






目录
1.初识Redis
1.1认识NoSQL
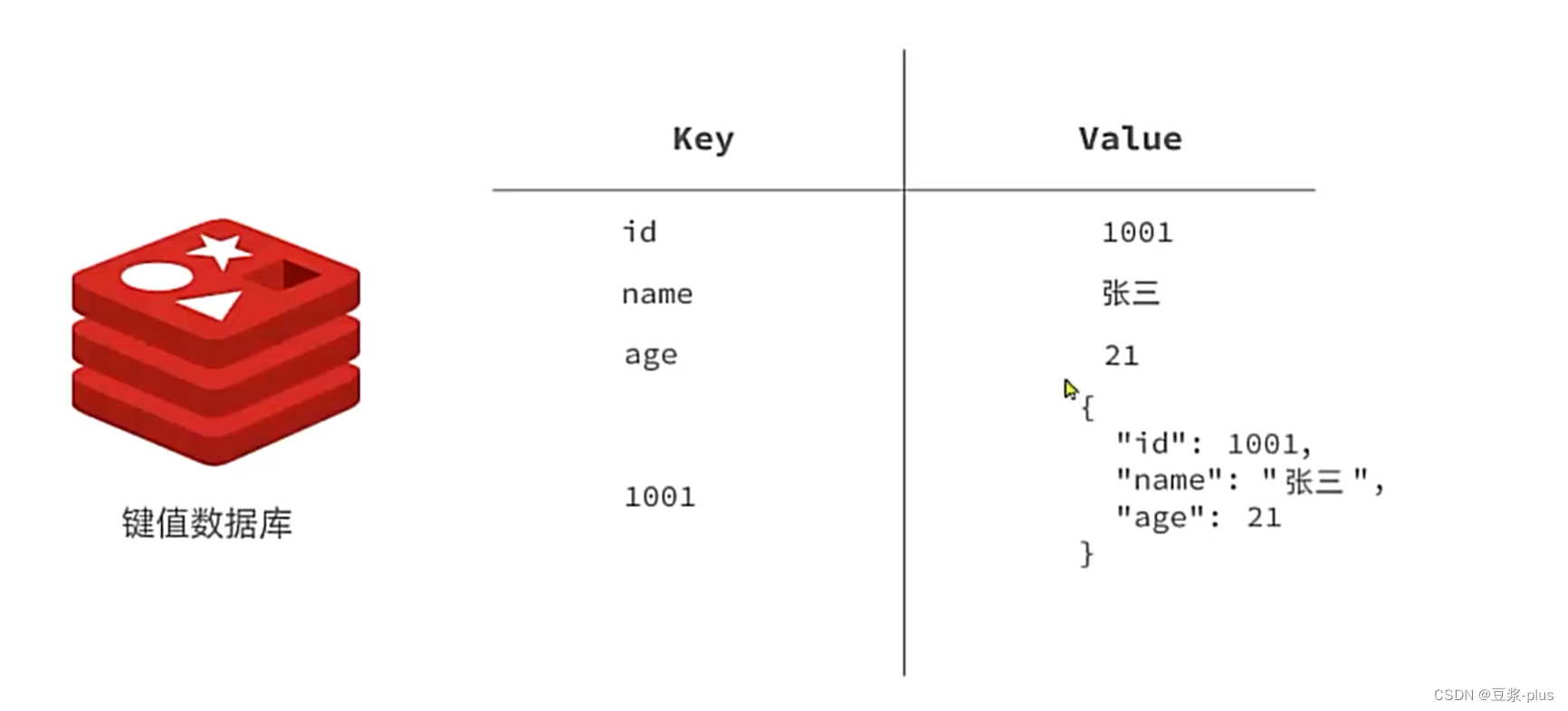

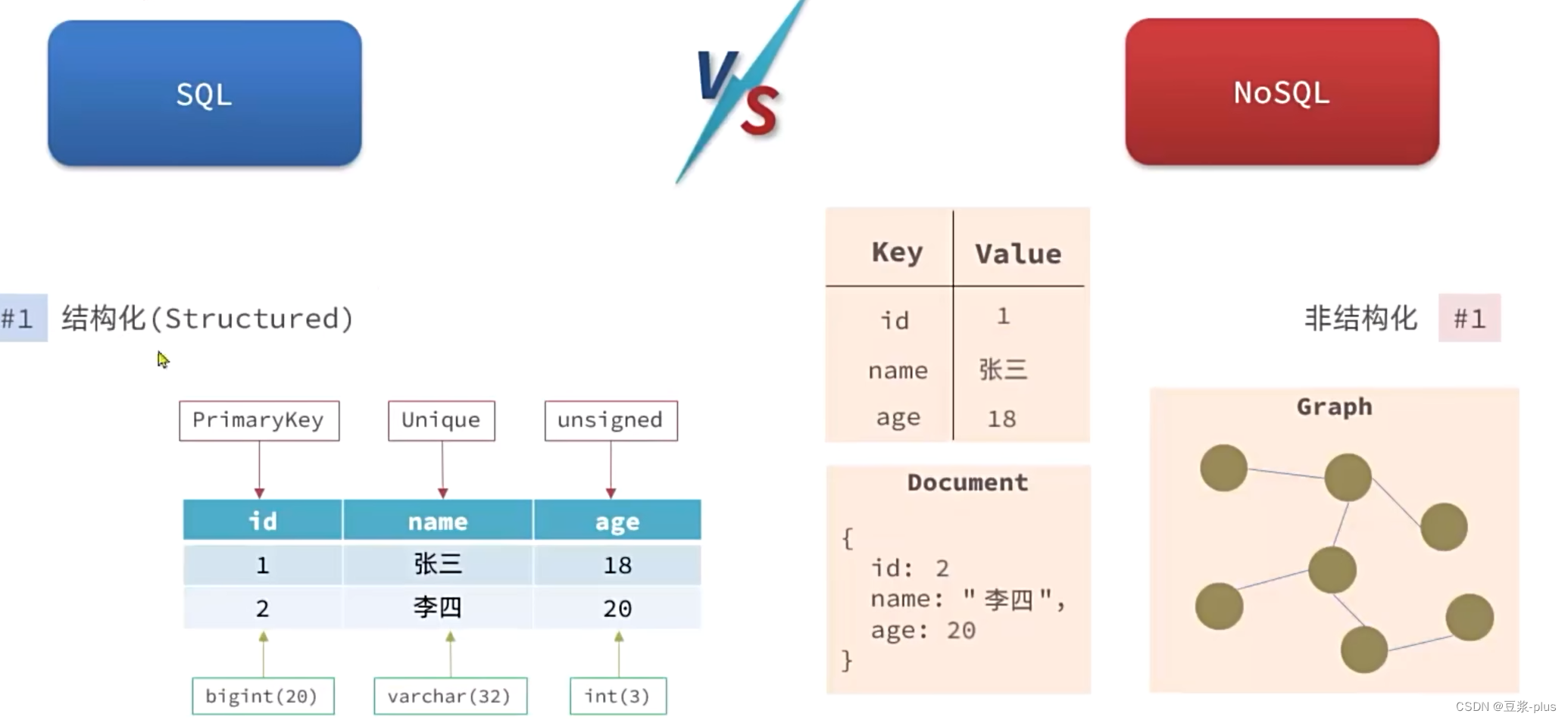
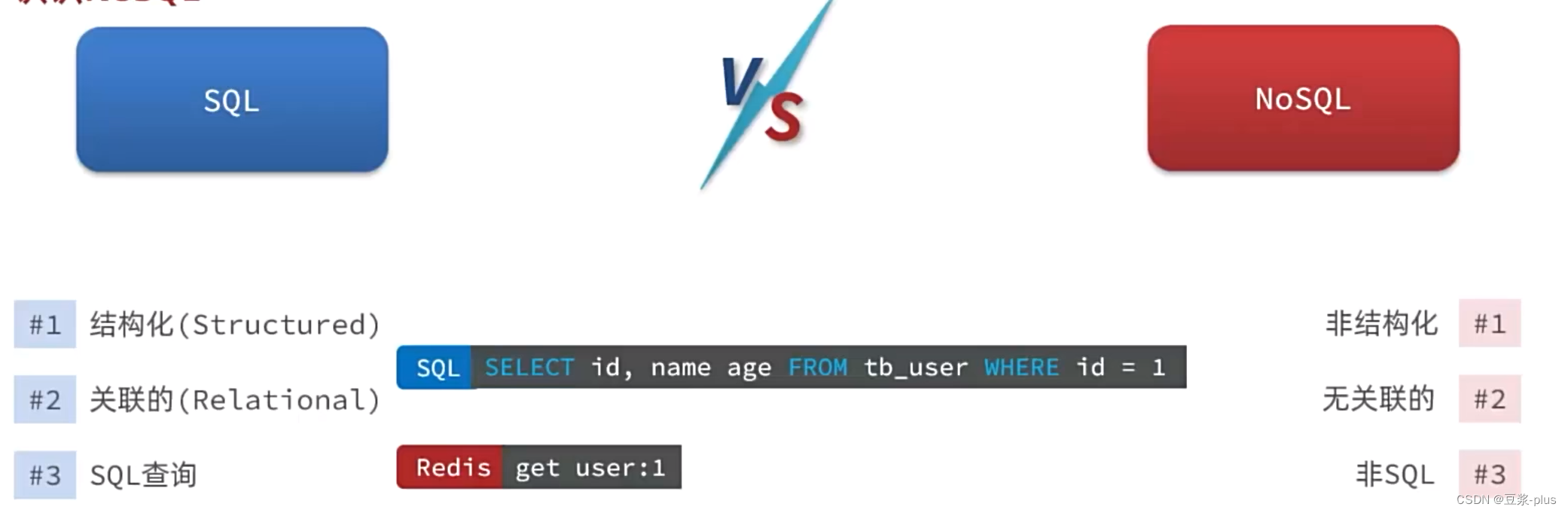


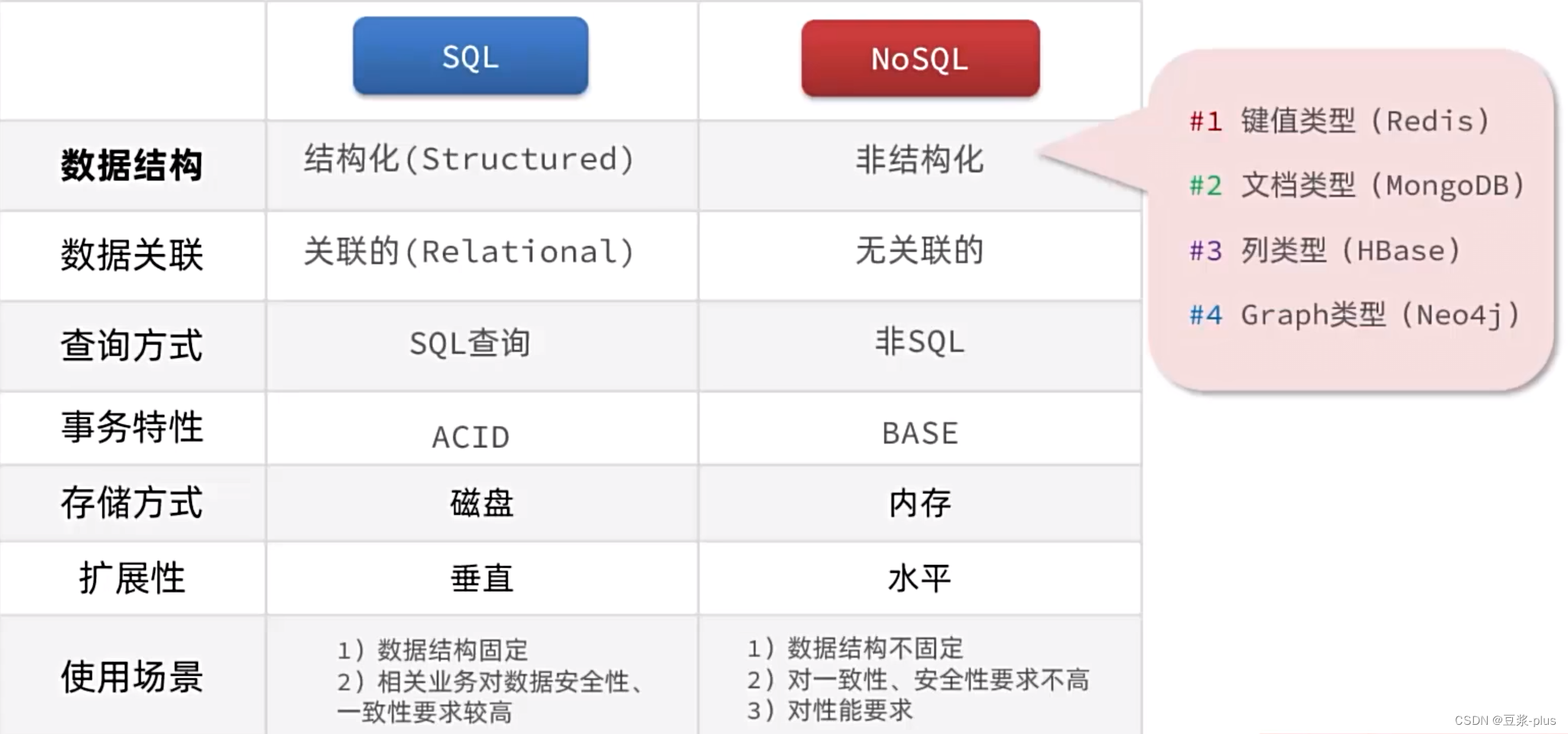
1.2认识Redis
特征:
- 键值(key-value)型,value支持多种不同数据结构,功能丰富
- 单线程,每个命令具备原子性
- 低延迟,速度快(基于内存、10多路复用、良好的编码)
- 支持数据持久化
- 支持主从集群、分片集群
- 支持多语言客户端
1.3安装Redis
Redis是基于C语言编写的,因此首先需要安装Redis所需要的gcc依赖:
yum install -y gcc tcl上传并解压 /usr/local/src目录下
进入redis安装目录
cd redis-7.2.4/运行编译命令:
make && make install安装文档:
cd /usr/local/bin/
安装成功:redis-server |
指定配置启动:
如果要让Redis以 后台 方式启动,则必须修改Redis配置文件,就在我们之前解压的redis安装包下
/usr/local/src/redis-6.2.6),名字叫redis.conf:



关机

开机自启
我们也可以通过配置来实现开机自启。
首先,新建一个系统服务文件:
vi /etc/systemd/system/redis.service
内容如下:
[Unit]
Description=redis-server
After=network.target
[Service]
Type=forking
ExecStart=/usr/local/bin/redis-server /usr/local/src/redis-7.2.4/redis.conf
PrivateTmp=true
[Install]
WantedBy=multi-user.target然后重载系统服务:
systemctl daemon-reload


redis-cli -h 192.168.200.129 -p 6379 -a 123456
下载图形化桌面客户端:
https://github.com/lework/RedisDesktopManager-Windows/releaseshttps://github.com/lework/RedisDesktopManager-Windows/releases
2.Redis常见命令
2.1 5种常见数据结构

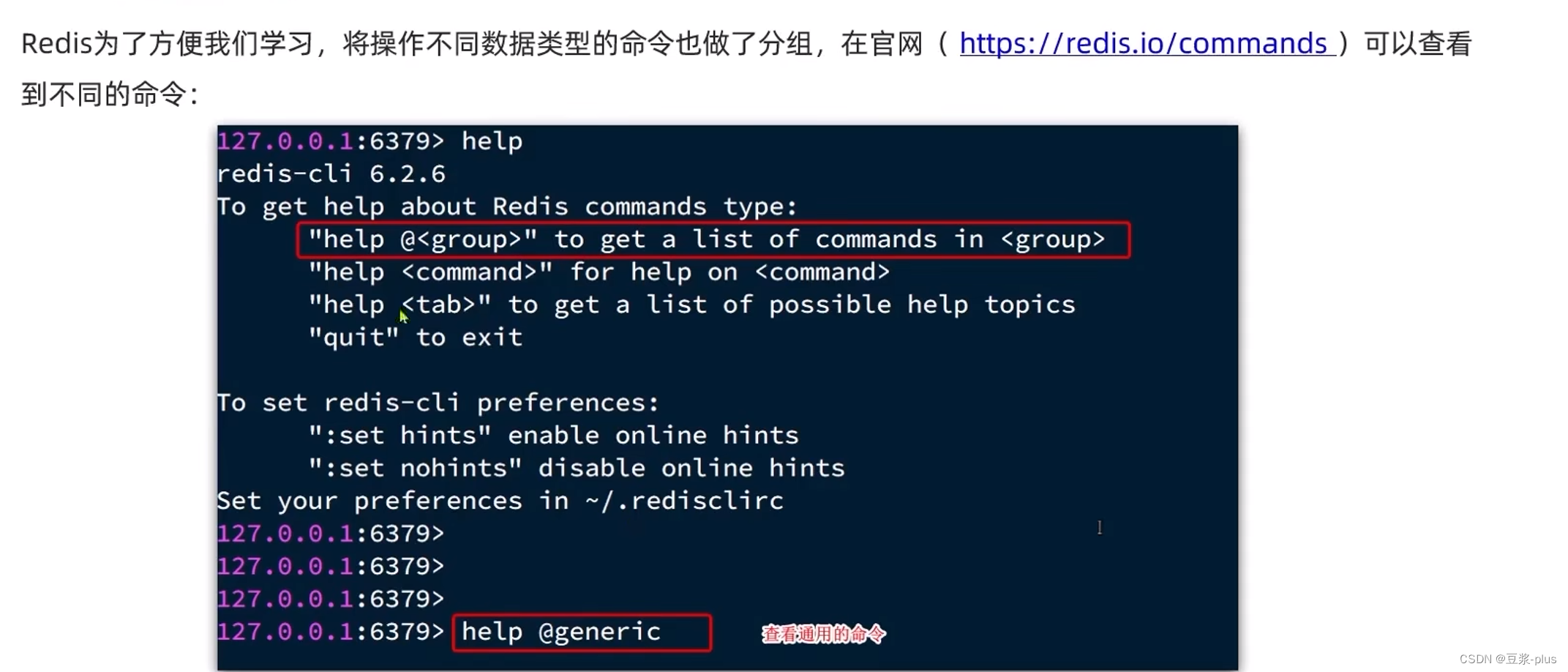
2.2通用命令
通用指令是部分数据类型的,都可以使用的指令,常见的有:
- KEYS:查看符合模板的所有key,不建议在生产环境设备上使用
- DEL:删除一个或多个指定的key
- EXISTS:判断key是否存在
- EXPIRE:给一个key设置有效期,有效期到期时该key会被自动删除
- TTL:查看一个KEY的剩余有效期
通过help[command]可以查看一个命令的具体用法,例如:

2.3不同数据结构的操作命令
2.3.1 String类型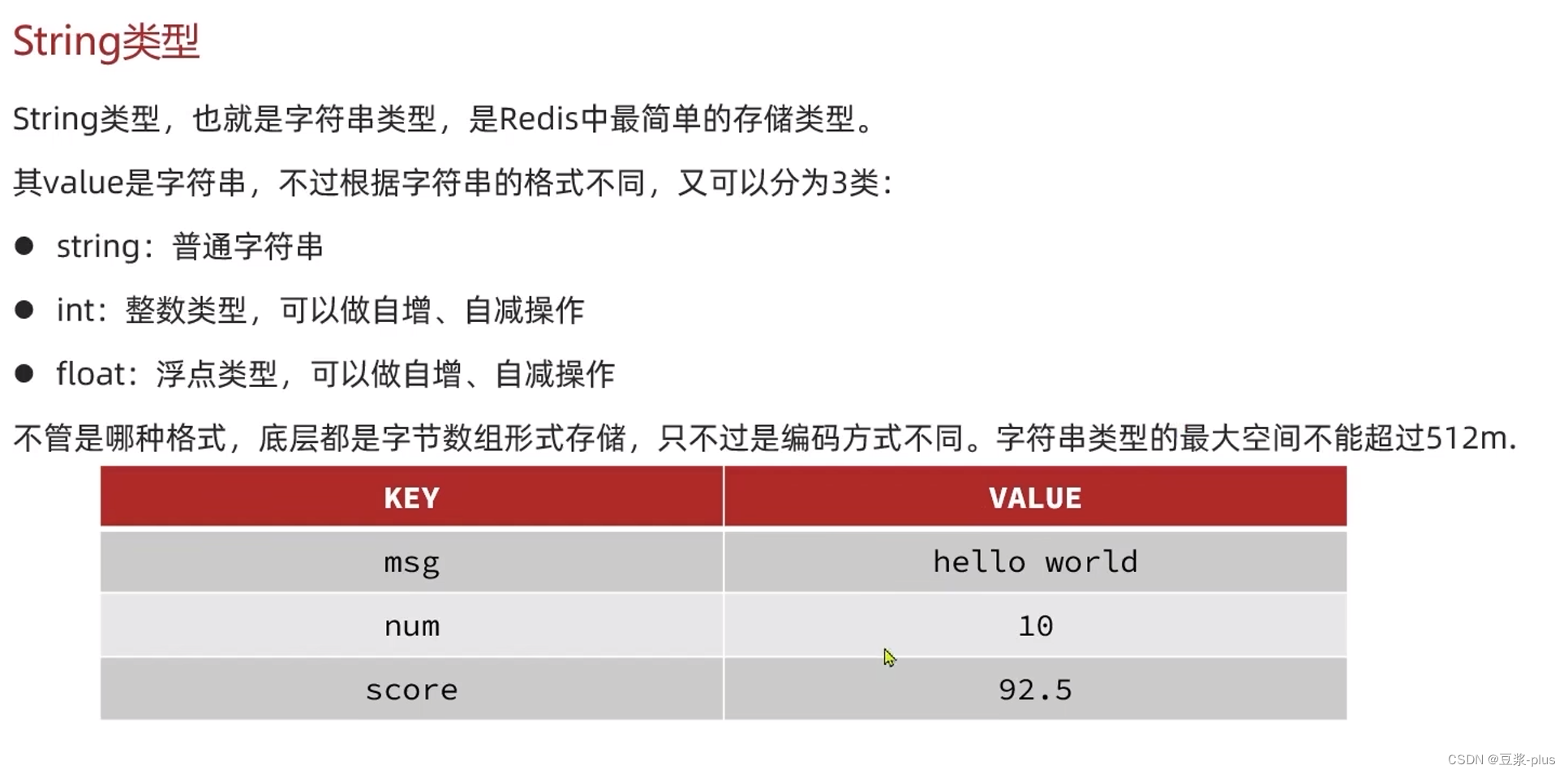
String类型的常见命令
String的常见命令有:
- SET:添加或者修改已经存在的一个String类型的键值对
- GET:根据key获取String类型的value
- MSET:批量添加多个String类型的键值对
- MGET:根据多个key获取多个String类型的value
- INCR:让一个整型的key自增1
- INCRBY:让一个整型的key自增并指定步长,例如:incrby num -2让num值自减2
- INCRBYFLOAT:让一个浮点类型的数字自增并指定步长
- SETNX:添加一个String类型的键值对,前提是这个key不存在,否则不执行(setnx)
- SETEX:添加一个String类型的键值对,并且指定有效期(setex)

2.3.2 Hash类型
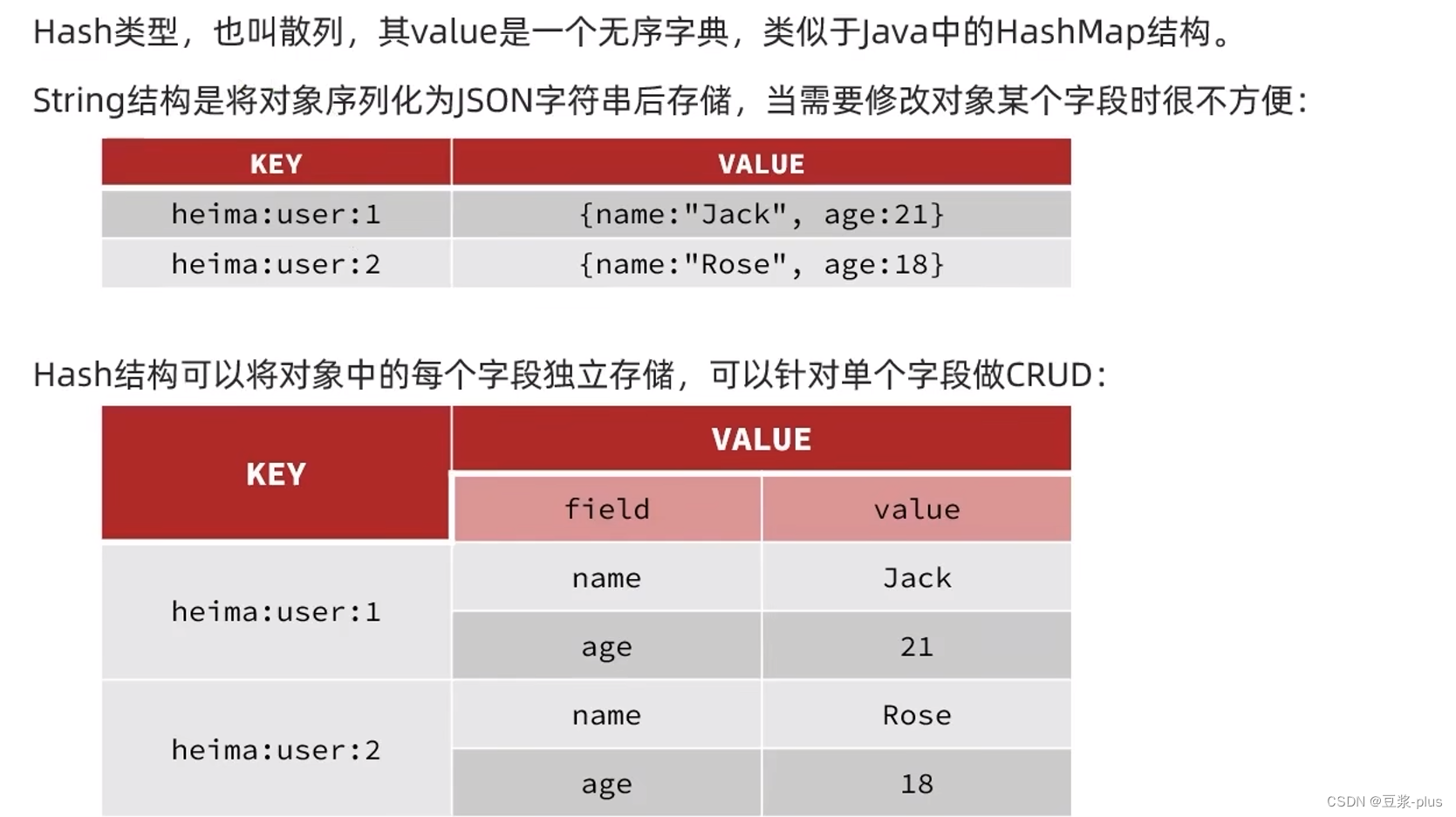
Hash类型的常见命令
Hash的常见命令有:
- HSET key field value:添加或者修改hash类型key的field的值
- HGET key field:获取一个hash类型key的field的值
- HMSET:批量添加多个hash类型key的field的值
- HMGET:批量获取多个hash类型key的field的值
- HGETALL:获取一个hash类型的key中的所有的field和value
- HKEYS:获取一个hash类型的key中的所有的field
- HVALS:获取一个hash类型的key中的所有的value
- HINCRBY:让一个hash类型key的字段值自增并指定步长
- HSETNX:添加一个hash类型的key的field值,前提是这个field不存在,否则不执行
2.3.3 List类型

List类型的常见命令
List的常见命令有
- LPUSH key element...:向列表左侧插入一个或多个元素
- LPOP key:移除并返回列表左侧的第一个元素,没有则返回nil
- RPUSH key element ...:向列表右侧插入一个或多个元素
- RPOP key:移除并返回列表右侧的第一个元素
- LRANGE key star end:返回一段角标范围内的所有元素
- BLPOP和BRPOP:与LPOP和RPOP类似,只不过在没有元素时等待指定时间,而不是直接返回nil


2.3.4 Set类型

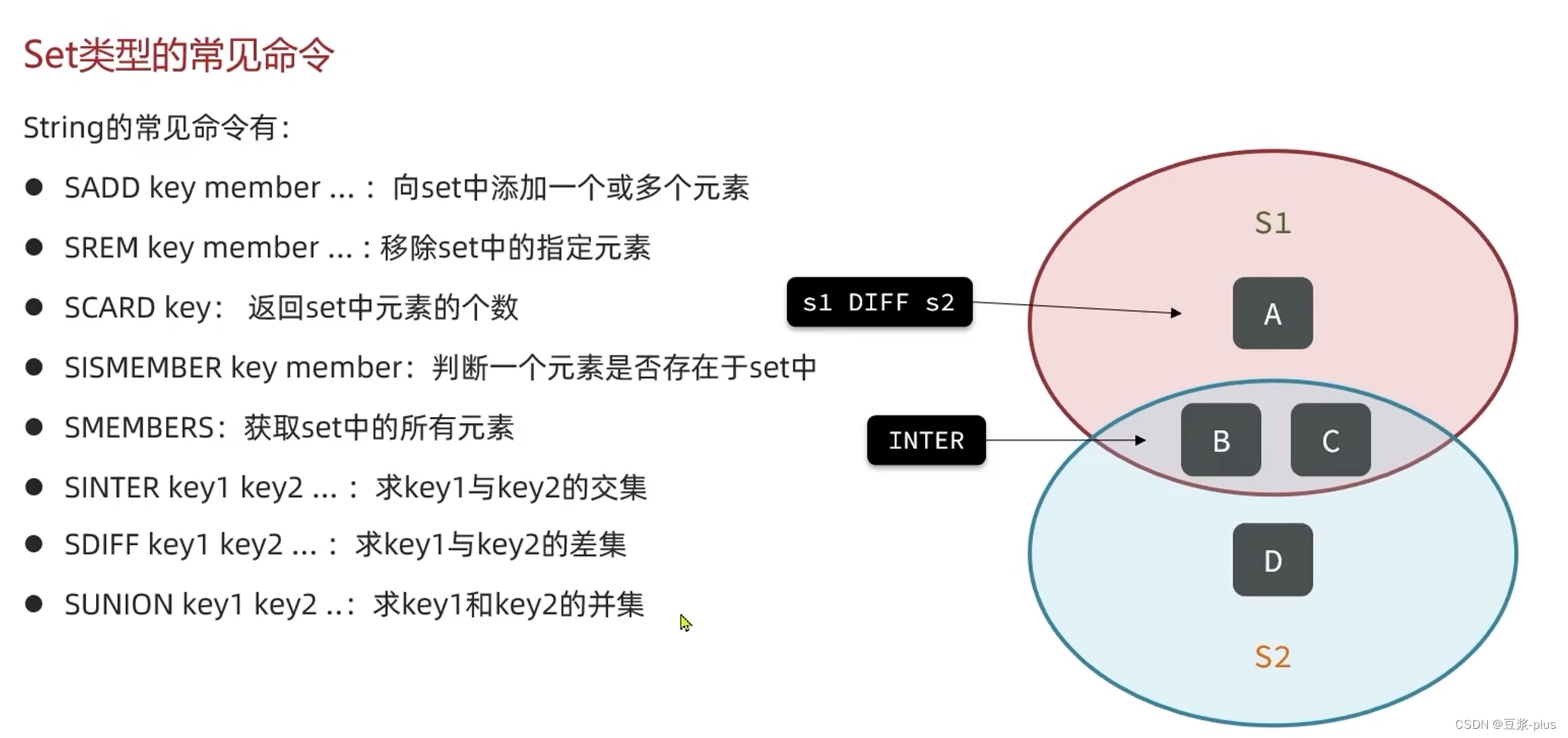
2.3.5 SortedSet类型


3.Redis的Java客户端
3.1Jedis客户端
Jedis 的官网地址:https://github.com/redis/jedis
1.引入依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.7.0</version>
</dependency>2.建立连接
package com.xj.test;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import redis.clients.jedis.Jedis;
import java.sql.SQLOutput;
/**
* @Author:豆浆
* @name :JedisTest
* @Date:2024/3/19 11:35
*/
public class JedisTest {
private Jedis jedis;
@BeforeEach
void setUp(){
//1 建立连接
jedis = new Jedis("10.156.211.164",6379);
// 2.设置密码
jedis.auth("123456");
// 3.选择库
jedis.select(0);
}
//测试string
@Test
void testString() {
// 插入数据
String result = jedis.set("name", "豆浆");
System.out.println("result=" + result);
// 获取数据
String name = jedis.get("name");
System.out.println("name ="+ name);
}
//4.释放资源
@AfterEach
void tearDown() {// 释放资源
if (jedis != null) {
jedis.close();
}
}
}


