







深度学习---机器翻译(Transformer)

目录
3.2 Sequence-to-sequence Transformer架构
一、机器翻译(MT)
机器翻译(machine translation)指的是 将序列从一种语言自动翻译成另一种语言。 事实上,这个研究领域可以追溯到数字计算机发明后不久的20世纪40年代, 特别是在第二次世界大战中使用计算机破解语言编码。 几十年来,在使用神经网络进行端到端学习的兴起之前, 统计学方法在这一领域一直占据主导地位 (Brown et al., 1990, Brown et al., 1988)。 因为统计机器翻译(statistical machine translation)涉及了 翻译模型和语言模型等组成部分的统计分析, 因此基于神经网络的方法通常被称为 神经机器翻译(neural machine translation), 用于将两种翻译模型区分开来。
机器翻译作为自然语言处理(NLP)领域的重要分支,已经有数十年的发展历史。从最早的基于规则的方法,到后来统计机器翻译(Statistical Machine Translation,SMT)的出现,再到如今深度学习方法的应用,机器翻译技术不断进步。然而,传统方法在处理长句子或上下文依赖问题时常常表现不佳。
二、Transformer
2.1 背景
Transformer 架构的诞生源于自然语言处理(NLP)领域的迫切需求。在过去,传统的循环神经网络(RNN)和卷积神经网络(CNN)在处理序列数据时面临一些挑战。RNN 虽然能够捕捉序列中的依赖关系,但由于其顺序处理的方式,导致计算效率低下,并且难以处理长距离依赖。而 CNN 虽然可以并行计算,但在处理变长序列时不够灵活。
为了克服这些挑战,2017 年,谷歌的 8 名研究人员联合发表了名为《Attention Is All You Need》的论文,并在这篇论文中提出了 Transformer 架构。该架构采用了自注意力机制,使得模型能够同时关注序列中的所有位置,从而捕捉长距离依赖关系。此外,Transformer 还采用了多头注意力和位置编码等技术,进一步提高了模型的性能。
Transformer 架构的出现,为自然语言处理领域带来了革命性的突破。它不仅提高了模型的性能和效率,还为后续的研究和发展奠定了基础。目前,Transformer 架构已经成为了自然语言处理领域的主流架构之一,并在机器翻译、文本生成、问答系统等任务中取得了显著的成果。
2.2 基本原理
当前主流的大语言模型都基于 Transformer 模型进行设计的。Transformer 是由多层的多头自注意力(Multi-head Self-attention)模块堆叠而成的神经网络模型。原始的 Transformer 模型由编码器和解码器两个部分构成,而这两个部分实际上可以独立使用,例如基于编码器架构的 BERT模型和解码器架构的 GPT 模型。与 BERT 等早期的预训练语言模型相比,大语言模型的特点是使用了更长的向量维度、更深的层数,进而包含了更大规模的模型参数,并主要使用解码器架构,对于 Transformer 本身的结构与配置改变并不大。
