







1、准备三台虚拟机
node1 192.168.72.88
node2 192.168.72.89
node3 192.168.72.90
2、安装JDK
2.1 上传需要的压缩包文件

2.2 解压压缩包
# 把压缩包解压到上一级目录的soft目录下
tar -zxvf jdk-8u361-linux-x64.tar.gz -C ../soft/
# 给解压后的目录重新命名-方便
mv jdk1.8.0_361/ jdk18 # mv 命令指定目录为移动,不指定为更改名称
# 配置jdk环境变量使其在任意目录下都可以使用jdkhome/bin中的命令
vim ~/.bashrc
# 增加如下内容,(查看jdk所在路劲可以使用 pwd命令)
export JAVA_HOME=jdk所在目录
export PATH=$JAVA_HOME/bin:$PATH
# 修改文件后,生效配置文件
source ~/.bashrc
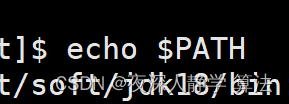
# 查看PATH变量是否具有jdk目录,也可直接输入java/javac等jdk中的命令验证
echo $PATH
3、解压安装hadoop-配置HDFS
3.1 解压hadoop配置环境变量
# 同样解压和配置环境变量
tar -zxvf hadoop-3.3.6.tar.gz -C ../soft/
mv hadoop-3.3.6/ hadoop336 # 需要进入到soft目录中,或者写全路劲
vim ~/.bashrc
# 添加如下内容
export HADOOP_HOME=hadoop所在目录
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
# 配置完成后需要使配置文件生效
source ~/.bashrc
echo $PATH # 查看path变量是否配置完成
3.2 编写配置文件
需要编写hadoop目录下的配置文件配置文件在hadoop安装目录下面的etc/hadoop/下
workers 配置datanode所在主机
hadoop-env.sh 配置hadoop的相关环境
core-site.xml hadoop的核心配置文件
hdfs-site.xml hdfs的核心配置文件
3.2.1 配置workers 文件
vim workers # 需要确保在hadoop安装目录下的etc/hadoop目录中
# 添加节点名称
node1 # 填写主机名需要再系统配置文件中/etc/hosts中配置ip映射
node2
node3
3.2.2 配置hadoop-env.sh
在配置文件中需要指定:
JAVA_HOME,
HADOOP_LOG_DIR,
HADOOP_CONF_DIR
vim hadoop-env.sh
export JAVA_HOME=jdk目录路劲
export HADOOP_LOG_DIR=hadoop日志存放路劲
export HADOOP_CONF_DIR=hadoop配置文件路劲hadoop安装目录下的etc/hadoop中
3.2.3 配置core-site.xml
<configuration>
<property>
<!--namenode所在节点,集群启动会读取该文件确定namenode节点位置-->
<name>fs.defaultFS </name>
<value>hdfs://node1:8020</value>
</property>
<property>
<!--表示io操作文件缓冲区大小-->
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!--hdfs副本的数量默认为3可以不用配置-->
