






各节点布置
| 主机IP(需要根据自己网段进行相应修改) | 主机名 | 描述 | HDFS | YARN |
| 192.168.209.150 | master | 主节点 | NameNode DataNode | ResourceManager NodeManager |
| 192.168.209.150 | slave1 | 备用节点 | NameNode DataNode | ResourceManager NodeManager |
| 192.168.209.150 | slave2 | 备用节点 | DataNode | ResourceManager NodeManager |
目录
五. Hadoop文件配置 (上传解压Hadoop的步骤省略)
8.分发hadoop文件到:salve1节点slave2节点
六.启动journalnode服务(三个节点都需要执行此步骤)
4.格式化zookeeper(只需要在master节点执行)
一.环境准备
JDK, ZKEEPER ,HADOOP
二 .设置网卡,主机名,密钥,映射
1.设置网卡
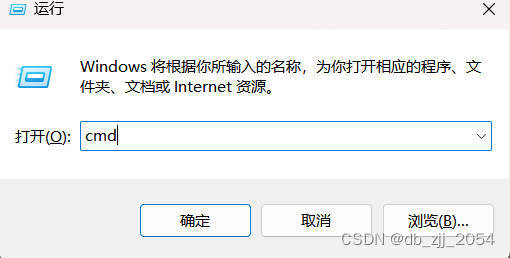
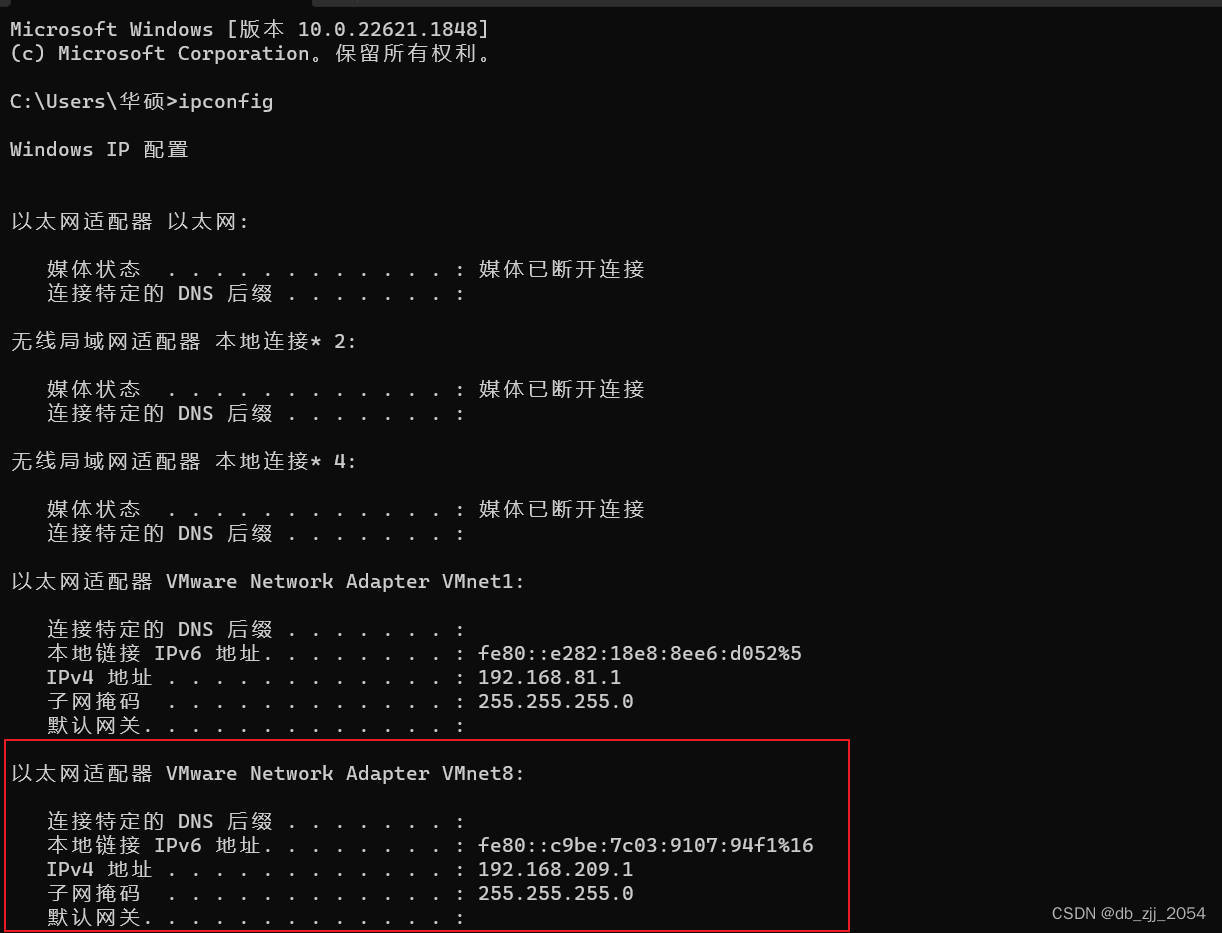
首先win+R输入cmd进入命令窗口,然后输入ipconfig获取VMnet8IP信息
输入vi /etc/sysconfig/network-scripts/ifcfg-ens33命令配置网卡

