








目录
一、案例分析
1、hello、everyone!long time no see,几日不见 初次见面,我叫不会print , 昨日我已经发部了1.5w字的结果不知道为啥,就被官方大大屏蔽了,编辑了几万字,半个小时的时间就这样废了,真不甘心。所以今天,我更新了一下昨天的内容,进行了一波锦上添花。
2、多的不说少的不唠,这次我们来说说关于python的多线程与多进程爬chong 某片 。大家都知道,生活中有很多高速公路,每条高速路上都分为低速道,中速道和超速道。这些道路在生活中看来只是为了不同速度而设计的,但是在编程语言来说:是为了能够同时进行多个项目。好比下载图片,一张张下和一个目录一个目录的下,这个任务完成的时间是不同的。
3、OK,说这么多,改到实战部分。今日我们就用17-22年最火的MOBA网站举例 ,总所周知,爬虫是为了人们能够更加方便的办公 获取资源 但是即使通过pa的方式依旧做不到最快,这时候我们可以导入多线程这个概念来完成。会节省我们很多的时间,关于多线程的概念这里作者就不再一一给大家解释,也不敢引用太多链接,怕封!怕封!怕封!。不过可以给大家说下关于多线程pytohn的库(thrid.Thread(为了防止错乱,配合lock),queue(配合pillow)使用)。多的不说少的不唠 不敢唠
上代码块
二、代码实现
import requests
from urllib import parse
import os
'''转化url成json格式'''
n=0
def respon(url):
'''标识头,防反pa'''
header = {
"referer": "https://pvp.qq.com/",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36"
}
respons = requests.get(url=url, headers=header)
'将网页数据返回一个json,便于后续查找photo'
return respons.json()这次献给大家说的不是多线程,咱得先理解基本思路到底是如何,我们这次该如何获取,细心的同学基本已经看出来了,我们并没有去使用selenium,为什么,因为这个东西(网站)反爬机制和数据隐藏机制是很强的,倘若使用seleniu是获取不到工具的,而这时候我们就需要抓取数据包,这里我在检查--网络里抓到了workList_inc.cgi这个东西,因为里面有我们要东西,(20条数据)。这里作者实在不敢展示了。大家可以进去好好看看,到底是不是这个。这里面有一些需要加密解密的操作,这里要涉及到json.cn这个网站,这里我们需要复制得到的包的url。进去里面,最后复制厘米那的东西,而不是说直接复制他。同时,我们还需要删除第一个花括号和jqury的范围

这个东西,删除,不要问为什么,因为我们需要把他转换成给我们 的json格式,而json格式没有他。就这个意思,大致懂了吧!!!!OK上代码
'''用于在解析好的json数据中筛选8寸照片'''
def parse_json(json_data):
'因为图片存放于List中,用索引取出好评对象'
json_lst = json_data["List"]
data_ls=[]
for data in json_lst:
'因为对象有很多照骗,这里我只用取出像素最好的8寸照就行'
data_ls.append(data['sProdImgNo_8'])
return data_ls
这上面的的内容是关于这个photo列表中会有n多个不同尺寸photo,我们只需要取出自己喜欢的一种就好,当然,我这里选的是最大,最好的。选中,打开,会发现是加密的,没错。欧克,继续解密
'''因为这里的照片会出现乱码,所以将照片进行转码一下,得出真实格式'''
def photo_parse(data_ls):
ls=[]
for data in data_ls:
DT=parse.unquote(data.replace('200',"0"))
ls.append(DT)
return ls经过parse.unquote后我们可以得到一张很xiao的photo ,这里我就不给大家说为什么我把200换成了0,因为他很大,你可以一步步试试,最好先了解里面的分布环境是如何的。继续,现在我们就已经得到了想要的u
os.chdir(r"C:\Users\杨jl\PycharmProjects\pythonProject7\venv\wang_zhe\王者荣耀高清壁纸")
for i in range(30):
url='https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page='+str(i)+'&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1665660316891'
json_data=respon(url)
photo_lst=parse_json(json_data)
photo=photo_parse(photo_lst)
for i in photo:
n = n + 1
'''存储爬取出来的图片'''
with open(r'{}.jpg'.format(n), 'wb')as f:
print(n)
f.write(requests.get(i).content)
print("第{}张图片爬取成功".format(n))
f.close()rl。but,这里的url只有一页的,很简单,上代码。这里的意思我从循环开始讲起,因为有30页,所以我用了这么多次,其次,需要修改的就是url的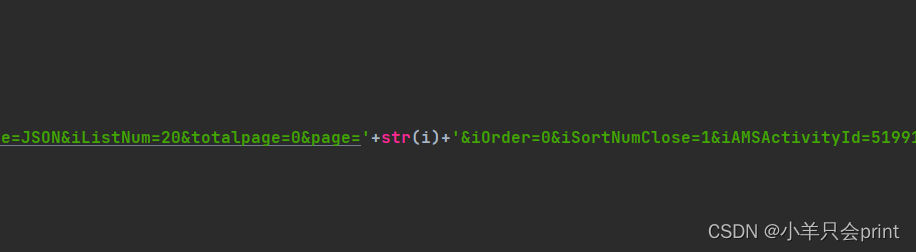
