







写在前面:
本系列文章收录:CAU计算机类公选课《Python语言程序设计》的课堂讲义
课程时间为:2022~2023学年秋季
供各位小白参考~
数据分析:
Numpy :主要用于数组计算,ndarray
Pandas:基于numpy,用于数据挖掘和分析。
Matplotlib:数据可视化
Pandas数据处理分析
两个主要的数据结构:Series和DataFrame
(1)Series(一维数组)
Series由索引(index)和值(value)
【示例】创建Series。
import pandas as pd
ser_obj = pd.Series(data=[185,175,190,167])
print(ser_obj)运行结果:
0 185
1 175
2 190
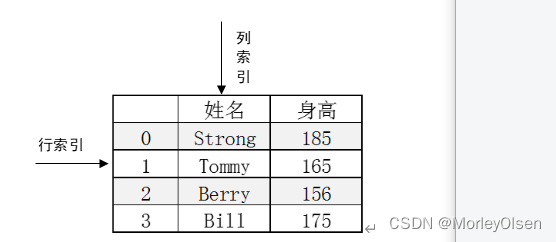
3 167(2)DataFrame
二维表格结构,包含index(行索引)、columns(列索引)和Value(值)
结合Pandas库实现成绩数据处理与分析:
# 导入Pandas库
import pandas as pd# 导入数据
df = pd.read_csv('./data/score.csv')
print(df)
# 查看数
(1)查看前五条
print(df.head())(2)查看最后的五条
print(df.tail())(3)随机抽取5条
print(df.sample(5))# 查看数据集属性
(1)查看数据的行数和列数。
print(df.shape)(2)查看各列的数据类型。
print(df.dtypes)运行结果:
name object
team object
No1 int64
No2 float64
No3 int64
No4 float64
dtype: object(3)查看数据行和列名。
print(df.axes)
[RangeIndex(start=0, stop=102, step=1), Index(['name', 'team', 'No1', 'No2', 'No3', 'No4'], dtype='object')](4)显示列名。
print(df.columns)
Index(['name', 'team', 'No1', 'No2', 'No3', 'No4'], dtype='object')(5)查看索引、列的数据类型和内存信息。
print(df.info())运行结果:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 102 entries, 0 to 101
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 name 102 non-null object
1 team 102 non-null object
2 No1 102 non-null int64
3 No2 100 non-null float64
4 No3 102 non-null int64
5 No4 99 non-null float64
dtypes: float64(2), int64(2), object(2)
memory usage: 4.9+ KB
None# 建立索引
df.set_index('name',inplace=True)
print(df)数据预处理
# 查看是否有重复
print(df[df.duplicated()])运行结果:
name team No1 No2 No3 No4
63 赵雨霏 A 70 73.0 75 87.0
82 沈洁宇 B 100 80.0 68 80.0# 删除重复的行
new_df = df.drop_duplicates(ignore_index=True)
print(new_df)运行结果:
name team No1 No2 No3 No4
0 李博 A 99 68.0 59 77.0
1 李明发 A 41 50.0 62 92.0
2 寇忠云 B 96 94.0 99 NaN
3 李欣 C 48 51.0 94 99.0
4 石璐 D 64 79.0 54 65.0
.. ... ... ... ... ... ...
95 李慧 A 73 73.0 85 53.0
96 陈晨 C 40 65.0 71 54.0
97 杨小传 A 100 70.0 55 90.0
98 赵敏 C 97 93.0 65 88.0
99 黄宏军 E 51 88.0 55 68.0
[100 rows x 6 columns]# 缺失值的处理
new_df = df.drop_duplicates(ignore_index=True)
print(new_df.info())运行结果:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 100 entries, 0 to 99
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 name 100 non-null object
1 team 100 non-null object
2 No1 100 non-null int64
3 No2 98 non-null float64
4 No3 100 non-null int64
5 No4 97 non-null float64
dtypes: float64(2), int64(2), object(2)
memory usage: 4.8+ KBdf.fillna(method='ffill',inplace=True)
print(df.info())运行结果:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 102 entries, 0 to 101
