






 论文提出了一种名为DDA的动态去摩尔纹加速方法,适用于移动设备。DDA根据图像块的摩尔纹复杂度重新分配计算资源,使用不同大小的网络处理不同复杂度的区域,以提高效率并保持图像质量。通过超级网络范式实现参数共享,减轻了额外的计算负担。实验表明DDA在减少FLOPs的同时,保持了去摩尔纹的性能,实现在现代智能手机上的实时处理。
论文提出了一种名为DDA的动态去摩尔纹加速方法,适用于移动设备。DDA根据图像块的摩尔纹复杂度重新分配计算资源,使用不同大小的网络处理不同复杂度的区域,以提高效率并保持图像质量。通过超级网络范式实现参数共享,减轻了额外的计算负担。实验表明DDA在减少FLOPs的同时,保持了去摩尔纹的性能,实现在现代智能手机上的实时处理。
论文来源:

摘要部分:

在拍摄数码屏幕时,摩尔纹经常出现,大大降低了画面质量,尽管cnn在图像去摩尔纹方面取得了进步,但现有的网络模型很大,对移动设备造成冗余计算负担,在本文中,我们首次对加快去摩尔纹网络和提出了一种动态去摩尔纹加速方法 (DDA)实现在移动设备上的实时部署。我们的灵感来自一个简单而普遍的事实,摩尔纹往往是不平衡分布在一张照片上的,过多的计算浪费在没有摩尔纹的区域上,因此,我们根据图像斑块的复杂度重新分配计算成本。为了达到这个目的,我们通过设计一种新的摩尔纹图像,它优先考虑云纹图案的颜色和频率信息,来测量了一个图片斑块的复杂度,接着我们通过小的网络去恢复简单的斑块,大的网络去恢复复杂的斑块,以此来减轻计算的负担。最后,我们在一个参数共享的超网络范式中训练所有的网络,以避免额外参数的负担。在几个基准上进行的大量实验证明了这一点我们提出的DDA的功效。另外,这个加速模型在配备有小龙8gen1的vivo x80pro上测试证明了我们的措施可以极大减少预测时间,实现实时的移动端去摩尔纹。
介绍:



