






目录
文献阅读:支持向量机与ARIMA模型在环境噪声水平时序预测中的比较
摘要
本周阅读的文献从环境噪声水平的时序预测出发,对SVM和ARIMA模型进行了比较,选择出更适合的时间序列方法。通过实验对比,SVM模型因其具有的极大边际概念、十倍交叉验证和对非线性的适应性,因此在时序预测方面优于ARIMA模型。SVM是一类按监督学习方式对数据进行二元分类的广义线性分类器,利用画出来的超平面可以很好地区分两个类别。通过拉格朗日对偶性和KKT条件推导出SVM的超平面计算,并将其计算原理应用到实例。除此之外,在梯度下降法的基础上,通过上周CNN正向传播的例子继续计算CNN反向传播,根据计算结果可以发现卷积层反向传播的计算规律。
Abstract
This week's article compares the SVM and ARIMA models to select a more suitable time series method from the perspective of time series prediction of environmental noise levels. Through experimental comparison, SVM model is superior to ARIMA model in time series prediction because of its large margin concept, ten-fold cross-validation and adaptability to nonlinearity. SVM is a kind of generalized linear classifier for binary classification of data according to supervised learning, two categories can be distinguished well by the drawn hyperplane. Through Lagrange duality and KKT condition derive the hyperplane computation of SVM, and apply its calculation principle to an example. In addition, on the basis of gradient descent method, CNN back propagation is continued to be calculated through the example of CNN forward propagation last week, and can found the calculation rule of convolutional layer back propagation according to the calculation results.
文献阅读:支持向量机与ARIMA模型在环境噪声水平时序预测中的比较
TITLE:Comparison of SVM and ARIMA Model in Time-Series Forecasting of Ambient Noise Levels
D O I:10.32604/cmc.2023.030703
现有问题
1)长期噪声监测策略与时间采样、时间序列建模等短期噪声监测策略的对比研究较少。而时间序列技术可以代替连续的长期噪声监测来预测和预报昼夜环境噪声水平,帮助我们在一定的误差范围内发现这个系列。
2)由于噪声监测数据的高度非线性,在大城市的各个场址建立噪声监测站是一项非常复杂的任务,因此研究各种时间序列建模技术的适宜性和适用性是十分必要的。
研究要点
