






sed
sed 是一种流编译器 流编译器会在编译器处理数据之前基于预先提供的一组规则来编辑数据流
sed编译器可以根据命令来成功优酷数据流中的数据 这些命令要么命令行 要么存储一个命令文本文件中
sed处理命令方式是从上往下处理
sed工作主要有三个过程:
1.读取:sed 从输入流 (文件 管道符号 标准输入)中读取一行内容并存储到临时的缓冲区中
2.执行:使用sed进行增删改查命令来处理读取到缓存区的行数据
3.显示: 将处理后的行数据 输出到屏幕中
命令格式:
1.sed -e ‘操作’ 文件1 文件2 .........
当sed操作命令大于一条时 一定要加上-e操作 只有一条命令的时候-e可以不用加
2.sed -f 脚本文件 文件1 文件2
-f 表示指定的脚本文件来处理输入文件
常用选项:
-h: 表示显示帮助
-n:禁止sed编译器输出,但可以与p命令一起使用完成输出
-i:修改目标文件 #当我们不使用-i的时候 是修改不了配置文件的
常用操作:
s:替换 替换指定字符
d:删除 删除选定的行
a:增加 再当前行下面增加一行指定内容
i:插入 在选定行上面插入一行指定内容
c:替换 将选定行替换为指定内容
y:字符转换 转换前后的字符长度必须相同
p:打印 要跟着-n选项一起使用
可根据n的变量实现跨行打印
sed -n -e '2,${n;p}' 文件名
第一次过程 读取 第二行 执行 先n 跳到下一行 (第三行) 再p 打印第三行内容
第二次过程 读取 第四行 执行 先n 跳到下一行 (第五行) 再p 打印第五行内容
第三次过程 读取 第六行 执行 先n 跳到下一行 (第七行) 再p 打印第七行内容
打印
打印内容 p(打印行内容) =(打印行号) l(打印ASCII字符)
sed -n -e '行号区间p' #根据行号或行区间进行打印
sed -n -e '/字符串/p' #根据字符串匹配行进行打印
sed -n -r -e '/正则表达式/p' #根据正则表达式匹配行进行打印
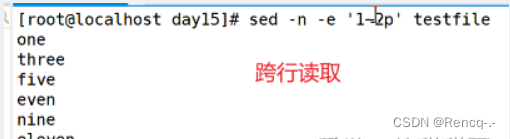
sed -n -e '1~2p' #从第一行开始每隔2行查看
sed -n '1,+3p' testfile1 #打印1之后的连续3行,即1-4行
sed '5q' testfile1 #打印前5行信息后退出,q表示退出
sed -n 'p;n' testfile1 #打印奇数行;n表示读取下一行,覆盖模式空间前一行
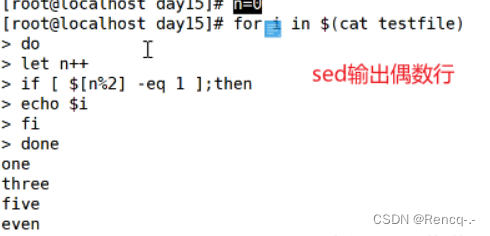
sed -n 'n;p' testfile1 #打印偶数行
替换
行范围 s/旧字符串/新字符串/替换标记
s:表示字符串替换
c:整行内容替换
y:对应字符替换
4种替换标记:
数字:表明新字符串将替换第几处匹配的地方
g:表明新字符串将会替换所有匹配的地方
p:打印与替换命令匹配的行,与-n一起使用
w 文件:将替换的结果写到文件中
注意使用替换命令的时候 我们可能会感觉很杂很乱 这时候可以选择不用\换一个字符来代替
插入: 在选定行上面插入一行指定内容
删除
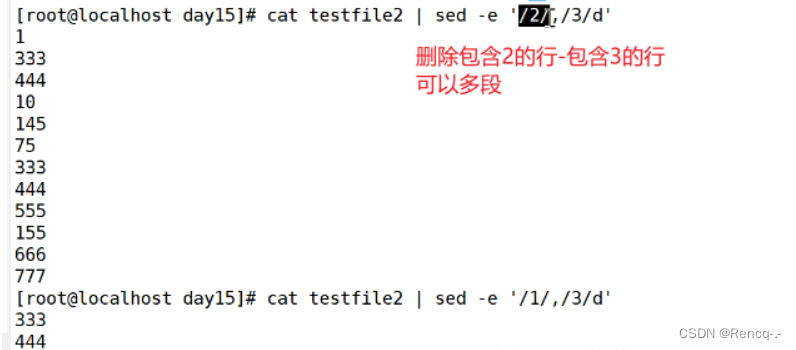
