










K-Nearest Neighbor (KNN)
📘 中英对照标题翻译:
-
K-Nearest Neighbor (KNN)
最近邻算法(KNN)
🧠 通俗解释:
KNN 是一种最简单的机器学习分类方法,它的核心思想就像这样👇:
“你是什么类型的人?看看你最接近的那几个邻居是什么样的。”
假设你搬到一个新城市,你不知道自己属于哪个社交圈(例如,运动爱好者、游戏宅、还是书虫📚)。你就看看你周围最近的 3 个邻居(K=3)是哪些类型的人,如果他们都爱打篮球,那你大概率也会被归为运动爱好者!
🎓 用最基础的术语解释 KNN:
-
你有一堆“训练数据” → 就像过去认识的人,每个人都告诉你“我是谁”(属于哪一类)。
-
然后来了一个“新朋友” → 你不知道他属于哪类。
-
KNN 就是通过测量这个人和别人有多“接近”(用距离,比如欧几里得距离),看看他最接近的 K 个人属于哪类,然后把他归进去。
👶 类比解释:你走进一间教室,看到大家穿的衣服颜色都不一样:
-
红色代表“理科生”,蓝色代表“文科生”。
-
你穿的是粉色,你站在教室的某个位置。
-
你观察你最近的3个人:他们都是红色衣服 → 那你可能是“理科生”。
🤔 为什么叫“K-最近邻”?
-
“K” 是你观察的邻居数量(比如最近的3个、5个……)。
-
“最近邻”指的是那些在特征空间里最接近你的人,比如你的身高、体重、爱好都和他们很像。
📌 你只需要记住:
KNN = 看看你最接近的 K 个老朋友是啥类型 → 你也就归到那个类型啦!
🔹Lecture 10, Page 3 — K-Nearest Neighbor (KNN)
K-Nearest Neighbor (KNN)
K 最近邻算法
📘系统讲解
K 最近邻算法(简称 KNN),这是一个非常基础、直观但有效的分类算法。
你可以理解为:
想知道一个新同学喜欢什么类型的音乐?那就看看跟他最像的几个老同学喜欢什么,就“投票”决定这个新同学的喜好。
KNN 就是这么简单!
✏️出题时间
填空题(Blank-filling):
The abbreviation "KNN" stands for ________________.
✅ Correct Answer: K-Nearest Neighbor
选择题(Multiple Choice):
What is the main idea of the KNN algorithm?
A. Building a deep neural network
B. Finding the shortest path
C. Comparing a new sample with its nearest neighbors
D. Training a decision tree
✅ Correct Answer: C. Comparing a new sample with its nearest neighbors
📍中文解析:
KNN 的核心思想就是“看你周围像你的人都是什么类别”,然后你也被归为这个类别。这跟 A、B、D 无关。
🧃通俗总结
你可以把 KNN 想象成“看邻居选归属”的算法:
你搬到一个新小区,想知道你是被归为“打篮球的群体”还是“下围棋的群体”?你就看看你周围的 K 个邻居里谁最多,如果 3 个邻居里有 2 个爱下围棋,那你大概率也被归到这个圈子!
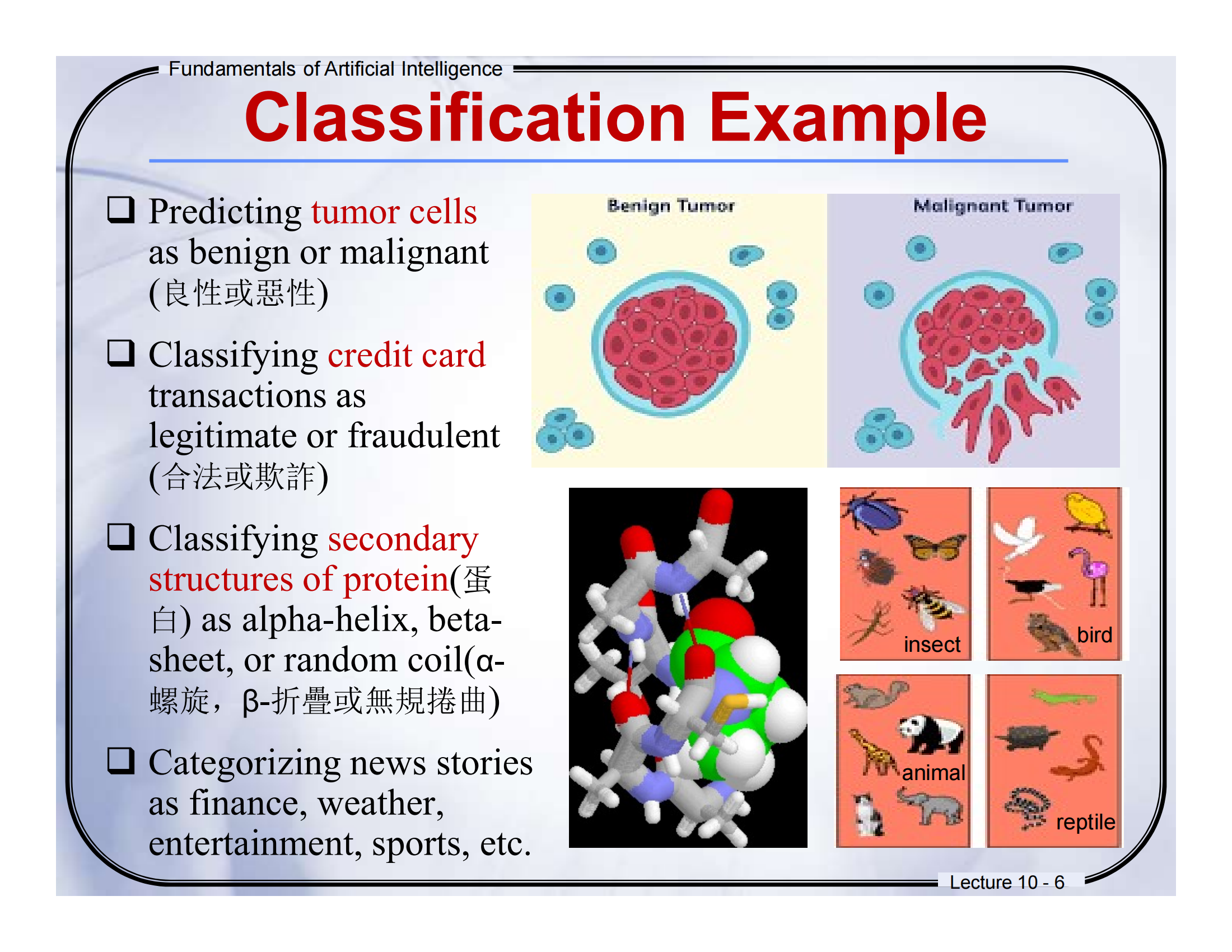
🔹Lecture 10, Page 4 — What is Classification?
🈶中英对照翻译
What is Classification?
什么是分类?
-
Given a collection of records (training set)
给定一组记录(训练集)-
Each record contains a set of attributes, one of the attributes is the class.
每条记录包含一组属性,其中一个属性是类别。
-
-
Find a model for class attribute as a function of the values of other attributes.
找到一个模型,将类别看作是其他属性值的函数。 -
Goal: previously unseen records should be assigned a class as accurately as possible.
目标:对之前没见过的记录,尽可能准确地分配一个类别。 -
A test set is used to determine the accuracy of the model.
使用测试集来评估模型的准确性。-
通常,将数据分为训练集和测试集,训练集用于建立模型,测试集用于验证模型。
-
📘系统讲解
这一页解释了“分类”这个任务本身是干嘛的:
-
训练集(Training Set):我们先拿到一堆“有标签的数据”,比如:
-
一堆狗的图片(🐶)都标好了这是“狗”;
-
一堆猫的图片(🐱)都标好了是“猫”。
-
-
属性(Attributes):每张图片都有很多属性,比如毛的颜色、耳朵的形状、尾巴的长度等。
-
目标(Goal):我们训练一个模型,让它“学会根据这些属性猜类别”。
-
测试集(Test Set):训练完后,再拿新的“没见过”的图像(比如一只新猫)让模型判断,看看它准不准。
🧠 核心思想:我们通过学习有标签的数据(有答案),来预测没标签的数据。
✏️出题时间
填空题(Blank-filling):
A classification model is trained using a __________ and evaluated using a __________.
✅ Correct Answer: training set, test set
选择题(Multiple Choice):
What is the goal of classification?
A. To find the shortest path between nodes
B. To predict numerical outcomes
C. To assign labels to new, unseen records based on past data
D. To compress the dataset into smaller dimensions
✅ Correct Answer: C. To assign labels to new, unseen records based on past data
📍中文解析:
分类的核心任务就是:拿新来的数据,判断它应该属于哪一类。所以答案是 C。
🧃通俗总结
“分类”其实就像你第一次见一个人,虽然你不知道他是谁,但你会根据他穿的衣服、说话口音、走路姿势来判断他是不是某个学校/社团/兴趣小组的。
我们教“计算机”也这么干:用已经知道身份的样本(训练集)来训练它,之后它就能“靠特征猜身份”了。

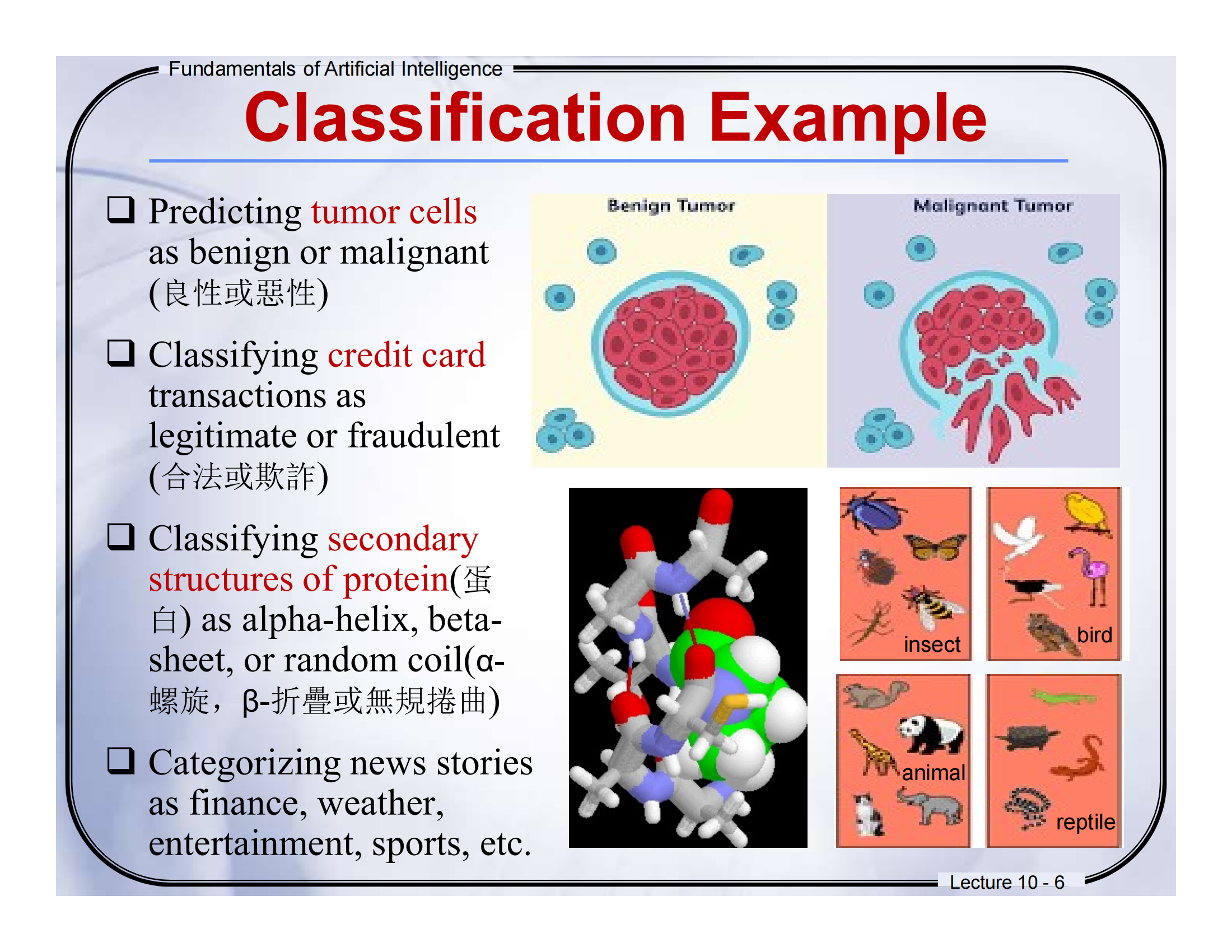
🔹Lecture 10, Page 5 — What is Classification?(续)
🈶中英对照翻译
-
Training Set(训练集):包含已知类别的记录,用于“学习模型”。
-
Test Set(测试集):包含未知类别的记录,用于“测试模型”。
-
Induction(归纳):
-
从训练数据中“学习”一个模型
-
图中箭头表示从数据进入“Learn Model”(学习模型)这个步骤
-
-
Deduction(推理):
-
使用已经学到的模型去“推断”测试数据的类别
-
图中箭头表示将“模型”用于测试数据,从而得到分类结果
-
-
Classification is the arrangement of organisms into orderly groups based on their similarities.
