









目录
一、导言
1、不知不觉就在暴戾,焦虑和虚无中过了一个无趣无味的一年,今年学了很多,但却又什么也学不好,学不通,毕竟自己今年的状况实在太差。眼高手低的情况让我一次又一次与‘熟练’,‘精通’挂不上一点勾。但愿在2023年转变为状态更好的自己,也愿各位能意志坚定,坐上自己想做的事情。切勿如作者一般,三天打鱼两天晒网.......................
二、代码讲解
1、今天是2022年的最后一天,决定回到起点,做自己该做的事情,给大家带来爬虫的起步作品---------------------爬取多页小说
2、工具:python 3.11 EXCEL requests openpyxl pyquery
3、代码讲解:URL
def send_data(url,headers):
'模拟客户端向网页发送请求'
respon=requests.get(url=url,headers=headers).text
return respon
##数据解析
def data_parser(data):
p=pq(data) ##将网页返回的源代码转化为pyquery格式,用pyquery解析器去解析,语法为css
'这里由于每一本书的结构都保存在class属性为rank_d_list的下面,一页有20本书'
'所以我们将网页多余源代码去掉了,这里的p('.rank_d_list')就包含了书的各个介绍结构'
'你可以将这个理解为列表,列表中有20本书,书:指的便是这些网页元素块'
book=p('.rank_d_list')
ls=[] ##先创建好一个列表,用于过后一个大列表,里面会将每一本书的内容整合到一个个小列表中
'book.items()这个方法不是字典本身的item方法,你可以理解为这是将一整块大元素分割成一个个网页小元素标签'
for i in book.items():
'这里的I就是每一本书的结构了,i.find('a').attr('href'):指的是找所有a标签中的href属性'
book_url=i.find('a').attr('href')##这个是书的所在网页
book_img=i.find('a img').attr('src')##这个是书的封页,找src的属性值
book_name=i.find('a img').attr('alt')##这个是书的名字,名字当放在img标签的alt属性里
writer=i.find('.rank_d_book_intro .rank_d_b_cate').attr('title')##这个是找作者
book_score=i.find('.rank_d_b_ticket').text()##书的评分类似<div>喜羊羊</div> 找到就是喜羊羊,因为.text的用法就是找的文本文字
kind=i.find('.rank_d_book_intro .rank_d_b_cate a:nth-child(2)').text()##找他的种类
content=i.find('.rank_d_book_intro .rank_d_b_info').text()##这是书的第一段内容
'数据解析之后将数据整合到一个小列表当中,这个小列表存储的就是每本书的基本介绍'
ls.append(["《"+book_name+"》",writer,kind,book_url,book_img,book_score,content])
print(["《"+book_name+"》",writer,kind,book_url,book_img,book_score,content])
return ls
4、数据的保存---excel
##执行菜单
def start():
##保存数据
'''创建工作铺'''
wb = openpyxl.Workbook()
sheet = wb.active##添加工作表(sheet)
'这里是给工作表起字段名----列名'
sheet.append(['书名', '作者', '种类', '书页URL', '图片', '评分', '内容'])