重启网卡:systemctl restart network后拼一下百度验证是否设置成功

2.设置主机名
输入命令:hostnamectl set-hostname master,输入之后需要exit关闭重新登录,重新登录看到主机名为master就表示成功了(我的在此之前已经设置)
3.设置密钥
ssh-keygen rsa

分发密钥到master:
ssh-copy-id -i ~/.ssh/id_rsa.pub master执行完命令之后会需要输入该主机的密码
验证是否分发成功:

4.设置映射
输入命令:vi /etc/hosts
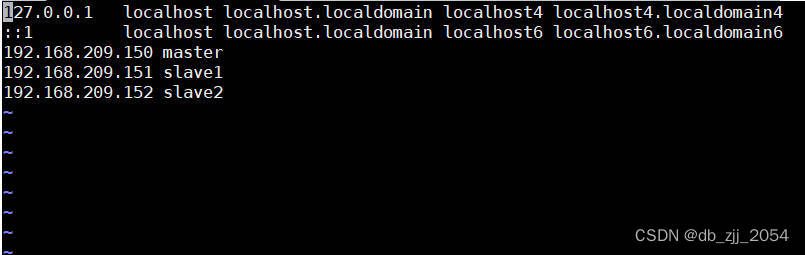
上诉步骤都需要在master,slave1,slave2执行,主机名需要相应修改。
master网卡文件信息:

slave1网卡文件信息:

slave2网卡文件信息:
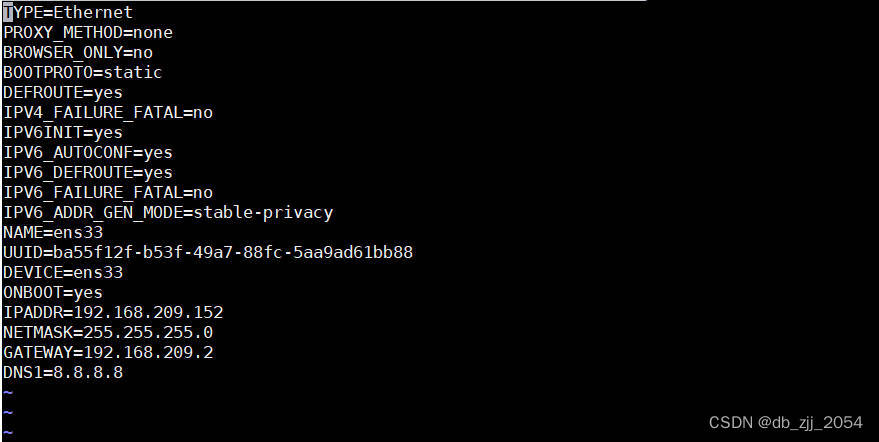
验证映射是否成功每个节点互相ping(只展示一个)


三.配置JDK
1.安装JDK
上传JDK到/usr/local然后cd /usr/local输入以下命令:
tar -xvzf jdk-8u221-linux-x64.tar.gz
2.配置环境变量
vi /etc/profile

3.验证环境变量是否设置成功
命令:java -version (执行之前需要 source /etc/profile 更新一下环境变量)

四.安装ZOOKEEPER并进行配置
1.上传ZKEEPER到/usr/local并进行解压
输入命令: tar -xvzf zookeeper-3.5.7-bin.tar.gz
2.配置zookeep
cd /usr/local/zookeeper-3.5.7-bin/conf进入conf目录修改zoo_sample.cfg文件为zoo.cfg