摩尔纹是一种常出现在电视和数码摄影中的一种图像的人工制品,在当代社会,使用手机来
拍屏幕图片已经成为最高效的快速记录信息的方式之一。然而,由于相机的彩色滤光片阵列(CFA)与高频重复信号的干扰,经常会出现摩尔纹,由此产生的不同颜色和频率的条纹大大降低了拍摄照片的视觉质量,因此,开发去摩尔纹算法一直是研究界关注的问题,但在移动设备上运行算法时仍未解决。对图像去噪的原始研究采用传统的机器学习技术,如low-rank and sparse matrix decomposition and bandpass filters (低秩和稀疏矩阵分解和带通滤波器).卷积神经网络(cnn)的兴起极大地提高了图像去噪的效果,然而,改进的定量性能,如PSNR(峰值信噪比),以不断增加的能源和计算成本为代价。例如,MBCNN (Zheng等人,2020)消耗4.22T FLOPs,以恢复1920×1080智能手机拍摄的摩尔纹图像。考虑到摩尔纹主要出现在移动摄影中,如此大规模的计算带来了相当大的推理延迟,阻止了用户的实时去摩尔纹体验,在视频录制下,这种去摩尔纹的体验要更加糟糕。因此,弥合学术界和工业界之间的技术鸿沟是非常必要的。
为了解决上述问题,我们启动了第一项关于加速去摩尔纹网络,移动设备实时部署的研究。我们的动力来源于摩尔纹的经验实例,如图1所示,图像通常会部分受到云纹的污染。一些位置布满了密集的摩尔纹,一些位置得到了很大的缓解,而一些位置则远离了摩尔纹纹污染。。对那些莫尔纹集中的区域进行计算是很正常的,但对这些稀疏的区域计算则较少。在极端情况下,没有必要清洗未受影响的区域。不幸的是,现有的方法没有对图像中不同区域进行区分处理。 它们不仅在非摩尔纹区域浪费了过多的计算,而且还会带来副作用,例如图像内容过度白化。因此,根据摩尔纹区域的复杂性重新分配计算成本可能是在移动设备上实现实时图像去噪的解决方案。基于上述分析,我们选择将整个图像分割为几个子图像块,为了测量斑块摩尔纹的复杂性,我们事先引入了一种新的摩尔纹,从图1中可以看出,摩尔纹区域具有频率高或色彩信息丰富的特点,因此,我们将摩尔纹先验定义为斑块中频率和颜色信息的产物,. 具体来说,我们通过高斯滤波器对频率信息进行建模,而色彩度度量是RGB颜色空间中像素云的均值和标准差的线性组合。用这种方法测量摩尔纹复杂度之后,每个图像块都由一个独特的网络处理,其计算成本与摩尔纹复杂度成比例,通过这种方式,利用较大的网络恢复摩尔纹集中区域,以确保恢复质量,而利用较小的网络恢复云纹稀释区域,以减轻计算负担。因此,我们在移动设备上的图像质量和资源需求之间有更好的权衡。但是,多个网络会带来更多的参数负担,这也会造成移动设备内存不足带来的部署压力。为了缓解这个问题,我们利用超级网络范式以参数共享的方式联合训练所有网络,具体而言,我们将这一普通去摩尔纹网络视为一个超级网络,从这个超级网络中直接提取不同大小的权重共享子网,以处理不同摩尔纹复杂度的图像斑块,在训练阶段,每个子网使用摩尔纹复杂度相似的图像斑块进行动态训练,因此,在不引入任何额外参数的情况下,可以有效地降低总体运行开销。我们在´LCDMoire (Yuan et al, 2019)和FHDMi (He et al, 2020)基准上进行了广泛的加速现有去摩尔纹网络的实验。结果表明,我们的动态去摩尔纹加速方法,称为DDA,即使在PSNR和SSIM增加的情况下,也能实现明显的FLOPs降低。例如,DDA降低了最先进的去摩尔纹网络MBCNN的45.2%的FLOPs (Zheng et al ., 2020), PNSR增加0.35 dB。这项工作解决了在资源有限的移动设备上解除网络部署的问题
The key contributions of this paper include: (1) A novel framework for accelerating image demoireing networks in a dynamic manner. (2) An effective moir ´ e prior to identify the demoir ´ eing ´ complexity of a given image patch. (3) Performance maintenance and apparent acceleration on modern smartphone devices.
相关工作:


技术部分:
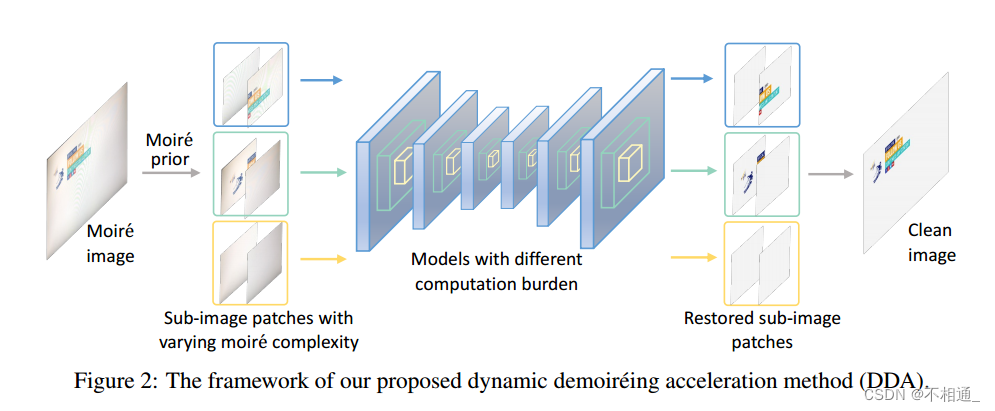

图2显示了我们的动态消噪加速方法(DDA)的总体框架。首先将一幅摩尔纹图像分割成若干个子图像块,然后根据块云纹复杂度重组成不同的组,这是通过考虑摩尔纹图案的颜色和频率信息的新型云纹先验来实现的,detail it in Sec. 3.1,为了在移动设备上进行实时图像提取,我们训练了多个不同复杂度的网络来处理不同组的斑块。在训练和测试阶段,将复杂度较高的图像送入较大的网络,将复杂度的图像送入较小的网络。Sec. 3.2 gives the implementations。。最后,作为训练产生更多参数的单独网络的替代方法,我们将每个网络视为普通分解网络(超级网络)的一个子网,从而产生 Sec. 3.3.所示的权重共享训练范式。
3.1