Jedis连接池:
Jedis本身是线程不安全的,并且频繁的创建和销毁连接会有性能损耗,因此我们推荐大家使用jedis连接池代替jedis的直连方式。
package com.xj.jedis.util;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
/**
* @Author:豆浆
* @name :JedisFactory
* @Date:2024/3/19 11:52
*/
public class JedisFactory {
private static final JedisPool jedispool;
static {
//配置连接池
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
// 最大连接
jedisPoolConfig.setMaxTotal(8);
// 最大空闲连接
jedisPoolConfig.setMaxIdle(8);
// 最小空闲连接
jedisPoolConfig.setMinIdle(0);
// 设置最长等待时间,ms
jedisPoolConfig.setMaxWaitMillis(200);
//创建连接池
jedispool = new JedisPool(jedisPoolConfig,
"10.156.211.164",6379,1000,"123456");
}
public static Jedis getJedis(){
return jedispool.getResource();
}
}
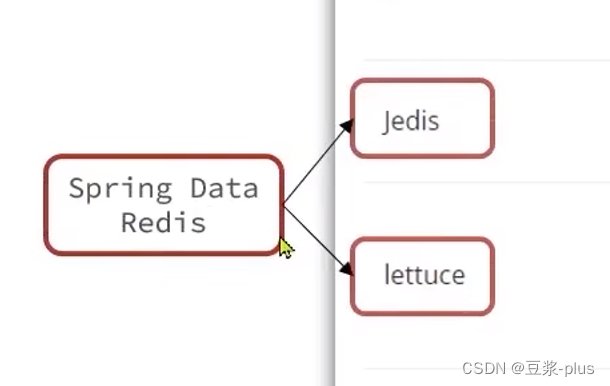
3.2SpringDataRedis客户端
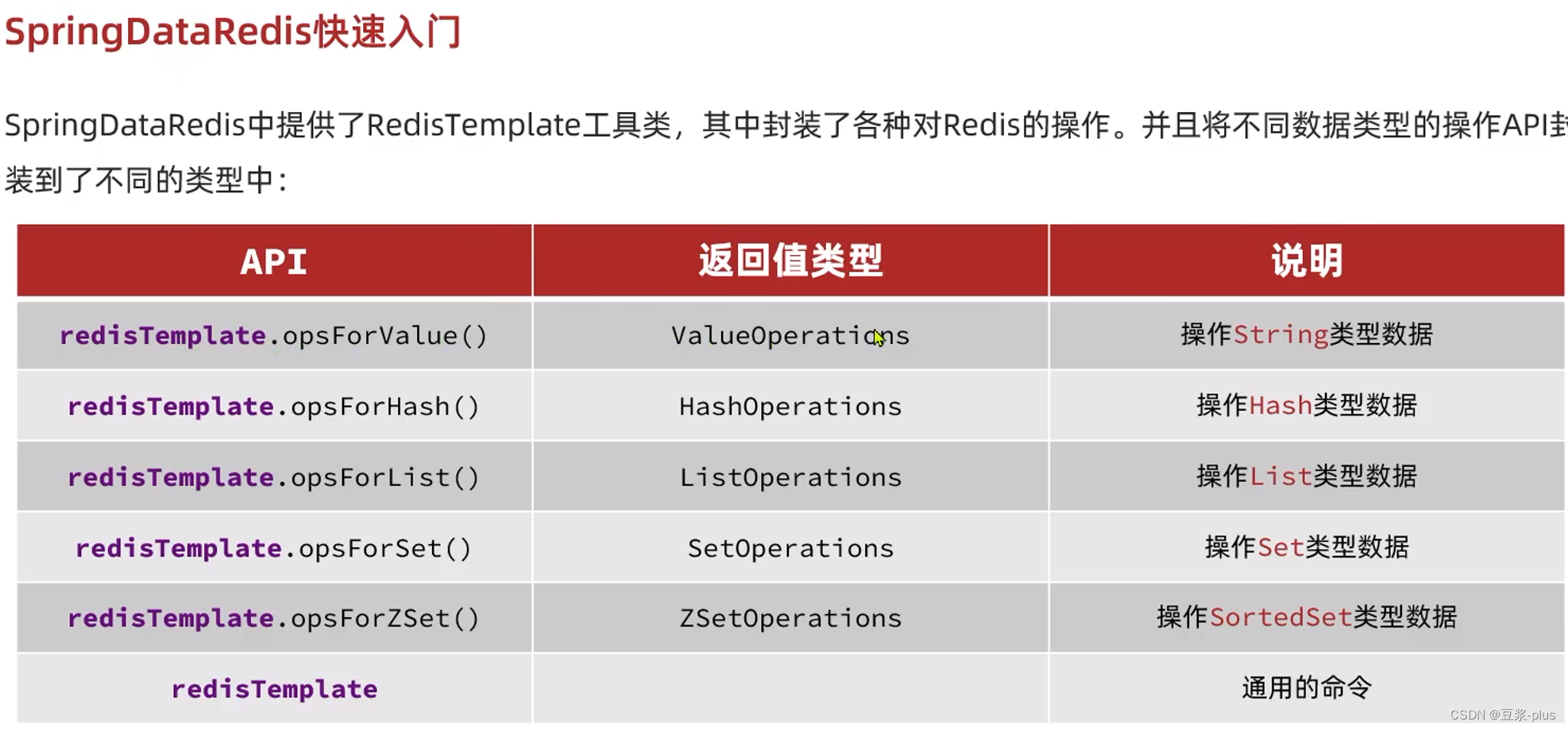
SpringDataRedis快速入门:
SpringBoqt已经提供了对SpringDataRedis的支持,使用非常简单:
1.引入依赖
<!--Redis依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--连接池依赖-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>2.配置文件
spring:
redis:
host: 192.168.200.129
port: 6379
password: 123456
lettuce:
pool:
max-active: 8 #最大连接
max-idle: 8 #最大空闲连接
min-idle: 0 #最小空闲连接
max-wait: 100ms #连接等待时间 
package com.xj;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
@SpringBootTest
class SpringbootRedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void testString() {
// 插入-条string类型数据
redisTemplate.opsForValue().set("name","豆浆1");
// 读取-条string类型数据
Object name =redisTemplate.opsForValue().get("name");
System.out.println("name=" + name);
}
}
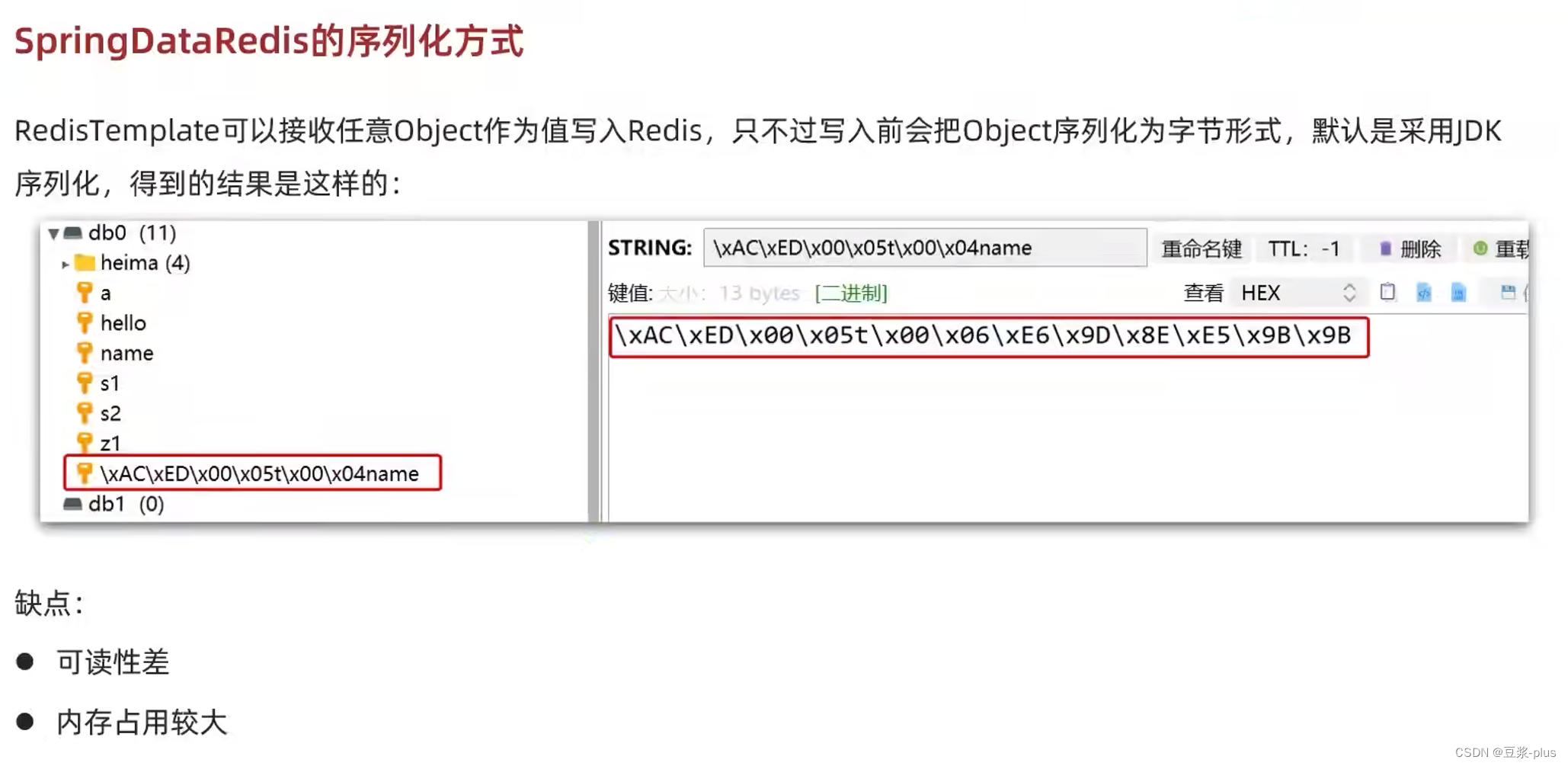
SpringDataRedis的序列化方式
我们可以自定义RedisTemplate的序列化方式,代码如下:
package com.xj.redis.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializer;
/**
* @Author:豆浆
* @name :RedisConfig
* @Date:2024/3/19 22:15
*/
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory){
// 创建RedisTemplate对象
RedisTemplate<String,Object> template = new RedisTemplate<>();
//设置连接工厂
template.setConnectionFactory(connectionFactory);
// 设置JSON序列化工具
GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();
// 设置key序列化
template.setKeySerializer(RedisSerializer.string());
template.setHashKeySerializer(RedisSerializer.string());
// 设置key序列化
template.setValueSerializer(jsonRedisSerializer);
template.setHashValueSerializer(jsonRedisSerializer);
//返回
return template;
}
}
修改:
@Autowired
private RedisTemplate<String,Object> redisTemplate;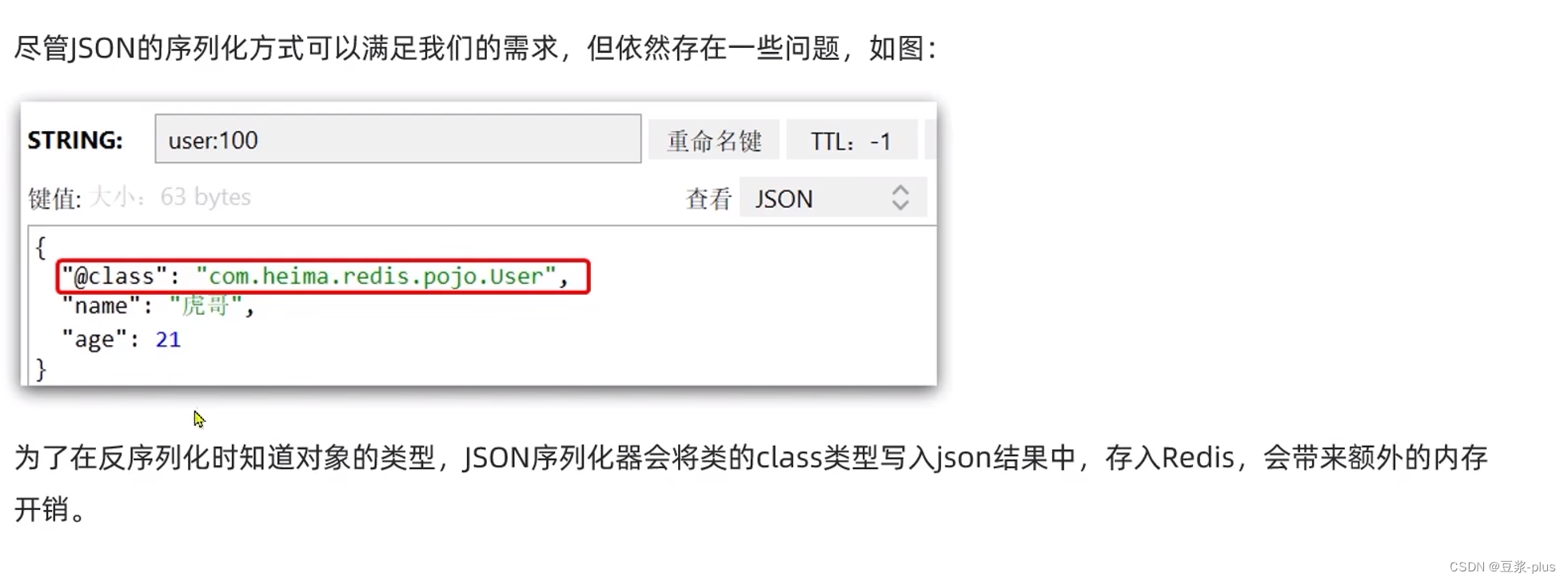
@Test
void testUser(){
redisTemplate.opsForValue().set("user:100",new User("xie",21));
User user = (User) redisTemplate.opsForValue().get("user:100");
System.out.println("0"+user);
}
Spring默认提供了一个StringRedisTemplate类,它的key和value的序列化方式默认就是String方式。省去了我们自定义RedisTemplate的过程:
package com.xj;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.xj.redis.pojo.User;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.StringRedisTemplate;
@SpringBootTest
class SpringbootRedis2Tests {
@Autowired
private StringRedisTemplate stringRedisTemplate;
//json
private static final ObjectMapper mapper=new ObjectMapper();
@Test
void testSt() {
// 插入-条string类型数据
stringRedisTemplate.opsForValue().set("name","豆浆5555");
// 读取-条string类型数据
Object name =stringRedisTemplate.opsForValue().get("name");
System.out.println("name=" + name);
}
@Test
void testString() throws JsonProcessingException {
// 准备对象
User user=new User("谢江1111",18);
// 手动序列化
String json = mapper.writeValueAsString(user);
//写入一条数据到redis
stringRedisTemplate.opsForValue().set("user:200",json);
//读取数据
String val = stringRedisTemplate.opsForValue().get("user:200");
//反序列化
User user1 =mapper.readValue(val,User.class);
System.out.println("user1="+user1);
}
}

TestHash:
@Test
void testHash(){
stringRedisTemplate.opsForHash().put("user:400","name","豆浆9999");
stringRedisTemplate.opsForHash().put("user:400","age","22");
Map<Object, Object> entries = stringRedisTemplate.opsForHash().entries("user:400");
System.out.println("entries"+entries);
}
4.实战
5.分布式缓存(Redis集群)
单点Redis的问题:
数据丢失问题
Redis是内存存储,服务重启可能会丢失数据
并发能力问题
单节点Redis并发能力虽然不错,但也无法满足如618这样的高并发场景
故障恢复问题
如果Redis宕机,则服务不可用,需要一种自动的故障恢复手段
存储能力问题
Redis基于内存,单节点能存储的数据量难以满足海量数据需求
5.1Redis持久化
RDB持久化:
RDB全称Redis Database Backup file(Redis数据备份文件),也被叫做Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。

Redis内部有触发RDB的机制,可以在redis.conf文件中找到,格式如下:
…”则表示禁用RDB# 900秒内,如果至少有1个key被修改,则执行bgsave如果是save
save 900 1
save 300 10
save 60 10000建议:30/60s
RDB的其它配置也可以在redis.conf文件中设置:
#是否压缩 ,建议不开启,压缩也会消耗cpu,磁盘的话不值钱
rdbcompression yes
# RDB文件名称
dbfilename dump.rdb
#文件保存的路径目录
dir ./#禁用RDB
save " "

AOF持久化:

AOF默认是关闭的,需要修改redis.conf配置文件来开启AOF:
#是否开启AOF功能,默认是no
appendonly yes# AOF文件的名称
appendfilename "appendonly.aof"
AOF的命令记录的频率也可以通过redis.conf文件来配:
#表示每执行一次写命令,立即记录到AOF文件
appendfsync always#写命令执行完先放入A0F缓冲区,然后表示每隔1秒将缓冲区数据写到A0F文件,是默认方案
appendfsync everysec
#写命令执行完先放入AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘appendfsync no

因为是记录命令,AOF文件会比RDB文件大的多。而且AOF会记录对同一个key的多次写操作,但只有最后一次写操作才有意义。通过执行bgrewriteaof命令,可以让AOF文件执行重写功能,用最少的命令达到相同效果。



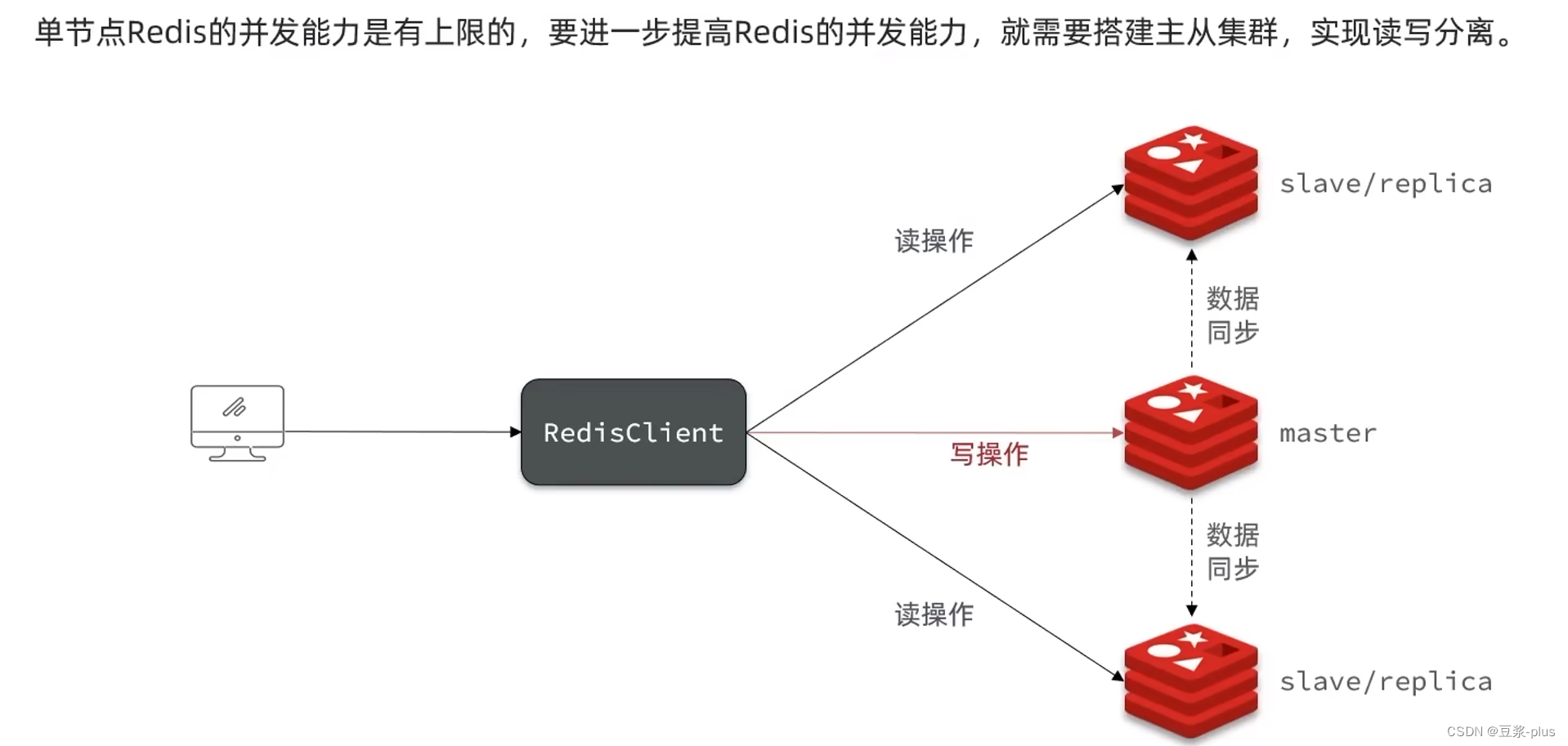
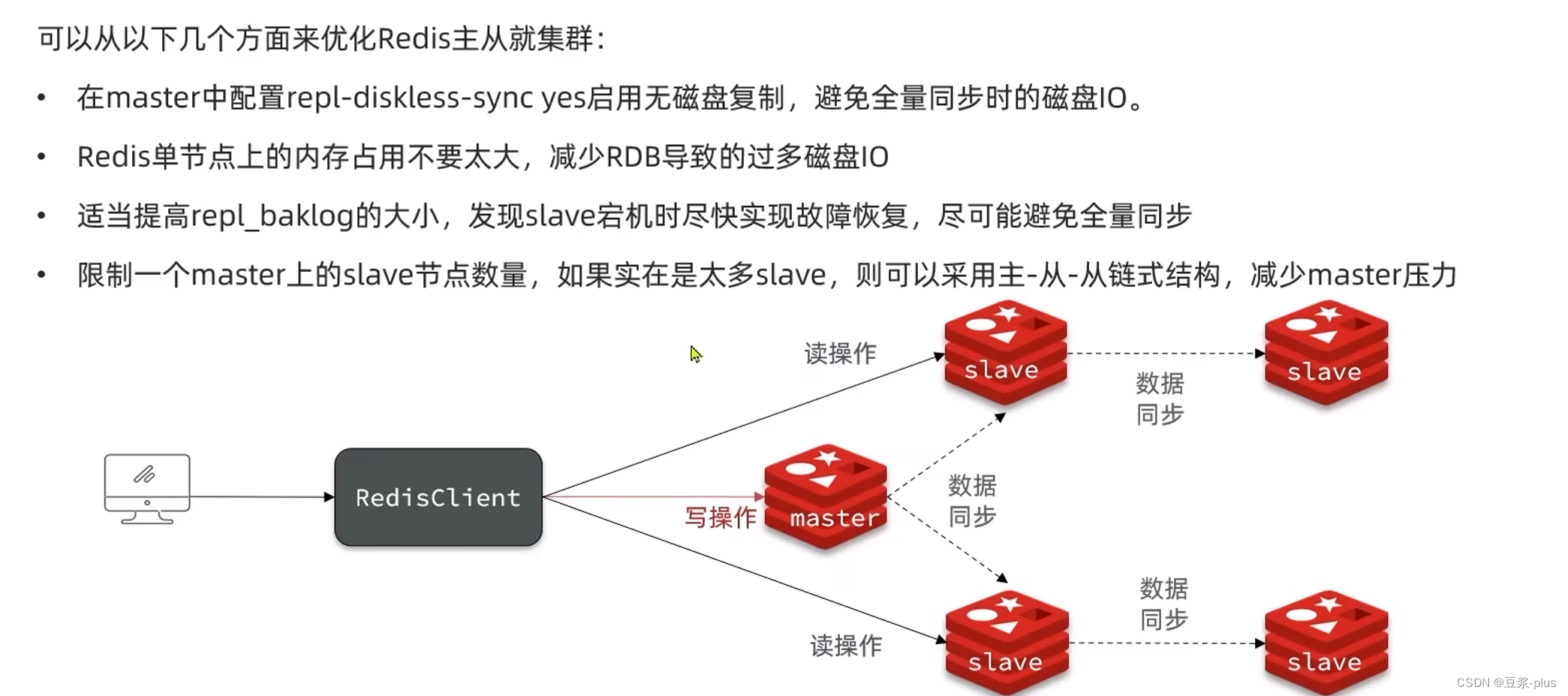
5.2Redis主从同步搭建主从架构:
5.2.1 搭建结构
共包含三个节点,一个主节点,两个从节点。
这里我们会在同一台虚拟机中开启3个redis实例,模拟主从集群,信息如下:
IP PORT 角色 192.168.150.101 7001 master 192.168.150.101 7002 slave 192.168.150.101 7003 slave 要在同一台虚拟机开启3个实例,必须准备三份不同的配置文件和目录,配置文件所在目录也就是工作目录。
5.2.2.准备实例和配置
1)创建目录
我们创建三个文件夹,名字分别叫7001、7002、7003:
# 进入/tmp目录
cd /tmp
# 创建目录
mkdir 7001 7002 7003
如图:
2)恢复原始配置
修改redis-6.2.4/redis.conf文件,将其中的持久化模式改为默认的RDB模式,AOF保持关闭状态。
```properties
# 开启RDB
# save ""
#save 3600 1
#save 300 100
#save 60 10000
# 关闭AOF
appendonly no
3)拷贝配置文件到每个实例目录
然后将redis-6.2.4/redis.conf文件拷贝到三个目录中(在/tmp目录执行下列命令):
# 方式一:逐个拷贝
cp ../usr/local/src/redis-7.2.4/redis.conf 7001
cp ../usr/local/src/redis-7.2.4/redis.conf 7002
cp ../usr/local/src/redis-7.2.4/redis.conf 7003
# 方式二:管道组合命令,一键拷贝
echo 7001 7002 7003 | xargs -t -n 1 cp ../usr/local/src/redis-7.2.4/redis.conf
4)修改每个实例的端口、工作目录
修改每个文件夹内的配置文件,将端口分别修改为7001、7002、7003,将rdb文件保存位置都修改为自己所在目录(在/tmp目录执行下列命令):
sed -i -e 's/6379/7001/g' -e 's/dir .\//dir \/tmp\/7001\//g' 7001/redis.conf
sed -i -e 's/6379/7002/g' -e 's/dir .\//dir \/tmp\/7002\//g' 7002/redis.conf
sed -i -e 's/6379/7003/g' -e 's/dir .\//dir \/tmp\/7003\//g' 7003/redis.conf
5)修改每个实例的声明IP
虚拟机本身有多个IP,为了避免将来混乱,我们需要在redis.conf文件中指定每一个实例的绑定ip信息,格式如下:
```properties
# redis实例的声明 IP
replica-announce-ip 192.168.150.101
每个目录都要改,我们一键完成修改(在/tmp目录执行下列命令):
# 逐一执行
sed -i '1a replica-announce-ip 192.168.200.129' 7001/redis.conf
sed -i '1a replica-announce-ip 192.168.200.129' 7002/redis.conf
sed -i '1a replica-announce-ip 192.168.200.129' 7003/redis.conf
# 或者一键修改
printf '%s\n' 7001 7002 7003 | xargs -I{} -t sed -i '1a replica-announce-ip 192.168.200.129' {}/redis.conf
5.2.3.启动
为了方便查看日志,我们打开3个ssh窗口,分别启动3个redis实例,启动命令:
# 第1个
redis-server 7001/redis.conf
# 第2个
redis-server 7002/redis.conf
# 第3个
redis-server 7003/redis.conf
启动后:
如果要一键停止,可以运行下面命令:
printf '%s\n' 7001 7002 7003 | xargs -I{} -t redis-cli -p {} shutdown
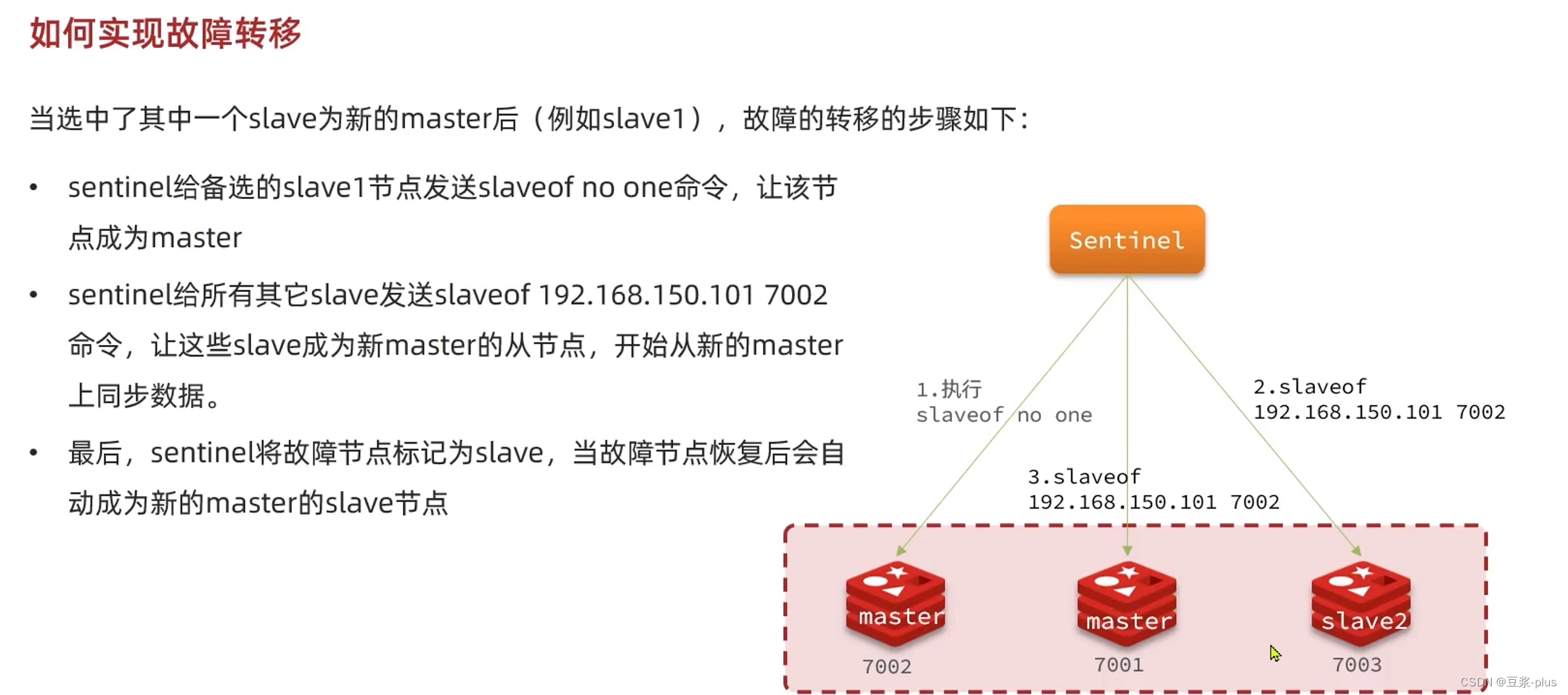
5.2.4.开启主从关系
现在三个实例还没有任何关系,要配置主从可以使用replicaof 或者slaveof(5.0以前)命令。
有临时和永久两种模式:
- 修改配置文件(永久生效)
- 在redis.conf中添加一行配置:```slaveof <masterip> <masterport>```
- 使用redis-cli客户端连接到redis服务,执行slaveof命令(重启后失效):
slaveof <masterip> <masterport>
<strong><font color='red'>注意</font></strong>:在5.0以后新增命令replicaof,与salveof效果一致。
这里我们为了演示方便,使用方式二。
通过redis-cli命令连接7002,执行下面命令:
# 连接 7002
redis-cli -p 7002 -h 192.168.200.129 -a 123456
# 执行slaveof
slaveof 1192.168.200.129 7001
通过redis-cli命令连接7003,执行下面命令:
# 连接 7003
redis-cli -p 7003
# 执行slaveof
slaveof 192.168.150.101 7001
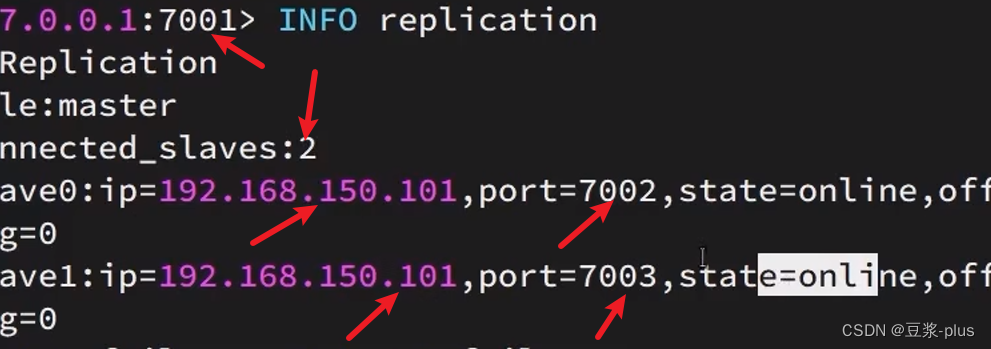
然后连接 7001节点,查看集群状态:
# 连接 7001
redis-cli -p 7001
# 查看状态
info replication
结果:
5.2.5.测试
执行下列操作以测试:
- 利用redis-cli连接7001,执行```set num 123```
- 利用redis-cli连接7002,执行```get num```,再执行```set num 666```
- 利用redis-cli连接7003,执行```get num```,再执行```set num 888```
可以发现,只有在7001这个master节点上可以执行写操作,7002和7003这两个slave节点只能执行读操作。