利用SVM和ARIMA技术来比较昼夜环境噪声水平,Lday和Lnight,提供最佳的时间序列方法。其中支持向量机(SVM)广泛用于时间序列预测、数据挖掘、回归、分类和基于金融的建模。在一些研究中,将支持向量机(SVM)与其他传统神经网络(NN)模型进行了比较,得出基于数据预测的支持向量机(SVM)比其他神经网络模型具有更好的性能。在统计学习中,支持向量机由于其处理长期评估数据的高维调谐能力,是一种适用于空气污染和噪声污染预测的技术
相关知识:SVM(支持向量机)模型
(ARIMA模型在上周周报)
1. 概念
支持向量机(SVM)是一类按监督学习方式对数据进行二元分类的广义线性分类器,可以将问题化为一个求解凸二次规划的问题。它将实例的特征向量映射为空间中的一些点,SVM 的目的就是想要画出一条线,以 “最好地” 区分这两类点,以至如果以后有了新的点,这条线也能做出很好的分类。SVM 适合中小型数据样本、非线性、高维的分类问题。与逻辑回归和神经网络相比,支持向量机在学习复杂的非线性方程时提供了一种更为清晰,更加强大的方式。
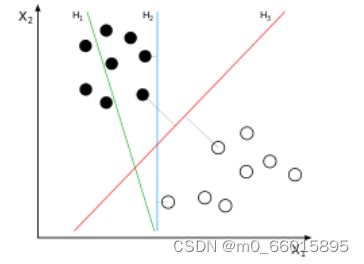
线是有无数条可以画的,区别就在于效果好不好,每条线都可以叫做一个划分超平面。比如上面的绿线就不好,蓝线还凑合,红线看起来就比较好。我们所希望找到的这条效果最好的线就是具有 “最大间隔的划分超平面”。之所以叫做超平面,是因为样本的特征很可能是高维的,此时样本空间的划分就不是一条线了。
2. 画线标准
SVM 将会寻找可以区分两个类别并且能使间隔(margin)最大的划分超平面。对于任意一个超平面,其两侧数据点都距离它有一个最小距离(垂直距离),这两个最小距离的和就是间隔。比较好的划分超平面即margin 尽量大,因为大 margin 犯错的几率比较小,样本局部扰动时对它的影响最小、产生的分类结果最鲁棒、对未见示例的泛化能力最强。
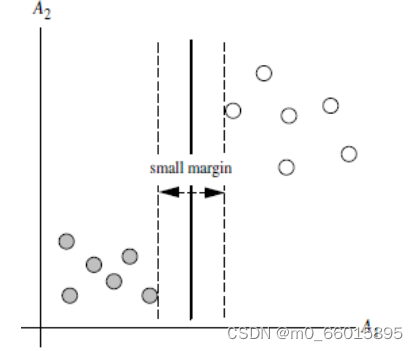