分类是把对象按照它们的相似性,整理成有序的类别。
📘系统讲解
💡 训练与测试流程
-
我们先拿到一个带有“Class(类别)”标签的数据集,叫训练集。
-
用这个训练集来训练模型(Learn Model),模型就是一个能预测“新数据类别”的公式或方法。
-
然后我们用测试集,里面的数据没有类别标签(用“?”表示),来验证模型有没有学好。
🧠 两个关键词:
-
Induction(归纳):从已知情况(训练数据)出发,归纳出一个通用的模型;
-
Deduction(推理):用这个模型去判断未知情况(测试数据)。
🐶 类比一下:
就像你告诉计算机:“大多数猫都有尖耳朵,柔软的毛,有胡须”,这是归纳;
之后拿一个新动物问它“这是不是猫”,它根据你教过的来判断,就是推理!
✏️出题时间
填空题(Blank-filling):
________ is the process of learning a general model from training data, and ________ is the process of applying that model to unseen data.
✅ Correct Answer: Induction, Deduction
选择题(Multiple Choice):
In the classification process, what is the purpose of the training set?
A. To test the prediction power of the model
B. To assign random labels
C. To build the model
D. To reduce data size
✅ Correct Answer: C. To build the model
📍中文解析:
训练集的作用就是训练模型(build the model),而不是拿来测试。
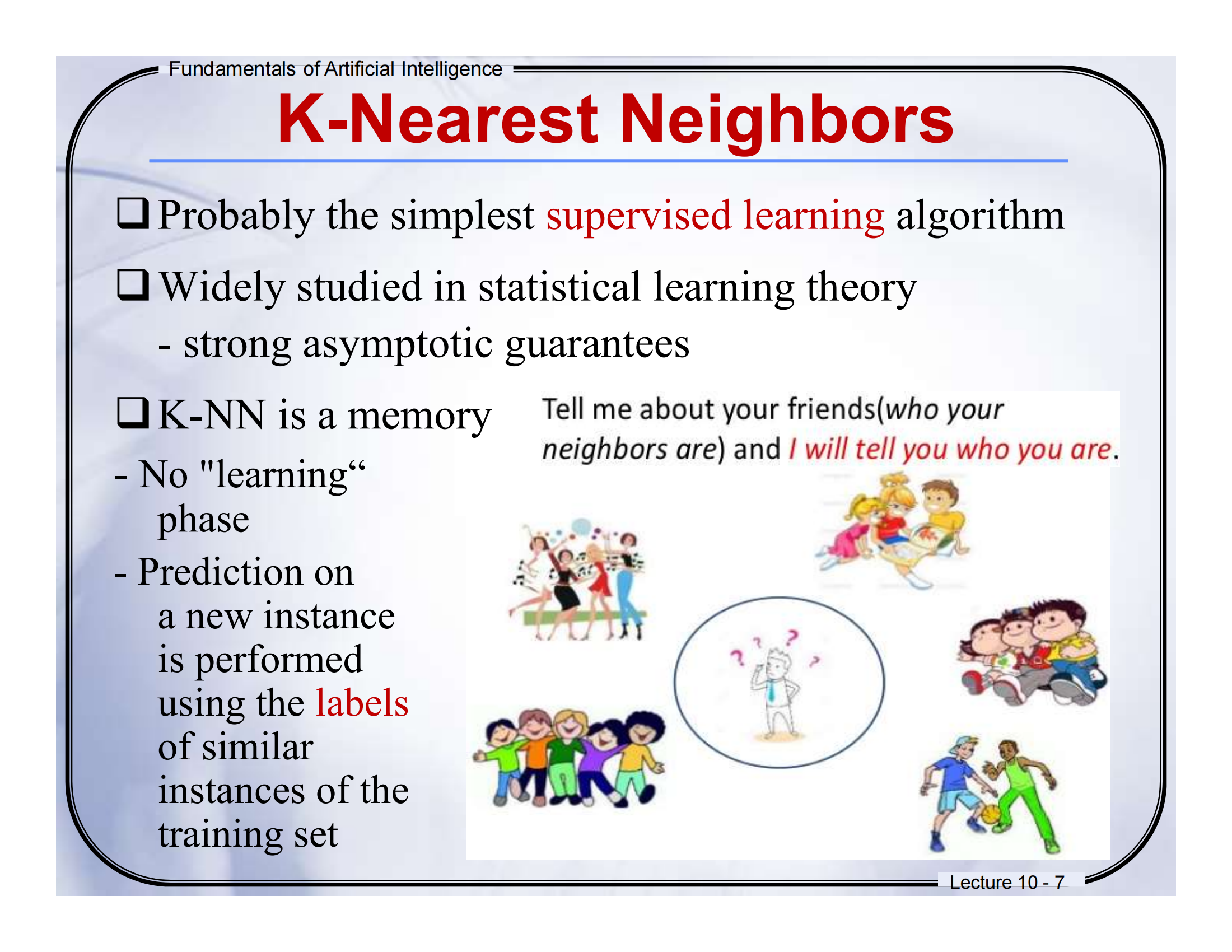
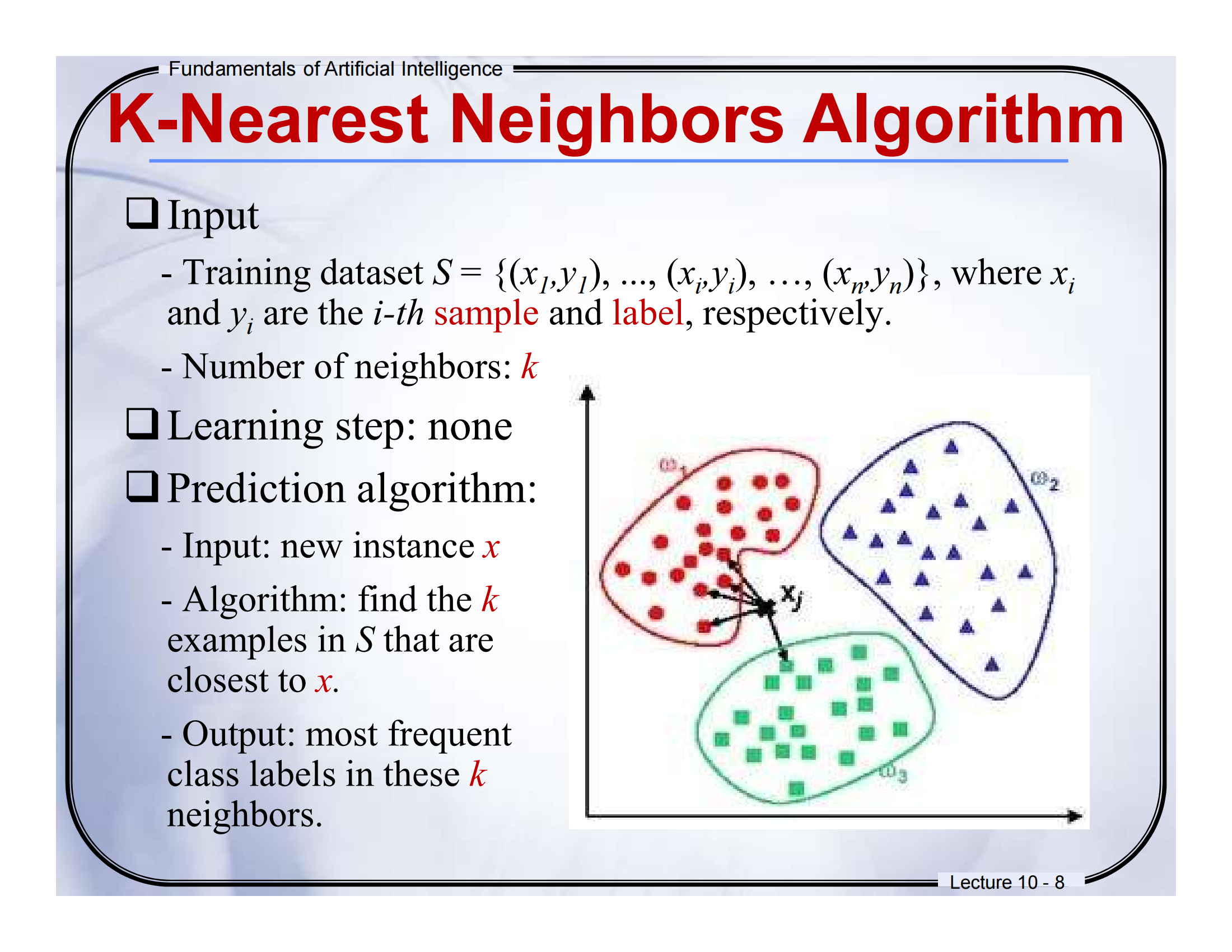
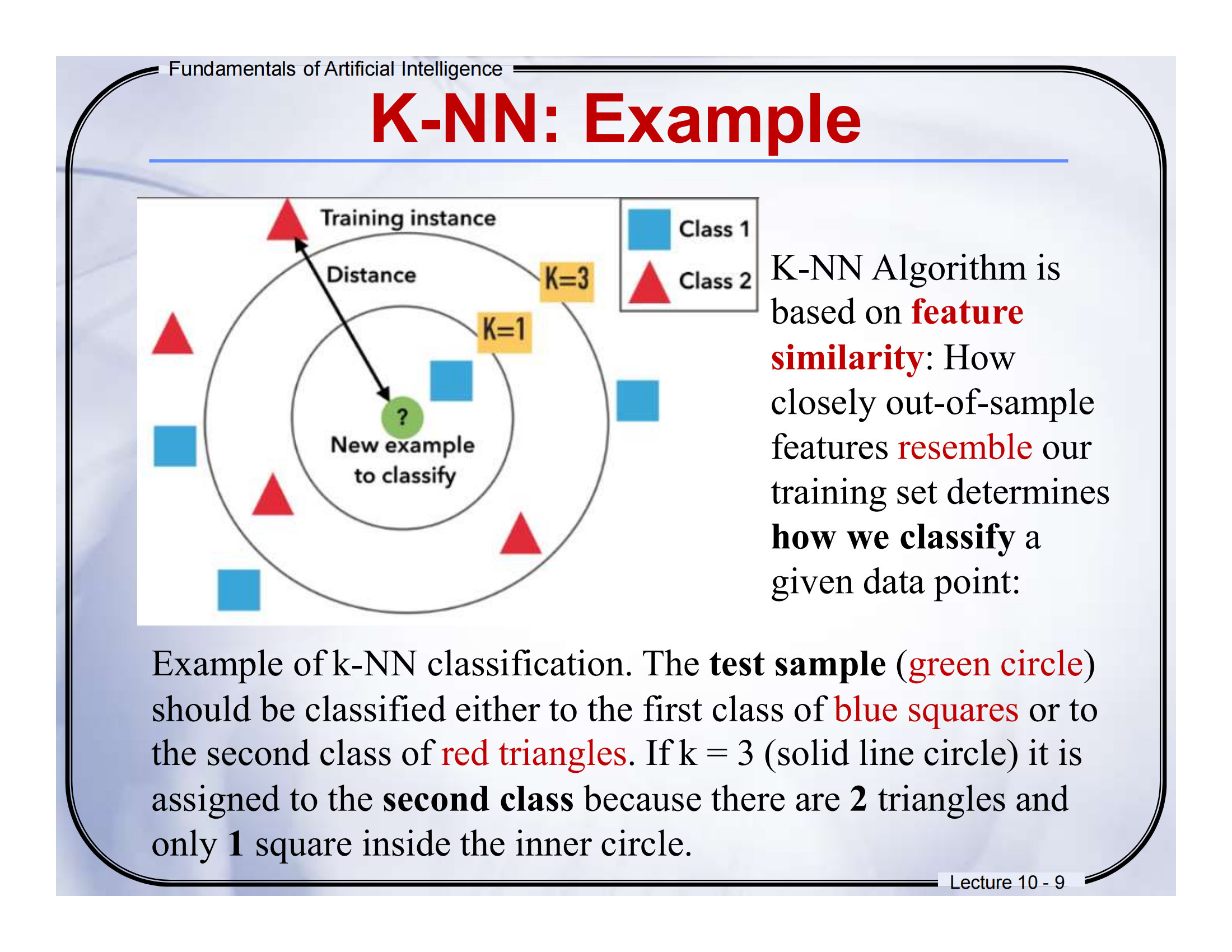
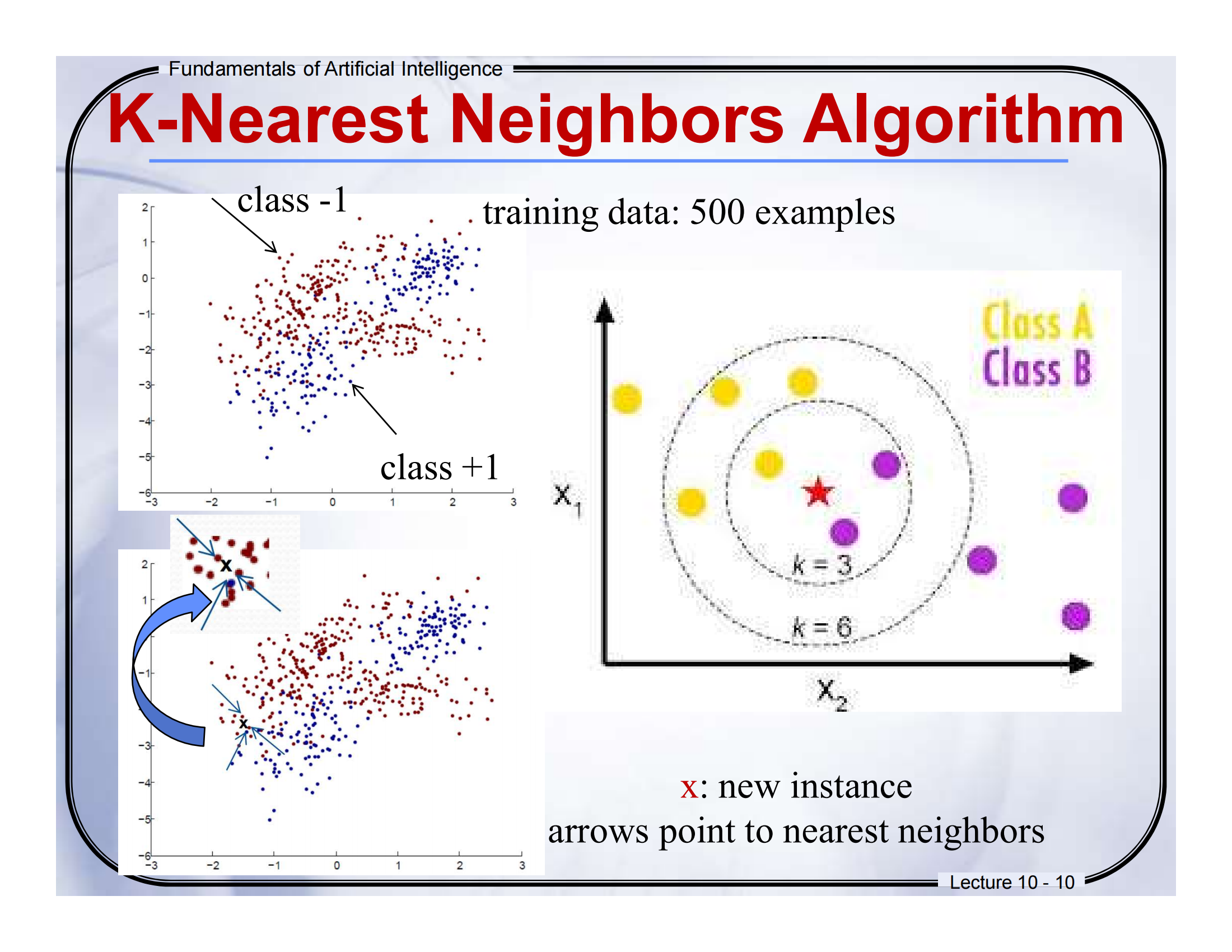
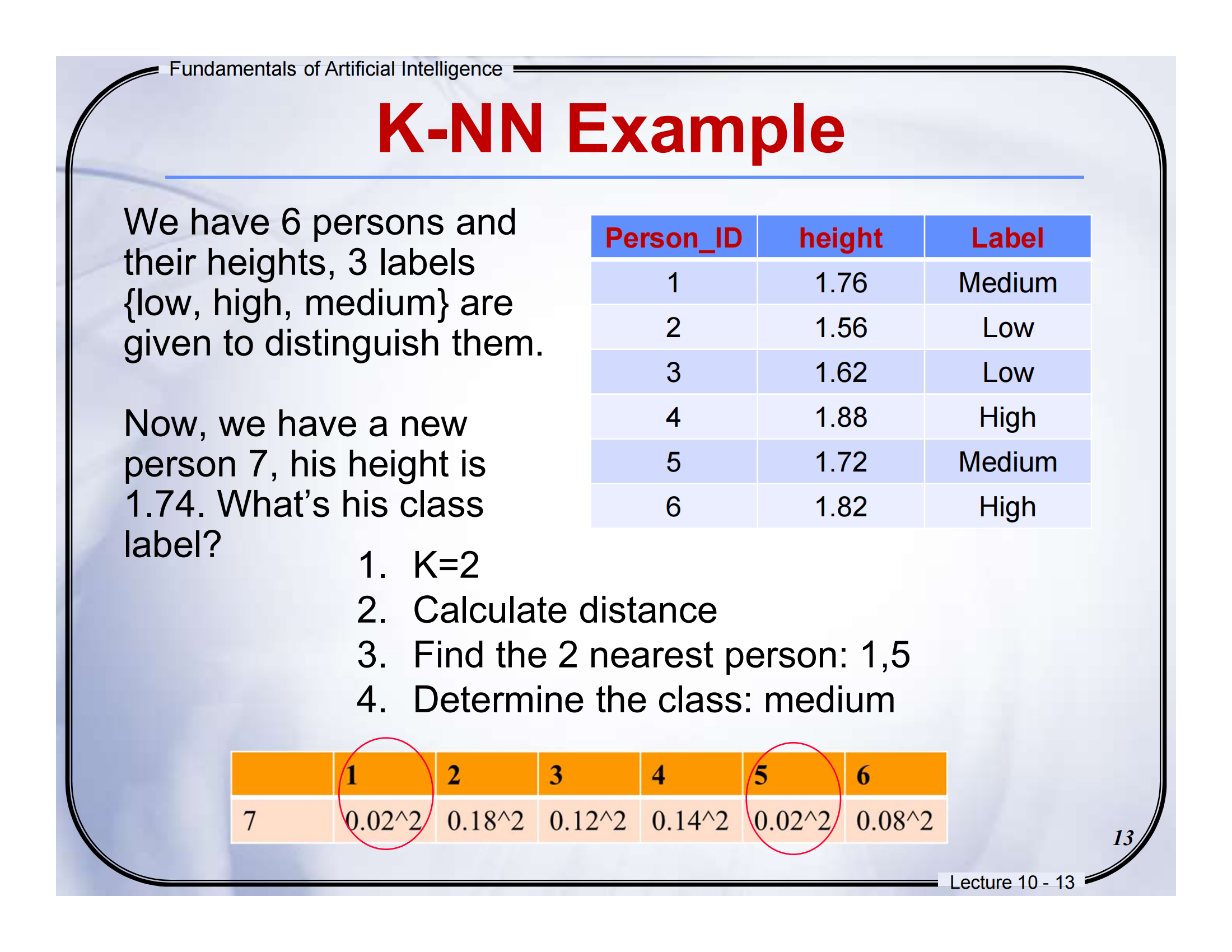
🧠 Lecture 10 - Page 10
📘 页面标题:K-Nearest Neighbors Algorithm
📕中英文对照翻译(结合图解)
-
Training data: 500 examples
训练数据:500 个样本点
图中左上角红色点属于class -1,蓝色点属于class +1,就是我们事先标注好类别的“老样本”。 -
x: new instance
x:新的样本
图中红色五角星是我们想要分类的“新点”。 -
Arrows point to nearest neighbors
箭头指向最近的邻居
箭头指出的就是离这个“新点 x”最近的若干训练点。 -
k = 3, k = 6
k=3 或 k=6 的意思是:找最近的 3 个(或 6 个)邻居来投票
图中圆圈就是“以 x 为中心的邻近区域”,你看,黄色(Class A)和紫色(Class B)都在这个范围里。
📘图示解析 + 通俗解释
KNN的核心思想就是:“看你周围的人是谁,我就猜你是啥”。
比如:
-
图中五角星是我们要分类的“新点”,
-
我们看看它最近的邻居是谁(比如 3 个邻居),
-
如果最近的邻居里多数是紫色(Class B),那就认为它也属于 B 类。
就像你在操场上,周围都是踢球的同学,别人可能就猜你也是踢球的。
📝填空题(Fill-in-the-blank)
Q: In the KNN algorithm, we classify a new instance by checking its _____\_\_\_\_\_ neighbors in the training data.
A) farthest
B) k-nearest
C) oldest
D) largest
✅ Answer: B
📘 中文解析:KNN 的核心就是“找最近的 k 个邻居”,所以选 B。
🎯选择题(Multiple-choice)