'这句代码段的前面部分千万不能放到循环里面,否则将会覆盖掉上一页的内容'
'由于网页有10页数据,这里我们需要遍历爬取,字符串的拼接'
for i in range(1,11):
url='https://www.zongheng.com/rank/details.html?rt=1&d=1&i=2&p='+str(i)
'UA和cookies的伪造'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.54',
'Cookie': 'ZHID=11678A3059610F4AA3B65CD2D83F040F; ver=2018; zhffr=cn.bing.com; zh_visitTime=1672482682605; sajssdk_2015_cross_new_user=1; Hm_lvt_c202865d524849216eea846069349eb9=1672482683; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2218567bc770e0-055e38e67580a2-7a575473-1327104-18567bc770f4ae%22%2C%22%24device_id%22%3A%2218567bc770e0-055e38e67580a2-7a575473-1327104-18567bc770f4ae%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%7D; Hm_lpvt_c202865d524849216eea846069349eb9=1672482734'
}
data=send_data(url=url,headers=headers)
ls=data_parser(data)
for i in ls:
'''将数据添加到工作表中,这里的ls就是刚才大列表的,i也就是一个个小列表,存储数据到
不同单元格需要放入小列表中存储,这样他才不会挤到同一个单元格中'''
sheet.append(i)
wb.save('小说网10页.xlsx')##爬取完成,保存到excel
print('第'+str(i)+'页爬取完成')5、完整代码
import openpyxl
from bs4 import BeautifulSoup
import requests
from pyquery import PyQuery as pq
##发送数据
def send_data(url,headers):
respon=requests.get(url=url,headers=headers).text
return respon
##数据解析
def data_parser(data):
p=pq(data)
book=p('.rank_d_list')
ls=[]
for i in book.items():
book_url=i.find('a').attr('href')
book_img=i.find('a img').attr('src')
book_name=i.find('a img').attr('alt')
writer=i.find('.rank_d_book_intro .rank_d_b_cate').attr('title')
book_score=i.find('.rank_d_b_ticket').text()
kind=i.find('.rank_d_book_intro .rank_d_b_cate a:nth-child(2)').text()
content=i.find('.rank_d_book_intro .rank_d_b_info').text()
ls.append(["《"+book_name+"》",writer,kind,book_url,book_img,book_score,content])
print(["《"+book_name+"》",writer,kind,book_url,book_img,book_score,content])