摩尔纹图案的复杂程度可以由人类来确定,但是,手动定义每个云纹图像中所有斑块的复杂性是费时费力的,许多以前的研究都是关于动态网络的,(Han等人,2021;Kong等人,2021)训练了一个额外的模块来适应不同输入的网络,然而,这给它的几个卷积层或全连接层的组成带来了意想不到的参数和计算。考虑到我们在移动设备上部署去摩尔纹网络的计划,这样的解决方案是不可行的,至少不是最优的。我们提出了一种新的摩尔纹先验,可以快速测量图像的摩尔纹复杂度。这一先验图的动机来自于对摩尔纹图像的深入观察。从图3可以推断,摩尔纹图案在频率和颜色上变化很大。通常,可感知的摩尔纹图案是通过高频或丰富的颜色信息来突出显示的。因此,同时反映图像频率和色彩的先验层可以是模拟摩尔纹图案复杂度的有效方法。将摩尔纹图像记为X,首先将其分解为子图像块为{xi}N(i=1),对于特定的patch x,我们使用高斯分布标准差为5的高斯高通滤波器提取频率信息为F(x)。为了测量色块的色彩度,我们考虑了RGB色彩空间中像素云的均值和标准差的线性组合。
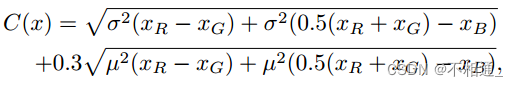
µ(·)和σ(·)为均值和标准差函数,xR, xG, xB表示R, G, B颜色通道,
这里0.3是通过最大化实验数据与色彩度度量之间的相关性得到的参数,参考(Hasler & Suesstrunk, 2003)更多测量图像色彩的原则。因此,我们提出的使用频率和色彩先验的摩尔纹复杂性评分最终定义为
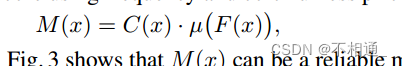
从图3可以看出,M(x)可以作为评估图像摩尔纹复杂度的可靠度量。 注意,在不构建任何额外的网络模块的情况下,我们的moire prior的操作变得非常便宜,计算负担可以忽略不计。
3.2


在图像去噪中,被摩尔纹污染的图像X被期望在自然场景中恢复到无摩尔纹的真值。传统的去噪过程是用cnn来表述的:
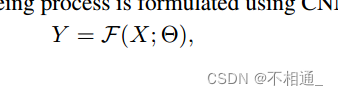
其中,F为去摩尔纹网络的标准,其参数记为 Θ。从Eq.(3)中可以看出,现有的方法使用相同的网络' F来恢复摩尔纹图像的所有区域,这浪费了过多的计算,因为摩尔纹复杂度在图像的不同区域之间的差异很大,如第1节所述。
这违背了我们在移动设备上实时图像去摩尔纹的目标。加速去摩尔纹的一种自然方法是根据摩尔纹区域的复杂性重新分配计算成本,为此,我们将X的子图像patch {xi} N (i=1)按照Eq.(2)中定义的摩尔纹复杂度分数升序进行重组,然后将有序的patch分成M组,分别表示为{G1, G2,…,Gm}。
每组Gi包括这些斑块,复杂度评分由高至低分别为
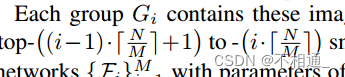
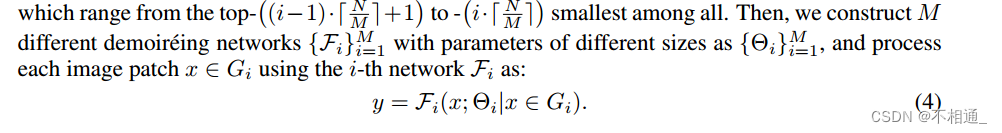
然后,我们构建M个不同大小的参数为{Θi}M i=1的不同去摩尔纹网络´{Fi}M i=1,使用第i个网络Fi对每个图像patch x∈Gi进行处理
在我们的设置中,Fi的复杂度比Fi+1的复杂度要小,使得计算成本较低的网络可以处理较小复杂度的图像patch,反之亦然。Eq.(4)通过根据云纹复杂程度分配计算代价,动态加速了Eq.(3)的推导。
同时,由于使用更大的网络对集中区域进行重新存储,仍然保证了恢复质量。最后,通过连接所有网络的patch输出,得到我们的 dynamic demoireing acceleration(DDA)方法的无莫尔纹输出:
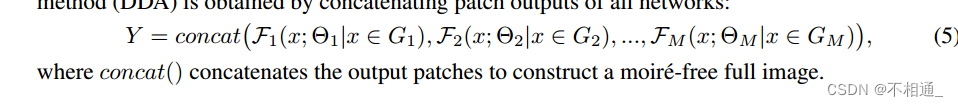
3.3