主从数据同步原理:
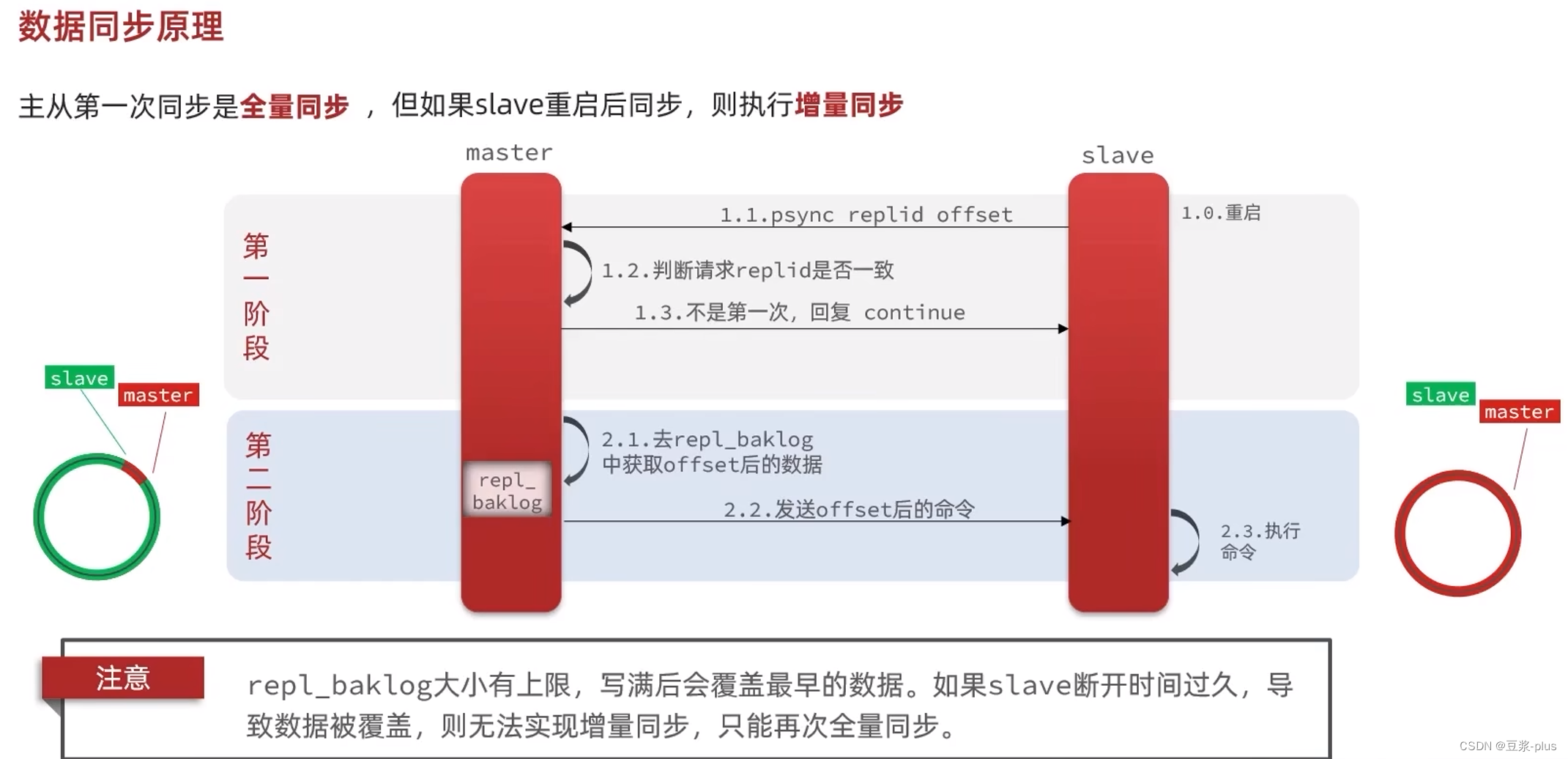
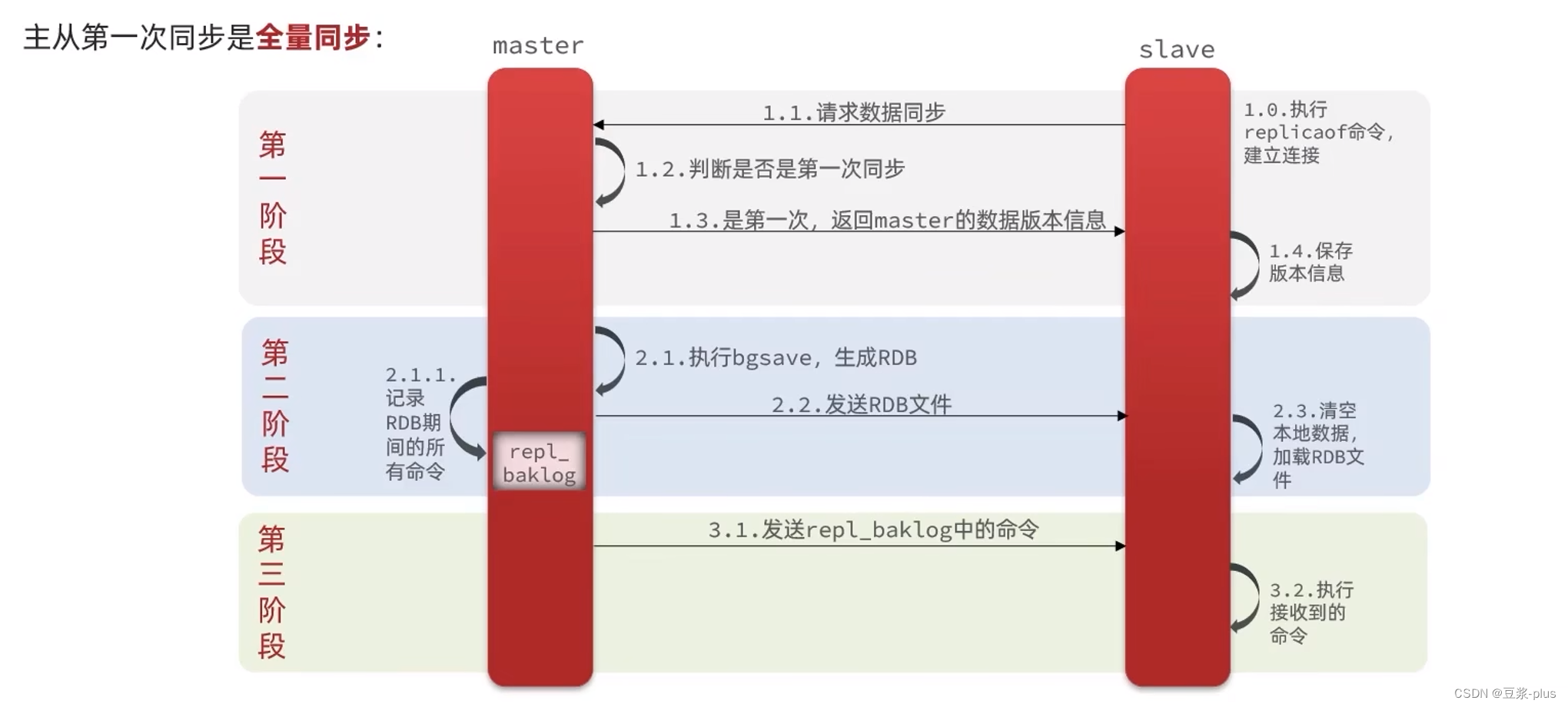

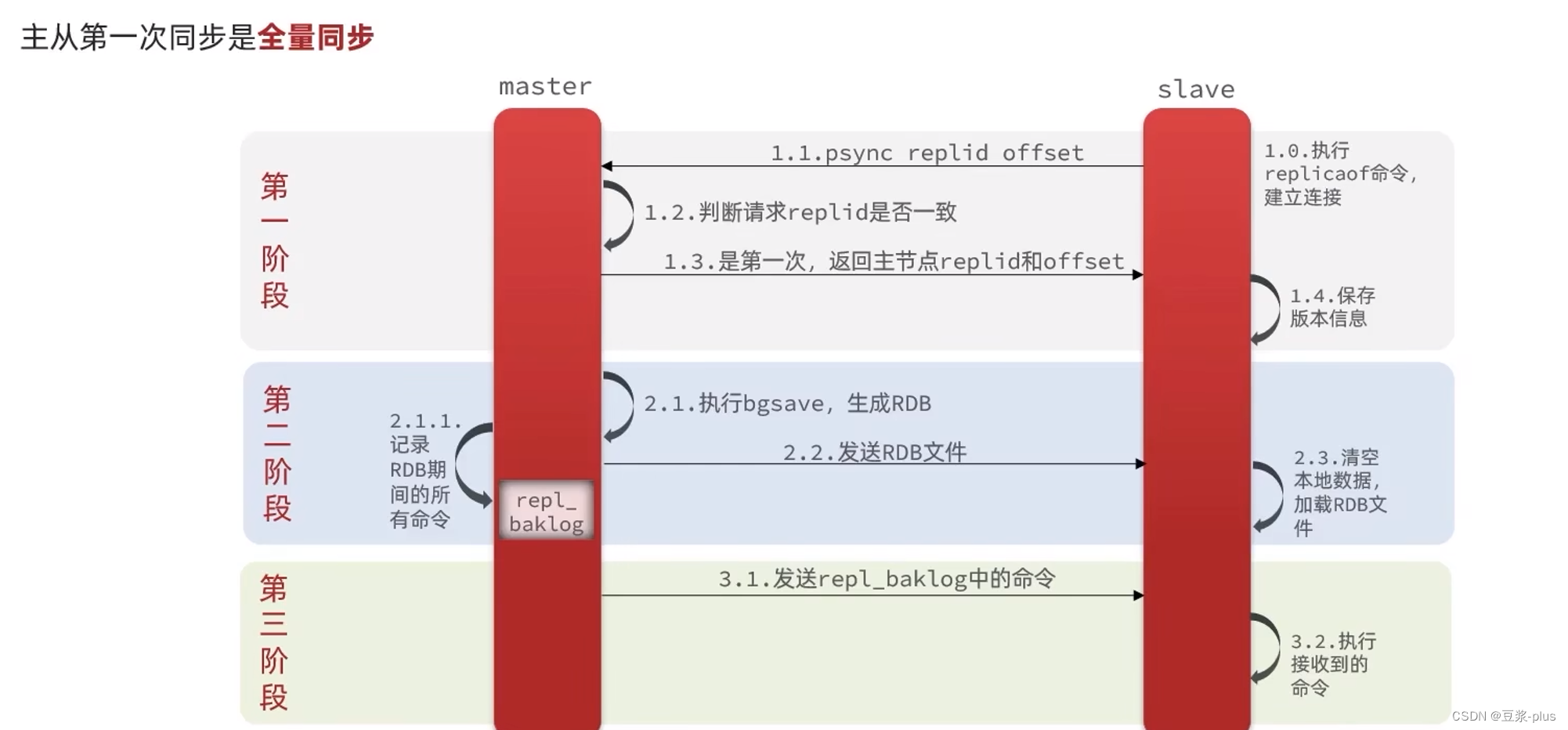


5.3Redis哨兵slave节点宕机恢复后可以找master节点同步数据
那master节点宕机怎么办?
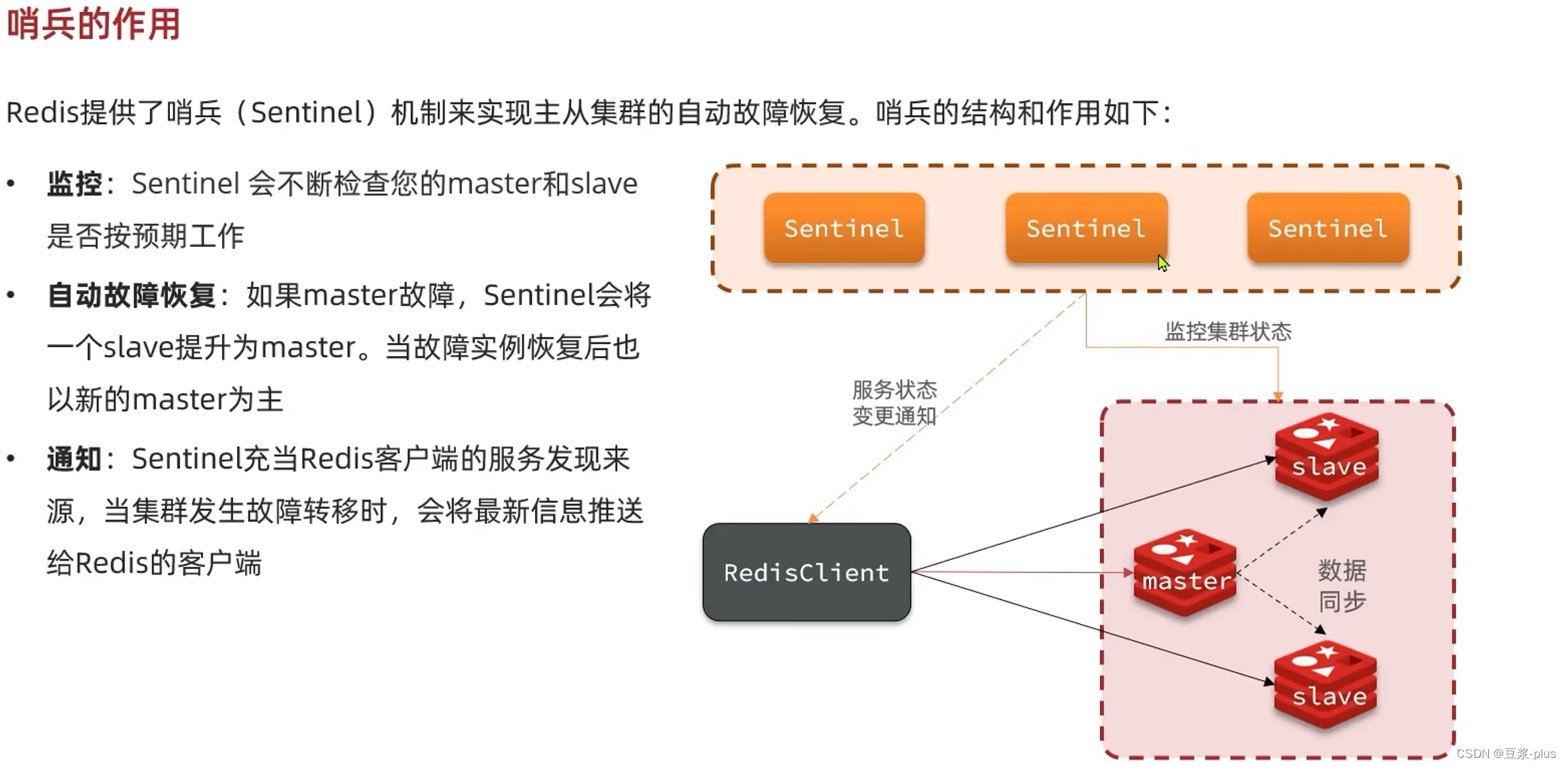
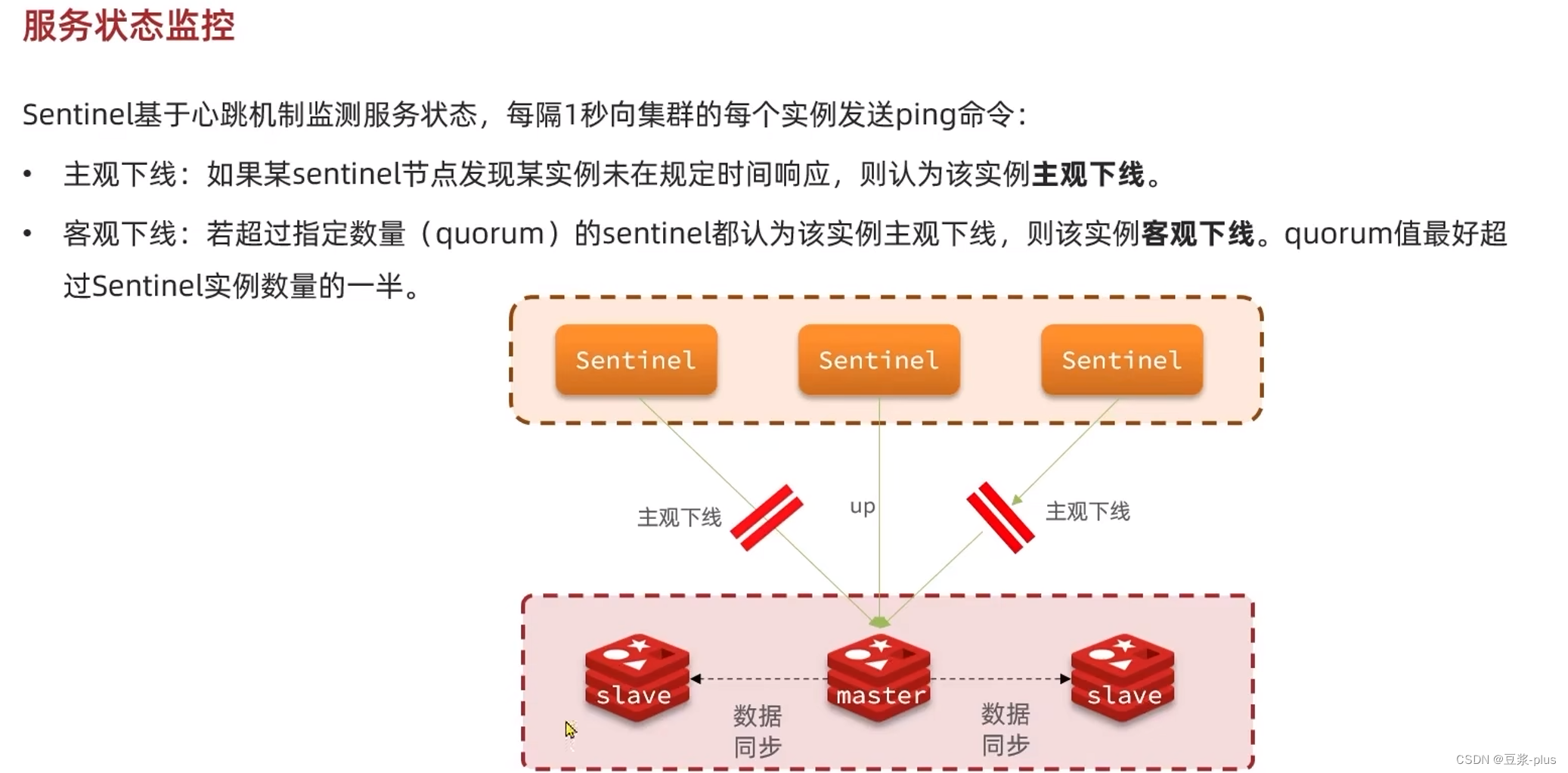
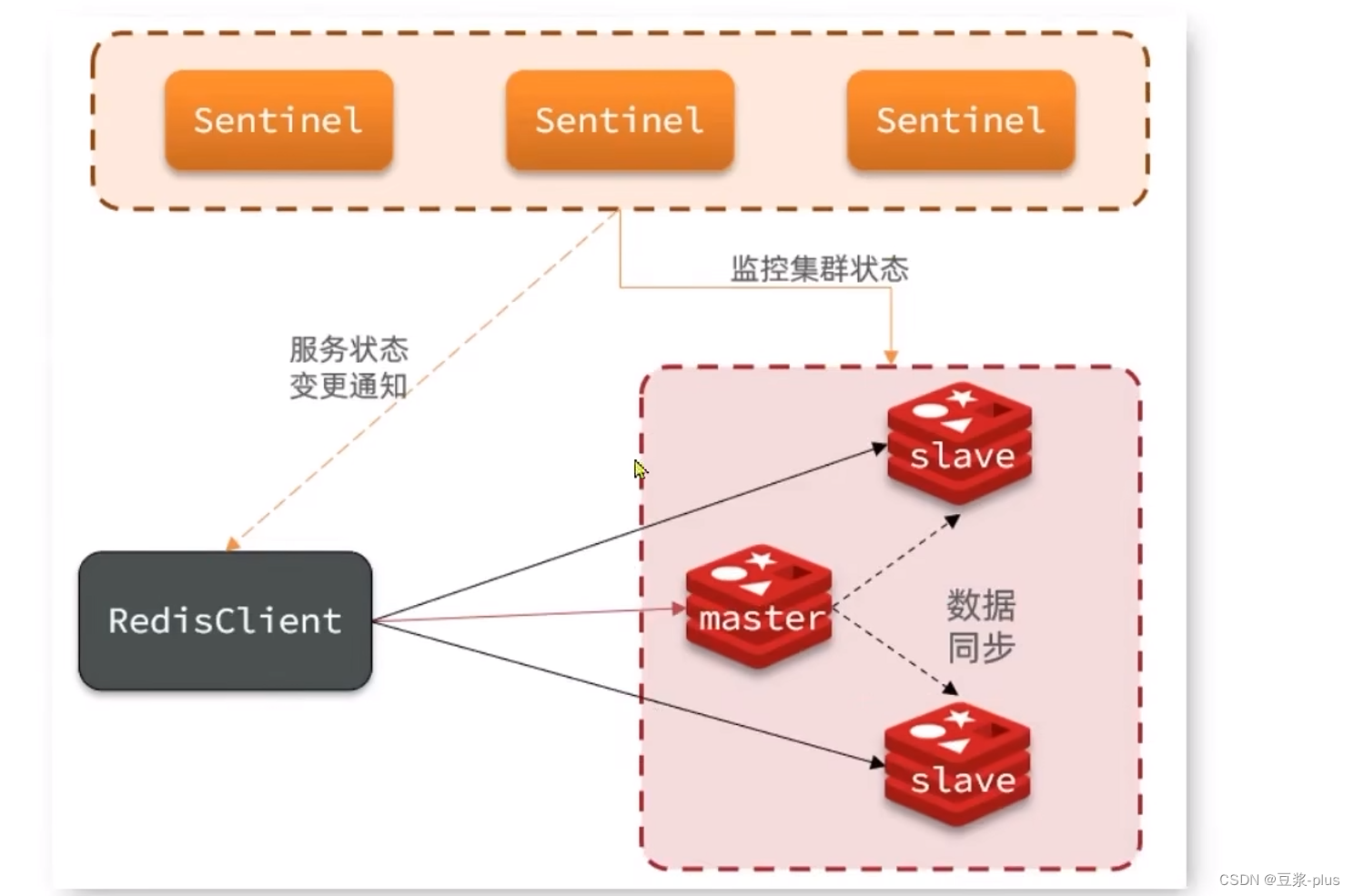
5.3.1哨兵的作用和原理

5.3.2搭建哨兵集群
## 5.3.1.集群结构
这里我们搭建一个三节点形成的Sentinel集群,来监管之前的Redis主从集群。如图:
三个sentinel实例信息如下:
节点 IP PORT s1 192.168.200.129 7001 s2 192.168.200.129 7002 s3 192.168.200.129 77003 ## 5.3.2.准备实例和配置
要在同一台虚拟机开启3个实例,必须准备三份不同的配置文件和目录,配置文件所在目录也就是工作目录。
我们创建三个文件夹,名字分别叫s1、s2、s3:
# 进入/tmp目录
cd /tmp
# 创建目录
mkdir s1 s2 s3
如图:
然后我们在s1目录创建一个sentinel.conf文件,添加下面的内容:
port 27001
sentinel announce-ip 192.168.200.129
sentinel monitor mymaster 192.168.200.129 7001 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
dir "/tmp/s1"
解读:
- `port 27001`:是当前sentinel实例的端口
- `sentinel monitor mymaster 192.168.200.129 7001 2`:指定主节点信息
- `mymaster`:主节点名称,自定义,任意写
- `192.168.200.129 7001`:主节点的ip和端口
- `2`:选举master时的quorum值
然后将s1/sentinel.conf文件拷贝到s2、s3两个目录中(在/tmp目录执行下列命令):
# 方式一:逐个拷贝
cp s1/sentinel.conf s2
cp s1/sentinel.conf s3
# 方式二:管道组合命令,一键拷贝
echo s2 s3 | xargs -t -n 1 cp s1/sentinel.conf
修改s2、s3两个文件夹内的配置文件,将端口分别修改为27002、27003:
sed -i -e 's/27001/27002/g' -e 's/s1/s2/g' s2/sentinel.conf
sed -i -e 's/27001/27003/g' -e 's/s1/s3/g' s3/sentinel.conf
## 5.3.3.启动
为了方便查看日志,我们打开3个ssh窗口,分别启动3个redis实例,启动命令:
# 第1个
redis-sentinel s1/sentinel.conf
# 第2个
redis-sentinel s2/sentinel.conf
# 第3个
redis-sentinel s3/sentinel.conf
## 5.3.4.测试
尝试让master节点7001宕机,查看sentinel日志:
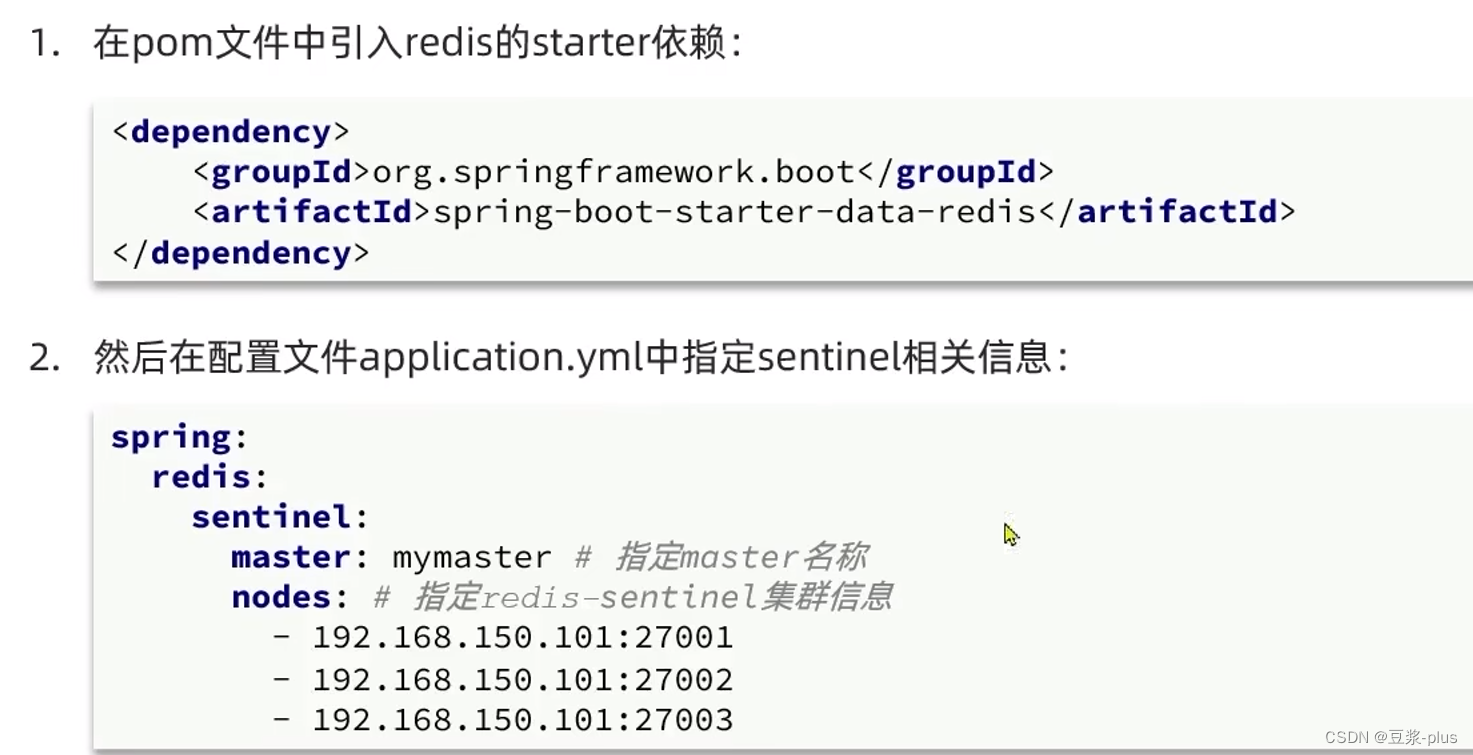
5.3.3RedisTemplate的哨兵模式