vi /zoo.cfg进行配置文件
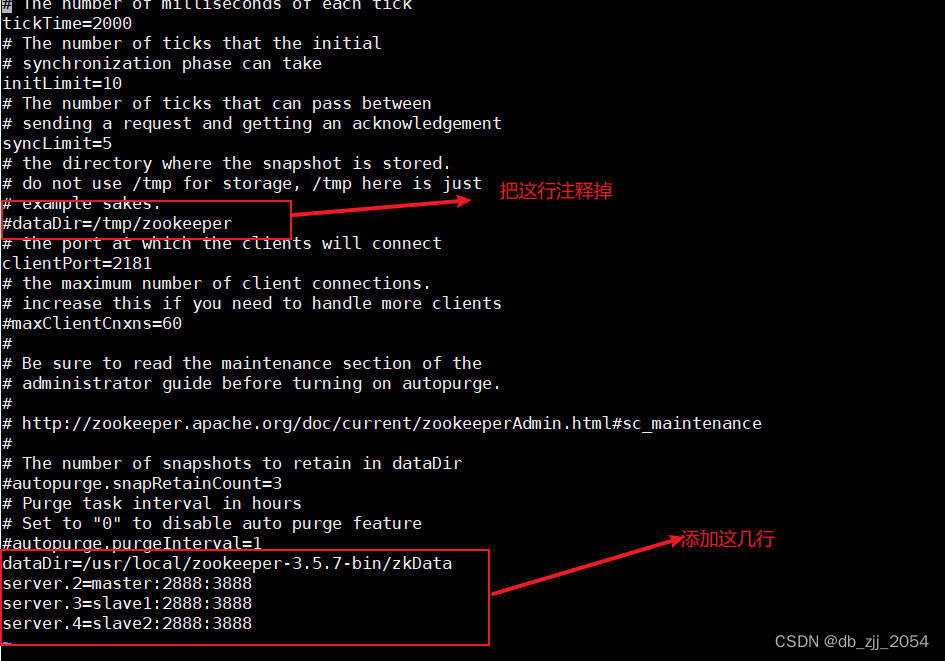
配置my_id文件:在zookeeper目录下新建zkDATA目录,并在目录下新建myid文件


分发jdk,zookeeper到slave1,slave2 : scp -r /usr/local root@slave1:/usr/local 、scp -r /usr/local root@slave2:/usr/local
在master节点的myid文件添加信息:2
在slave1节点的myid文件添加信息:3
在slave2节点的myid文件添加信息:4
3.配置zookeeper环境变量

4.启动zookeeper服务(每个节点都执行该步骤)
命令:zkServer.sh start

五. Hadoop文件配置 (上传解压Hadoop的步骤省略)
1.添加环境变量

2.修改core-site.xml
cd $HADOOP_HOME/etc/hadoop然后vi core-site.xml进行配置

3.修改hdfs-site.xml
vi hdfs-site.xml

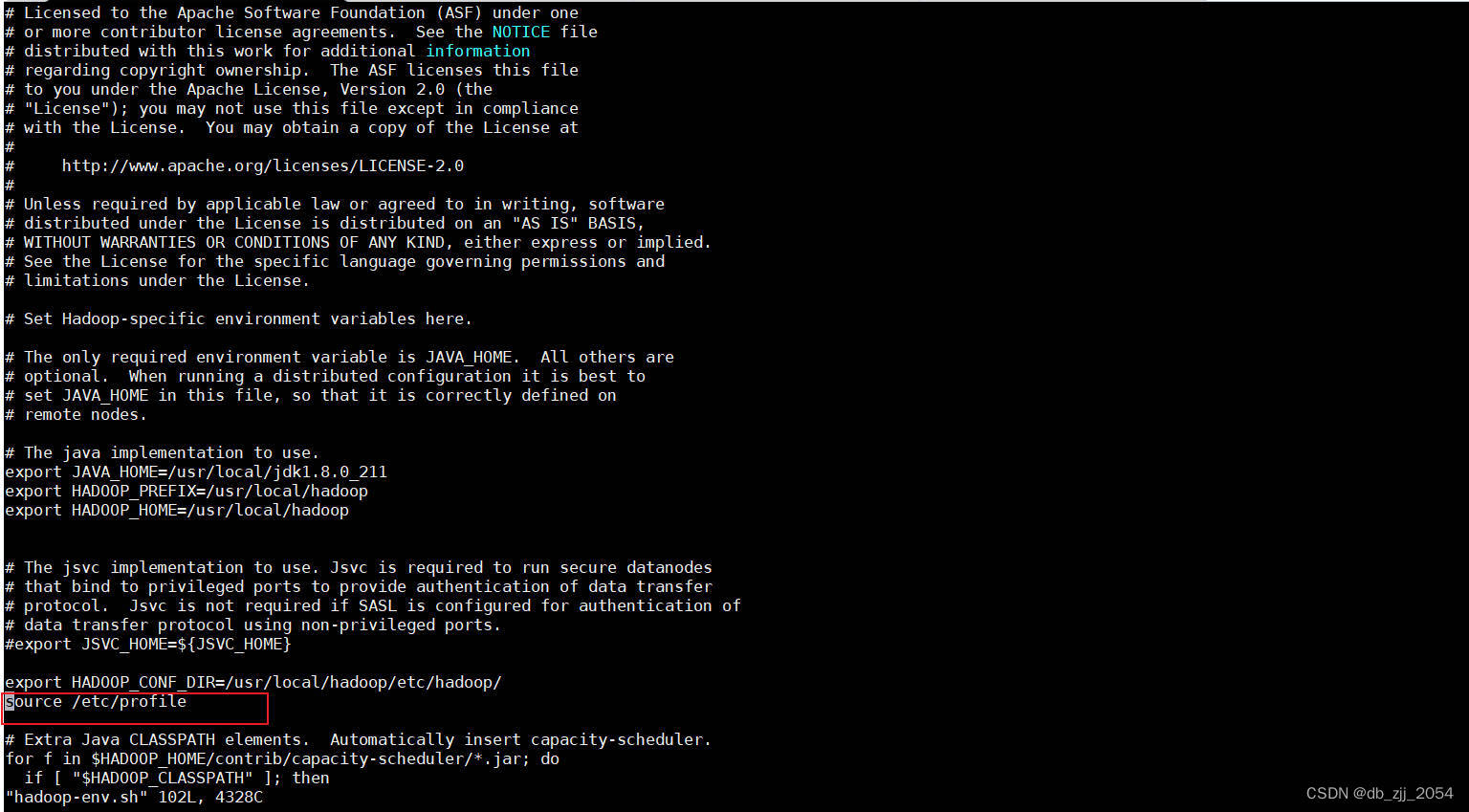
4.在hadoop-env.sh添加内容
5.配置 yarn-site.xml文件

