






目录
摘要
本周阅读的文献中提出了一种相互适应的群体深度学习框架,不同于深度互学习中模型间互相学习,该框架是通过选择一个最优原型模型,使深度学习模型能够从原型模型中学习以进行时间序列预测。通过深度网络原理,推导出要实现同样功能时,使用浅层网络比深层网络需要更多的参数,因此模型更容易过拟合并且需要更多的数据。适量增加深度,深度学习效果可以更好,其参数量可以更少。
Abstract
The literature read this week proposes an adaptive group deep learning framework, which unlike deep mutual learning, allows the deep learning model to learn from the prototype model for time series prediction by selecting an optimal prototype model. Based on the deep network principle, it is deduced that the shallow network needs more parameters than the deep network to achieve the same function, so the model is easier to overfit and require more data. When depth is properly increased, deep learning can be better and the number of parameters can be reduced.
1. 文献阅读:相互适应:从原型中学习时间序列预测
title:Mutual adaptation: learning from prototype for time series prediction
time:2023
DOI:10.1109/TAI.2023.3282201
1.1. 研究背景
传统时间序列预测方法
时间序列预测广泛研究了几种方法,包括机器学习、统计模型和深度学习,以从不同的角度解决这个问题。以前的方法包括时间序列分析和信号处理。Prophet、ARIMA、SARIMAX是时间序列分析的统计模型。时间序列分析关注的是理解时间序列数据的底层结构,包括趋势、季节模式和随机波动。因此,这些方法将时间序列数据分解为趋势、周期变化和不规则时间表,并将这三个方程与历史数据拟合,预测未来。在信号处理中,马尔可夫链根据前一步的观测结果预测未来,利用历史数据拟合各时间步之间的概率转移矩阵。小波分析方法利用小波函数将时间序列分解成不同的频带,可以同时捕捉信号的短期和长期特征,该方法在处理非平稳和不规则时间序列数据方面具有较好的效果。
深度学习在时间序列预测的应用
深度学习已经被证明是解决时间序列预测问题的一种非常有效的方法,因为它能够对输入和输出变量之间复杂的非线性关系进行建模。然而,现实世界的数据总是非平稳的。随着时间的推移,统计性质和联合分布发生了不断的变化。预测变量所处的环境总是随着时间的推移而变化,这就使得影响预测序列的因素发生了变化。这给预测带来了很多不确定性。在某些情况下,当我们对天气等影响因素没有清晰的认识或充分的观察时,变量变得难以预测。
深度互学习
深度互学习被用于提高计算机视觉中图形标记的准确性,该方法的基本概念是将一些具有相同结构或具有相似学习能力的深度学习模型放在一个结构中。在训练过程中,每个组件模型都会消耗相同的输入,并相互共享它们的输出。然后,每个模型同时从基础事实中学习,并通过Kullback-Leibler距离从其他模型输出。这种方法背后的核心思想是在一个共同的框架内训练多个不同类型或不同初始化的深度学习模型,该框架允许模型从其他模型的基本事实和知识中学习,以便找到更好的收敛点。