5.4Redis分片集群
## 5.4.1.集群结构
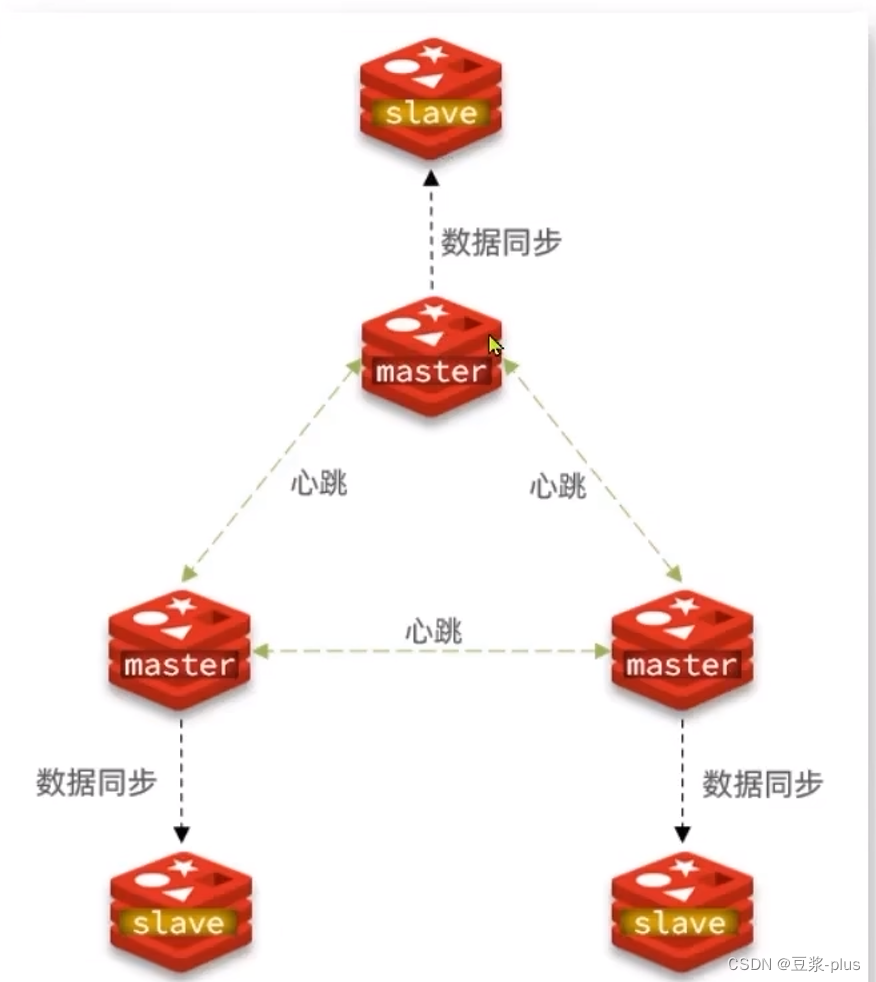
分片集群需要的节点数量较多,这里我们搭建一个最小的分片集群,包含3个master节点,每个master包含一个slave节点,结构如下:
这里我们会在同一台虚拟机中开启6个redis实例,模拟分片集群,信息如下:
IP PORT 角色 192.168.200.129 7001 master 192.168.200.129 7002 master 192.168.200.129 7003 master 192.168.200.129 8001 slave 192.168.200.129 8002 slave 192.168.200.129 8003 slave ## 5.4.2.准备实例和配置
删除之前的7001、7002、7003这几个目录,重新创建出7001、7002、7003、8001、8002、8003目录:
# 进入/tmp目录
cd /tmp# 删除旧的,避免配置干扰
rm -rf 7001 7002 7003# 创建目录
mkdir 7001 7002 7003 8001 8002 8003在/tmp下准备一个新的redis.conf文件,内容如下:
port 6379 # 开启集群功能 cluster-enabled yes # 集群的配置文件名称,不需要我们创建,由redis自己维护 cluster-config-file /tmp/6379/nodes.conf # 节点心跳失败的超时时间 cluster-node-timeout 5000 # 持久化文件存放目录 dir /tmp/6379 # 绑定地址 bind 0.0.0.0 # 让redis后台运行 daemonize yes # 注册的实例ip replica-announce-ip 192.168.150.101 # 保护模式 protected-mode no # 数据库数量 databases 1 # 日志 logfile /tmp/6379/run.log将这个文件拷贝到每个目录下:
# 进入/tmp目录
cd /tmp# 执行拷贝
echo 7001 7002 7003 8001 8002 8003 | xargs -t -n 1 cp redis.conf修改每个目录下的redis.conf,将其中的6379修改为与所在目录一致:
# 进入/tmp目录
cd /tmp# 修改配置文件
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t sed -i 's/6379/{}/g' {}/redis.conf## 5.4.3.启动
因为已经配置了后台启动模式,所以可以直接启动服务:
# 进入/tmp目录
cd /tmp# 一键启动所有服务
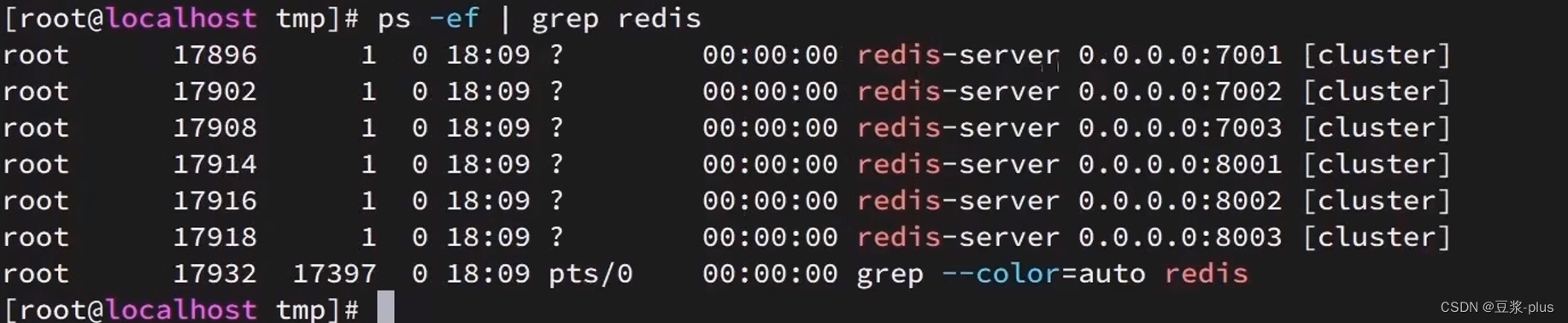
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t redis-server {}/redis.conf通过ps查看状态:
ps -ef | grep redis发现服务都已经正常启动:
如果要关闭所有进程,可以执行命令:
ps -ef | grep redis | awk '{print $2}' | xargs kill或者(推荐这种方式):
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t redis-cli -p {} shutdown## 5.4.4.创建集群
虽然服务启动了,但是目前每个服务之间都是独立的,没有任何关联。
我们需要执行命令来创建集群,在Redis5.0之前创建集群比较麻烦,5.0之后集群管理命令都集成到了redis-cli中。
1)Redis5.0之前
Redis5.0之前集群命令都是用redis安装包下的src/redis-trib.rb来实现的。因为redis-trib.rb是有ruby语言编写的所以需要安装ruby环境。
# 安装依赖
yum -y install zlib ruby rubygems gem install redis然后通过命令来管理集群:
# 进入redis的src目录
cd /tmp/redis-6.2.4/src# 创建集群
./redis-trib.rb create --replicas 1 192.168.150.101:7001 192.168.150.101:7002 192.168.150.101:7003 192.168.150.101:8001 192.168.150.101:8002 192.168.150.101:80032)Redis5.0以后
我们使用的是Redis6.2.4版本,集群管理以及集成到了redis-cli中,格式如下:
redis-cli --cluster create --cluster-replicas 1 192.168.150.101:7001 192.168.150.101:7002 192.168.150.101:7003 192.168.150.101:8001 192.168.150.101:8002 192.168.150.101:8003命令说明:
- `redis-cli --cluster`或者`./redis-trib.rb`:代表集群操作命令
- `create`:代表是创建集群
- `--replicas 1`或者`--cluster-replicas 1` :指定集群中每个master的副本个数为1,此时`节点总数 ÷ (replicas + 1)` 得到的就是master的数量。因此节点列表中的前n个就是master,其它节点都是slave节点,随机分配到不同master
运行后的样子:
这里输入yes,则集群开始创建:
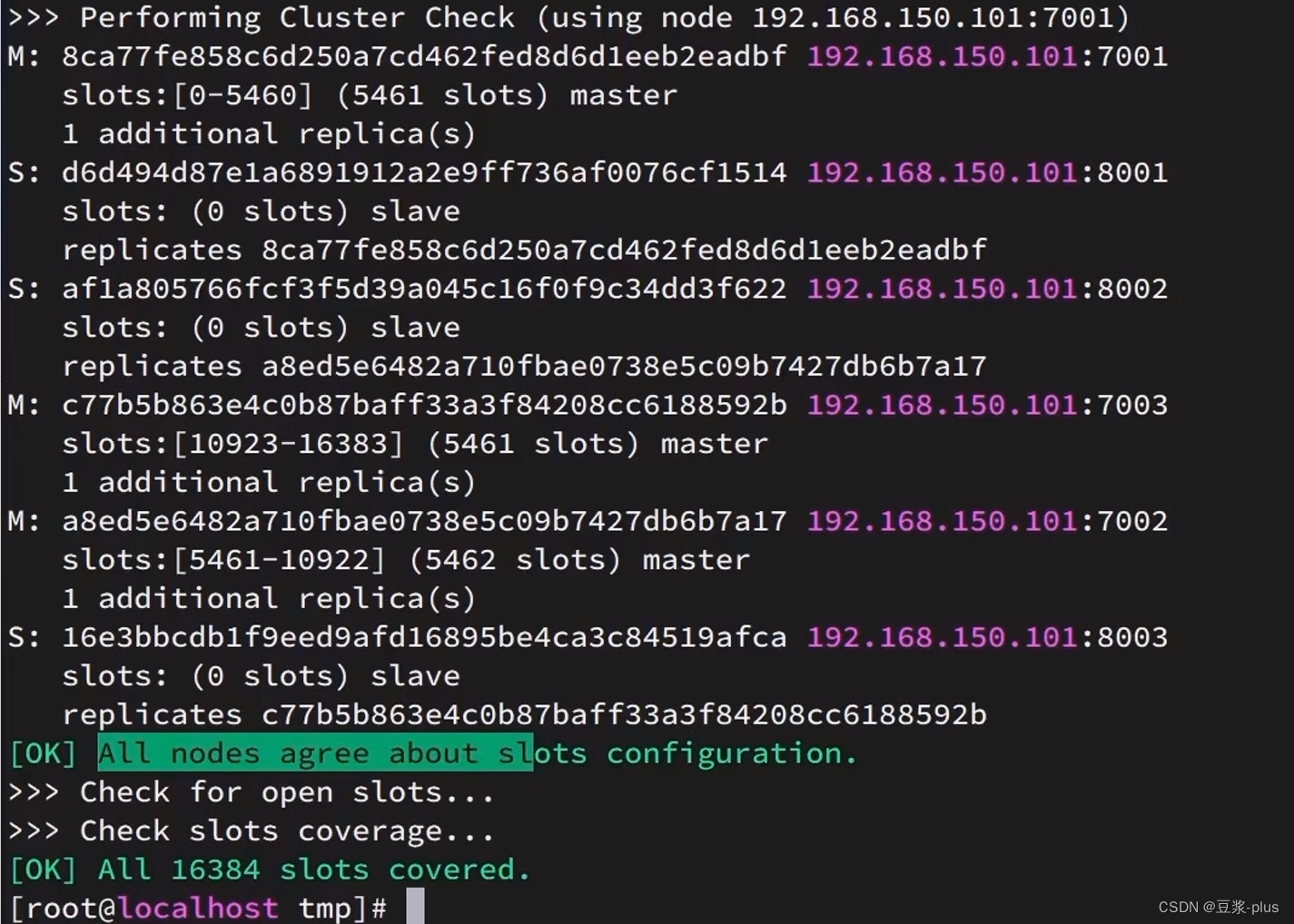
通过命令可以查看集群状态:
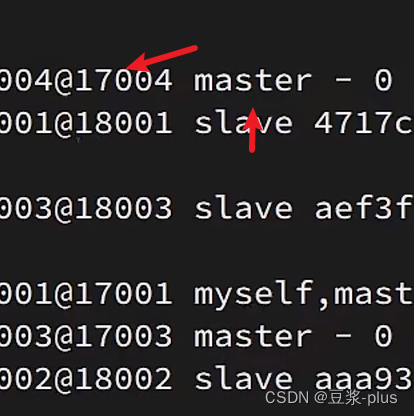
redis-cli -p 7001 cluster nodes
散列插槽:
## 5.4.5.测试
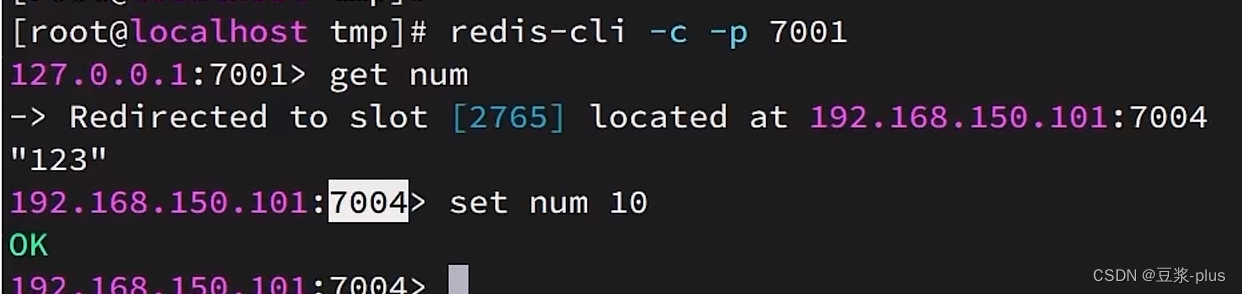
尝试连接7001节点,存储一个数据:
# 连接
集群操作时,需要给`redis-cli`加上`-c`参数才可以:
redis-cli -c -p 7001# 存储数据
set num 123# 读取数据
get num# 再次存储
set a 1这次可以了:
集群伸缩
这里需要两个新的功能:
- - 添加一个节点到集群中
- - 将部分插槽分配到新插槽
###1.创建新的redis实例
创建一个文件夹:
mkdir 7004拷贝配置文件:
cp redis.conf /7004修改配置文件:
sed -i /s/6379/7004/g 7004/redis.conf启动
redis-server 7004/redis.conf
### 2.添加新节点到redis
添加节点的语法如下:
执行命令:
redis-cli --cluster add-node 192.168.150.101:7004 192.168.150.101:7001通过命令查看集群状态:
redis-cli -p 7001 cluster nodes如图,7004加入了集群,并且默认是一个master节点:
但是,可以看到7004节点的插槽数量为0,因此没有任何数据可以存储到7004上
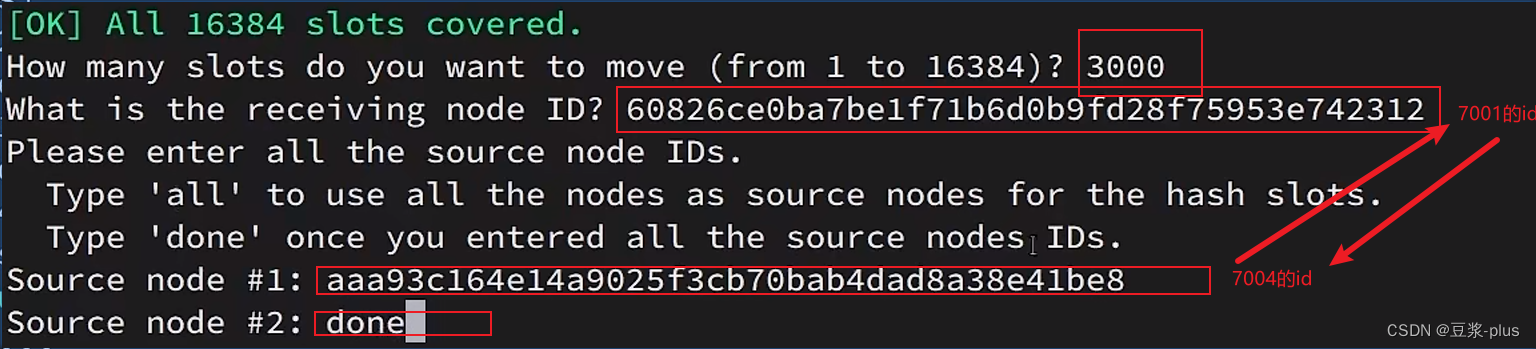
### 3.转移插槽
redis-cli --cluster reshard 192.168.200.129:7001可以将0~3000的插槽从7001转移到7004,命令格式如下:
确认要转移吗?输入yes:
yes
- all:代表全部,也就是三个节点各转移一部分
- 具体的id:目标节点的id
- done:没有了
然后,通过命令查看结果:
目的达成。
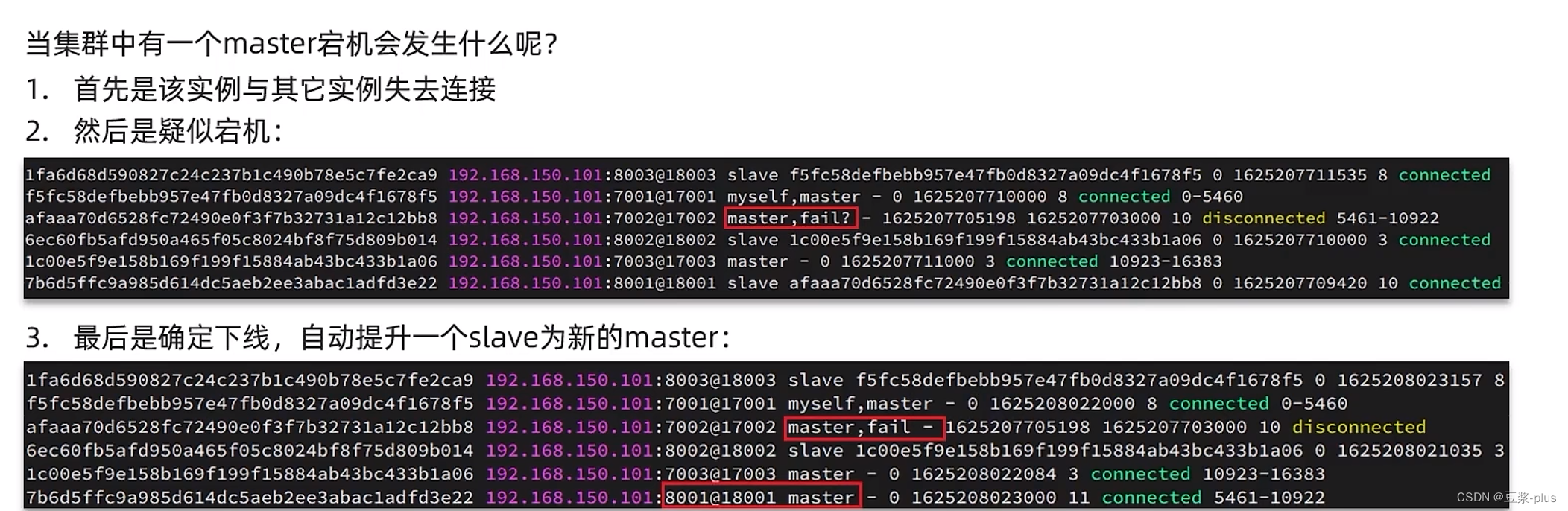
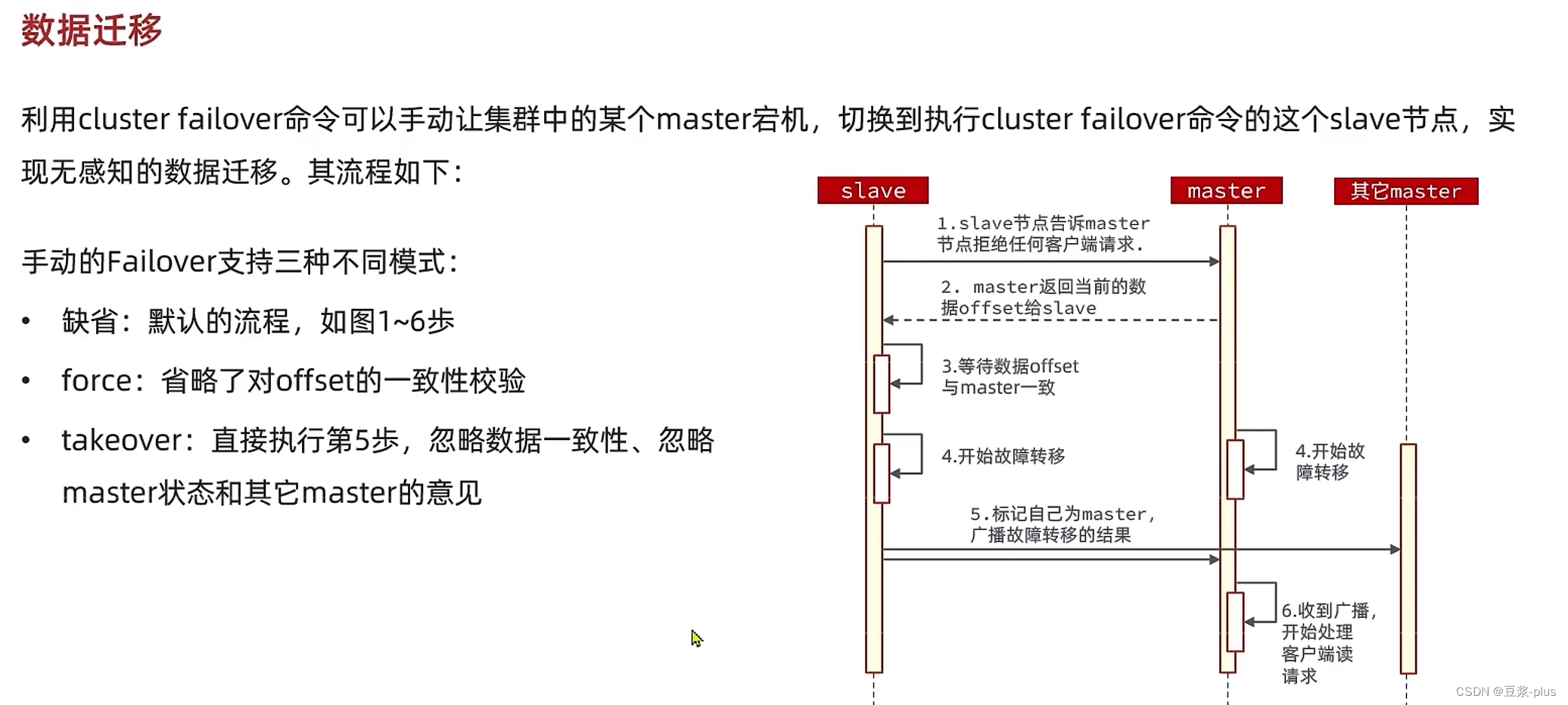
故障转移

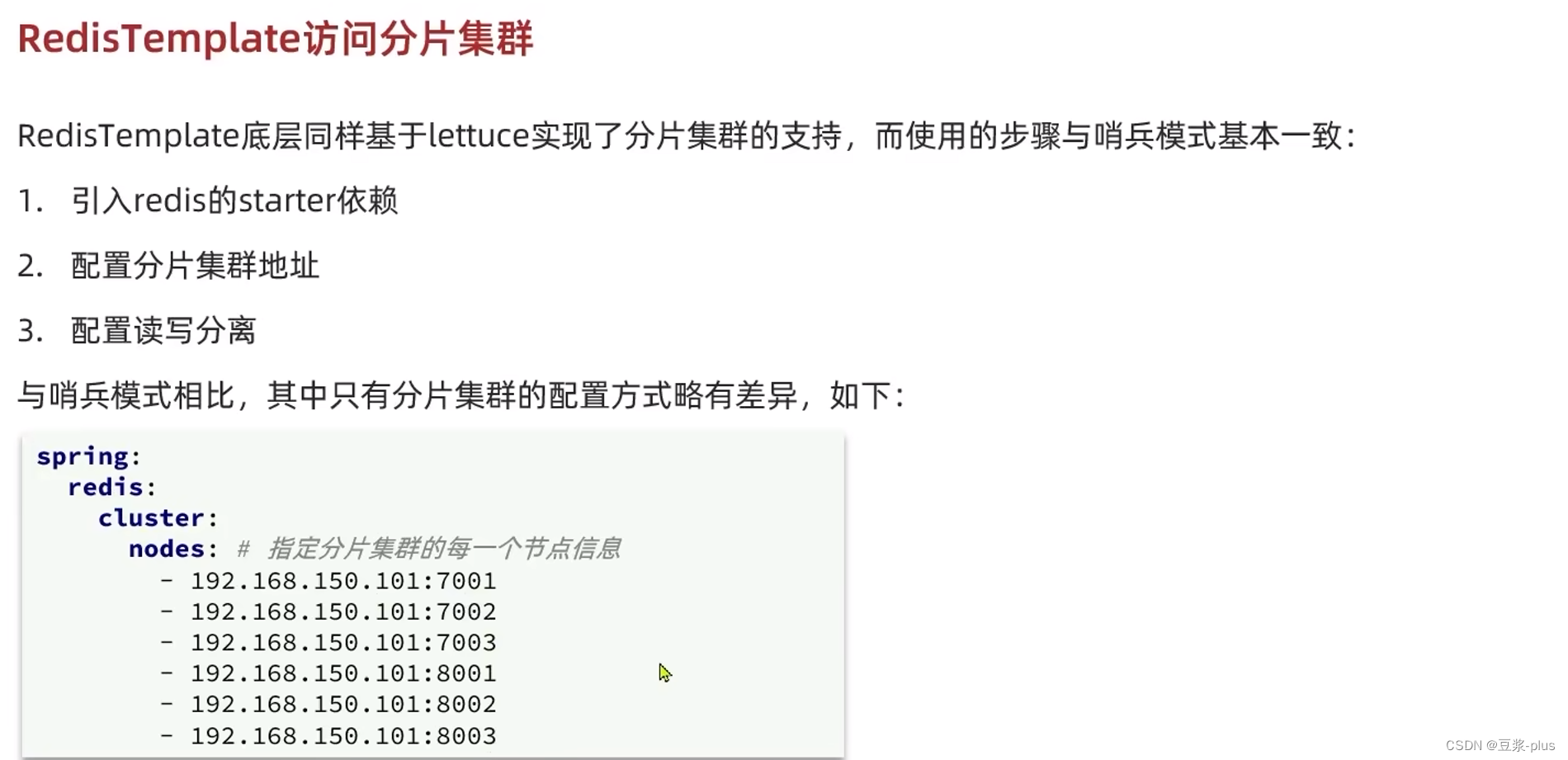
RedisTemplate访问分片集群






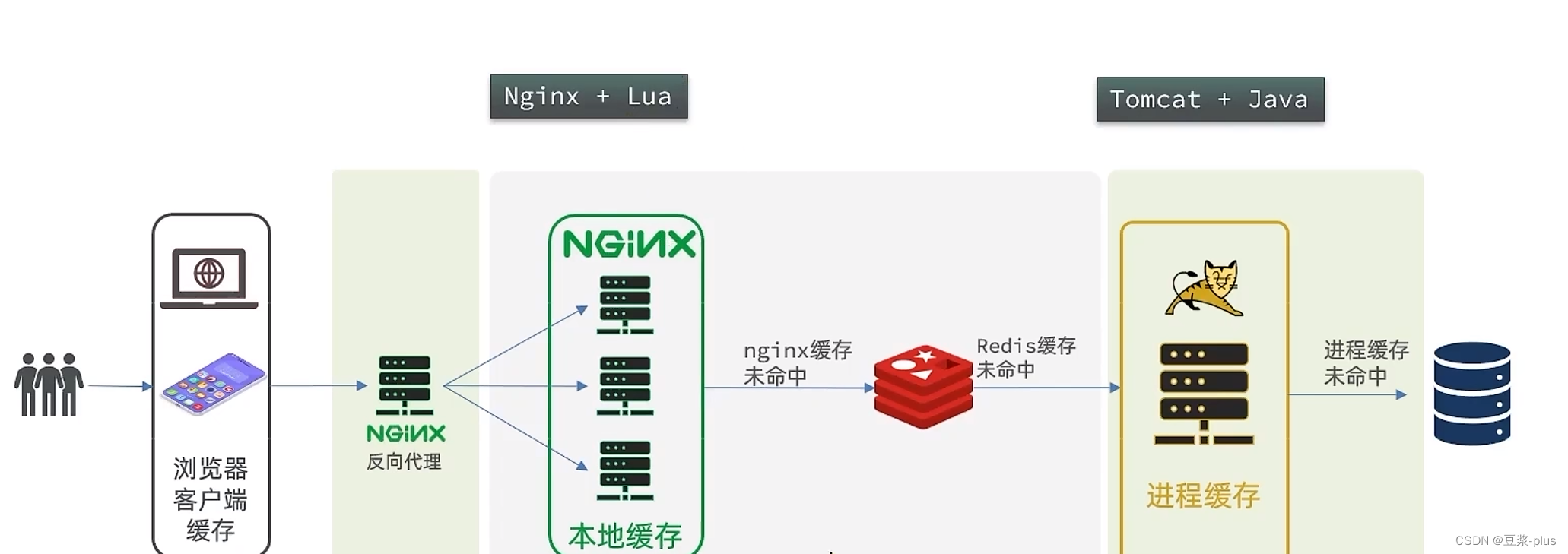
6.多级缓存
SpringCloud自学笔记 (yuque.com)
亿级流量的缓存方案
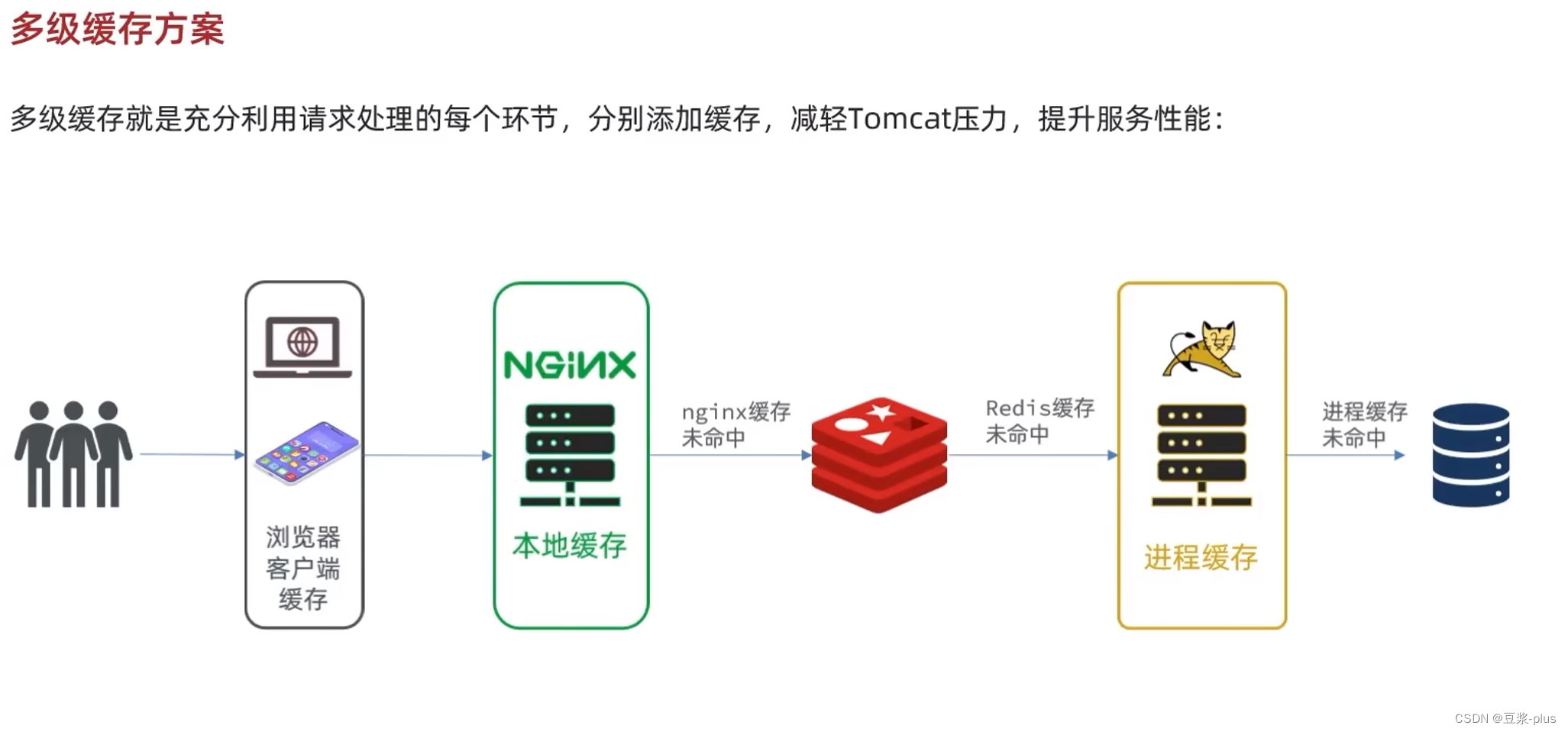
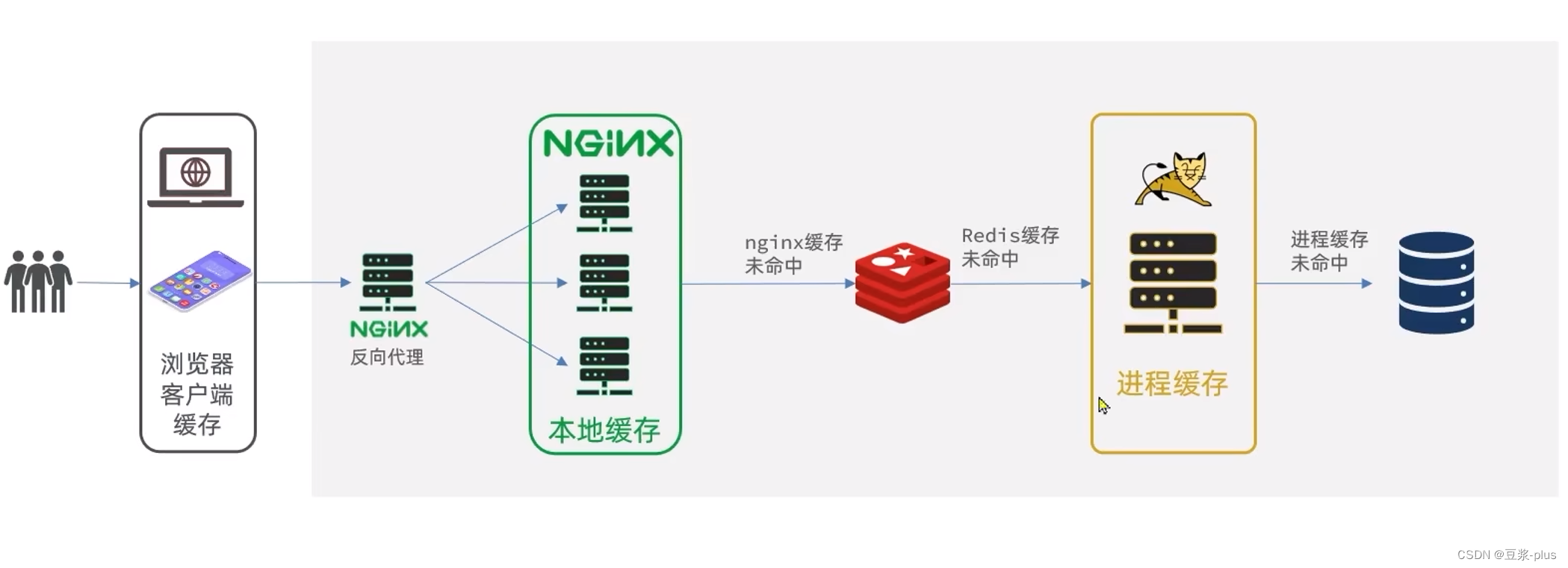
多级缓存就是充分利用请求处理的每个环节,分别添加缓存,减轻Tomcat压力,提升服务性能:
- - 浏览器访问静态资源时,优先读取浏览器本地缓存
- - 访问非静态资源(ajax查询数据)时,访问服务端
- - 请求到达Nginx后,优先读取Nginx本地缓存
- - 如果Nginx本地缓存未命中,则去直接查询Redis(不经过Tomcat)
- - 如果Redis查询未命中,则查询Tomcat
- - 请求进入Tomcat后,优先查询JVM进程缓存
- - 如果JVM进程缓存未命中,则查询数据库
可见,多级缓存的关键有两个:
- - 一个是在nginx中编写业务,实现nginx本地缓存、Redis、Tomcat的查询
- - 另一个就是在Tomcat中实现JVM进程缓存
其中Nginx编程则会用到OpenResty框架结合Lua这样的语言。
6.1JVM进程缓存
## 1.初识Caffeine
缓存在日常开发中启动至关重要的作用,由于是存储在内存中,数据的读取速度是非常快的,能大量减少对数据库的访问,减少数据库的压力。我们把缓存分为两类:
- 分布式缓存,例如Redis:
- - 优点:存储容量更大、可靠性更好、可以在集群间共享
- - 缺点:访问缓存有网络开销
- - 场景:缓存数据量较大、可靠性要求较高、需要在集群间共享
- 进程本地缓存,例如HashMap、GuavaCache:
- - 优点:读取本地内存,没有网络开销,速度更快
- - 缺点:存储容量有限、可靠性较低、无法共享
- - 场景:性能要求较高,缓存数据量较小
我们今天会利用Caffeine框架来实现JVM进程缓存。
**Caffeine**是一个基于Java8开发的,提供了近乎最佳命中率的高性能的本地缓存库。目前Spring内部的缓存使用的就是Caffeine。GitHub地址:https://github.com/ben-manes/caffeine
Caffeine的性能非常好
缓存使用的基本API:
@Test
void testBasicOps() {
// 构建cache对象
Cache<String, String> cache = Caffeine.newBuilder().build();
//key value
// 存数据
cache.put("gf", "迪丽热巴");
// 取数据
String gf = cache.getIfPresent("gf");
System.out.println("gf = " + gf);
// 取数据,包含两个参数:
// 参数一:缓存的key
// 参数二:Lambda表达式,表达式参数就是缓存的key,方法体是查询数据库的逻辑
// 优先根据key查询JVM缓存,如果未命中,则执行参数二的Lambda表达式
String defaultGF = cache.get("defaultGF", key -> {
// 根据key去数据库查询数据
return "柳岩";
});
System.out.println("defaultGF = " + defaultGF);
}Caffeine既然是缓存的一种,肯定需要有缓存的清除策略,不然的话内存总会有耗尽的时候。
Caffeine提供了三种缓存驱逐策略:
- **基于容量**:设置缓存的数量上限
// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder()
.maximumSize(1) // 设置缓存大小上限为 1
.build();- **基于时间**:设置缓存的有效时间
// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder()
// 设置缓存有效期为 10 秒,从最后一次写入开始计时
.expireAfterWrite(Duration.ofSeconds(10))
.build();- **基于引用**:设置缓存为软引用或弱引用,利用GC来回收缓存数据。性能较差,不建议使用。
> **注意**:在默认情况下,当一个缓存元素过期的时候,Caffeine不会自动立即将其清理和驱逐。而是在一次读或写操作后,或者在空闲时间完成对失效数据的驱逐。
##2.实现JVM进程缓存
### 2.1.需求
利用Caffeine实现下列需求:
- - 给根据id查询商品的业务添加缓存,缓存未命中时查询数据库
- - 给根据id查询商品库存的业务添加缓存,缓存未命中时查询数据库
- - 缓存初始大小为100
- - 缓存上限为10000
### 2.2.实现
首先,我们需要定义两个Caffeine的缓存对象,分别保存商品、库存的缓存数据。
在item-service的`com.xj.item.config`包下定义`CaffeineConfig`类:
```java
package com.xj.item.config;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.heima.item.pojo.Item;
import com.heima.item.pojo.ItemStock;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class CaffeineConfig {
@Bean
public Cache<Long, Item> itemCache(){
//id value
return Caffeine.newBuilder()
.initialCapacity(100)
.maximumSize(10_000)
.build();
}
@Bean
public Cache<Long, ItemStock> stockCache(){
//id value
return Caffeine.newBuilder()
.initialCapacity(100)
.maximumSize(10_000)
.build();
}
}然后,修改item-service中的`com.xj.item.web`包下的ItemController类,添加缓存逻辑:
```java
@RestController
@RequestMapping("item")
public class ItemController {
@Autowired
private IItemService itemService;
@Autowired
private IItemStockService stockService;
@Autowired
private Cache<Long, Item> itemCache;
@Autowired
private Cache<Long, ItemStock> stockCache;
// ...其它略
@GetMapping("/{id}")
public Item findById(@PathVariable("id") Long id) {
return itemCache.get(id, key -> itemService.query()
.ne("status", 3).eq("id", key)
.one()
);
}
@GetMapping("/stock/{id}")
public ItemStock findStockById(@PathVariable("id") Long id) {
return stockCache.get(id, key -> stockService.getById(key));
}
}
第二次查看无日志,进程本地缓存
6.2Lua语法入门
## 初识Lua
Lua 是一种轻量小巧的脚本语言,用标准C语言编写并以源代码形式开放, 其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。官网:https://www.lua.org/
Lua经常嵌入到C语言开发的程序中,例如游戏开发、游戏插件等。
Nginx本身也是C语言开发,因此也允许基于Lua做拓展
## HelloWorld
CentOS7默认已经安装了Lua语言环境,所以可以直接运行Lua代码。
1)在Linux虚拟机的任意目录下,新建一个hello.lua文件