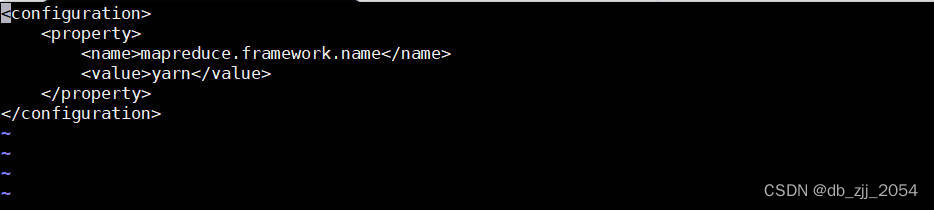
6.配置mapred-site.xml文件
7.配置 slaves文件

到此hadoopHA的文件已经配置完。
8.分发hadoop文件到:salve1节点slave2节点
scp -r /usr/local/hadoop_2.7.1 root@slave1:/usr/local/
scp -r /usr/local/hadoop_2.7.1 root@slave2:/usr/local/
因为我们只设置了master节点的环境变量因此也要把该文件分发到slave1,slave2
scp -r /etc/profile root@slave1:/etc
scp -r /etc/profile root@slave2:/etc
自行检查各节点的配置文件是否已经成功分发
六.启动journalnode服务(三个节点都需要执行此步骤)
1.启动命令
hadoop-daemon.sh start journalnode