1.2. 现有问题
1)由于时间序列数据的复杂性,一个单独的模型需要学习多个不同的数据分布,因此时间序列预测任务中的建模通常是非凸的,这可能使最终的收敛不稳定,并在变分布上失去泛化。
2)为了解决不收敛问题,提出的深度相互学习框架,有一个关键缺点是由于每个单独的模型由于初始化的不同而处于不同的局部最优,所以在训练过程中,每个组件模型都是一个学生,从其他组件模型中学习,同时从其他成员的ground truth和结果中学习,因此收敛到较差的局部最优的模型可能仍然会共享它们的知识,从而限制了整体性能。
1.3. 解决方案
1)有一种更具选择性的方法,其中基于相对于基础真值的最小损失,选择原型模型作为共同学习目标。在训练过程中,只有原型模型的知识被提炼到其他模型中。
2)在本研究中,提出了一种称为相互适应的群体深度学习框架,该框架通过选择一个原型模型作为共同教师来更好地指导小组学习。此外,每个模型都被鼓励记住它在学习过程中找到的最佳局部最优,该框架使深度学习模型能够从原型模型中学习以进行时间序列预测。
3)为了防止原型模型的过度引导,建议在每个模型中添加自记忆。
1.4. 提出框架和结构
相互适应的学习框架
相互适应的学习框架选择一个原型模型作为训练期间所有其他模型的共同老师。在每个训练历元中,找到当前最优局部最优的模型,或与地面真实值误差最小的最优模型作为原型模型。
原型模型的输出用作所有其他模型的附加学习目标。为了避免被原型模型误导,每个模型还会记住自己的历史最优。在学习过程中,每个模型同时从地面真相、原型模型和自己的记忆中学习最优的局部最优。与个体学习相比,
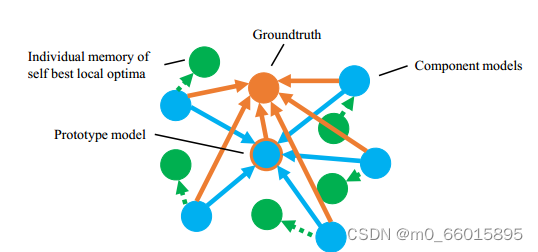
橙色点表示地面真相,蓝色点表示组件模型。在这个框架中,每个组件模型从基础事实和其他模型生成的所有输出中学习,从而得到b