Q: What happens when we increase the value of kk in the KNN algorithm?
A) We look at fewer neighbors
B) The classification becomes noisier
C) The decision becomes smoother and less sensitive to noise
D) The training data is ignored
✅ Answer: C
📘 中文解析:k 越大,考虑的邻居越多,分类时更“平均”,对单点异常值更不敏感,结果更平滑。
🧸一句话通俗总结(口语风)
KNN 就像是“你是和谁最像的?投票决定你是谁”,新来的点看周围谁多就归谁,超级直觉简单!

🧠出题练习:
填空题 Fill in the Blank:
KNN does not have a learning phase, so it is often called a ___ algorithm.
→ Answer: lazy
选择题 Multiple Choice:
What is the output of the KNN algorithm?
A. A distance matrix
B. The predicted label based on nearest neighbors
C. A trained model
D. A decision tree
→ Answer: B
→ 解析: KNN 的输出是根据邻近样本预测出的标签。
🗣️通俗总结:
这一页告诉你:KNN 没有建模环节,它是“记忆型选手”。你给它新问题,它就翻字典——看看谁最像你,多数投票决定你是谁。

🧠出题练习:
填空题 Fill in the Blank:
If k = 3 and 2 out of 3 neighbors are Class 2, the test sample will be classified as ____.
→ Answer: Class 2
选择题 Multiple Choice:
What is the main assumption of KNN?
A. Data must be Gaussian
B. Features must be labeled
C. Similar points are likely to have the same label
D. Model must be trained first
→ Answer: C
→ 解析: KNN 基于相似性:相近的数据点标签可能一样。
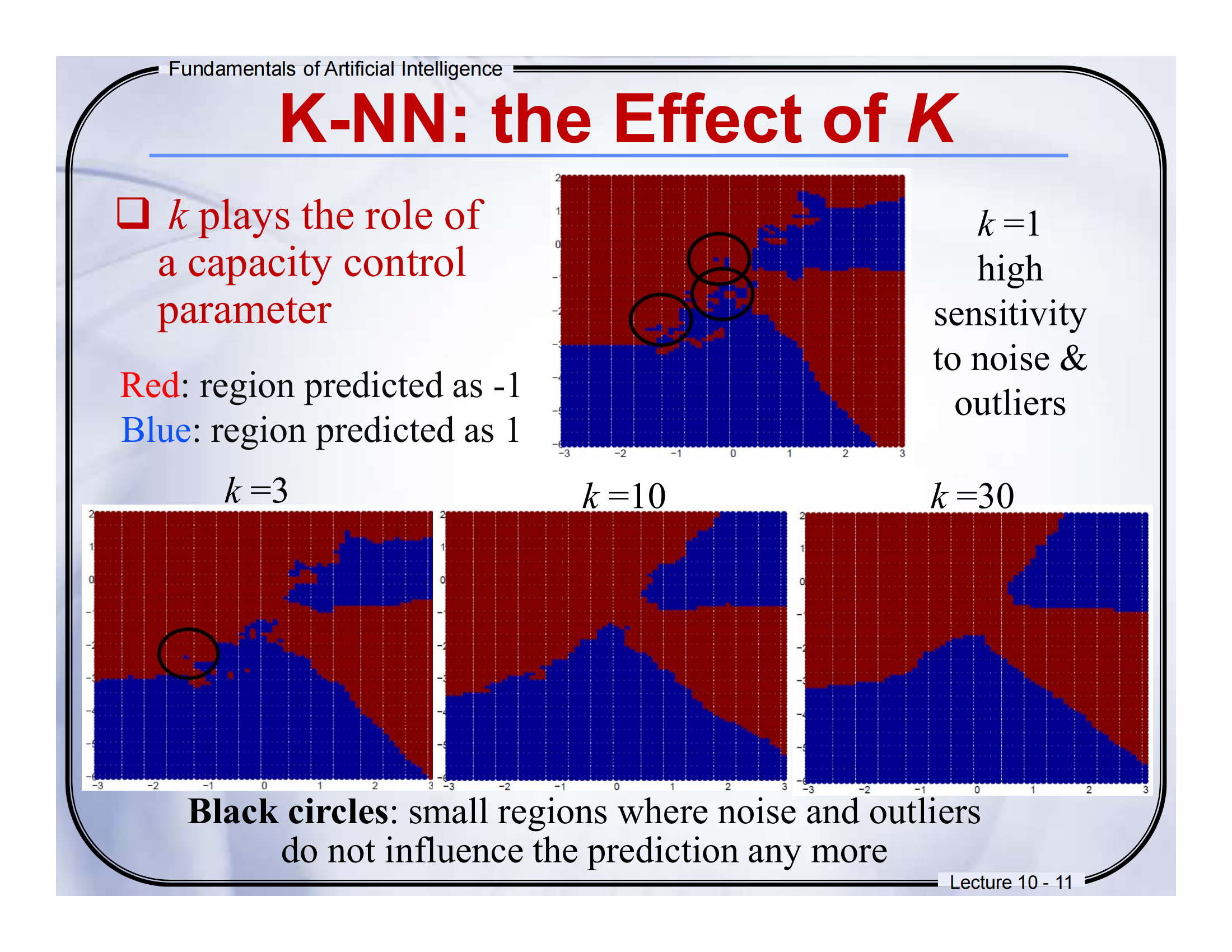
📘 第 11 页:K-NN: the Effect of k
一、中英文翻译对照:
-
k plays the role of a capacity control parameter
k 是控制模型容量的参数(越小越“灵活”,越大越“保守”) -
Red: region predicted as -1
红色区域表示被预测为类别 -1 -
Blue: region predicted as 1
蓝色区域表示被预测为类别 1 -
k = 1 → high sensitivity to noise & outliers
当 k = 1 时,对噪声和离群值非常敏感 -
Black circles: small regions where noise and outliers do not influence the prediction any more
黑圈:表示随着 k 增大,噪声和离群值不再影响预测的区域
二、图示讲解(适合零基础)
-
当 k = 1 时,只看最近的一个邻居 → 很容易被“坏点”干扰。
-
当 k 慢慢变大(k = 3、10、30)时,决策边界变得更平滑,也就是说模型更稳定、更鲁棒。
-
黑圈表示:这些区域原本容易受到噪声影响,但因为 k 大了,模型忽略了这些小异常,预测结果不变。
三、英文练习题
填空题(Fill-in-the-blank)
Increasing the value of kk in K-NN generally makes the decision boundary more ________.