虽然上述过程有利于降低总体计算成本,但在内存供应不足的移动设备上部署我们的去摩尔纹方法时,会出现参数负担方面的挑战。 以设置最大网络FM为普通去摩尔纹网络F为例,共引入了附加参数M−1 i=1 (|Θi |)。
为了解决这个问题,我们进一步建议使用超级网络范式以参数共享的方式训练和预测所有网络,而不是孤立地训练网络{Fi}M i=1。
具体来说,我们把普通的去摩尔纹网络F看作一个超级网络,它的参数Θ部分由Fi共享。假设Fi的网络宽度为Wi,我们将卷积滤波器权值的第一个Wi比例继承给子网Fi,记为Θ[Wi]。因此,网络Fi成为F的子网。因此,我们的无摩尔纹输出最终被重新表述为:
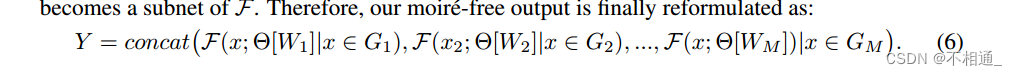
因此,即使没有任何额外的参数负担,也可以有效地加速图像去噪,最终达到我们在移动设备上实时部署的目标。
4.实验

4.1 实验准备
图像去噪有三个主要的公共数据集。(1)来自AIM19图像分解挑战的LCDMoir数据集(Yuan et al ., 2019)由10200个合成图像对组成,其中包括10000个训练图像、100个验证图像和100个测试图像,分辨率为1024×1024。(2) FHDMi数据集(He et al ., 2020)包含9981对用于训练的图像和2019对用于1920×1080分辨率测试的图像。(3) TIP2018数据集(Huang et al ., 2017)由真实照片组成,该数据集通过拍摄显示在计算机屏幕上的ImageNet (Deng et al ., 2009)中400×400分辨率的图像构建而成。在本文中,我们在LCDMoire '和FHDMi数据集上进行了实验。我们不考虑TIP2018基准,因为分辨率太小,无法满足我们在移动设备上进行图像提取的目标,而从移动设备捕获的图像通常具有1920×1080或更高的极高分辨率。
4.1.2

我们采用广泛使用的PSNR(峰值信噪比)和SSIM(结构相似度)指标对去噪性能进行定量比较。我们还报告了使用CIE DeltaE 2000 (Sharma et al, 2005)测量的恢复图像和干净图像之间的色差,用∆E表示。在采用骁龙8 Gen 1网络芯片的VIVO X80 Pro智能手机上,每幅图像的浮点运算(以FLOPs表示)和网络延迟被报告为加速评估
4.1.3

基准线
我们选择加速DMCNN (Sun et al ., 2018)和MBCNN (Zheng et al ., 2020)来验证我们的DDA方法的有效性。DMCNN是一种具有多尺度结构的图像去噪网络。MBCNN是一种最先进的解调网络,它包括一个可学习的带通滤波器来学习频率先验和一个两步色调映射机制来恢复颜色信息。我们根据PyTorch框架的重新实现,通过缩小网络宽度来报告基线模型及其紧凑版本的结果(Paszke et al, 2019)。
4.1.4
实现细节

