






目录
1、Legendre Projection(Legendre投影)
摘要
本周阅读的文献《FiLM: Frequency improved Legendre Memory Model for Long-term Time Series Forecasting》提出了一种创新的长期时间序列预测模型——FiLM(Frequency improved Legendre Memory Model)。该模型旨在通过改进历史信息的保留方式及减少噪声影响,提升深度学习模型在长序列预测任务中的性能。FiLM模型的核心机制包括使用Legendre多项式投影来逼近历史信息,应用Fourier投影去除数据中的噪声,并通过低秩近似加速计算过程。研究结果显示,FiLM模型在多变量和单变量的长期预测任务上,分别比当前最优模型的准确率提高了20.3%和22.6%,显著增强了预测精度。此外,论文指出FiLM的表示模块具有通用性,可作为插件集成到其他深度学习架构中,以提升它们的长期预测表现。实验还表明,仅增加模型复杂度并不能确保更准确的预测,而 FiLM通过稳健的时间序列表征,在避免过拟合历史噪声的同时,更好地捕捉关键历史信息,从而实现了更精准的长期预测。
Abstract
The literature "FiLM: Frequency Improved Legendary Memory Model for Long term Time Series Forecasting" read this week proposes an innovative long-term time series prediction model - FiLM (Frequency Improved Legendary Memory Model). This model aims to enhance the performance of deep learning models in long sequence prediction tasks by improving the retention of historical information and reducing the impact of noise. The core mechanism of the FiLM model includes using Legendre polynomial projection to approximate historical information, applying Fourier projection to remove noise from the data, and accelerating the calculation process through low rank approximation. The research results show that the FiLM model has improved the accuracy of multivariate and univariate long-term prediction tasks by 20.3% and 22.6% respectively compared to the current optimal model, significantly enhancing prediction accuracy. In addition, the paper points out that the representation module of FiLM has universality and can be integrated as a plugin into other deep learning architectures to improve their long-term prediction performance. The experiment also showed that increasing model complexity alone cannot ensure more accurate predictions, while FiLM achieves more accurate long-term predictions by robust time series representation, avoiding overfitting of historical noise while better capturing key historical information.
文献阅读:用于长时间序列预测的频率改进的勒让德记忆模型
FiLM: Frequency improved Legendre Memory Model for Long-term Time Series Forecasting https://arxiv.org/abs/2205.08897arxiv.org/pdf/2205.08897
https://arxiv.org/abs/2205.08897arxiv.org/pdf/2205.08897
一、现有问题
长期时间序列预测面临的主要挑战在于如何在确保预测准确性和鲁棒性的同时,平衡历史信息的保存与噪声信号的剔除。传统的深度学习模型,如循环神经网络(RNNs)和变压器(Transformers),虽然在利用历史信息方面有显著进步,但在长期预测中仍容易受到历史数据中的噪声干扰,导致过拟合,从而限制了模型的潜力。
二、提出方法
为解决上述问题,FiLM模型通过以下设计进行了优化:
- Legendre投影单元(LPU):Legendre多项式是正交函数,能有效捕获不同频率的信息。利用Legendre多项式对输入序列进行投影,以压缩和表示历史数据,捕捉长期时间依赖性。
- Fourier增强层(FEL):结合Fourier分析和低秩矩阵近似技术,对LPU输出进行降维,以滤除高频噪声,同时保留低频信号,从而在保留重要历史信息的同时,减轻过拟合问题。
三、相关知识
1、Legendre Projection(Legendre投影)
Legendre多项式是一系列正交多项式,在区间[-1, 1]上定义,常用于数值分析和函数逼近。这些多项式在数学的多个领域中扮演着重要角色,特别是在求解特定类型的微分方程、特别是在与 Legendre 方程相关的问题中,以及在球面谐波分析和电势问题等领域。勒让德多项式通常记为 ,其中n是非负整数,定义在区间 [-1, 1]上。它们具有一系列特性,包括:
- 正交性:勒让德多项式在区间 [-1, 1]上与权重函数
构成正交系,即对于任意不同的m和 n,有:
- 递归关系:勒让德多项式满足特定的递归关系,这使得计算高阶多项式变得相对直接。例如,一个常用的递归关系是:
- 规范性:通常情况下,勒让德多项式被归一化为
。
- 对称性:勒让德多项式是偶函数或奇函数,具体取决于n的奇偶性,即
- 解Legendre方程:勒让德多项式是Legendre微分方程的解,该方程是一个二阶线性常微分方程,形式为:
,其中
。
https://zhuanlan.zhihu.com/p/352724194
2、Fourier Transform(傅立叶变换)
傅立叶变换是一种将时域信号转换为频域信号的技术,能够将复杂的时间序列分解成不同频率的成分。傅里叶变换认为一个周期函数(信号)包含多个频率分量,任意函数(信号)f(t)可通过多个周期函数(基函数)相加而合成。 从物理角度理解傅里叶变换是以一组特殊的函数(三角函数)为正交基,对原函数进行线性变换,物理意义便是原函数在各组基函数的投影。

以下是傅里叶变换的原理图,也是时域信号转化为频域信号的原理。
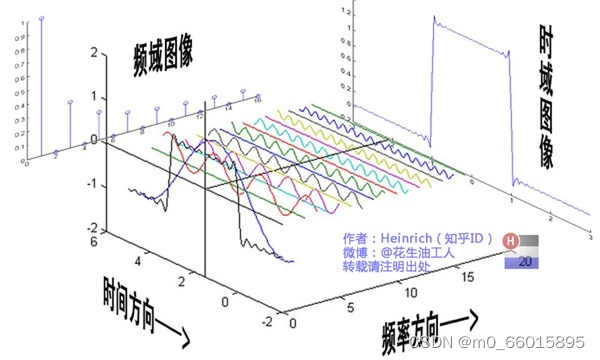
- 上图所示波形是三角函数的规律,表示时域图像的规律有三角函数的规律,可以通过一系列的三角函数相加(注意:还需要添加正负值)而得到。傅里叶变换就是以三角函数为正交基。
- 将这些波形的规律相加得到右边的时域图像。横轴为时间,纵轴为测量值,
- 将这些波形进行投影得到左边的频域图像。横轴为频率,纵轴为频域。
- 将一个函数分解成一系列三角函数相加(注意:还需要添加正负值)的形式,我们称之为傅里叶变换。
在上图中,右边的波形部分是,信息量含量较小的规律,左边的波形是信息量含量较高的规律。保留左边的低频部分,就是把信息量含量较高的部分拿出来,这是我们需要的部分。而左边的波形,也就是高频部分。可以把他们过滤掉,因为他们的信息量含量较小,可以称之为噪声。
低通滤波器就是滤除高频部分,保留低频部分,目的是为了保留信息量较高的部分。
在FiLM模型中,通过傅立叶变换,可以识别并分离出时间序列中的低频信号(通常与长期趋势相关)和高频噪声。结合低秩近似,模型能够专注于对预测有意义的低频部分,忽略或减少高频噪声的干扰。
四、提出的方法(FiLM)
FiLM(Frequency Improved Legendre Memory Model)被设计出用于探索长期时间序列预测,目标在于通过精确保存历史信息并有效减少噪声干扰,来提升预测的准确性和稳定性。FiLM模型的构建围绕两个核心组件展开:Legendre Projection Unit (LPU) 和 Frequency Enhanced Layer (FEL),这些组件共同工作以实现对时间序列的高效建模和未来趋势的精准预测。
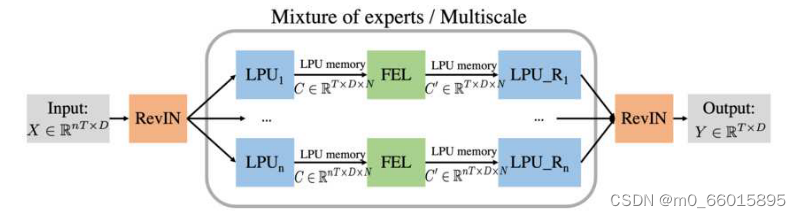
LPU:勒让德投影单位;LPU_R:勒让德投影的逆恢复;FEL:频率增强层;Revin:数据规格化模块。输入数据首先被归一化,然后投影到勒让德多项式空间。LPU memoryC用FEL处理,并产生输出的memory 。最后,利用LPUR对
进行重构和反规格化,得到输出序列。
1、RevIN:数据标准化块
输入数据首先被归一化,对于每一个输入数据 ,平均值和标准差分别为:
,平均值和标准差分别为:

将输入数据进行标准化,即:
和
是可学习的参数矩阵,然后将标准化的输入数据发送到模型中进行后续训练。最后,我们通过归一化的倒数来反归一化模型的输出。
2、 LPU:勒让德投影装置