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 name 102 non-null object
1 team 102 non-null object
2 No1 102 non-null int64
3 No2 102 non-null float64
4 No3 102 non-null int64
5 No4 102 non-null float64
dtypes: float64(2), int64(2), object(2)
memory usage: 4.9+ KB
None数据选取
(1)选择列
1)选择一列
print(new_df['No1'])等价
print(new_df.No1)2)选择多列
print(new_df[['team','No1']])(2)选择行
1)通过索引选取行
import pandas as pd
df = pd.read_csv('./data/score.csv' )
df.set_index('name',inplace=True)
print(df[df.index == '李欣'])2)通过自然索引选取行,类似于切片。
import pandas as pd
df = pd.read_csv('./data/score.csv' )
df.set_index('name',inplace=True)
print(df[90:100:2])指定行和列
import pandas as pd
df = pd.read_csv('./data/score.csv' )
df.set_index('name',inplace=True)
print(df.loc['张鑫','No1':'No4'])运行结果:
No1 36
No2 83.0
No3 82
No4 85.0
Name: 张鑫, dtype: object条件选择
(1)单一条件
import pandas as pd
df = pd.read_csv('./data/score.csv' )
df.set_index('name',inplace=True)
# 查看No1列中大于90
print(df[df.No1 > 90] )
# 查看team为C组
print(df[df.team == 'C'])(2)组合条件选择数据
# C组,No2考试成绩大于90分
import pandas as pd
df = pd.read_csv('./data/score.csv' )
df.set_index('name',inplace=True)
print(df[ (df.team == 'C')&(df.No2 >= 90)])简单的数据分析
# 查看每组的个数
import pandas as pd
df = pd.read_csv('./data/score.csv' )
df.set_index('name',inplace=True)
print(df.team.value_counts())运行结果:
B 23
C 22
E 20
D 19
A 18(1)排序
# 按照No1排序,默认为升序
import pandas as pd
df = pd.read_csv('./data/score.csv' )
df.set_index('name',inplace=True)
print(df.sort_values(by='No1',ascending=True))# 先按照组升序,No1 降序
import pandas as pd
df = pd.read_csv('./data/score.csv' )
df.set_index('name',inplace=True)
print(df.sort_values(['team','No1'],ascending=[True,False]))分组聚合
分组查看:groupby()
# 查看 每组四次的平均成绩
import pandas as pd
df = pd.read_csv('./data/score.csv' )
df.set_index('name',inplace=True)
print(df.groupby('team').mean())数据转换
import pandas as pd
df = pd.read_csv('./data/score.csv' )
df.set_index('name',inplace=True)
print(df.groupby('team').mean().T)运行结果:
team A B C D E
No1 65.388889 69.739130 61.590909 64.736842 64.400000
No2 76.166667 77.434783 66.863636 77.157895 72.277778
No3 101.888889 76.173913 64.409091 77.210526 75.100000
No4 78.333333 72.350000 74.136364 73.052632 82.100000# 增加数据列
import pandas as pd
df = pd.read_csv('./data/score.csv' )
df.set_index('name',inplace=True)
df['year'] = 2022
df['total'] = df.No1 + df.No2 + df.No3 + df.No4
df['avg'] = df['total'] / 4
print(df )import pandas as pd
df = pd.read_csv('./data/score.csv' )
df.set_index('name',inplace=True)
print(df.describe())运行结果:
No1 No2 No3 No4
count 102.000000 100.000000 102.000000 99.000000
