






今天主要是给大家详细的讲解Map集合,大家对于集合感兴趣的话,可以再去看下前面两篇文章,详细的给大家讲解了list和set集合。
目录
一.Map集合
HashMap集合,HashTable集合,ConcurrentHashMap集合,TreeMap集合,LinkedHashMap都是继承了Map集合,下面详细的为大家依次介绍这些集合。
- Map集合是无序的。
- Map是一种依照键(key)存储元素的容器,键(key)很像下标,在List中下标是整数。在Map中键(key)可以使任意类型的对象。Map中不能有重复的键(Key),每个键(key)都有一个对应的值(value)。如果键重复的话,那么会被覆盖。
- 没有继承接口collection接口,只有list集合和set集合继承了collection接口。
- 扩容:初始容量16,负载因子0.75,扩容增量1倍。
- Map增加元素不是使用add增加的,而是使用put增加元素。
- 遍历:Map集合没有直接取出元素的方法,而是先转成Set集合,在通过迭代获取元素。
二.Map集合常用方法
1.添加
- put(key,value)(输入的值可以为相同的key,但是如果出现相同的key,新增加的会将原本的给覆盖,返回的值为前一个,如果没有就返回null)
2.删除
- remove()根据键删除里面的元素
- clear() 清空集合中的所有元素
3.获取
- get(key)根据键获取到值
- keySet()先获取所有的key集合,当需要查询value的时候,我们通过key来查询。
- entrySet()是将key和value的键值对全取出来,只查询一次。
等会在代码中为大家详细的讲解如何使用。
4.判断
- boolean isEmpty() 长度为0返回true否则false
- boolean containsKey(Object key) 判断集合中是否包含指定的key
- boolean containsValue(Object value) 判断集合中是否包含指定的value
注:继承Map集合的集合都是具备Map集合的方法
三.HashMap集合
- HashMap线程不安全,但是速度快,最常用的一个集合
- 它是内部是采用数组存放数据
1.HashMap数据结构
jdk1.8之前:数组+链表
jdk1.8之后:采用数组+链表+红黑树,当链表长度大于8时,链表结构转换为红黑树结构。
2.为什么使用红黑树?
为什么在jdk1.8会添加红黑树嘞,主要是因为链表插入虽然快,查找慢,如果说该链表非常的长,而我们需要找的数据在最后,那么查询就会非常的慢,而红黑树能够使查询更加的快,它采用了将值放在左旋右旋,加快查找速度。
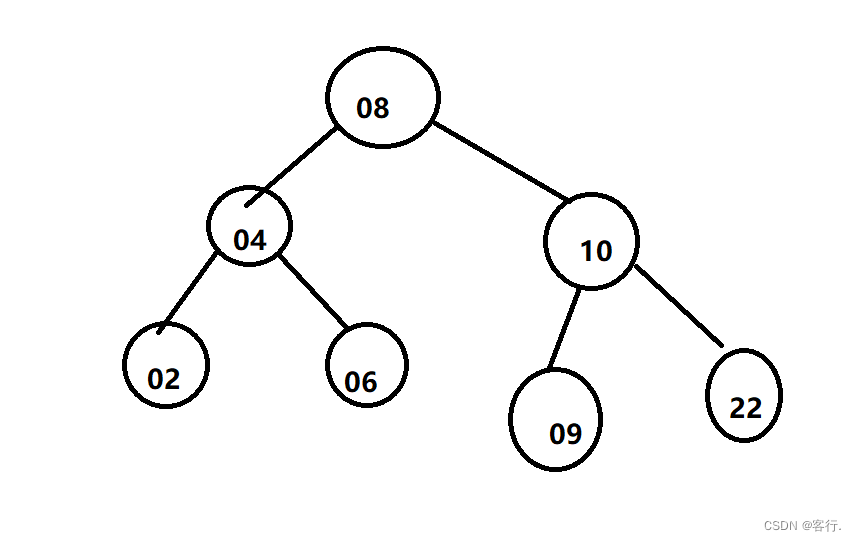
3.什么是红黑树?
