]用于存储简化后的路径,去掉字符串中/的并将/之间的元素提取出来存在列表ll中。2. 用i遍历列表ll,若i是空格或当前目录(.)则不做任何操作,若i是文件夹名称则存入栈中,若i是..则删除栈的最后一个元素即返回上一级目录。3. 结果为/后面跟上用/分开stack各元素形成的字符串。
def simplifyPath(self, path):
stack = []
ll = path.split('/')
for i in ll:
if i == '' or i == '.':
continue
elif i == '..':
if stack:
stack.pop()
else:
stack.append(i)
result = '/' + '/'.join(stack)
return result155. 最小栈
题目:设计一个支持 push ,pop ,top 操作,并能在常数时间内检索到最小元素的栈。即实现如下MinStack类:
1. MinStack() 初始化堆栈对象,属性包含一个空列表。
2. push(val) 方法将元素val推入堆栈。
3. pop() 方法删除堆栈顶部的元素。
4. top() 方法获取堆栈顶部的元素。
5. getMin() 方法取堆栈中的最小元素。
算法:为了实现这个最小栈,我们可以使用一个辅助栈来存储当前栈中的最小值。当我们向主栈中添加一个新元素时,我们同时检查这个元素是否比辅助栈顶的元素小。如果是,我们将这个新元素也压入辅助栈;如果不是,我们保持辅助栈不变。这样,辅助栈的栈顶元素就始终是当前主栈中的
最小元素,getMin()方法直接返回辅助栈最后一个元素即可。
class MinStack(object):
def __init__(self):
self.stack = []
self.aux = [float('inf')]
def push(self, val):
self.stack.append(val)
self.aux.append(min(val, self.aux[-1]))
def pop(self):
if self.stack:
self.stack.pop()
self.aux.pop()
def top(self):
if self.stack:
return self.stack[-1]
else:
return None
def getMin(self):
if self.stack:
return self.aux[-1]
else:
return None需要注意的是,返回和删除栈的元素时需要先判断栈有没有元素,如果是空栈,则返回None、不删除。
150. 逆波兰表达式求值
题目:给你一个字符串数组 tokens ,表示一个根据逆波兰表示法表示的算术表达式(逆波兰表达式是一种后缀表达式,所谓后缀就是指算符写在后面,平常使用的算式则是一种中缀表达式,中缀表达式的a operator b放在逆波兰表达式中写作a b operator,逆波兰表达式主要优点为适合用栈操作运算,遇到数字则入栈;遇到算符则取出栈顶两个数字进行计算,并将结果压入栈中)。
请你计算该表达式。返回一个表示表达式值的整数。
注意:
1. 有效的算符为 '+'、'-'、'*' 和 '/' 。
2. 每个操作数(运算对象)都可以是一个整数或者另一个表达式。
3. 两个整数之间的除法总是 向零截断 。
4. 表达式中不含除零运算。
5. 输入是一个根据逆波兰表示法表示的算术表达式。
6. 答案及所有中间计算结果可以用 32 位 整数表示。
输入tokens = ['10', '6', '9', '3', '+', '-11', '*', '/', '*', '17', '+', '5', '+'],其对应的中缀表达式为:((10*(6/((9+3)*-11)))+17)+5,因此输出22。
算法:1. 定义了一个空栈 stack 来存储操作数和中间结果。2. 用i遍历 tokens 列表。如果i是操作数(即不是操作符),则将其转换为整数并压入栈中。如果 token 是操作符,则弹出栈顶的两个元素(它们分别是操作数),根据操作符进行相应的计算,并将结果压回栈中。3. 栈中最后剩下的元素stack[0]就是逆波兰表达式的值。
def evalRPN(tokens):
stack = []
operator = {'+', '-', '*', '/'}
for i in tokens:
if i not in operator:
stack.append(int(i))
else:
num2 = stack.pop()
num1 = stack.pop()
if i == '+':
stack.append(num1 + num2)
if i == '-':
stack.append(num1 - num2)
if i == '*':
stack.append(num1 * num2)
if i == '/':
stack.append(int(num1 / num2))
return stack[0]链表
链表(Linked List)是一种数据结构,它若干节点组成,每个节点包含两个信息即存储的数据和指向下一个节点的指针或引用。节点通过指针或引用连接在一起,形成一条链。每个节点只知道它下一个节点的位置,而不知道其他节点的位置。链表有多种类型,包括:
• 单向链表(Singly Linked List):每个节点只有一个指针,指向下一个节点。
• 双向链表(Doubly Linked List):每个节点有两个指针,一个指向下一个节点一个指向前一个节点。
• 循环链表(Circular Linked List):链表最后一个节点指向第一个节点形成一个循环,可以是单向循环链表也可以是双向循环链表。
链表的主要优点是动态分配内存、插入和删除操作效率高(在已知节点位置的情况下)。但是,链表需要额外的空间来存储指针,并且不能像数组那样通过下标直接访问元素。
Python中可以通过定义如下类实现单向链表:
# Definition for singly-linked list.
class ListNode:
def __init__(self, x, next=None):
self.val = x
self.next = next138. 随机链表的复制
题目:给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val,random_index] 表示:
• val:一个表示 Node.val 的整数。
• random_index:随机指针指向的节点索引(范围从 0 到 n-1);如果不指向任何节点,则为 null 。
你的代码 只 接受原链表的头节点 head 作为传入参数。
算法:本题coding之前先画出图形来引导思路。首先检查链表是否为空,然后进行三个步骤的处理:
• 复制每个节点,并将复制的节点链接在原节点之后:

• 复制每个节点的random指针。如本例中x2指向x4, 则y2应当指向y4,用x2.next.random=x2.random.next即可实现,因为xi.next指向其对应的副本节点yi,因此该操作等价于y2.random=y4。

• 拆分复制的链表。

最后返回新的复制链表的头指针。
class Node:
def __init__(self, x, next, random):
self.val = int(x)
self.next = next
self.random = random
def copyRandomList(head):
if not head:
return None
# 第一步:复制每个节点,并将复制的节点链接在原节点之后
cur = head
while cur:
clone = Node(x=cur.val)
clone.next = cur.next
cur.next = clone
cur = clone.next
# 第二步:复制每个节点的random指针
cur = head
while cur:
if cur.random:
cur.next.random = cur.random.next
cur = cur.next.next
# 第三步:拆分复制的链表
cur = head
resul = head.next
while cur:
clone = cur.next
cur.next = cur.next.next if cur.next.next else None # 此处条件是cur.next.next因为cur是原链表其每个节点必然存在后代节点(也就是其副本节点), 当其后代结点没有后代时表示遍历到最后一个原链表节点了, 应当给cur的后代赋值为None.
cur = cur.next
clone.next = clone.next.next if clone.next else None # 此处条件是clone.next因为clone没有后代节点时表示其时副本链表中最后一个节点, 此时其后代赋值为None.
return resul92. 反转链表 II
题目:给你单链表的头指针 head 和两个整数 left 和 right ,其中 left <= right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。
算法:
1. 找到需要反转部分的前一个节点(如果left是1,那么前一个节点就是空)。
2. 从前一个节点开始,一直找到需要反转部分的最后一个节点。
3. 反转从前一个节点到需要反转部分的最后一个节点的链表。
4. 将反转后的链表接回原链表。
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
def reverseList(head_node, end_node): # 注意end节点没有被翻转, 即end是被翻转的子链表往后的一个节点
pre_node = None
cur_node = head_node
while cur_node != end_node:
next_node = cur_node.next
cur_node.next = pre_node
pre_node = cur_node
cur_node = next_node
return pre_node
def reverseBetween(head, left: int, right: int):
dummy = ListNode(0, head)
pre = dummy
# 找到需要反转部分的前一个节点
for _ in range(left - 1):
pre = pre.next
head = head.next
# 找到需要反转部分的最后一个节点
end = head
for _ in range(right - left +1):
end = end.next
# 反转从head到end的链表
new_head = reverseList(head, end)
# 接回原链表
pre.next = new_head
head.next = end
return dummy.next19. 删除链表的倒数第N个结点
题目:给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
算法:1. 首先在头节点前添加一个哑节点,以防单节点链表要求删除唯一节点的情况。2. 计算链表总长。3. 将链表从头节点遍历到需要删除的节点的前一个节点,然后将此节点链接到需要删除的节点的后一个节点上。
def removeNthFromEnd(head, n):
# 设置额外的头节点, 防止单节点链表删除倒数第一个节点的情况
dummy = ListNode(val=0, next=head)
# 计算链表长度
cur = dummy
l = 0
while cur:
l += 1
cur = cur.next
# 倒数第N个节点是正数第l+1-n个节点
cur = dummy
for i in range(0,l+1-n-2):