这个部分,最后,保存图片,那上面也有。当然,记得提前os.chirld以下,指定一下目录存储,上完整代码
# 作者:杨家乐
# 阶段:进阶练习中,请稍后.......
# 开发时间:2022/10/13 19:28
import requests
from urllib import parse
import os
'''转化url成json格式'''
n=0
def respon(url):
'''标识头,防反pa'''
header = {
"referer": "https://pvp.qq.com/",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36"
}
respons = requests.get(url=url, headers=header)
'将网页数据返回一个json,便于后续查找photo'
return respons.json()
'''用于在解析好的json数据中筛选8寸照片'''
def parse_json(json_data):
'因为图片存放于List中,用索引取出好评对象'
json_lst = json_data["List"]
data_ls=[]
for data in json_lst:
'因为对象有很多照骗,这里我只用取出像素最好的8寸照就行'
data_ls.append(data['sProdImgNo_8'])
return data_ls
'''因为这里的照片会出现乱码,所以将照片进行转码一下,得出真实格式'''
def photo_parse(data_ls):
ls=[]
for data in data_ls:
DT=parse.unquote(data.replace('200',"0"))
ls.append(DT)
return ls
if __name__ == '__main__':
os.chdir(r"C:\Users\杨jl\PycharmProjects\pythonProject7\venv\wang_zhe\*****高清壁纸")
for i in range(30):
url='https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page='+str(i)+'&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1665660316891'
json_data=respon(url)
photo_lst=parse_json(json_data)
photo=photo_parse(photo_lst)
for i in photo:
n = n + 1
'''存储出来的图片'''
with open(r'{}.jpg'.format(n), 'wb')as f:
print(n)
f.write(requests.get(i).content)
print("第{}张图片成功".format(n))
f.close()3、以为这就完了?那我昨天的封禁岂不是白费了,给大家笼统介绍下多线程,python里面的多线程有一个组队的叫法,用pachong来举例,你要怕一个网站,一定要的就是发送请求,存储数据。而发送请求,数据处理的那部分可以叫做生产者,因为他是负责给我们数据的嘛,而对于生产的我们需要往里面注入内容,注入获得的内容,这样才能供给消费者消费,而注入的方法就是对象.put(这个就是注入的内容,你可以理解为添加内容)。这时候消费者就能得到内容了,咱就可以对他进行取值消费了,这个方法就是get()方法,这里面有参数,一次趣味多少,这里我就直接举例说明吧
class product(threading.Thread):
def __init__(self, page_queue, image_url_queue):
super().__init__()
self.page_queue = page_queue
self.image_url_queue = image_url_queue
def run(self):
global n
while not self.page_queue.empty():
page_url=self.page_queue.get()
respon=requests.get(url=page_url,headers=header)
json_data= respon.json()
'因为图片存放于List中,用索引取出好评对象'
json_lst = json_data["List"]
data_ls = []
dirpath=r"C:\Users\杨jl\PycharmProjects\pythonProject7\venv\wang_zhe\****高清壁纸"
for data in json_lst:
'因为对象有很多照骗,这里我只用取出像素最好的8寸照就行'
data_ls.append(data['sProdImgNo_8'])
'''照片变大'''
lt=[]
dirpath = os.path.join(dirpath, f"第{n}页")
if not os.path.exists(dirpath):
os.mkdir(dirpath)
for index,photo in enumerate(data_ls):
DT = parse.unquote(photo.replace('200', "0"))
self.image_url_queue.put({'image_path':os.path.join(dirpath,f'{index+1}.jpg'),'image_url':DT})
n+=1
这里我定义了一个生产者,他存储了我获取的url这是存储在生产者这个队列里的
class customer(threading.Thread):
def __init__(self, image_url_queue):
super().__init__()
self.image_url_queue = image_url_queue
def run(self):
while True:
try:
image_obj = self.image_url_queue.get(timeout=20)
request.urlretrieve(image_obj['image_url'],image_obj['image_path'])
print(f'{image_obj["image_path"]}下载完成')
except:
break这里,我定义了一个消费者,这个消费者专门从生产者里面获取东西,然后进行存储。当然,作者也不知道说的清不清楚,大家可以专门去搜搜python多线程多进程。以后到企业是常用的