我们的DDA实现基于PyTorch框架(Paszke等人,2019),组号M = 3,宽度列表W ={0.25, 0.5, 0.75}在FHDMi上,W ={0.4, 0.5, 0.6}在LCDMoire上。我们将LCDMoir´e和FHDMi数据集的原始图像分别拆分为512×512和640×540的子图像patch。然后,我们使用我们提出的摩尔纹先验将子图像块分成具有不同摩尔纹复杂度的多组。我们使用Adam (Kingma & Ba, 2014)优化器训练超级网络。所有实验的初始学习率和批大小都设置为1e-4和4。在训练过程中,我们在特定的摩尔纹复杂度类别中迭代提取一批图像对,用于训练从超级网络中提取的相应宽度的子网。对于DMCNN,我们给出200个epoch进行训练,在第100个epoch和第150个epoch的学习率除以10。对于MBCNN,我们遵循(Zheng et al ., 2020),如果连续四个epoch的验证损失下降量低于0.001 dB,则将学习率降低一半,一旦学习率低于1e-6,则停止训练。所有实验均在NVIDIA Tesla V100 gpu上运行。
4.2 性能分析
 在本节中,我们对DDA的不同组件进行了详细的性能分析,包括超级网络训练范式和莫尔先验。
在本节中,我们对DDA的不同组件进行了详细的性能分析,包括超级网络训练范式和莫尔先验。
4.2.1
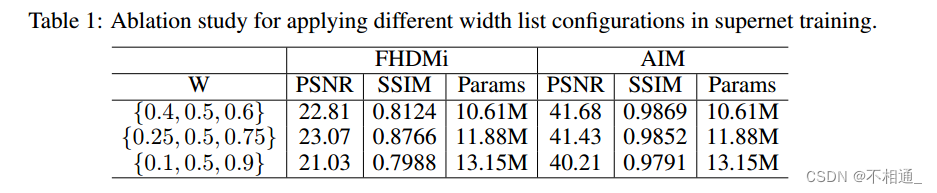
 我们首先利用MBCNN在FHDMi (He et al ., 2020)和LCDMoire (Yuan et al ., 2019)数据集上进行实验,研究超级网络训练中的超参数如何影响DDA、w.r.t和宽度列表配置w的性能。我们可以从表1中观察到,分散配置W ={0.25, 0.5, 0.75}在FHDMi数据集上表现更好,而紧凑配置W ={0.4, 0.5, 0.6}在LCDMoire数据集上表现更好。
我们首先利用MBCNN在FHDMi (He et al ., 2020)和LCDMoire (Yuan et al ., 2019)数据集上进行实验,研究超级网络训练中的超参数如何影响DDA、w.r.t和宽度列表配置w的性能。我们可以从表1中观察到,分散配置W ={0.25, 0.5, 0.75}在FHDMi数据集上表现更好,而紧凑配置W ={0.4, 0.5, 0.6}在LCDMoire数据集上表现更好。
为了解释这一点,LCDMoire是一个合成数据集,与使用嵌入式摄像机捕获的FHDMi相比,其中的摩尔纹分布更加平衡。一般来说,更离散的宽度列表保证了我们在实际场景中动态移除不同复杂性的摩尔纹斑块的目的.
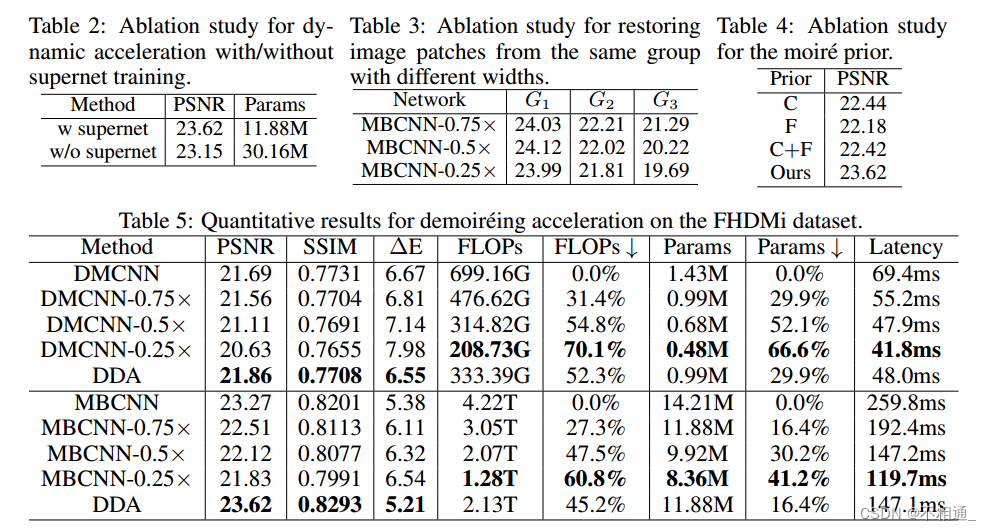 此外,表2比较了super- net训练和分别训练各子网络在LCDMoire上加速MBCNN的性能。可以看出,与同时保留多个子网相比,超级网络训练不会导致性能下降,并且大大减少了参数负担。结果很好地证明了我们的DDA在实际部署中的有效性。
此外,表2比较了super- net训练和分别训练各子网络在LCDMoire上加速MBCNN的性能。可以看出,与同时保留多个子网相比,超级网络训练不会导致性能下降,并且大大减少了参数负担。结果很好地证明了我们的DDA在实际部署中的有效性。

