







Evaluate model
1 test set
- split the training set into training set and a test set
- the test set is used to evaluate the model
1. linear regression
compute test error
J t e s t ( w ⃗ , b ) = 1 2 m t e s t ∑ i = 1 m t e s t [ ( f ( x t e s t ( i ) ) − y t e s t ( i ) ) 2 ] J_{test}(\vec w, b) = \frac{1}{2m_{test}}\sum_{i=1}^{m_{test}} \left [ (f(x_{test}^{(i)}) - y_{test}^{(i)})^2 \right ] Jtest(w,b)=2mtest1i=1∑mtest[(f(xtest(i))−ytest(i))2]
2. classification regression
compute test error
J t e s t ( w ⃗ , b ) = − 1 m t e s t ∑ i = 1 m t e s t [ y t e s t ( i ) l o g ( f ( x t e s t ( i ) ) ) + ( 1 − y t e s t ( i ) ) l o g ( 1 − f ( x t e s t ( i ) ) ] J_{test}(\vec w, b) = -\frac{1}{m_{test}}\sum_{i=1}^{m_{test}} \left [ y_{test}^{(i)}log(f(x_{test}^{(i)})) + (1 - y_{test}^{(i)})log(1 - f(x_{test}^{(i)}) \right ] Jtest(w,b)=−mtest1i=1∑mtest[ytest(i)log(f(xtest(i)))+(1−ytest(i))log(1−f(xtest(i))]
2 cross-validation set
- split the training set into training set, cross-validation set and test set
- the cross-validation set is used to automatically choose the better model, and the test set is used to evaluate the model that chosed
3 bias and variance
- high bias: J t r a i n J_{train} Jtrain and J c v J_{cv} Jcv is both high
- high variance: J t r a i n J_{train} Jtrain is low, but J c v J_{cv} Jcv is high
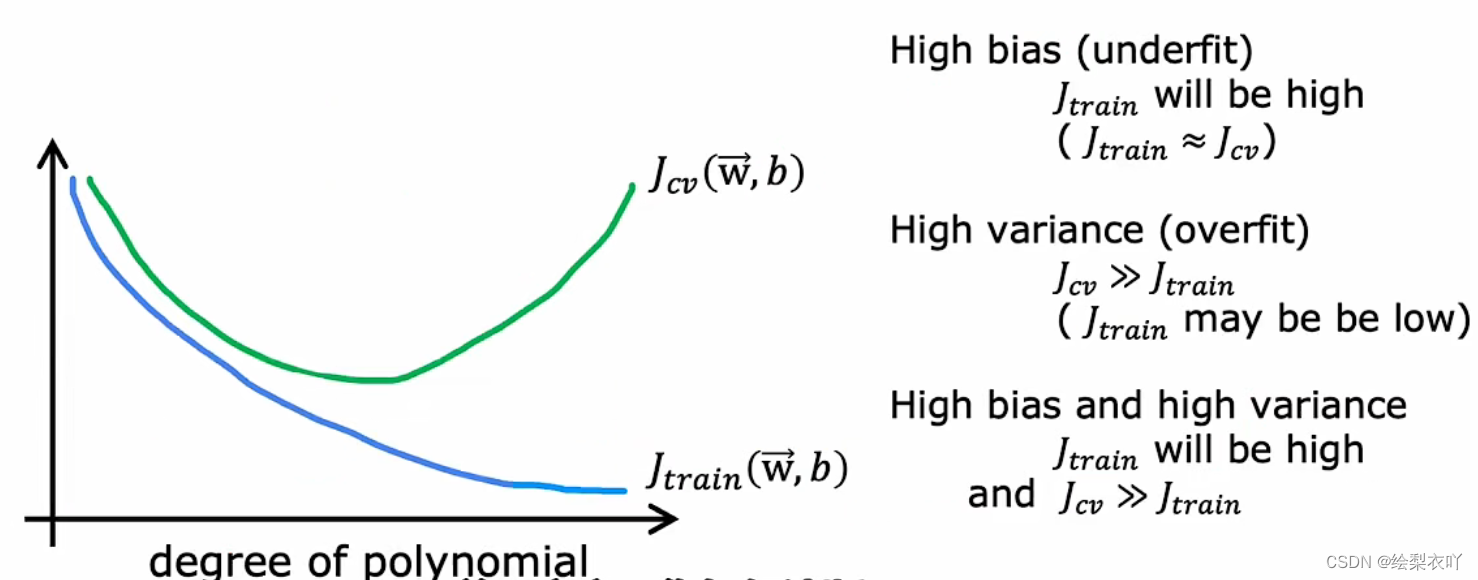
- if high bias: get more training set is helpless
- if high variance: get more training set is helpful
4 regularization
- if λ \lambda λ is too small, it will lead to overfitting(high variance)