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
3.2.4 配置hdfs-site.xml
<configuration>
<property>
<name>dfs.datanode.data.dir.perm </name><!--hdfs文件系统,默认创建的文件权限设置-->
<value>700</value><!--即(rwx)-->
</property>
<property>
<name>dfs.namenode.name.dir</name> <!--namenode元数据存储位置-->
<value> /home/kk/data/namenode </value> <!--在node1节点的目录下(不会自动创建需要创建目录)-->
</property>
<property>
<name>dfs.namenode.hosts</name> <!--namenode允许在那几个节点的datanode连接-->
<value>node1,node2,node3</value> <!--这三台服务器被授权-->
</property>
<property>
<name>dfs.blocksize</name> <!--hdfs默认块大小-->
<value>268435456</value> <!--268435456(256MB)-->
</property>
<property>
<name>dfs.namenode.handler.count</name> <!--namenode处理的并发线程数-->
<value>100</value> <!--以一百个并行度处理文件系统的管理事务(自定义)-->
</property>
<property>
<name>dfs.datanode.data.dir</name> <!--从节点datanode数据存储目录-->
<value> /home/kk/data/datanode </value> <!--datanode数据存放在node1,node2,node3,三台机器的目录内,目录需要自己创建-->
</property>
</configuration>
3.2.5 通过远程复制命令将hadoop jdk 分别赋值到node2和node3上
# 把环境变量配置文件复制到其他节点上,
# 复制需要注意当前所在路劲,和其他节点是否存在前置路劲,不存在需要创建
scp -r ~/.bashrc node2:~/.bashrc # 配置文件需要到节点中source让其生效
scp -r ~/.bashrc node3:~/.bashrc
scp -r jdk18 node2:`pwd`
scp -r jdk18 node3:`pwd`
scp -r hadoop336 node2:`pwd`
scp -r hadoop336 node2:`pwd`
3.2.6 格式化文件系统
hadoop namenode -format
格式化成功会出现namenode has been successfully formatted.字样
3.2.7 启动hdfs集群
# 启动或关闭hdfs集群
start-dfs.sh
stop-dfs.sh
# 查看系统中正在启动的java进程
jps
成功会出现namenode,datanode,secondarynamenode
3.2.8 web网页端口访问
在浏览器中打开namenode所在id: 192.168.72.88:9870
注意需要关闭防火墙: systemctl stop firewalld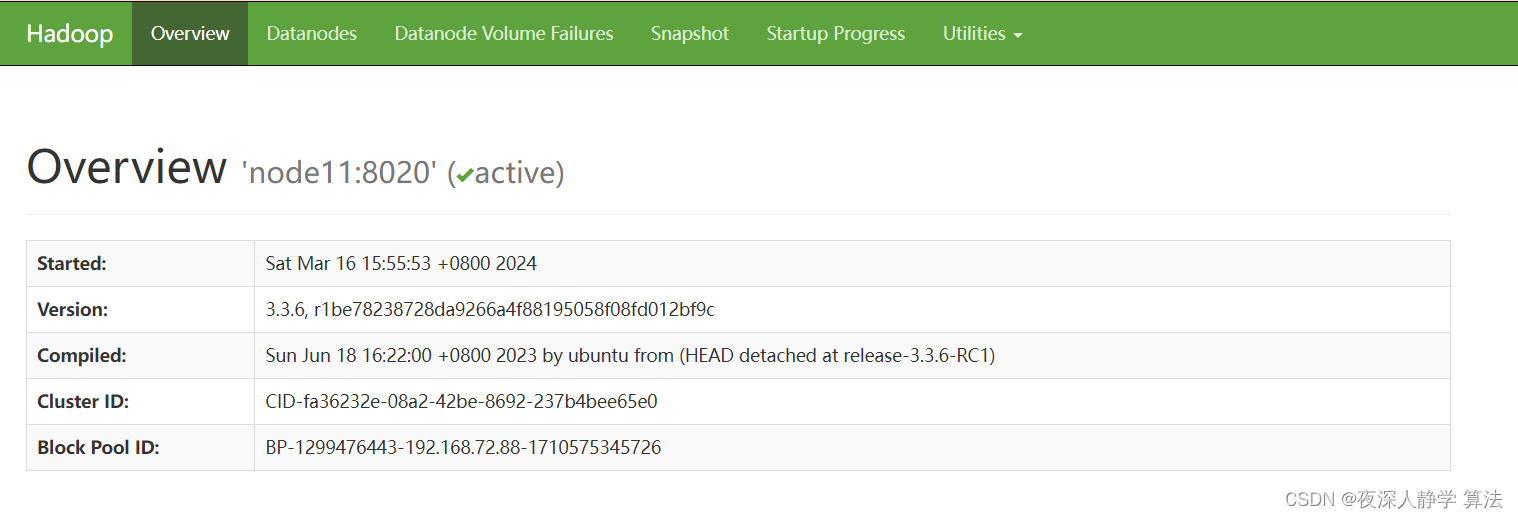