我们进一步分析了所提出的云纹先验的性能。实验采用MBCNN在FHDMi数据集上进行。我们使用不同宽度的网络来推断不同复杂度的图片组。表3的结果显示,对于最简单的组,所有宽度的表现相似,而对于具有最大摩尔纹复杂度的组,较大的宽度明显优于较小的宽度。这些结果证明了我们提出的摩尔纹先验的有效性,也验证了我们的观点,即使用大型网络来恢复具有低摩尔纹复杂度的斑块会浪费大量的计算资源。最后,我们研究了我们提出的云纹先验的三种变体,包括(1)仅使用高频信息(记为F),(2)仅使用色彩信息(记为C),(3)添加两个信息分数而不是在Eq.(2)中乘法(记为C+F)。如表4所示,所有变体都会导致更差的性能,这很好地证明了我们提出的摩尔纹先验算法的有效性,该算法同时考虑了云纹图案的颜色和频率特性。值得一提的是,C+F意味着色彩测量的主导地位,因为在我们的观察中,C给出的分数通常比F的分数高两个数量级。
因此,C+F的性能与C相似。相反,通过将两个分数相乘,我们的先验算法为给定的图像补丁提供了可靠的云纹复杂度
4.3


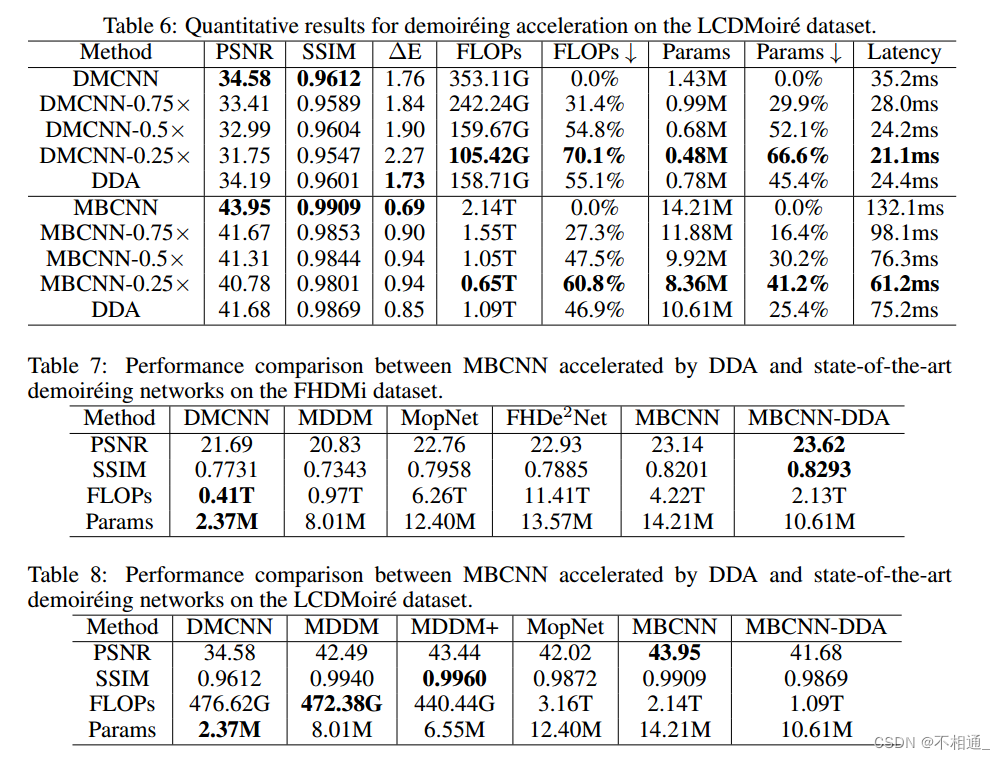
表5和表6给出了我们的DDA加速DMCNN和MBCNN的定量结果。
在FHDMi上,DDA惊人地提高了MBCNN的PSNR 0.35 dB,即使FLOPs降低了45.2%。我们将这样的结果归因于原始基线分配了相同的网络来恢复很少或没有摩尔纹图案的区域,这些区域可能会破坏图像的原始细节。因此,较差的性能阻碍了去摩尔纹网络在实际部署中的使用。相比之下,DDA利用最小的网络来恢复这些非摩尔纹区域,从而获得更好的全局去除效果。此外,我们通过比较由其加速的MBCNN与几种最先进的去摩尔纹网络,包括MDDM在FHDMi数据集上的有效性,证明了DDA的有效性。从表7可以看出,DDA在降低复杂性和去摩尔纹性能方面都优于其他网络。例如,DDA比fhde2net高出0.69dB PSNR 并且有着更少的FLOPs (DDA为2.13T, FHDe2Net为11.41T),这表明我们的观点:重新分配计算成本与图像补丁的云纹复杂性成比例 是正确和有效的