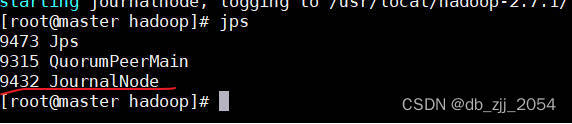
2.检查是否启动成功
有JournalNode进程在就证明启动成功,QuorumPeerMain是zookeeper服务
七.启动HDFS集群
1.格式化NameNode(只需要在master节点执行)
在格式化之前需要确保以下三个进程在
命令:hdfs namenode -format
2.单独启动NameNode
此步骤可能影响后面的namenode主从信息同步,启动完服务之后自行使用jps检查是否启动成功
命令:hadoop-daemon.sh NameNode
3.namenode主从信息同步(在slave1执行)
命令:hdfs namenode -bootstrapStandby
如果执行时报下图的错误:就是只在master节点启动了NameNode进程,解决这个报错的方法是在slave2节点也启动NameNode进程然后重新执行hdfs namenode -bootstrapStandby。
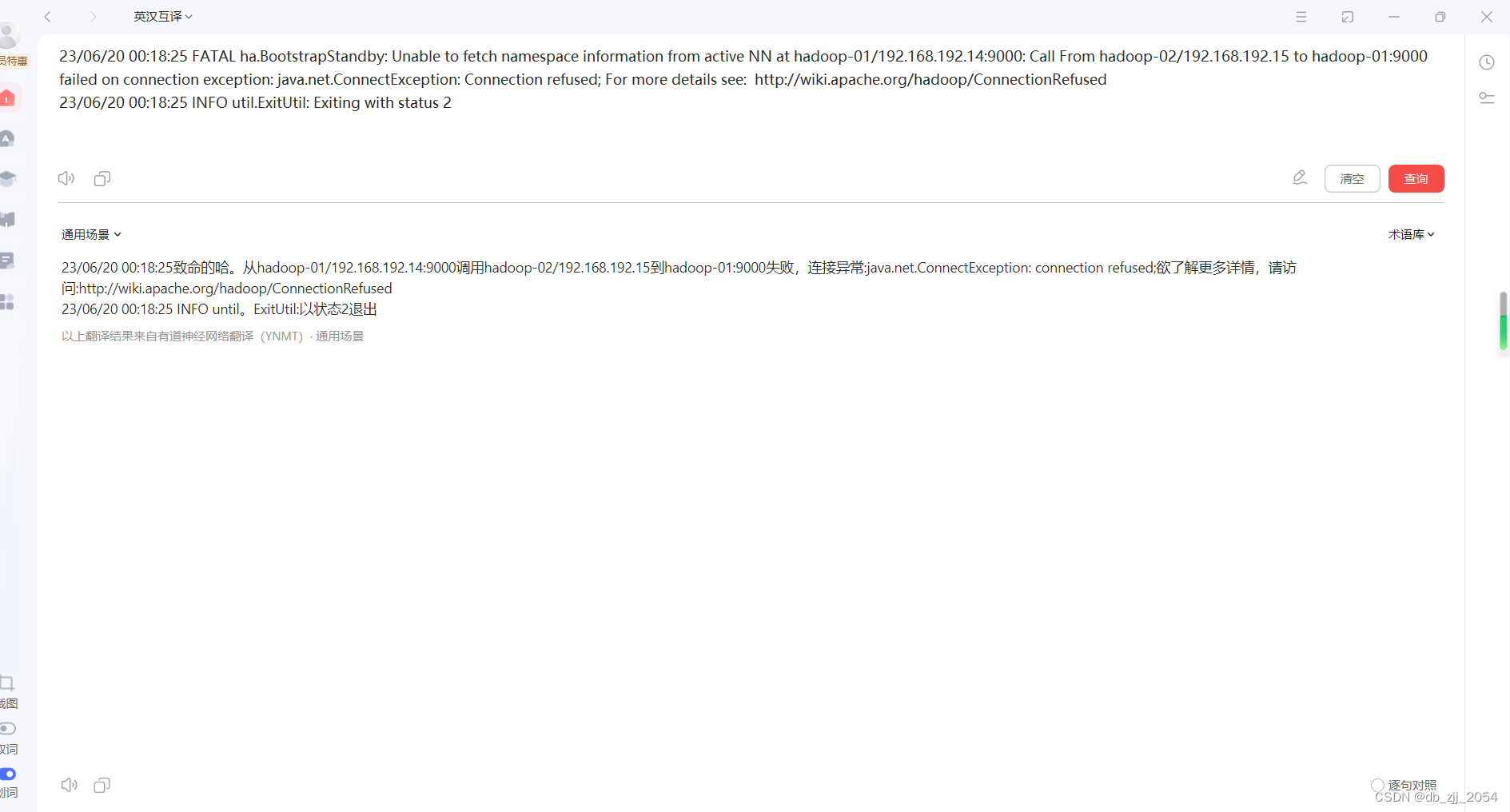
