







- 如何利用你的垂域数据补充LLM的能力
- 如何构建你的垂域向量知识库
- 搭建一套完整的RAG系统需要哪些模块
2. 什么是检索增强的生成模型(RAG)
LLM固有的局限性
- LLM的只是可能不是实时的
- LLM可能不知道你私有的领域/业务知识
检索增强生成
RAG可以通过检索的方法来增强生成模型的能力。
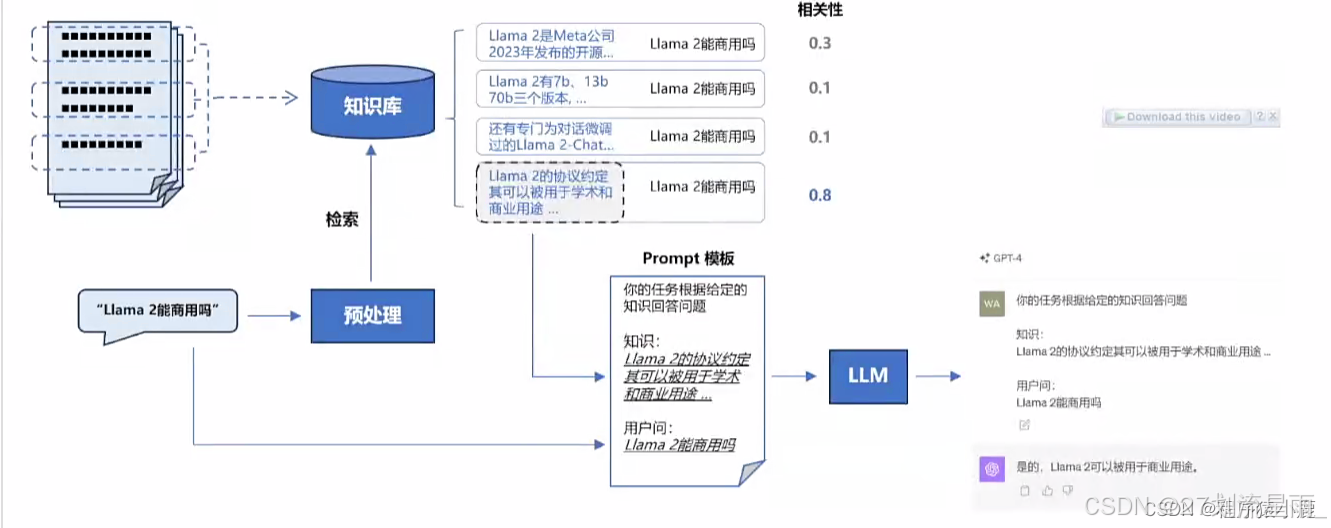
RAG的目标是通过知识库增强内容生成的质量,通常做法是将检索出来的文档作为提示词的上下文,一并提供给大模型让其生成更可靠的答案。更进一步地,RAG的整体链路还可以与提示词工程(Prompt Engineering)、模型微调(Fine Tuning)、知识图谱(Knowledge Graph)等技术结合,构成更广义的RAG问答链路。

3. RAG系统的基本搭建流程
搭建过程:
- 文档加载,并按一定条件
切割成片段 - 将切割的文本片段灌入
检索引擎 - 封装
检索接口 - 构建
调用流程:Query–> 检索 --> Prompt --> LLM --> 回复
文档的加载与切割
4. 向量检索
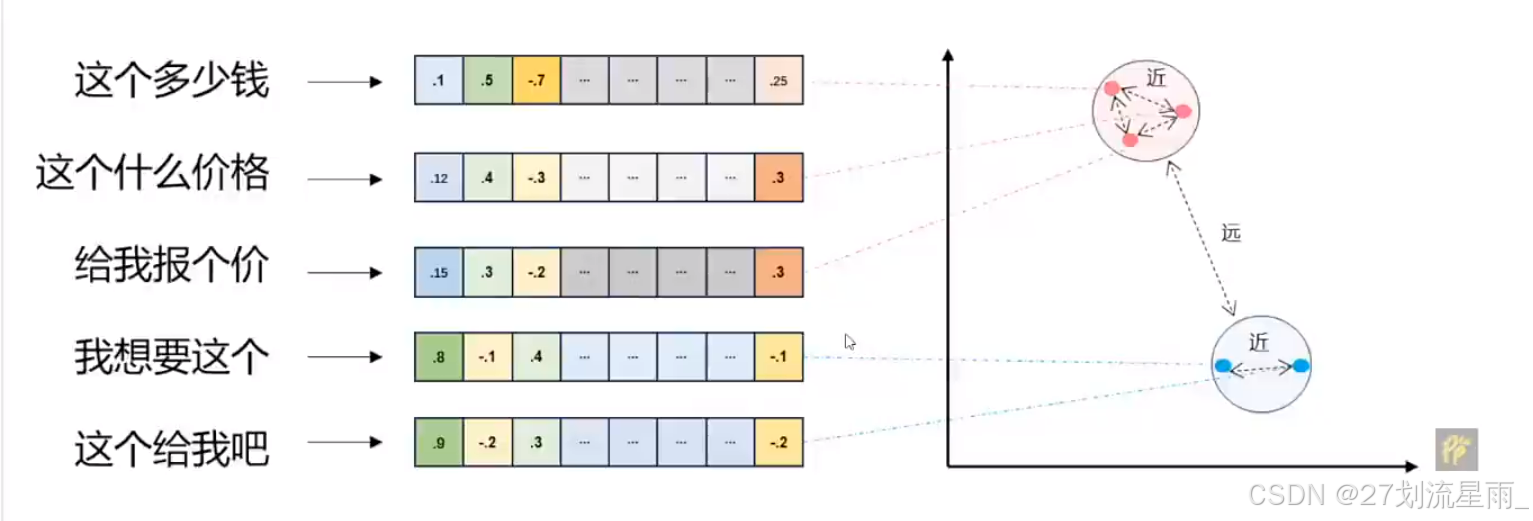
文本向量
- 将文本转换成一组浮点数:每个下标 i i i ,对应一个维度
- 整个数组对应一个n维空间的一个点,即
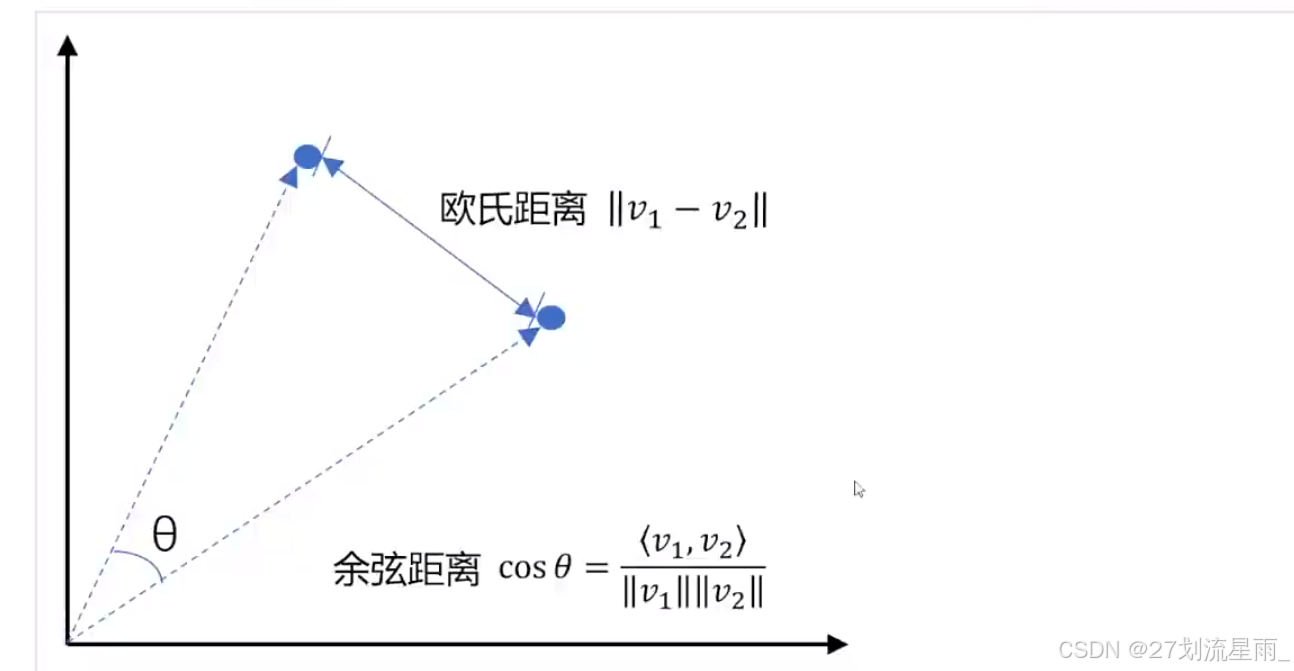
文本向量 - 向量之间可以计算距离,距离远近对应
语义相似度的大小
向量间的相似度计算
向量数据库
import numpy as np
from numpy import dot
from numpy.linalg import norm
# 余弦距离,越大越相似
def cosine_distance(x, y):
return dot(x, y) / (norm(x) * norm(y))
# 欧式距离,越小越相似
def euclidean_distance(x, y):
a = np.array(x) - np.array(y)
return norm(x)
import numpy as np
from numpy import dot
from numpy.linalg import norm
from sqlalchemy.orm.collections import collection
from pdfminer.high_level import extract_pages # 用于提取 PDF 文本
from pdfminer.layout import LTTextContainer # 1. 从 PDF 中提取文本 2. 提供了有关文本的布局和样式信息,包括字体大小、颜色、文本的起始和结束位置
# 余弦距离,越大越相似
def cosine_distance(x, y):
return dot(x, y) / (norm(x) * norm(y))
# 欧式距离,越小越相似
def euclidean_distance(x, y):
return norm(x - y)