FiLM模型的核心理念是利用Legendre多项式投影来近似历史信息,这是基于Legendre多项式的正交性质,它们能够高效地捕获和表示不同尺度的信号特征。Legendre多项式具有良好的逼近能力,特别是在光滑函数的近似上。在给定输入序列的情况下,函数逼近问题的目标是逼近每个时刻t的累积历史。利用勒让德多项式投影,可以将延长的数据序列投影到有界维子空间上,从而导致对历史数据的压缩或特征表示。

输入信号首先通过预定义的矩阵A和B进行投影,其中A是基于Legendre多项式的系数矩阵,B则负责将原始信号映射到Legendre多项式空间。这一过程发生在LPU层,它包含两阶段:
- 投影阶段将原始信号映射到记忆单元C(t)
- 重建阶段从记忆单元中恢复信号,形成Xre。
通过这种方式,FiLM能够以较低维度精确捕捉历史信号的核心特征,减少冗余信息和噪声干扰。
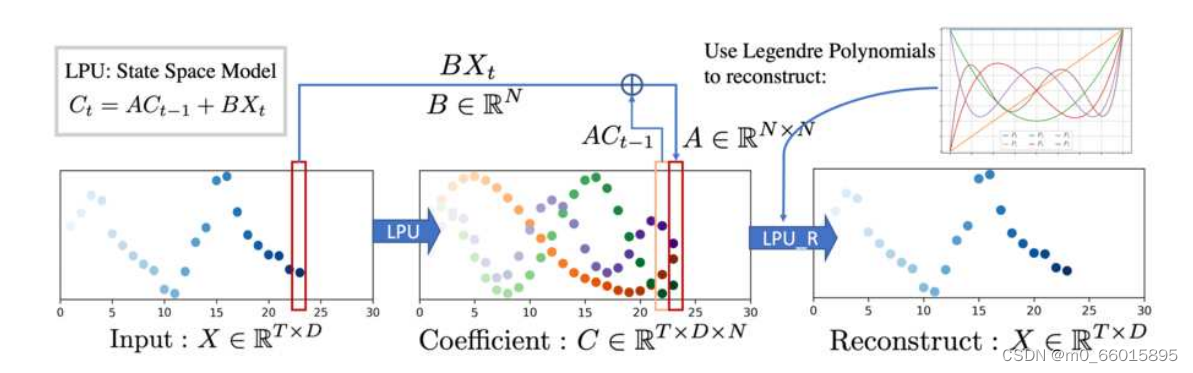
通过公示原理可以发现,勒让德多项式的基数越大,逼近的精度就越高,这可能会导致历史上噪声信号的过拟合。直接向深度学习模块(如MLP、RNN和普通注意模块)提供上述功能将不会产生最先进的性能,这主要是由于历史上的噪声信号。这就是为什么需要引入一个带有傅立叶变换的频率增强层来进行特征选择。
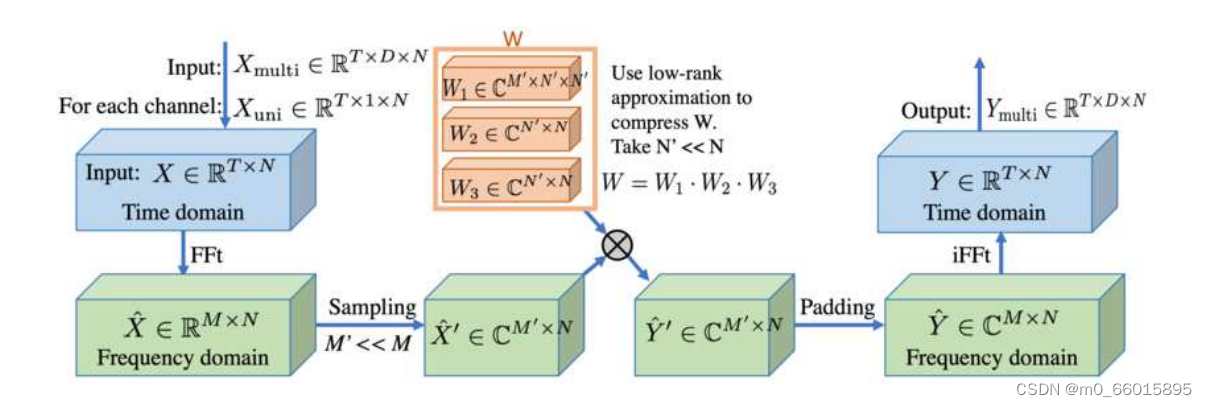
2、FEL: 频率增强层
为了进一步提升模型的抗噪能力和长期预测的准确性,FiLM模型引入了FEL。这一层的作用是通过Fourier变换来选择性地增强或抑制特定频率模式,从而去除噪声并强化信号中的关键趋势。FEL中,信号经过Fourier变换后,能够被分解为不同频率的分量,允许模型专注于对长期预测有益的低频部分,同时削弱或排除高频噪声。特别是,FEL采用了低秩近似技术来降低模型的参数量,加速计算过程,同时保持预测性能。低秩近似的应用意味着原本需要学习的大型权重矩阵W被分解为几个较小矩阵的乘积(例如W = W1·W2·W3),这不仅减少了内存使用,还可能减轻过拟合的风险。
五、研究实验
1、数据集
实验选择了六个真实世界的数据集,涵盖交通、能源、经济、天气以及疾病等多个领域,以全面检验FiLM模型的泛化能力。这些数据集包括:ETTm1(交通)、Exchange(能源)、Economics、Weather、Disease(流感样疾病)等,来源广泛,如UCI机器学习库、PEMS交通数据集、德国耶拿大学气象站以及美国疾控中心流感监测数据。这些数据集具有不同的输入长度和预测范围,例如对于流感样疾病(ILI)数据集,预测长度设置为24、36、48、60,其他数据集则固定为96、192、336、720,以此来模拟多样化的长期预测场景。
2、评估指标
实验中采用均方误差(MSE)和平均绝对误差(MAE)作为主要评估指标,这两个指标越低,表明模型的预测效果越好。
3、实验过程
实验遵循Informer模型的设置,对输入长度进行调优以获得最佳预测性能,同时训练和评估阶段的预测长度保持不变。在多变量和单变量预测任务中,FiLM模型与一系列当前最优的Transformer基线模型进行对比,包括FEDformer、Autoformer、S4、Informer、LogTrans以及Reformer。此外,实验还包括了RevIN(反向实例归一化)作为可选的训练稳定器,并对其效果进行了详细的消融研究。
4、实验结果
多变量预测
在多变量预测任务中,FiLM模型展现出了显著的性能优势。通过与当前最先进技术(SOTA)如FEDformer、Autoformer、S4、Informer、LogTrans以及Reformer的比较,FiLM在六个不同的基准数据集上均实现了最佳的预测表现。特别是,在Exchange数据集上,FiLM相比FEDformer的相对均方误差(MSE)减少了超过30%,这一成就突显了模型在复杂多变数据中的强适应性和高效信息提取能力。整体来看,FiLM在所有预测长度(96, 192, 336, 720)上平均实现了20.3%的MSE减少,说明它在处理多维度时间序列数据时能够有效利用历史信息并抑制噪声干扰,从而提升预测精度。
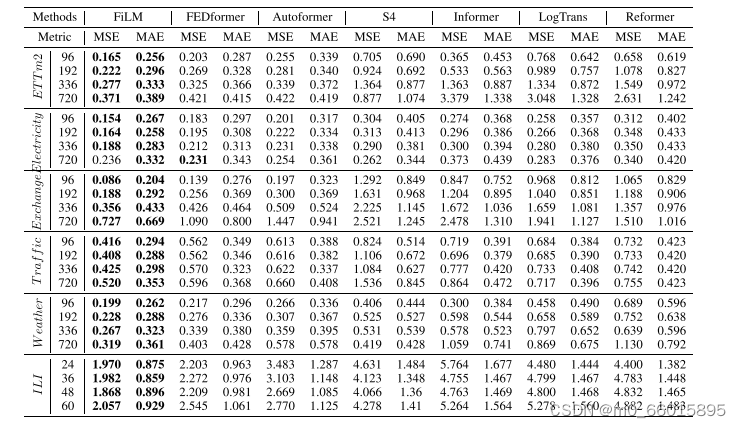
单变量预测
在单变量预测方面,FiLM同样显示出了卓越的性能提升。在对ETT数据集的全面基准测试中,FiLM在四个不同时间分辨率的子数据集上,相较于SOTA方法FEDformer,平均MSE减少了14.0%。这一结果强调了模型在处理单序列数据时,依然能有效提取时间序列中的长期依赖性,同时减少过拟合风险。无论是按小时记录的ETTh1、ETTh2,还是每15分钟记录一次的ETTm1、ETTm2,FiLM均保持了一致的性能增益,这表明模型具有高度的泛化能力和对不同采样率数据的适应性。
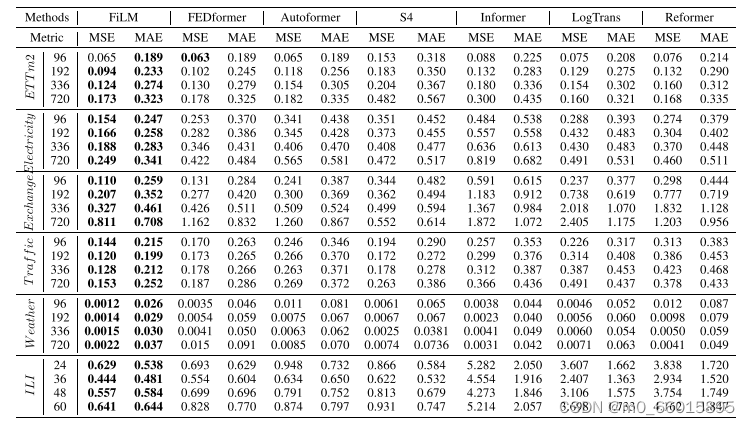
消融研究
为了深入理解FiLM模型各组成部分的贡献进行了消融研究,重点考察了低秩近似(low-rank approximation)在FEL(Frequency Enhanced Layer)中的作用、频率模式选择策略以及多尺度专家机制。研究发现,通过低秩近似,FiLM能够大幅度减少模型参数量(例如,当使用4个低秩维度代替默认的256维Legendre多项式时,参数量减少至0.4%),同时仅带来轻微的性能损失。这不仅证明了低秩近似在保持模型预测性能的同时,还能有效提升计算效率。此外,对频率模式的选择研究表明,除了默认选择最低M个模式外,适度添加随机高频率模式能在某些数据集中进一步提升预测性能,这一发现与理论分析相符,表明了模型在噪声过滤与特征提取间的精细平衡。最后,多尺度专家机制的引入显著增强了模型在所有数据集上的表现,显示了考虑不同时间尺度信息对于提高长期预测准确性的关键作用。综合这些消融实验可以确信FiLM模型的每个设计决策都是经过深思熟虑并对其性能有着积极影响的。
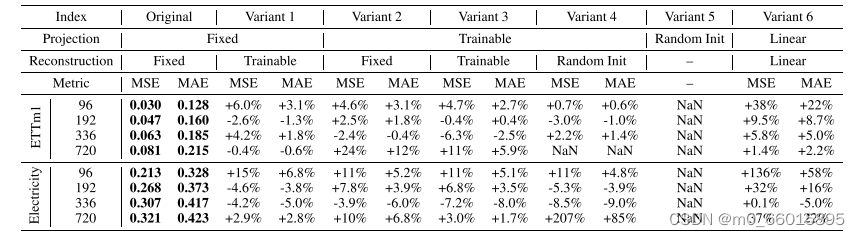
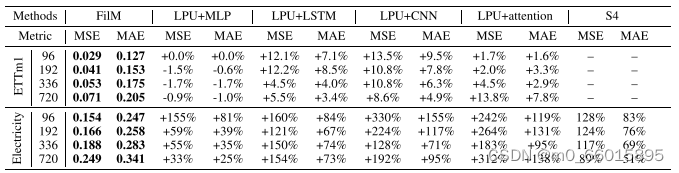

六、模型代码实现
FiLM模型
# coding=utf-8
import sys
import os
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
import numpy as np
from scipy import signal
from scipy import linalg as la
from scipy import special as ss
from utils import unroll
from utils.op import transition
import pickle
import pdb
from einops import rearrange, repeat
import opt_einsum as oe
contract = oe.contract
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#勒让德投影
class HiPPO_LegT(nn.Module):
def __init__(self, N, dt=1.0, discretization='bilinear'):
#N: HiPPO投影的顺序
#dt: 离散化步长,应大致与序列长度相反
super(HiPPO_LegT,self).__init__()
self.N = N
A, B = transition('lmu', N)
C = np.ones((1, N))
D = np.zeros((1,))
A, B, _, _, _ = signal.cont2discrete((A, B, C, D), dt=dt, method=discretization)
B = B.squeeze(-1)
self.register_buffer('A', torch.Tensor(A).to(device))
self.register_buffer('B', torch.Tensor(B).to(device))
vals = np.arange(0.0, 1.0, dt)
self.register_buffer('eval_matrix', torch.Tensor(
ss.eval_legendre(np.arange(N)[:, None], 1 - 2 * vals).T).to(device))
def forward(self, inputs): # torch.Size([128, 1, 1]) -
"""
inputs : (length, ...)
output : (length, ..., N) where N is the order of the HiPPO projection
"""
c = torch.zeros(inputs.shape[:-1] + tuple([self.N])).to(device) # torch.Size([1, 256])
cs = []
for f in inputs.permute([-1, 0, 1]):
f = f.unsqueeze(-1)
# f: [1,1]
new = f @ self.B.unsqueeze(0) # [B, D, H, 256]
c = F.linear(c, self.A) + new
# c = [1,256] * [256,256] + [1, 256]
cs.append(c)
return torch.stack(cs, dim=0)
def reconstruct(self, c):
a = (self.eval_matrix @ c.unsqueeze(-1)).squeeze(-1)
return (self.eval_matrix @ c.unsqueeze(-1)).squeeze(-1)
#频谱卷积
class SpectralConv1d(nn.Module):
def __init__(self, in_channels, out_channels,seq_len, modes1,compression=0,ratio=0.5,mode_type=0):