4.格式化zookeeper(只需要在master节点执行)
执行之前执行stop-all.sh先关掉JournalNode进程。
命令:hdfs zkfc -formatZK
5.启动hadoop
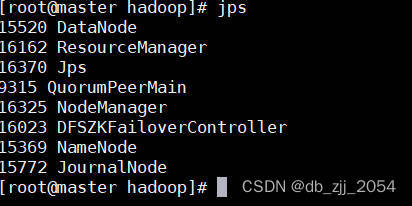
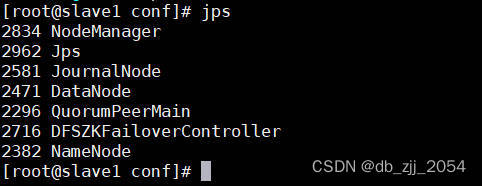
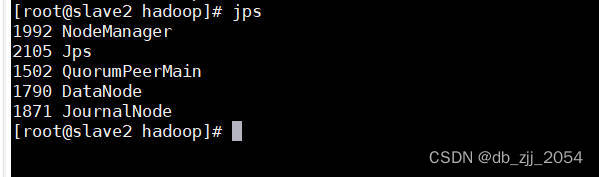
执行以上操作我们就可以使用start-all.sh启动hdfs了,启动完之后还需要检查各节点的进程信息。
master 节点:
slave1节点:
slave2节点:
八.验证HA
我们打开web端的页面显示是一个active一个standby。
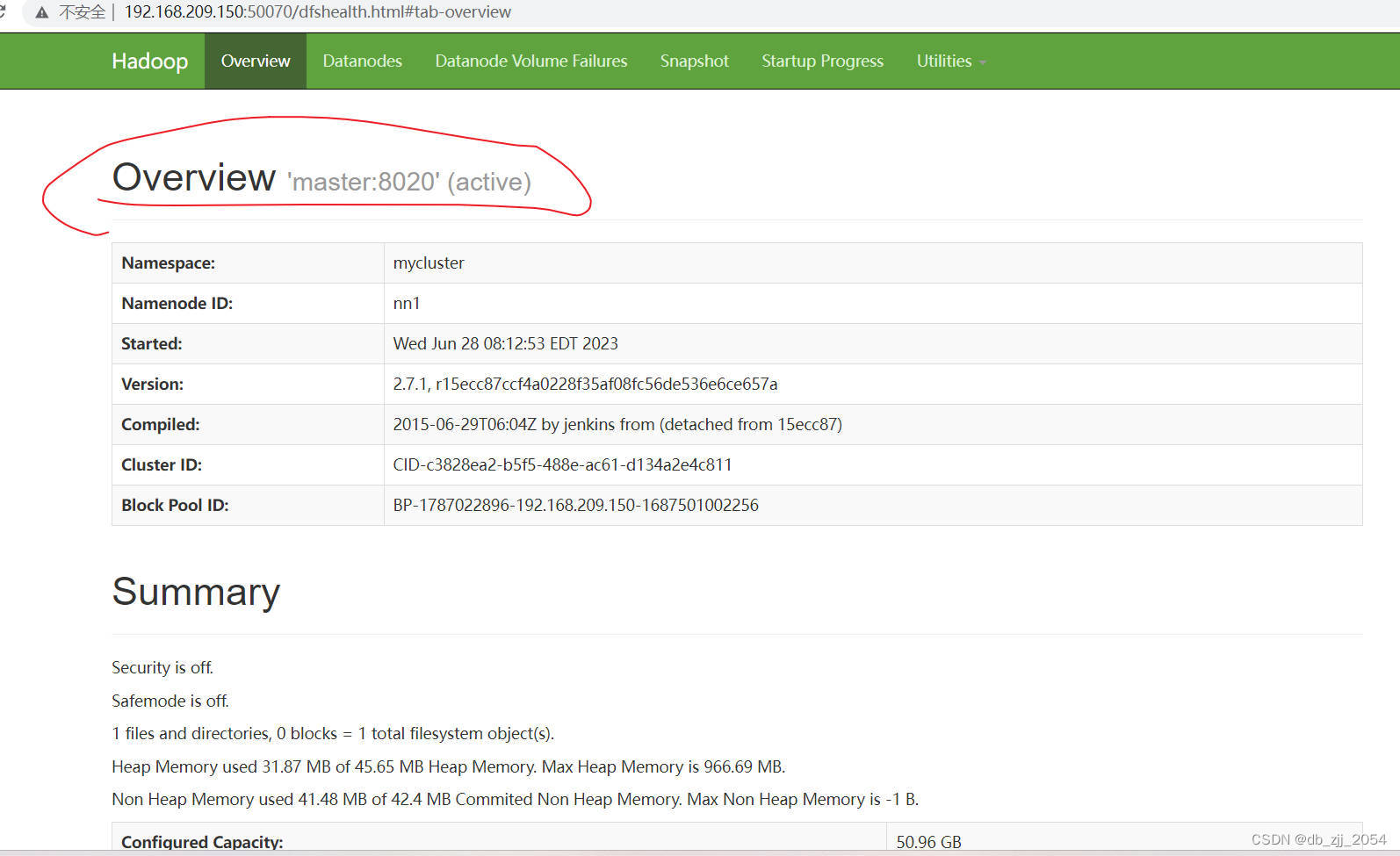
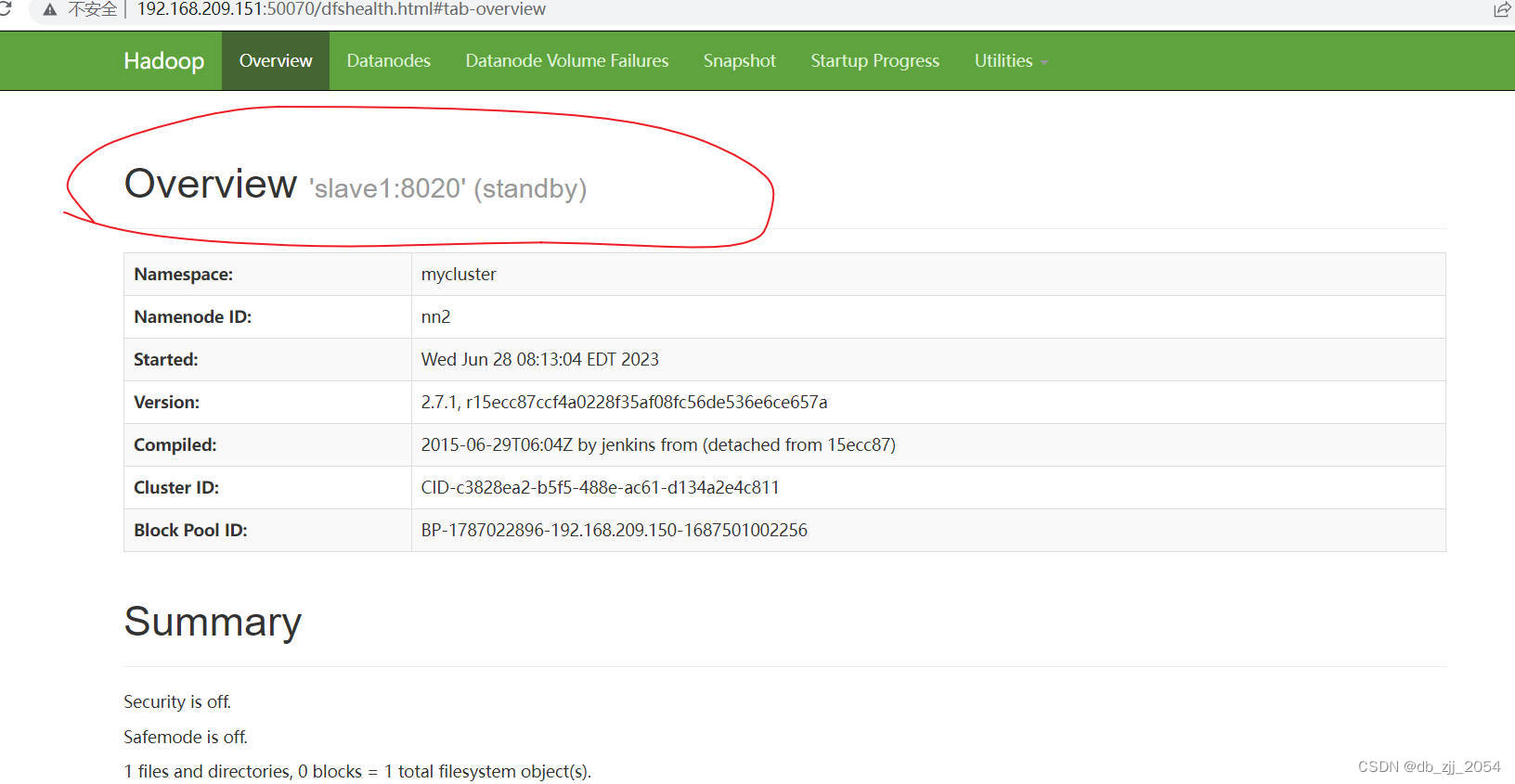
我们可以kill掉正在运行的主机的NameNode看看另一台是否能自启。

