






相比国外大模型产品的认知度,国产大模型好像一直处在一片混沌中,相关的新闻也总是在“遥遥领先”和“洗洗睡吧”之间反复横跳。今天就借着题主的问题,聊聊我眼中的国产大模型,帮你看清那些“遥遥领先”者的真面目,以及现在市场上到底有哪些靠谱的产品。
没错,在243个国产大模型中,我还真找到了一两个能用的。
“百家争鸣”还是“人云亦云”?
据不完全统计,截止2024年1月,国内已有AI大模型243家
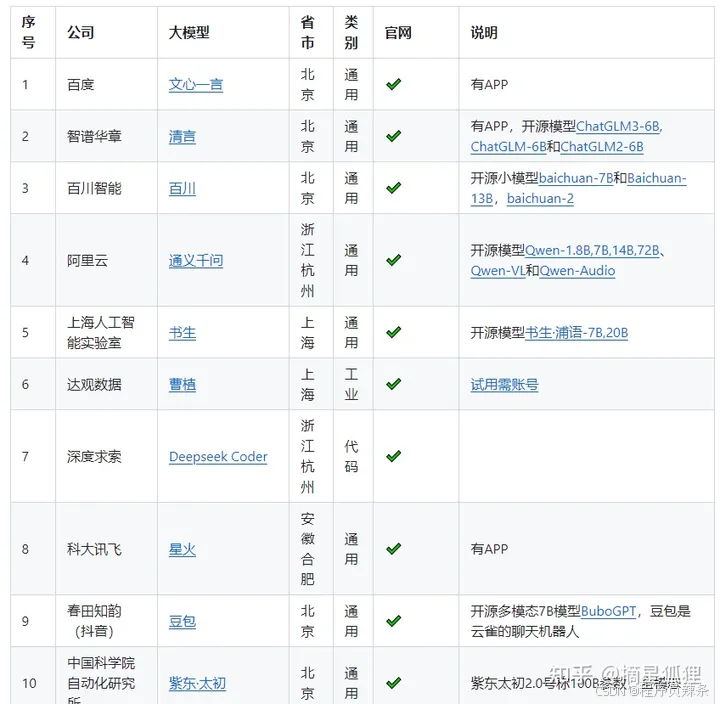 知名度较高且通过备案(面向大众开放)的大模型厂商主要有13家,
知名度较高且通过备案(面向大众开放)的大模型厂商主要有13家,
包括位于北京的百度(文心一言)、抖音(云雀)、百川智能(百川大模型)、智谱(智谱清言)、月之暗面(Kimi)以及中科院(紫东太初);位于上海的商汤(日日新大模型)、上海人工智能实验室(书生大模型)和MiniMax(ABAB大模型);位于广东的华为(盘古大模型),腾讯(混元大模型);以及安徽的科大讯飞(星火大模型),杭州的阿里(通义千问)。
这种热闹的氛围让我想起了团购网站刚刚开始流行的时候,互联网赢家通吃的现实催促着所有人全力冲刺。百团大战只是开始,战场上的硝烟还远未到散去的时候。远观总是差点意思,让我们把镜头拉近一些,看看这些战士的脸都是什么模样?

过拟合
国内很多公司开发的大模型都在拿GPT3.5或者4对标,宣称在某些方面“不落下风”,有的号称在参数更少的情况下性能相当,有的甚至宣称“全面领先”。这些模型是如何实现这些所谓的领先呢?
简而言之,这多半是过拟合现象导致的。所谓过拟合,是机器学习和统计建模中的一个常见问题,即在测试中表现出色,而在实际应用中却不尽如人意。