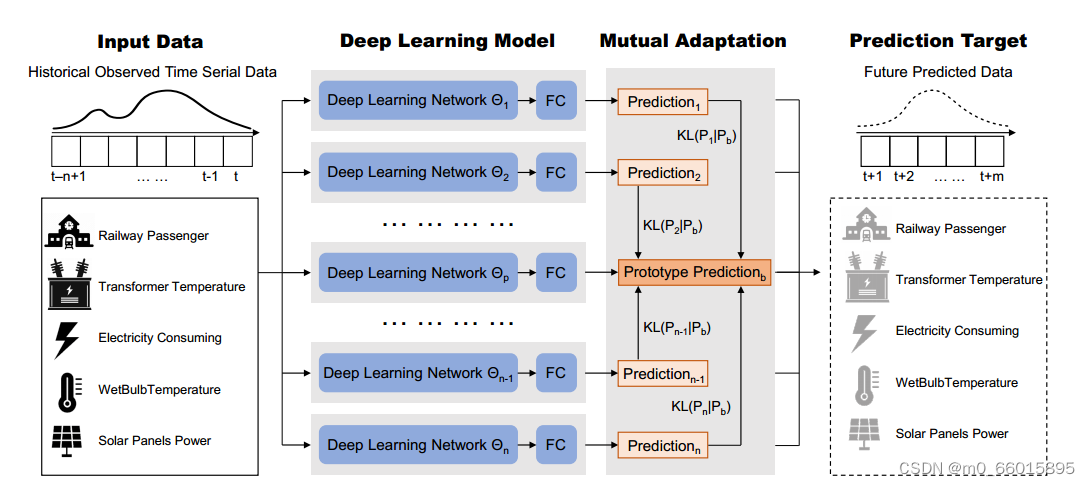
相互适应结构
基于这一思路,在本研究中,我们提出了对原型模型的选择。每个模型也会通过Kullback-Leibler散度的方式向共同的原型模型学习。该过程将框架中具有相同结构的多个时间序列预测模型合并在一起,这与相互学习类似,从而可以更广泛地搜索最优解。组件模型的初始化是不同的。这使得它们在训练过程中往往会导致不同的局部最优。在框架中,每个组件模型有三个学习目标。(1)接地真值:首先,输出需要符合接地值。(2)原型模型:在训练的每个历元,给模型输入相同的训练数据。由于初始化的不同,它们会给出不同的输出。所有模型的输出将与groundtruth进行比较,并选择最佳(与groundtruth误差最小)作为原型模型。这是我们提出的相互适应的核心。与深度相互学习的不同之处在于,它为所有组件模型设置了一个共同的学习目标。(3)自学习:在训练过程中,每个模型都会记住与groundtruth误差最小的输出。在每个时期,每个模型都会将它们的输出与它们记忆的历史最佳输出进行比较。这就是第三个学习目标。经过训练后,模型会选择训练最好的模型进行预测
1.5. 实验
1.5.1. 数据集
使用几个时间序列数据集进行实验。数据集包括一个我们自己的JR站检票口数据集以及6个开放数据集。接下来,我们对这些数据集做一些简要的介绍。
1.5.2. 评估指标
mae(平均绝对误差)和mse(均方误差)
1.5.3. 实验目的
通过在框架中分别合并Informer和LSTM模型,同时保持模型的公共超参数相同,来测试所提出的学习框架的有效性。
1.5.4. 实验设置
在几个开放和私有数据集上进行实验,将我们提出的方法与其他基线方法的性能进行比较。分别比较Informer(一种基于transformer的模型)和LSTM(一种经典的基于rnn的模型)在相互适应和深度相互学习方面的性能。进行了测试来验证记忆每个个体学习历史中的最佳局部最优的功能。