4、高可用集群搭建 - HA
4.1 安装zookeeper
将下载的zookeeper安装包上传到linux中

4.1.1 解压zookeeper
tar -zxvf apache-zookeeper-3.7.0-bin.tar.gz -C ../soft
# 进入到解压目录中,给目录重命名
mv apache-zookeeper-3.7.0-bin zookeeper370
4.1.2 配置环境变量
vim ~/.bashrc
# 添加如下内容
export ZOOKEEPER_HOME=zookeeper所在目录
export PATH=$ZOOKEEPER_HOME/bin:$PATH
4.1.3 配置zookeeper
复制安装目录下的conf目录下的zoo_sample.cfg文件为zoo.cfg
cp zoo_sample.cfg zoo.cfg
配置zoo.cfg文件
vim zoo.cfg
# 添加如下内容
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/kk/export/soft/zookeeper370/data
# 客户端连接端口
clientPort=2181
server.1=192.168.72.88:2888:3888
server.2=192.168.72.89:2888:3888
server.3=192.168.72.90:2888:3888
进入上面配置的dataDir选项的目录中创建myid文件,并配置编号
vim myid
# 把编号写入即可这里为 1


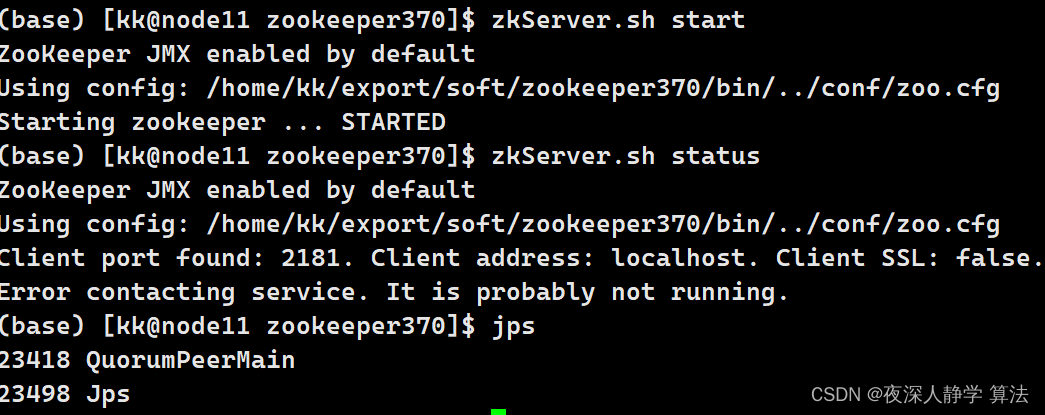
4.1.4 启动zookeeper查看服务
zkServer.sh start # 启动服务
zkServer.sh status # 查看服务
zkServer.sh stop # 关闭服务
jps # 查看进程
4.1.4 复制到node2和node3中
进入到安装目录中 - 这里为soft
rcp -r zookeeper370 node2:`pwd`
rcp -r zookeeper370 node3:`pwd`
到node2和node3中分别添加环境变量和修改zookeeper编号myid文件内分别为2和3
在node2和node3中分别测试:
zkServer.sh start
zkServer.sh status
4.1.5 编写shell文件一件启动所有服务和关闭所有服务
需要先实现ssh免密登录
创建一个shell目录 – 这里操作多在node1中,所以只在node1中创建
mkdir ~/shell
cd ~/shell
# 创建两个文件
touch start-zookeeper.sh
touch stop-zookeeper.sh
# 编写两个sh文件
vim start-zookeeper.sh
vim start-zookeeper.sh
内容分别为:
start-zookeeper.sh:
#zkStart.sh
#!/bin/bash
#启动
for host in node11 node22 node33
do
echo "===========$host start==============="
ssh $host 'source /home/kk/.bashrc; zkServer.sh start'
done
sleep 1s
#状态
for host in node11 node22 node33
do
echo "===========> $host status <==============="
