






目前我们使用的数据集成和数据同步方案都是以flink作为底层同步数据工具,所以对于我们针对数据集成的资源的优化,实际上就是优化我们flink的过程。
一 Flink 集群剖析
Flink 运行时由两种类型的进程组成:一个 JobManager 和一个或者多个 TaskManager。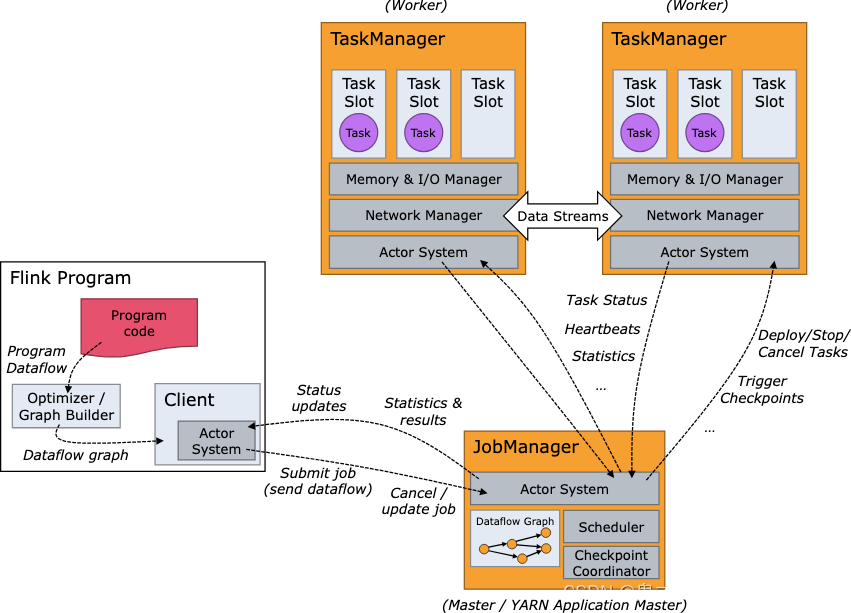
JobManager 具有许多与协调 Flink 应用程序的分布式执行有关的职责:它决定何时调度下一个 task(或一组 task)、对完成的 task 或执行失败做出反应、协调 checkpoint、并且协调从失败中恢复等等
TaskManager(也称为 worker)执行作业流的 task,并且缓存和交换数据流。
必须始终至少有一个 TaskManager。在 TaskManager 中资源调度的最小单位是 task slot。TaskManager 中 task slot 的数量表示并发处理 task 的数量
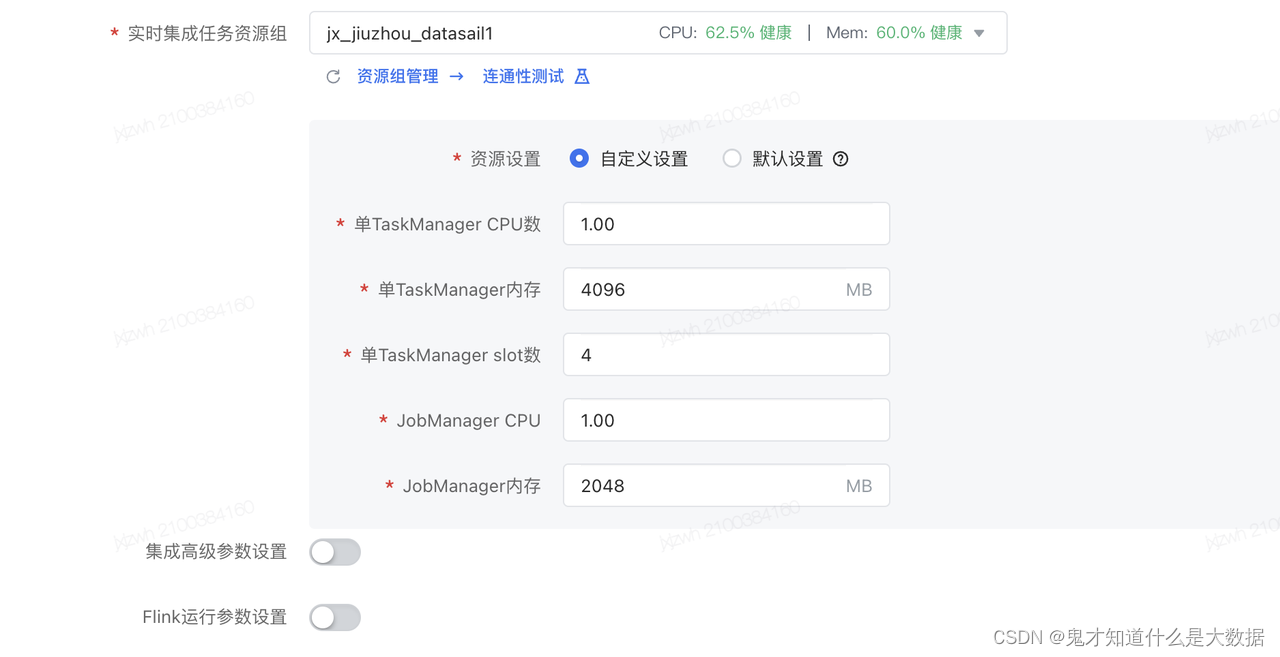
火山这边的Flink session管理系统 :k8s Flink 集群的大小调整应该根据实际的作业负载和资源使用情况来进行。确保flink资源能抗住高峰值的每秒数据量。
二 Flink资源调优
【Flink内存模型】
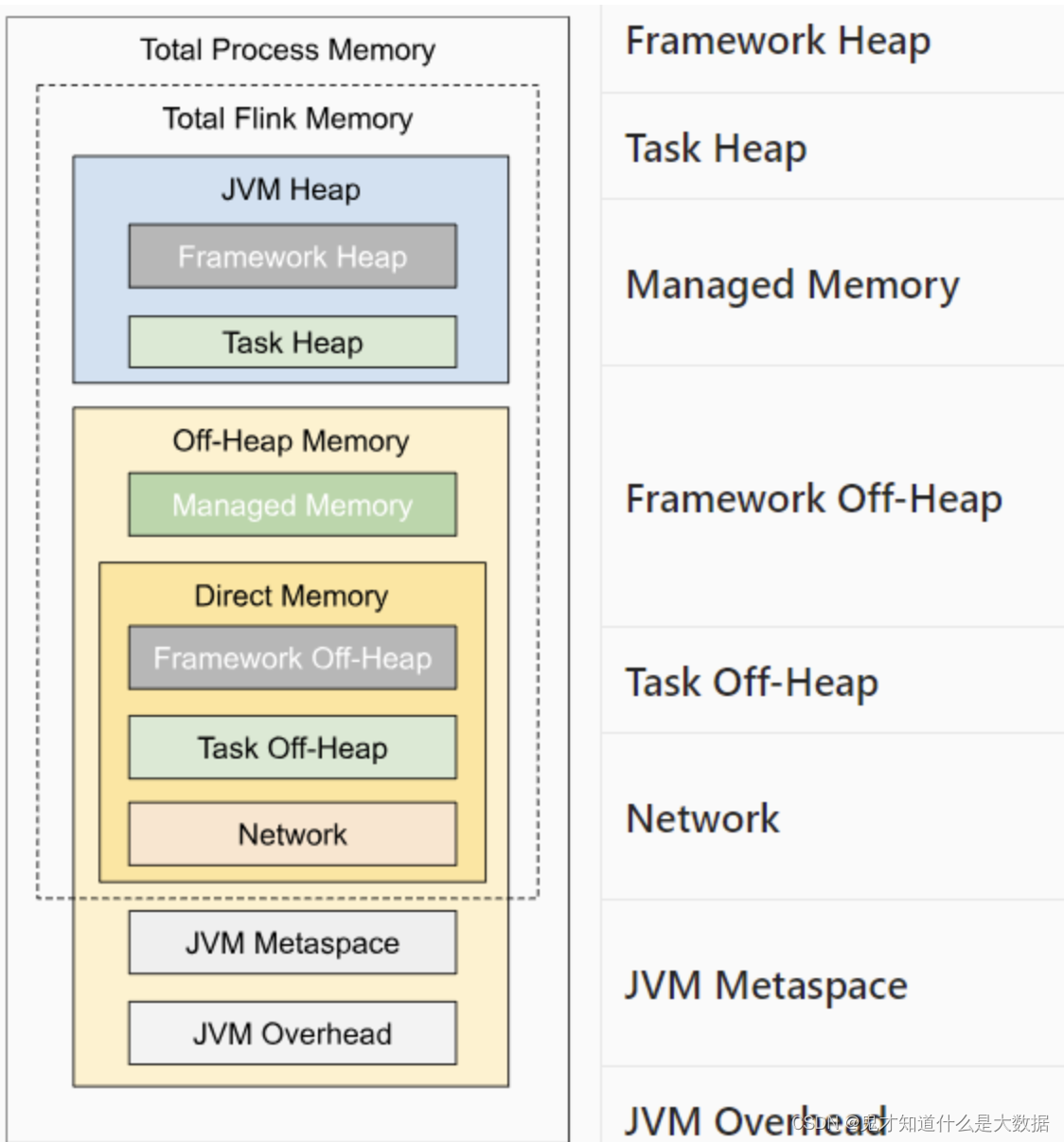
【Flink内存模型详解】
进程内存(Total Process Memory):Flink 进程内存分为堆上内存和堆外内存,堆上内存和
堆外内存的主要区别在于它们的管理方式不同和使用方式不同,这些会影响到它们的性能和使用场景。
(1)JVM Heap(堆上内存):由 JVM 进行管理和分配的内存空间,可以快速的分配和释放内存,具有更好的内存管理和垃圾回收机制(JVM 垃圾回收机制)。