2)添加下面的内容
print("Hello World!")
3)运行
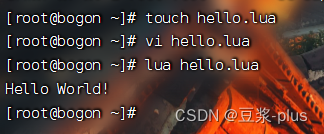
6.3 openResty
多级缓存的实现离不开Nginx编程,而Nginx编程又离不开OpenResty。
## 1.安装OpenResty
OpenResty® 是一个基于 Nginx的高性能 Web 平台,用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。具备下列特点:
- - 具备Nginx的完整功能
- - 基于Lua语言进行扩展,集成了大量精良的 Lua 库、第三方模块
- - 允许使用Lua**自定义业务逻辑**、**自定义库**
官方网站:https://openresty.org/cn/
location /api/item {
#默认的响应类型
default_type application/json;
#响应结果由Lua/item文件来决定
context_by_Lua_file Lua/item.Lua;
}
ngx.say('{"id":10001,"name":"SALSA ATR"}')
6.4 高级篇-多级缓存
缓存的作用: 减轻数据库的压力,缩短服务响应的时间,提高服务的并发能力。虽然Redis的并发效果已经很好了,但是依然有上限,随着互联网的发展,用户量越来越大,并发量非常庞大时,仅仅靠Redis不能满足庞大的并发需求,我们下面学习的多级缓存正式用来应对亿级流量的并发
注意本篇内容非常多,而且是同一个实验,所以最好是跟着从上到下,不要跳过
1. 多级缓存的意义
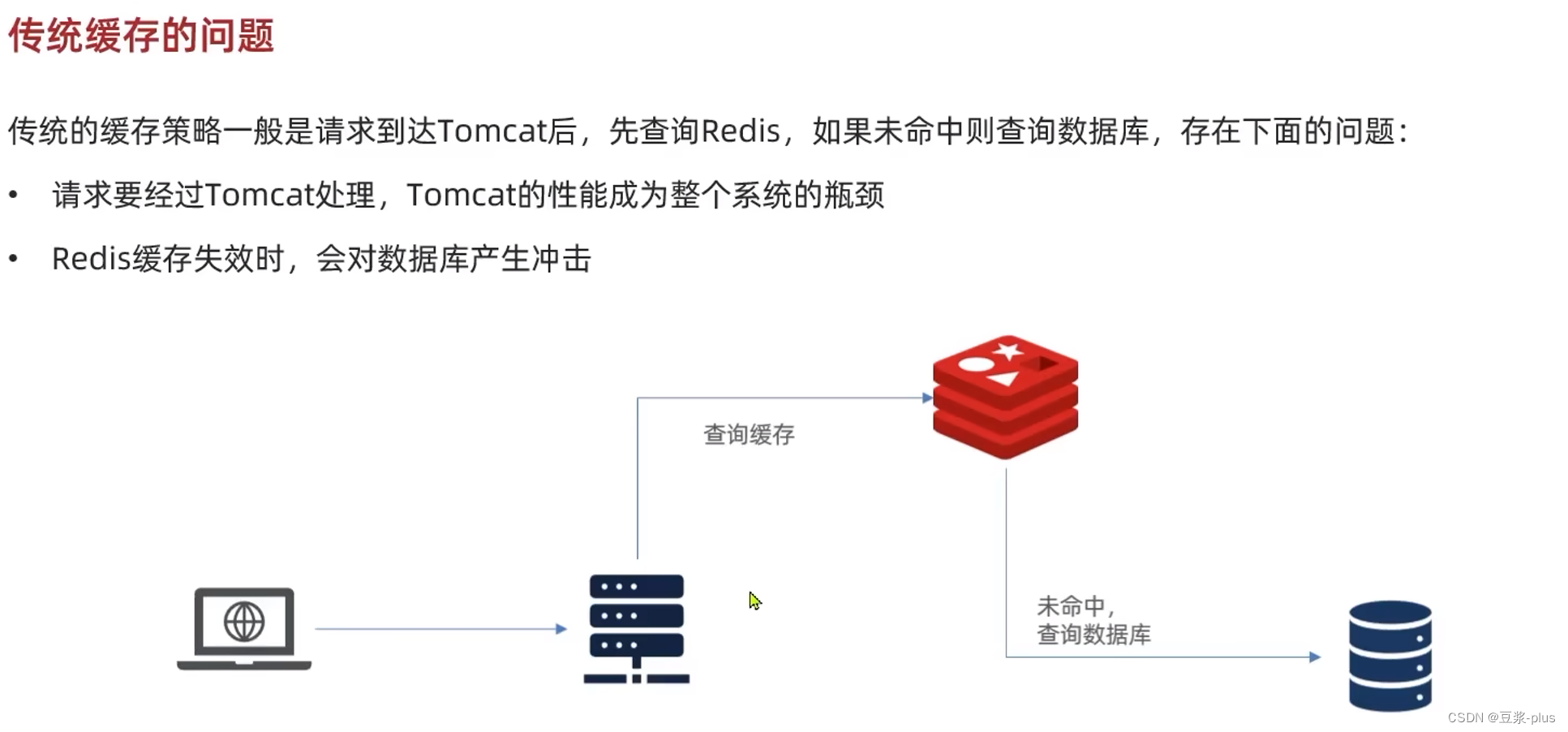
传统的缓存策略一般是请求到达Tomcat后,先查询Redis,如果未命中则查询数据库,存在下面的问题:
1、请求要经过Tomcat处理,Tomcat的并发能力其实是不如Redis,导致Tomcat的性能成为整个系统的瓶颈
2、Redis缓存失效时,会对数据库产生冲击

多级缓存就是充分利用请求处理的每个环节,分别添加缓存,减轻Tomcat压力,提升服务性能

在上图中,我们需要学习如何在Tomcat编写进程缓存,还需要学习如何在Nginx内部使用Lua语言进行编程,然后学习Nginx本地缓存、Redis缓存、Tomcat缓存等多级缓存,最后学习数据库与缓存之间的同步策略。下面会逐步学习
2. JVM进程缓存案例搭建
先学习 '如何在Tomcat编写进程缓存' ,也就是 JVM进程缓存,我们会通过一个案例进行学习
为了演示多级缓存,我们先导入一个商品管理的案例,其中包含商品的CRUD功能。我们将来会给查询商品添加多级缓存

【部署mysql容器,虽然前面在学习 '实用篇-Docker容器' 学过,但是为避免出现各种问题,下面还是需要再做一次】
删除之前做过的mysql容器
docker rm -f mysql # 删除在docker里面的mysql容器
rm -rf /tmp/mysql # 删除mysql的挂载数据
第一步: 创建三个目录,分别是/tmp/mysql/data、/tmp/mysql/conf,/tmp/mysql/logs
mkdir -p /tmp/mysql/{data,conf,logs}
cd /tmp/mysql && ls
第二步: 在docker部署mysql容器。由于MySQL文件较大,拉取耗时较长,所以下面提供了下载链接,下载到自己Windows电脑,
然后传到虚拟机/tmp/mysql目录
mysql.tar文件快速下载: https://cowtransfer.com/s/b047088bc7f048
第三步: 将mysql.tar文件,上传到虚拟机/tmp/mysql目录,再通过前面学的'镜像命令-导入镜像到docker',里面学过load命令
cd /tmp/mysql
docker load -i mysql.tar

第四步: 在/tmp/mysql/conf目录,创建一个文件叫hmy.cnf,写入如下
cd /tmp/mysql/conf
touch hmy.cnf
vi hmy.cnf[mysqld]
skip-name-resolve
character_set_server=utf8
datadir=/var/lib/mysql
server-id=1000
第五步: 到此准备工作已结束,正式开始挂载。在Docker大容器(也叫Docker主机、宿主机)使用MySQL镜像来创建并运行MySQL容器
cd /tmp/mysql
下面命令全部复制执行,注意密码为123
docker run \
-p 3306:3306 \
--name mysql \
-v $PWD/conf:/etc/mysql/conf.d \
-v $PWD/logs:/logs \
-v $PWD/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123 \
--privileged \
-d \
mysql:5.7.25
# docker run: 创建并运行容器
# --name: 给容器起一个名字,例如叫mysql
# -e: MySQL登录密码
# -p: 端口号
# -v: [挂载宿主机的配置文件]:[mysql容器的配置文件]
# -v: [挂载宿主机的用于存放数据的文件]:[mysql容器的用于存放数据的文件]
# -d: 后台运行容器
# mysql:5.7.25: 镜像名称,由于我们的mysql镜像是这个版本,所以镜像名称需要带上镜像版本号
第六步: 去连接一下这个mysql容器里面的mysql服务,查看连接是否正常


第七步: 下次运行这个mysql容器,只要执行如下即可
systemctl start docker # 启动docker服务
docker restart mysql #启动mysql容器
第八步: 在mysql数据库创建名为JvmDataShop的库,并在JvmDataShop库执行创建tb_item商品表、tb_item_stock商品库存表的SQL语句
create database if not exists JvmDataShop;
use JvmDataShop;
CREATE TABLE `tb_item` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '商品id',
`title` varchar(264) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '商品标题',
`name` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT '' COMMENT '商品名称',
`price` bigint(20) NOT NULL COMMENT '价格(分)',
`image` varchar(200) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '商品图片',
`category` varchar(200) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '类目名称',
`brand` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '品牌名称',
`spec` varchar(200) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '规格',
`status` int(1) NULL DEFAULT 1 COMMENT '商品状态 1-正常,2-下架,3-删除',
`create_time` datetime NULL DEFAULT NULL COMMENT '创建时间',
`update_time` datetime NULL DEFAULT NULL COMMENT '更新时间',
PRIMARY KEY (`id`) USING BTREE,
INDEX `status`(`status`) USING BTREE,
INDEX `updated`(`update_time`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 50002 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '商品表' ROW_FORMAT = COMPACT;
INSERT INTO `tb_item` VALUES (10001, 'RIMOWA 21寸托运箱拉杆箱 SALSA AIR系列果绿色 820.70.36.4', 'SALSA AIR', 16900, 'https://m.360buyimg.com/mobilecms/s720x720_jfs/t6934/364/1195375010/84676/e9f2c55f/597ece38N0ddcbc77.jpg!q70.jpg.webp', '拉杆箱', 'RIMOWA', '{\"颜色\": \"红色\", \"尺码\": \"26寸\"}', 1, '2019-05-01 00:00:00', '2019-05-01 00:00:00');
INSERT INTO `tb_item` VALUES (10002, '安佳脱脂牛奶 新西兰进口轻欣脱脂250ml*24整箱装*2', '脱脂牛奶', 68600, 'https://m.360buyimg.com/mobilecms/s720x720_jfs/t25552/261/1180671662/383855/33da8faa/5b8cf792Neda8550c.jpg!q70.jpg.webp', '牛奶', '安佳', '{\"数量\": 24}', 1, '2019-05-01 00:00:00', '2019-05-01 00:00:00');
INSERT INTO `tb_item` VALUES (10003, '唐狮新品牛仔裤女学生韩版宽松裤子 A款/中牛仔蓝(无绒款) 26', '韩版牛仔裤', 84600, 'https://m.360buyimg.com/mobilecms/s720x720_jfs/t26989/116/124520860/644643/173643ea/5b860864N6bfd95db.jpg!q70.jpg.webp', '牛仔裤', '唐狮', '{\"颜色\": \"蓝色\", \"尺码\": \"26\"}', 1, '2019-05-01 00:00:00', '2019-05-01 00:00:00');
INSERT INTO `tb_item` VALUES (10004, '森马(senma)休闲鞋女2019春季新款韩版系带板鞋学生百搭平底女鞋 黄色 36', '休闲板鞋', 10400, 'https://m.360buyimg.com/mobilecms/s720x720_jfs/t1/29976/8/2947/65074/5c22dad6Ef54f0505/0b5fe8c5d9bf6c47.jpg!q70.jpg.webp', '休闲鞋', '森马', '{\"颜色\": \"白色\", \"尺码\": \"36\"}', 1, '2019-05-01 00:00:00', '2019-05-01 00:00:00');
INSERT INTO `tb_item` VALUES (10005, '花王(Merries)拉拉裤 M58片 中号尿不湿(6-11kg)(日本原装进口)', '拉拉裤', 38900, 'https://m.360buyimg.com/mobilecms/s720x720_jfs/t24370/119/1282321183/267273/b4be9a80/5b595759N7d92f931.jpg!q70.jpg.webp', '拉拉裤', '花王', '{\"型号\": \"XL\"}', 1, '2019-05-01 00:00:00', '2019-05-01 00:00:00');
CREATE TABLE `tb_item_stock` (
`item_id` bigint(20) NOT NULL COMMENT '商品id,关联tb_item表',
`stock` int(10) NOT NULL DEFAULT 9999 COMMENT '商品库存',
`sold` int(10) NOT NULL DEFAULT 0 COMMENT '商品销量',
PRIMARY KEY (`item_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = COMPACT;
INSERT INTO `tb_item_stock` VALUES (10001, 99996, 3219);
INSERT INTO `tb_item_stock` VALUES (10002, 99999, 54981);
INSERT INTO `tb_item_stock` VALUES (10003, 99999, 189);
INSERT INTO `tb_item_stock` VALUES (10004, 99999, 974);
INSERT INTO `tb_item_stock` VALUES (10005, 99999, 18649);
第九步: 下载item-service.zip,解压后是item-service文件夹,是一个项目工程,用idea打开,并且修改application.yml的数据库连接信息
https://cowtransfer.com/s/353ec9dc3dd54d
第十步: 运行ItemApplication引导类
访问主页: http://localhost:8081
访问商品: http://localhost:8081/item/10001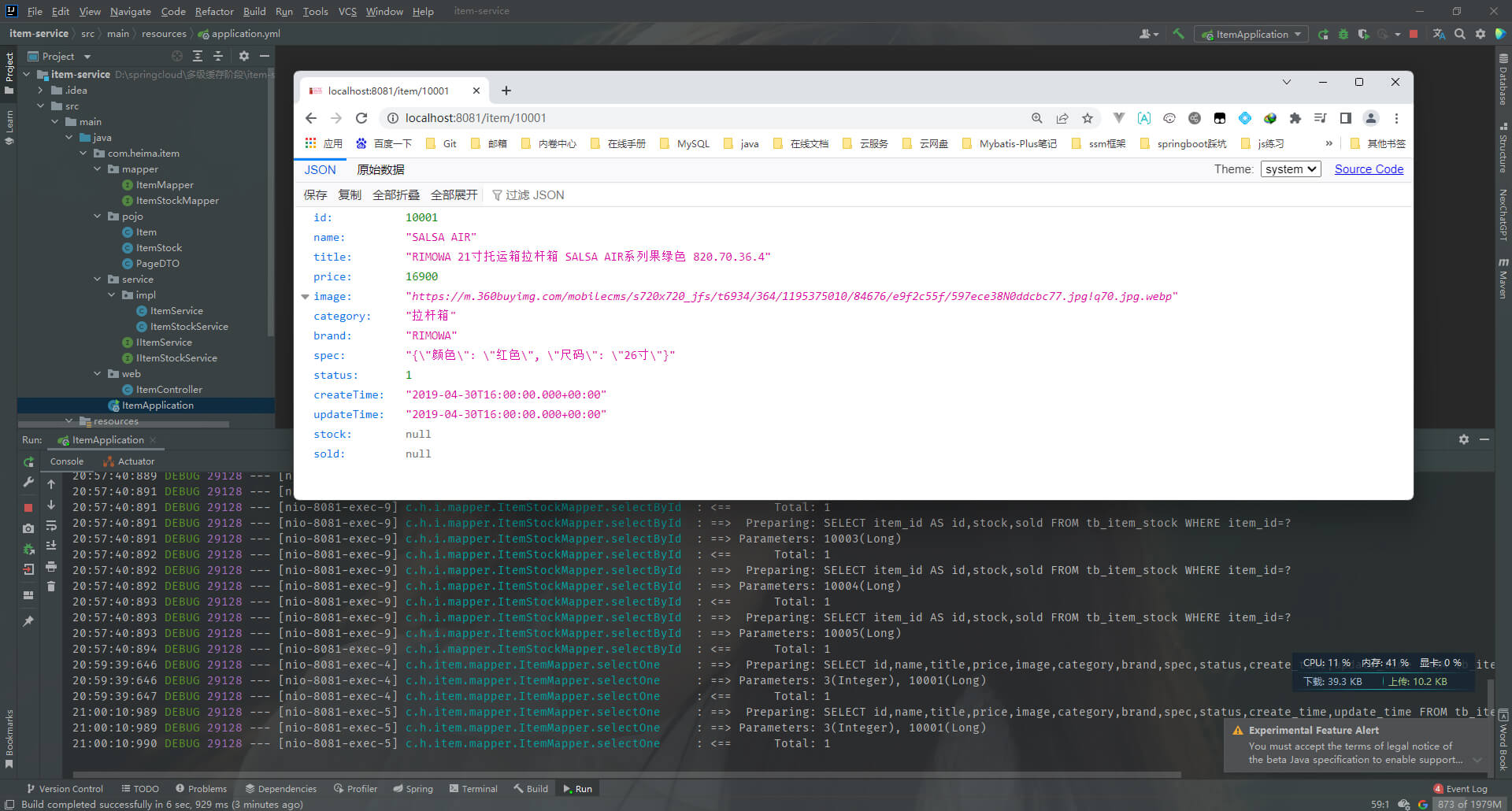
访问商品库存: http://localhost:8081/item/stock/10001
第十一步: 部署Nginx反向代理服务。
我们希望在查询接口增加缓存业务。设计如下。把item.html页面放在Nginx反向代理服务器,用户请求商品页面时,就把这个item.html页面返回给用户

(1) 下载nginx-1.18.0.zip,下载后解压到D盘,下载链接如下
https://cowtransfer.com/s/9d4e834d28e345

(2) 修改nginx.conf文件

(3) win+r,输入cmd并回车,然后输入下面的命令启动Nginx
d:
cd nginx-1.18.0
start nginx.exe
(3)浏览器访问Nginx
localhost
(4) 浏览器访问Nginx的item.html页面。目前这个页面的数据是写死的假数据,后续我们会使用缓存向服务器查询数据,然后把请求到的数据渲染到页面
http://localhost/item.html?id=10001
3. JVM进程缓存案例实现
上面我们已经部署了必要的环境,请确保你的环境正常启动,然后我们就开始业务需求的实现
(1) 启动mysql
systemctl start docker # 启动docker服务
docker restart mysql #启动mysql容器
(2) 启动Nginx
d:
cd nginx-1.18.0
start nginx.exe
我们下面会使用Caffeine来实现 JVM进程缓存案例
一、初始Caffeine
Caffeine是一个缓存技术相关的库,读 kě fì,翻译过来就是咖啡因
【本地进程缓存】
缓存在日常开发中启动至关重要的作用,由于是存储在内存中,数据的读取速度是非常快的,能大量减少对数据库的访问,减少数据库的压力
我们把缓存分为如下两类
1、分布式(往往用在集群的环境下)缓存,例如Redis
●优点:存储容量更大、可靠性更好、可以在集群间共享
●缺点:访问缓存有网络开销
●场景:缓存数据量较大、可靠性要求较高、需要在集群间共享
2、进程本地缓存,例如HashMap、GuavaCache
●优点:读取本地内存,没有网络开销,速度更快
●缺点:存储容量有限、可靠性较低、无法共享
●场景:性能要求较高,缓存数据量较小
Caffeine是一个基于Java8开发的,提供了近乎最佳命中率的高性能的本地缓存库。目前Spring内部的缓存使用的就是Caffeine
GitHub地址:GitHub - ben-manes/caffeine: A high performance caching library for Java
Caffeine提供了三种缓存驱逐策略,也就是缓存过期策略:
1、基于容量:设置缓存的数量上限
// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder()
.maximumSize(1) // 设置缓存大小上限为 1
.build();
2、基于时间:设置缓存的有效时间
// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder()
.expireAfterWrite(Duration.ofSeconds(10)) // 设置缓存有效期为 10 秒,从最后一次写入开始计时
.build();
3、基于引用:设置缓存为软引用或弱引用,利用GC来回收缓存数据。性能较差,不建议使用
在默认情况下,当一个缓存元素过期的时候,Caffeine不会自动立即将其清理和驱逐。而是在一次读或写操作后,或者在空闲时间完成对失效数据的驱逐
二、Caffeine基本演示
用idea打开item-service项目,在item-service项目进行Caffeine基本API的使用
第一步(已做可跳过): 在item-service项目的pom.xml添加如下
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
</dependency>
第二步(已做可跳过): 打开CaffeineTest类,写入如下
package com.heima.item.test;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import org.junit.jupiter.api.Test;
import java.time.Duration;
public class CaffeineTest {
/*
基本用法测试
*/
@Test
void testBasicOps() {
// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder().build();
// 存数据
cache.put("gf", "迪丽热巴");
// 取数据,不存在则返回null
String gf = cache.getIfPresent("gf");
System.out.println("gf = " + gf);
// 取数据,不存在则去数据库查询
String defaultGF = cache.get("defaultGF", key -> {
// 这里可以去数据库根据 key查询value
return "柳岩";
});
System.out.println("defaultGF = " + defaultGF);
}
/*
基于大小设置驱逐策略:
*/
@Test
void testEvictByNum() throws InterruptedException {
// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder()
// 设置缓存大小上限为 1
.maximumSize(1)
.build();
// 存数据
cache.put("gf1", "柳岩");
cache.put("gf2", "范冰冰");
cache.put("gf3", "迪丽热巴");
// 延迟10ms,给清理线程一点时间
Thread.sleep(10L);
// 获取数据
System.out.println("gf1: " + cache.getIfPresent("gf1"));
System.out.println("gf2: " + cache.getIfPresent("gf2"));
System.out.println("gf3: " + cache.getIfPresent("gf3"));
}
/*
基于时间设置驱逐策略:
*/
@Test
void testEvictByTime() throws InterruptedException {
// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder()
.expireAfterWrite(Duration.ofSeconds(3)) // 设置缓存有效期为 3 秒
.build();
// 存数据
cache.put("gf", "柳岩");
// 获取数据
System.out.println("gf: " + cache.getIfPresent("gf"));
// 休眠一会儿
Thread.sleep(1200L);
System.out.println("gf: " + cache.getIfPresent("gf"));
}
}
第三步: 运行CaffeineTest类的testBasicOps方法,测试在缓存中存取数据的基本用法

第四步: 运行CaffeineTest类的testEvictByNum方法,测试给缓存设置一个过期策略,例如当缓存缓存上限超过1,那么旧缓存就会被清理

第五步: 运行CaffeineTest类的testEvictByTime方法,测试给缓存设置一个过期策略,例如当缓存缓存时间超过3秒,那么旧缓存就会被清理

三、Caffeine实现进程缓存
案例: 实现商品的查询的本地进程缓存,利用Caffeine实现下列需求
1、给根据id查询商品的业务添加缓存,缓存未命中时查询数据库
2、给根据id查询商品库存的业务添加缓存,缓存未命中时查询数据库
3、缓存初始大小为100
4、缓存上限为10000
具体操作如下
第一步(已做可跳过): 在item-service项目的pom.xml添加如下
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
</dependency>
第二步: 在item-service项目的com.heima.item目录新建config.CaffeineConfig类,写入如下
package com.heima.item.config;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.heima.item.pojo.Item;
import com.heima.item.pojo.ItemStock;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class CaffeineConfig {
@Bean
//下面的Cache接口是caffeine提供的
public Cache<Long, Item> itemCache(){
return Caffeine.newBuilder()
//缓存初始大小为100
.initialCapacity(100)
//缓存上限为10000,写成10_000会被自动处理成10000
.maximumSize(10_000)
.build();
}
@Bean
//下面的Cache接口是caffeine提供的
public Cache<Long, ItemStock> stockCache(){
return Caffeine.newBuilder()
//缓存初始大小为100
.initialCapacity(100)
//缓存上限为10000,写成10_000会被自动处理成10000
.maximumSize(10_000)
.build();
}
}
第三步: 查看ItemController类,分析一下我们要给什么请求加缓存

第四步: 在ItemController类添加如下。也就是引入依赖,修改findById、findStockById方法
//注入bean,用来做商品缓存
@Autowired
private Cache<Long,Item> itemCache;
//注入bean,用来做库存缓存
@Autowired
private Cache<Long,ItemStock> stockCache;
@GetMapping("/{id}")
public Item findById(@PathVariable("id") Long id){
//给这个请求添加缓存功能。使用get,实现自动查缓存,缓存没查到查数据库
//get的第一个参数是根据id优先查缓存,第二个参数是如果缓存没查到就根据Lambda表达式来查数据库
return itemCache.get(id,key -> itemService.query()
.ne("status", 3).eq("id", key)
.one());
}
@GetMapping("/stock/{id}")
public ItemStock findStockById(@PathVariable("id") Long id){
//给这个请求添加缓存功能。使用get,实现自动查缓存,缓存没查到查数据库
//get的第一个参数是根据id优先查缓存,第二个参数是如果缓存没查到就根据Lambda表达式来查数据库
return stockCache.get(id,key -> stockService.getById(key));
}
第五步: 重新运行ItemApplication引导类,浏览器测试商品功能
http://localhost:8081/item/10001

第六步: 重新运行ItemApplication引导类,浏览器测试库存功能
http://localhost:8081/item/stock/10001

4. Lua语法
Lua 是一种轻量小巧的脚本语言,用标准C语言编写并以源代码形式开放, 其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能
官网:https://www.lua.org/。Lua读 lū ǎ

一、安装Lua
第一步: 打开官网

第二步: 在linux终端输入如下。注意CentOS自带Lua环境

curl -R -O http://www.lua.org/ftp/lua-5.4.6.tar.gz
tar zxf lua-5.4.6.tar.gz
cd lua-5.4.6
make all test
二、初识Lua
第一步: 在Linux虚拟机的/root目录下,新建LuaDemo目录,里面新建一个hello.lua文件
cd /root
mkdir LuaDemo
cd LuaDemo && touch hello.lua
vi hello.lua
第二步: 在hello.lua文件里面写入如下
print("Hello World")
第三步: 运行hello.lua文件
cd /root/LuaDemo
lua hello.lua
三、变量和循环
【数据类型】
| 数据类型 | 描述 |
| nil | 这个最简单,只有值nil属于该类,表示一个无效值(在条件表达式中相当于false) |
| boolean | 包含两个值:false和true |
| number | 表示双精度类型的实浮点数 |
| string | 字符串由一对双引号或单引号来表示 |
| function | 由 C 或 Lua 编写的函数 |
| table | Lua 中的表(table)其实是一个"关联数组"(associative arrays),数组的索引可以是数字、字符串或表类型。在 Lua 里,table 的创建是通过"构造表达式"来完成,最简单构造表达式是{},用来创建一个空表 |
可以利用type函数测试给定变量或者值的类型:

【变量】
Lua声明变量的时候,并不需要指定数据类型,也可以去掉local表示全局:
-- 声明字符串
local str = 'hello'
-- 拼接字符串
local str2 = 'hello' .. 'world'
-- 声明数字
local num = 21
-- 声明布尔类型
local flag = true
-- 声明数组 key为索引的 table
local arr = {'java', 'python', 'lua'}
-- 声明table,类似java的map
local map = {name='Jack', age=21}
访问table:
-- 访问数组,lua数组的角标从1开始
print(arr[1])
-- 访问table
print(map['name'])
print(map.name)
【循环】
用ipairs遍历数组:
-- 声明数组 key为索引的 table
local arr = {'java', 'python', 'lua'}
-- 遍历数组
for index,value in ipairs(arr) do
print(index, value)
end
用pairs遍历table:
-- 声明map,也就是table
local map = {name='Jack', age=21}
-- 遍历table
for key,value in pairs(map) do
print(key, value)
end
四、条件控制、函数
【函数】
定义函数的语法:
function 函数名( argument1, argument2..., argumentn)
-- 函数体
return 返回值
end
例如,定义一个函数,用来打印数组:
function printArr(arr)
for index, value in ipairs(arr) do
print(value)
end
end【条件控制】
类似Java的条件控制,例如if、else语法:
if(布尔表达式)
then
--[ 布尔表达式为 true 时执行该语句块 --]
else
--[ 布尔表达式为 false 时执行该语句块 --]
end
与java不同,布尔表达式中的逻辑运算是基于英文单词:
| 操作符 | 描述 | 示例 |
| and | 逻辑与操作符。 若 A 为 false,则返回 A,否则返回 B | (A and B) 为 false |
| or | 逻辑或操作符。 若 A 为 true,则返回 A,否则返回 B | (A or B) 为 true |
| not | 逻辑非操作符。与逻辑运算结果相反,如果条件为 true,逻辑非为 false | not(A and B) 为 true |
案例: 自定义一个函数,可以打印table,当参数为nil时,打印错误信息。具体操作如下
第一步: 在/root/LuaDemo目录新建FunctionDemo.lua文件,写入如下
cd /root/LuaDemo
touch FunctionDemo.lua
vi FunctionDemo.lualocal function printXxx(arr)
if (not arr) then
print('数组不能为空!')
return nil
end
for i, val in ipairs(arr) do
print(val)
end
end
local arr1 = {100,200,300}
printXxx(arr1)
printXxx(nil)

5. 多级缓存的最终实现
一、安装OpenResty
OpenResty是一个基于 Nginx的高性能 Web 平台,用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。具备下列特点:
1、具备Nginx的完整功能
2、基于Lua语言进行扩展,集成了大量精良的 Lua 库、第三方模块
3、允许使用Lua自定义业务逻辑、自定义库
官方网站: https://openresty.org/cn/。在下面的操作中,你完全可以把OpenResty认为是Nginx,并且OpenResty是基于Nginx实现的
第一步: 首先要安装OpenResty的依赖开发库,执行命令:
yum install -y pcre-devel openssl-devel gcc --skip-broken
第二步: 安装OpenResty仓库。在你的 CentOS 系统中添加 openresty 仓库,这样就可以便于未来安装或更新软件包
yum-config-manager --add-repo https://openresty.org/package/centos/openresty.repo
如果提示说命令不存在,则先运行:
yum install -y yum-utils
第三步: 安装OpenResty软件包
yum install -y openrestycd /usr/local/openresty
ll
或者直接执行下面那条命令
ll /usr/local/openresty
第四步: 安装opm工具。opm是OpenResty的一个管理工具,可以帮助我们安装一个第三方的Lua模块
yum install -y openresty-opm
第五步: 目录结构。默认情况下,OpenResty安装的目录是:/usr/local/openresty
注意其中的nginx目录,OpenResty就是在Nginx基础上集成了一些Lua模块
cd /usr/local/openresty
ll
或者直接执行下面那条命令
ll /usr/local/openresty
第七步: 配置nginx的环境变量,以后就能在任意目录启动和运行
打开配置文件:
vi /etc/profile
在最下面加入两行:
export NGINX_HOME=/usr/local/openresty/nginx
export PATH=${NGINX_HOME}/sbin:$PATH
NGINX_HOME:后面是OpenResty安装目录下的nginx的目录
然后让配置生效:
source /etc/profile
第八步: nginx的默认配置文件注释太多,影响后续我们的编辑,这里将nginx.conf中的注释部分删除,保留有效部分。
修改 /usr/local/openresty/nginx/conf/nginx.conf 文件,内容如下:
#user nobody;
worker_processes 1;
error_log logs/error.log;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen 8081;
server_name localhost;
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}第九步: 启动和运行。由于OpenResty底层是基于Nginx的,查看OpenResty目录的nginx目录,结构与windows中安装的nginx基本一致
所以运行方式与nginx基本一致:
# 启动nginx,就是启动OpenResty
nginx
# 重新加载配置
nginx -s reload
# 停止
nginx -s stop
# 查看nginx运行状态
ps -ef | grep nginx第十步: 然后访问页面:http://192.168.127.180:8081,注意ip地址替换为你自己的虚拟机IP:

二、OpenResty快速入门
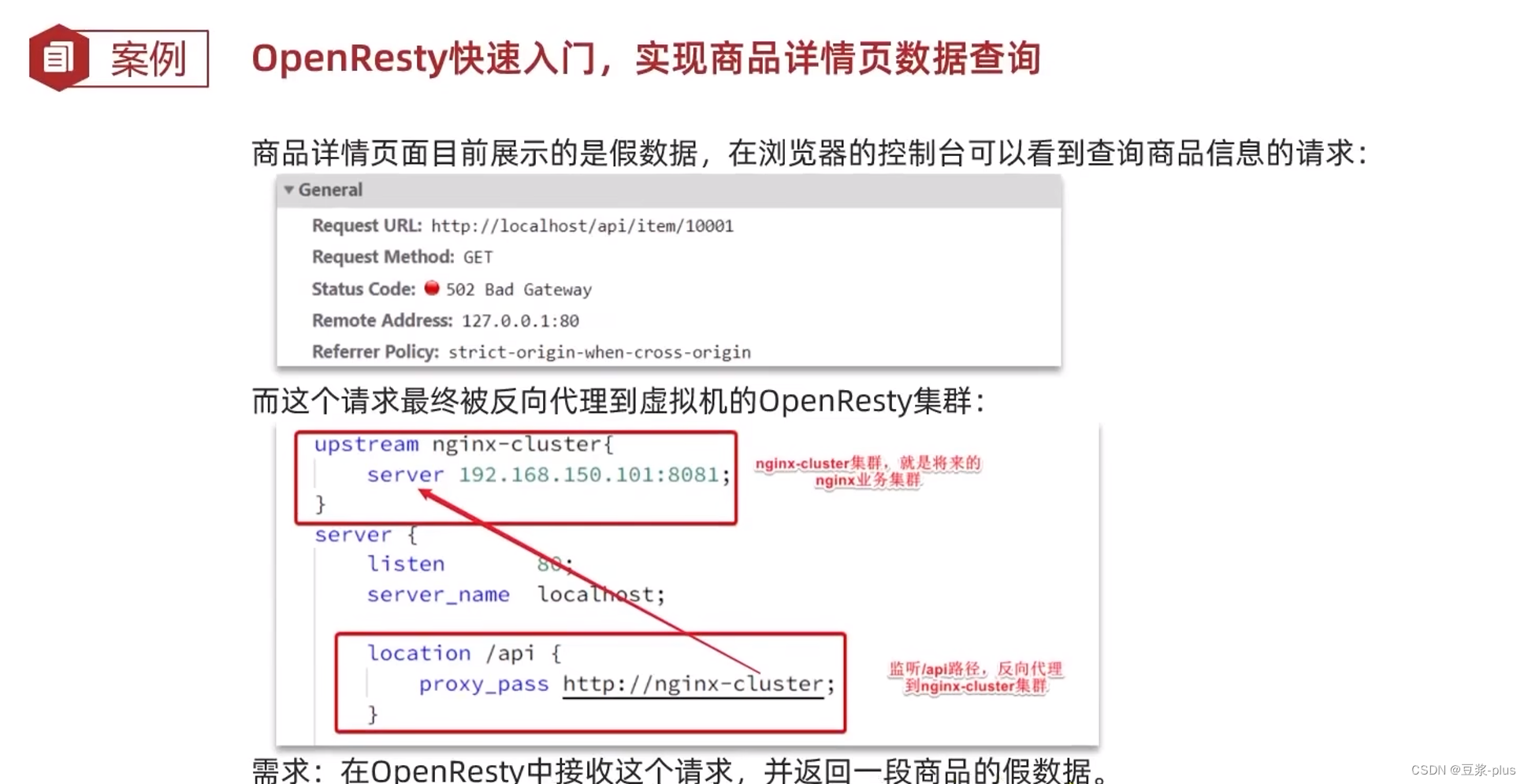
商品详情页面目前展示的是假数据,在浏览器的控制台可以看到查询商品信息的请求:

而这个请求最终被反向代理到虚拟机的OpenResty集群:

需求:实现商品详情页数据查询。在OpenResty中接收这个请求,并返回一段商品的假数据
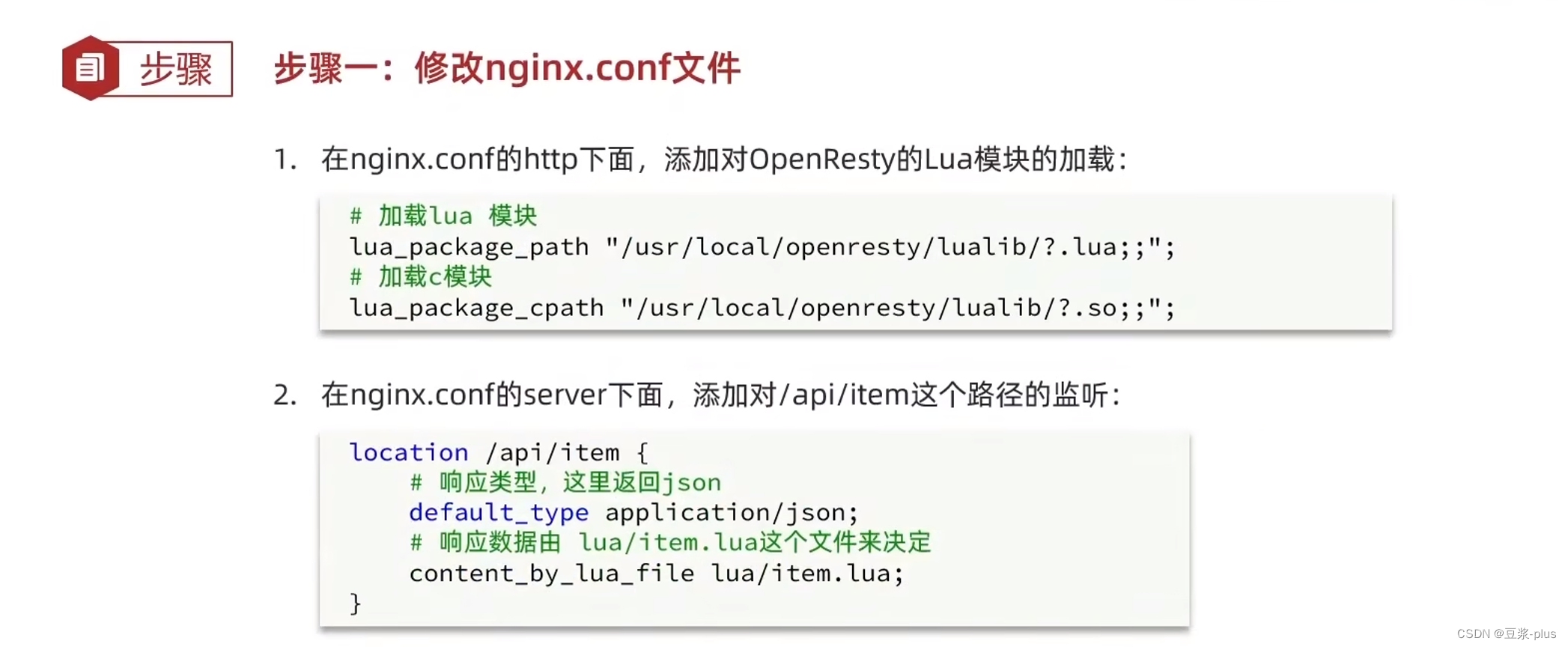
第一步: 在nginx.conf的http下面,添加对OpenResty的Lua模块的加载
vi /usr/local/openresty/nginx/conf/nginx.conf# 加载lua模块
lua_package_path "/usr/local/openresty/lualib/?.lua;;";
# 加载c模块
lua_package_cpath "/usr/local/openresty/lualib/?.so;;";
第二步: 在nginx.conf的server下面,添加对/api/item这个路径的监听
vi /usr/local/openresty/nginx/conf/nginx.conflocation /api/item {
# 响应类型,这里返回json
default_type application/json;
# 响应数据由 lua/item.lua这个文件来决定
content_by_lua_file lua/item.lua;
}

第三步: 在 /usr/local/openresty/nginx 目录创建lua文件夹,在lua文件夹新建item.lua文件
cd /usr/local/openresty/nginx
mkdir lua
cd lua && touch item.lua
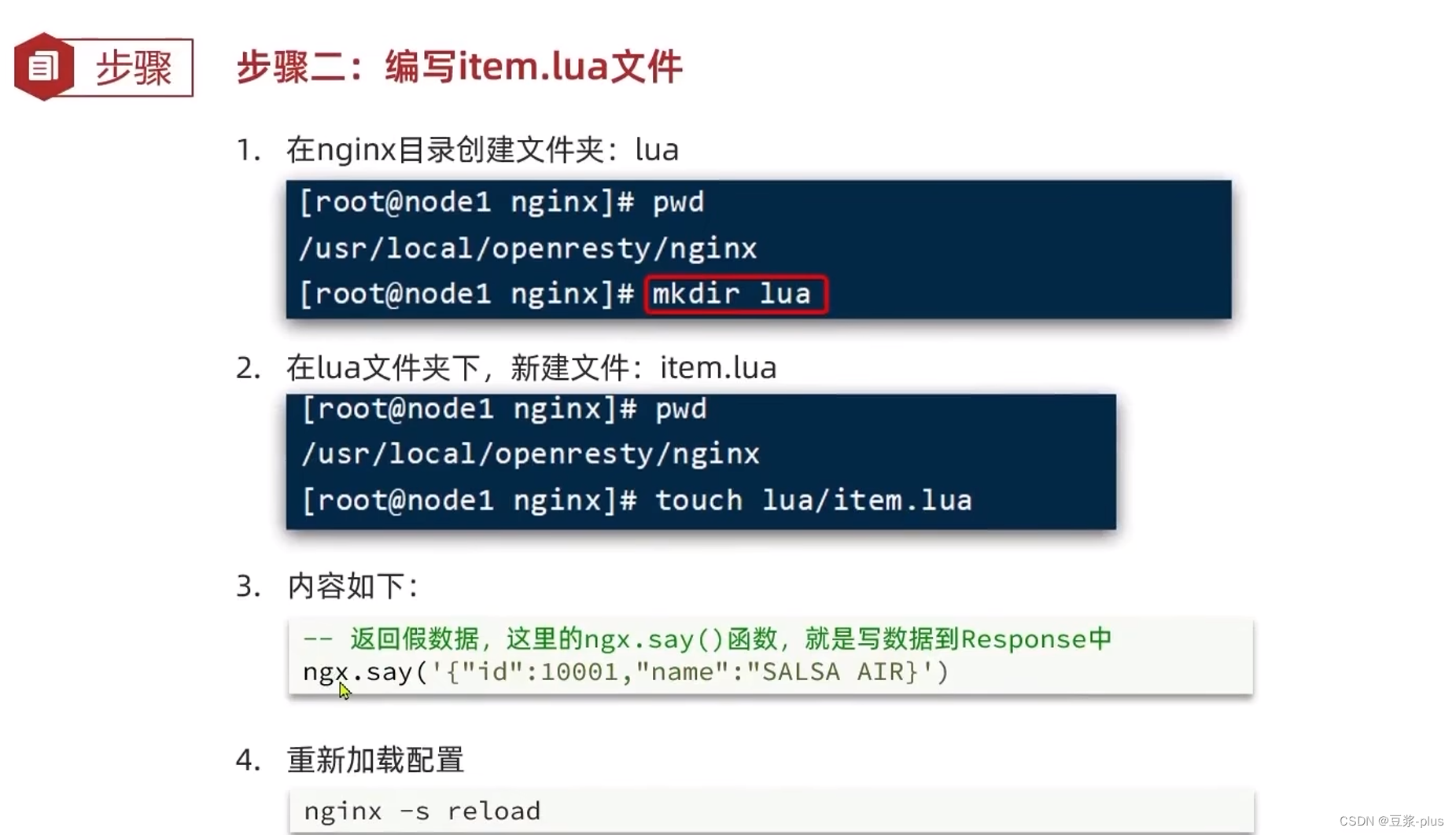
第四步: 在item.lua文件写入如下
-- 返回假数据,这里的ngx.say()函数,就是写数据到Response中
ngx.say('{"id":10001,"name":"SALSA AIR","title":"RIMOWA 999寸托运箱拉杆箱 SALSA AIR系列果绿色 820.70.36.4","price":99999,"image":"https://m.360buyimg.com/mobilecms/s720x720_jfs/t6934/364/1195375010/84676/e9f2c55f/597ece38N0ddcbc77.jpg!q70.jpg.webp","category":"拉杆箱","brand":"RIMOWA","spec":"","status":1,"createTime":"2019-04-30T16:00:00.000+00:00","updateTime":"2019-04-30T16:00:00.000+00:00","stock":2999,"sold":31290}')
第五步: 重新加载配置,可在任意目录执行下面那条命令。如果下面那条命令执行失败,就手打上面第一步、第二步的nginx.conf文件的命令,不要粘贴
nginx
nginx -s reload
第六步: 确保你Windows的Nginx正在运行。win+r,输入cmd并回车,然后输入下面的命令启动Nginx
d:
cd nginx-1.18.0
start nginx.exe
确保你Windows的Nginx配置正确

第七步: 不需要启动idea,不需要启动docker里面的mysql容器。浏览器访问如下
localhost/item.html?id=10001
三、请求参数处理
刚刚我们在OpenResty快速入门中,学习了如何把假数据返回给用户,但是在实际开发中,我们需要根据不同请求去查询不同的商品数据,那么我们就需要先得到不同请求的参数,如何得到,下面就来学习请求参数处理,在OpenResty里面获取用户的请求参数,也就是如何在请求路径里获取参数
OpenResty提供了各种API用来获取不同类型的请求参数,如下表
| 参数格式 | 参数示例 | 参数解析代码示例 |
| 路径占位符 | /item/1001 | ①正则表达式匹配: location ~ /item/(\d+) { content_by_lua_file lua/item.lua;}; ②匹配到的参数会存入ngx.var数组中,可以用角标获取,例如local id = ngx.var[1] |
| 请求头 | id: 1001 | 获取请求头,返回值是table类型,例如local headers = ngx.req.get_headers() |
| Get请求参数 | ?id=10 | 获取GET请求参数,返回值是table类型,例如local getParams = ngx.req.get_uri_args() |
| Post表单参数 | id=1001 | ①读取请求体ngx.req.read_body(); ②获取POST表单参数,返回值是table类型,例如local postParams = ngx.req.get_post_args() |
| JSON参数 | {"id": 1001} | ①读取请求体ngx.req.read_body(); ②获取body中的json参数,返回值是string类型,例如local jsonBody = ngx.req.get_body_data() |
在查询商品信息的请求中,通过路径占位符的方式,传递了商品id到后台:

需求: 在OpenResty中接收这个请求,并获取路径中的id信息,拼接到结果的json字符串中返回
第一步: 在nginx.conf的server下面,给/api/item监听路径添加正则表达式,~表示正则表达式
我把整个代码都放出来了,不要复制,只是在原来的基础上修改了一点点,手打就行
vi /usr/local/openresty/nginx/conf/nginx.conf#user nobody;
worker_processes 1;
error_log logs/error.log;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
# 加载lua模块
lua_package_path "/usr/local/openresty/lualib/?.lua;;";
# 加载c模块
lua_package_cpath "/usr/local/openresty/lualib/?.so;;";
server {
listen 8081;
server_name localhost;
location ~ /api/item/(\d+) {
# 响应类型,这里返回json
default_type application/json;
# 响应数据由 lua/item.lua这个文件来决定
content_by_lua_file lua/item.lua;
}
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
vi /usr/local/openresty/nginx/lua/item.lua
第二步: 把/usr/local/openresty/nginx/lua 目录下的item.lua文件,修改为如下

-- 获取路径参数
local id = ngx.var[1]
-- 返回结果
ngx.say('{"id":'..id ..',"name":"SALSA AIR","title":"RIMOWA 999寸托运箱拉杆箱 SALSA AIR系列果绿色 820.70.36.4","price":99999,"image":"https://m.360buyimg.com/mobilecms/s720x720_jfs/t6934/364/1195375010/84676/e9f2c55f/597ece38N0ddcbc77.jpg!q70.jpg.webp","category":"拉杆箱","brand":"RIMOWA","spec":"","status":1,"createTime":"2019-04-30T16:00:00.000+00:00","updateTime":"2019-04-30T16:00:00.000+00:00","stock":2999,"sold":31290}')
第三步: 在任意目录执行如下命令,重新加载nginx(也就是OpenResty)的配置。执行报错的话,就自己把第一步的代码手打,不要直接复制粘贴
nginx
nginx -s reload
第四步: 确保你Windows的Nginx正在运行。win+r,输入cmd并回车,然后输入下面的命令启动Nginx
d:
cd nginx-1.18.0
start nginx.exe
确保你Windows的Nginx配置正确

第五步: 不需要启动idea,不需要启动docker里面的mysql容器。浏览器访问如下
http://localhost/item.html?id=10002
四、查询Tomcat

【nginx内部发送Http请求】
nginx提供了内部API用以发送http请求:
local resp = ngx.location.capture("/path",{
method = ngx.HTTP_GET, -- 请求方式
args = {a=1,b=2}, -- get方式传参数
body = "c=3&d=4" -- post方式传参数
})
返回的响应内容包括如下:
1、resp.status:响应状态码
2、resp.header:响应头,是一个table
3、resp.body:响应体,就是响应数据
注意:上面的的path是路径,并不包含IP和端口。这个请求会被nginx内部的server监听并处理。但是我们希望这个请求发送到Tomcat服务器,所以还需要编写一个server来对这个路径做反向代理:
location /path {
# 这里是windows电脑的ip和Java服务端口,需要确保windows防火墙处于关闭状态
proxy_pass http://192.168.127.1:8081;
}
【封装http查询的函数】
我们可以把http查询的请求封装为一个函数,放到OpenResty函数库中,方便后期使用
在/usr/local/openresty/lualib目录下创建common.lua文件,在common.lua文件写入如下
vi /usr/local/openresty/lualib/common.lua-- 封装函数,发送http请求,并解析响应
local function read_http(path, params)
local resp = ngx.location.capture(path,{
method = ngx.HTTP_GET,
args = params,
})
if not resp then
-- 记录错误信息,返回404
ngx.log(ngx.ERR, "http not found, path: ", path , ", args: ", args)
ngx.exit(404)
end
return resp.body
end
-- 将方法导出
local _M = {
read_http = read_http
}
return _M
【使用Http函数查询数据】
我们刚才已经把http查询的请求封装为一个函数,放到OpenResty函数库中,接下来就可以使用这个库了
把 /usr/local/openresty/nginx/lua 目录的item.lua文件,修改为如下
vi /usr/local/openresty/nginx/lua/item.lua-- 引入自定义工具模块
local common = require("common")local read_http = common.read_http
-- 获取路径参数
local id = ngx.var[1]
-- 根据id查询商品
local itemJSON = read_http("/item/".. id, nil)
-- 根据id查询商品库存
local itemStockJSON = read_http("/item/stock/".. id, nil)
查询到的是商品、库存的json格式数据,我们需要将两部分数据组装,需要用到JSON处理函数库
【JSON结果处理】
OpenResty提供了一个cjson的模块用来处理JSON的序列化和反序列化。
官方地址: https://github.com/openresty/lua-cjson/
引入cjson模块:
local cjson = require "cjson"
序列化:
local obj = {
name = 'jack',
age = 21
}
local json = cjson.encode(obj)
反序列化:
local json = '{"name": "jack", "age": 21}'
-- 反序列化
local obj = cjson.decode(json);
print(obj.name)
案例: 获取请求路径中的商品id信息,根据id向Tomcat查询商品信息,注意这里要修改item.lua,满足下面的需求
1、获取请求参数中的id根据id
2、向Tomcat服务发送请求,查询商品信息
3、根据id向Tomcat服务发送请求,查询库存信息
4、组装商品信息、库存信息,序列化为JSON格式并返回
第一步: 在nginx.conf的server下面,再添加一个location
我把整个代码都放出来了,不要复制,只是在原来的基础上修改了一点点,手打就行
vi /usr/local/openresty/nginx/conf/nginx.conf#user nobody;
worker_processes 1;
error_log logs/error.log;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
# 加载lua模块
lua_package_path "/usr/local/openresty/lualib/?.lua;;";
# 加载c模块
lua_package_cpath "/usr/local/openresty/lualib/?.so;;";
server {
listen 8081;
server_name localhost;
# 给/item请求地址做反向代理,ip地址是Windows的地址
# 作用是用户请求/item的时候,实际请求的是windows的idea的tomcat
location /item {
proxy_pass http://192.168.127.1:8081;
}
location ~ /api/item/(\d+) {
# 响应类型,这里返回json
default_type application/json;
# 响应数据由 lua/item.lua这个文件来决定
content_by_lua_file lua/item.lua;
}
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}

第二步: 在/usr/local/openresty/lualib目录下创建common.lua文件,在common.lua文件写入如下
cd /usr/local/openresty/lualib
touch common.lua
vi common.lua-- 封装函数,发送http请求,并解析响应
local function read_http(path, params)
local resp = ngx.location.capture(path,{
method = ngx.HTTP_GET,
args = params,
})
if not resp then
-- 记录错误信息,返回404
ngx.log(ngx.ERR, "http not found, path: ", path , ", args: ", args)
ngx.exit(404)
end
return resp.body
end
-- 将方法导出
local _M = {
read_http = read_http
}
return _M
第三步: 为了实现把在lua文件中,把JSON类型的数据转为lua的table类型,我们需要用到OpenResty提供的cjson模块(也就是/usr/local/openresty/lualib 目录下的cjson.so文件),就可以处理JSON的序列化和反序列化。把 /usr/local/openresty/nginx/lua 目录下的item.lua文件修改为如下
vi /usr/local/openresty/nginx/lua/item.lua-- 导入写好的common.lua文件,也就是导入common.lua函数库
local common = require('common')
local read_http = common.read_http
-- 导入OpenResty提供的cjson模块(也就是cjson.so文件),用于下面拼接商品、库存信息时,将JSON转化为lua的table类型
local cjson = require('cjson')
-- 获取路径参数
local id = ngx.var[1]
-- 查询商品信息
local itemJSON = read_http("/item/" .. id, nil)
-- 查询库存信息
local stockJSON = read_http("/item/stock/" .. id, nil)
-- 调用cjson函数,拼接商品、库存信息,一起返回给用户,也就是把商品、库存信息一起返回到页面
local item = cjson.decode(itemJSON)
local stock = cjson.decode(stockJSON)
item.stock = stock.stock
item.sold = stock.sold
-- 上面的item此时是table类型,我们还要序列化回来,也就是把table类型转为JSON类型
-- 返回结果,这次没有假数据,全部都是通过虚拟机nginx(也就是OpenResty)去请求Windows的idea的Tomcat拿到的
ngx.say(cjson.encode(item))
第四步: 在任意目录执行如下,表示重新加载Nginx(也就是OpenResty)的配置文件
nginx
nginx -s reload
第五步: 由于现在是虚拟机的Nginx(也就是OpenResty)向Windows的idea的Tomcat查询数据,所以我们需要先启动一些必要的环境,如下
(1) 启动docker里面的mysql容器
systemctl start docker # 启动docker服务
docker restart mysql #启动mysql容器
(2) 启动Windows的Nginx。win+r,输入cmd回车,然后输入如下
d:
cd nginx-1.18.0
start nginx.exe
(3) 启动idea的item-service项目的ItemApplication引导类,浏览器访问如下
http://localhost/item.html?id=10003
五、Tomcat集群的负载均衡

具体操作如下
第一步: 在nginx.conf的http里面定义upstream作为要访问的地址(也就是Tomcat集群),把Nginx的负载均衡算法设置为基于url地址的负载均衡算法,然后把proxy_pass值,从原来的ip地址修改为集群名称,这样虚拟机的Nginx就会访问idea的Tomcat集群
我把整个代码都放出来了,不要复制,只是在原来的基础上修改了一点点,手打就行
vi /usr/local/openresty/nginx/conf/nginx.conf#user nobody;
worker_processes 1;
error_log logs/error.log;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
# 加载lua模块
lua_package_path "/usr/local/openresty/lualib/?.lua;;";
# 加载c模块
lua_package_cpath "/usr/local/openresty/lualib/?.so;;";
upstream tomcat-cluster {
hash $request_uri;
server 192.168.127.1:8081;
server 192.168.127.1:8082;
}
server {
listen 8081;
server_name localhost;
# 给/item请求地址做反向代理,ip地址是Windows的地址
# 作用是用户请求/item的时候,实际请求的是windows的idea的tomcat
location /item {
proxy_pass http://tomcat-cluster;
}
location ~ /api/item/(\d+) {
# 响应类型,这里返回json
default_type application/json;
# 响应数据由 lua/item.lua这个文件来决定
content_by_lua_file lua/item.lua;
}
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}

第二步: 在任意目录执行如下,表示重新加载Nginx(也就是OpenResty)的配置文件
nginx
nginx -s reload
第三步: 由于现在是虚拟机的Nginx(也就是OpenResty)向Windows的idea的Tomcat查询数据,所以我们需要先启动一些必要的环境,如下
(1) 启动docker里面的mysql容器
systemctl start docker # 启动docker服务
docker restart mysql #启动mysql容器(2) 启动Windows的Nginx。win+r,输入cmd回车,然后输入如下
d:
cd nginx-1.18.0
start nginx.exe
(3) 如何启动两个Tomcat服务。打开idea软件,在item-service项目,进行下面操作



(4) 测试。浏览器访问10001~10004,看看哪个Tomcat响应来自虚拟机Nginx的请求,响应的规律是什么
http://localhost/item.html?id=10004

六、Redis缓存预热

冷启动:服务刚刚启动时,Redis中并没有缓存,如果所有商品数据都在第一次查询时添加缓存,可能会给数据库带来较大压力
缓存预热:在实际开发中,我们可以利用大数据统计用户访问的热点数据,在项目启动时将这些热点数据提前查询并保存到Redis中。对于我们现在这个项目来说,由于数据量较少,所以可以在启动时将所有数据都放入缓存中
【缓存预热】
利用Docker安装Redis
docker run --name redis -p 6379:6379 -d redis redis-server --appendonly yes
在item-service服务中引入Redis依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
配置Redis地址
spring:
redis:
host: 192.168.127.180
编写初始化类
@Component
public class RedisHandler implements InitializingBean {
@Autowired
private StringRedisTemplate redisTemplate;
@Override
public void afterPropertiesSet() throws Exception { // 初始化缓存 ... }
}
具体操作如下
第一步(已做可跳过): 在CentOS7虚拟机的docker里面创建redis容器,并且启动redis容器
# 启动docker服务
systemctl start docker
# 使用pull命令从DockerHub官网拉取redis镜像
docker pull redis
# 查看本地有哪些镜像,是否有redis镜像
docker images
# 把redis镜像创建成redis容器
docker run --name redis -p 6379:6379 -d redis --appendonly yes
# docker run: 运行Docker容器的命令
# --name redis: 指定容器的名称为redis
# -p 6379:6379: 将Redis服务器的端口6379映射到Docker主机的端口6379上。如果不进行端口映射,外部无法访问Redis服务器
# -d: 后台运行容器
# redis: 指定要运行的镜像名称(必须是已经拉取到本地的),不知道版本的话默认是最新版本
# --appendonly yes: 开启Redis持久化功能
# 查看有docker里面有哪些容器
docker ps -a
# 下次要启动redis容器,运行下面那条命令即可
docker start redis
# 删除redis容器,非必要不执行
docker rm -f redis
# 删除redis镜像,非必要不执行
docker rmi redis:latest
第二步: 在idea的item-service项目的pom.xml文件添加如下,表示引入Redis依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
第三步: 在item-service项目的application.yml添加如下
spring:
# 配置redis地址,redis是在虚拟机中
redis:
port: 6379
host: 192.168.127.180
第四步: 在config目录新建RedisHandler类,写入如下
package com.heima.item.config;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.heima.item.pojo.Item;
import com.heima.item.pojo.ItemStock;
import com.heima.item.service.IItemService;
import com.heima.item.service.IItemStockService;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;
import java.util.List;
/**
* @author 35238
* @date 2023/6/28 0028 22:47
*/
@Component
//实现redis缓存的预热功能
public class RedisHandler implements InitializingBean {
@Autowired
//注入redis提供的StringRedisTemplate类,用于操作redis
private StringRedisTemplate redisTemplate;
@Autowired
//注入写好的IItemService接口,用于查询商品信息
private IItemService itemService;
@Autowired
//注入写好的IItemStockService接口,用于查询库存信息
private IItemStockService stockService;
@Autowired
//注入spring提供的JSON处理工具,用于序列化为JSON。为方便使用,我们写成静态常量
private static final ObjectMapper MAPPER = new ObjectMapper();
@Override
//初始化缓存
public void afterPropertiesSet() throws Exception {
//查询商品信息
List<Item> itemList = itemService.list();
//把查到的商品信息放入缓存
for (Item item : itemList) {
//把item(拿到的item是lua语言的table类型)序列化为JSON
String json = MAPPER.writeValueAsString(item);//把任意对象转为json字符串
//把序列化后的item存入redis
//由于商品信息的key存入redis后,可能与后面的库存信息的key重复,
//所以在存key的时候,我们要给key加上前缀,其实就是拼接一个字符串,冒号用于分隔便于观察
redisTemplate.opsForValue().set("item:id:" +item.getId(),json);
}
//查询库存信息
List<ItemStock> stockList = stockService.list();
//把查到的库存信息放入缓存
for (ItemStock stock : stockList) {
//把item(拿到的item是lua语言的table类型)序列化为JSON
String json = MAPPER.writeValueAsString(stock);//把任意对象转为json字符串
//把序列化后的item存入redis
//由于库存信息的key存入redis后,可能与前面的商品信息的key重复,
//所以在存key的时候,我们要给key加上前缀,其实就是拼接一个字符串,冒号用于分隔便于观察
redisTemplate.opsForValue().set("stock:id:" +stock.getId(),json);
}
}
}
第五步: 需要先启动一些必要的环境,如下
(1) 启动docker里面的mysql容器、redis容器
systemctl start docker # 启动docker服务
docker restart mysql #启动mysql容器
docker start redis #启动redis容器
(2) 启动Windows的Nginx。win+r,输入cmd回车,然后输入如下
d:
cd nginx-1.18.0
start nginx.exe
第六步: 在idea的item-service项目,运行ItemApplication引导类、ItemApplication2引导类。查看在启动时,控制台是否先查了数据库,把数据存入缓存

第七步: 在虚拟机的Redis查看一下,有没有数据
# 进入redis容器的终端
docker exec -it redis bash
# 连接redis
redis-cli
# 查看所有的key,也就是存入redis的数据
keys *
七、查询Redis缓存
刚刚我们已经实现了redis(虚拟机的Redis)的缓存预热功能,提前把数据存入了Redis当中,下面我们就需要需要修改OpenResty(就是虚拟机的Nginx)的逻辑,让OpenResty优先查询Redis,Redis未命中再查询Tomcat(idea的Tomcat),我们需要先解决如何在OpenResty来操作Redis,解决: 使用OpenResty提供的操作Redis的模块
首先: 引入Redis模块,并初始化Redis对象
-- 引入redis模块
local redis = require("resty.redis")
-- 初始化Redis对象
local red = redis:new()
-- 设置Redis超时时间(建立连接的超时时间,发送请求的超时时间,响应结果的超时时间)
red:set_timeouts(1000, 1000, 1000)
然后: 封装函数,用来释放Redis连接,其实是放入连接池
-- 关闭redis连接的工具方法,其实是放入连接池
local function close_redis(red)
local pool_max_idle_time = 10000 -- 连接的空闲时间,单位是毫秒
local pool_size = 100 --连接池大小
local ok, err = red:set_keepalive(pool_max_idle_time, pool_size)
if not ok then
ngx.log(ngx.ERR, "放入Redis连接池失败: ", err)
end
end
然后: 封装函数,作用是从Redis读数据并返回
-- 查询redis的方法 ip和port是redis地址,key是查询的key
local function read_redis(ip, port, key)
-- 获取一个连接
local ok, err = red:connect(ip, port)
if not ok then
ngx.log(ngx.ERR, "连接redis失败 : ", err)
return nil
end
-- 查询redis
local resp, err = red:get(key)
-- 查询失败处理
if not resp then
ngx.log(ngx.ERR, "查询Redis失败: ", err, ", key = " , key)
end
--得到的数据为空处理
if resp == ngx.null then
resp = nil
ngx.log(ngx.ERR, "查询Redis数据为空, key = ", key)
end
close_redis(red)
return resp
end
案例: 查询商品时,优先Redis缓存查询,需求如下
1、修改item.lua,封装一个函数read_data,实现先查询Redis,如果未命中,再查询tomcat
2、修改item.lua,查询商品和库存时都调用read_data这个函数
-- 封装函数,先查询redis,再查询http
local function read_data(key, path, params)
-- 查询redis
local resp = read_redis("127.0.0.1", 6379, key)
-- 判断redis是否命中
if not resp then
-- Redis查询失败,查询http
resp = read_http(path, params)
end
return resp
end
具体操作如下
第一步: 把/usr/local/openresty/lualib目录的common.lua文件,修改为如下
-- 导入OpenResty提供的Redis模块
local redis = require('resty.redis')
-- 初始化导入的Redis,也就是创建redis对象
local red = redis:new()
-- 为redis设置超时时间,括号内的参数分别表示'建立连接的超时时间'、'发送请求的超时时间'、'响应结果的超时时间'
red:set_timeouts(1000,1000,1000)
-- 释放Redis的连接
local function close_redis(red)
local pool_max_idle_time = 10000 -- 连接的空闲时间,单位是毫秒
local pool_size = 100 --连接池大小
local ok, err = red:set_keepalive(pool_max_idle_time, pool_size)
if not ok then
ngx.log(ngx.ERR, "放入redis连接池失败: ", err)
end
end
-- 建立Redis的连接,并且读数据
local function read_redis(ip, port, key)
-- 获取一个连接
local ok, err = red:connect(ip, port)
if not ok then
ngx.log(ngx.ERR, "连接redis失败 : ", err)
return nil
end
-- 查询redis
local resp, err = red:get(key)
-- 查询失败处理
if not resp then
ngx.log(ngx.ERR, "查询Redis失败: ", err, ", key = " , key)
end
--得到的数据为空处理
if resp == ngx.null then
resp = nil
ngx.log(ngx.ERR, "查询Redis数据为空, key = ", key)
end
close_redis(red)
return resp
end
-- 封装函数,发送http请求,并解析响应
local function read_http(path, params)
local resp = ngx.location.capture(path,{
method = ngx.HTTP_GET,
args = params,
})
if not resp then
-- 记录错误信息,返回404
ngx.log(ngx.ERR, "http查询失败, path: ", path , ", args: ", args)
ngx.exit(404)
end
return resp.body
end
-- 将方法导出
local _M = {
read_http = read_http,
read_redis = read_redis
}
return _M
第二步: 把/usr/local/openresty/nginx/lua目录的item.lua文件,修改为如下
-- 导入写好的common.lua文件的common.lua函数、read_redis函数
local common = require('common')
local read_http = common.read_http
local read_redis = common.read_redis
-- 导入OpenResty提供的cjson模块(也就是cjson.so文件),用于下面拼接商品、库存信息时,将JSON转化为lua的table类型
local cjson = require('cjson')
-- 封装函数
function read_data(key, path, params)
-- 先查询Redis,也就是先查询虚拟机的Redis
local resp = read_redis("192.168.127.180", 6379, key)
-- 判断查询结果,如果未命中Redis,再查询数据库
if not resp then
-- 记录日志
ngx.log("redis查询未命中,将要去查询数据库。查不到的key是: ",key)
-- redis查询未命中
resp = read_http(path, params)
end
return resp
end
-- 获取路径参数
local id = ngx.var[1]
-- 查询商品信息,调用上面封装好的read_data函数。注意下面括号的第一个参数是Redis的key(用了前缀拼接),要跟你的idea的RedisHandler类里面的key一致(当时也用了前缀拼接)
local itemJSON = read_data("item:id:" .. id, "/item/" .. id, nil)
-- 查询库存信息
local stockJSON = read_data("stock:id:" .. id, "/item/stock/" .. id, nil)
-- 调用cjson函数,拼接商品、库存信息,一起返回给用户,也就是把商品、库存信息一起返回到页面
local item = cjson.decode(itemJSON)
local stock = cjson.decode(stockJSON)
item.stock = stock.stock
item.sold = stock.sold
-- 上面的item此时是table类型,我们还要序列化回来,也就是把table类型转为JSON类型
-- 返回结果,这次没有假数据,全部都是通过虚拟机nginx(也就是OpenResty)去请求Windows的idea的Tomcat拿到的
ngx.say(cjson.encode(item))
第三步: 启动nginx,就是启动OpenResty。不执行这一步的话,下面的第四步执行不了
nginx
第四步: 在任意目录执行如下,表示重新加载Nginx(也就是OpenResty)的配置文件
nginx -s reload
第五步: 需要先启动一些必要的环境,如下
(1) 启动docker里面的mysql容器、redis容器
systemctl start docker # 启动docker服务
docker restart mysql #启动mysql容器
docker start redis #启动redis容器
(2) 启动Windows的Nginx。win+r,输入cmd回车,然后输入如下
d:
cd nginx-1.18.0
start nginx.exe
第六步: 在idea的item-service项目,运行ItemApplication引导类、ItemApplication2引导类。让Nginx(也就是虚拟机的OpenResty)先去idea的Tomcat读取数据存入Redis(虚拟机的redis容器),然后停止运行ItemApplication引导类、ItemApplication2引导类,去浏览器访问如下地址,测试redis是否生效,也就是让Nginx去查询Redis,而不是查询Tomcat
http://localhost/item.html?id=10003
八、Nginx本地缓存