1.5.5. 实验结果
当组件模型为Informer时,与深度相互学习相比,相互适应在MAE和MSE方面的平均性能分别提高了4.38%和6.56%。对于具有输入嵌入的LSTM模型,相互适应使MAE和MSE的误差分别降低了11.35%和17.81%。
此外,基于相互适应的Informer在MAE和MSE上的平均表现比单个Informer高出7.05%和10.28%。对于LSTM,相互自适应使MAE和MSE的准确率分别提高了12.62%和18.99%。与深度相互学习相比,我们提出的相互适应在提高单个深度学习模型的性能方面表现出更强大和稳健的能力。因此认为在目前的研究阶段,相互适应有可能成为最先进的深度学习框架。
1.6. 文献贡献
1)提出了一种创新的深度学习群体学习框架,与个体学习相比,该框架可以提高深度学习模型的准确性。此外,我们提出的框架表现出比深度相互学习更好的性能,深度相互学习是小组学习中最先进的框架。
2)推荐允许学习框架中的组件模型记住它们自己在历史上发现的最佳局部最优。
3)对训练过程进行系统分析,包括原型模型的变化规律、损失下降过程以及框架中模型数量的敏感性分析。
为什么需要深度学习
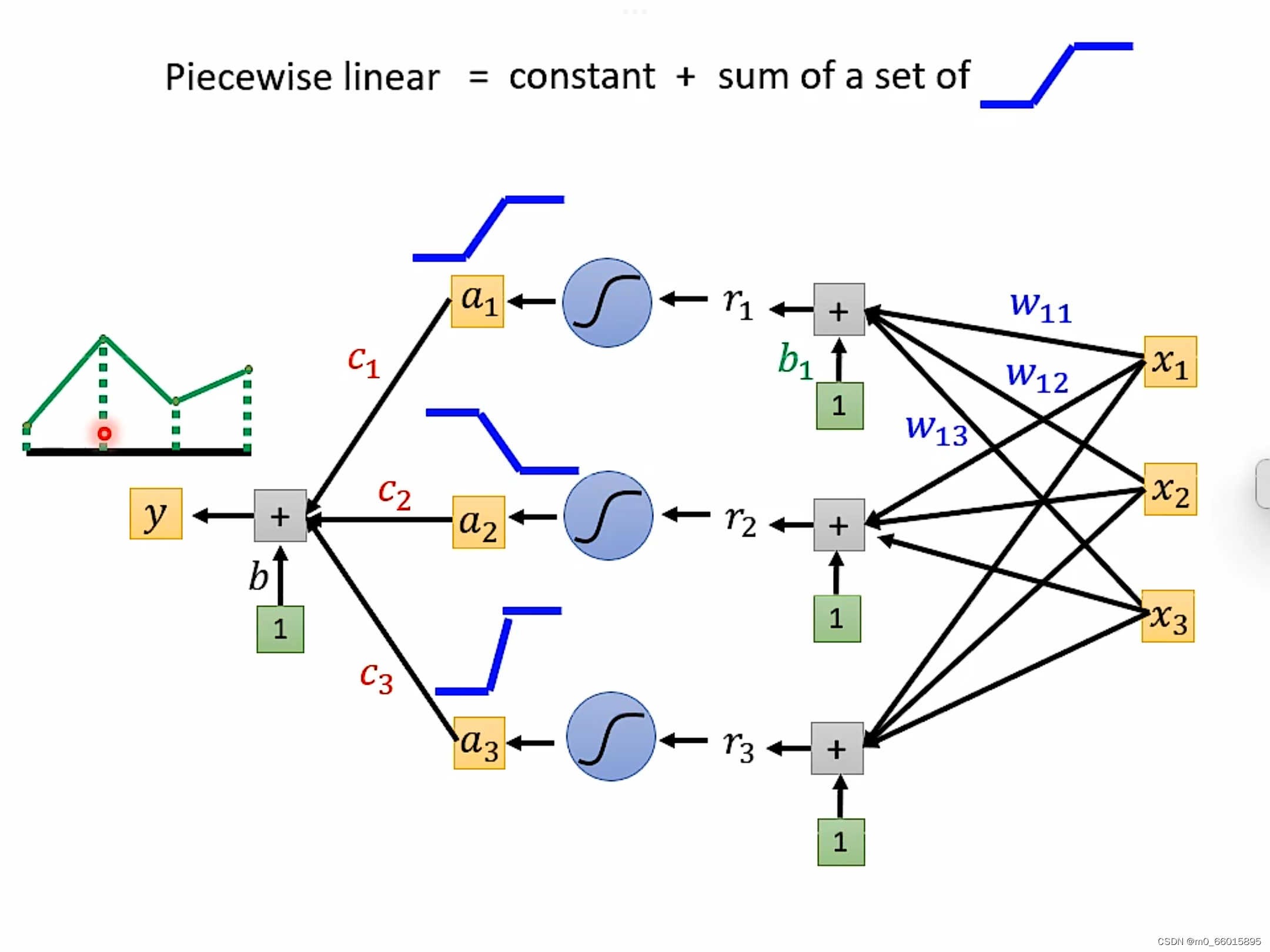
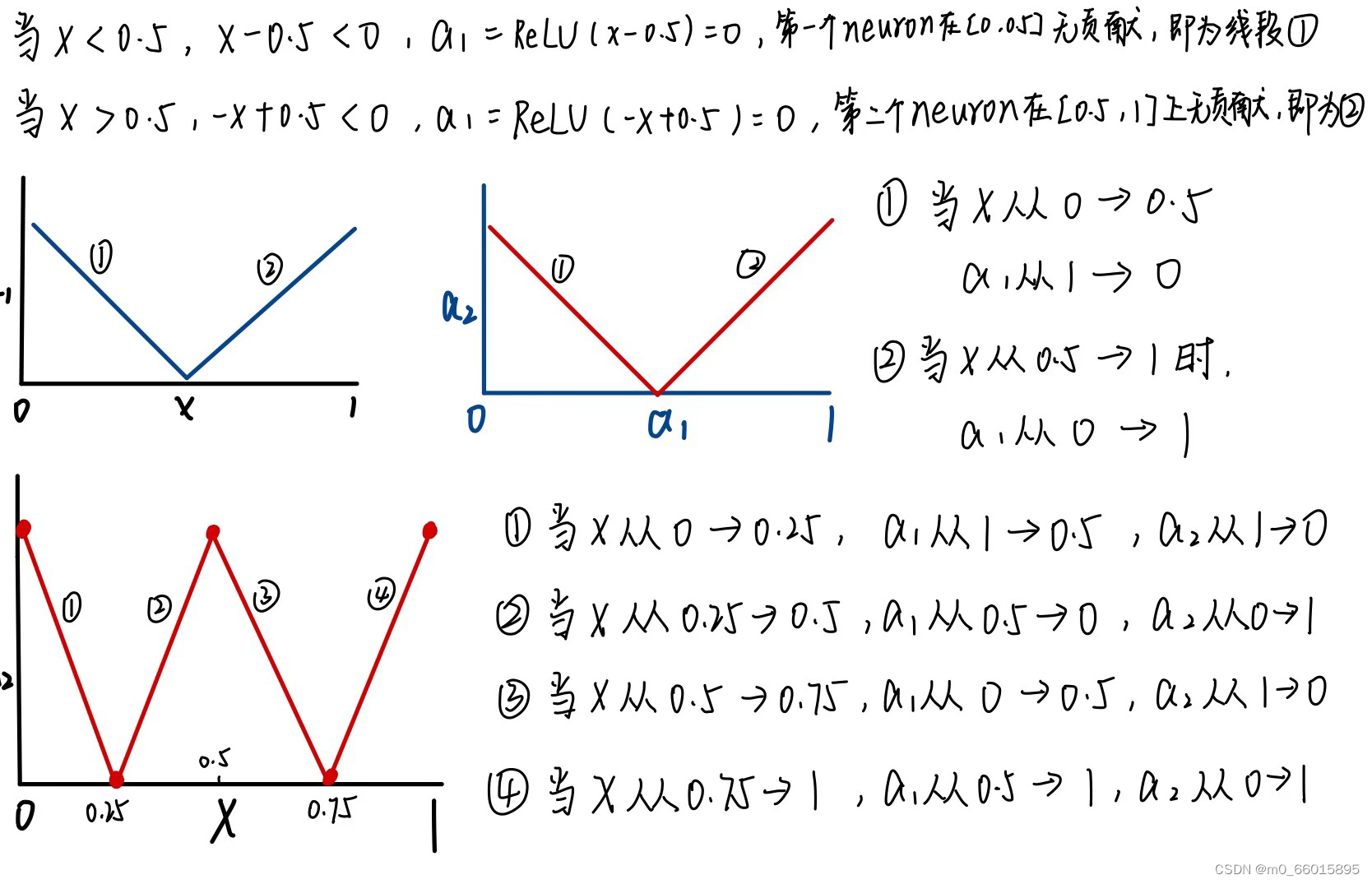
通过深度学习可以制造出所有可能的function。下图输入是图中C轴,输出是Y轴,怎么找到一个function用神经网来产生这条线呢?只要分的点足够的细,即生成的直线越多,就越能逼近曲线。
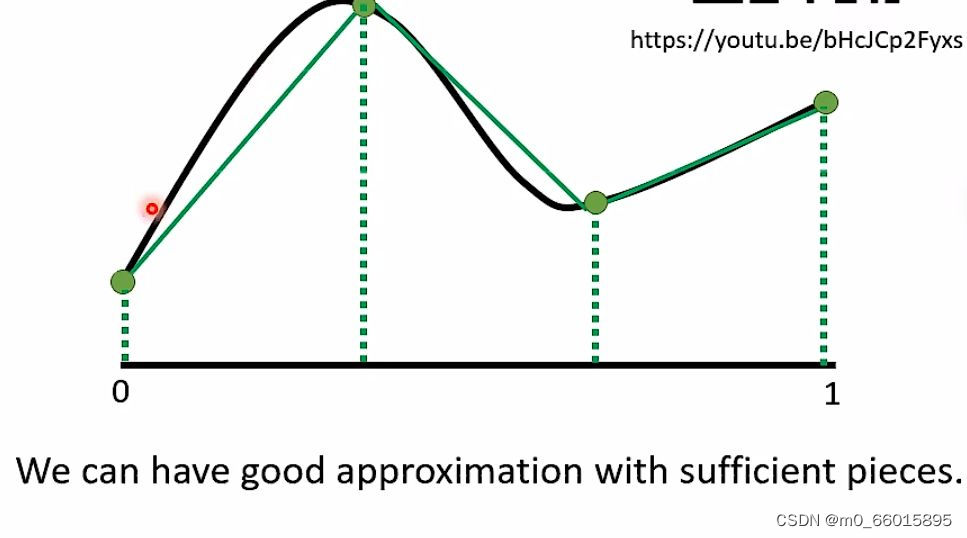