cur = cur.next
# 此时cur是要删除的节点的前一个节点
cur.next = cur.next.next if cur.next.next else None
return dummy.next82. 删除排序链表中的重复元素 II
题目:给定一个已排序的链表的头head,删除原始链表中所有重复数字的节点,只留下不同的数字 。返回已排序的链表。
算法:1. 遍历链表将链表中的重复元素储存到一个列表中,若此列表为空则直接返回head。2. 给head前添加一个哑节点dum,从哑节点开始遍历链表,若当前结点的下一个结点在重复元素列表中,则令当前结点指向下下个节点,重复此操作直到当前结点的下一个结点不在重复元素列表中或已不存在下一个列表。
def deleteDuplicates(head):
cur = head
dup = []
while cur and cur.next:
if cur.val == cur.next.val:
dup.append(cur.val)
cur = cur.next
if not dup:
return head
dum = ListNode(val=min(dup)-1, next=head)
cur = dum
while cur.next:
if cur.next.val in dup:
cur.next = cur.next.next
else:
cur = cur.next
return dum.next61. 旋转链表
题目:给你一个链表的头节点 head ,旋转链表,将链表每个节点向右移动 k 个位置。例:

算法:1. 空链表或长度为1的链表直接原样返回。2. 计算链表长度,旋转次数大于链表长度时将旋转次数取为其除以链表长度的余数。3. 将最后一个结点链接到头节点上。4. 将第l-k个节点的下一个结点取成空。
def rotateRight(head, k):
# 直接返回结果的情况(旋转次数为0/空链表/长度为1的链表)
if k==0 or (not head) or (not head.next):
return head
# 链表长度
cur = head
l = 0
while cur:
l += 1
cur = cur.next
# 旋转次数等于链表长度时等于没旋转
k = k % l
if k == 0:
return head
# 将最后一个结点链接到头节点上
cur = head
for i in range(0, l-1):
cur = cur.next
cur.next = head
# 截取链表前l-k个节点
cur = head
if l-k-1>0:
for i in range(0,l-k-1):
cur = cur.next
resul = cur.next
cur.next = None
return resul86. 分隔链表
题目:给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。
你应当 保留 两个分区中每个节点的初始相对位置。
算法:创建两条链表,分别用于存储原链表中小于x和大于等于x的节点,然后将二者连接起来。
def partition(self, head: Optional[ListNode], x: int) -> Optional[ListNode]:
# 分别将原链表中小于/大于等于x的节点按原顺序接入以下两条链表中
dum_left = ListNode(val=-1)
dum_right = ListNode(val=+1)
ll_left = dum_left
ll_right = dum_right
cur = head
while cur:
if cur.val < x:
ll_left.next = cur
ll_left = ll_left.next
else:
ll_right.next = cur
ll_right = ll_right.next
cur = cur.next
ll_left.next = dum_right.next
ll_right.next = None # 注意这一步
return dum_left.next146. LRU缓存
题目:请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
• LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存
• int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。
• void put(int key, int value) 如果关键字 key 已经存在,则变更其数据值 value ;如果不存在,则向缓存中插入该组 key-value 。如果插入操作导致关键字数量超过 capacity ,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
算法:没看懂
class LRUCache:
def __init__(self, capacity: int):
self.capacity = capacity
self.cache = {}
self.keys = []
def get(self, key: int) -> int:
if key not in self.cache.keys():
return -1
self.keys.remove(key)
self.keys.append(key)
return self.cache[key]
def put(self, key: int, value: int) -> None:
if key in self.cache:
self.keys.remove(key)
elif len(self.cache) == self.capacity: # 这一步用列表keys判断各关键字被使用的顺序, 这就是为什么要定义keys