OpenResty为Nginx提供了 shard dict(中文意思是共享词典) 的功能,可以在nginx的多个worker之间共享数据,实现缓存功能
-- 获取本地缓存对象
local item_cache = ngx.shared.item_cache
-- 存储, 指定key、value、过期时间,单位s,默认为0代表永不过期
item_cache:set('key', 'value', 1000)
-- 读取
local val = item_cache:get('key')
1、开启共享字典,在nginx.conf的http下添加配置:
# 共享字典,也就是本地缓存,名称叫做:item_cache,大小150m
lua_shared_dict item_cache 150m;
2、操作共享字典:
案例: 在查询商品时,优先查询OpenResty的本地缓存。需求如下
1、修改item.lua中的read_data函数,优先查询本地缓存,未命中时再查询Redis、Tomcat
2、查询Redis或Tomcat成功后,将数据写入本地缓存,并设置有效期
3、商品基本信息,有效期30分钟
4、库存信息,有效期1分钟
具体操作如下
第一步: 把/usr/local/openresty/nginx/conf目录的nginx.conf文件,修改为如下。注意nginx.conf文件的代码复制容易出错,如果出错了就手打
#user nobody;
worker_processes 1;
error_log logs/error.log;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
# 加载lua模块
lua_package_path "/usr/local/openresty/lualib/?.lua;;";
# 加载c模块
lua_package_cpath "/usr/local/openresty/lualib/?.so;;";
# 添加共享词典功能,也就是本地缓存功能。item_cache是自定义缓存名称,150m是缓存最多存到150MB
lua_shared_dict item_cache 150m;
upstream tomcat-cluster {
hash $request_uri;
server 192.168.127.1:8081;
server 192.168.127.1:8082;
}
server {
listen 8081;
server_name localhost;
# 给/item请求地址做反向代理,ip地址是Windows的地址
# 作用是用户请求/item的时候,实际请求的是windows的idea的tomcat
location /item {
proxy_pass http://tomcat-cluster;
}
location ~ /api/item/(\d+) {
# 响应类型,这里返回json
default_type application/json;
# 响应数据由 lua/item.lua这个文件来决定
content_by_lua_file lua/item.lua;
}
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
第二步: 把/usr/local/openresty/nginx/lua目录的item.lua文件,修改为如下
-- 导入写好的common.lua文件的common.lua函数、read_redis函数
local common = require('common')
local read_http = common.read_http
local read_redis = common.read_redis
-- 导入OpenResty提供的cjson模块(也就是cjson.so文件),用于下面拼接商品、库存信息时,将JSON转化为lua的table类型
local cjson = require('cjson')
-- 导入OpenResty提供的共享词典,也就是导入Nginx本地缓存的模块
local item_cache = ngx.shared.item_cache
-- 封装函数。注意expire是下面需要把数据存入Nginx时,的缓存有效期,单位是秒
function read_data(key, expire, path, params)
-- 不优先查Redis,而是优先查询Nginx(也就是OpenResty)本地缓存
local val = item_cache:get(key)
-- 判断得到的val是否为空,也就是Nginx本地缓存里面是否有用户要查询的数据
if not val then
ngx.log(ngx.ERR, "Nginx本地缓存查询未命中,将要去查询redis。查不到的key是: ",key)
-- 然后才查询Redis,也就是先查询虚拟机的Redis
val = read_redis("192.168.127.180", 6379, key)
-- 判断查询结果,如果未命中Redis,再查询数据库
if not val then
-- 记录日志
ngx.log(ngx.ERR, "redis查询未命中,将要去查询数据库。查不到的key是: ",key)
-- redis查询未命中
val = read_http(path, params)
end
end
-- Nginx本地缓存->Redis->mysql,经过这一轮必然会查询成功,查询成功后,不着急返回,先把数据写入Nginx本地缓存,方便下次直接走Nginx本地缓存
item_cache:set(key, val, expire)
-- 返回数据
return val
end
-- 获取路径参数
local id = ngx.var[1]
-- 查询商品信息,调用上面封装好的read_data函数。注意下面括号的第一个参数是Redis的key(用了前缀拼接),要跟你的idea的RedisHandler类里面的key一致(当时也用了前缀拼接)
local itemJSON = read_data("item:id:" .. id, 1800, "/item/" .. id, nil)
-- 查询库存信息。注意第二个参数是缓存在存入本地Nginx时的缓存有效期,单位是秒
local stockJSON = read_data("stock:id:" .. id, 60, "/item/stock/" .. id, nil)
-- 调用cjson函数,拼接商品、库存信息,一起返回给用户,也就是把商品、库存信息一起返回到页面
local item = cjson.decode(itemJSON)
local stock = cjson.decode(stockJSON)
item.stock = stock.stock
item.sold = stock.sold
-- 上面的item此时是table类型,我们还要序列化回来,也就是把table类型转为JSON类型
-- 返回结果,这次没有假数据,全部都是通过虚拟机nginx(也就是OpenResty)去请求Windows的idea的Tomcat拿到的
ngx.say(cjson.encode(item))
第三步: 启动nginx,就是启动OpenResty。不执行这一步的话,下面的第四步执行不了
nginx
第四步: 在任意目录执行如下,表示重新加载Nginx(也就是OpenResty)的配置文件
nginx -s reload
第五步: 需要先启动一些必要的环境,如下,
(1) 启动docker里面的mysql容器、redis容器
systemctl start docker # 启动docker服务
docker restart mysql #启动mysql容器
docker start redis #启动redis容器
(2) 启动Windows的Nginx。win+r,输入cmd回车,然后输入如下
d:
cd nginx-1.18.0
start nginx.exe
(3) 在idea的item-service项目,运行ItemApplication引导类、ItemApplication2引导类。注意必须运行着,如果关了的话,第一次查询必然请求报错,第二次开始就不报错了,建议开着,这样第一次查询就不会出错
第六步: 测试。先打开Nginx的日志,使用tail命令进行实时监控日志信息的输出
cd /usr/local/openresty/nginx/logs
tail -f error.log
第七步: 测试。浏览器第一次访问如下,这是第一次查询,失败很正常,因为Nginx本地缓存还没有这条数据。下图纠正一下,我们设置的过期时间是60秒
http://localhost/item.html?id=10003
第八步: 测试。浏览器第二次访问如下,由于在第一次查询后,Nginx本地缓存就会有了这条数据。所以第二次查询走的是Nginx本地缓存
http://localhost/item.html?id=10003
总结: 在 '5. 多级缓存的最终实现' 里面,我们实现了一条如下的请求链
用户 -> Windows的Nginx -> 虚拟机的Nginx(也就是OpenResty) -> 虚拟机的Nginx(也就是OpenResty)的本地缓存 -> 虚拟机的Redis容器 ->
idea的Tomcat -> idea的Tomcat的进程缓存 -> 数据库在实现多级缓存后,还有一个很重要的问题,就是如何实现这么多级缓存之间的数据同步,下面将深入学习缓存同步
6. 缓存同步
一、数据同步策略
缓存数据同步的常见方式有三种:
1、设置有效期:给缓存设置有效期,到期后自动删除。再次查询时更新
●优势:简单、方便
●缺点:时效性差,缓存过期之前可能不一致
●场景:更新频率较低,时效性要求低的业务
2、同步双写:在修改数据库的同时,直接修改缓存
●优势:时效性强,缓存与数据库强一致
●缺点:有代码侵入,耦合度高
●场景:对一致性、时效性要求较高的缓存数据
3、异步通知:修改数据库时发送事件通知,相关服务监听到通知后修改缓存数据
●优势:低耦合,可以同时通知多个缓存服务
●缺点:时效性一般,可能存在中间不一致状态
●场景:时效性要求一般,有多个服务需要同步
【具体实现就下面两种,我们采取的是第二种,也就是基于Canal的异步通知】
基于MQ的异步通知(这个可以实现,但我们下面不演示这种,因为这种是要对项目代码进行修改):

基于Canal的异步通知(我们下面演示这个,优点是使用Canal监听数据库的变化,不需要修改项目代码,代码零侵入、零耦合,效率最高):

二、安装Canal
Canal 读 kē nǒu,译意为水道/管道/沟渠,canal是阿里巴巴旗下的一款开源项目,基于Java开发。基于数据库增量日志解析,提供增量数据订阅&消费
GitHub的地址:https://github.com/alibaba/canal
Canal是基于mysql的主从同步来实现的,MySQL主从同步的原理如下:
1、MySQL master 将数据变更写入二进制日志( binary log),其中记录的数据叫做binary log events
2、MySQL slave 将 master 的 binary log events拷贝到它的中继日志(relay log)
3、MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据

Canal就是把自己伪装成MySQL的一个slave节点,从而监听master的binary log变化。再把得到的变化信息通知给Canal的客户端,进而完成对其它数据库的同步

由于Canal是基于MySQL的主从同步功能,因此必须先开启MySQL的主从功能才可以。我们在前面的 '2. JVM进程缓存案例搭建' 里面搭建了一个mysql容器,以这个Docker运行的mysql容器为例。下面我们会在docker里面,使用Canal镜像创建Canal容器。安装Canal的具体操作如下:
第一步: 启动docker里面的mysql容器,并且进入mysql容器终端,登录mysql,查一下你业务使用的是哪个数据库
systemctl start docker # 启动docker服务
docker restart mysql #启动mysql容器
docker exec -it mysql bash #进入mysql容器的终端
mysql -u root -p123 #登录mysql
show databases #查看有哪些database
第二步: 在mysql容器挂载的日志文件,添加如下
vi /tmp/mysql/conf/my.cnflog-bin=/var/lib/mysql/mysql-bin
binlog-do-db=JvmDataShop
# log-bin=/var/lib/mysql/mysql-bin:设置binary log文件的存放地址和文件名,叫做mysql-bin
# binlog-do-db=JvmDataShop:指定对哪个database记录binary log events,这里记录JvmDataShop这个库

第三步: 再次进入mysql容器终端,登录mysql,创建一个用于数据同步的用户,用户名和密码都为canal,为canal用户授予所有权限
docker exec -it mysql bash #进入mysql容器的终端
mysql -u root -p123 #登录mysql
create user 'canal'@'%' IDENTIFIED by 'canal'; # 创建用户
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT,SUPER ON *.* TO 'canal'@'%' identified by 'canal'; #授权
FLUSH PRIVILEGES; # 刷新权限
第四步: 重启mysql容器,然后查看/tmp/mysql/data目录,里面有没有mysql-bin.000001文件
exit # 退出mysql的视图
exit # 退出mysql容器终端的视图
docker restart mysql
ll /tmp/mysql/data
第五步: 现在开始安装Canal。先创建一个网络,将mysql容器放到这个Docker网络中
docker network create heima
docker network connect heima mysql
第六步: 下载链接提供的canal的镜像压缩包到Windows,然后上传到虚拟机的 /root 目录
canal的镜像压缩包下载: https://cowtransfer.com/s/ff2ee7d6bf2644
第七步: 把 /root 目录下的canal镜像压缩包导入docker,然后查看docker里面是否有canal镜像
cd /root
docker load -i canal.tar
docker images
第八步: 在docker,使用canal镜像,来创建并运行canal容器
docker run -p 11111:11111 --name canal \
-e canal.destinations=heima \
-e canal.instance.master.address=mysql:3306 \
-e canal.instance.dbUsername=canal \
-e canal.instance.dbPassword=canal \
-e canal.instance.connectionCharset=UTF-8 \
-e canal.instance.tsdb.enable=true \
-e canal.instance.gtidon=false \
-e canal.instance.filter.regex=JvmDataShop\\..* \
--network heima \
-d canal/canal-server:v1.1.5
# --name canal: 自定义容器名称,例如叫canal
# -p 11111:11111: 这是canal的默认监听端口
# -e canal.destinations: 自定义canal的实例名称
# -e canal.instance.master.address=mysql:3306:数据库地址和端口,由于canal和mysql会在同一网络,所以可以使用容器名进行访问,用来代替ip地址
# -e canal.instance.dbUsername=canal: 数据库用户名
# -e canal.instance.dbPassword=canal: 数据库密码
# -e canal.instance.filter.regex=: canal监听的是mysql的哪个库哪个表,监听的写法是有讲究的,常见语法如下表名称监听支持的语法:
mysql 数据解析关注的表,Perl正则表达式.
多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\)
常见例子:
1. 所有表:.* or .*\\..*
2. canal schema下所有表: canal\\..*
3. canal下的以canal打头的表:canal\\.canal.*
4. canal schema下的一张表:canal.test1
5. 多个规则组合使用然后以逗号隔开:canal\\..*,mysql.test1,mysql.test2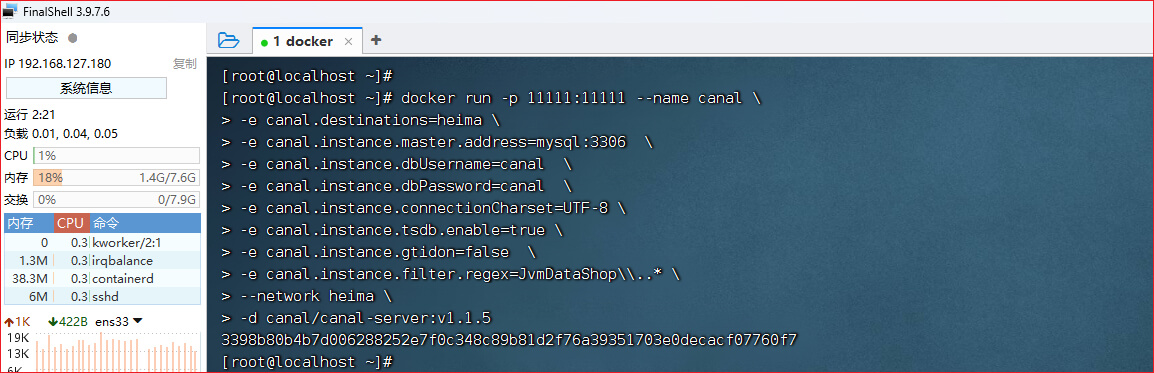
第九步: 查看canal容器是否创建和运行成功,查看的是docker的日志
docker logs -f canal
第十步: 验证canal容器是否跟mysql容器建立了连接。我们需要进入canal容器的终端,再通过tail命令,查看的是canal的日志、查看heima网络的日志
docker exec -it canal bash
tail -f canal-server/logs/canal/canal.log
tail -f canal-server/logs/heima/heima.log
纠正上图: canal不会去读取mysql的数据,只是监听mysql的数据有没有变化。heima并不是网络,而是上面第八步设置的canal的实例名称
三、Canal实现缓存同步
下面的操作是紧接着上面的 '二、安装Canal',请先完成 '二、安装Canal',再进行下面的操作
我们刚刚使用canal(虚拟机的canal容器)监听到了mysql(虚拟机的mysql容器)的数据日志,当canal监听到mysql的数据发生了变化,怎么才能告知redis(虚拟机的redis容器)或Tomcat(idea的item-service项目)呢 ? 下面就来学习
Canal提供了各种语言(包括java语言)的客户端,当Canal监听到binlog变化时,会通知Canal的客户端
我们只需要在idea的Tomcat里面编写这个客户端,让这个客户端在接收到canal的通知之后,去更新Redis,让Redis的缓存保持最新数据

我们使用GitHub上的第三方开源的canal-starter。地址: https://github.com/NormanGyllenhaal/canal-client
具体操作如下
第一步: 在item-service项目的pom.xml文件,添加如下
<!--引入canal依赖-->
<dependency>
<groupId>top.javatool</groupId>
<artifactId>canal-spring-boot-starter</artifactId>
<version>1.2.1-RELEASE</version>
</dependency>
第二步: 在item-service项目的application.yml文件,添加如下
# 配置Canal的地址、实例名称
canal:
destination: heima
server: 192.168.127.180:11111
第三步: Canal推送给canal-client的是被修改的这一行数据(row),而我们引入的canal-client则会帮我们把行数据封装到Item实体类中。这个过程中需要知道数据库与实体的映射关系,要用到JPA的几个注解。把Item类修改为如下
package com.heima.item.pojo;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.annotation.Transient;
import javax.persistence.Column;
import java.util.Date;
@Data
@TableName("tb_item")
public class Item {
@TableId(type = IdType.AUTO)
@Id //表中的id字段
private Long id;//商品id
@Column(name = "name") //表中与属性名不一致的字段。我们目前是一样的,这里写的是name,真实字段名也叫name
private String name;//商品名称
private String title;//商品标题
private Long price;//价格(分)
private String image;//商品图片
private String category;//分类名称
private String brand;//品牌名称
private String spec;//规格
private Integer status;//商品状态 1-正常,2-下架
private Date createTime;//创建时间
private Date updateTime;//更新时间
@TableField(exist = false)
@Transient//不属于表中的字段,将来canal会忽略这个字段
private Integer stock;
@TableField(exist = false)
@Transient//不属于表中的字段,将来canal会忽略这个字段
private Integer sold;
}
第四步: 在RedisHandler类,添加如下,用于操作redis
//往Redis写入数据
public void saveItem(Item item){
try {
//把item(拿到的item是lua语言的table类型)序列化为JSON
String json = MAPPER.writeValueAsString(item);//把任意对象转为json字符串
//把序列化后的item存入redis
//由于商品信息的key存入redis后,可能与后面的库存信息key重复,所以存key的时候,我们给key加上前缀,也就是拼接一个字符串,冒号用于分隔便于观察
redisTemplate.opsForValue().set("item:id:" +item.getId(),json);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}
//删除在redis的数据
public void deleteItemById(Long id){
redisTemplate.delete("item:id:" + id);
}
第五步: 编写监听器,监听Canal消息。在item-service项目的com.heima.item目录新建canal.ItemHandler类,写入如下
package com.heima.item.canal;
import com.github.benmanes.caffeine.cache.Cache;
import com.heima.item.config.RedisHandler;
import com.heima.item.pojo.Item;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import top.javatool.canal.client.annotation.CanalTable;
import top.javatool.canal.client.handler.EntryHandler;
/**
* @author 35238
* @date 2023/6/30 0030 16:29
*/
@CanalTable("tb_item")//指定要监听的表
@Component
//下面的Item是tb_item表对应的实体类
public class ItemHandler implements EntryHandler<Item> {
@Autowired
//注入caffeine提供的Cache接口,用来操作Tomcat进程缓存(也就是JVM进程缓存)
private Cache<Long, Item> itemCache;
@Autowired
//注入刚刚添加了操作redis方法的RedisHandler类
private RedisHandler redisHandler;
@Override
//insert方法是canal提供的EntryHandler接口里面的
//canal监听数据库,如果发生新增数据,要做什么事情
public void insert(Item item) {
//写数据到Tomcat进程缓存(也就是JVM进程缓存)。put方法的第一个参数是key,第二个参数是Value
itemCache.put(item.getId(), item);
//写数据到redis缓存
redisHandler.saveItem(item);
}
@Override
//insert方法是canal提供的EntryHandler接口里面的
//canal监听数据库,如果发生修改数据,要做什么事情。下面的before是更新前的数据,after是更新后的数据
public void update(Item before, Item after) {
//写数据到Tomcat进程缓存(也就是JVM进程缓存)。put方法的第一个参数是key,第二个参数是Value
itemCache.put(after.getId(), after);
//修改数据到redis缓存
redisHandler.saveItem(after);
}
@Override
//insert方法是canal提供的EntryHandler接口里面的
//canal监听数据库,如果发生删除数据,要做什么事情
public void delete(Item item) {
//删除数据到Tomcat进程缓存(也就是JVM进程缓存),根据id进行删除
itemCache.invalidate(item.getId());
//删除数据到redis缓存
redisHandler.deleteItemById(item.getId());
}
}
第六步: 需要先启动一些必要的环境,如下,
(1) 启动docker里面的mysql容器、redis容器
systemctl start docker # 启动docker服务
docker restart mysql #启动mysql容器
docker start redis #启动redis容器
docker start canal #启动canal容器
nginx # 启动nginx,就是启动OpenResty
(2) 启动Windows的Nginx。win+r,输入cmd回车,然后输入如下
d:
cd nginx-1.18.0
start nginx.exe
第七步: 运行idea的item-service项目,运行ItemApplication引导类、ItemApplication2引导类。查看idea控制台信息
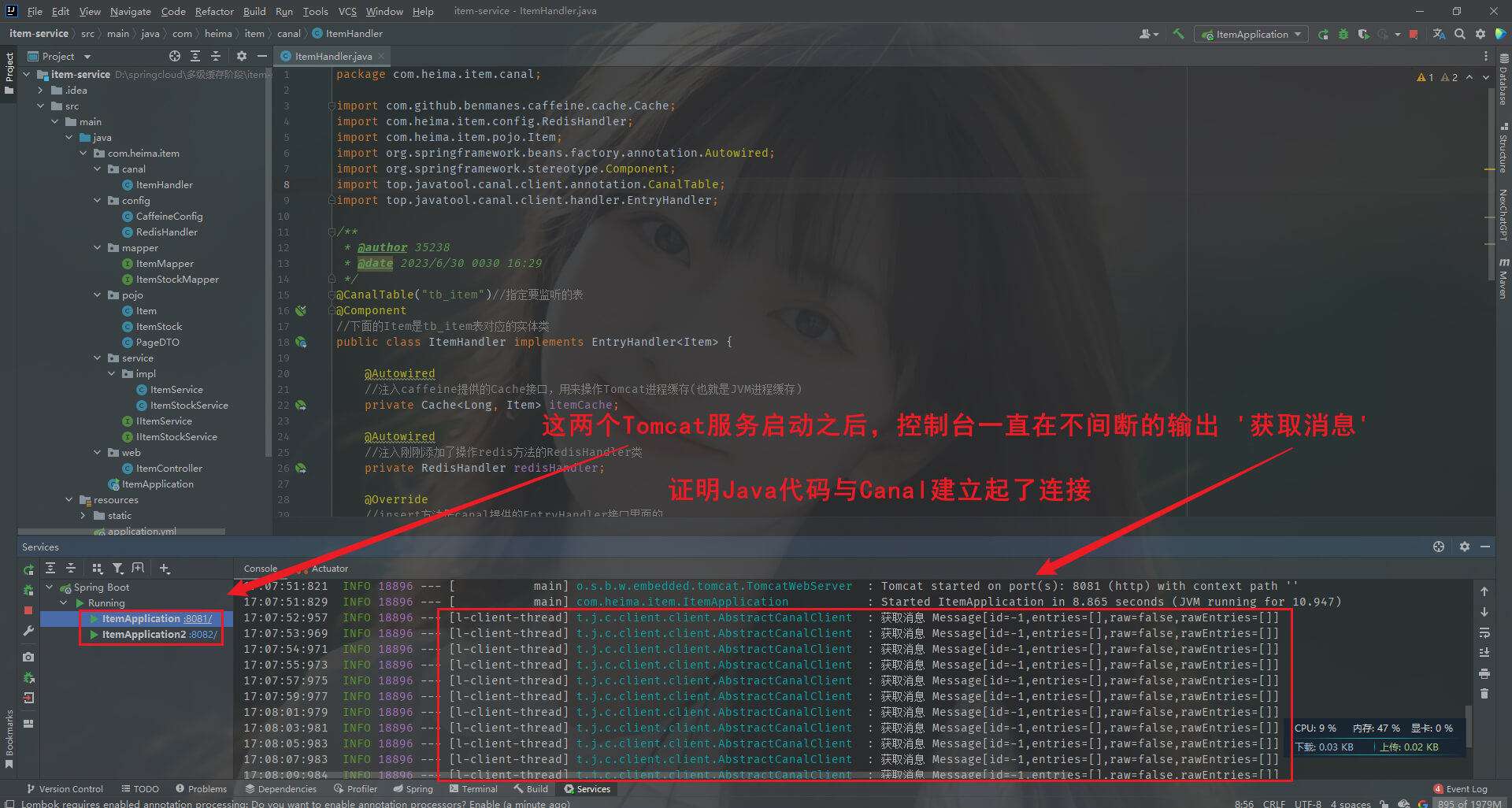
第八步: 测试。当我们对数据库(虚拟机的mysql容器)的数据进行修改时,是否能被canal监控到,从而告知Redis、Tomcat进程缓存去及时更新最新数据。注意由于我们没有去让canal操作Nginx(虚拟机的OpenResty)本地缓存,只是让canal去操作Redis、Tomcat,所以为了直观看到测试结果,我们可以根据如下步骤进行
(1) 浏览器访问如下,拿到id为10001的数据
http://localhost:8081/item/10001
(2) 浏览器访问如下,我们去修改id为10001的数据,就能够触发canal
http://localhost:8081

(3) 查看idea控制台

(4) 浏览器访问如下,看一下数据有没有更新过来
http://localhost:8081/item/10001
(5) 那用户拿到的数据,到底是redis还是tomcat返回的呢 ? 首先,缓存刚更新的时候,用户拿的是tomcat的进程缓存,因为tomcat的处理速度比redis快,等redis也把自己的本地缓存更新之后,就会一直拿redis的本地缓存,如果Nginx也有,就优先拿Nginx的,也就是下面那条请求链
用户 -> Windows的Nginx -> 虚拟机的Nginx(也就是OpenResty) -> 虚拟机的Nginx(也就是OpenResty)的本地缓存 -> 虚拟机的Redis容器 ->
idea的Tomcat -> idea的Tomcat的进程缓存 -> 数据库注意在上面的请求链中,我们除了没有对Nginx的缓存进行同步(但是有缓存失效,我们当时设置的是60秒,所以其实对Nginx也是进行了缓存同步,只不过是被动的)之外,对redis和tomcat都进行了缓存同步,并且是使用canal做的缓存同步,数据永远都是最新的
整体来说,这个请求链是实现了多级缓存+缓存同步,也就是下图的全部功能

6.5缓存同步策略
7.Redis的最佳实践
7.1Redis键值设计
### 1.1、优雅的key结构
Redis的Key虽然可以自定义,但最好遵循下面的几个最佳实践约定:
- - 遵循基本格式:[业务名称]:[数据名]:[id]
- - 长度不超过44字节
- - 不包含特殊字符
例如:我们的登录业务,保存用户信息,其key可以设计成如下格式:
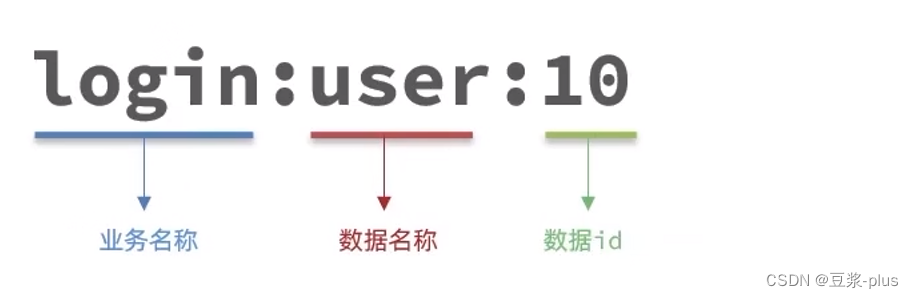
这样设计的好处:
- - 可读性强
- - 避免key冲突
- - 方便管理
- - 更节省内存: key是string类型,底层编码包含int、embstr和raw三种。embstr在小于44字节使用,采用连续内存空间,内存占用更小。当字节数大于44字节时,会转为raw模式存储,在raw模式下,内存空间不是连续的,而是采用一个指针指向了另外一段内存空间,在这段空间里存储SDS内容,这样空间不连续,访问的时候性能也就会收到影响,还有可能产生内存碎片
4.0以上 -> 44个字节
4.0以下 -> 39个字节
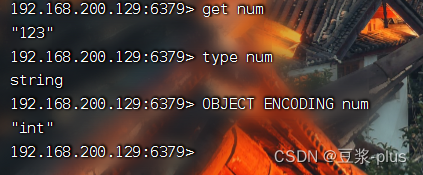
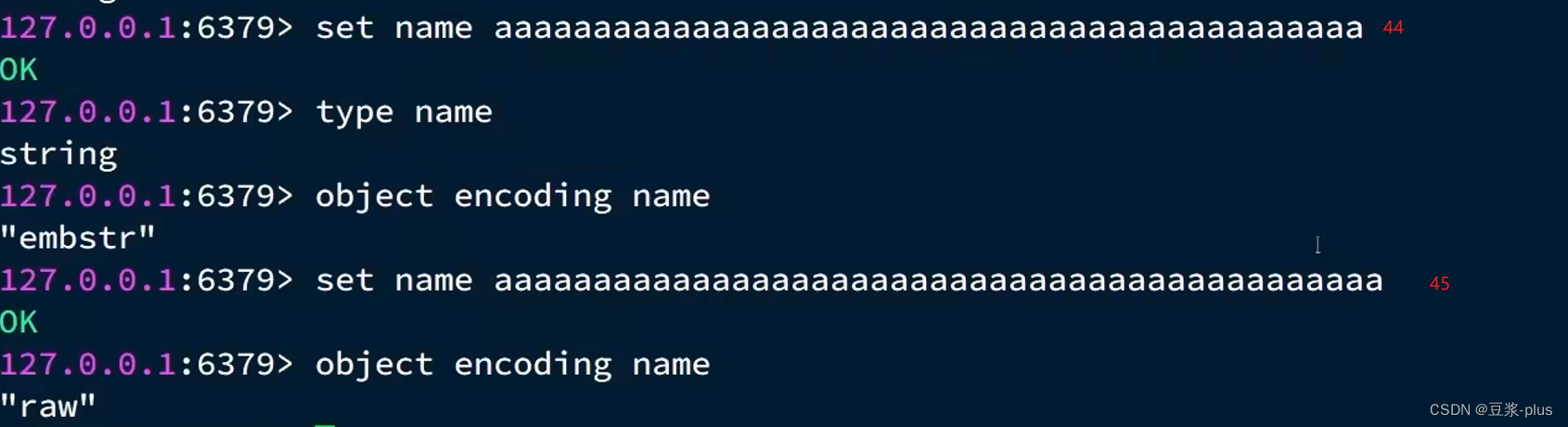
### 1.2、拒绝BigKey
BigKey通常以Key的大小和Key中成员的数量来综合判定,例如:
- - Key本身的数据量过大:一个String类型的Key,它的值为5 MB
- - Key中的成员数过多:一个ZSET类型的Key,它的成员数量为10,000个
- - Key中成员的数据量过大:一个Hash类型的Key,它的成员数量虽然只有1,000个但这些成员的Value(值)总大小为100 MB
那么如何判断元素的大小呢?redis也给我们提供了命令

推荐值:
- - 单个key的value小于10KB
- - 对于集合类型的key,建议元素数量小于1000
#### 1.2.1、BigKey的危害
- - 网络阻塞
- 对BigKey执行读请求时,少量的QPS就可能导致带宽使用率被占满,导致Redis实例,乃至所在物理机变慢
- - 数据倾斜
- BigKey所在的Redis实例内存使用率远超其他实例,无法使数据分片的内存资源达到均衡
- - Redis阻塞
- 对元素较多的hash、list、zset等做运算会耗时较旧,使主线程被阻塞
- - CPU压力
- 对BigKey的数据序列化和反序列化会导致CPU的使用率飙升,影响Redis实例和本机其它应用
#### 1.2.2、如何发现BigKey
##### ①redis-cli --bigkeys
利用redis-cli提供的--bigkeys参数,可以遍历分析所有key,并返回Key的整体统计信息与每个数据的Top1的big key
命令:`redis-cli -a 密码 --bigkeys`

##### ②scan扫描
自己编程,利用scan扫描Redis中的所有key,利用strlen、hlen等命令判断key的长度(此处不建议使用MEMORY USAGE)
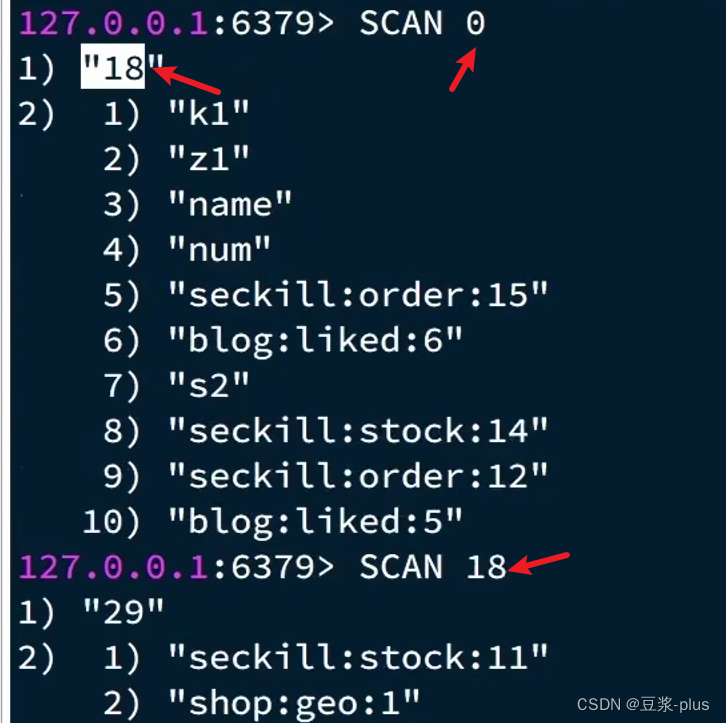
scan 命令调用完后每次会返回2个元素,第一个是下一次迭代的光标,第一次光标会设置为0,当最后一次scan 返回的光标等于0时,表示整个scan遍历结束了,第二个返回的是List,一个匹配的key的数组
```java
import com.heima.jedis.util.JedisConnectionFactory;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.ScanResult;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class JedisTest {
private Jedis jedis;
@BeforeEach
void setUp() {
// 1.建立连接
// jedis = new Jedis("192.168.150.101", 6379);
jedis = JedisConnectionFactory.getJedis();
// 2.设置密码
jedis.auth("123321");
// 3.选择库
jedis.select(0);
}
final static int STR_MAX_LEN = 10 * 1024;
final static int HASH_MAX_LEN = 500;
@Test
void testScan() {
int maxLen = 0;
long len = 0;
String cursor = "0";
do {
// 扫描并获取一部分key
ScanResult<String> result = jedis.scan(cursor);
// 记录cursor
cursor = result.getCursor();
List<String> list = result.getResult();
if (list == null || list.isEmpty()) {
break;
}
// 遍历
for (String key : list) {
// 判断key的类型
String type = jedis.type(key);
switch (type) {
case "string":
len = jedis.strlen(key);
maxLen = STR_MAX_LEN;
break;
case "hash":
len = jedis.hlen(key);
maxLen = HASH_MAX_LEN;
break;
case "list":
len = jedis.llen(key);
maxLen = HASH_MAX_LEN;
break;
case "set":
len = jedis.scard(key);
maxLen = HASH_MAX_LEN;
break;
case "zset":
len = jedis.zcard(key);
maxLen = HASH_MAX_LEN;
break;
default:
break;
}
if (len >= maxLen) {
System.out.printf("Found big key : %s, type: %s, length or size: %d %n", key, type, len);
}
}
} while (!cursor.equals("0"));
}
@AfterEach
void tearDown() {
if (jedis != null) {
jedis.close();
}
}
}##### ③第三方工具
- - 利用第三方工具,如 Redis-Rdb-Tools 分析RDB快照文件,全面分析内存使用情况
- - https://github.com/sripathikrishnan/redis-rdb-tools
##### ④网络监控
- - 自定义工具,监控进出Redis的网络数据,超出预警值时主动告警
- - 一般阿里云搭建的云服务器就有相关监控页面
#### 1.2.3、如何删除BigKey
BigKey内存占用较多,即便时删除这样的key也需要耗费很长时间,导致Redis主线程阻塞,引发一系列问题。
- redis 3.0 及以下版本
- 如果是集合类型,则遍历BigKey的元素,先逐个删除子元素,最后删除BigKey
- Redis 4.0以后
- Redis在4.0后提供了异步删除的命令:unlink

### 1.3、恰当的数据类型
#### 例1:比如存储一个User对象,我们有三种存储方式:
##### ①方式一:json字符串
user:1 {"name": "Jack", "age": 21}
优点:实现简单粗暴
缺点:数据耦合,不够灵活
##### ②方式二:字段打散
| user:1:name | Jack |
| user:1:age | 21 |
优点:以灵活访问对象任意字段
缺点:占用空间大、没办法做统一控制
##### ③方式三:hash(推荐)

优点:底层使用ziplist,空间占用小,可以灵活访问对象的任意字段
缺点:代码相对复杂
#### 例2:假如有hash类型的key,其中有100万对field和value,field是自增id,这个key存在什么问题?如何优化?

存在的问题:
- - hash的entry数量超过500时,会使用哈希表而不是ZipList,内存占用较多
- - 可以通过hash-max-ziplist-entries配置entry上限。但是如果entry过多就会导致BigKey问题
##### 方案一
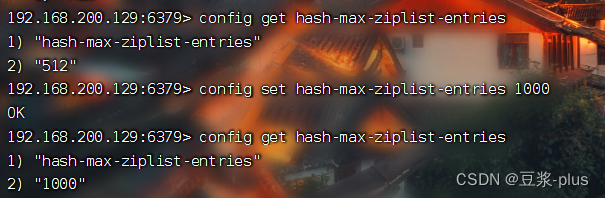
##### 方案二
拆分为string类型
存在的问题:
- string结构底层没有太多内存优化,内存占用较多
- 想要批量获取这些数据比较麻烦
##### 方案三
拆分为小的hash,将 id / 100 作为key, 将id % 100 作为field,这样每100个元素为一个Hash