def extract_text_from_pdf(filename, page_numbers=None, min_line_lenth=1):
''' 从 PDF 文件中提取文本 '''
pagegrams = []
buffer = ''
full_text = ''
# 提取全部文本
for i, page_layout in enumerate(extract_pages(filename)):
# 如果指定了 page_numbers,则只提取指定的页面
if page_numbers is not None and i not in page_numbers:
continue
for element in page_layout:
if isinstance(element, LTTextContainer):
full_text += element.get_text() + '\n'
# 按行分割文本, 并过滤掉长度小于 min_line_lenth 的行
lines = full_text.split('\n')
for text in lines:
if len(text) >= min_line_lenth:
buffer += (' '+text) if not text.endswith('-') else text.strip('-')
elif buffer:
pagegrams.append(buffer)
buffer = ''
if buffer:
pagegrams.append(buffer)
return pagegrams
from transformers import BertTokenizer, BertModel
import torch
# 初始化 BERT 模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 示例文本
text = "这是一个句子"
def get_embedding(text):
# 对文本进行编码
inputs = tokenizer(text, return_tensors='pt', padding=True, truncation=True) # pt 表示返回 pytorch tensor
# 获取模型输出
with torch.no_grad():
outputs = model(**inputs)
# 获取句子的向量表示
sentence_vector = outputs.last_hidden_state.mean(dim=1) # 对所有 token 进行平均
return sentence_vector
query = "国际争端"
documents = [
# 举出三个国际争端的例子,两个不相关的句子
"联合国苏丹达尔富尔地区打过莫暴力事件发出警告,要求所有人保持警惕,不要参与莫暴力活动。",
"土耳其总统埃尔多安宣布对叙利亚发动全面战争,并宣布与叙利亚建立外交关系",
"美国国务卿布林肯在白宫会见了特朗普总统,并宣布美国将与叙利亚建立外交关系",
"上海迪士尼乐园将于2月10日开幕,吸引了全球观众",
"苹果公司发布了全新的iPad Pro,售价为1249美元"
]