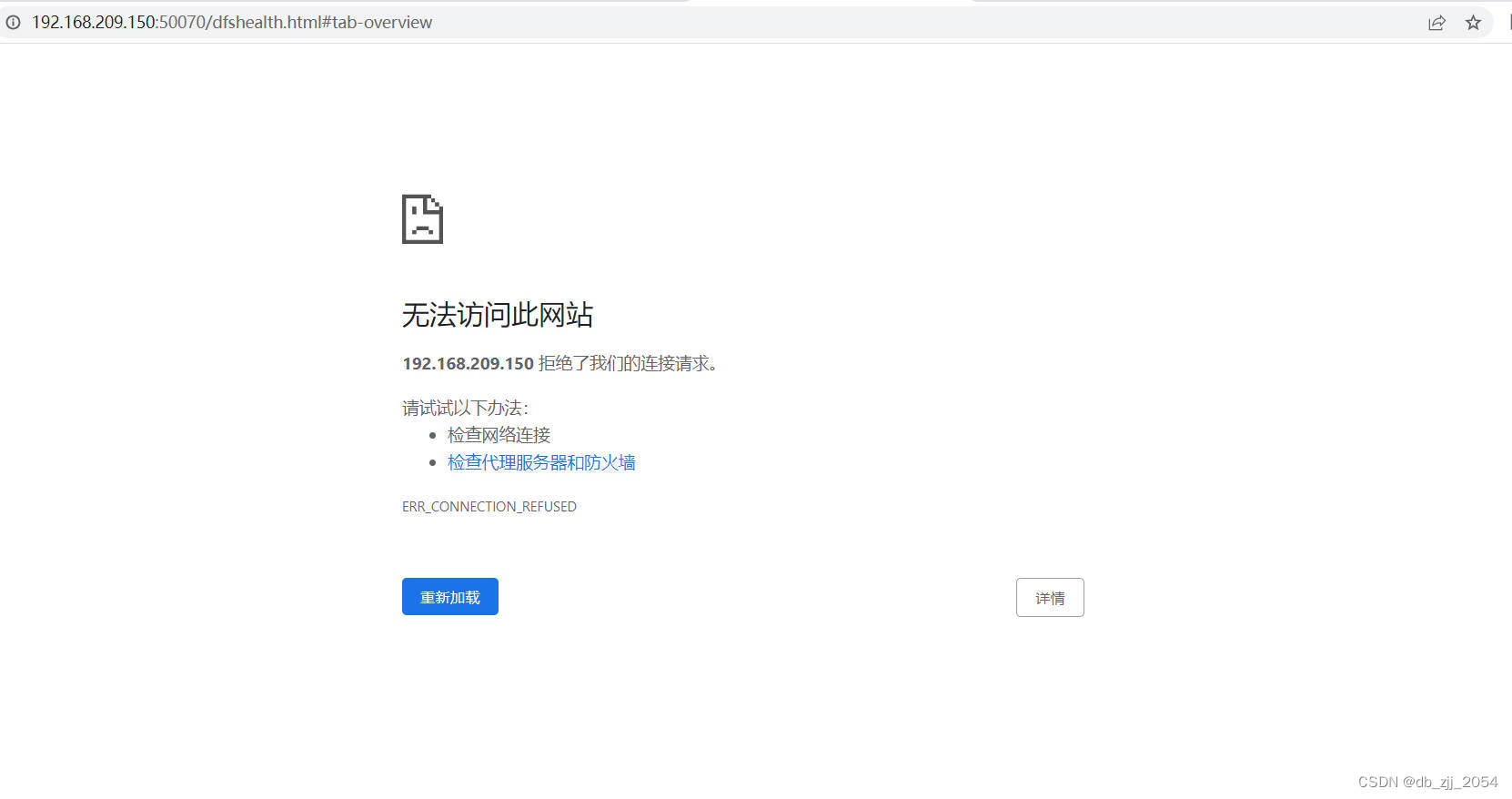
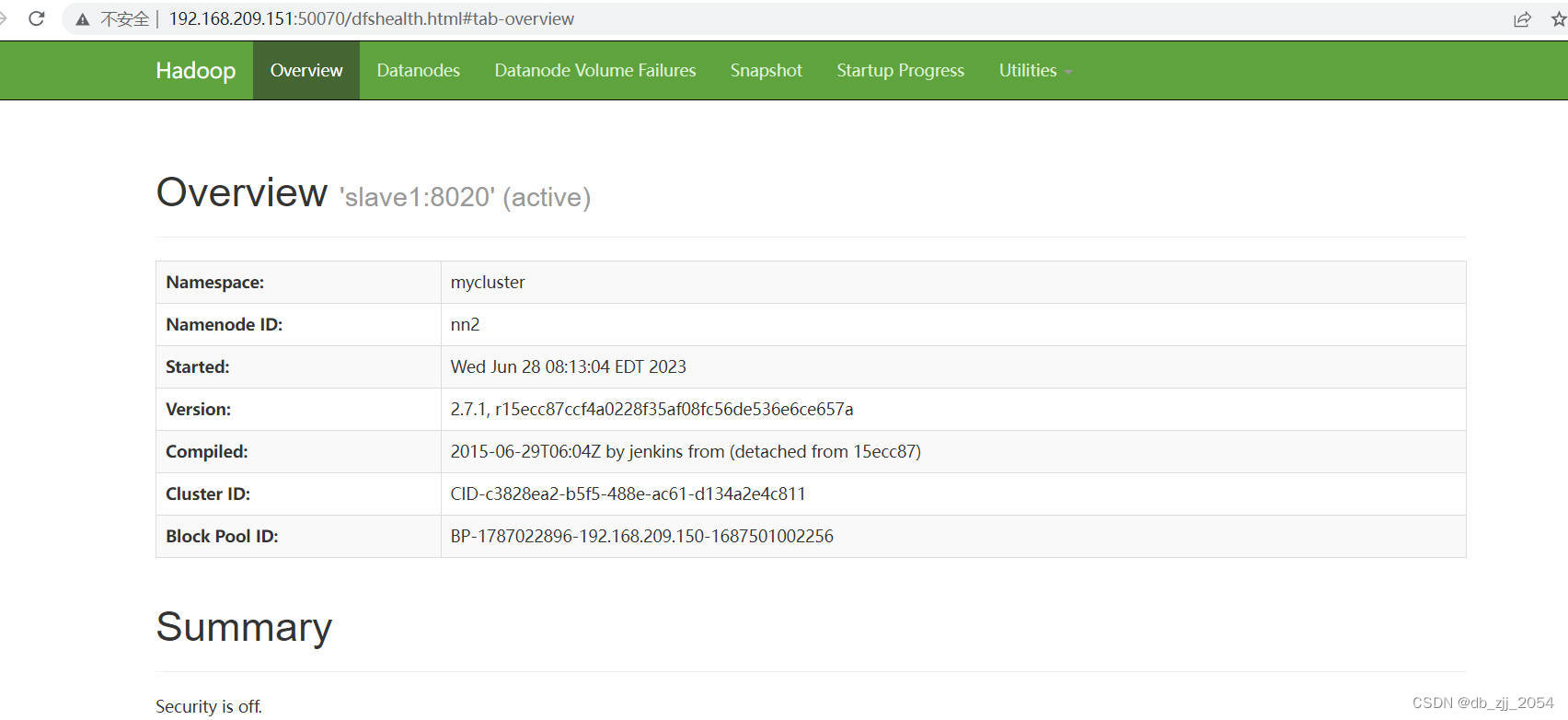
我杀掉的是192.168.209.150这台主机所以访问不了web端,但我们可以发现192.168.209.151这个web端界面已经变成(active),证明另一台主机已经能自启,至此HA部署成功。














 562
562











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