对于LCDMoire,与简单推断整个图像的DMCNN-0.75相比,我们的DDA根据斑块的云纹复杂度动态分配计算资源,保持了更好的PSNR性能(DDA为34.19 dB, DMCNN-0.75为33.41 dB)和更多的FLOPs降低(DDA为55.1%,DMCNN-0.75为31.4%)。同时,DDA通过加速MBCNN实现了56.9ms的显著延迟减少(DDA为75.2ms,基线为132.1ms),从而在移动设备上实现了实时图像提取。尽管如此,仍然观察到明显的PSNR性能下降(DDA为41.68 dB,完整模型为43.95 dB),并且与表8中最先进的网络(包括MDDM (Cheng等人,2019),MDDM+ (Cheng等人,2021)和MopNet (He等人,2019))的比较结果也表明DDA的结果相对较差。
在这里,我们认为 LCDMoire数据集是建立在模拟CFA和屏幕LCD亚像素之间的混叠的基础上的,这导致与智能手机捕获的云纹图像相比,图像具有不同的云纹图案分布。与具有不同云纹分布的智能手机捕获的FHDMi相比,LCDMoire 中的云纹图案更加均匀,其裁剪的云纹斑块具有相似的复杂性。这解释了DDA在LCDMoire数据集上相对较差的性能。请注意,我们的方法甚至在FHDMi上以更少的计算负担证明了基线模型的性能,并且与SOTA网络相比取得了更好的性能。鉴于我们在实际案例中实际部署图像去噪的动机,所提出的方法的有效性仍然是肯定的。
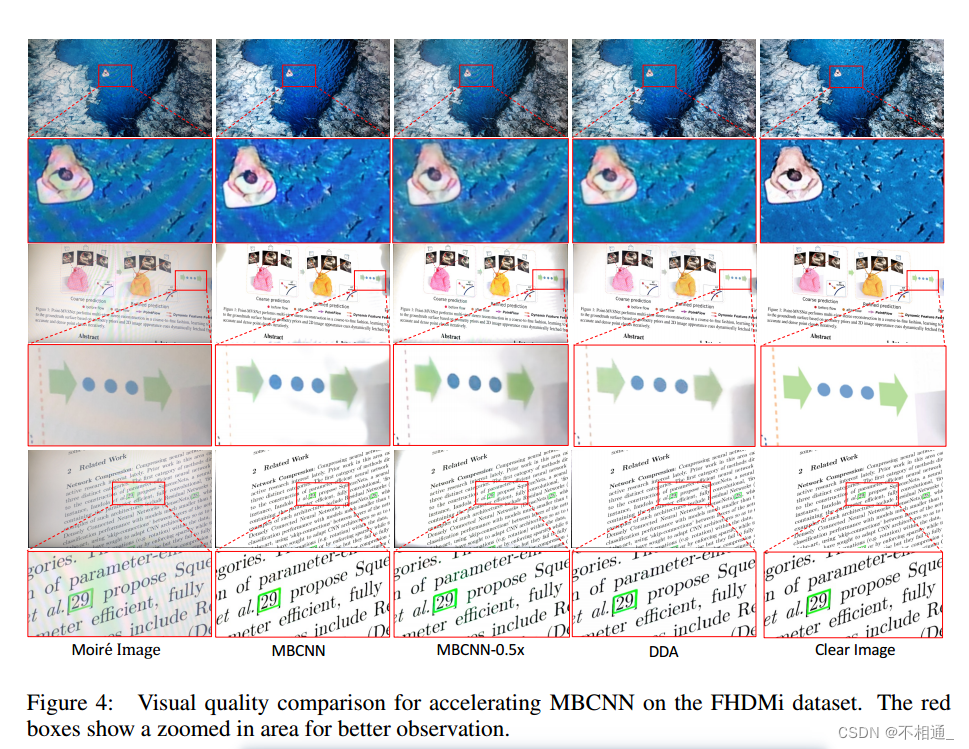
4.4 定性比较