query_vec = get_embedding([query])[0]
doc_vec = get_embedding(documents)
print("cosine_distance:")
print(cosine_distance(query_vec, query_vec))
for vec in doc_vec:
print(cosine_distance(query_vec, vec))
print("euclidean_distance:")
print(euclidean_distance(query_vec, query_vec))
for vec in doc_vec:
print(euclidean_distance(query_vec, vec))
# 4.3 向量数据库
import chromadb
from chromadb.config import Settings
class MyVectorDBConnector:
def __init__(self, colleciton_name, embedding_fn):
chroma_client = chromadb.Client(Settings(allow_reset=True))
chroma_client.reset()
# 创建一个 collection
self.collection = chroma_client.get_or_create_collection(name=colleciton_name)
self.embedding_fn = embedding_fn
def add_document(self, documents):
# 向 collection 中插入一个 document
self.collection.add(
embeddings=self.embedding_fn(documents), # 计算 document 的 embedding
documents=documents, # 保存 document 原文
ids=[f"id{i}" for i in range(len(documents))] # 为 document 赋予 id
)
def search(self, query, top_n):
''' 检索向量数据库 '''
results = self.collection.query(
query_embeddings=self.embedding_fn([query]),
n_results=top_n
)
return results
# 创建一个向量数据库
vector_db = MyVectorDBConnector(colleciton_name="my_vector_db", embedding_fn=get_embedding)
# 向数据库中插入文档
paragraphs = extract_text_from_pdf("llama2.pdf", page_numbers=[0, 1, 2], min_line_lenth=10)
vector_db.add_document(paragraphs)
# 检索文档
user_query = "llama2 有多少参数?"