A) sharp
B) random
C) smooth
D) noisy
✅ 答案:C
🈶 中文解析:k 越大,受单个点影响越小,预测区域边界会更平滑。
选择题(MCQ)
Which of the following statements is TRUE when k=1k = 1 in K-NN?
A) Prediction is robust to outliers.
B) The decision boundary becomes smooth.
C) The model becomes highly sensitive to noise.
D) All test samples will be predicted as the majority class.
✅ 答案:C
四、通俗总结(打比方)
你可以把 k 想象成“你问几个朋友的建议”。
-
如果你只问 1 个朋友(k=1),他刚好是个“怪人”,你就被误导了。
-
如果你问 10 个朋友,他们多数说好,那你就更有信心了。
-
所以 k 不能太小也不能太大!
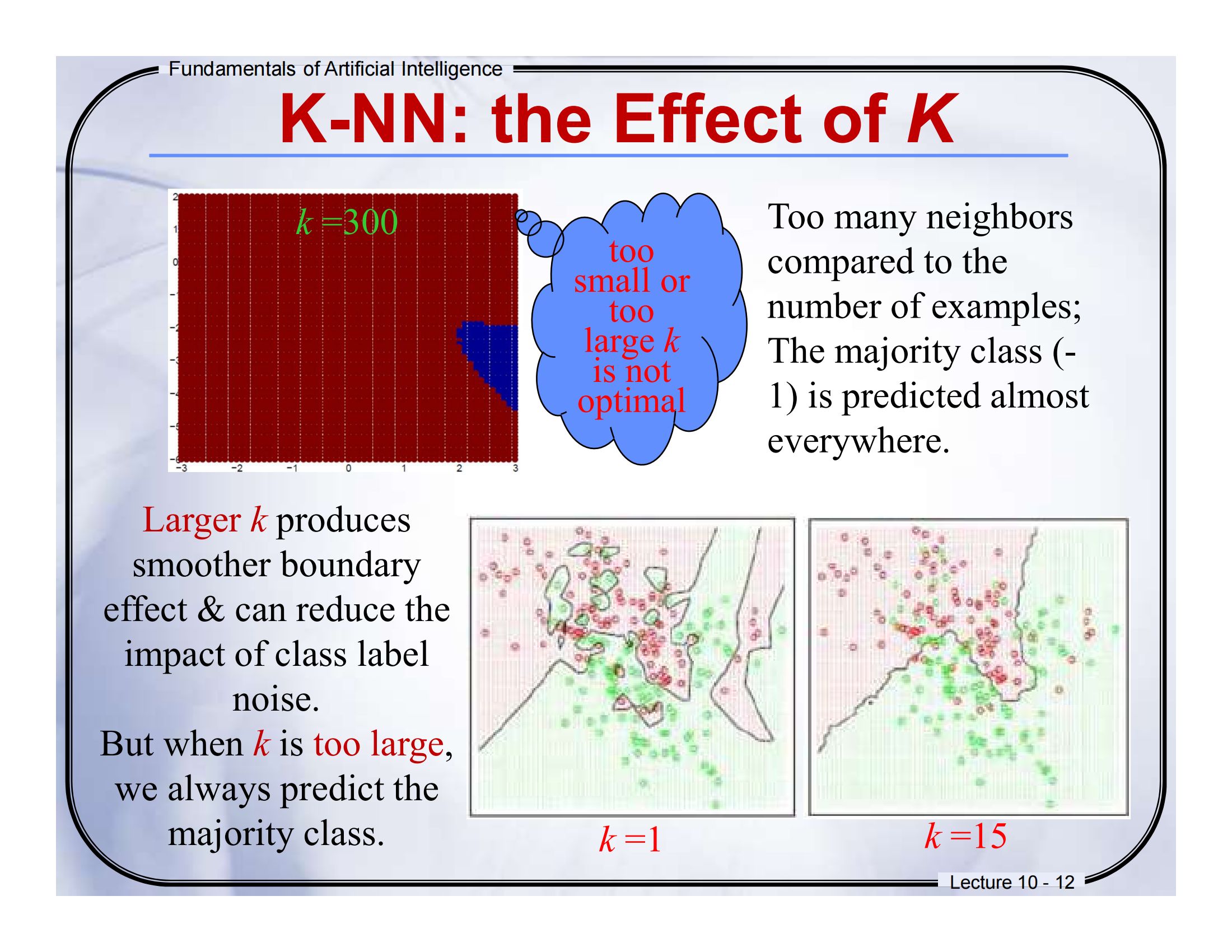
📘 第 12 页:K-NN: the Effect of k (Too Large)
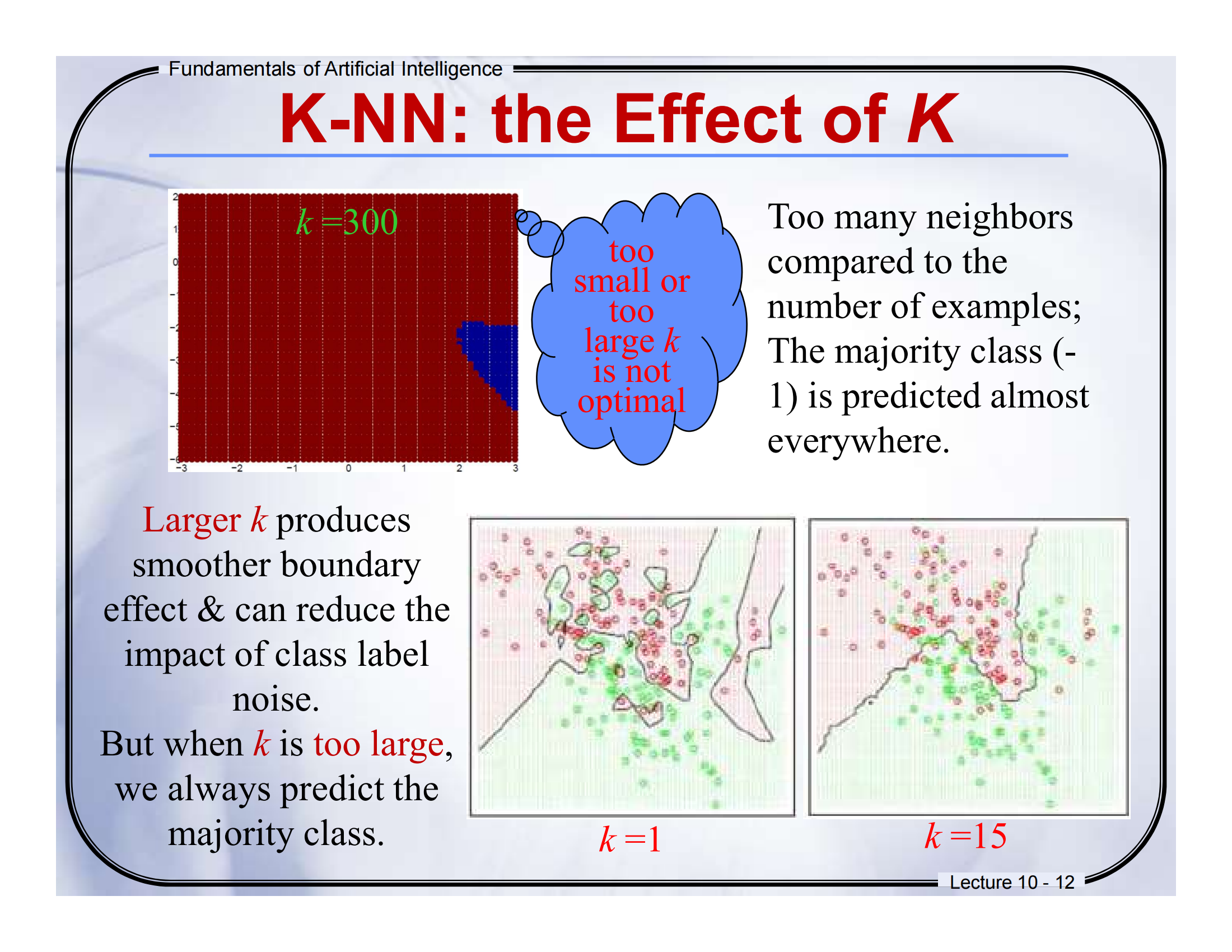 一、中英文翻译对照:
一、中英文翻译对照:
-
Too many neighbors compared to the number of examples
相对于样本数量,邻居数太多 -
The majority class (-1) is predicted almost everywhere
几乎所有地方都预测为多数类(-1) -
Larger k produces smoother boundary effect & can reduce the impact of class label noise
较大的 k 会产生更平滑的边界,并减小标签噪声影响 -
But when k is too large, we always predict the majority class
但如果 k 太大,会忽略小众类 → 全部变成“大多数”!
二、图示讲解
-
当 k 设为 300 时,预测几乎全是红色(类 -1),因为它是数据中的“大多数类”。
-
下面的图显示:
-
左图:k=1,有很多局部边界,非常“抖动”
-
右图:k=15,边界更平滑,但小类也容易被忽略
-
三、英文练习题
填空题
When kk is too large in a K-NN model, it tends to predict the ________ class.
✅ 答案:majority
🈶 中文解析:k 太大时,就像“多数投票”把所有小群体都吞没了。
选择题
What is a disadvantage of using too large kk in K-NN?
A) Overfitting
B) Too sensitive to noise
C) Too slow to compute
D) Ignores minority class
✅ 答案:D
四、通俗总结
就像你问了 300 个人意见,但有 290 个都说一样的答案 → 结果就是被“多数派”控制了思路。
✅ 大 k → 更稳定
❌ 太大 → 什么都预测成“大类”,小类被忽略!
📘 第 13 页:K-NN Summary
一、中英文翻译对照:
-
K-NN can be used for classification
KNN 可以用来做分类 -
Predicts a class — a discrete value
预测的是一个离散值的类别标签 -
Majority vote of its neighbors
通过“邻居多数投票”来决定类别
✅ 优点(Advantages):
-
不需要提前知道决策函数的形式(无需“假设”)
-
易于实现,有数学保证
-
在数据维度不高、大样本情况下效果好
❌ 缺点(Disadvantages):
-
预测时计算开销大(每次都要算距离)
-
需要大量样本才能学习到真实边界
-
距离度量方式(比如欧几里得距离)和 k 值的选取很关键!
二、图示讲解
-
红色:强调 KNN 是通过“多数投票”决定分类结果。
-
不需要模型训练,但每次预测都要查“所有邻居” → 算力开销大。
三、英文练习题
填空题
K-NN predicts the class of a new instance using the ________ vote of its neighbors.
✅ 答案:majority
选择题
四、通俗总结
KNN 就像“问周围人意见”。你不自己判断,而是靠邻居表决。
-
好处:简单、零预设
-
坏处:每次都要挨个问,太慢、太吃力
-
所以选好 k 和距离计算方式非常关键!

📄 Slide 15 — Support Vector Machine (SVM)
📕翻译 Translation:
-
Support Vector Machine (SVM)
→ 支持向量机
📘讲解:
SVM 是一种强大的监督学习方法(supervised learning),在图像识别、人脸检测、文本分类等领域都很有用。
🎯一句话总结:
SVM 就是帮我们“画出最合适的一条线”,把不同类别的数据分开!