removed_key = self.keys.pop(0)
self.cache.pop(removed_key)
self.keys.append(key)
self.cache[key] = value
# Your LRUCache object will be instantiated and called as such:
# obj = LRUCache(capacity)
# param_1 = obj.get(key)
# obj.put(key,value)二叉树
100. 相同的树
题目:给你两棵二叉树的根节点p和q,编写一个函数来检验这两棵树是否相同。
如果两个树在结构上相同,并且节点具有相同的值,则认为它们是相同的。
算法:使用递归算法。1. 检查两个根节点是否都为空,如果都为空则返回True,表示两棵树在当前位置上是相同的。2. 检查是否只有一个节点为空(另一个非空),或者两个节点的值不同,如果满足这两个条件中的任何一个,则返回False,表示两棵树不相同。3. 递归地检查两个根节点的左子树和右子树是否相同,只有当左子树和右子树都相同时,才返回 True。
def isSameTree(p, q):
if not p and not q:
return True
if (not p or not q) or (p.val != q.val):
return False
result = isSameTree(p.left, q.left) and isSameTree(p.right, q.right)
return result注意上述代码中not p or not q其包含了p和q同时非空的情况,但是由于这一情况若满足则在上一条语句中就已经返回结果了因此不影响。
112. 路径总和
题目:给你二叉树根节点root和一个表示目标和的整数 targetSum 。判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。如果存在,返回 true ;否则,返回 false 。
算法:1. 检查根节点是否为空,如果为空则返回False。2. 检查当前节点是否为叶子节点,并且判断当前节点的值是否等于目标和。如果满足条件,则返回True。3. 否则递归地检查左子树和右子树,看是否存在满足条件的路径。我们通过从目标和中减去当前节点的值来更新递归调用的目标和。
def hasPathSum(root, targetSum):
if not root:
return False
if not root.left and not root.right:
if root.val == targetSum:
return True
else:
return False
y1 = self.hasPathSum(root.left, targetSum-root.val)
y2 = self.hasPathSum(root.right, targetSum-root.val)
return y1 or y2106. 从中序与后序遍历序列构造二叉树
题目:给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这棵二叉树。
所谓中序遍历指左子树-->根节点-->右子树,后序遍历指左子树-->右子树-->根节点。
例:上题的树在本题中对应输入inorder=[9,3,15,20,7],postorder=[9,15,7,20,3],输出树[3,9,20,null,null,15,7]。
算法:使用递归算法。1. 由于后序遍历是"左子树-->右子树-->根节点",因此从后序遍历中我们可以直接得到根节点(即postorder[-1]),用它来生成树的根节点。2. 在中序遍历中找到这个根节点的位置,从而可以分割出左子树和右子树(由于中序遍历是"左子树-->根节点-->右子树"因此中序遍历中根节点左边是左子树的中序遍历,右边是右子树的中序遍历)。也就知道了左子树的元素个数(等于中序遍历中根节点索引前的元素个数),从而能在后序遍历中得到左子树和右子树的后序遍历3. 知道了左右子树的中序和后序遍历,从而可以递归地对左子树和右子树进行同样的操作。
def buildTree(inorder, postorder):
if not inorder or not postorder:
return None
# 根节点值和根节点在中序遍历中的位置
root = TreeNode(val = postorder[-1])
root_index = inorder.index(postorder[-1])
# 左右子树的中序遍历
left_inorder = inorder[0:root_index]
right_inorder = inorder[root_index+1:len(inorder)]
# 左右子树的后序遍历
left_postorder = postorder[0:len(left_inorder)]
right_postorder = postorder[len(left_inorder):len(postorder)-1]
# 递归生成左右子树
root.left = buildTree(left_inorder, left_postorder)
root.right = buildTree(right_inorder, right_postorder)
return root236. 二叉树的最近公共祖先
题目:给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
最近公共祖先的定义为:“对于有根树T的两个节点p、q,最近公共祖先为一个节点x,满足x是p、q的祖先且x的深度尽可能大(一个节点也可以是它自己的祖先)。算法:使用递归算法。1. 如果根节点为空,或者根节点就是p或q,那么根节点就是最近公共祖先。2. 递归地在左子树和右子树中搜索p和q。如果左子树和右子树都返回了非空节点,那么当前节点就是最近公共祖先。否则,我们返回左子树或右子树中找到的节点(如果存在的话),或者返回None(如果两者都未找到)。
