







什么是算法的复杂度
算法在编写成可执行程序后,运行起来要消耗时间资源和空间资源。因此衡量一个算法的好坏,一般是从时间和空间两个角度来衡量的,即时间复杂度和空间复杂度。
时间复杂度主要衡量一个算法运行的快慢,而空间复杂度主要衡量一个算法运行所需要的额外空间。值得一提的是,在计算机发展的早期,由于存储容量很小,所以对空间复杂度很看重。但是在如今的时代,计算机存储容量已经非常巨大,所以一般而言不会过多去关注空间复杂度。
时间复杂度
定义
算法的时间复杂度是一个函数,它定量描述该算法的运行时间。(这里的“函数”不是指的C语言中的函数,而是数学上的带有未知数的函数表达式)。格式为 O(n) ,被称作大O的渐进表示法。
但是,这里的运行时间并不是指一个程序跑了多少秒,程序运行的时间是没有一个方式去计算的。比如,一台搭载最新的芯片和拥有大内存的电脑,和数十年前的一台老版电脑,运行同样的一个算法,其运行时间肯定是不同的,那么同一个算法在不同的电脑上会跑出不同的时间,我们就不用具体时间来衡量时间复杂度。但是一个算法执行的时间是和算法的语句执行次数成正比例,算法中基本操作的执行次数,为算法的时间复杂度。
实例
我们来举一个例子,比如下方的 test() 函数,其中count++ 这个操作被执行的次数 F(N)=N,其时间复杂度就是O(N) ,这里的N就类似于数学的函数表达式里面的未知数,O( )是规定的写法:
void test(int N)
{
intcount=0;
for (int i=0;i<N;i++)
{
count++;
}
return;
}又比如下方函数 test1() 其基本语句count1++,count2++,M--,这些被执行次数 F(N)=N*N+2*N+10 ,如下方,对比假设了F(N)=N*N 时候的情况,发现当N越大的时候, F(N)=N*N+2*N+10 这个函数表达式的后两项对F(N)的值影响越小。我们算时间复杂度的时候,只需要计算大概执行次数就行,这时候利用估算——先算出精确的表达式,再找出对F(N)影响最大的,取最大的,在test1() 里面就是 F(N)=N*N,故 时间复杂度为O(N*N)。
N=10,F(N)=130; 当F(N)=N*N,N=10,F(N)=100
N=100,F(N)=10210; N=100,F(N)=10000
N=1000,F(N)=1002010; N=1000,F(N)=1000000
void test1(int N)
{
int count1=0;
int count2=0;
for (int i=0;i<N;i++)
{
for( int i=0;i<N;i++)
{
count1++;
}
}
for (int i=0;i<2*N;i++)
{
count2++;
}
int M=10;
while(M)
{
M--;
}
return;
}又比如下方的例子,count++这个基本语句被执行次数F(N)=5*N+10,然后找到对F(N)影响最大的,无疑是5*N,那么其时间复杂度就是O(5*N)了吗? 并不是,在这里有规定,计算时间复杂度时,如果有和最高阶项相乘的常数,那么要去掉这个常数,这里的5*N,5就是常数,所以时间复杂度为 O(N):
void test2(int N)
{
int count=0;
for (int i=0;i<5;i++)
{
for(int j=0;j<N;j++)
{
count++;
}
}
for(int i=0;i<10;i++)
{
count++;
}
return;
}上述例子都是有未知数的情况下,那么如果没有未知数呢,比如下方的例子,count++被执行了100次,但是时间复杂度却是O(1),这是因为,如果基本语句被执行次数是常数,那么时间复杂度统一写成O(1):
void test3()
{
int count=0;
for(int i=0;i<100;i++)
count++;
return;
}又比如下方例子,同时出现M、N两个未知数,其时间复杂度就是O(M+N)。但是如果给出限定条件比如M远大于N,此时时间复杂度就是O(M);如果N远大于M,那么就是O(N):
void test4(int M,int N)
{
couont=0;
for(int i=0;i<M;i++)
count++;
for (int i=0;i<N;i++)
count++;
return;
}通过以上几个例子,不难得出大O渐进表示法的规律:
1、用常数1取代运行时间中的所有加法常数。
2、在修改后的运行次数函数中,只保留最高阶项。