📄 Slide 16 — SVM: Introduction
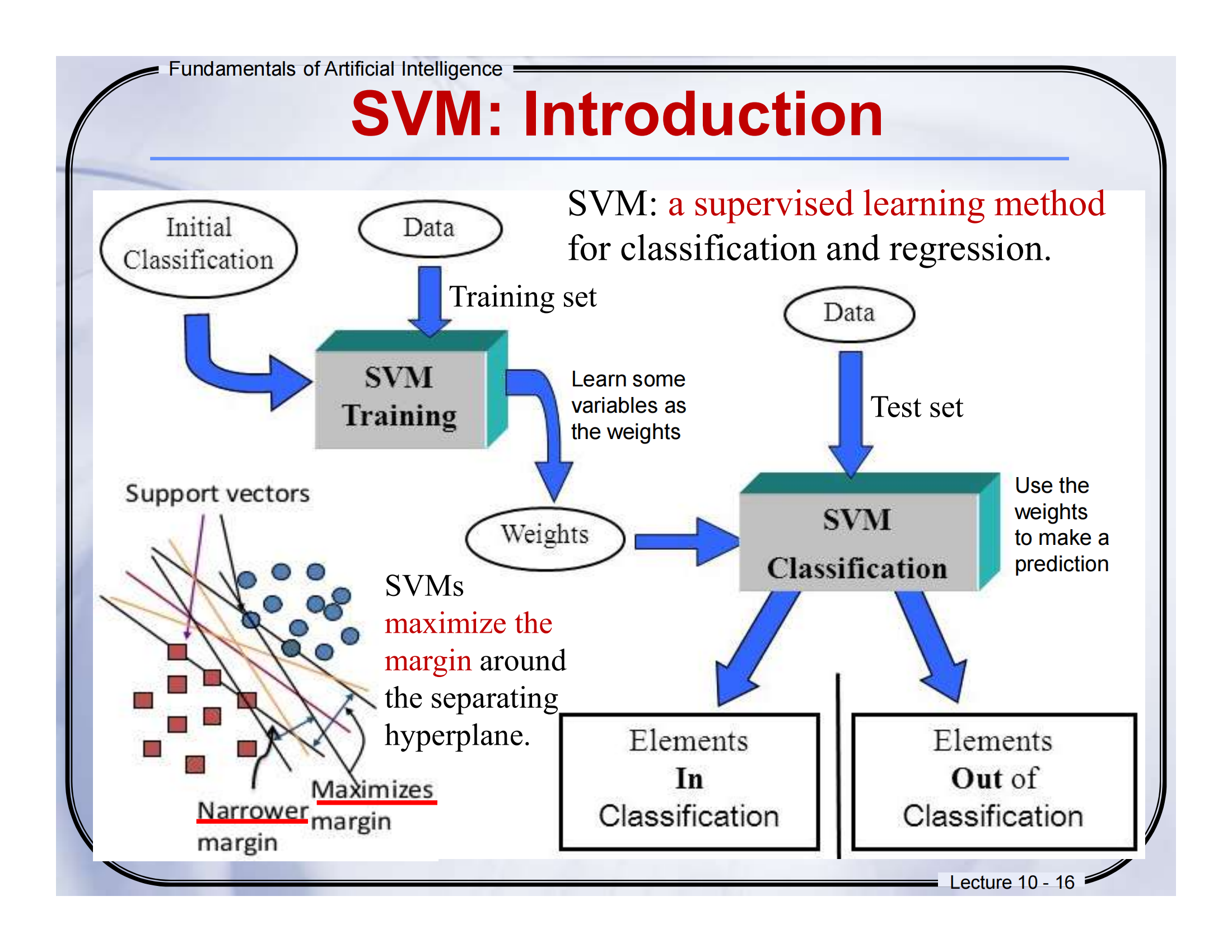 📕翻译:
📕翻译:
-
SVM:一种用于分类和回归的监督学习方法。
-
左图:SVM 的训练阶段会找到最好的“分隔边界”。
-
SVM 会最大化(maximize)这个分隔面的“边距”(margin)。
-
右图:我们通过“训练集”训练模型,再用“测试集”预测结果。
📘讲解:
想象一下你有一群红豆和绿豆混在一起,我们的目标就是找到一条“线”把它们分开。SVM 会找到离红豆和绿豆中“最靠近的点”都最远的那条线(这就叫“最大化边距”),这让分类更稳健、不容易出错。
🧠出题:
-
填空题:
SVM tries to maximize the ______ around the separating hyperplane.
✅答案:margin
🧠中文解析:SVM 的核心思想就是“拉大边距”,更远的分界线更稳定。 -
选择题:
Which of the following best describes SVM?
A. A clustering method
B. A supervised method that maximizes margin
C. A probability model
✅答案:B
🧠中文解析:SVM 是监督学习方法,核心是“最大化边界”。
🎯一句话总结:
SVM 想的就是“我画一条最安全的线,中间距离两边数据都最远”!
📄 Slide 17 — Linear Classifiers
 📕翻译:
📕翻译:
-
黑点表示 +1 类,白圈表示 -1 类。
-
问题:如何画一条线把这两类数据分开?
-
我们要找到一个函数
f(x) = sign(wᵀx + b)来决定每个点属于哪个类。
📘讲解:
这是在引出:分类就是“划线”问题。
用一个公式(其实是一个直线公式)来判断:在这条线左边就是一类,右边就是另一类。
如果你学过 y = ax + b,这里的 wᵀx + b 就是类似的概念,只不过 x 是多维的点,w 是你选择的“斜率”。
🎯一句话总结:
我们要学的,是“如何找对那条线”。
📄 Slide 18 — Linear Classifiers (Which Line is Best?)
 📕翻译:
📕翻译:
-
有很多条线都可以分开这两类,但哪条最好?
-
经验法则:选那条“分得最开的线”,也就是让两类之间最远的线。
📘讲解:
不是随便找条能分开的线就好。SVM 选择的是最优线,也就是“安全距离最大”的线。
这让模型在“遇到新数据”时更有鲁棒性(不容易出错)。
🧠出题:
-
填空题:
A linear classifier separates data using a ________.
✅答案:hyperplane
🧠解析:超平面是高维空间中类似于“线”的边界。 -
选择题:
What does SVM select as the best classifier?
A. The line with most correct predictions
B. The line closest to all points
C. The line with the widest margin
✅答案:C
🧠解析:SVM 的目标是最大化 margin(边界间隔)。
🎯一句话总结:
SVM 不光“能分开”,而是“分得最远”!
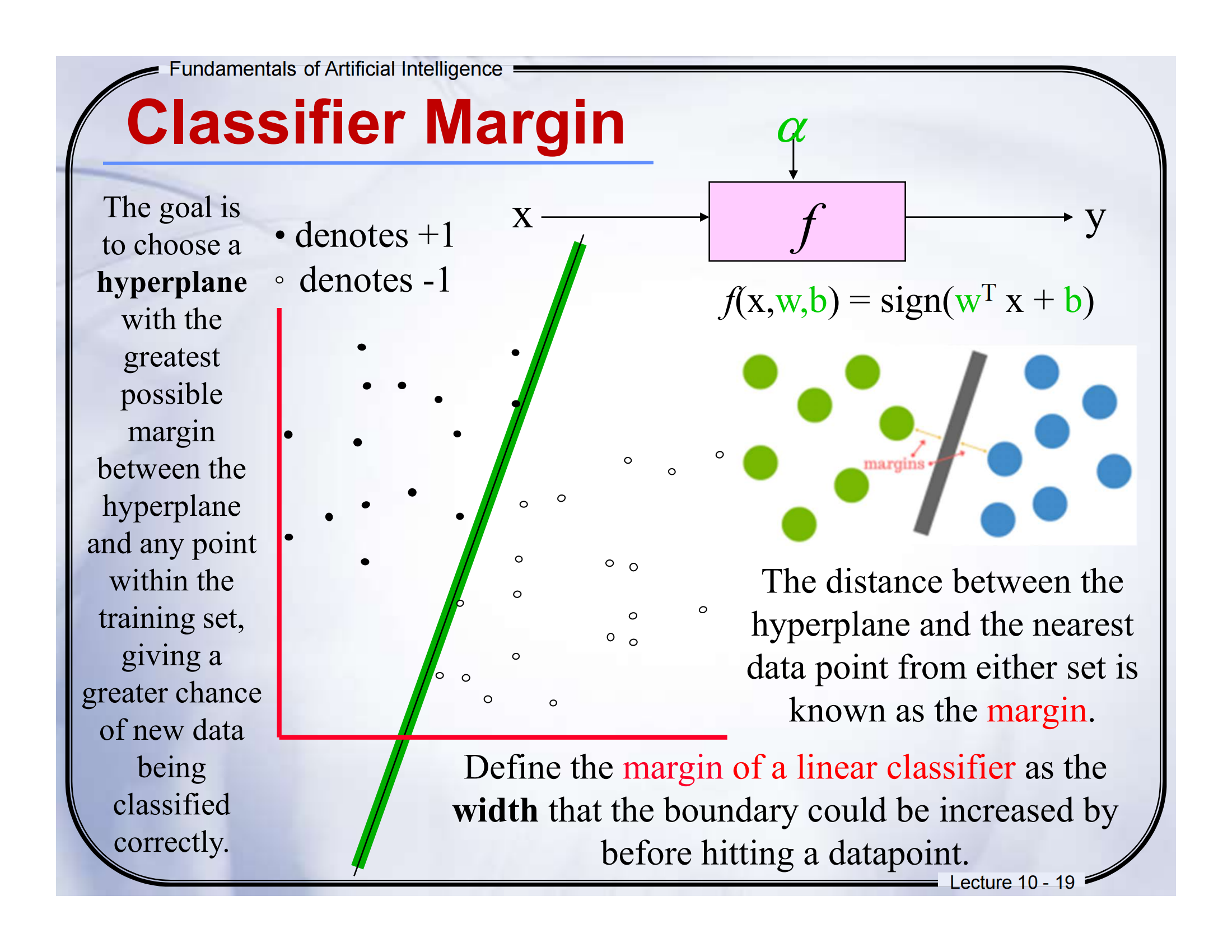
🔹Lecture 10 - 19:Classifier Margin
🈶 中英对照翻译:
-
The goal is to choose a hyperplane with the greatest possible margin between the hyperplane and any point within the training set.
目标是选择一个使超平面与训练集中任意点之间的间隔最大的超平面。 -
The margin gives a greater chance of new data being classified correctly.
较大的间隔有助于新样本被正确分类。 -
Define the margin of a linear classifier as the width that the boundary could be increased by before hitting a datapoint.
线性分类器的“间隔”定义为决策边界在碰到样本点之前可以扩展的“宽度”。
📘 通俗解释:
-
超平面就像是“把两类数据分开的一堵墙”。
-
间隔(Margin)越大,代表你这堵墙“离两边数据都更远”,分类更稳。
-
它的本质是:你希望找一个“最安全的决策线”,不要贴得太近任何一个数据点。
📝 出题练习:
填空题:
The margin is the __________ between the hyperplane and the nearest data point.
👉 答案:distance(距离)
选择题:
Which of the following is true about a larger margin?
A. More overfitting
B. More generalization
C. Less safety margin
D. More noise
👉 答案:B。
🧠 中文解析:更大的间隔意味着模型泛化能力更强,不容易过拟合。
🧾 总结一句话:
“间隔越大,分类越可靠!”
🔹Lecture 10 - 20:Support Vectors & Linear SVM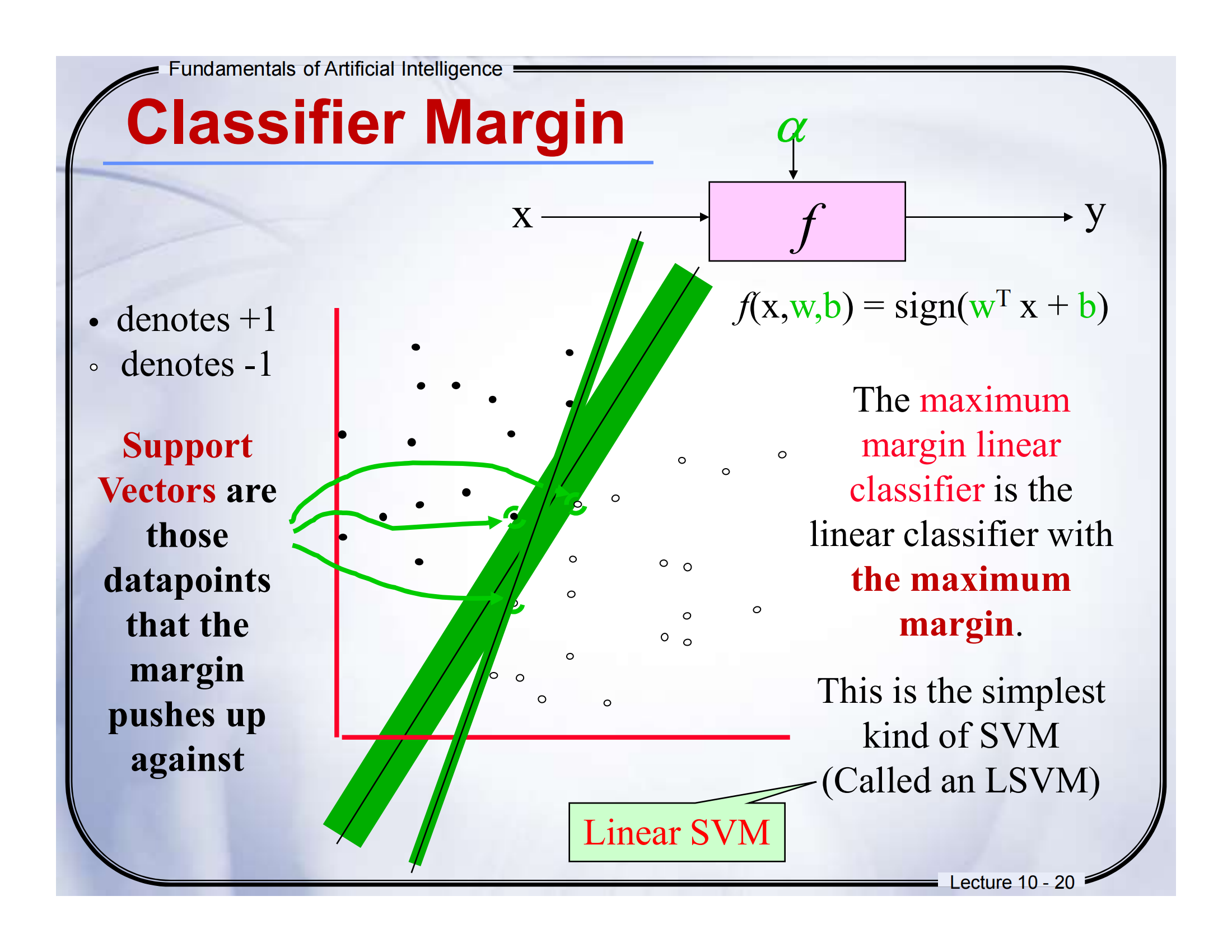
🈶 中英对照翻译:
-
Support Vectors are those data points that the margin pushes up against.