super(SpectralConv1d, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.modes1 = modes1 #Number of Fourier modes to multiply, at most floor(N/2) + 1
self.compression = compression
self.ratio = ratio
self.mode_type=mode_type
if self.mode_type ==1:
#modes2=modes1-10000
modes2 = modes1
self.modes2 =min(modes2,seq_len//2)
self.index0 = list(range(0, int(ratio*min(seq_len//2, modes2))))
self.index1 = list(range(len(self.index0),self.modes2))
np.random.shuffle(self.index1)
self.index1 = self.index1[:min(seq_len//2,self.modes2)-int(ratio*min(seq_len//2, modes2))]
self.index = self.index0+self.index1
self.index.sort()
elif self.mode_type > 1:
#modes2=modes1-1000
modes2 = modes1
self.modes2 =min(modes2,seq_len//2)
self.index = list(range(0, seq_len//2))
np.random.shuffle(self.index)
self.index = self.index[:self.modes2]
else:
self.modes2 =min(modes1,seq_len//2)
self.index = list(range(0, self.modes2))
self.scale = (1 / (in_channels*out_channels))
self.weights1 = nn.Parameter(self.scale * torch.rand(in_channels, out_channels, len(self.index), dtype=torch.cfloat))
if self.compression > 0:
print('compressed version')
self.weights0 = nn.Parameter(self.scale * torch.rand(in_channels,self.compression,dtype=torch.cfloat))
self.weights1 = nn.Parameter(self.scale * torch.rand(self.compression,self.compression, len(self.index), dtype=torch.cfloat))
self.weights2 = nn.Parameter(self.scale * torch.rand(self.compression,out_channels, dtype=torch.cfloat))
#print(self.modes2)
def forward(self, x):
B, H,E, N = x.shape
# 计算傅立叶系数,直至因子e^(某个常数)
x_ft = torch.fft.rfft(x)
#pdb.set_trace()
# 乘以相关傅立叶模式
out_ft = torch.zeros(B,H, self.out_channels, x.size(-1)//2 + 1, device=x.device, dtype=torch.cfloat)
#a = x_ft[:, :,:, :self.modes1]
#out_ft[:, :,:, :self.modes1] = torch.einsum("bjix,iox->bjox", a, self.weights1)
if self.compression ==0:
if self.modes1>1000:
for wi, i in enumerate(self.index):
#print(self.index)
#print(out_ft.shape)
out_ft[:, :, :, i] = torch.einsum('bji,io->bjo',(x_ft[:, :, :, i], self.weights1[:, :,wi]))
else:
a = x_ft[:, :,:, :self.modes2]
out_ft[:, :,:, :self.modes2] = torch.einsum("bjix,iox->bjox", a, self.weights1)
elif self.compression > 0:
a = x_ft[:, :,:, :self.modes2]
a = torch.einsum("bjix,ih->bjhx", a, self.weights0)
a = torch.einsum("bjhx,hkx->bjkx", a, self.weights1)
out_ft[:, :,:, :self.modes2] = torch.einsum("bjkx,ko->bjox", a, self.weights2)
#返回物理空间
x = torch.fft.irfft(out_ft, n=x.size(-1))
return x
class Model(nn.Module):
"""
Autoformer is the first method to achieve the series-wise connection,
with inherent O(LlogL) complexity
"""
def __init__(self, configs, N=512, N2=32):
super(Model, self).__init__()
self.configs = configs
# self.modes = configs.modes
self.seq_len = configs.seq_len
self.label_len = configs.label_len
self.pred_len = configs.pred_len
self.seq_len_all = self.seq_len+self.label_len
self.output_attention = configs.output_attention
self.layers = configs.e_layers
self.modes1 = min(configs.modes1,self.pred_len//2)
#self.modes1 = 32
self.enc_in = configs.enc_in
self.proj=False
self.e_layers = configs.e_layers
self.mode_type=configs.mode_type
if self.configs.ours:
#b, s, f means b, f
self.affine_weight = nn.Parameter(torch.ones(1, 1, configs.enc_in))
self.affine_bias = nn.Parameter(torch.zeros(1, 1, configs.enc_in))
if configs.enc_in>1000:
self.proj=True
self.conv1 = nn.Conv1d(configs.enc_in,configs.d_model,1)
self.conv2 = nn.Conv1d(configs.d_model,configs.dec_in,1)
self.d_model = configs.d_model
self.affine_weight = nn.Parameter(torch.ones(1, 1, configs.d_model))
self.affine_bias = nn.Parameter(torch.zeros(1, 1, configs.d_model))
if self.configs.ab == 2:
self.multiscale = [1,2,4]
#self.multiscale = [1]
self.window_size=[256]
self.legts = nn.ModuleList([HiPPO_LegT(N=n, dt=1./self.pred_len/i) for n in self.window_size for i in self.multiscale])
self.spec_conv_1 = nn.ModuleList([SpectralConv1d(in_channels=n, out_channels=n,seq_len=min(self.pred_len,self.seq_len), modes1=configs.modes1,compression=configs.version,ratio=configs.ratio,mode_type=self.mode_type) for n in self.window_size for _ in range(len(self.multiscale))])
self.mlp = nn.Linear(len(self.multiscale)*len(self.window_size), 1)
def forward(self, x_enc, x_mark_enc, x_dec_true, x_mark_dec,
enc_self_mask=None, dec_self_mask=None, dec_enc_mask=None):
# decomp init
if self.configs.ab == 2:
return_data=[x_enc]
if self.proj:
x_enc = self.conv1(x_enc.transpose(1,2))
x_enc = x_enc.transpose(1,2)
if self.configs.ours:
means = x_enc.mean(1, keepdim=True).detach()
#mean
x_enc = x_enc - means
#var
stdev = torch.sqrt(torch.var(x_enc, dim=1, keepdim=True, unbiased=False)+ 1e-5).detach()
x_enc /= stdev
# affine
x_enc = x_enc * self.affine_weight + self.affine_bias
B, L, E = x_enc.shape
seq_len = self.seq_len
x_decs = []
jump_dist=0
for i in range(0, len(self.multiscale)*len(self.window_size)):
x_in_len = self.multiscale[i%len(self.multiscale)] * self.pred_len
x_in = x_enc[:, -x_in_len:]
legt = self.legts[i]
x_in_c = legt(x_in.transpose(1, 2)).permute([1, 2,3, 0])[:,:,:,jump_dist:]
out1 = self.spec_conv_1[i](x_in_c)
if self.seq_len >= self.pred_len:
x_dec_c = out1.transpose(2, 3)[:,:, self.pred_len-1-jump_dist, :]
else:
x_dec_c = out1.transpose(2, 3)[:,:, -1, :]
x_dec = x_dec_c @ (legt.eval_matrix[-self.pred_len:,:].T)
x_decs += [x_dec]
return_data.append(x_in_c)
return_data.append(out1)
x_dec = self.mlp(torch.stack(x_decs, dim=-1)).squeeze(-1).permute(0,2,1)
if self.configs.ours:
x_dec = x_dec - self.affine_bias
x_dec = x_dec / (self.affine_weight + 1e-10)
x_dec = x_dec * stdev
x_dec = x_dec + means
if self.proj:
x_dec = self.conv2(x_dec.transpose(1,2))
x_dec = x_dec.transpose(1,2)
return_data.append(x_dec)
if self.output_attention:
return x_dec, return_data
else:
return x_dec,None # [B, L, D]
#参数设置
if __name__ == '__main__':
class Configs(object):
ab = 2
modes1 = 8
seq_len = 336
label_len = 0
pred_len = 720
output_attention = True
enc_in = 7
dec_in = 7
d_model = 16
embed = 'timeF'
dropout = 0.05
freq = 'h'
factor = 1
n_heads = 8
d_ff = 16
e_layers = 2
d_layers = 1
moving_avg = 25
c_out = 1
activation = 'gelu'
wavelet = 0
ours = False
version = 16
ratio = 1
configs = Configs()
model = Model(configs).to(device)
enc = torch.randn([32, configs.seq_len, configs.enc_in]).cuda()
enc_mark = torch.randn([32, configs.seq_len, 4]).cuda()
dec = torch.randn([32, configs.label_len+configs.pred_len, configs.dec_in]).cuda()
dec_mark = torch.randn([32, configs.label_len+configs.pred_len, 4]).cuda()
out=model.forward(enc, enc_mark, dec, dec_mark)
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print('model size',count_parameters(model)/(1024*1024))
print('input shape',enc.shape)
print('output shape',out[0].shape)
a,b,c,d = out[1]
print('input shape',a.shape)
print('hippo shape',b.shape)
print('processed hippo shape',c.shape)
print('output shape',d.shape)
实验总函数(exp_exp_mian.py)
import os
import sys
from data_provider.data_factory import data_provider
from exp.exp_basic import Exp_Basic
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from models import Informer, Autoformer, Transformer, Logformer,FiLM,LSTM
#from models.pyraformer import Pyraformer_LR
# from models.reformer_pytorch.reformer_pytorch import Reformer
from utils.tools import EarlyStopping, adjust_learning_rate, visual
from utils.metrics import metric
import numpy as np
import torch
import torch.nn as nn
from torch import optim
import os
import time
import warnings
import matplotlib.pyplot as plt
import numpy as np
import io
from scipy import stats
warnings.filterwarnings('ignore')
import pdb
import pickle
class Exp_Main(Exp_Basic):
def __init__(self, args):
super(Exp_Main, self).__init__(args)
def _build_model(self):
model_dict = {
'Autoformer': Autoformer,
'Transformer': Transformer,
'Informer': Informer,
#'S4':S4_model,
#'S4film':S4_FiLM,
#'LSTM':LSTM,
#'Seasonal':Seasonal,
#'Ficonv':Ficonv,
#'Pyraformer':Pyraformer_LR,
#'Reformer': Reformer,
'Logformer': Logformer,
#'Transformer_sin':Transformer_sin,
#'Autoformer_sin':Autoformer_sin,
#'TreeDRNet':TreeDRNet,
'FiLM':FiLM,
#'HippoFNOformerMulti':HippoFNOformerMulti
#'HippoFNOformer': HippoFNOformer,
}
model = model_dict['Autoformer'].Model(self.args).float()
if self.args.model=='LSTM':
all_length = self.args.seq_len + self.args.label_len
hidden = model.init_hidden(self.args.batch_size,all_length)
if self.args.use_multi_gpu and self.args.use_gpu:
model = nn.DataParallel(model, device_ids=self.args.device_ids)
return model
def _get_data(self, flag):
data_set, data_loader = data_provider(self.args, flag)
return data_set, data_loader
def _select_optimizer(self):
model_optim = optim.Adam(self.model.parameters(), lr=self.args.learning_rate)
return model_optim
def _select_criterion(self):