ssh $host 'source zkServer.sh status'
done
stop-zookeeper.sh:
#!/bin/bash
for host in node11 node22 node33
do
echo "===========start zk cluster :$host start==============="
ssh $host 'source /home/kk/.bashrc; zkServer.sh stop'
done
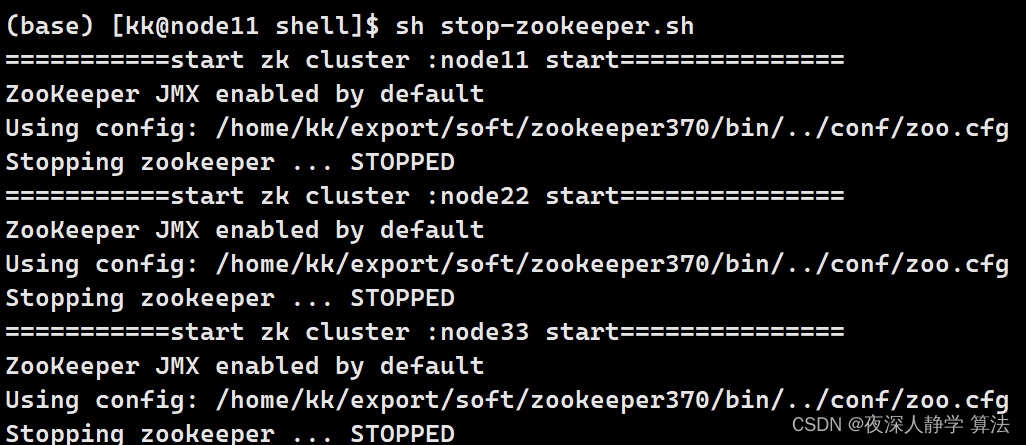
4.1.6 运行编写的shell文件
sh ./start-zookeeper.sh
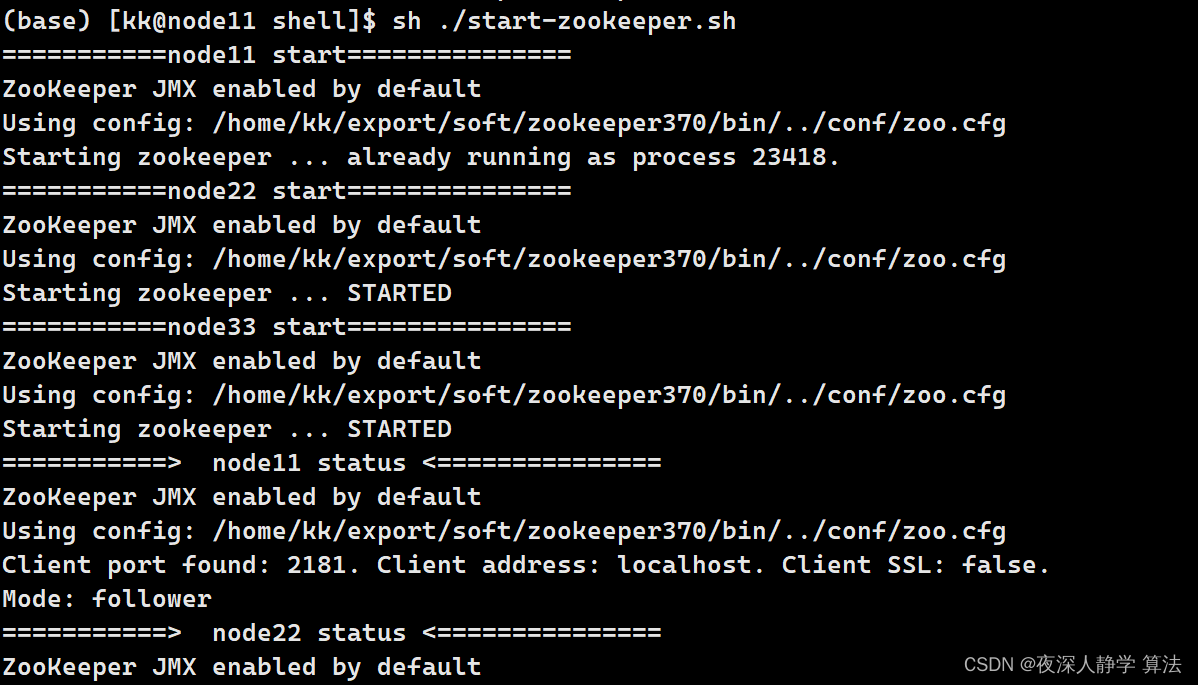
sh ./stop-zookeeper.sh
4.2 配置hdfs高可用
进入到hadoop配置文件中
4.2.1 在core-site.xml中新增
vim core-site.xml
# 新增如下配置
<!--指定zookeeper地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>node11:2181,node22:2181,node33:2181</value>
</property>
#修改内容
<!-- 高可用模式配置,这里的xjycluster为自定义名称,需要和hdfs-site.xml中配置的值保持一致-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://xjycluster</value>
</property>
4.2.2 在hdfs-site.xml中新增
vim hdfs-site.xml
# 新增如下
<!--指定namenode集群名称-->
<property>
<name>dfs.nameservices</name>
<value>xjycluster</value>
</property>
<!--确定那几台为namenode节点-->
<property>
<name>dfs.ha.namenodes.xjycluster</name>
<value>nn1,nn2</value>
</property>
<!--指定两个namenode节点的通信地址-->
<property>
<name>dfs.namenode.rpc-address.xjycluster.nn1</name>
<value>node11:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.xjycluster.nn2</name>
<value>node22:8020</value>
</property>
<!--配置namenode在web端浏览的地址-->
<property>
<name>dfs.namenode.http-address.xjycluster.nn1</name>
<value>node11:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.xjycluster.nn2</name>
<value>node22:9870</value>
</property>
<!--指定journalnode存储地址-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/kk/data/journalnode</value>
</property>
<!--指定namenode失败后自动切换的主类-->
<property>