sed -e '行号区间d'
sed -e '/字符串/d'
sed -r -e '/正则表达式/d'
注释行
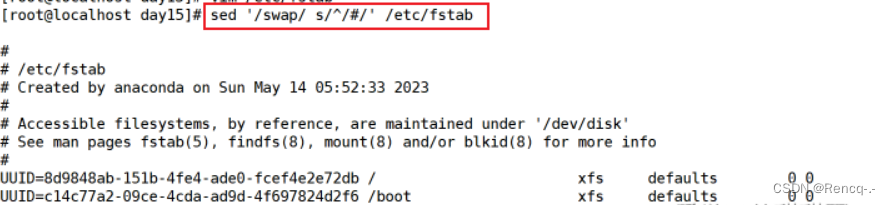
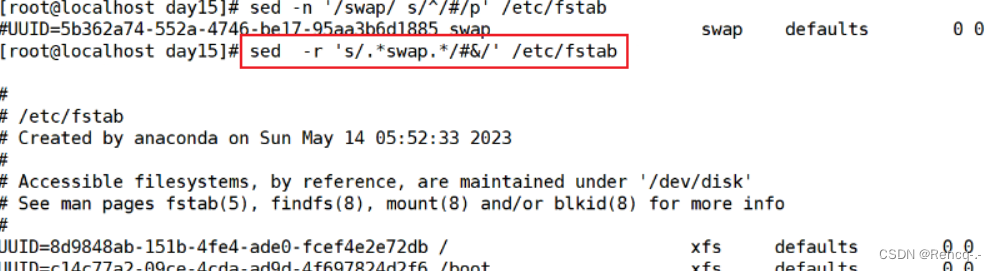
sed -i 's/.*XXX.*/#&/'
'行号 s/^/#/'
sed -e '行号c 新行内容'
sed -e '/字符串/c 新行内容'
sed -e 'y/旧字符/新字符/' #注:新字符和旧字符的长度要一致
插入
a(在指定行下面插入行内容) i(在指定行上面插入行内容) r(在指定行下面插入整个文件内容)
sed -e '行号区间a 行内容'
sed -r -e '/字符串或正则/a 行内容'
sed -e '行号区间i 行内容'
sed -r -e '/字符串或正则/i 行内容'
sed -e '行号区间r 文件'
复制粘贴
sed -e '1,3H;$G' #将1-3行内容复制粘贴到最后一行下面
sed -e '1,3{H;d};$G' #将1-3行内容剪切粘贴到最后一行下面
实验
输出偶数行
awk
awk工作原理
命令格式:
awk 选项 ’条件 (操作)‘ 文件1 文件2 .......
awk -f 脚本文件 文件1 文件2............
awk常见内建变量
FS:列分隔符 指定每行文本的字段分隔符
NF:当前处理的行的字段个数
NR:当前处理的行的行号 #如果想处理多行内容的话NR后面加逗号 然后再NR
$0 当前处理的行的整行内容
$n当前处行的第n个字段
FILENAME:被处理的文件名。
RS:行分隔符
按行输出文本
awk '{print}' testfile2 #输出所有内容
awk '{print $0}' testfile2 #输出所有内容
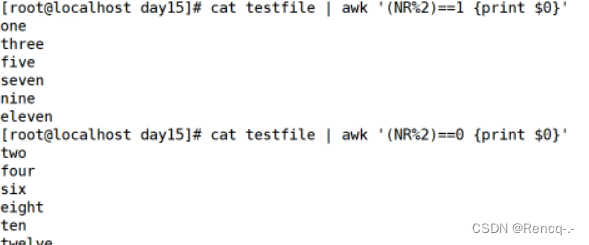
awk 'NR==1,NR==3{print}' testfile2 #输出第 1~3 行内容
awk '(NR>=1)&&(NR<=3){print}' testfile2 #输出第 1~3 行内容
awk 'NR==1||NR==3{print}' testfile2 #输出第1行、第3行内容


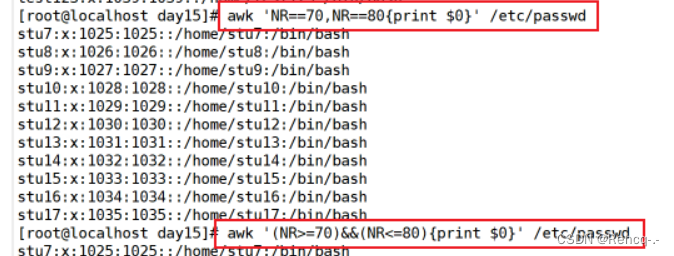
awk '(NR%2)==1{print}' testfile2 #输出所有奇数行的内容
awk '(NR%2)==0{print}' testfile2 #输出所有偶数行的内容
awk '/^root/{print}' /etc/passwd #输出以 root 开头的行
awk '/nologin$/{print}' /etc/passwd #输出以 nologin 结尾的行
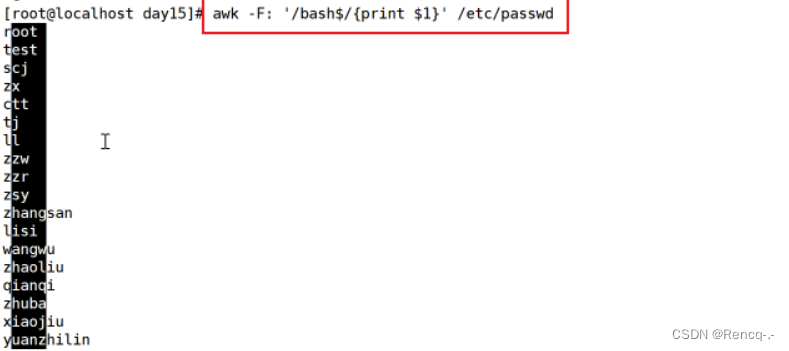
awk 'BEGIN {x=0};/\/bin\/bash$/{x++};END {print x}' /etc/passwd #统计以/bin/bash 结尾的行数,等同于 grep -c "/bin/bash$" /etc/passwd