criterion = nn.MSELoss()
return criterion
def vali(self, vali_data, vali_loader, criterion):
total_loss = []
ks_test_96,ks_test_192,ks_test_336,ks_test_720,ks_test_96_back=[],[],[],[],[]
ks_result=[]
ks_test_96_raw,ks_test_192_raw,ks_test_336_raw,ks_test_720_raw,ks_test_96_back_raw=[],[],[],[],[]
self.model.eval()
#input_len=720
with torch.no_grad():
for i, (batch_x, batch_y, batch_x_mark, batch_y_mark) in enumerate(vali_loader):
batch_x = batch_x.float().to(self.device)
batch_y = batch_y.float()
if self.args.add_noise_vali:
batch_x = batch_x + 0.3*torch.from_numpy(np.random.normal(0, 1, size=batch_x.shape)).float().to(self.device)
batch_x_mark = batch_x_mark.float().to(self.device)
batch_y_mark = batch_y_mark.float().to(self.device)
# decoder input
dec_inp = torch.zeros_like(batch_y[:, -self.args.pred_len:, :]).float()
dec_inp = torch.cat([batch_y[:, :self.args.label_len, :], dec_inp], dim=1).float().to(self.device)
# encoder - decoder
if self.args.use_amp:
with torch.cuda.amp.autocast():
if self.args.output_attention:
outputs,attention = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)
if i==0:
with open(self.args.model_id+'data.pickle', 'wb') as f:
pickle.dump(attention, f, pickle.HIGHEST_PROTOCOL)
else:
outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]
else:
if self.args.output_attention:
outputs,attention = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)
if i==0:
with open(self.args.model_id+'data.pickle', 'wb') as f:
pickle.dump(attention, f, pickle.HIGHEST_PROTOCOL)
else:
outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]
f_dim = -1 if self.args.features == 'MS' else 0
batch_y = batch_y[:, -self.args.pred_len:, f_dim:].to(self.device)
pred = outputs.detach().cpu()
true = batch_y.detach().cpu()
loss = criterion(pred, true)
total_loss.append(loss)
total_loss = np.average(total_loss)
self.model.train()
return total_loss
def train(self, setting):
train_data, train_loader = self._get_data(flag='train')
vali_data, vali_loader = self._get_data(flag='val')
test_data, test_loader = self._get_data(flag='test')
path = os.path.join(self.args.checkpoints, setting)
if not os.path.exists(path):
os.makedirs(path)
time_now = time.time()
train_steps = len(train_loader)
early_stopping = EarlyStopping(patience=self.args.patience, verbose=True)
model_optim = self._select_optimizer()
criterion = self._select_criterion()
if self.args.use_amp:
scaler = torch.cuda.amp.GradScaler()
for epoch in range(self.args.train_epochs):
iter_count = 0
train_loss = []
self.model.train()
epoch_time = time.time()
for i, (batch_x, batch_y, batch_x_mark, batch_y_mark) in enumerate(train_loader):
iter_count += 1
model_optim.zero_grad()
batch_x = batch_x.float().to(self.device)
batch_y = batch_y.float().to(self.device)
if self.args.add_noise_train:
batch_x = batch_x + 0.3*torch.from_numpy(np.random.normal(0, 1, size=batch_x.float().shape)).float().to(self.device)
batch_x_mark = batch_x_mark.float().to(self.device)
batch_y_mark = batch_y_mark.float().to(self.device)
# decoder input
dec_inp = torch.zeros_like(batch_y[:, -self.args.pred_len:, :]).float()
dec_inp = torch.cat([batch_y[:, :self.args.label_len, :], dec_inp], dim=1).float().to(self.device)
# encoder - decoder
if self.args.use_amp:
with torch.cuda.amp.autocast():
if self.args.output_attention:
outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]
else:
outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]
f_dim = -1 if self.args.features == 'MS' else 0
batch_y = batch_y[:, -self.args.pred_len:, f_dim:].to(self.device)
loss = criterion(outputs, batch_y)
train_loss.append(loss.item())
else:
if self.args.output_attention:
outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]
else:
outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]
f_dim = -1 if self.args.features == 'MS' else 0
batch_y = batch_y[:, -self.args.pred_len:, f_dim:].to(self.device)
loss = criterion(outputs, batch_y)
train_loss.append(loss.item())
if (i + 1) % 100 == 0:
# print("\titers: {0}, epoch: {1} | loss: {2:.7f}".format(i + 1, epoch + 1, loss.item()))
speed = (time.time() - time_now) / iter_count
left_time = speed * ((self.args.train_epochs - epoch) * train_steps - i)
# print('\tspeed: {:.4f}s/iter; left time: {:.4f}s'.format(speed, left_time))
iter_count = 0
time_now = time.time()
if self.args.use_amp:
scaler.scale(loss).backward()
scaler.step(model_optim)