支持向量是“紧贴着间隔边界”的那些点。 -
The maximum margin linear classifier is the one with the widest margin.
最大间隔分类器就是选间隔最大的那条线。 -
This is the simplest kind of SVM, called a Linear SVM.
这是最简单的支持向量机,叫做线性SVM。
📘 通俗解释:
-
想象你的“墙”正好贴着几个训练样本,这些被“推着”的点就是支持向量。
-
它们非常重要,因为只要它们稍微动一下,整堵墙都要重建。
-
SVM 就是选择“间隔最大 + 支持向量确定边界”的那条线。
📝 出题练习:
填空题:
Support vectors are data points that lie ________ the margin.
👉 答案:on (或 close to)
选择题:
Which point has the most influence on the SVM decision boundary?
A. Points far from the margin
B. Points close to the margin
C. Random points
D. All points equally
👉 答案:B。
🧠 中文解析:只有支持向量对分类边界有影响。
🧾 总结一句话:
“SVM 的边界线是靠贴边的点来决定的。”
🔹Lecture 10 - 21:Functional Margin 函数间隔

🈶 中英对照翻译:
-
Functional margin 是 y(w^T x + b),表示预测值与实际标签的一致性。
-
如果、y(w^T x + b) > 0,说明预测正确;越大说明越“有信心”。
📘 通俗解释:
-
函数间隔是一个“符号 + 距离”的东西。
-
如果函数值是正的,而且越大,说明分类越正确,越“坚定”。
-
SVM想要最大化最小的函数间隔,也就是“让最边缘的那个点离决策线尽量远”。
📝 出题练习:
填空题:
The functional margin is defined as ________.
👉 答案:y(w^T x + b)
选择题:
If the functional margin is negative, the classifier:
A. is overfitting
B. predicted correctly
C. predicted incorrectly
D. has high margin
👉 答案:C
🧠 中文解析:负值表示预测错误。
🧾 总结一句话:
“函数间隔 = 预测值和真实值的一致性”
🔹Lecture 10 - 22:为什么函数间隔不够
🈶 中英对照翻译:
-
如果把 w 和 b 同时乘以一个常数,平面不会变,但函数间隔会变。
-
所以函数间隔本身“没法比较”不同的超平面,必须归一化。
📘 通俗解释:
-
就像你拿尺子量长度,结果有人用厘米,有人用米,这样量出的数值不能直接比。
-
所以我们要引入“几何间隔”来标准化比较。
📝 出题练习:
填空题:
Functional margin can be changed by scaling ________ and ________.
👉 答案:w,b
选择题:
Which of the following explains why functional margin is not sufficient?
A. It depends on the label
B. It changes when scaling w,b
C. It’s too hard to compute
D. It ignores support vectors
👉 答案:B
🧾 总结一句话:
“函数间隔容易受缩放影响,不够稳定。”
🔹Lecture 10 - 23:Geometrical Margin 几何间隔
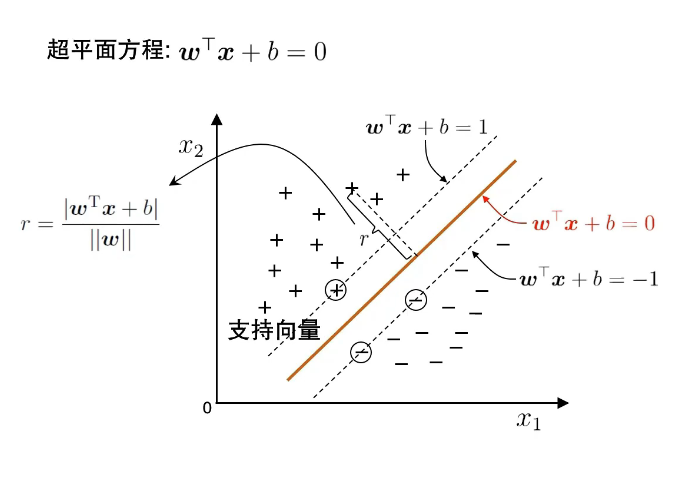


🈶 中英对照翻译:
-
Geometric margin = y(wTx+b)∥w∥\frac{y(w^T x + b)}{\|w\|}
-
它是真实距离,不会被缩放影响。
-
所以 SVM 实际上是最大化几何间隔。
📘 通俗解释:
-
如果函数间隔是“带有尺度的预测强度”,几何间隔就是“真正的几何距离”。
-
几何间隔不随 ww 的放大而改变,是真正可以比较的量。
📝 出题练习:
填空题:
Geometrical margin = functional margin divided by ________.
👉 答案:∥w∥\|w\|
选择题:
Which margin does SVM ultimately aim to maximize?
A. Functional margin
B. Prediction margin
C. Geometrical margin
D. Label margin
👉 答案:C
🧾 总结一句话:
“几何间隔 = 真正反映分类效果的距离”


刚才不是说w可以随意变大变小都不影响平面,现在怎么有说要让w变小了?

那我把b变小,不就可以把w无限变小了吗?平面又没变,怎么会导致距离变小呢?



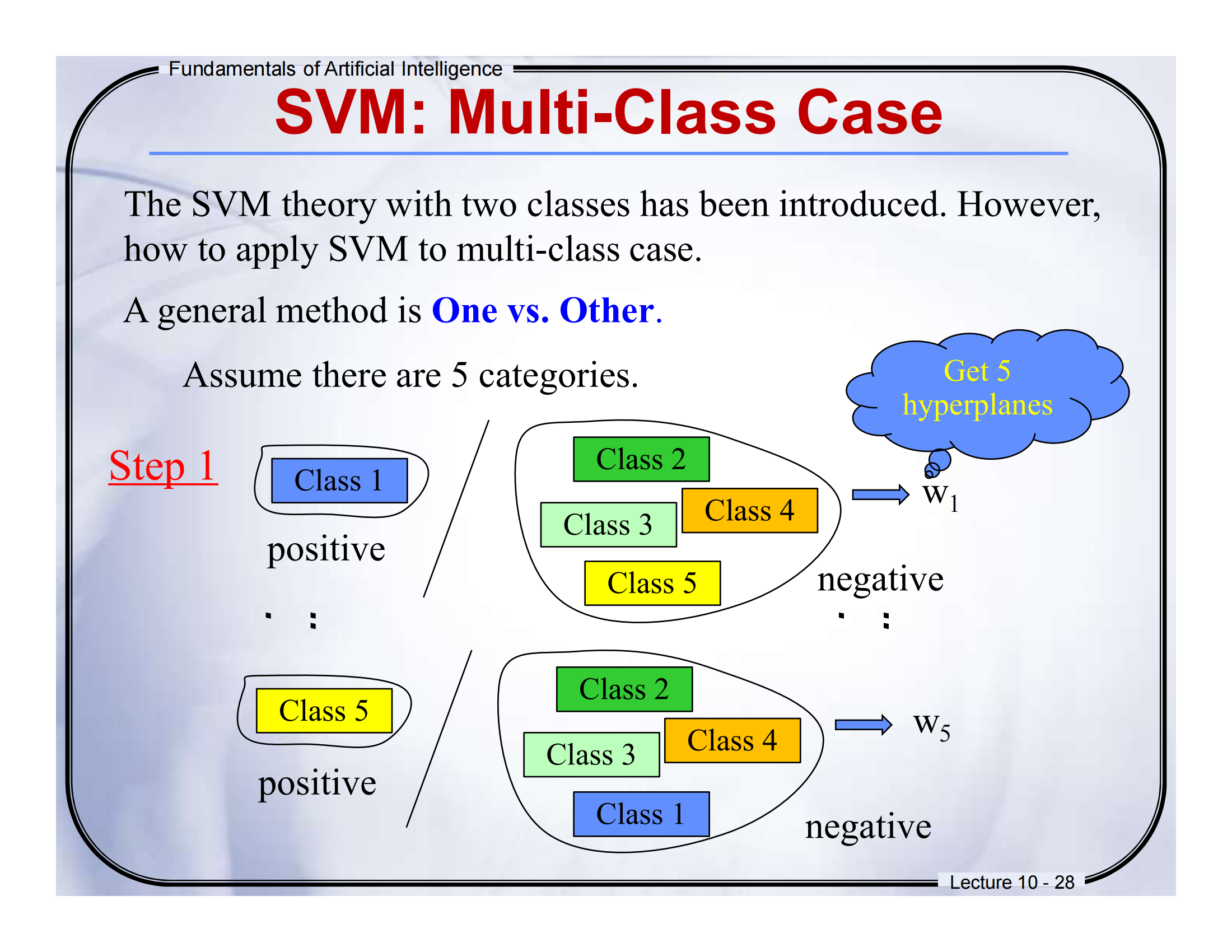

📘 Slide 标题:SVM: Multi-Class Case(多类别情况)
关于 max[si(x)] 依然适用
- max[si(x)] 的含义:表示在所有 si(x) 中选取最大的一个值,即 max[si(x)] = max{s1(x), s2(x), ..., sC(x)}。
- 依然适用的原因:尽管所有 si(x) 都小于 0,但 max[si(x)] 仍然可以作为一个相对的参考指标。即使样本 x 被分配到 C + 1 类,我们仍然可以通过比较 max[si(x)] 来了解在所有已知类别中,样本 x 与哪个类别的相似度相对最高。这有助于进一步分析样本 x 的特征,或者在后续处理中提供一些参考信息。
📗中英翻译对照:
Step 2:
-
英文原文:Given a test sample 𝑥, alternatively use [𝑤₁, 𝑤₂, 𝑤₃, 𝑤₄, 𝑤₅] to compute the belonging score corresponding to each hyperplane.
-
中文翻译:给定一个测试样本 𝑥,分别使用超平面 𝑤₁, 𝑤₂, 𝑤₃, 𝑤₄, 𝑤₅ 来计算它对应每个分类器的得分。
📘补充解释:这里我们假设总共有 5 个类别,那么就训练出 5 个超平面(每一个超平面是“一对多”的方式,比如第一个分类器用于区分“类别1 vs 其他所有类别”)。
-
英文原文:For instance, using 𝑤₁ we can get the score 𝑠₁(𝑥) to judge whether the test sample belongs to 1-st class or not.
-
中文翻译:例如,用 𝑤₁ 得到得分 𝑠₁(𝑥),可以判断这个样本是否属于第 1 类。
Step 3:
-
英文原文:Assign 𝑥 to the category whose score is maximum: Identity(𝑥) = max[𝑠ᵢ(𝑥)], i = {1, 2, 3, 4, 5}
-
中文翻译:把 𝑥 分到得分最高的类别中:Identity(𝑥) = 最大的 𝑠ᵢ(𝑥)。
✅ Advantage(优点):
-
Only 𝑐 (the number of categories) hyperplanes should be computed, having low complexity.
-
只需要训练 𝑐 个超平面(类别数),复杂度低。
❗ Limitation(缺点):
-
Perhaps the test sample 𝑥 is assigned to the 𝑐+1-th class. This means all scores 𝑠ᵢ(𝑥) < 0. However, in this case, max[𝑠ᵢ(𝑥)] still works.
-
有时候样本 𝑥 不属于任何已知的类别(得分都是负的),这种情况下也只能选最大得分的类别。
🧠 通俗解释:
我们现在已经知道怎么用 SVM 来区分两个类别了。但现实中,很多任务都是多分类的,比如识别数字 0-9,总共 10 类。
SVM 怎么应对这个?很简单——每次只看一个类 vs 所有其他类,这样我们就可以用一对多的方式来“硬凑出”多个二分类器。
你可以把这个过程想象成一个“选美评委”系统,每个评委负责选出“最像自己”那一类的选手。最后哪个评委最满意这位选手(得分最高),就把他拉到自己的队伍里去。
📝 练习题(含中文解析):
Fill-in-the-blank 填空题:
The method "One-vs-Other" in multi-class SVM needs to train ___ classifiers if there are 𝑐 categories.
A. 𝑐 - 1
B. 𝑐
C. 𝑐 + 1
D. 𝑐²
✅ Correct Answer:B. 𝑐
🈸 中文解析:对于每个类别,都训练一个“一对其他”分类器,所以总共是𝑐个。
Multiple-choice 选择题:
What is the disadvantage of using One-vs-All SVM for multi-class classification?
A. It requires too many support vectors
B. It cannot be applied to binary classification
C. The test sample may not belong to any of the known classes
D. It is faster than other models
✅ Correct Answer:C
🈸 中文解析:有时候测试样本可能“看起来都不像”,即所有得分都为负。这时候虽然还是会硬选一个最大得分的类别,但这说明预测不确定性很大。
📌 小结:
-
多分类 SVM 常采用 One-vs-All 策略,每类训练一个分类器。
-
给测试数据时,每个分类器都会“打分”,选得分最高的类别。
-
优点是计算简洁,缺点是遇到“不像任何类”的样本时不太可靠。

🔹第30页:SVM Example 2
📘中英对照翻译:
-
假设现在有三个分类:猫(cat)、狗(dog)、船(ship)。
-
训练好的权重 WW 和偏置 bb 已经给出。
-
问题是:输入一张猫的图片,这个分类器能正确分吗?