- if λ \lambda λ is too large, it will lead to underfitting(high bias)
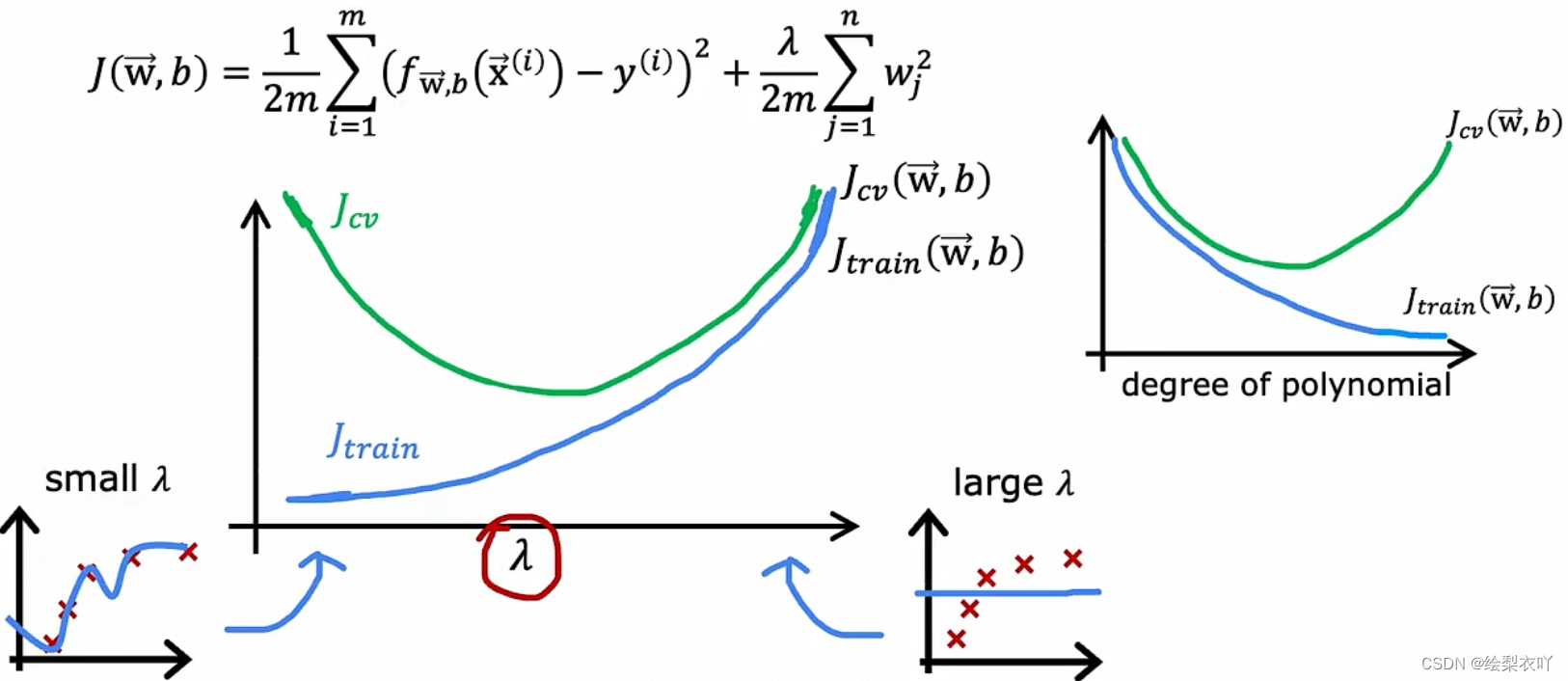
5 method
- fix high variance:
- get more training set
- try smaller set of features
- reduce some of the higher-order terms
- increase λ \lambda λ
- fix high bias:
- get more addtional features
- add polynomial features
- decrease λ \lambda λ
6 neural network and bias variance
- a bigger network means a more complex model, so it will solve the high bias
- more data is helpful to solve high variance
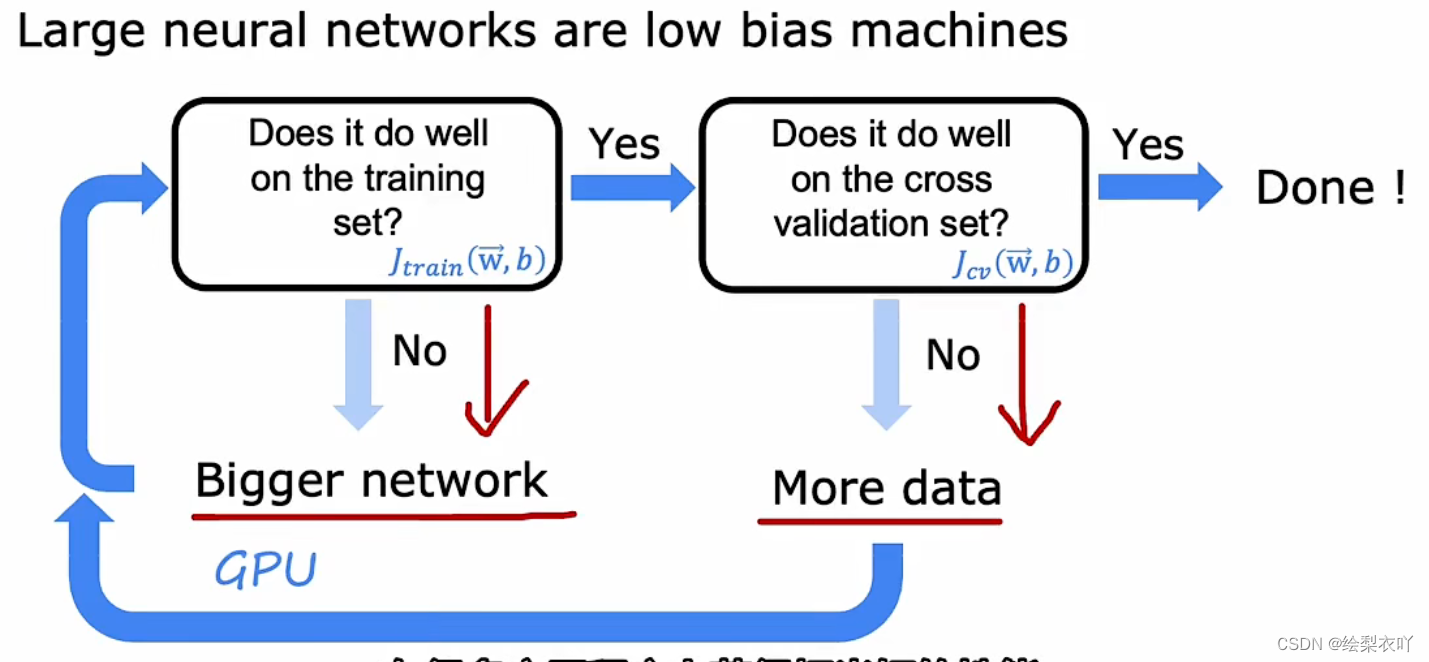
- it turns out that a bigger(may be overfitting) and well regularized neural network is better than a small neural network















 3338
3338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