scaler.update()
else:
loss =loss.clone()
loss.backward()
model_optim.step()
print("Epoch: {} cost time: {}".format(epoch + 1, time.time() - epoch_time))
train_loss = np.average(train_loss)
vali_loss = self.vali(vali_data, vali_loader, criterion)
test_loss = self.vali(test_data, test_loader, criterion)
print("Epoch: {0}, Steps: {1} | Train Loss: {2:.7f} Vali Loss: {3:.7f} Test Loss: {4:.7f}".format(
epoch + 1, train_steps, train_loss, vali_loss, test_loss))
early_stopping(vali_loss, self.model, path)
if early_stopping.early_stop:
print("Early stopping")
break
adjust_learning_rate(model_optim, epoch + 1, self.args)
best_model_path = path + '/' + 'checkpoint.pth'
self.model.load_state_dict(torch.load(best_model_path))
return self.model
def test(self, setting, test=0):
test_data, test_loader = self._get_data(flag='test')
if test:
print('loading model')
self.model.load_state_dict(torch.load(os.path.join('./checkpoints/' + setting, 'checkpoint.pth')))
preds = []
trues = []
folder_path = './test_results/' + setting + '/'
if not os.path.exists(folder_path):
os.makedirs(folder_path)
self.model.eval()
with torch.no_grad():
for i, (batch_x, batch_y, batch_x_mark, batch_y_mark) in enumerate(test_loader):
batch_x = batch_x.float().to(self.device)
batch_y = batch_y.float().to(self.device)
batch_x_mark = batch_x_mark.float().to(self.device)
batch_y_mark = batch_y_mark.float().to(self.device)
if self.args.add_noise_vali:
batch_x = batch_x + 0.3*torch.from_numpy(np.random.normal(0, 1, size=batch_x.shape)).float().to(self.device)
# decoder input
dec_inp = torch.zeros_like(batch_y[:, -self.args.pred_len:, :]).float()
dec_inp = torch.cat([batch_y[:, :self.args.label_len, :], dec_inp], dim=1).float().to(self.device)
# encoder - decoder
if self.args.use_amp:
with torch.cuda.amp.autocast():
if self.args.output_attention:
outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]
else:
outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]
else:
if self.args.output_attention:
outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]
else:
outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]
f_dim = -1 if self.args.features == 'MS' else 0
batch_y = batch_y[:, -self.args.pred_len:, f_dim:].to(self.device)
outputs = outputs.detach().cpu().numpy()
batch_y = batch_y.detach().cpu().numpy()
pred = outputs # outputs.detach().cpu().numpy() # .squeeze()
true = batch_y # batch_y.detach().cpu().numpy() # .squeeze()
preds.append(pred)
trues.append(true)
#if i % 20 == 0:
# input = batch_x.detach().cpu().numpy()
# gt = np.concatenate((input[0, :, -1], true[0, :, -1]), axis=0)
# pd = np.concatenate((input[0, :, -1], pred[0, :, -1]), axis=0)
# visual(gt, pd, os.path.join(folder_path, str(i) + '.pdf'))
preds = np.array(preds)
trues = np.array(trues)
print('test shape:', preds.shape, trues.shape)
#preds = preds.reshape(-1, preds.shape[-2], preds.shape[-1])
#trues = trues.reshape(-1, trues.shape[-2], trues.shape[-1])
print('test shape:', preds.shape, trues.shape)
# result save
folder_path = './results/' + setting + '/'
if not os.path.exists(folder_path):
os.makedirs(folder_path)
mae, mse, rmse, mape, mspe = metric(preds, trues)
print('mse:{}, mae:{}'.format(mse, mae))
f = open("result.txt", 'a')
f.write(setting + " \n")
f.write('mse:{}, mae:{}'.format(mse, mae))
f.write('\n')
f.write('\n')
f.close()
np.save(folder_path + 'metrics.npy', np.array([mae, mse, rmse, mape, mspe]))
np.save(folder_path + 'pred.npy', preds)
np.save(folder_path + 'true.npy', trues)
return
def predict(self, setting, load=False):
pred_data, pred_loader = self._get_data(flag='pred')
if load:
path = os.path.join(self.args.checkpoints, setting)
best_model_path = path + '/' + 'checkpoint.pth'
self.model.load_state_dict(torch.load(best_model_path))
preds = []
self.model.eval()
with torch.no_grad():
for i, (batch_x, batch_y, batch_x_mark, batch_y_mark) in enumerate(pred_loader):
batch_x = batch_x.float().to(self.device)
batch_y = batch_y.float()
batch_x_mark = batch_x_mark.float().to(self.device)
batch_y_mark = batch_y_mark.float().to(self.device)
# decoder input
dec_inp = torch.zeros_like(batch_y[:, -self.args.pred_len:, :]).float()
dec_inp = torch.cat([batch_y[:, :self.args.label_len, :], dec_inp], dim=1).float().to(self.device)
# encoder - decoder
if self.args.use_amp:
with torch.cuda.amp.autocast():
if self.args.output_attention:
outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]
else:
outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]
else:
if self.args.output_attention:
outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]
else:
outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]
pred = outputs.detach().cpu().numpy() # .squeeze()
preds.append(pred)
preds = np.array(preds)
preds = preds.reshape(-1, preds.shape[-2], preds.shape[-1])
# result save
folder_path = './results/' + setting + '/'
if not os.path.exists(folder_path):
os.makedirs(folder_path)
np.save(folder_path + 'real_prediction.npy', preds)
return
实验运行模块(run.py)
import argparse
import os
import torch
from exp.exp_main import Exp_Main
import random
import numpy as np
#torch.autograd.set_detect_anomaly(True)
fix_seed = 2021
random.seed(fix_seed)
torch.manual_seed(fix_seed)
np.random.seed(fix_seed)
parser = argparse.ArgumentParser(description='Autoformer & Transformer family for Time Series Forecasting')
# basic config
parser.add_argument('--is_training', type=int, default=1, help='status')
parser.add_argument('--model_id', type=str, default='test', help='model id')
parser.add_argument('--model', type=str, default='Reformer',
help='model name, options: [Autoformer, Informer, Transformer]')
#数据加载
parser.add_argument('--data', type=str, default='ETTh1', help='dataset type')# 数据名称
# 数据所在文件夹
parser.add_argument('--root_path', type=str, default='./data/ETT/', help='root path of the data file')
# 数据文件全称
parser.add_argument('--data_path', type=str, default='ETTh1.csv', help='data file')
# 时间特征处理方式
parser.add_argument('--features', type=str, default='M',
help='forecasting task, options:[M, S, MS]; M:multivariate predict multivariate, S:univariate predict univariate, MS:multivariate predict univariate')
# 目标列列名
parser.add_argument('--target', type=str, default='OT', help='target feature in S or MS task')
# 时间采集粒度
parser.add_argument('--freq', type=str, default='h',
help='freq for time features encoding, options:[s:secondly, t:minutely, h:hourly, d:daily, b:business days, w:weekly, m:monthly], you can also use more detailed freq like 15min or 3h')
# 模型保存文件夹
parser.add_argument('--checkpoints', type=str, default='./checkpoints/', help='location of model checkpoints')
# 回视窗口
n = 96
parser.add_argument('--seq_len', type=int, default=n, help='input sequence length')
# 先验序列长度
parser.add_argument('--label_len', type=int, default=int(n/2), help='start token length')
# 预测窗口长度
parser.add_argument('--pred_len', type=int, default=n, help='prediction sequence length')
parser.add_argument('--modes1', type=int, default=16, help='modes to be 64')
parser.add_argument('--L', type=int, default=3, help='ignore level')
parser.add_argument('--base',type=str,default='legendre',help='mwt base')
parser.add_argument('--cross_activation',type=str,default='tanh',help='mwt cross atention activation function tanh or softmax')
#parser.add_argument('--base',type=str,default='chebyshev',help='mwt base')
#模型参数定义
parser.add_argument('--ab', type=int, default=0, help='ablation version')
parser.add_argument('--wavelet', type=int, default=0, help='use wavelet')
# encoder输入特征数
parser.add_argument('--enc_in', type=int, default=7, help='encoder input size')
# decoder输入特征数
parser.add_argument('--dec_in', type=int, default=7, help='decoder input size')
# 输出通道数
parser.add_argument('--c_out', type=int, default=7, help='output size')
# 线性层隐含神经元个数
parser.add_argument('--d_model', type=int, default=512, help='dimension of model')
# 多头注意力机制
parser.add_argument('--n_heads', type=int, default=8, help='num of heads')
parser.add_argument('--e_layers', type=int, default=2, help='num of encoder layers')
parser.add_argument('--d_layers', type=int, default=1, help='num of decoder layers')
parser.add_argument('--d_ff', type=int, default=2048, help='dimension of fcn')
parser.add_argument('--moving_avg',default=[24], help='window size of moving average')
#parser.add_argument('--moving_avg', type=int,action='append', help='window size of moving average')
parser.add_argument('--factor', type=int, default=1, help='attn factor')
parser.add_argument('--distil', action='store_false',
help='whether to use distilling in encoder, using this argument means not using distilling',
default=True)
parser.add_argument('--dropout', type=float, default=0.05, help='dropout')
parser.add_argument('--embed', type=str, default='timeF',