mean 65.235294 73.900000 78.156863 75.939394
std 21.747961 14.049336 59.138827 15.295603
min 30.000000 50.000000 50.000000 50.000000
25% 47.000000 63.750000 59.500000 61.500000
50% 63.500000 75.000000 71.500000 78.000000
75% 84.000000 85.000000 84.750000 89.500000
max 100.000000 99.000000 650.000000 100.000000数据可视化
Pandas可以利用plot调用Maplotlib库,快速绘制出数据可视化图像。
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('./data/score.csv' )
df.set_index('name',inplace=True)
# MAC
# plt.rcParams['font.sans-serif'] = 'Arial Unicode MS'
# windows
plt.rcParams['font.sans-serif'] = 'SimHei'
df.No1.plot()
plt.show()
# 李欣 四次成绩的变化
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('./data/score.csv' )
df.set_index('name',inplace=True)
# MAC
# plt.rcParams['font.sans-serif'] = 'Arial Unicode MS'
# windows
plt.rcParams['font.sans-serif'] = 'SimHei'
df.loc['李欣','No1':'No4'].plot()
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('./data/score.csv' )
df.set_index('name',inplace=True)
# MAC
# plt.rcParams['font.sans-serif'] = 'Arial Unicode MS'
# windows
plt.rcParams['font.sans-serif'] = 'SimHei'
# df.loc['李欣','No1':'No4'].plot()
# 各组四次总成绩趋势
df.groupby('team').mean().T.plot()
plt.show()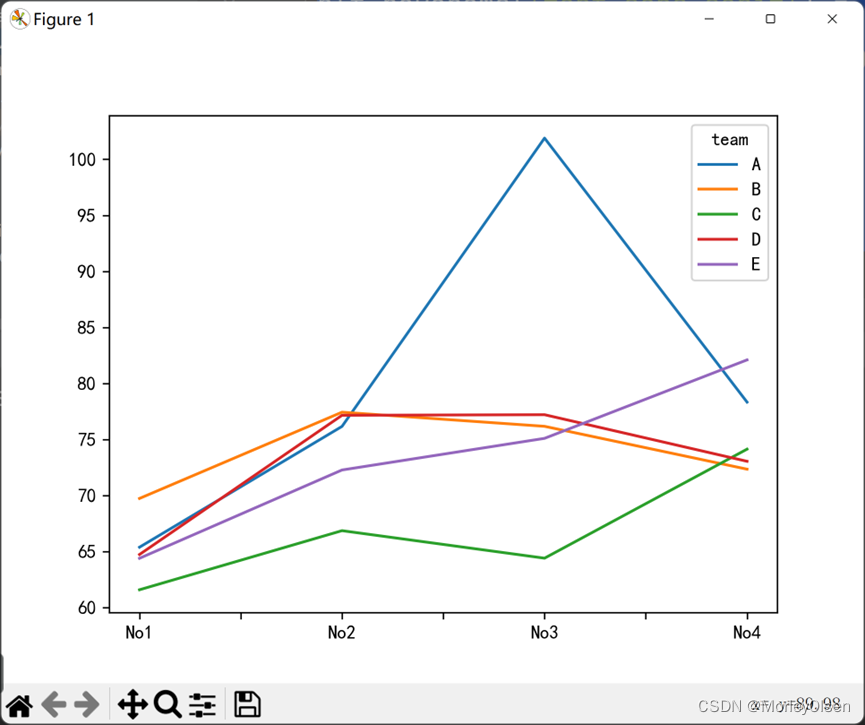
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('./data/score.csv' )
df.set_index('name',inplace=True)
# MAC
# plt.rcParams['font.sans-serif'] = 'Arial Unicode MS'
# windows
plt.rcParams['font.sans-serif'] = 'SimHei'
# df.loc['李欣','No1':'No4'].plot()
# 各组四次总成绩趋势
df.groupby('team').count().No1.plot.pie()
plt.show()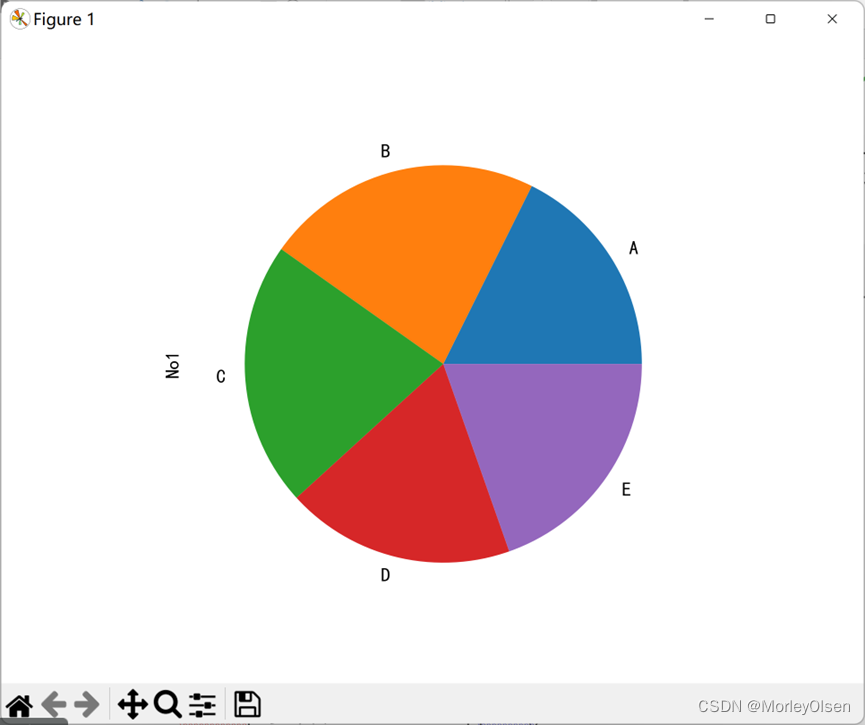
将处理后的数据保存入“score.xlsx”
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('./data/score.csv' )
df.set_index('name',inplace=True)
new_df = df.drop_duplicates(ignore_index=True)
new_df.to_excel('./data/score.xlsx')课程回顾:
第1章 Python概述
Python特点
应用领域
Pycharm IDE安装和使用
Python运行方式
Python解释器类型
第2章 Python语法特点
标识符与变量
变量的定义和赋值
基本数据类型:数值型 布尔型 NoneType
数据类型转换
字符串类型
基本输入输出:input() print()
常见的运算符和表达式:算术、赋值、逻辑、关系、条件三目
第3章 Python的基本流程控制
选择结构
if
if…else
if…elif…else
循环结构
while
for range()
转移和中断
continue
break
pass
while…else for…else
第4章 Python的4种典型序列结构
列表 创建 访问与遍历 常见操作 统计和排序
元组 创建 常见操作 与列表的区别
字典 创建 访问与遍历 常见操作
集合 创建 常见操作
容器的公共操作
第5章 Python函数
函数定义,调用和返回值
函数参数(位置、关键字、默认值、不定长)与值传递
变量的作用域:局部变量 全局变量(global)
递归函数
匿名函数
第6章 Python文件操作
文件打开与关闭
文件与文件判断
文件的基本操作
第7章 面向对象程序设计
类和对象 定义 使用 构造函数 访问机制
类的继承
第8章 模块和包
模块的定义 导入
包的创建
第三方模块的下载和安装
标准模块的使用
Pandas数据分析和可视化
















 3092
3092











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