具体而言,除了那些宣传“与GPT-4并驾齐驱”的公司可能只是夸大其词外,其他国内大模型至少提供了一些实质性的证据。这些证据通常集中在当前中文大语言模型的三大主流测试集上,即C-Eval、MMLU和AGIEval,在这些测试集上它们均取得了优异的成绩。
这三个测试集分别代表了针对中文语言能力的综合评估、大规模多任务语言理解以及AI的类人能力测试。然而,这些实际上都是“开卷考试”。如果一个模型的开发者将这些测试集的表现作为主要目标,经过足够时间的训练,自然能在这些测试上取得好成绩。但与此同时,对于这些测试集之外的问题,其回答质量往往就不那么令人满意。
模型开发者自然希望全面评估模型性能,不希望出现“高分低能”的情况,但他们常常面临来自上级的指标压力,不得不针对测试成绩进行优化。这正是这些模型难以真正与GPT3.5或GPT4抗衡的原因。
过拟合问题在企业追求超越竞争对手的过程中尤为常见。例如,在自动驾驶技术尚未成熟时,某些公司就宣称能在复杂路况下实现完全自动驾驶,并通过录制特定路段的实测视频来展示其技术。
这种突然的技术飞跃是如何实现的呢?实际上,这往往是通过对特定路段进行反复训练,利用高精度地图详细标注各种环境因素,从而实现对该特定路段的完美驾驶。但这样的系统在陌生环境下的表现往往就不尽如人意。
国内大模型研究的先行者之一,智源研究院总工程师林咏华指出,目前确实缺乏公认的测评集,但现有的C-Eval、MMLU等测试集已经出现了被过度训练的现象。
因此,在评估大模型能力时,我们不应过分关注这些测试集的得分。实际上,过度拟合在生活中的例子比比皆是,如大学排名的刷分、自媒体的刷流量等。真正优秀的模型应当是在公开市场竞争中,人们愿意为其支付额外费用的模型。其他任何补充说明都是多余的。
如果你想了解如何打造这样的模型,知乎知学堂的AI解决方案课将是你的不二选择。
作为AI行业十年从业者,我深知技术和商业化的结合有多么重要。这门课程不仅让我掌握了大模型的核心技术,还通过真实的商业案例,让我看到了这些技术在实际应用中的巨大潜力。课程由业内大咖崔超亲自授课,内容深入浅出,即使没有编程基础,也能轻松理解复杂的算法原理和应用场景。最让我感到兴奋的是,课程还提供了大模型在金融、医疗等行业中的落地案例分析,让我在理论之外,更深入地理解了大模型的商业化路径。
从“能用”到“好用”
2023年9月,国产大模型终于甩掉“内测”的帽子,能够无障碍触及普通用户。
百度着力推广文心一言应用,鉴于百度在移动端的重头应用数量有限,将资源集中打造文心一言成为国内版的ChatGPT似乎是一条明智之路。相比之下,阿里巴巴采取了截然不同的策略,将大型模型作为中台支持,将通义千问整合进天猫、淘宝、钉钉、高德地图、天猫精灵等多个产品中,以发挥集团协同作战的优势。而用户基数庞大的腾讯则保持了一贯的低调风格,在微信平台上静悄悄地推出了“腾讯混元助手”小程序。
然而,不管各家的推广策略如何,国产大模型在吸引用户方面尚未达到预期效果。在苹果中国区应用商店的前100名排行榜上,尚未见到任何国产大模型产品的身影,而ChatGPT在苹果美国区商店的排名一直稳居前十。这一现象的根本原因在于技术水平上的差距。一旦对比过ChatGPT、Claude和国产大模型的使用体验,便能明显感受到国产模型在理解力、逻辑推理等方面的不足。
当用户对模型生成的一段看似流畅的文本不再感到新奇时,要想留住用户,大模型必须变得更加精准、实用、少犯错误。这一阶段的挑战比之前更为艰巨,只有当国产大模型跨越“能用”的门槛,达到“好用”的水平,其商业化潜力才真正值得探讨。
幸运的是,产品的成败并不局限于公司具备的大模型研发能力,产品设计、运营能力等因素也将成为重点。在当下的市场上,我们已经可以看到这样的产品开始涌现了。我试用了其中大部分,针对目前最常用的通用类、写作问答类以及设计类的产品,挑选了一些适合的推荐给大家。
通用类: 智谱AI
一家源自清华大学计算机系技术成果的公司。这家公司最优秀的地方是开源了两个重要的产品ChatGLM和CodeGeeX。其中ChatGLM-6B是其开源的单卡版本,含有62亿参数,可以在消费级显卡上运行,而CodeGeeX则是一个代码生成预训练模型,支持20多种编程语言,具备代码生成、续写、翻译、注释、bug修复等能力,且目前已经有针对各种IDE的插件,实测体感真的不输Copilot。

阅读理解类:kimichat
KimiChat 是由月之暗面科技有限公司(Moonshot AI)开发的人工智能助手,也属于清华系。这款产品最大的特点是允许用户上传TXT、PDF、Word文档、PPT幻灯片和Excel电子表格等格式的文件,或者是网址,它可以阅读这些文件或网址的内容并根据内容回答用户的问题。实测体感比较像ChatPDF和微软Copilot的集合体,但是它搜索中文内容的能力比Copilot要好,能提供最新的信息和数据来源。

网文阅读提炼
KimiChat应该是一个特化了长文本阅读能力的大模型,在实际体验中,我的感受是比Claude2 100K和GPT3.5要好用一些的,一次最多可以无损处理13-15万字(公开的是200K模型,最近又开放了2000K模型的内测),中文输出比Claude2略强。这就意味着已经达到了国际前列的水平。
设计类:Whee
Whee 是由美图公司开发的一款AI视觉创作工具,是国内最好的Midjourney平替。
支持文生图(Text-to-Image),图生图(Image-to-Image),AI修图功能,风格模型训练等功能,相比Midjourney,Whee对中文的理解更好,出图速度更快,极大的方便了国内的用户。

“你们赢了,但我却没有输”
随着大型模型的不断涌现,新技术所带来的神秘面纱逐渐揭开,ChatGPT也不再显得那么高不可攀。加之开源模型生态的蓬勃发展,爱好者仅需投入时间学习网络上的教程,便能模仿搭建出属于自己的“小模型”。大模型不是操作系统,也不会被垄断。未来的焦点不再是哪个大模型更强,而是谁更会用大模型,能把它跟自己的业务和场景结合得更好,训练得更有用。
与此同时,智能体开始成为焦点。字节跳动推出的豆包就是这样一个款产品。用户可以非常方便地定制自己的AI智能体,包括聊天机器人、写作助手以及英语学习助手等。

在这场围绕大模型以及人工智能的激烈比拼中,中国的AI产品一定会不断进化,而作为普通人的我们,也将借此机会成为可以与AI共舞的。
大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