help='time features encoding, options:[timeF, fixed, learned]')
parser.add_argument('--activation', type=str, default='gelu', help='activation')
parser.add_argument('--output_attention', action='store_true', help='whether to output attention in ecoder')
parser.add_argument('--do_predict', action='store_true', help='whether to predict unseen future data')
# optimization
parser.add_argument('--num_workers', type=int, default=0, help='data loader num workers')
parser.add_argument('--itr', type=int, default=2, help='experiments times')
parser.add_argument('--train_epochs', type=int, default=5, help='train epochs')
parser.add_argument('--batch_size', type=int, default=16, help='batch size of train input data')
parser.add_argument('--patience', type=int, default=3, help='early stopping patience')
parser.add_argument('--learning_rate', type=float, default=0.0001, help='optimizer learning rate')
parser.add_argument('--des', type=str, default='test', help='exp description')
parser.add_argument('--loss', type=str, default='mse', help='loss function')
parser.add_argument('--lradj', type=str, default='type1', help='adjust learning rate')
parser.add_argument('--use_amp', action='store_true', help='use automatic mixed precision training', default=False)
# GPU
parser.add_argument('--use_gpu', type=bool, default=True, help='use gpu')
parser.add_argument('--gpu', type=int, default=0, help='gpu')
parser.add_argument('--use_multi_gpu', action='store_true', help='use multiple gpus', default=False)
parser.add_argument('--devices', type=str, default='0,1', help='device ids of multile gpus')
parser.add_argument('--add_noise_vali',type=bool,default=False,help='add noise in vali')
parser.add_argument('--add_noise_train',type=bool,default=False,help='add noise in training')
parser.add_argument('--ours', default=False, action='store_true')
parser.add_argument('--version', type=int, default=0, help='compression')
parser.add_argument('--seasonal',type=int,default=7)
parser.add_argument('--mode_type',type=int,default=0)
parser.add_argument('--ratio', type=float, default=0.5, help='dropout')
args = parser.parse_args()
args.use_gpu = True if torch.cuda.is_available() and args.use_gpu else False
if args.use_gpu and args.use_multi_gpu:
args.dvices = args.devices.replace(' ', '')
device_ids = args.devices.split(',')
args.device_ids = [int(id_) for id_ in device_ids]
args.gpu = args.device_ids[0]
print('Args in experiment:')
print(args)
Exp = Exp_Main
if args.is_training:
for ii in range(args.itr):
# setting record of experiments
setting = '{}_{}_fourCroguidedm2TanhR_ab{}_modes{}_uwl{}_{}_ft{}_sl{}_ll{}_pl{}_dm{}_nh{}_el{}_dl{}_df{}_fc{}_eb{}_dt{}_{}_{}'.format(
args.model_id,
args.model,
args.ab,
args.modes1,
args.wavelet,
args.data,
args.features,
args.seq_len,
args.label_len,
args.pred_len,
args.d_model,
args.n_heads,
args.e_layers,
args.d_layers,
args.d_ff,
args.factor,
args.embed,
args.distil,
args.des, ii)
exp = Exp(args) # set experiments
print('>>>>>>>start training : {}>>>>>>>>>>>>>>>>>>>>>>>>>>'.format(setting))
exp.train(setting)
print('>>>>>>>testing : {}<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<'.format(setting))
exp.test(setting)
if args.do_predict:
print('>>>>>>>predicting : {}<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<'.format(setting))
exp.predict(setting, True)
torch.cuda.empty_cache()
else:
ii = 0
setting = '{}_{}_{}_ft{}_sl{}_ll{}_pl{}_dm{}_nh{}_el{}_dl{}_df{}_fc{}_eb{}_dt{}_{}_{}'.format(args.model_id,
args.model,
args.data,
args.features,
args.seq_len,
args.label_len,
args.pred_len,
args.d_model,
args.n_heads,
args.e_layers,
args.d_layers,
args.d_ff,
args.factor,
args.embed,
args.distil,
args.des, ii)
exp = Exp(args) # set experiments
print('>>>>>>>testing : {}<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<'.format(setting))
exp.test(setting, test=1)
torch.cuda.empty_cache()
跑10个epoch的训练结果如下,测试数据集的loss达到了0.93

总结
FiLM模型通过结合Legendre多项式投影、Fourier投影以及低秩近似等策略,显著提升了长期时间序列预测的准确性,实验结果显示,FiLM模型在多变量和单变量的长期时间序列预测任务上均实现了显著的性能提升,分别提高了20.3%和22.6%的准确性。此外,FiLM模型的灵活性体现在其模块化的构建上,使得该框架可以作为通用插件应用于其他深度学习模型,以改善其长期预测性能。例如,通过替换LPU中的Legendre多项式投影为其他正交基函数(如Fourier、Wavelets等),或者根据噪声特性调整FEL的策略,都有望进一步拓展FiLM的应用范围和效能。实验不仅验证了FiLM相对于当前SOTA模型的优越性,还展示了其作为一个通用插件模块,能够有效增强其他深度学习模型的长期预测性能。通过精心设计的实验设置和全面的评估,FiLM模型展现了其在实际应用中的巨大潜力,为长期时间序列预测领域带来了新的研究视角和技术进展。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