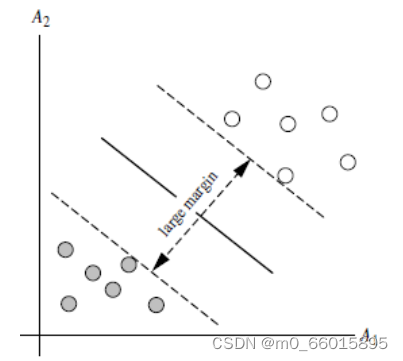
从上图可以看出,虚线上的点到划分超平面的距离都是一样的,实际上只有这几个点共同确定了超平面的位置,因此被称作 “支持向量(support vectors)”,“支持向量机” 也是由此来的。
3. SVM超平面公式推导(对于线性可分)
拉格朗日对偶性
简单来讲,通过给每一个约束条件加上一个拉格朗日乘子(Lagrange multiplier)
,定义拉格朗日函数,通过拉格朗日函数将约束条件融合到目标函数里去,从而只用一个函数表达式便能清楚的表达出我们的问题。
KKT条件
一个最优化数学模型能够表示成下列标准形式:
其中,f(x)是需要最小化的函数,h(x)是等式约束,g(x)是不等式约束,p和q分别为等式约束和不等式约束的数量。
KKT条件的意义:它是一个非线性规划(Nonlinear Programming)问题能有最优化解法的必要和充分条件。而KKT条件就是指上面最优化数学模型的标准形式中的最小点 x* 必须满足下面的条件:
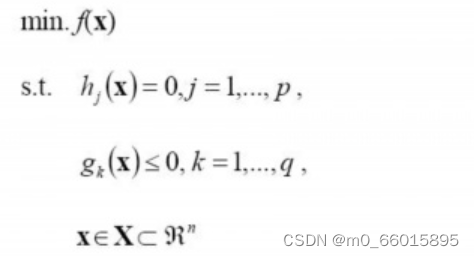
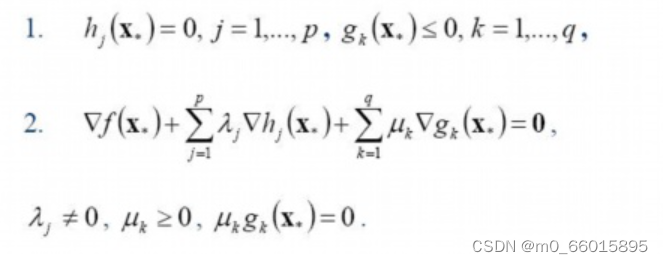


5. 求解SVM超平面实例

实验设计
1. 数据集
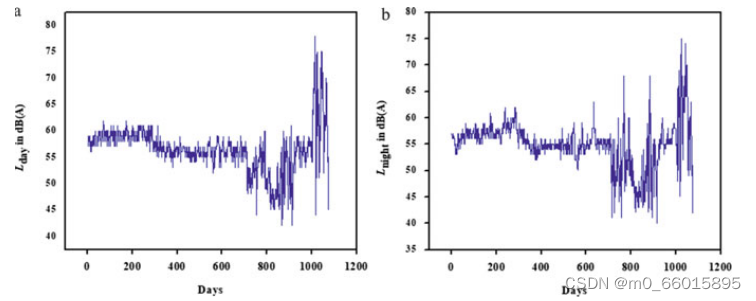
该研究主要关注由中央污染控制委员会(CPCB)在印度七个主要城市的国家环境噪声监测网项目下收集的噪声数据。以某商业区的连续昼夜噪声水平(3年× 365天× 24小时)为例进行了分析。即2015年1月至2018年12月的日等值水平Lday和Lnight 。单位为dB(A)。时间序列图如下,a是白天,b是晚上。
2. 定义模型精度的参数
确认模型性能和准确性的统计参数为均方根误差(RMSE)、平均误差(MAE)、均方误差(MSE)和决定系数(R2)。这些参数的公式为:
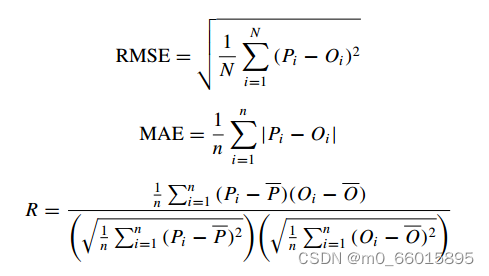
3. 实验设置
(1)SVM模型的统计分析
SVM建模主要集中在三个阶段:第一阶段准备数据,80%的输入数据作为训练数据集,其余20%作为测试数据集。第二阶段涉及超参数的选择,即gamma, Epsilon和cost (γ, ε, C),其中ε 是精度近近值,C是惩罚因子,γ定义单个训练数据到分类器的距离。第三阶段涉及与训练和测试数据相对应的数据模拟。
(2)ARIMA模型的统计分析
ARIMA建模主要集中在三个阶段:第一阶段是验证变量数据的平稳性,即在均值和方差恒定的情况下,值不随时间变化。为了使序列平稳,使用差分(d)。研究从d = 1的最低值开始,进一步增加,直到序列趋于平稳。第二阶段是模型估计阶段,确定p和q值,确定ARIMA (p, d, q)模型。基于参数条件,主要采用(0,0,13)、(0,0,14)、(0,1,12)和(0,1,10)四个ARIMA模型。
4. 实验结果
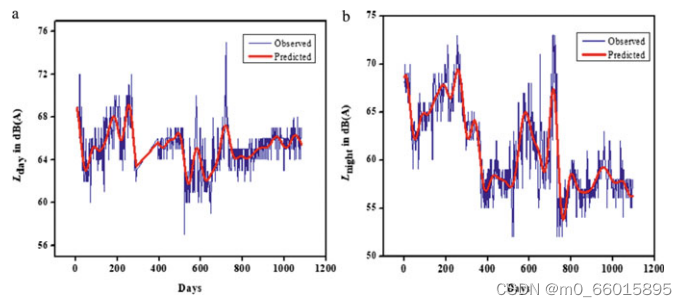
SVM对商业区两种环境白天和夜间噪音水平实测值(蓝线)与预测值(红线)的比较结果如下图。
ARIMA对商业区两种环境白天和夜间噪音水平实测值(蓝线)与预测值(红线)的比较结果如下图。
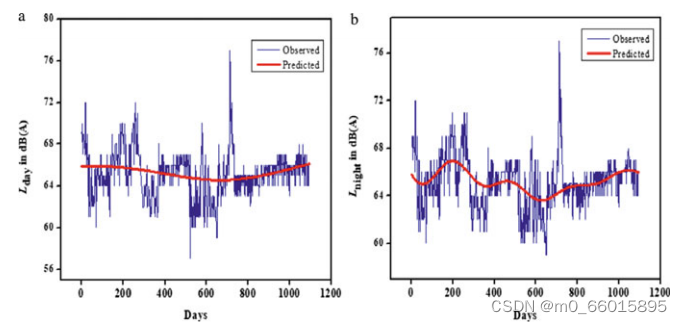
观察均方误差(MSE)、均方根误差(RMSE)和决定系数(R2),比较训练数据和检验数据的时间序列模型。由表可知,对于环境昼夜声级参数,SVM模型的RMSE和MSE均小于ARIMA模型。在使用SVM模型开发的时间序列方法中,支持向量机模型对昼夜噪声水平的决定系数(R2)都较高。
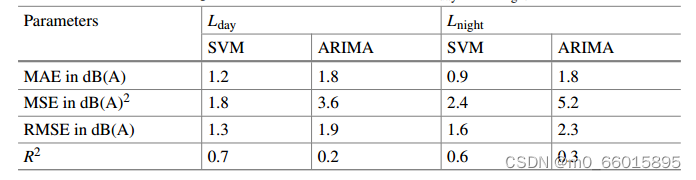
结论