piecewise linear = 常量+若干个neuron。即这个绿色的线,可以由每一个neural产生的蓝色的线拼凑而成,任何再复杂的function只要有足够的neuron就可以产生。

为了表现这个function,最后经过sigmoid把它曲线化,结果化为0-1之间的数值。
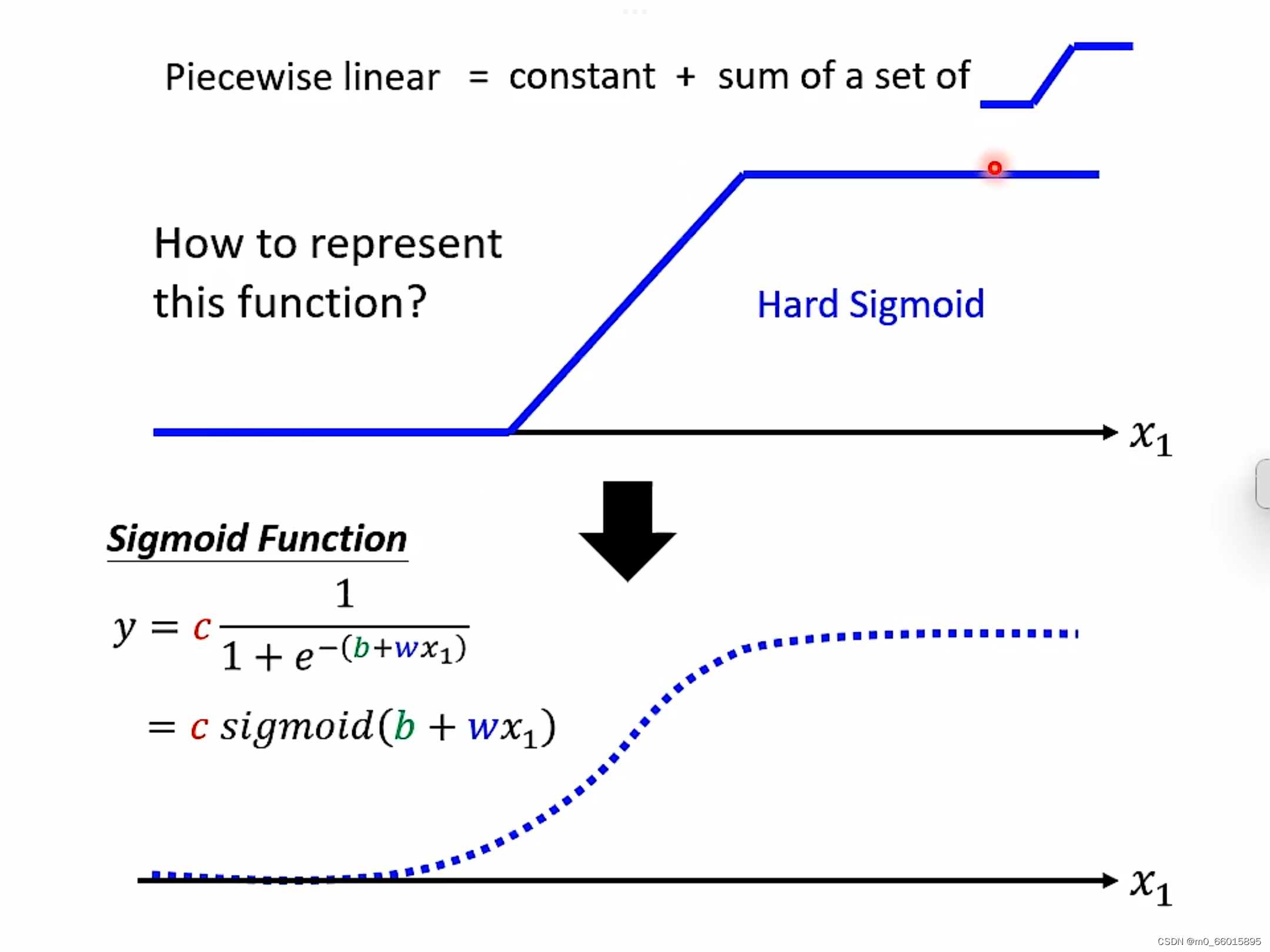
通过设置不同weigh权重以及不同的bias制造出不同的sigmoid function,把他们统统加起来再加上常数,你可以得到任何的picewiselinear function。
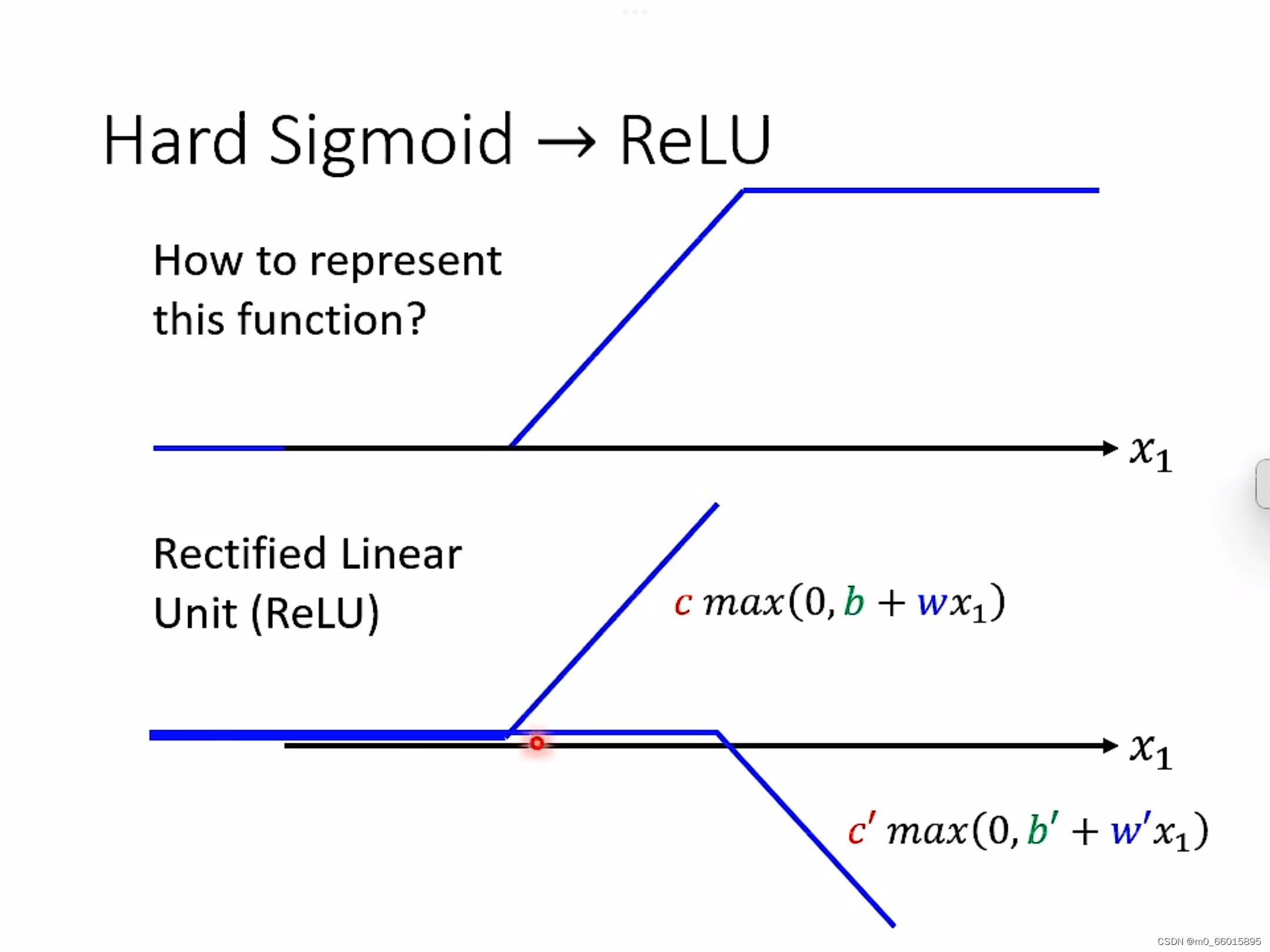
Hard Sigmoid的另一种方法就是ReLU,可以把sigmoid换成ReLU,两个ReLU可以合成一个hard sigmoid,够多的hard sigmoid就能形成piecewiselinear function,而picewiselinear function可以逼近任何的function。
深度学习更好吗
如果有更多的数据,那么最好的选择就是使用性能更好的深度网络来处理,对于深度学习,当神经网络越来越深时,H就越来越大,这就代表你的理想越来越好。很多时候,使用的数据越多,结果就越准确。而经典的ML方法需要一组复杂的ML算法,而更多的数据只会影响其精度,需要使用复杂的方法来弥补较低准确性的缺陷。此外,学习也受到影响,即当添加更多的训练数据来训练模型时,学习几乎在某个时间点停止。
但在实际应用上,neuron越深错误率可能越低,但是越深的neuron产生的模型就会越复杂,那么理想的loss就会很低,要想要现实和理想接近,按照公式可以得出,就需要有更多的Data。

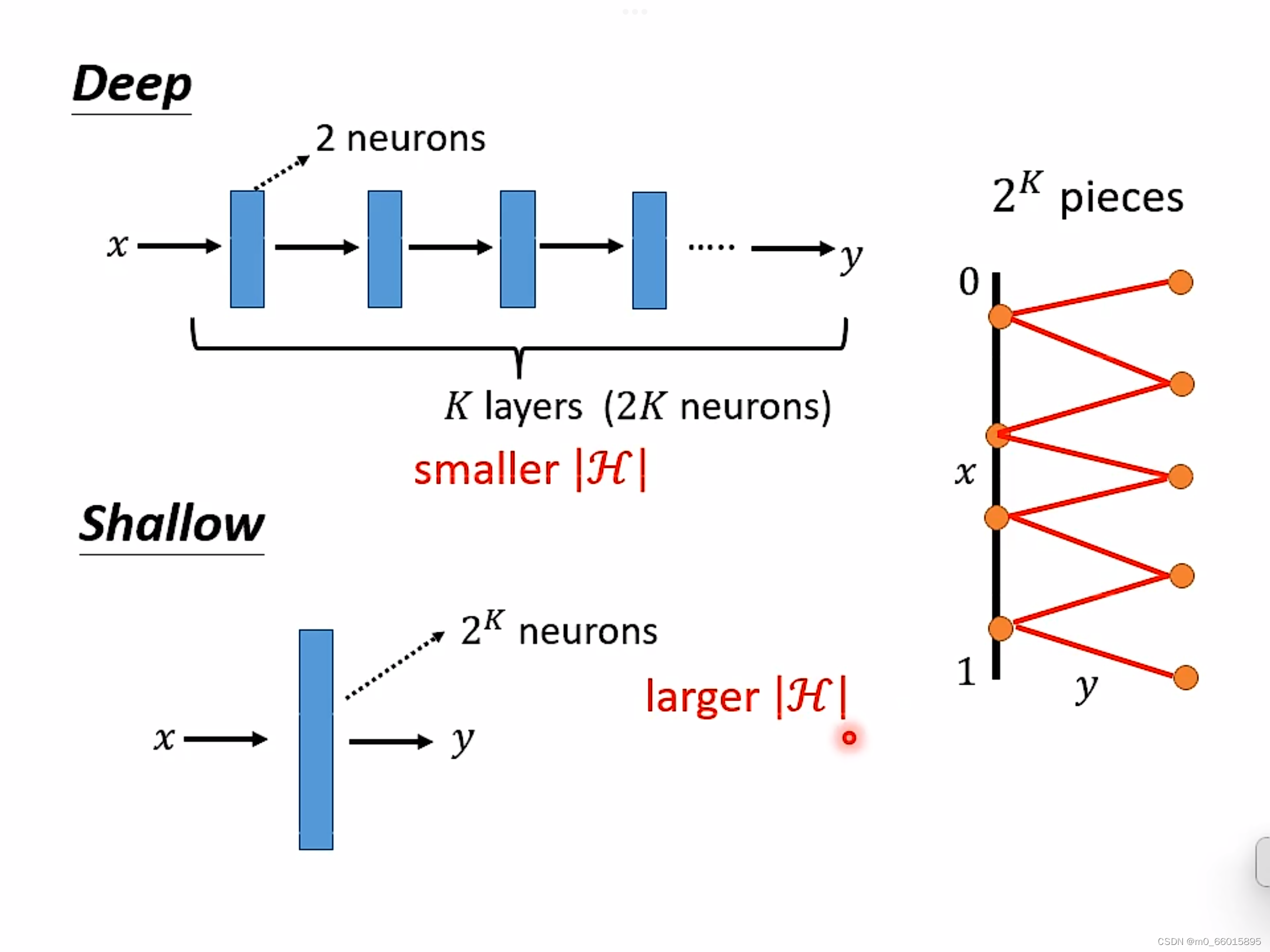
当参数一样的时候,是选择层数少neuron多的,还是选择层数深neuron少的更好?