def lowestCommonAncestor(root, p, q):
if not root or root == p or root == q:
return root
left = self.lowestCommonAncestor(root.left, p, q)
right = self.lowestCommonAncestor(root.right, p, q)
if left and right:
return root
elif left:
return left
elif right:
return right
else:
return None173. 二叉搜索树迭代器
题目:二叉搜索树(BST)是左子树的所有节点值小于根节点、右子树的所有节点值大于根节点的二叉树。请实现一个类BSTIterator,表示一个按中序遍历二叉搜索树(BST)的迭代器:
• 用BSTIterator(TreeNode root)实例化BSTIterator类,其中root是按照本节开头所定义的二叉树类实例化的BST。
• boolean hasNext()方法作用为:按中序遍历二叉树时若下一个节点存在则返回true,否则返回false。
• int next()方法返回按中序遍历二叉树的下一个节点的值。
注意next()的首次调用应当将返回BST中的最小元素。
算法:__init__ 方法初始化栈,将根节点及其所有左子节点压入栈中(按从上到下的顺序,由BST的性质可知初始化的栈元素是从大到小排列的)。next方法返回栈顶节点的值,同时将此元素从栈中删除,并将此节点的右子节点及其所有左子节点压入栈中。hasNext 方法检查栈是否为空,如果不为空,则意味着还有下一个节点可以访问。pushLeft 方法是一个辅助方法,用于从给定节点开始依次将节点的左子节点压入栈中。
class BSTIterator:
def __init__(self, root: Optional[TreeNode]):
self.stack = []
self.pushLeft(root)
def next(self) -> int:
node = self.stack.pop()
self.pushLeft(node.right)
return node.val
def hasNext(self) -> bool:
return len(self.stack) > 0
def pushLeft(self, node):
while node:
self.stack.append(node)
node = node.left129. 求根节点到叶节点数字之和
题目:给你一个二叉树的根节点 root ,树中每个节点都存放有一个 0 到 9 之间的数字。
每条从根节点到叶节点的路径都代表一个数字,例如,从根节点到叶节点的路径 1 -> 2 -> 3 表示数字 123 。
计算从根节点到叶节点生成的 所有数字之和 。叶节点 是指没有子节点的节点。
算法:定义函数dfs从一个节点开始向下遍历二叉树。对于给定节点,我们将当前节点的值加到当前数字上(注意是乘以10的当前位数,然后加上当前节点的值),然后递归地遍历左子树和右子树。当遍历到叶节点时,我们将当前数字加到总和中。最后返回总和即可。
def sumNumbers(root: Optional[TreeNode]) -> int:
if not root:
return 0
total_sum = 0
# 给定一个数和一个节点, 计算从此节点往下走的所有路径的数字之和
def dfs(current_num, node):
if not node:
return
# 将当前节点的值加到当前数字上(注意是乘以10的当前位数,然后加上当前节点的值)
current_num = current_num * 10 + node.val
# 如果当前节点是叶节点(没有子节点),则将当前数字加到总和中
if not node.left and not node.right:
total_sum += current_num
# 递归遍历左子树和右子树
dfs(node.left, current_num)
dfs(node.right, current_num)
# 从根节点开始,当前数字初始化为0
dfs(root, 0)
return total_sum117. 填充每个节点的下一个右侧节点指针 II
题目:给定一个二叉树:
struct Node {
int val;
Node *left;
Node *right;
Node *next;
}
填充它的每个next指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将next指针设置为 NULL 。
初始状态下,所有next指针都被设置为 NULL 。
例:

算法:本题中的二叉树除了使用常规的左右子树指针外,每个节点还有一个 next 指针,它可以指向同一层中的下一个节点。解法为使用队列来进行层次遍历(广度优先搜索)。在遍历过程中,我们跟踪当前层的所有节点,并将它们添加到队列中。然后,我们处理当前层的节点,并将它们的 next 指针指向同一层的下一个节点。当我们处理完当前层的所有节点时,我们将它们的子节点(如果存在)添加到队列中,并继续处理下一层。
class Node:
def __init__(self, val=None, left=None, right=None, next=None):
self.val = val
self.left = left
self.right = right
self.next = next
class Solution:
def connect(self, root: 'Node') -> 'Node':
if not root:
return root
queue = [root] # 初始化队列,将根节点入队
while queue:
level_size = len(queue) # 当前层的节点数量
prev_node = None # 用于跟踪当前层的上一个节点
for _ in range(level_size):
node = queue.pop(0) # 出队一个节点
if prev_node:
prev_node.next = node # 将上一个节点的 next 指针指向当前节点
if node.left:
queue.append(node.left) # 如果左子节点存在,入队
if node.right:
queue.append(node.right) # 如果右子节点存在,入队
prev_node = node # 更新上一个节点为当前节点
return root图
200. 岛屿数量
题目:给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。例:
输入
grid = [
['1','1','0','0','0'],
['1','1','0','0','0'],
['0','0','1','0','0'],
['0','0','0','1','1']
],
输出3。
算法:1. 定义dfs函数,对给定单元格,若其为未访问过的陆地则将其标记为访问过,并将与之相连的陆地全部标记为访问过。2. 遍历整个图,遇到陆地就将岛屿数量加一,并对当前单元格使用dfs。
def numIslands(grid):
rnum = len(grid)
cnum = len(grid[0])
num = 0
def dfs(i, j):
if (i>=0 and i<rnum) and (j>=0 and j<cnum) and (grid[i][j]=='1'):
grid[i][j] = '-1'
dfs(i-1, j)
dfs(i+1, j)
dfs(i, j-1)
dfs(i, j+1)
for i in range(rnum):
for j in range(cnum):
if grid[i][j]=='1':
num += 1
dfs(i, j)
return num130. 被围绕的区域
题目:给你一个 m x n 的矩阵 board ,由若干字符 'X' 和 'O' 组成,捕获 所有 被围绕的区域:
• 连接:一个单元格与水平或垂直方向上相邻的单元格连接。
• 区域:连接所有 'O' 的单元格来形成一个区域。
• 围绕:如果您可以用 'X' 单元格 连接这个区域,并且区域中没有任何单元格位于 board 边缘,则该区域被 'X' 单元格围绕。
通过将输入矩阵 board 中的所有 'O' 替换为 'X' 来 捕获被围绕的区域。例:
输入board=[['X','X','X','X'],['X','O','O','X'],['X','X','O','X'],['X','O','X','X']],
输出[['X','X','X','X'],['X','X','X','X'],['X','X','X','X'],['X','O','X','X']]。

算法:从外向内遍历。1. 定义dfs函数,对给定单元格,若其为'O'则将此单元格和与之相连的'O'全部标记为'#'。2. 先遍历4条边界,将其上的'O'全部以dfs作用。再遍历整个图,将'O'改成'X',再将'#'改成'O'。
def solve(board):
"""
Do not return anything, modify board in-place instead.
"""
nrow = len(board)
ncol = len(board[0])
def bfs(i, j):
if (i>=0 and i<nrow) and (j>=0 and j<ncol) and (board[i][j]=='O'):
board[i][j]='#'
bfs(i-1, j)
bfs(i+1, j)
bfs(i, j-1)
bfs(i, j+1)
for i in range(nrow): # 左右边界
bfs(i, 0)
bfs(i, ncol-1)
for j in range(ncol): # 上下边界
bfs(0, j)
bfs(nrow-1, j)
for i in range(nrow):
for j in range(ncol):
if board[i][j] == 'O':
board[i][j] = 'X'
elif board[i][j] == '#':
board[i][j] = 'O'133. 克隆岛
题目:给你无向 连通 图中一个节点的引用,请你返回该图的 深拷贝(克隆)。
图中的每个节点都包含它的值 val(int) 和其邻居的列表(list[Node])。
测试用例格式:
简单起见,每个节点的值都和它的索引相同。例如,第一个节点值为 1(val = 1),第二个节点值为 2(val = 2),以此类推。该图在测试用例中使用邻接列表表示。
邻接列表 是用于表示有限图的无序列表的集合。每个列表都描述了图中节点的邻居集。
给定节点将始终是图中的第一个节点(值为1)。你必须将 给定节点的拷贝 作为对克隆图的引用返回。例:
输入adjList = [[2,4],[1,3],[2,4],[1,3]],输出[[2,4],[1,3],[2,4],[1,3]]。图中有 4 个节点。 节点 1 的值是 1,它有两个邻居:节点 2 和 4 。 节点 2 的值是 2,它有两个邻居:节点 1 和 3 。 节点 3 的值是 3,它有两个邻居:节点 2 和 4 。 节点 4 的值是 4,它有两个邻居:节点 1 和 3 。
算法:定义一个递归函数 dfs,它接受一个原节点作为参数,并返回该节点的克隆节点。在 dfs 函数中,我们首先检查当前节点是否已经被访问过。如果是,则直接返回对应的克隆节点。否则,我们克隆当前节点,并将其添加到 visited 字典中。然后,我们递归地克隆当前节点的所有邻居节点,并将克隆的邻居节点添加到克隆节点的邻居列表中。最后,我们返回克隆节点。直接将函数dfs作用在输入节点上作为返回值。
"""