(2)OFF-Heap Memory(堆外内存):由操作系统进行管理和分配的内存空间,能够存储更大的数据和缓存,提供更好的性能和扩展性,堆外内存的使用的管理是要手动编码实现,相对于堆上内存更加复杂和容易出错。
JVM 内存: JVM 内存包括 JVM Mataspace(JVM 元空间)和 JVM OverHead(JVM 执行开销)
(1)JVM Mataspace(JVM 元空间):用于存放 class 文件中的类和方法等信息。
(2)JVM OverHead(JVM 执行开销):JVM 执行时自身所需要的内容,包括线程堆栈、IO、编译缓存等所使用的内存。
框架内存:框架内存即 TaskManager 本身占用的内存,包括 Framework Heap(框架堆上
内存)和 Framework Off-Heap(框架堆外内存),不计入 slot 资源。
网络内存:NetWork(网络内存)即网络数据交换所使用的堆外内存大小,如网络数据交换缓冲区。
托管内存:Managed Memory(托管内存)用于 Flink 中状态的缓存存储。
Task 内存:Task 内存分为 Task Heap(Task 堆上内存)和 Task Off-Heap(Task 堆外内存),这部分内存用于执行用户代码。
【Flink内存优化参数】
1.基础配置
# jobManager 的IP地址 jobmanager.rpc.address: localhost # JobManager 的端口号 jobmanager.rpc.port: 6123 # JobManager JVM heap 内存大小 jobmanager.heap.size: 1024m # TaskManager JVM heap 内存大小 taskmanager.heap.size: 1024m # 每个 TaskManager 提供的任务 slots 数量大小 taskmanager.numberOfTaskSlots: 1 # 程序默认并行计算的个数 parallelism.default: 1 # 文件系统来源 # fs.default-scheme
2. 高可用性配置