return ls
##执行菜单
def start():
##保存数据
'''创建工作铺'''
wb = openpyxl.Workbook()
sheet = wb.active
sheet.append(['书名', '作者', '种类', '书页URL', '图片', '评分', '内容'])
for i in range(1,11):
url='https://www.zongheng.com/rank/details.html?rt=1&d=1&i=2&p='+str(i)
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.54',
'Cookie': 'ZHID=11678A3059610F4AA3B65CD2D83F040F; ver=2018; zhffr=cn.bing.com; zh_visitTime=1672482682605; sajssdk_2015_cross_new_user=1; Hm_lvt_c202865d524849216eea846069349eb9=1672482683; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2218567bc770e0-055e38e67580a2-7a575473-1327104-18567bc770f4ae%22%2C%22%24device_id%22%3A%2218567bc770e0-055e38e67580a2-7a575473-1327104-18567bc770f4ae%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%7D; Hm_lpvt_c202865d524849216eea846069349eb9=1672482734'
}
data=send_data(url=url,headers=headers)
ls=data_parser(data)
for i in ls:
sheet.append(i)
wb.save('小说网10页.xlsx')
print('第'+str(i)+'页爬取完成')
if __name__ == '__main__':
start()
三、成品展示
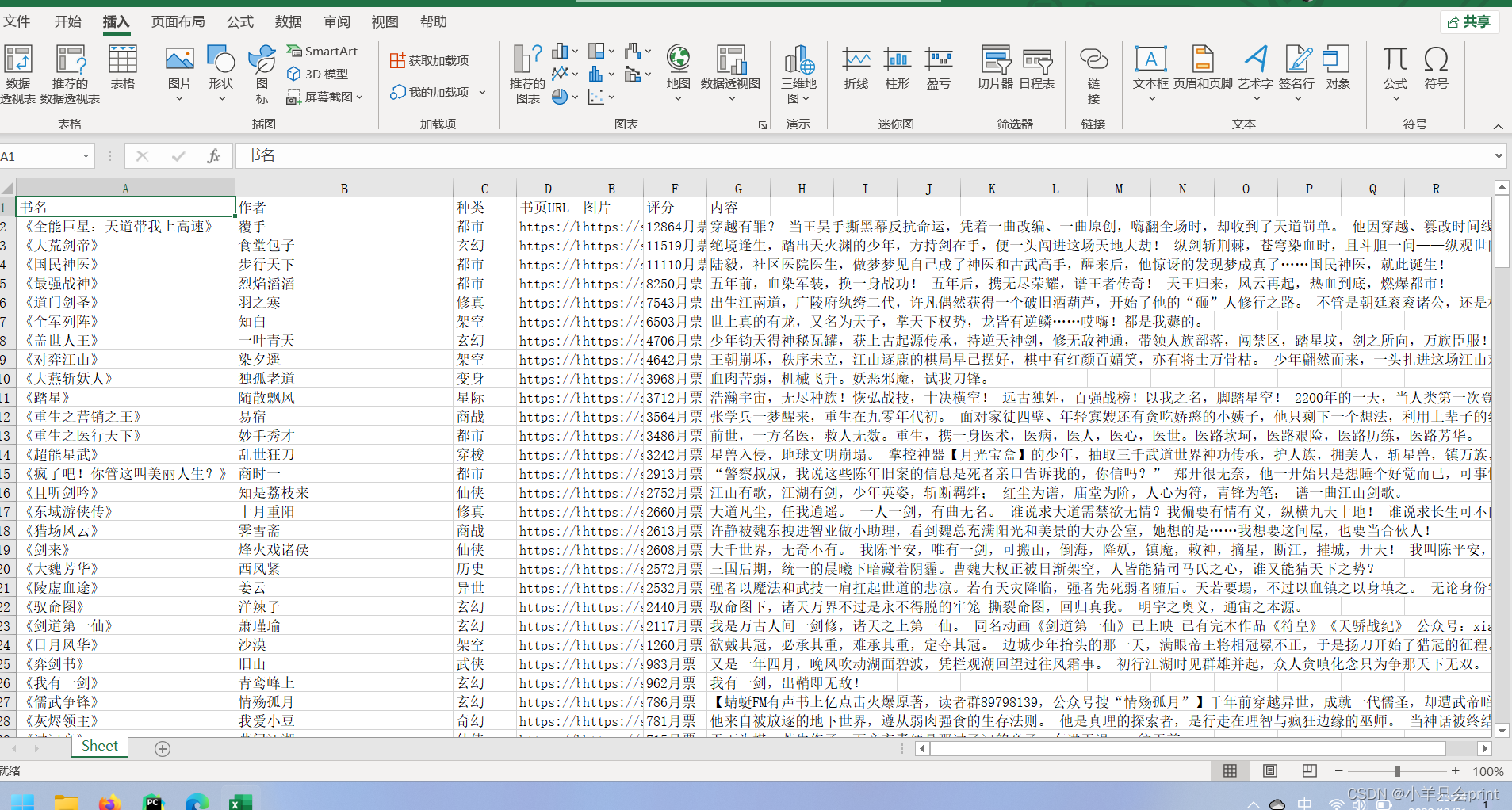
错误小tips:
大家最有可能出错找不到元素的时候可能就是在css语法上,也就是pyquery那里,例如有一个标签为<div class=rank_d_list borderB_c_dsh clearfix></div>,这里如果注意看的话很容易发现是有两个空格的,需要将borderB_c_dsh 和clearfix删除,只留最前面那个
四、爬虫CSS语法;
<div id='f1' class='v1'>我的
<div id='f2' class='v2'>你的
<img src='http:................'>
<div id='f2' class='v2'>你的
</div>
<span id='f3' class='v3'>他的</span>
</div>查找第二个div 的img标签:1、.f1 div img(一个空格代表下一个节点)
2、.f1 .f2 img
css查找同名同属性的最后一个标签----------找这个可以用 : .f1 div:last-child------这是大的div中的最后一个div标签,第一个的话就是.f1 div:first-child
第N个可以用.f1 div:nth-child(x)

以上的方法就是用在定位同一标签下的多个标签中的其中一个,大家可以好好去找资料,好好的巩固这个CSS语法,后期学习会更加重要,基本上的网页解析都可以用上他
















 5223
5223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