2.2.1 Transformer整体结构
Transformer作为编码器-解码器架构的一个实例,其整体架构图在图中展示。正如所见到的,Transformer是由编码器和解码器组成的。Transformer的编码器和解码器是基于自注意力的模块叠加而成的,源(输入)序列和目标(输出)序列的嵌入(embedding)表示将加上位置编码(positional encoding),再分别输入到编码器和解码器中。
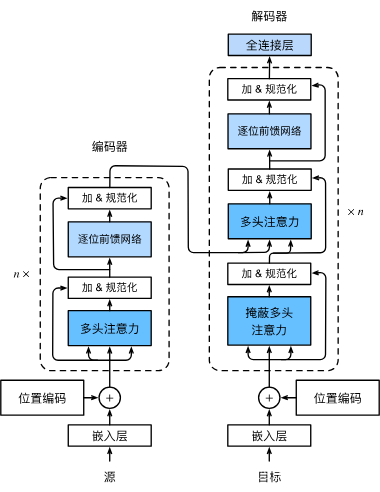
图2.1.1.1 Transformer架构 (a)
图中概述了Transformer的架构。从宏观角度来看,Transformer的编码器是由多个相同的层叠加而成的,每个层都有两个子层(子层表示为sublayer)。第一个子层是多头自注意力(multi-head self-attention)汇聚;第二个子层是基于位置的前馈网络(positionwise feed-forward network)。具体来说,在计算编码器的自注意力时,查询、键和值都来自前一个编码器层的输出。受残差网络的启发,每个子层都采用了残差连接(residual connection)。在Transformer中,对于序列中任何位置的任何输入𝑥∈𝑅𝑑,都要求满足sublayer(𝑥)∈𝑅𝑑,以便残差连接满足𝑥+sublayer(𝑥)∈𝑅𝑑。在残差连接的加法计算之后,紧接着应用层规范化(layer normalization)。因此,输入序列对应的每个位置,Transformer编码器都将输出一个𝑑维表示向量。
Transformer解码器也是由多个相同的层叠加而成的,并且层中使用了残差连接和层规范化。除了编码器中描述的两个子层之外,解码器还在这两个子层之间插入了第三个子层,称为编码器-解码器注意力(encoder-decoder attention)层。在编码器-解码器注意力中,查询来自前一个解码器层的输出,而键和值来自整个编码器的输出。在解码器自注意力中,查询、键和值都来自上一个解码器层的输出。但是,解码器中的每个位置只能考虑该位置之前的所有位置。这种掩蔽(masked)注意力保留了自回归(auto-regressive)属性,确保预测仅依赖于已生成的输出词元。
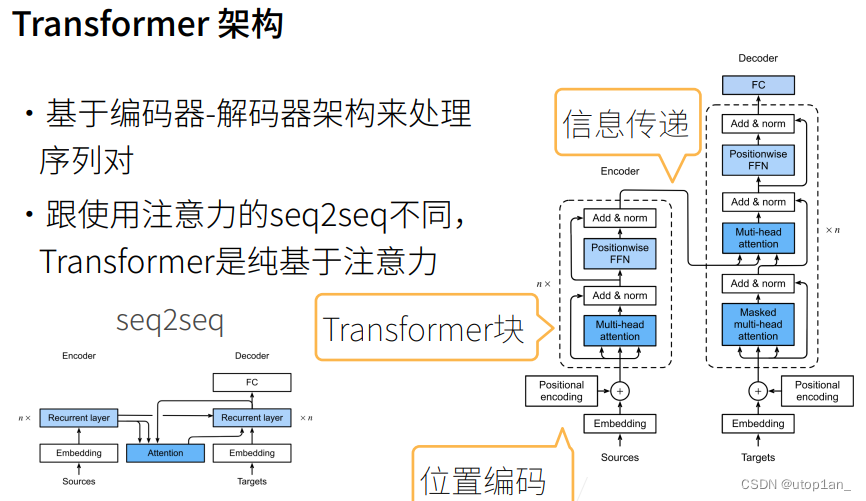
图2.1.1.2 Transformer架构 (b)
2.2.2 多头注意力
相关注意力机制具体内容与实现可参考另一篇文章:基于注意力机制GRU网络的机器翻译