# Definition for a Node.
class Node:
def __init__(self, val = 0, neighbors = None): # neighbors属性是一个列表
self.val = val
self.neighbors = neighbors if neighbors is not None else []
"""
def cloneGraph(node):
if not node:
return None
def dfs(node, visited):
if node in visited.keys():
return visited[node]
clone = Node(val=node.val, neighbors=[])
visited[node] = clone
for neighbor in node.neighbors:
clone.neighbors.append(dfs(neighbor, visited))
return clone
return dfs(node,{})399. 除法求值
题目:给你一个变量对数组 equations 和一个实数值数组 values 作为已知条件,其中 equations[i] = [Ai, Bi] 和 values[i] 共同表示等式 Ai / Bi = values[i] 。每个 Ai 或 Bi 是一个表示单个变量的字符串。
另有一些以数组 queries 表示的问题,其中 queries[j] = [Cj, Dj] 表示第 j 个问题,请你根据已知条件找出 Cj / Dj = ? 的结果作为答案。
返回 所有问题的答案 。如果存在某个无法确定的答案,则用 -1.0 替代这个答案。如果问题中出现了给定的已知条件中没有出现的字符串,也需要用 -1.0 替代这个答案。
注意:输入总是有效的。你可以假设除法运算中不会出现除数为 0 的情况,且不存在任何矛盾的结果。
注意:未在等式列表中出现的变量是未定义的,因此无法确定它们的答案。
例:
输入equations = [['a','b'],['b','c']],values = [2.0,3.0],queries = [['a','c'],['b','a'],['a','e'],['a','a'],['x','x']]。输出[6,0.5,-1,1,-1]。
条件:a/b = 2.0,b/c = 3.0。问题:a/c = ?,b/a = ?,a/e = ?,a/a = ?,x/x = ?,结果:[6.0,0.5,-1.0,1.0,-1.0]。
算法:1. 将已知条件构建成一个双层字典,外层字典的键和值分别为已知条件的分子和内层字典,内层字典的键和值分别为分母和分式的值,如已知条件是a/b = 2.0,b/a = 0.5,b/c= 3.0,c/b = 1/3.0,其构成的字典为:
{'a':{'b':2.0}, 'b':{'a':0.5, 'c':3.0}, 'c':{'b':1/3}}
2. 设计递归函数dfs(node, target, visited, path_product),用于求node/target的值。其原理为找到一条从node到target的路径,每段移动都代表一个分式,如求node/target = a/c,则先从'a'的分母(只有'b')中寻找一个没走过的结点,若其能走则从这走,本段移动'a'-->'b'代表a/b。然后从'b'开始往下走(这一步是递归),寻找其分母中没走过的节点('a'走过因此不走只能走'c'),若其能走则从这走,本段移动'b'-->'c'代表b/c。然后从'c'开始往下走(这一步是递归),由于已经到达目的地,因此直接返回结果path_product。
3. 遍历queries,若分子或分母不在条件字典的键中则返回-1,否则计算dfs(分子, 分母, [], 1.0)。
def calcEquation(equations, values, queries):
def f(dic, num, den, val):
if num in dic.keys():
dic[num][den] = val
else:
dic[num] = {den: val}
if den in dic.keys():
dic[den][num] = 1/val
else:
dic[den] = {num: 1/val}
return dic
graph = {}
for i in range(len(equations)):
graph = f(graph, equations[i][0], equations[i][1], values[i])
def dfs(node, target, visited, path_product):
if node == target:
return path_product
visited.append(node)
for neighbor, val in graph[node].items(): # 检查node的分母, 看那条路不在已访问节点列表中且能走通
if neighbor not in visited:
result = dfs(neighbor, target, visited, path_product * val)
if result is not None:
return result
return None
results = []
for numerator, denominator in queries:
if numerator not in graph or denominator not in graph:
results.append(-1.0) # 如果任一节点不在图中,则无法计算
else:
resul = dfs(numerator, denominator, [], 1.0)
results.append(resul if resul is not None else -1.0)
return results














 192
192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