<name>dfs.client.failover.proxy.provider.xjycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 指定namenode元数据在journalnode上的存放位置,journalnode用于同步主备namenode之间的edits文件 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node11:8485;node22:8485;node33:8485/xjycluster</value>
</property>
<!-- 启用namenode故障自动转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh秘钥登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/kk/.ssh/id_rsa</value>
</property>
4.2.3 在hadoop-env.sh中新增
vim hadoop-env.sh
# 新增如下内容,kk用户名
export HDFS_JOURNALNODE_USER=kk
export HDFS_ZKFC_USER=kk
4.2.4 分发配置
scp -r hadoop-env.sh hdfs-site.xml core-site.xml node22:`pwd`
scp -r hadoop-env.sh hdfs-site.xml core-site.xml node33:`pwd`
4.2.5 初始化启动
启动三台机器上的journalnode
hdfs --daemon start journalnode
# 这里使用远程命令,也可到每台机器上单独执行
ssh node22 hdfs --daemon start journalnode
ssh node33 hdfs --daemon start journalnode
# jps查看会出现journalnode进程
重新格式化namenode:
# 在node11上格式化namenode节点
hdfs namenode -format
# 格式化后启动namenode节点,在node22中同步执行namenode同步-一定需要先启动node11中的namenode否则无法与node11通讯
hdfs --daemon start namenode # 单独启动namenode节点命令
hdfs namenode -bootstrapStandby
# 同步之后停止node11上namenode
hdfs --daemon stop namenode
# 初始化在zookeeper中的状态
hdfs zkfc -formatZK
启动hdfs集群:
# 需要保证zookeeper集群启动
start-dfs.sh
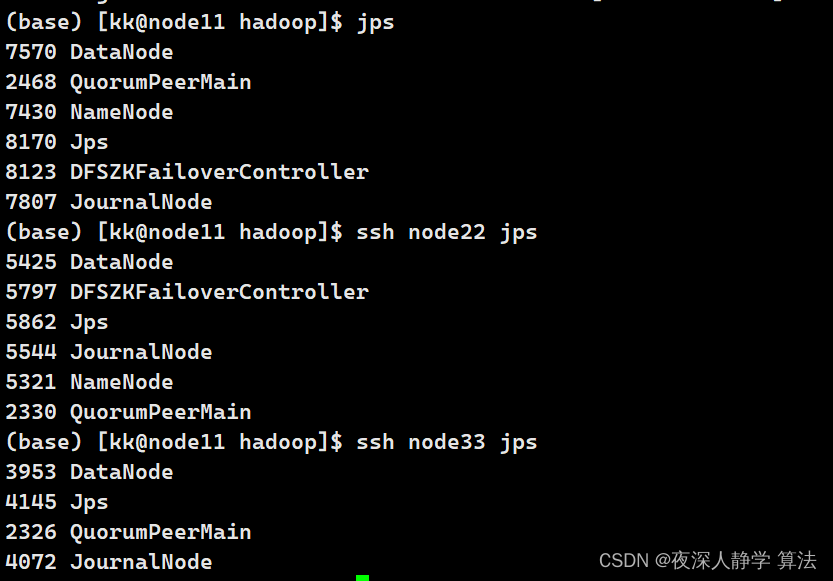
查看每个节点上的进程:
node11和node22中都有namenode节点
4.2.5 查看状态
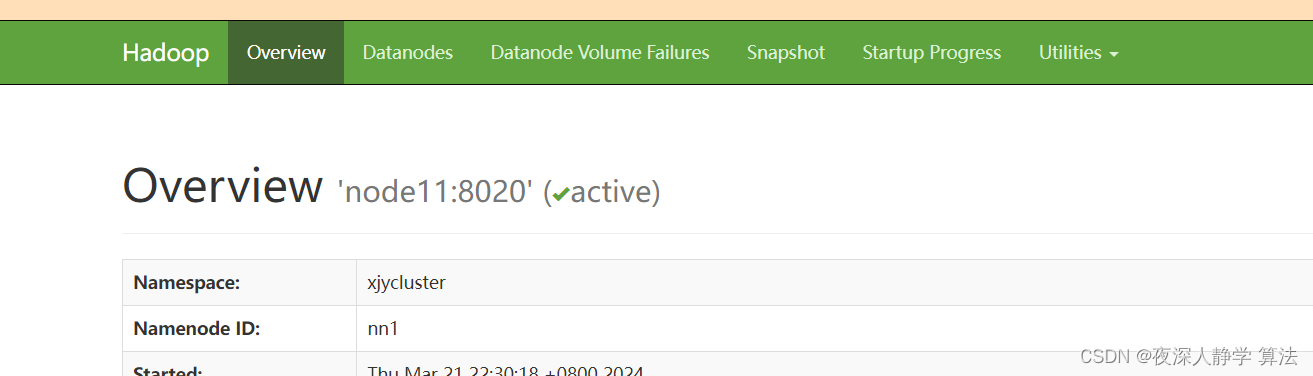
# 查看nn1是否为active
hdfs haadmin -getServiceState nn1
active在nn2(node22)上:

制造node22宕机:
# 杀死node22的namenode进程
skill 进程号

active已经自动转换到了nn1上:















 2265
2265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