# 可以选择 'NONE' 或者 'zookeeper'. high-availability: zookeeper # 文件系统路径,让 Flink 在高可用性设置中持久保存元数据 high-availability.storageDir: hdfs:///flink/ha/ # zookeeper 集群中仲裁者的机器 ip 和 port 端口号 high-availability.zookeeper.quorum: localhost:2181 # 默认是 open,如果 zookeeper security 启用了该值会更改成 creator high-availability.zookeeper.client.acl: open
3.容错和检查点 配置
# 用于存储和检查点状态 state.backend: filesystem # 存储检查点的数据文件和元数据的默认目录 state.checkpoints.dir: hdfs://namenode-host:port/flink-checkpoints savepoints 的默认目标目录(可选) state.savepoints.dir: hdfs://namenode-host:port/flink-checkpoints # 用于启用/禁用增量 checkpoints 的标志 state.backend.incremental: false
4.web 前端配置
# 基于 Web 的运行时监视器侦听的地址. jobmanager.web.address: 0.0.0.0 # Web 的运行时监视器端口 rest.port: 8081 # 是否从基于 Web 的 jobmanager 启用作业提交 jobmanager.web.submit.enable: false
5.高级配置
# io.tmp.dirs: /tmp # 是否应在 TaskManager 启动时预先分配 TaskManager 管理的内存 taskmanager.memory.preallocate: false # 类加载解析顺序,是先检查用户代码 jar(“child-first”)还是应用程序类路径(“parent-first”)。 默认设置指示首先从用户代码 jar 加载类 classloader.resolve-order: child-first # 用于网络缓冲区的 JVM 内存的分数。 # 这决定了 TaskManager 可以同时拥有多少流数据交换通道以及通道缓冲的程度。 # 如果作业被拒绝或者您收到系统没有足够缓冲区的警告,请增加此值或下面的最小/最大值。 # 另请注意,“taskmanager.network.memory.min”和“taskmanager.network.memory.max” # 可能会覆盖此分数 taskmanager.network.memory.fraction: 0.1 taskmanager.network.memory.min: 67108864 taskmanager.network.memory.max: 1073741824
6.Flink 集群安全配置
# 指示是否从 Kerberos ticket 缓存中读取 security.kerberos.login.use-ticket-cache: true # 包含用户凭据的 Kerberos 密钥表文件的绝对路径 security.kerberos.login.keytab: /path/to/kerberos/keytab # 与 keytab 关联的 Kerberos 主体名称 security.kerberos.login.principal: flink-user # 以逗号分隔的登录上下文列表,用于提供 Kerberos 