在实践中,当给定相同的查询、键和值的集合时, 我们希望模型可以基于相同的注意力机制学习到不同的行为, 然后将不同的行为作为知识组合起来, 捕获序列内各种范围的依赖关系 (例如,短距离依赖和长距离依赖关系)。 因此,允许注意力机制组合使用查询、键和值的不同 子空间表示(representation subspaces)可能是有益的。
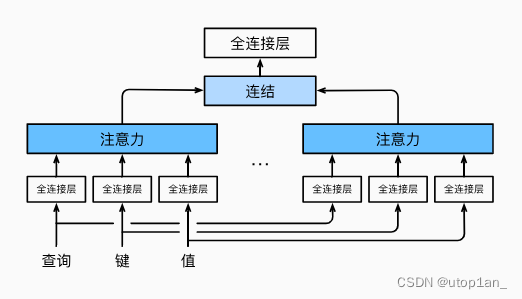
图2.2.2.1 多头注意力
为此,与其只使用单独一个注意力汇聚, 我们可以用独立学习得到的ℎ组不同的 线性投影(linear projections)来变换查询、键和值。 然后,这ℎ组变换后的查询、键和值将并行地送到注意力汇聚中。 最后,将这ℎ个注意力汇聚的输出拼接在一起, 并且通过另一个可以学习的线性投影进行变换, 以产生最终输出。 这种设计被称为多头注意力(multihead attention)。 对于ℎ个注意力汇聚输出,每一个注意力汇聚都被称作一个头(head)。展示了使用全连接层来实现可学习的线性变换的多头注意力。
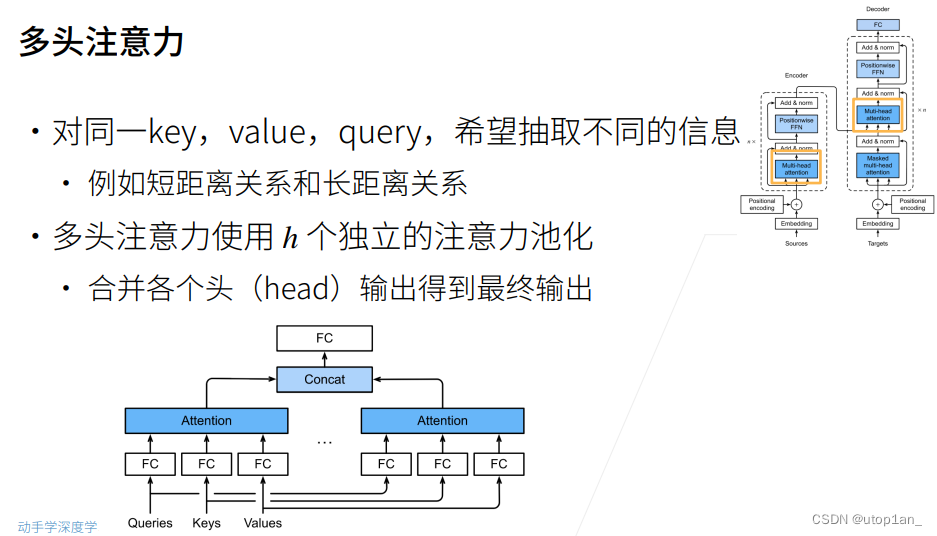
图2.2.2.2 多头注意力:多个头连结然后线性变换¶
2.2.3 基于位置的前馈网络
为了学习复杂的函数关系和特征,Transformer 模型引入了一个前馈网络层 (Feed Forward Netwok, FFN),对于每个位置的隐藏状态进行非线性变换和特征 提取。具体来说,给定输入 𝒙,Transformer 中的前馈神经网络由两个线性变换和 一个非线性激活函数组成:
基于位置的前馈网络对序列中的所有位置的表示进行变换时使用的是同一个多层感知机(MLP),这就是称前馈网络是基于位置的(positionwise)的原因。在下面的实现中,输入X的形状(批量大小,时间步数或序列长度,隐单元数或特征维度)将被一个两层的感知机转换成形状为(批量大小,时间步数,ffn_num_outputs)的输出张量。

图2.2.3.1 前馈网络
2.2.4 残差连接和层规范化
现在让我们关注架构中的加法和规范化(add&norm)组件。正如在本文开头所述,这是由残差连接和紧随其后的层规范化组成的。两者都是构建有效的深度架构的关键。
层规范化和批量规范化的目标相同,但层规范化是基于特征维度进行规范化。尽管批量规范化在计算机视觉中被广泛应用,但在自然语言处理任务中(输入通常是变长序列)批量规范化通常不如层规范化的效果好。
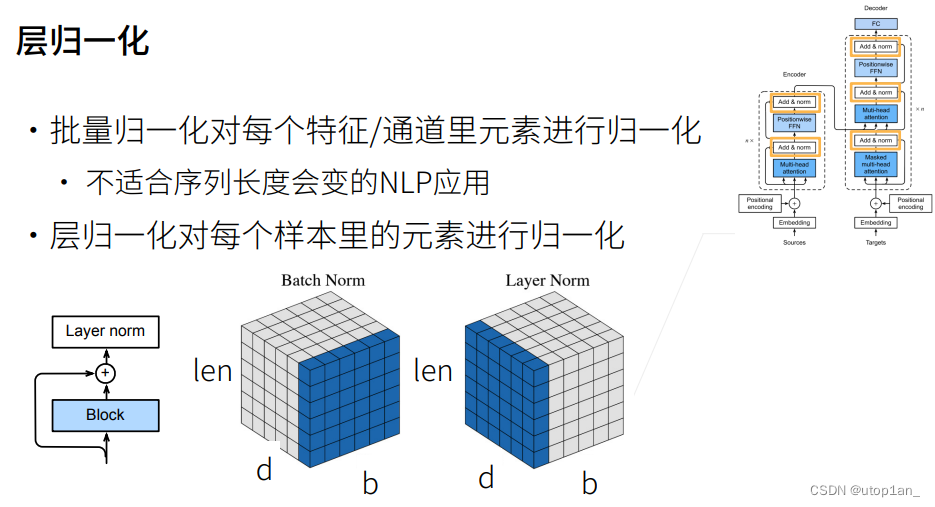
图2.2.4.1 规范化
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1993
1993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