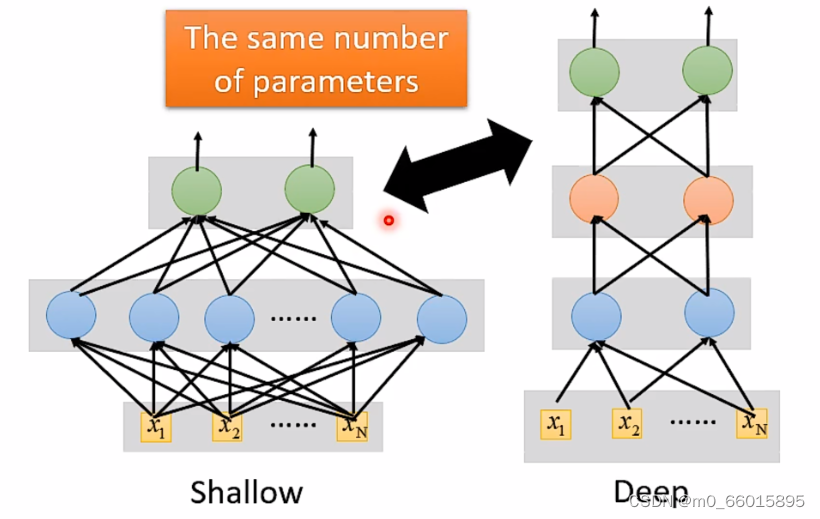
Q:从测试结果的错误率来看,当参数量一样时高瘦明显比矮胖效果更好。这是为什么呢?
A:因为实现同一个funciton时,深的只需要比胖的更少的参数就能达到效果。
事实上,在实现同一个复杂函数时,使用深度较大宽度较小的网络,相较于只有一层而宽度很大的网络来说,其参数量会小很多,也就是说其效率会更高,同时参数量小也就说明需要的训练数据量也会小,也就更加不容易过拟合。
总而言之,深度学习可以使得function的集合H的大小减小,并且效果也能够与宽度很大的神经网络相当。如果让你loss很低的那个function是复杂且有规律的(语音、影像等),那么deep neuron会优于shallow neuron,深度学习的效果可以更好,其参数量可以更小。
深度学习的优点:
1)深度学习可以用更多的数据或是更好的算法来提高学习算法的结果。对于某些应用而言,深度学习在大数据集上的表现比其他机器学习(ML)方法都要好。
2)性能表现方面,深度学习探索了神经网络的概率空间,与其他工具相比,深度学习算法更适合无监督和半监督学习,更适合强特征提取,也更适合于图像识别领域、文本识别领域、语音识别领域等。