3、如果最高阶项存在且不是1,则取出与这个项相乘的常数,得到的结果就是大O阶。
二分查找的时间复杂度
二分查找的时间按复杂度是log2^N(2为底)的原因是(参考下图,黑色的为辅助理解还原折半过程的线),假设在长度为N(有N块空间)的内容里面查找a,现在已经找到a,逆向还原该查找过程,就是原本是一块a区间,第n次查找之前,是2块,第n-1次查找之前是4块,第n-2次查找之前是8块……
可以写成:
1*2*2*2*2*2……=N (假设查找了n次,即要还原n次)1*2^n=N
n=log2^N(2为底)
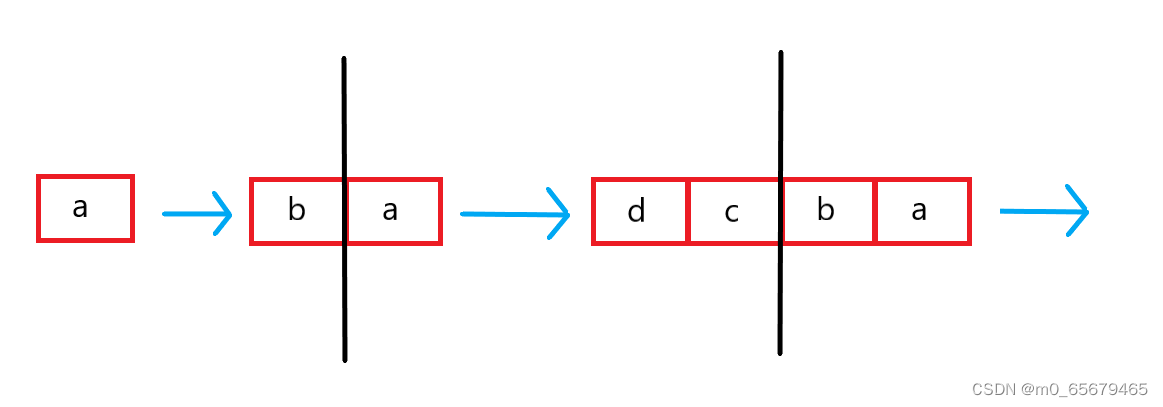
在这里就不免有人提出疑问,如果我要查找的那个数,恰好就在这块空间的中间呢,那么是不是一次就找到了;如果在1/4空间处,那么就找两次;1/8空间处,就要找三次……这些情况下的时间复杂度都是O(1),可是为什么二分算法的时间复杂度是O(log 2^N)呢?
这是因为,我们计算时间复杂度的时候,是按照最坏的情况计算的,即基本条件最多能被执行多少次。比如下方这段代码,假设src指向的字符串长度是N,则其时间复杂度是O(N):
假设src指向的字符串是“hello world”
target='h' 时, 最好情况
target='w'时, 平均情况
target=’d‘时, 最坏情况 ,此时的情况来计算时间复杂度
char* strchar(char* src,char taget)
{
while(*src)
{
if (*src == target)
return src;
else
++src;
}
}算法的空间复杂度
定义
算法的空间复杂度也是一个数学函数表达式,是对一个算法运行过程中临时额外占用空间大小的量度。
空间复杂度不是指程序占用了多少byte的空间,因为这个也没有太大意义,空间复杂度算的是变量个数,其方法也是大O渐进法。
注:程序运行时,所需要的栈空间(局部变量、存储参数、一些寄存器信息等等)在编译期间已经确定好了,因此空间复杂度主要通过函数运行时显示申请的额外空间来确定。
实例
冒泡排序的空间复杂度
比如下方的BubbleSort()函数,它的空间复杂度是O(1),其过程是这样的:
首先,这个函数已经确定好的变量是int* a,int n,这两个不是额外申请的空间,是已经确定的。
其次,寻找出额外开辟的空间。在嵌套的循环里面,分别开辟了i、j两个变量,假设n=10,代入去看,i=0的时候,内层循环 j<9,执行九次内层循环,在这一轮循环里面,为了存储 i 开辟的空间一直不变,存储 j 开辟的空间还是那个空间,只是里面的值改变。但是,在这一轮循环执行完之后,为了存储 j 开辟的空间就会被销毁。
当 i=1时,为了存储 i 开辟的空间依然是那个空间,上一轮循环中的 为了存储 j 开辟的空间 已然被销毁,这时内层循环又有一个变量 j ,又需要开辟一个空间来存储 这一轮的 j ,根据函数栈帧的知识,不难明白,此时开辟的空间和上一轮被销毁的空间是同一块空间,所以并没有额外申请空间,循环结束也只是申请了两个空间来存储 i 和 j。
由于2是常数,所以其空间复杂度是O(1)。
void BubbleSort(int* a,int n)
{
assert(a);
for (int i=0;i<n-1;i++)
{
for (int j=0;j<n-i-1;j++)
{
if (a[j] > a[j+1])
swap(&a[j],&a[j+1]);
}
}
return 0;
}斐波那契数列的空间复杂度
如下,输入N,返回前N个斐波那契数列的函数,其空间复杂度为O(N)。
首先,N是已经确定好的变量,不会额外申请空间。
其次,arr开辟了N+1个存储int类型数据的空间,然后i又开辟了1个存储int类型数据的空间,所以一共开辟了N+2个额外的,存储int类型数据的空间。
最后,和上面时间复杂度的规则类似,去掉常数,其空间复杂度为O(N)。
int * fib(int N)
{
int *arr=(int*)malloc((N+1)*sizeof(int));
arr[0]=1;
arr[1]=1;
for (int i=2;i<=n;i++)
{
arr[i]=arr[i-1]+arr[i-2];
}
return arr;
}关于算法的时间复杂度和空间复杂度就介绍到这里啦!!喜欢的话不要忘记一键三连哦!!!
















 141
141











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











