






误差:预测输出结果与真实输出的结果之间的差异
经验误差、训练误差:在训练集上的误差
泛化误差:在新样本上的误差
泛化误差越小越好,经验误差不一定越小越好,可能导致过拟合
3种数据集之间的关系: 训练集相当于上课学知识;验证集相当于课后的的练习题,用来纠正和强化学到的知识;测试集相当于期末考试,用来最终评估学习效果
验证集:当我们的模型训练好之后,我们并不知道他的表现如何。这个时候就可以使用验证集 (Validation Dataset)来看看模型在新数据(验证集和测试集是不同的数据)上的表现如何。 同时通过调整超参数,让模型处于最好的状态。
验证集有2个主要的作用:1、评估模型效果,为了调整超参数而服务 2、调整超参数,使得模型在验证集上的效果最好(说明:验证集不像训练集和测试集,它是非必需的。如果不需要调整超参数,就可以不使用验证集, 直接用测试集来评估效果。验证集评估出来的效果并非模型的最终效果,主要是用来调整超参数的,模型最终效果以测 试集的评估结果为准。)
划分数据集:对于小规模样本集(几万量级),常用的划分比例:
训练集:验证集:测试集=6:2:2
训练集:测试集==8:2、7:3
对于大规模样本集(百万级以上),只要验证集和测试集的数量足够即可。
超参数越少,或者超参数很容易调整,那么可以减少验证集的比例,更多的分配给训练集。
过拟合:将训练样本自身的一些特点当作所 有样本潜在的泛化特点。
产生过拟合的原因:1、训练数据太少(比如只有几百组) 2、模型的复杂度太高(比如隐藏层层数设置的过多,神 经元的数量设置的过大) 3、数据不纯
防止过拟合通常可以采取的方法:1、 移除特征,降低模型的复杂度:减少神经元的个数, 减少隐藏层的层数 ◦ 2、训练集增加更多的数据 ◦ 3、重新清洗数据 ◦ 4、数据增强 ◦ 5、正则化 ◦ 6、早停
欠拟合:还没训练好。 发生欠拟合的原因:1. 数据未做归一化处理 2. 神经网络拟合能力不足 3. 数据的特征项不够 。 解决方法:1. 寻找最优的权重初始化方案 2. 增加网络层数、epoch 3. 使用适当的激活函数、优化器和学习率 4. 减少正则化参数 5. 增加特征
监督学习
监督学习分为两个为题:回归问题和分类问题 回归问题的输出是连续值分类问题的输出是离散值
监督学习—回归
均方误差损失函数(Mean Squared Error,MSE):最常用的回归问题的损失函数。其定义为预测值与真实值之间的平方差的平均值。(该损失函数的值越小,表示模型的预测结果越接近真实值。)
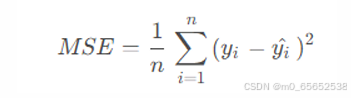
简单线性回归:自变量x 和因变量y之间存在一条线性关系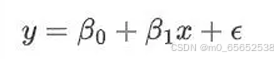
多元线性回归: 假设自变量和因变量y之间存在一条线性关系,即:![]()
监督学习—分类
想要预测(检测)的目标在数据集中为正样本 (Positive ),其他数据为负样本 (Negative )。
分类评估指标:
准确率(Accuracy):对于测试集中D个样本,有k个被正 确分类,D-k个被错误分类,则准确率为:
虽然准确率可以判断总的正确率,但是在样本不平衡的 情况下,并不能作为很好的指标来衡量结果。(如果样本不平衡,准确率就 会失效。)
精确率(查准率)-Precision:所有被预测为正样本中实际为 正样本的概率 精准率代表对正样本结果中的预测准确程度。 准确率则代表整体的预测准确程度,既包括正样本,也包括负样本。
精准率代表对正样本结果中的预测准确程度。 准确率则代表整体的预测准确程度,既包括正样本,也包括负样本。
召回率(查全率)-Recall:实际为正样本中被预测为正样 本的概率 召回率越高,也代表网络可以改进的空间越大。
召回率越高,也代表网络可以改进的空间越大。

















 2778
2778

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