 除了定量结果外,图4进一步展示了FHDMi数据集上恢复图像的可视化结果。LCDemoire数据集的结果可在附录A.2中找到。可以看出,对整个图像均匀执行相同的加速速率(MBCNN-0.5X),但由于具有密集云纹图案的区域没有足够的计算资源来有效地恢复,因此大大降低了性能。
除了定量结果外,图4进一步展示了FHDMi数据集上恢复图像的可视化结果。LCDemoire数据集的结果可在附录A.2中找到。可以看出,对整个图像均匀执行相同的加速速率(MBCNN-0.5X),但由于具有密集云纹图案的区域没有足够的计算资源来有效地恢复,因此大大降低了性能。
相比之下,通过动态分配计算资源,与原始网络相比,我们的DDA获得了很好的去噪质量。因此,我们提出的DDA在实际应用中加速解调网络的有效性得到了很好的证明。
5.局限性与未来工作

我们将进一步讨论DDA的局限性,这将是我们未来的重点。首先,DDA简单地将所有图像在每个类别中划分为相等数量的patch,为未来设计图像感知分类先验的研究奠定了一些途径。此外,我们有限的计算设备阻止了我们加速其他具有不同结构的去摩尔纹网络预计将进行更多的验证以进一步证明DDA的有效性。
 6.结论
6.结论
在本文中,我们提出了一种新的动态解调加速方法(DDA),以减少现有网络在移动设备上实时去摩尔纹的巨大计算负担。我们的DDA是基于观察到的云纹复杂性在图像的不同区域是高度不平衡的。在此基础上,我们建议将整个图像分割成子块,然后根据它们的云纹复杂性进行重组,该摩尔纹复杂性由考虑频率和色彩信息的新型摩尔纹先验测量。然后,我们使用不同大小的模型来恢复每一组的斑块。其中,利用较大的网络恢复云纹中心化区域以保证恢复质量,利用较小的网络恢复云纹稀释区域以减轻计算负担。为了避免保留多个网络带来的额外参数负担,我们进一步利用超级网络范式以参数共享的方式联合训练网络。几个基准测试的结果表明,我们的方法可以有效地降低现有网络的计算成本,而性能下降可以忽略不计,从而实现当前智能手机的实时去摩尔纹。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