右边图片表示输入图像(x 向量),下面是它与 WW、bb 相乘后的三个得分:
-
猫:437.9 ✅
-
狗:-96.8
-
船:60.75
因此分到了分数最高的“猫”类别,判断 正确(correct)。
📙通俗解释:
图片其实被拉平成一列数字(像素强度),SVM 就是把这些数“加权求和”,加上偏置之后,哪个类别得分高就选谁。
就像比赛:三个候选人,谁总分高就选谁。
📋小测验:
填空题:SVM 的分类决策是选出得分最高的类别,得分是通过________和偏置计算得出的。
→ 权重矩阵 W
选择题:图中得分最高的是哪一类?
A. 狗 B. 猫 C. 船 D. 无法判断
→ ✅ B. 猫
🧠总结:
SVM 对多分类的做法是「谁得分最高就归谁」,得分来源于 W⋅x+bW \cdot x + b。这里通过数学乘法“投票”,其实非常像用“加权成绩”评奖。
🔹第31页:SVM: 2-D Image
📘中英对照翻译:
-
每个样本可以表示为列向量
,其中 dd 是维度。
-
如果有 c 个类别,就有 c 个超平面组成
。
-
若输入是二维图像,则先“拉平成”一个向量,再输入到模型中。
-
反过来,如果我们想可视化这些权重,可以把向量 wjw_j 再还原成图像。
📙通俗解释:
一张图是二维的(如 5×5 像素),但计算机只认识一串数字。SVM 会把图像展平成一条“像素线”,计算完后还可以还原成图像,看出模型学会了哪些特征。
📋小测验:
填空题:SVM 需要将图像从 2D 转换为 ______ 维向量再进行分类。
→ 1D
选择题:若你想观察模型“看”到了什么,你应该:
A. 增加维度 B. 使用 softmax C. 将权重向量转为图像 D. 随机初始化
→ ✅ C
🧠总结:
SVM 可以处理图像,但得先将图片“拉直成一行”,最后分类是靠「加权总分」。看懂权重图像,就是理解模型在“看哪里”。
🔹第32–33页:SVM Example 3(使用 CIFAR-10)
📘中英对照翻译:
-
数据集为 CIFAR-10,有 10 类(如猫、狗、飞机、汽车等),图像为 32×32×332\times32\times3。
-
模型学习的是权重 W 和偏置 b。
-
SVM 最终可以得到每一类的权重图像,如图所示,很多权重图都大致反映了对应物体的外形(例如 truck 和 car)。
📙通俗解释:
SVM 训练出权重后,我们可以把这些权重重新“画”成图片,看看模型脑海里每类图像“长啥样”。
比如 “car” 类的权重图像,确实像有个车头的轮廓。
📋小测验:
填空题:CIFAR-10 数据集中共有 ______ 张训练图像和 ______ 张测试图像。
→ 50,000 和 10,000
选择题:权重图像反映了:
A. 模型精度 B. 输入图像 C. 模型看到的“模板” D. 噪声
→ ✅ C
🧠总结:
训练好 SVM 后,权重不仅能用于分类,还能反映模型“对每类的理解”。这就像让机器画出它心中的“狗/车/船”。
🔹第34页:SVM Summary 总结页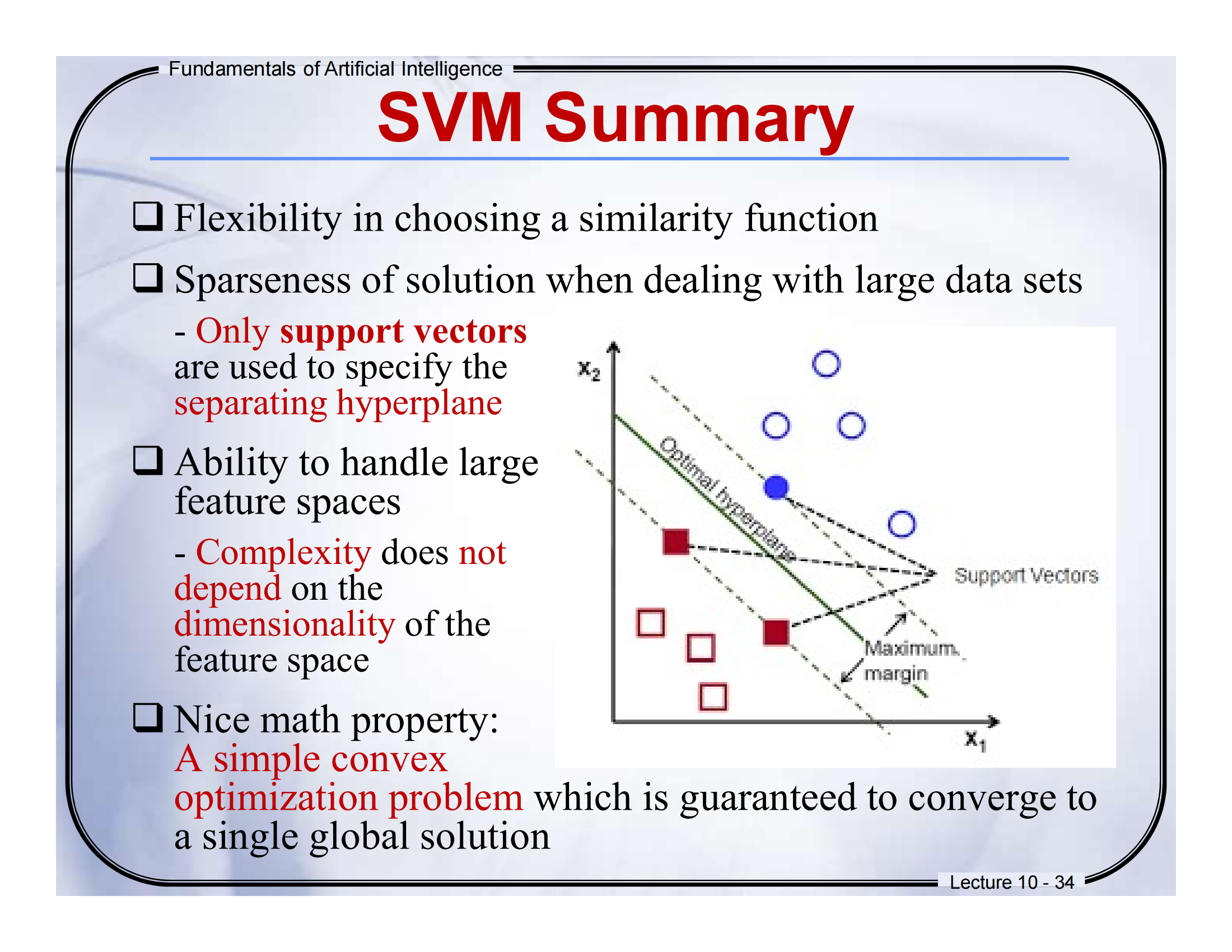
📘中英对照翻译:
SVM 的优点:
-
可以选择多种“相似度函数”
-
解是稀疏的,只依赖支持向量
-
可以处理高维空间
-
数学优化目标是“凸函数”(一定能收敛)
1. 可以选择多种 “相似度函数”(核函数)
- 理解:SVM 通过核函数实现非线性映射,将低维空间中线性不可分的数据映射到高维空间,使其线性可分。不同的核函数(如线性核、多项式核、径向基核 RBF 等)可适应不同数据特征与问题场景,例如 RBF 核函数能有效处理非线性问题,提升模型对复杂数据的拟合能力。
- 为什么:现实中数据多为非线性分布,单一线性模型难以有效分类。核函数赋予了 SVM 处理非线性问题的能力,通过隐式映射避免了直接在高维空间计算的复杂性。
- 来源:核函数技巧的引入,它允许 SVM 在不明确执行高维映射的情况下,计算高维空间中的内积,既解决了非线性问题,又避免了 “维数灾难”,增加了模型灵活性与适用性。
2. 解是稀疏的,只依赖支持向量
- 理解:训练完成后,只有支持向量(离超平面最近、对分类边界起决定性作用的样本)影响最终的分类超平面,其他样本不参与决策。这使得模型简洁,存储与计算成本低。
- 为什么:SVM 的目标是最大化分类间隔,只有支持向量决定间隔大小,其他样本远离超平面,对间隔无影响,因此在优化过程中,非支持向量的系数最终为零,解呈现稀疏性。
- 来源:源于 SVM 最大化间隔的优化目标。在求解过程中,通过拉格朗日乘数法等,最终只有支持向量对应的拉格朗日乘子不为零,决定了分类模型。
3. 可以处理高维空间
- 理解:SVM 借助核函数,无需显式计算高维空间坐标,直接通过核函数计算高维空间内积,避免了因维度增加导致的计算量暴增(维数灾难),使高维数据分类切实可行。
- 为什么:高维空间中数据更易线性可分,核函数的 “隐式映射” 特性,让 SVM 在高维空间处理数据时,计算复杂度未显著增加,依然保持高效。
- 来源:核函数技巧克服了高维计算难题。例如,RBF 核函数可将数据映射到无限维空间,同时计算复杂度可控,使 SVM 适用于高维数据(如文本分类中的高维特征向量)。
4. 数学优化目标是 “凸函数”(一定能收敛)
- 理解:SVM 的优化问题最终转化为凸二次规划问题,其目标函数是凸函数,约束条件为线性。凸函数的特性是局部最优解即全局最优解,因此优化过程必然收敛到全局最优解。
- 为什么:凸优化问题具有良好的数学性质,不存在多个局部最优解导致算法陷入次优解的情况,保证了 SVM 能找到真正的最优分类超平面。
- 来源:SVM 的数学模型构建。从最大化间隔出发,通过数学变换将问题转化为凸二次规划,确保了优化目标的凸性,如利用拉格朗日乘数法处理约束条件后,目标函数的凸性得以保持,保障了算法的稳定性与可解性。
📙通俗解释:
SVM 好比一个“聪明的裁判”,它不是关注所有数据,而是只看“临界点”(支持向量),然后找到最稳妥的那条线把他们分开。
而且它的计算过程像山谷一样,总能找到最低点(最优解),所以结果稳定、不容易被卡住。
📋小测验:
填空题:SVM 的分类边界只由一小部分训练数据决定,这些数据叫 ________。
→ 支持向量(support vectors)
选择题:以下哪项不是 SVM 的优势?
A. 高维处理能力强
B. 所有训练点都会用来分界
C. 可选择不同核函数
D. 最终收敛到全局最优解
→ ✅ B
🧠最终总结:SVM 是啥?
SVM(支持向量机)是一种:
-
寻找最佳分界线的方法,
-
尽量让不同类别离得远远的,
-
并且分类时只靠关键点(support vectors)决策,
-
数学过程又稳又快!