统计分析表明,SVM模型优于ARIMA模型。SVM模型优于ARIMA模型的特点是:极大边际概念、十倍交叉验证和对非线性的适应性。支持向量机模型可以作为预测环境噪声水平的合适替代方法,而不考虑连续的长期噪声监测策略。
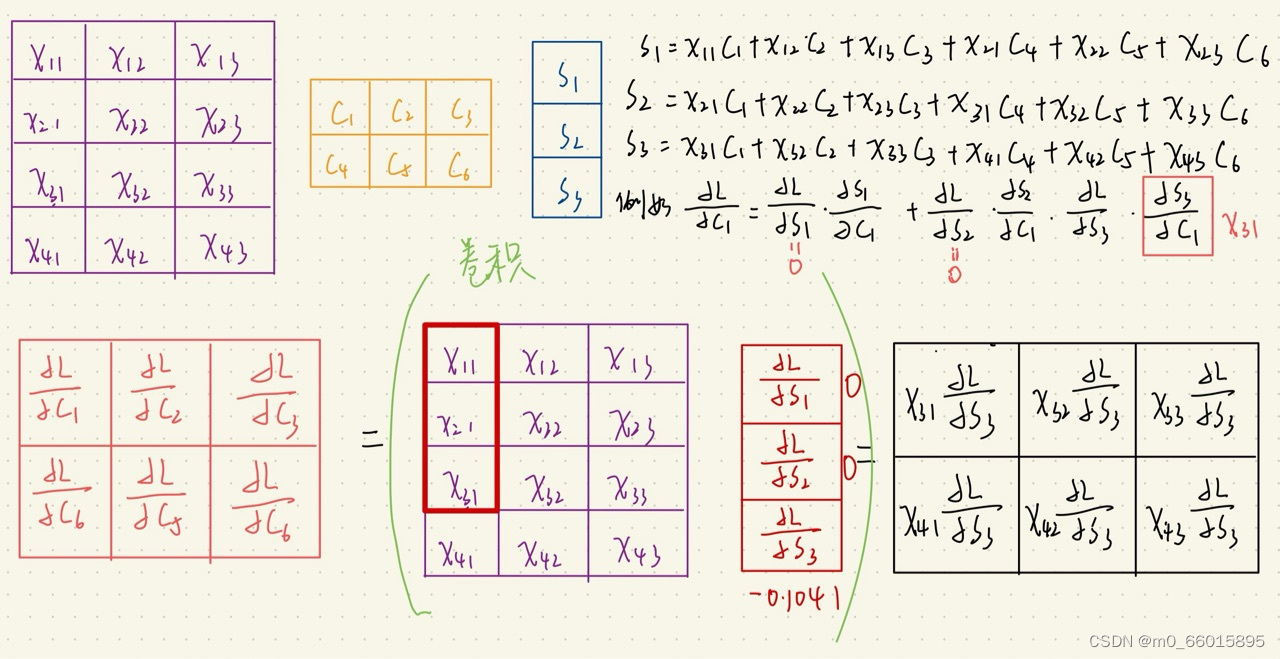
CNN反向传播
池化层反向传播
池化层的反向传播比较容易理解,我们以最大池化举例,在上周写的前向传播例子中,池化后的数字是2.5,实际上只有区域中最大值数字2.5对池化后的结果有影响,权重为1,而1.6、1.4对池化后的结果影响都为0。假设池化后数字2.5的位置误差为X,误差反向传播回去时,矩阵最大值对应的位置误差即等于X,而其它2个位置对应的误差为0。
而平均池化就更简单了,由于平均池化时,区域中每个值对池化后结果贡献的权重都为区域大小的倒数,所以delta误差反向传播回来时,在区域每个位置的delta误差都为池化后delta误差除以区域的大小。
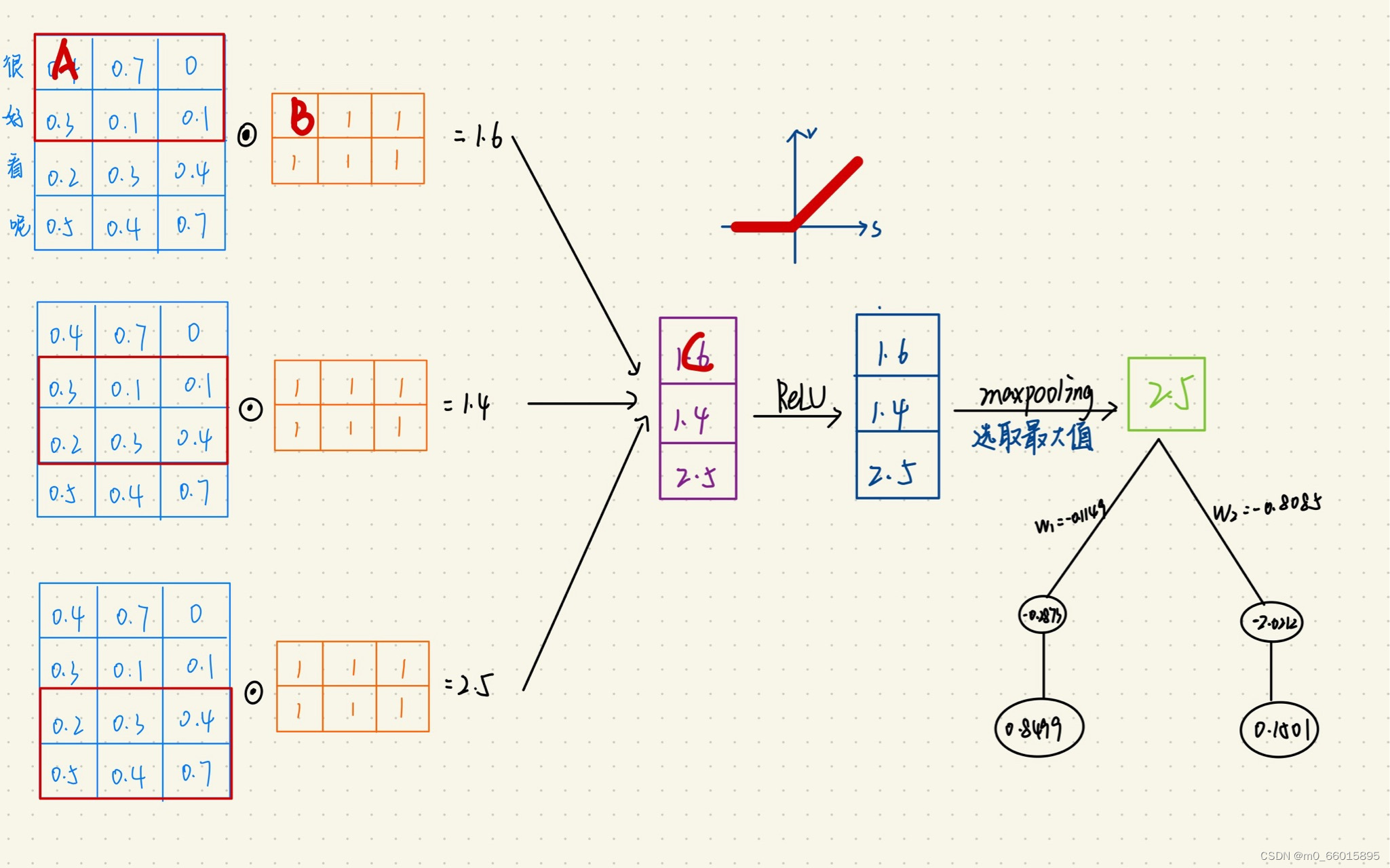
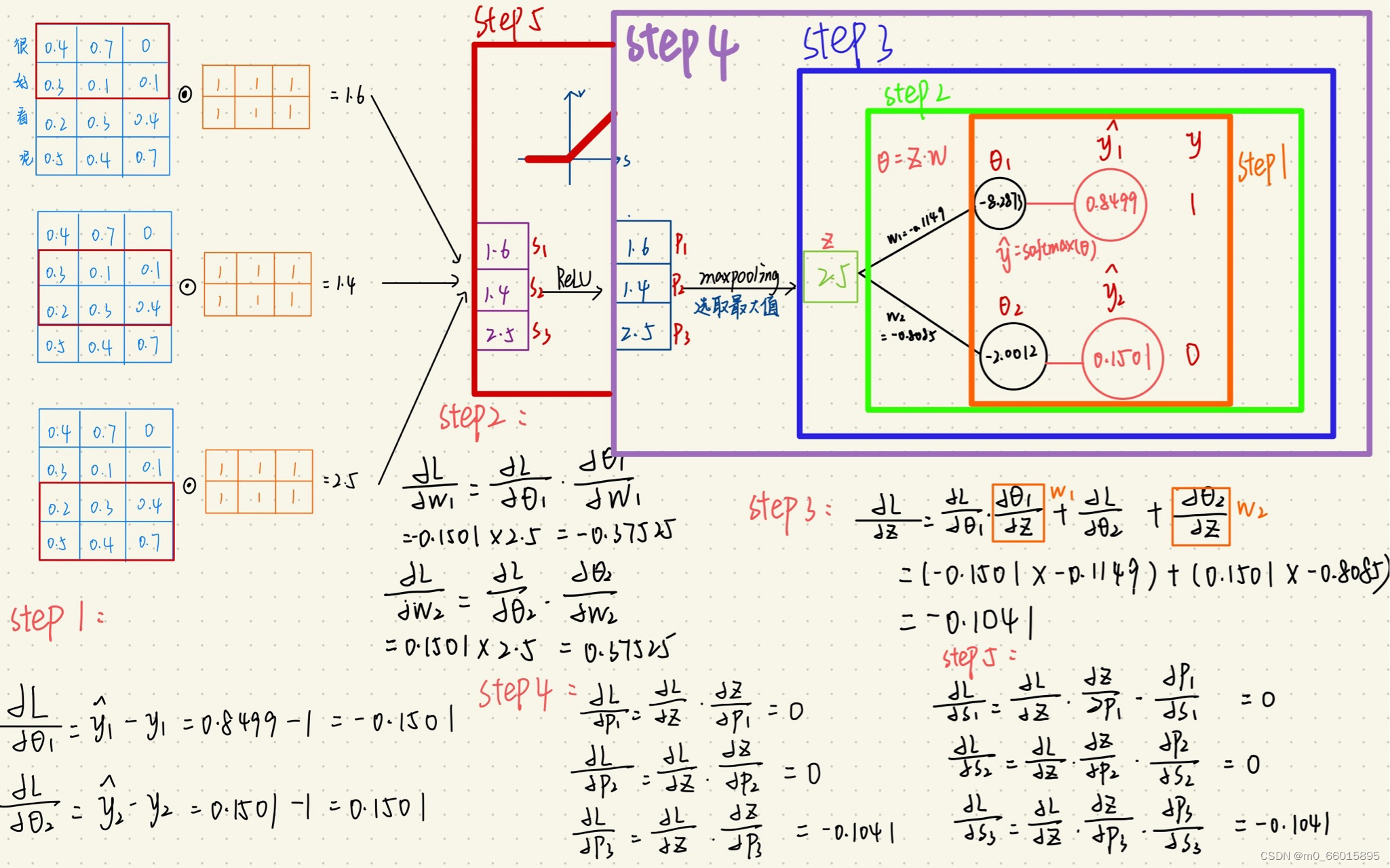
卷积层反向传播
如上图所示,我们求矩阵A处的误差,就先分析,它在前向传播中影响了下一层的哪些结点。显然,它只对结点C有一个权重为B的影响,对卷积结果中的其它结点没有任何影响。因此A的误差应该等于C点的误差乘上权重B。
上周正向传播实例的反向传播计算
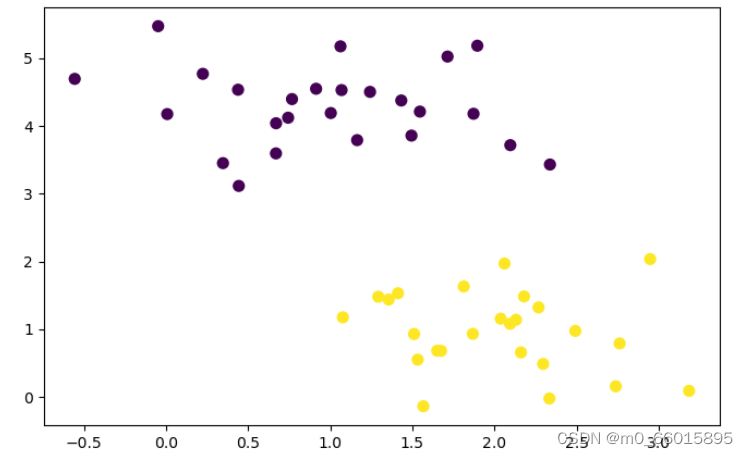
SVM实现线性分类
1、引入数据集
利用sklearn中的
make_blobs函数生成数据集,其中四个参数如下:
n_samples表示样本的个数;
centers是聚类中心点的个数,可以理解为label的种类数;
random_state是随机种子,可以固定生成的数据;
cluster_std设置每个类别的方差
# 导入必要的包
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