最后,上优化后的代码
# 作者:杨家乐
# 阶段:进阶练习中,请稍后.......
# 开发时间:2022/10/14 10:31
'''多线程下载'''
import requests
from urllib import parse
from queue import Queue
import threading
import os
from urllib import request
n=1
os.chdir(r"C:\Users\杨jl\PycharmProjects\pythonProject7\venv\wang_zhe\王者荣耀高清壁纸")
'''
用于在解析好的json数据中筛选8寸照片
'''
header = {
"referer": "https://pvp.qq.com/",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36"
}
'''
生产者线程
'''
class product(threading.Thread):
def __init__(self, page_queue, image_url_queue):
super().__init__()
self.page_queue = page_queue
self.image_url_queue = image_url_queue
def run(self):
global n
while not self.page_queue.empty():
page_url=self.page_queue.get()
respon=requests.get(url=page_url,headers=header)
json_data= respon.json()
'因为图片存放于List中,用索引取出好评对象'
json_lst = json_data["List"]
data_ls = []
dirpath=r"C:\Users\杨jl\PycharmProjects\pythonProject7\venv\wang_zhe\王者荣耀高清壁纸"
for data in json_lst:
'因为对象有很多照骗,这里我只用取出像素最好的8寸照就行'
data_ls.append(data['sProdImgNo_8'])
'''照片变大'''
lt=[]
dirpath = os.path.join(dirpath, f"第{n}页")
if not os.path.exists(dirpath):
os.mkdir(dirpath)
for index,photo in enumerate(data_ls):
DT = parse.unquote(photo.replace('200', "0"))
self.image_url_queue.put({'image_path':os.path.join(dirpath,f'{index+1}.jpg'),'image_url':DT})
n+=1
'''
消费者线程
'''
class customer(threading.Thread):
def __init__(self, image_url_queue):
super().__init__()
self.image_url_queue = image_url_queue
def run(self):
while True:
try:
image_obj = self.image_url_queue.get(timeout=20)
request.urlretrieve(image_obj['image_url'],image_obj['image_path'])
print(f'{image_obj["image_path"]}下载完成')
except:
break
'''
启动线程的函数
'''
def start():
page_queue = Queue(30)
image_url_queue = Queue(1000)
for i in range(30):
page_url = 'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=' + str(
i) + '&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1665660316891'
page_queue.put(page_url)#放入线程数据
'''
创建生产者线程对象
'''
for i in range(5):
t = product(page_queue, image_url_queue)
t.start()
'''
创建消费者线程对象
'''
for i in range(10):
t = customer(image_url_queue)
t.start()
if __name__ == '__main__':
start()
这里作者实在不方便多说,我很害怕好不容易编辑的几万字,又没了,大家哪一步不懂得可以在评论区下面问问,作者一步步为你们解答!!!
三、今日美文
高度不同,视角不一,不必过度羡慕别人。其实在别人水平线上,自己其实算不上什么。而我们要做的仅仅是控制住欲望,提升自己的水平线就好!
忍受住寂寞,别去期待。五年。再回来会很感激自己!
















 1949
1949











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