awk -F '字段分隔符' '条件{print NR; print $0}' 文件 #换行输出行号和行内容
awk -F '字段分隔符' '条件{print NR} 条件{print $0}' 文件
awk -F '字段分隔符' '条件{print NR,$0}' 文件 #同行输出行号和行内容
awk -F '字段分隔符' 'NR==n {print $0}' #输出 第n行的 整行内容
awk -F '字段分隔符' 'NR==n {print $1}' #输出 第n行的 第一个字段的内容
awk -F '字段分隔符' 'NR==n {print $1,$NF}' #输出 第n行的 第一个字段和最后一个字段的内容
awk -F '字段分隔符' 'NR==n,NR==M {print $1}' #输出 第n行到第m行的 第一个字段的内容
awk -F '字段分隔符' 'NR>=n&&NR<=M {print $1}'
awk -F '字段分隔符' 'NR==n||NR==M {print $1}' #输出 第n行和第m行的 第一个字段的内容
awk -F '字段分隔符' '/字符串/ {print $1}' #输出 包含指定字符串的行的 第一个字段的内容
awk -F '字段分隔符' '/正则表达式/ {print $1}' #输出 匹配正则表达式的行的 第一个字段的内容
awk -F '字段分隔符' '$1>=n {print $0}' #输出 第一个字段的数值大于等于n的 整行内容
== != >= > <= <
awk -F '字段分隔符' '$1~"字符串" {print $0}' #输出 第一个字段包含指定字符串的 整行内容
~(包含) !~(不包含) ==(等于) !=(不等于)
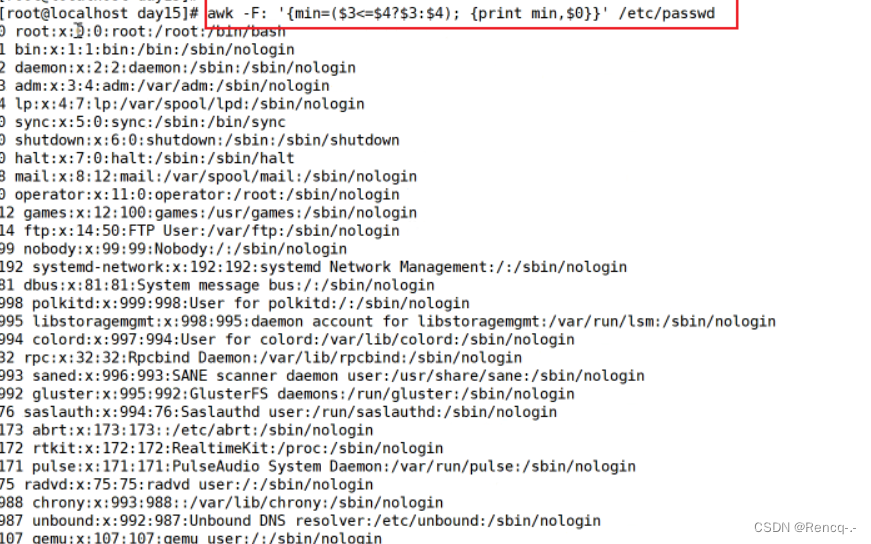
通过管道、双引号调用 Shell 命令
free | awk '/Mem:/{print int($3/$2*100)"%"}' #内存使用率
top -b -n1 | awk -F, '/%Cpu\(s\)/{print $4}' | awk '{print 100-$1"%"}' #CPU使用率
df | grep -w "/" | awk '{print $5}' | awk -F% '{print $1}' #磁盘分区容量使用率
echo $PATH | awk 'BEGIN{RS=":"};END{print NR}' #统计以冒号分隔的文本段落数,END{}语句块中,往往会放入打印结果等语句
awk '(NR%2)==1 {print $0}' #输出奇数行
awk '{print $0; getline}'
sed -n 'p; n'
awk '(NR%2)==0 {print $0}' #输出偶数行
awk '{getline; print $0}'
sed -n 'n; p'
总结sed是对整行处理 awk是对于整个字段处理

















 369
369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