凭据(例如,`Client,KafkaClient`使用凭证进行 ZooKeeper 身份验证和 Kafka 身份验证) security.kerberos.login.contexts: Client,KafkaClient
【flink内存优化案例】
<优化前>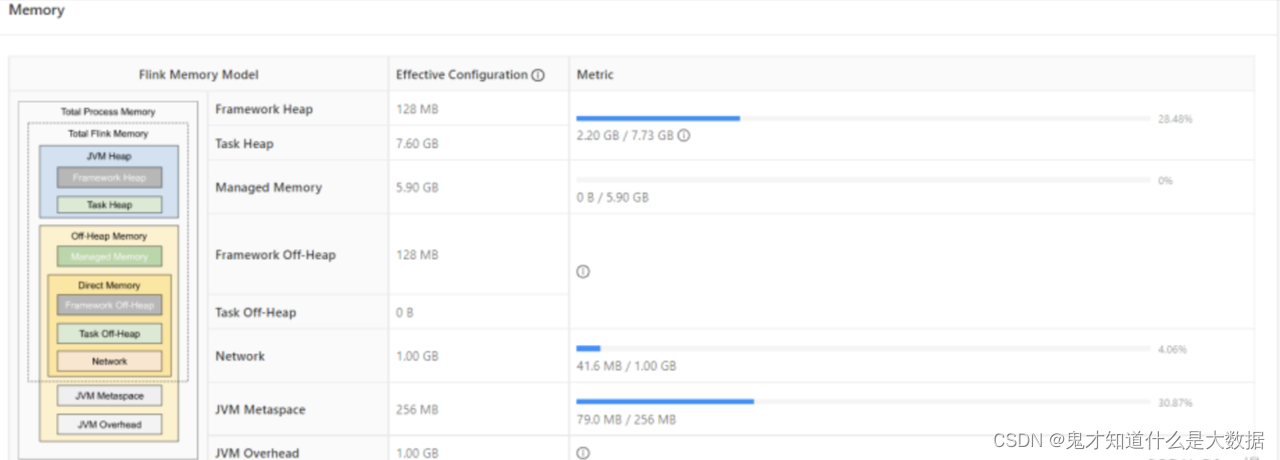
存在的问题: 1)进程总内存设置为 16g,但是 Task 所分得的堆内存只占 2 分之 1,容易造成频繁 GC,影响性能,甚至出现 OOM。 2)除了 Task 内存其他内存利用率不高,浪费资源,主要使用的就是 Task 内存资源。
<优化后>
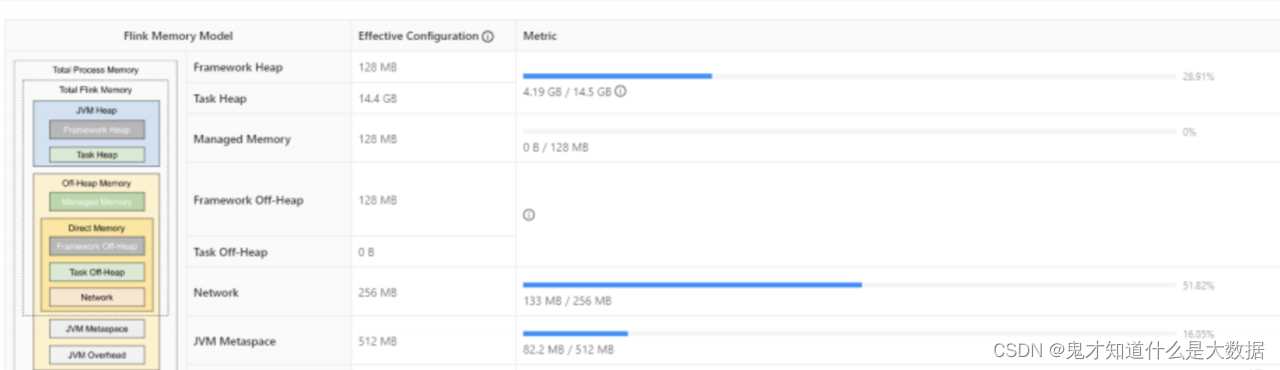
【flink压测方法】
资源推算公式如下:
-
作业所配置的CU数 = MAX(JM和TM的CPU总和, JM和TM的内存总和/4)。
-
每个作业所需IP数 = JM数(每个作业只有一个)+实际TM数。
-
实际TM数= MAX(⌈总CPU数/TM的CPU默认最大值⌉,⌈总内存数/TM的内存默认最大值⌉)。
-
总CPU数=设置的并发度/设置的每个TaskManager Slot数*设置的单个TM CPU。
-
总内存数=设置的并发度/设置的每个TaskManager Slot数*设置的单个TM的内存。
-
TM的CPU默认最大值为16 Core。
-
TM的内存默认最大值为64 GiB。
-
-
实际每个TM上可分配的slot数 = ⌈设置的并发数/实际TM数⌉。
例如,当并发度设置为80,每个TM Slot数设置为20,每个TM CPU设置为22 core,每个TM 内存设置为30 GiB时,配置如下图所示。

















 661
661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