# 引入数据集,并可视化
from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples=50, centers=2,
random_state=0, cluster_std=0.60)
plt.figure(figsize=(8,8))
plt.scatter(X[:, 0], X[:, 1], c=y, s=50);
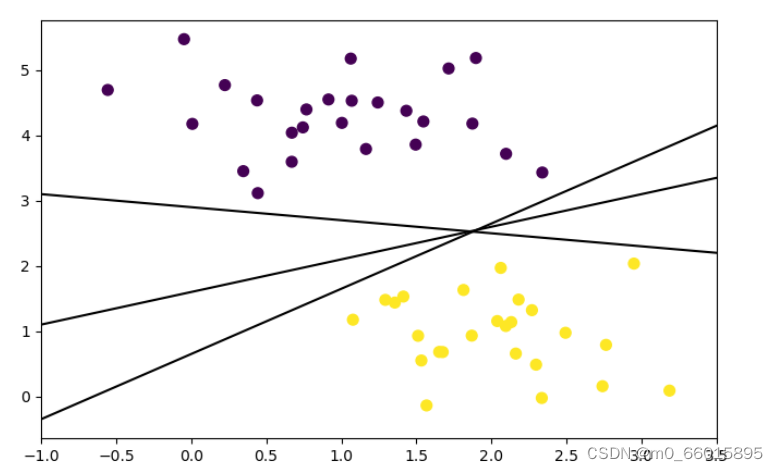
2、画出决策边界
要完成一个分类问题,需要在2种不同的样本点之间产出一条“决策边界”,给定三组(k,b)画出3条不同的可选决策边界。
xfit = np.linspace(-1, 3.5) #在-1到3.5范围内创建等差数列,即横坐标
plt.figure(figsize=(8,8))
plt.scatter(X[:, 0], X[:, 1], c=y, s=50)
for k, b in [(1, 0.65), (0.5, 1.6), (-0.2, 2.9)]:
plt.plot(xfit, k * xfit + b, '-k') #y=kx+b
plt.xlim(-1, 3.5);
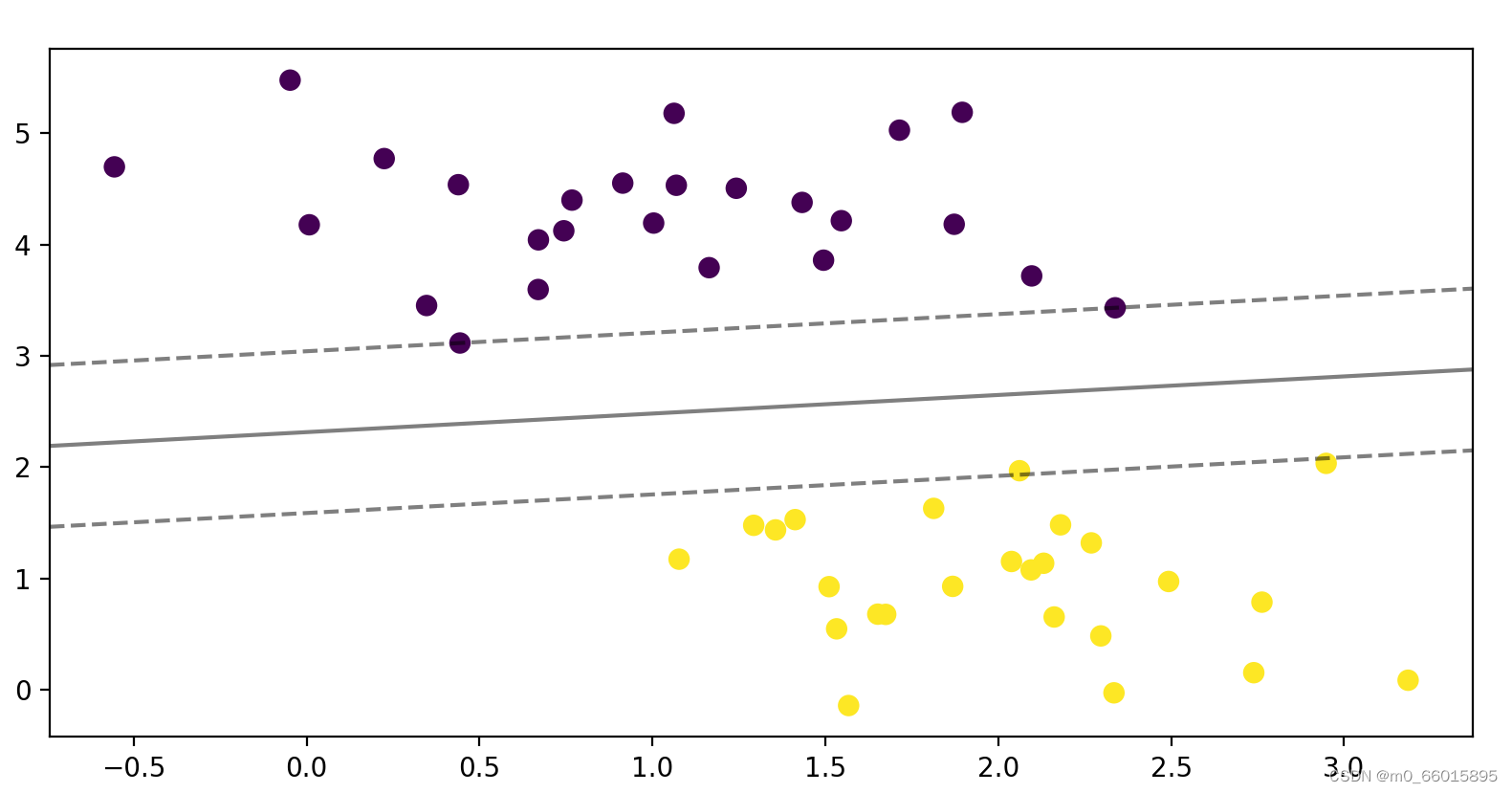
3、构建一个线性SVM分类器并可视化结果
找到一个SVM分类器,能得到上图里在中间位置的,能有最大分类间隔的决策边界。给出的数据集是一个线性可分的例子,因此可以使用sklearn中linear kernel的svm来进行划分。
from sklearn.svm import SVC # "Support Vector Classifier"
# 用线性核函数的SVM来对样本进行分类
clf = SVC(kernel='linear')
clf.fit(X, y)
def plot_svc_decision_function(clf, ax=None):
"""Plot the decision function for a 2D SVC"""
if ax is None:
ax = plt.gca()
#创建网格用于评价模型
x = np.linspace(plt.xlim()[0], plt.xlim()[1], 30)
y = np.linspace(plt.ylim()[0], plt.ylim()[1], 30)
Y, X = np.meshgrid(y, x)
P = np.zeros_like(X)
for i, xi in enumerate(x):
for j, yj in enumerate(y):
P[i, j] = clf.decision_function([[xi, yj]])
#绘制超平面
ax.contour(X, Y, P, colors='k',
levels=[-1, 0, 1], alpha=0.5,
linestyles=['--', '-', '--'])
plt.figure(figsize=(8,8))
plt.scatter(X[:, 0], X[:, 1], c=y, s=50)
#函数plot_svc_decision_function用于绘制分割超平面和其两侧的辅助超平面
plot_svc_decision_function(clf);
总结
SVM是一种二分类模型,其核心思想是找出能够最大化训练集数据间隔(margin)的最优分类超平面。 SVM可以作线性分类器,但是在引入核函数(Kernel Method)之后,也可以进行非线性分类,下周将继续学习SVM的非线性分类。














 1332
1332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