results = vector_db.search(user_query, top_n=3)
for para in results:
print(para + '\n')
向量数据库服务
server 端
chroma run --path /db_path
client 端
import chromadb
chroma_client = chromadb.HttpClient(host='localhost', poer=8000)
基于向量检索的RAG
# 4.4 基于向量检索的RAG
### 构建 Prompt
def build_prompt(prompt_template, **kwargs):
''' 将Prompt模版赋值 '''
prompt = prompt_template
for k, v in kwargs.items():
if isinstance(v, str):
val = v
elif isinstance(v, list) and all(isinstance(i, str) for i in v):
val = '\n'.join(v)
else:
val = str(v)
prompt = prompt.replace(f"__{k.upper()}__", val)
return prompt
prompt_template = """
你是一个问答机器人。
你的任务是根据下属给定的已知信息回答用户提出的问题。
确保你的回复完全依据下述已知信息,不要编造答案。
如果下述已知信息不足以回答用户的问题,请直接回复"我无法回答你的问题"
已知信息:
__INFO__
用户问:
__QUERY__
请用中文回答用户的问题。
"""
class RAG_Bot:
def __init__(self, vector_db, llm_api, n_results=2):
self.vector_db = vector_db
self.llm_api = llm_api
self.n_results = n_results
def chat(self, user_query):
# 1. 检索
search_results = self.vector_db.search(user_query, self.n_results)
# 2. 构建 Prompt
prompt = build_prompt(
prompt_template,
info=search_results['documents'][0],
query=user_query
)
# 3. 调用 LLM
response = self.llm_api(prompt)
return response
# 创建一个RAG机器人
bot = RAG_Bot(
vector_db=vector_db,
llm_api=get_completions
)
user_query = "llama2 有多少参数?"
response = bot.chat(user_query)
print(response)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