3)深度学习不以任何损失函数为特征,也不会被特定公式所限制,它能以比其他传统机器学习工具更好的方式进行使用和扩展。
Deep Network
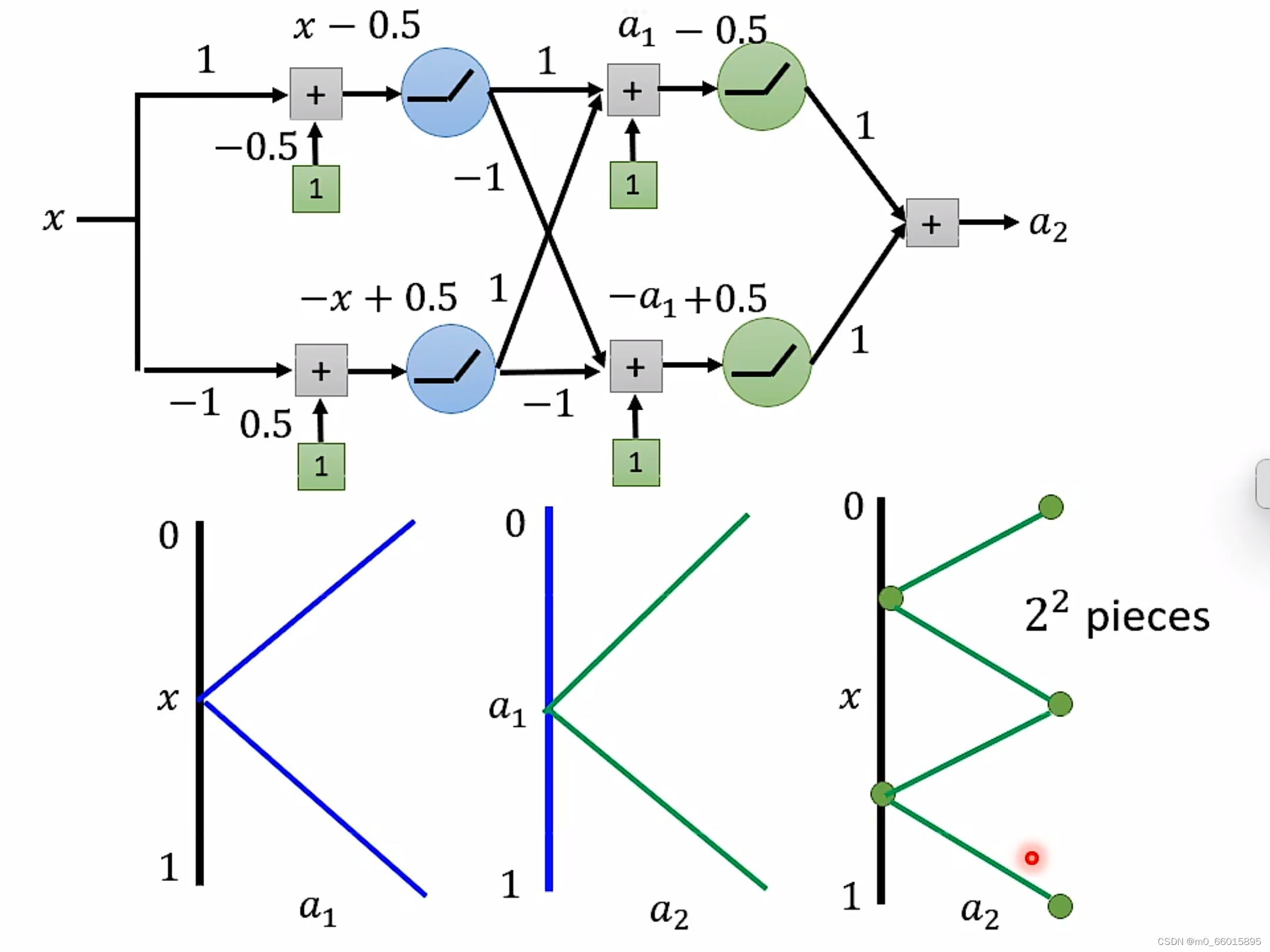
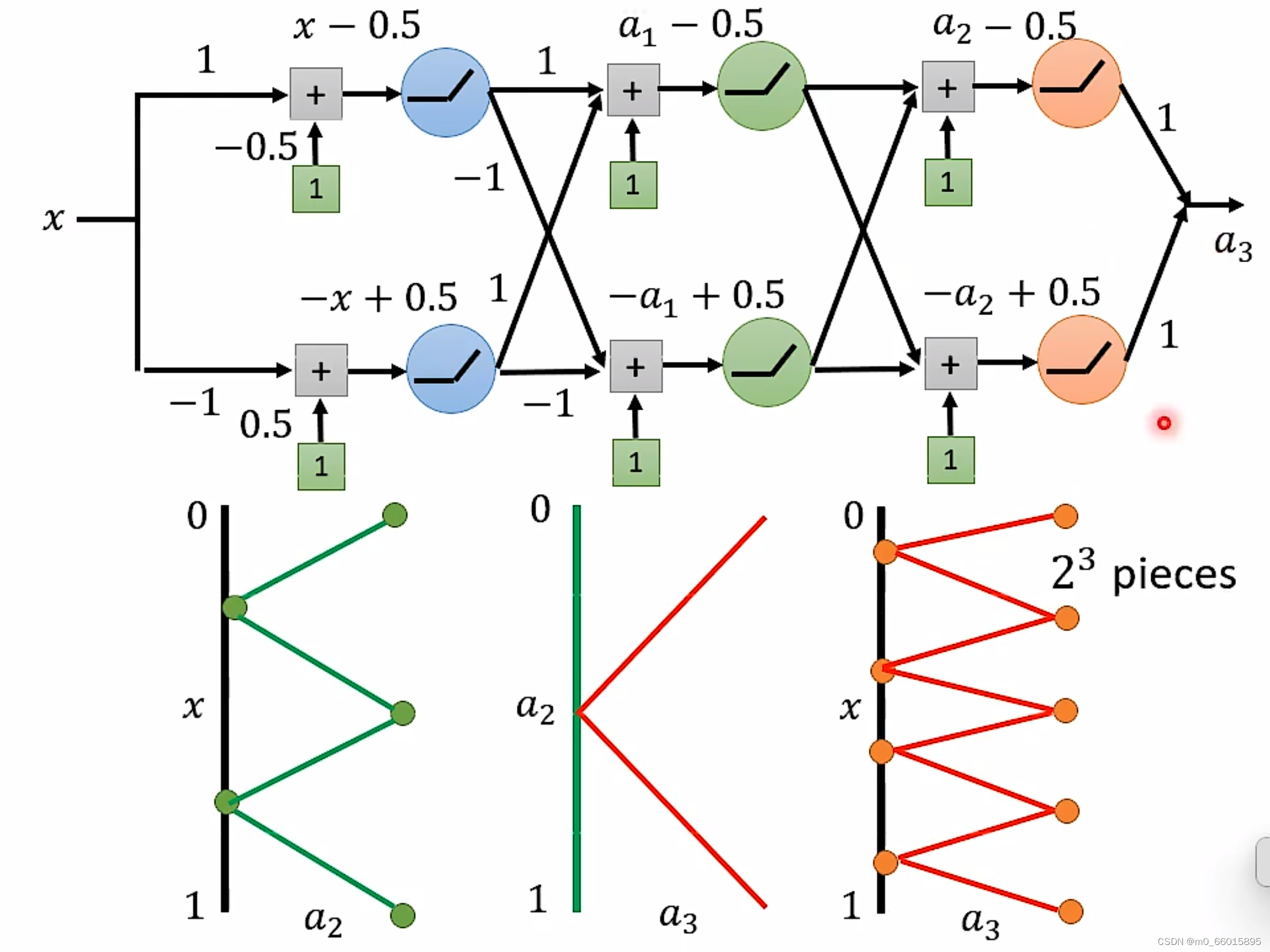
如果同样要实现
的锯齿线段,两者之间区别:
对于Deep来说,每一层只需要两个neuron,有K层,因此总共需要2K个neuron即可。
对于Shallow来说,只有一层,如果使用ReLU,那么每一个neuron只能产生一条线段,那么要生成
要产生同样的function,Deep的neuron参数量比较小,它有有比较简单的模型,而Shallow的参数量比较大,需要一个比较复杂的模型。而复杂的模型因为比较容易过拟合,因此需要大量的资料。由此可是,要做到同样的事情,Shallow需要的资料远远大于Deep。
总结
机器学习在时间序列预测方面的研究存在多种研究方法,下周将继续学习这方面的文献。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