红黑树是一种特化的AVL树(平衡二叉树),都是在进行插入和删除操作时通过特定操作保持二叉查找树的平衡,从而获得较高的查找性能。
大家看下下面这幅图
4.HashMap的put执行过程
我们在使用put方法的时候会传进key和value参数
在我们将这两个参数传入后,
- 第一步,我们的put方法会去判断这个hashmap是否为null 或者长度是否为0,如果是则对hashmap数组进行resize()扩容,
- 第二步,put方法会根据这个key计算hash码来得到数组的位置,(这里需要解释一下,我们的hashmap默认是由一个数组加链表组成的),得到位置后当然是继续判断这个数组下标的值是否为null,为null 自然是直接插入我们的value值,如果不为空的话进行第三步
- 第三步,判断key是否为null,当key!=null我们就可以覆盖value值,key==null继续
- 第四步,如果key值也为空,则判断结点类型是链表还是红黑树
- 第五步,如果节点类型为红黑树,则执行红黑树插入操作
如果节点类型为链表,那么put方法就会遍历这个链表,for循环遍历链表直至链表尾部,然后进行尾插,当链表长度>=8时,会进入链表转红黑树的方法,treeifyBin方法中还会判断数组长度,数组长度>=64,链表长度>=8同时满足,才会将链表转为红黑树;在for循环遍历过程中,如果key相同,则直接插入元素
- 第五步,记录操作次数变量modCount+1,最后再判断当前map中有多少元素,和阈值做对比,如果超过阈值则进行扩容当数组容量超过最大容量时就会扩容一倍(即二进制的进位),没有则返回null
图片:来自网络 
5.代码实操
- 使用put方法往集合中增加数据
package com.yjx.test;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import org.junit.Before;
import org.junit.Test;
public class MapDeome {
//定义键和值为什么类型,键可以是任意类型。
private Map<Integer, String> map=new HashMap<Integer, String>();
map.put(1, "张一");
map.put(2, "张二");
map.put(3, "张三");
map.put(4, "张四");
}
- 使用map.entrySet()获取数据
@Test
public void test01() {
//迭代器
Iterator<Entry<Integer,String>> it=map.entrySet().iterator();
//通过迭代器遍历元素
while(it.hasNext()) {
Entry<Integer, String> key=it.next();
System.out.println("key:"+key.getKey()+"value:"+key.getValue()+"-----");
}
}- 使用map.keySet()获取数据
@Test
public void test02() {
Iterator<Integer> it=map.keySet().iterator();
while(it.hasNext()) {
int key=it.next();
System.out.println(map.get(key));
}
}四.HashTable集合
该集合线程安全,但是性能太慢。
为什么性能慢?
在线程运行时,他会上一把锁,全部锁上,只允许一个线程进入,当该线程执行完以后,才会到下一个线程进入,所以性能太慢了。
代码如下:
我是使用Junit,直接在方法上加上Test就不需要再写一个main方法执行,但是你们如果没有使用这个,就在mian方法中执行就好。
package com.yjx.test;
import java.util.Hashtable;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import org.junit.Before;
import org.junit.Test;
public class HashTableDeom {
private Map<Integer, String> map=new Hashtable<Integer, String>();
@Before
public void put() {
map.put(1, "张一");
map.put(2, "张二");
map.put(3, "张三");
map.put(4, "张四");
}
@Test
public void test() {
Iterator<Entry<Integer, String>> it=map.entrySet().iterator();
while(it.hasNext()) {
Entry<Integer, String> obj=it.next();
System.out.println("key:"+obj.getKey()+"value:"+obj.getValue());
}
}
}
五.ConcurrentHashMap集合
线程安全,比HashTable性能更好。
为什么比HashTable更好?
因为HashTable锁是直接全锁上了,但是ConcurrentHashMap集合是一个数组一把锁,所以性能比HashTable好。
代码实操:
-
package com.yjx.test; import java.util.Iterator; import java.util.Map; import java.util.Map.Entry; import java.util.concurrent.ConcurrentHashMap; import org.junit.Before; import org.junit.Test; public class ConcurrentHashMapDeom { private Map<Integer, String> map=new ConcurrentHashMap<Integer, String>(); @Before public void put() { map.put(1, "张一"); map.put(2, "张二"); map.put(3, "张三"); map.put(4, "张四"); } @Test public void test01() { Iterator<Entry<Integer, String>> it= map.entrySet().iterator(); while(it.hasNext()) { Entry<Integer, String> obj=it.next(); System.out.println("key:"+obj.getKey()+"value:"+obj.getValue()); } } }
六.TreeMap集合
- key值按一定的顺序排序,基于红黑树,容量无限制,非线程安全,比较常用
- 添加或获取元素时性能较HashMap慢(因为需求维护内部的红黑树,用于保证key值的顺序)
- 能比较元素的大小,根据key比较(元素的自然顺序,集合中自定义的比较器也可排序)
代码实操
private TreeMap<String,Student> treeMap;
@Before
public void setup() {
treeMap = new TreeMap<String,Student>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
// 负数 0 正数
return o1.compareTo(o2);
}
});
treeMap.put("1", new Student(5, "小白"));
treeMap.put("2", new Student(3, "小黑"));
treeMap.put("3", new Student(2, "小黄"));
treeMap.put("4", new Student(4, "小明"));
treeMap.put("3", new Student(1, "小黑"));
treeMap.put("4", new Student(4, "小明"));
七.LinkedHashMap集合
- 继承HashMap
- 维护了一个双向链表
- LinkedHashMap是有序的,且默认为插入顺序
- 默认情况下使用entryset获取的集合顺序是与节点的插入顺序(默认是按照插入的顺序进行排列的,最先插入的节点(即最老的节点)为head,最新插入的节点为tail)
代码如下
Map<String, String> linkedHashMap = new LinkedHashMap<>();
@Test
public void linkedHashMap() {
linkedHashMap.put("5", "嘿嘿");
linkedHashMap.put("4", "喜喜");
linkedHashMap.put("1", "哈哈");
linkedHashMap.put("3", "呵呵");
linkedHashMap.put("3", "嗨嗨");
linkedHashMap.put("4", "喜喜");
linkedHashMap.put("1", "哈哈");
Set<Entry<String, String>> set = linkedHashMap.entrySet();
Iterator<Entry<String, String>> iterator = set.iterator();
while(iterator.hasNext()) {
Entry entry = iterator.next();
String key = (String) entry.getKey();
String value = (String) entry.getValue();
System.out.println("key:" + key + ",value:" + value);
}
集合的讲解就到这里啦,对集合感兴趣的,可以再去看下前面两篇list和set集合。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