它可以:
-
做二分类、多分类;
-
也能用于图像、文本、甚至回归。
✅ 第 36 页:PCA: Review(PCA复习)
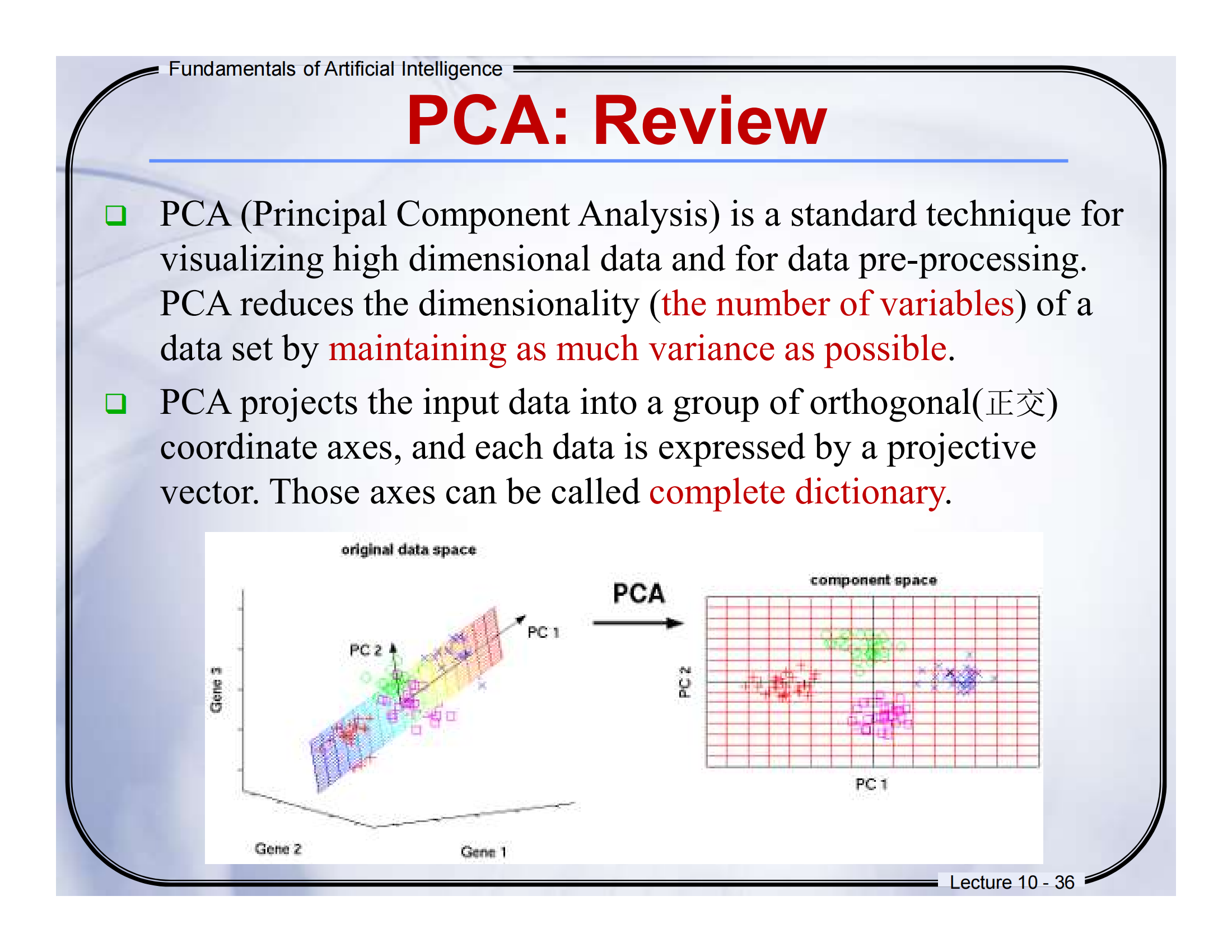 🉐 中英翻译:
🉐 中英翻译:
-
PCA(主成分分析)是一种常用的高维数据可视化和预处理技术。
-
它通过保留尽可能多的方差信息,来降低数据的维度(变量数量)。
-
它会把原始数据投影到一组正交坐标轴上,每个数据点都可以由这些轴(主成分)表示。
-
这些轴可以称为完整字典(complete dictionary)。
🧠 通俗讲解:
想象你有一个 3D 的数据点云,现在你想把它“压平”成 2D 或 1D,还想保留尽可能多的信息。PCA 就是帮你找出“信息最多的方向”(主成分)来做这个降维的事。就像从不同角度看一个立方体,PCA 会选择“最好看懂的那个方向”。
✅ 第 37 页:PCA: Complete Dictionary

 🉐 中英翻译:
🉐 中英翻译:
-
通过求解特征值和特征向量,可以获得一组正交基(基底)。
-
这些特征向量组成一个矩阵 D,它是完整字典,也满足 DTD=ID^T D = I(正交)。
-
如果训练数据的均值为 0,就可以写成 X=DαX = D \alpha,即数据等于字典乘以系数。
🧠 通俗讲解:
完整字典就像一个“标准拼图模板”,任何数据都可以用这个模板拼出来。比如说你有一套标准颜色(红、绿、蓝),那别的颜色就可以通过这三种颜色的配比表示出来。
✅ 第 38 页:PCA → Sparse Representation
🉐 中英翻译:
-
从 PCA 走向稀疏表示,核心是:从完整字典拓展为过完备字典(over-complete dictionary)。
-
问题:如果字典“太多了”(列数多于行数)怎么办?
🧠 通俗讲解:
PCA 中的字典就像拼图模板,但每块拼图刚刚好能拼出全部图片。现在你给模板加倍多,想提高表示能力,但这会带来一个新问题:拼图块多了,怎么选?——这就是稀疏表示的关键点。
✅ 第 39 页:Sparse Representation(稀疏表示)
🉐 中英翻译:
-
用“过完备”字典来表达样本,目标是稀疏的线性组合。
-
优点:
-
更简洁(压缩)
-
自然适合分类
-
对异常值更鲁棒(不容易被干扰)
-
🧠 通俗讲解:
稀疏表示的意思是:虽然模板很多,但我们希望每次只用很少几块模板来拼出结果。这样不仅省,而且还更容易看出“属于谁”。
✅ 第 40 页:Sparse Representation 实例(人脸识别)
🉐 中英翻译:
-
稀疏表示在计算机视觉领域尤其热门。
-
它在图像分类中(尤其是人脸识别)非常有效。
-
每张图像可以由字典(由少数样本构成)稀疏表示出来。
🧠 通俗讲解:
比如我们有很多人脸图,想识别一个新图是哪个人。我们可以用已知的人脸图(训练样本)组成一个字典,然后看新图能否只靠“某几个人的脸”拼出来——能说明新图就是那几个人其中之一。
✅ 第 41 页:Sparsland 中的信号生成
🉐 中英翻译:
-
字典 DD 中的每一列称为“原子(atom)”。
-
稀疏向量 α\alpha 只有少量非零值,这些值决定了图像是由哪些“原子”组成。
-
过完备字典是指:模板比实际维度还要多。
🧠 通俗讲解:
想象你有很多种声音(字典),但每次说话只用到其中几个声音。你录下一个声音后,可以通过“拆解”得到这个声音用了哪些“原子音”拼出来的。
📝 练习题汇总(填空 + 选择)
填空题
-
In sparse representation, the sample is represented by a ______ linear combination of atoms.
→ 答案:sparse -
The dictionary in sparse representation is called ______ when it has more columns than dimensions.
→ 答案:over-complete
选择题
-
What is the main benefit of sparse representation in face recognition?
A. It uses all training samples equally
B. It avoids PCA completely
C. It identifies faces using only a few key samples
D. It compresses images into binary✅ 正确答案:C
📌 解析:稀疏表示只使用少量关键训练样本来表示测试样本。 -
In PCA, the dictionary is constructed using:
A. Mean subtraction
B. Eigenvectors of the covariance matrix
C. Decision trees
D. Singular values only✅ 正确答案:B
📌 解析:PCA 是通过特征向量构建变换基的,这些特征向量来自协方差矩阵。
🧾 通俗总结
-
PCA 是“压缩数据 + 保留信息”的方法,稀疏表示则是“少而精地表示数据”。
-
稀疏表示特别适合做分类、识别,因为它能抓住最关键的那几维特征。
-
和 SVM 或 KNN 不同,SRC 背后的思路是“我可以由谁组成”,不是“我最像谁”。
第35页:Sparse Representation Classification (SRC)
🇬🇧 标题:Sparse Representation Classification (SRC)
🇨🇳 标题:稀疏表示分类方法(SRC)
📘通俗讲解:
这是本节的标题页。SRC 是一种新兴的分类方法,尤其在图像识别(比如人脸识别)中非常有效。它的关键思想是用“少数几个”已有样本的线性组合来表示新样本。
第36页:PCA 回顾
🇬🇧 Translation:
-
PCA is a technique for reducing dimensions while preserving variance.
-
PCA projects data onto orthogonal axes to form a complete dictionary.
🇨🇳 翻译:
-
主成分分析(PCA)是一种在保留数据尽量多的方差的同时降维的技术。
-
PCA 会将数据投影到一组正交坐标轴上,这些轴可以构成一个“完整字典”。
📘通俗讲解:
PCA 就像是给复杂的数据找一组最重要的“参考轴”。我们保留变化最大的部分,并丢掉“无关紧要”的维度。
第37页:PCA 完整字典
🇬🇧 Translation:
-
Each eigenvector becomes a projection axis.
-
These form an orthogonal matrix D.
-
X can be reconstructed using
🇨🇳 翻译:
-
每个特征向量都可以作为一条投影轴。
-
所有的轴组合成正交矩阵 D。
-
原数据 X 可以用 X=DαX = D\alpha 重建。
📘通俗讲解:
你可以把每个主成分(PCA轴)当作一把“尺子”,可以用这些尺子来重建任何原始数据点。
第38页:从 PCA 到稀疏表示
🇬🇧 Translation:
-
Move from complete dictionary to over-complete dictionary.
-
Over-complete means more axes than dimensions.
🇨🇳 翻译:
-
从“完整字典”过渡到“过完备字典”(更多轴)。
-
也就是说,用“更多的参考样本”来表示数据。
📘通俗讲解:
就像拼乐高积木一样,原来有 N 块,现在多准备了一大堆积木备用。
第39页:稀疏表示定义
🇬🇧 Translation:
-
Represent a sample using few atoms (columns) of an over-complete dictionary.
-
Advantages: compression, classification, robustness.
🇨🇳 翻译:
-
用过完备字典中少量元素来表示样本。
-
优点:更压缩、更适合分类、更不怕噪声。
📘通俗讲解:
就像拼积木,只用很少几块积木,就能拼出一个图形。这样更高效,也不容易被“坏积木”(噪声)影响。
第40页:稀疏表示在人脸识别中的应用
🇬🇧 Translation:
-
Sparse representation is hot in computer vision, especially face recognition.
-
Even with few training samples, it works well.
🇨🇳 翻译:
-
稀疏表示是图像处理领域的热点,尤其是在人脸识别上表现出色。
-
只需要很少的训练图像就能起效。
📘通俗讲解:
只看几张照片就能认出你是谁,因为每张脸都可以被“稀疏地”拼出来。
第41页:Sparsity 中的生成模型
🇬🇧 Translation:
-
Each dictionary column is a “prototype atom”.
-
α is a sparse vector: most values are zero.
🇨🇳 翻译:
-
字典中的每一列都是一个“原子”样本。
-
表示系数 α 是稀疏的,大多数值是 0。
📘通俗讲解:
从一大堆参考脸里,随机只用几个,就能拼出目标脸。
第42页:信号是特殊的
🇬🇧 Translation:
-
Signals are constructed using few dictionary atoms.
-
Example: 9 non-zeros out of 35 entries = 26% density.
🇨🇳 翻译:
-
每个信号只需要用很少的原子来组合而成。
-
示例矩阵稀疏度为 74%。
📘通俗讲解:
只用少量“积木”就搭好了一个复杂形状,代表了高效且有辨识度的拼法。
第43页:如何进行变换(稀疏编码)
🇬🇧 Translation:
-
Need to solve: Dα=xD\alpha = x.
-
Want the sparsest solution.
-
Use ∥α∥0\| \alpha \|_0 to measure sparsity.
🇨🇳 翻译:
-
我们要解这个方程 Dα=xD\alpha = x。
-
目标是找到“最稀疏”的 α。
-
用 ∥α∥0\| \alpha \|_0 衡量稀疏度。
📘通俗讲解:
在所有可能的解法中,我们要找出那种“只用了最少积木”的拼法。
第44页:Relax L0范数(优化目标)
🇬🇧 Translation:
-
Original goal: minimize ∥α∥0\| \alpha \|_0.
-
Relaxed version: minimize ∥x−Dα∥2+λ∥α∥1\| x - D\alpha \|^2 + \lambda \| \alpha \|_1.
-
Called Lasso problem.
🇨🇳 翻译:
-
原问题是最小化非零数目。
-
放松成更容易求解的问题,目标是“拟合误差 + 稀疏惩罚”。
-
这就是著名的 Lasso 回归。
📘通俗讲解:
不去死抠“最稀疏”,我们换一种方式:找“差不多稀疏又好用”的解,容易算又能解决问题。
第45页:两个核心问题
🇬🇧 Translation:
-
How to get D? (Dictionary Learning)
-
How to get α? (Sparse Coding)
🇨🇳 翻译:
-
如何获得字典 D?(学习过程)
-
给定 D 和 x,如何求解 α?(编码过程)
📘通俗讲解:
这是稀疏表示的核心两问:准备哪些“参考积木”?以及怎么用积木拼目标?
第46页:SRC 应用举例
🇬🇧 Translation:
-
Combine dictionaries for different people.
-
For the input signal x, only the related dictionary has non-zero α.
🇨🇳 翻译:
-
把每个人的样本组成一个大字典。
-
新来的脸,只用某一个人的照片就能拼出来。
📘通俗讲解:
你给我一张脸,我就从几个人的照片里找出最少量的“拼图块”,最后会告诉你这张脸是谁的。
📝 练习题示例
填空题:
Sparse representation aims to represent a signal using a __________ number of atoms from a dictionary.
A. large B. fixed C. small D. noisy
✅ 答案:C. small
👉 解析:稀疏 = few = 少量元素组成
选择题:
Which of the following is NOT an advantage of sparse representation?
A. Robust to noise
B. Efficient compression
C. Requires many training samples
D. Suitable for classification
✅ 答案:C
👉 解析:稀疏表示的一大优势就是只需要少量训练样本!
🧠 总结一句话:
稀疏表示(SRC)是一种“用最少积木拼出你是谁”的方法,在人脸识别等任务中表现出色,兼具压缩、鲁棒、和可解释性。
🔴 第一部分:背景与动机
为什么要提出 SRC?
传统的分类器(如 KNN、SVM)通常:
-
需要大量训练样本;
-
对噪声敏感;
-
不能很好利用样本之间的结构。
而SRC 的核心思想是:
用很少的一部分训练样本(稀疏的)来表达一个测试样本,这种表示方式能自然地进行分类。


🔵 第五部分:SRC 在人脸识别中的应用(示例)
步骤详解:
-
输入数据:
-
训练集:每类若干张脸;
-
测试图像 xxx:转换为一维向量。
-
-
构造字典 D:
每列为一个训练图像的一维化向量。 -
稀疏编码:
求解稀疏系数 ααα,只有属于该类的图像系数非零。 -
残差计算:
每一类分别计算重建误差。 -
分类结果:
残差最小 → 归属该类别。
📌 如图像展示:
-
Obama 的测试照片可以主要由 Obama 的训练照片线性组合还原;
-
所以 α1α_1α1 非零,其它全是 0;
-
于是判定属于第 1 类(Obama)。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