```java
package com.heima.test;
import com.heima.jedis.util.JedisConnectionFactory;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Pipeline;
import redis.clients.jedis.ScanResult;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class JedisTest {
private Jedis jedis;
@BeforeEach
void setUp() {
// 1.建立连接
// jedis = new Jedis("192.168.150.101", 6379);
jedis = JedisConnectionFactory.getJedis();
// 2.设置密码
jedis.auth("123321");
// 3.选择库
jedis.select(0);
}
@Test
void testSetBigKey() {
Map<String, String> map = new HashMap<>();
for (int i = 1; i <= 650; i++) {
map.put("hello_" + i, "world!");
}
jedis.hmset("m2", map);
}
@Test
void testBigHash() {
Map<String, String> map = new HashMap<>();
for (int i = 1; i <= 100000; i++) {
map.put("key_" + i, "value_" + i);
}
jedis.hmset("test:big:hash", map);
}
@Test
void testBigString() {
for (int i = 1; i <= 100000; i++) {
jedis.set("test:str:key_" + i, "value_" + i);
}
}
@Test
void testSmallHash() {
int hashSize = 100;
Map<String, String> map = new HashMap<>(hashSize);
for (int i = 1; i <= 100000; i++) {
int k = (i - 1) / hashSize;
int v = i % hashSize;
map.put("key_" + v, "value_" + v);
if (v == 0) {
jedis.hmset("test:small:hash_" + k, map);
}
}
}
@AfterEach
void tearDown() {
if (jedis != null) {
jedis.close();
}
}
}```## 1.4、总结
- Key的最佳实践
- - 固定格式:[业务名]:[数据名]:[id]
- - 足够简短:不超过44字节
- - 不包含特殊字符
- Value的最佳实践:
- - 合理的拆分数据,拒绝BigKey
- - 选择合适数据结构
- - Hash结构的entry数量不要超过1000
- - 设置合理的超时时间
7.2批处理优化
####1.Pipeline





####2.集群下的批处理
推荐并行slot
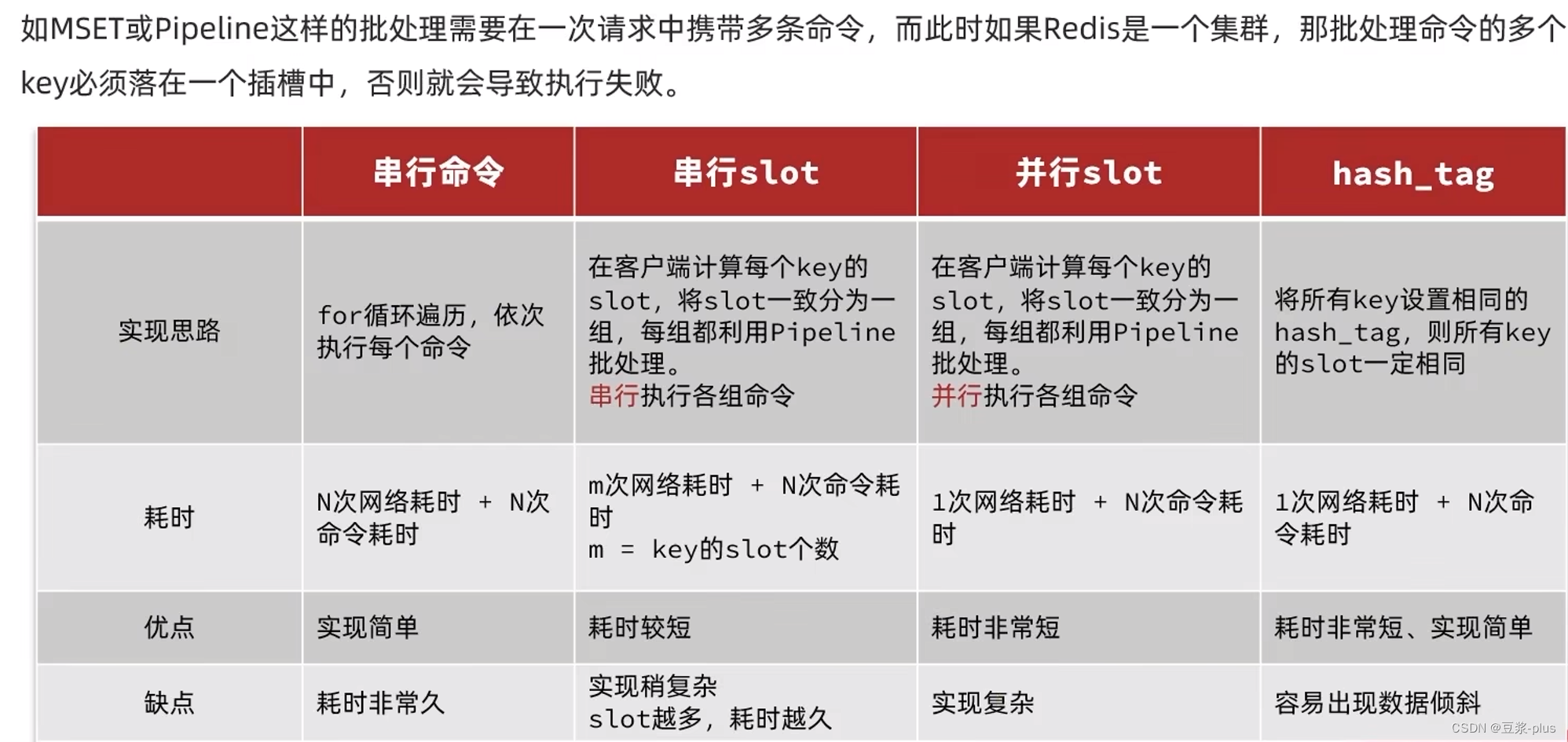
hash_tag:(不推荐)

第一种方案:串行执行,所以这种方式没有什么意义,当然,执行起来就很简单了,缺点就是耗时过久。
第二种方案:串行slot,简单来说,就是执行前,客户端先计算一下对应的key的slot,一样slot的key就放到一个组里边,不同的,就放到不同的组里边,然后对每个组执行pipeline的批处理,他就能串行执行各个组的命令,这种做法比第一种方法耗时要少,但是缺点呢,相对来说复杂一点,所以这种方案还需要优化一下
第三种方案:并行slot,相较于第二种方案,在分组完成后串行执行,第三种方案,就变成了并行执行各个命令,所以他的耗时就非常短,但是实现呢,也更加复杂。
第四种:hash_tag,redis计算key的slot的时候,其实是根据key的有效部分来计算的,通过这种方式就能一次处理所有的key,这种方式耗时最短,实现也简单,但是如果通过操作key的有效部分,那么就会导致所有的key都落在一个节点上,产生数据倾斜的问题,所以我们推荐使用第三种方式。
推荐并行slot:
7.3服务端优化
## 1、服务器端优化-持久化配置
Redis的持久化虽然可以保证数据安全,但也会带来很多额外的开销,因此持久化请遵循下列建议:
- * 用来做缓存的Redis实例尽量不要开启持久化功能
- * 建议关闭RDB持久化功能,使用AOF持久化
- * 利用脚本定期在slave节点做RDB,实现数据备份
- * 设置合理的rewrite阈值,避免频繁的bgrewrite
- * 配置no-appendfsync-on-rewrite = yes,禁止在rewrite期间做aof,避免因AOF引起的阻塞
部署有关建议:
- * Redis实例的物理机要预留足够内存,应对fork和rewrite
- * 单个Redis实例内存上限不要太大,例如4G或8G。可以加快fork的速度、减少主从同步、数据迁移压力
- * 不要与CPU密集型应用部署在一起
- * 不要与高硬盘负载应用一起部署。例如:数据库、消息队列
## 2、服务器端优化-慢查询优化
### 2.1 什么是慢查询
并不是很慢的查询才是慢查询,而是:在Redis执行时耗时超过某个阈值的命令,称为慢查询。
慢查询的危害:由于Redis是单线程的,所以当客户端发出指令后,他们都会进入到redis底层的queue来执行,如果此时有一些慢查询的数据,就会导致大量请求阻塞,从而引起报错,所以我们需要解决慢查询问题。
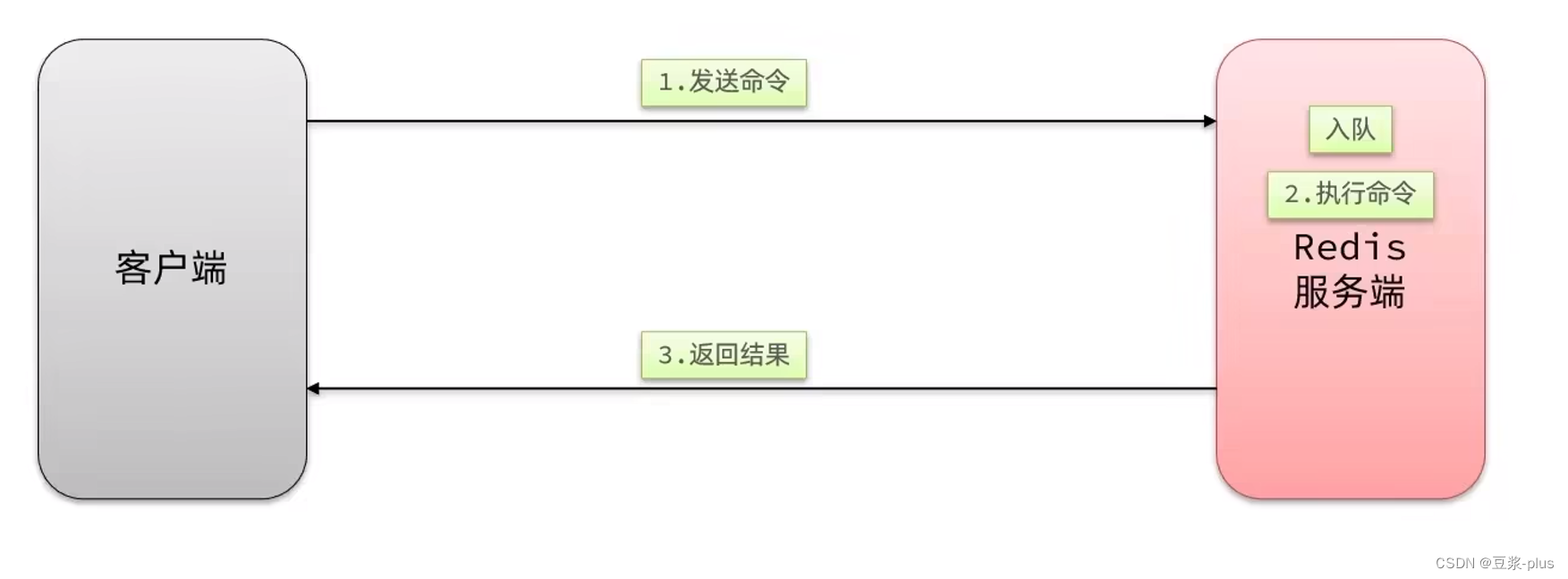
慢查询的阈值可以通过配置指定:
slowlog-log-slower-than:慢查询阈值,单位是微秒。默认是10000,建议1000
慢查询会被放入慢查询日志中,日志的长度有上限,可以通过配置指定:
slowlog-max-len:慢查询日志(本质是一个队列)的长度。默认是128,建议1000
修改这两个配置可以使用:config set命令:

### 2.2 如何查看慢查询
知道了以上内容之后,那么咱们如何去查看慢查询日志列表呢:
- * slowlog len:查询慢查询日志长度
- * slowlog get [n]:读取n条慢查询日志
- * slowlog reset:清空慢查询列表
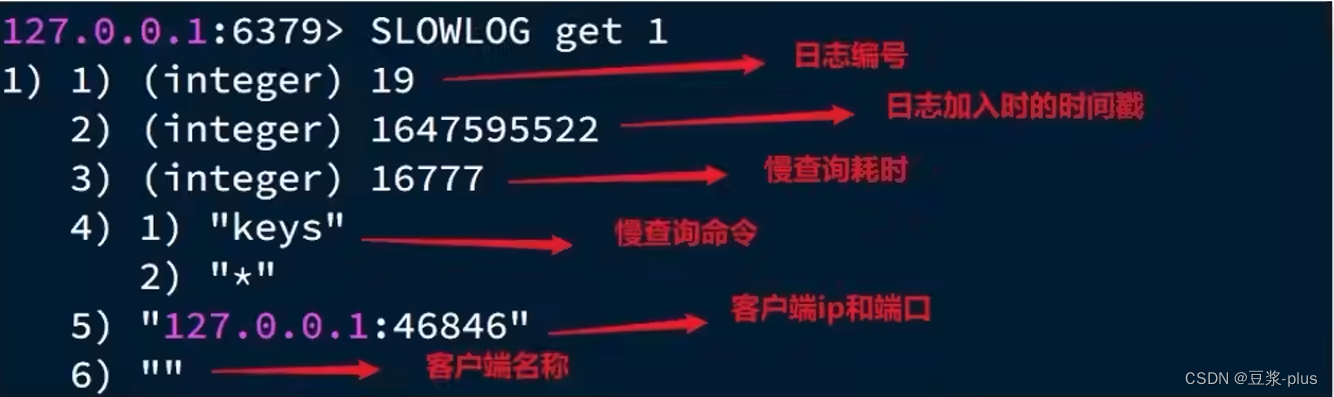
## 3、服务器端优化-命令及安全配置
安全可以说是服务器端一个非常重要的话题,如果安全出现了问题,那么一旦这个漏洞被一些坏人知道了之后,并且进行攻击,那么这就会给咱们的系统带来很多的损失,所以我们这节课就来解决这个问题。
Redis会绑定在0.0.0.0:6379,这样将会将Redis服务暴露到公网上,而Redis如果没有做身份认证,会出现严重的安全漏洞.
漏洞重现方式:https://cloud.tencent.com/developer/article/1039000
为什么会出现不需要密码也能够登录呢,主要是Redis考虑到每次登录都比较麻烦,所以Redis就有一种ssh免秘钥登录的方式,生成一对公钥和私钥,私钥放在本地,公钥放在redis端,当我们登录时服务器,再登录时候,他会去解析公钥和私钥,如果没有问题,则不需要利用redis的登录也能访问,这种做法本身也很常见,但是这里有一个前提,前提就是公钥必须保存在服务器上,才行,但是Redis的漏洞在于在不登录的情况下,也能把秘钥送到Linux服务器,从而产生漏洞
漏洞出现的核心的原因有以下几点:
* Redis未设置密码
* 利用了Redis的config set命令动态修改Redis配置
* 使用了Root账号权限启动Redis
所以:如何解决呢?我们可以采用如下几种方案
为了避免这样的漏洞,这里给出一些建议:
- * Redis一定要设置密码
- * 禁止线上使用下面命令:keys、flushall、flushdb、config set等命令。可以利用rename-command禁用。



- * bind:限制网卡,禁止外网网卡访问
- * 开启防火墙
- * 不要使用Root账户启动Redis
- * 尽量不是有默认的端口
## 4、服务器端优化-Redis内存划分和内存配置
当Redis内存不足时,可能导致Key频繁被删除、响应时间变长、QPS不稳定等问题。当内存使用率达到90%以上时就需要我们警惕,并快速定位到内存占用的原因。

**有关碎片问题分析**
Redis底层分配并不是这个key有多大,他就会分配多大,而是有他自己的分配策略,比如8,16,20等等,假定当前key只需要10个字节,此时分配8肯定不够,那么他就会分配16个字节,多出来的6个字节就不能被使用,这就是我们常说的 碎片问题
**进程内存问题分析:**
这片内存,通常我们都可以忽略不计
**缓冲区内存问题分析:**
一般包括客户端缓冲区、AOF缓冲区、复制缓冲区等。客户端缓冲区又包括输入缓冲区和输出缓冲区两种。这部分内存占用波动较大,所以这片内存也是我们需要重点分析的内存问题。
于是我们就需要通过一些命令,可以查看到Redis目前的内存分配状态:
* info memory:查看内存分配的情况
* memory xxx:查看key的主要占用情况
接下来我们看到了这些配置,最关键的缓存区内存如何定位和解决呢?
内存缓冲区常见的有三种:
- * 复制缓冲区:主从复制的repl_backlog_buf,如果太小可能导致频繁的全量复制,影响性能。通过replbacklog-size来设置,默认1mb
- * AOF缓冲区:AOF刷盘之前的缓存区域,AOF执行rewrite的缓冲区。无法设置容量上限
- * 客户端缓冲区:分为输入缓冲区和输出缓冲区,输入缓冲区最大1G且不能设置。输出缓冲区可以设置
以上复制缓冲区和AOF缓冲区 不会有问题,最关键就是客户端缓冲区的问题
客户端缓冲区:指的就是我们发送命令时,客户端用来缓存命令的一个缓冲区,也就是我们向redis输入数据的输入端缓冲区和redis向客户端返回数据的响应缓存区,输入缓冲区最大1G且不能设置,所以这一块我们根本不用担心,如果超过了这个空间,redis会直接断开,因为本来此时此刻就代表着redis处理不过来了,我们需要担心的就是输出端缓冲区
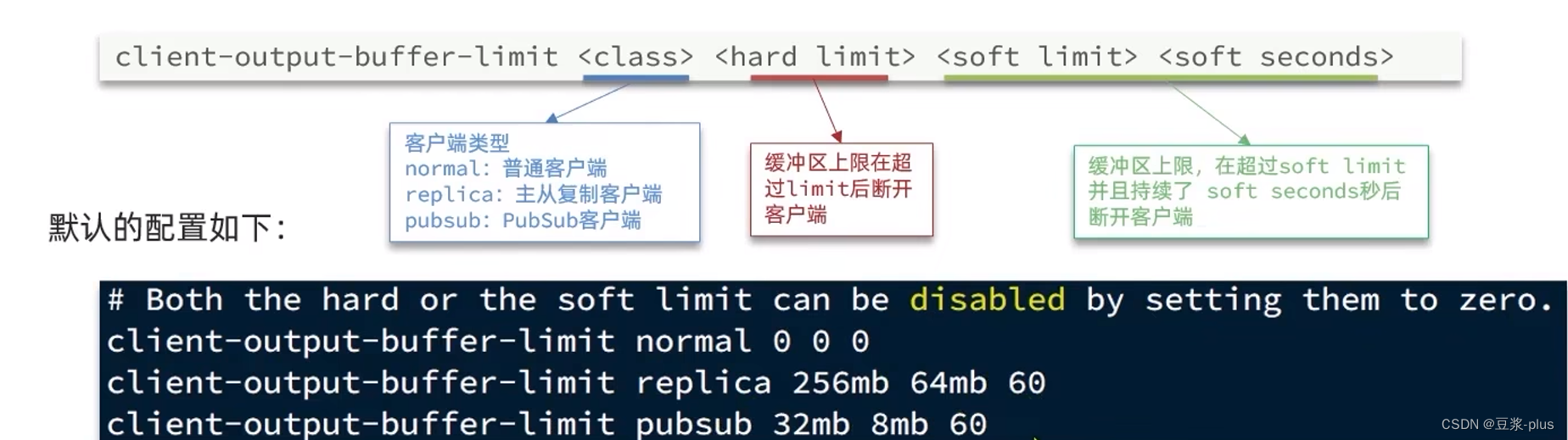
我们在使用redis过程中,处理大量的big value,那么会导致我们的输出结果过多,如果输出缓存区过大,会导致redis直接断开,而默认配置的情况下, 其实他是没有大小的,这就比较坑了,内存可能一下子被占满,会直接导致咱们的redis断开,所以解决方案有两个
1、设置一个大小
2、增加我们带宽的大小,避免我们出现大量数据从而直接超过了redis的承受能力
7.4集群最佳实践
## 1、服务器端集群优化-集群还是主从
集群虽然具备高可用特性,能实现自动故障恢复,但是如果使用不当,也会存在一些问题:
- * 集群完整性问题
- * 集群带宽问题
- * 数据倾斜问题
- * 客户端性能问题
- * 命令的集群兼容性问题
- * lua和事务问题
**问题1、在Redis的默认配置中,如果发现任意一个插槽不可用,则整个集群都会停止对外服务:**


大家可以设想一下,如果有几个slot不能使用,那么此时整个集群都不能用了,我们在开发中,其实最重要的是可用性,所以需要把如下配置修改成no,即有slot不能使用时,我们的redis集群还是可以对外提供服务
**问题2、集群带宽问题**
集群节点之间会不断的互相Ping来确定集群中其它节点的状态。每次Ping携带的信息至少包括:
- * 插槽信息
- * 集群状态信息
集群中节点越多,集群状态信息数据量也越大,10个节点的相关信息可能达到1kb,此时每次集群互通需要的带宽会非常高,这样会导致集群中大量的带宽都会被ping信息所占用,这是一个非常可怕的问题,所以我们需要去解决这样的问题
**解决途径:**
- * 避免大集群,集群节点数不要太多,最好少于1000,如果业务庞大,则建立多个集群。
- * 避免在单个物理机中运行太多Redis实例
- * 配置合适的cluster-node-timeout值
**问题3、命令的集群兼容性问题**
有关这个问题咱们已经探讨过了,当我们使用批处理的命令时,redis要求我们的key必须落在相同的slot上,然后大量的key同时操作时,是无法完成的,所以客户端必须要对这样的数据进行处理,这些方案我们之前已经探讨过了,所以不再这个地方赘述了。
**问题4、lua和事务的问题**
lua和事务都是要保证原子性问题,如果你的key不在一个节点,那么是无法保证lua的执行和事务的特性的,所以在集群模式是没有办法执行lua和事务的
**那我们到底是集群还是主从**
单体Redis(主从Redis)已经能达到万级别的QPS,并且也具备很强的高可用特性。如果主从能满足业务需求的情况下,所以如果不是在万不得已的情况下,尽量不搭建Redis集群
8.Redis原理
8.1 数据结构
8.1.1 动态字符串SDS(单个字符串时)
我们都知道Redis中保存的Key是字符串,value往往是字符串或者字符串的集合。可见字符串是Redis中最常用的一种数据结构。
不过Redis没有直接使用C语言中的字符串,因为C语言字符串存在很多问题:
- 获取字符串长度的需要通过运算
- 非二进制安全
- 不可修改

Redis构建了一种新的字符串结构,称为简单动态字符串(Simple Dynamic String),简称SDS。例如,我们执行命令:

那么Redis将在底层创建两个SDS,其中一个是包含“name”的SDS,另一个是包含“虎哥”的SDS。
Redis是C语言实现的,其中SDS是一个结构体,源码如下:

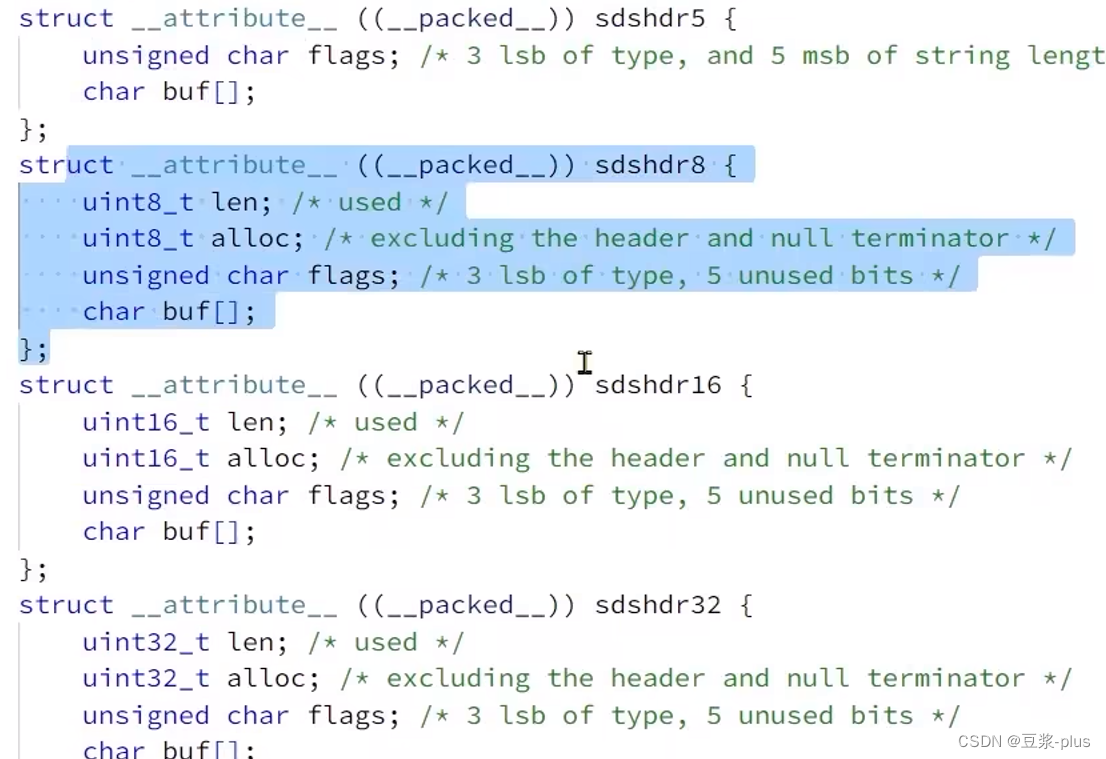

5,8,16,32,64 五种
例如,一个包含字符串“name”的sds结构如下:

SDS之所以叫做动态字符串,是因为它具备动态扩容的能力,例如一个内容为“hi”的SDS:

假如我们要给SDS追加一段字符串“,Amy”,这里首先会申请新内存空间:
- 如果新字符串小于1M,则新空间为扩展后字符串长度的两倍+1;
- 如果新字符串大于1M,则新空间为扩展后字符串长度+1M+1。称为内存预分配。


IntSet:数据不多时
IntSet是Redis中set集合的一种实现方式,基于整数数组来实现,并且具备长度可变、有序等特征。
结构如下:

其中的encoding包含三种模式,表示存储的整数大小不同:

为了方便查找,Redis会将intset中所有的整数按照升序依次保存在contents数组中,结构如图:

现在,数组中每个数字都在int16_t的范围内,因此采用的编码方式是INTSET_ENC_INT16,每部分占用的字节大小为:
- encoding:4字节
- length:4字节
- contents:2字节 * 3 = 6字节
我们向该其中添加一个数字:50000,这个数字超出了int16_t的范围,intset会自动升级编码方式到合适的大小。
以当前案例来说流程如下:
- * 升级编码为INTSET_ENC_INT32, 每个整数占4字节,并按照新的编码方式及元素个数扩容数组
- * 倒序依次将数组中的元素拷贝到扩容后的正确位置
- * 将待添加的元素放入数组末尾
- * 最后,将inset的encoding属性改为INTSET_ENC_INT32,将length属性改为4
源码如下:
小总结:
Intset可以看做是特殊的整数数组,具备一些特点:
- * Redis会确保Intset中的元素唯一、有序
- * 具备类型升级机制,可以节省内存空间
- * 底层采用二分查找方式来查询
8.1.2 Dict(字典)
我们知道Redis是一个键值型(Key-Value Pair)的数据库,我们可以根据键实现快速的增删改查。而键与值的映射关系正是通过Dict来实现的。(同Java HashMap)
Dict由三部分组成,分别是:哈希表(DictHashTable)、哈希节点(DictEntry)、字典(Dict)

当我们向Dict添加键值对时,Redis首先根据key计算出hash值(h),然后利用 h & sizemask来计算元素应该存储到数组中的哪个索引位置。我们存储k1=v1,假设k1的哈希值h =1,则1&3 =1,因此k1=v1要存储到数组角标1位置。(同Java size求余计算)

Dict由三部分组成,分别是:哈希表(DictHashTable)、哈希节点(DictEntry)、字典(Dict)


**Dict的扩容**
Dict中的HashTable就是数组结合单向链表的实现,当集合中元素较多时,必然导致哈希冲突增多,链表过长,则查询效率会大大降低。
Dict在每次新增键值对时都会检查负载因子(LoadFactor = used/size) ,满足以下两种情况时会触发哈希表扩容:
- 哈希表的 LoadFactor >= 1,并且服务器没有执行 BGSAVE(bgsave) 或者 BGREWRITEAOF(bgrewriteaof) 等后台进程;
- 哈希表的 LoadFactor > 5 ;
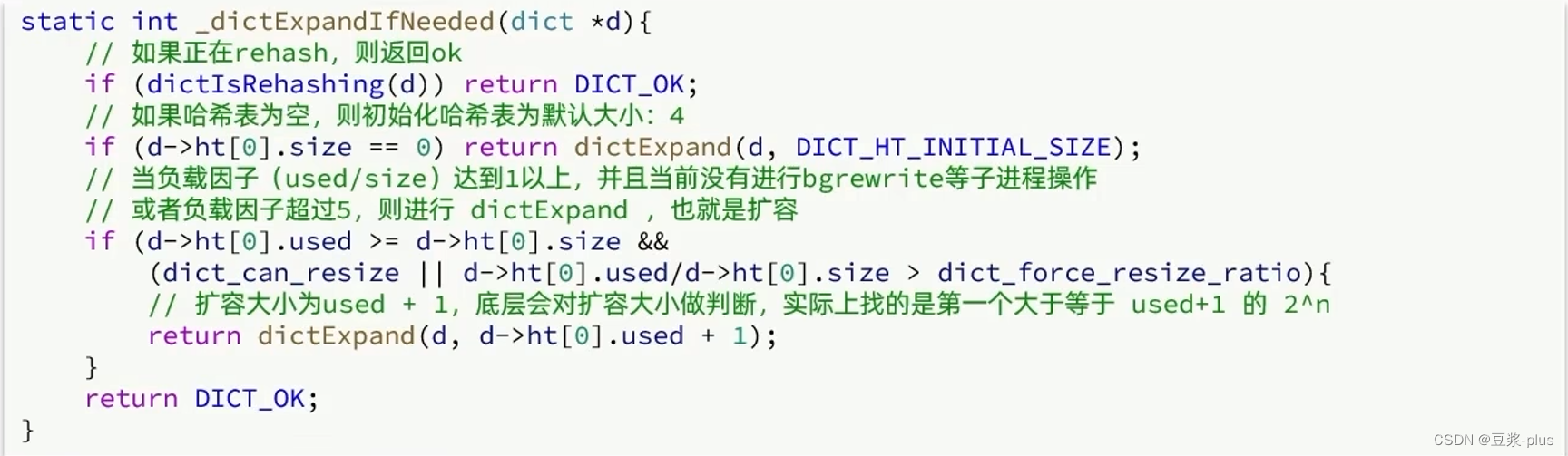
**Dict的收缩**
Dict除了扩容以外,每次删除元素时,也会对负载因子做检查,当LoadFactor<0.1 时,会做哈希表收缩:

**Dict的rehash**
不管是扩容还是收缩,必定会创建新的哈希表,导致哈希表的size和sizemask变化,而key的查询与sizemask有关。因此必须对哈希表中的每一个key重新计算索引,插入新的哈希表,这个过程称为rehash。过程是这样的:
- * 计算新hash表的realeSize,值取决于当前要做的是扩容还是收缩:
- * 如果是扩容,则新size为第一个大于等于dict.ht[0].used + 1的2^n
- * 如果是收缩,则新size为第一个大于等于dict.ht[0].used的2^n (不得小于4)
- * 按照新的realeSize申请内存空间,创建dictht,并赋值给dict.ht[1]
- * 设置dict.rehashidx = 0,标示开始rehash
- * 将dict.ht[0]中的每一个dictEntry都rehash到dict.ht[1]
- * 将dict.ht[1]赋值给dict.ht[0],给dict.ht[1]初始化为空哈希表,释放原来的dict.ht[0]的内存
- * 将rehashidx赋值为-1,代表rehash结束
- * 在rehash过程中,新增操作,则直接写入ht[1],查询、修改和删除则会在dict.ht[0]和dict.ht[1]依次查找并执行。这样可以确保ht[0]的数据只减不增,随着rehash最终为空
整个过程可以描述成:
小总结:
Dict的结构:
- * 类似java的HashTable,底层是数组加链表来解决哈希冲突
- * Dict包含两个哈希表,ht[0]平常用,ht[1]用来rehash
Dict的伸缩:
- * 当LoadFactor大于5或者LoadFactor大于1并且没有子进程任务时,Dict扩容
- * 当LoadFactor小于0.1时,Dict收缩
- * 扩容大小为第一个大于等于used + 1的2^n
- * 收缩大小为第一个大于等于used 的2^n
- * Dict采用渐进式rehash,每次访问Dict时执行一次rehash
- * rehash时ht[0]只减不增,新增操作只在ht[1]执行,其它操作在两个哈希表
8.1.3 ZipList:
ZipList 是一种特殊的“双端链表” ,由一系列特殊编码的连续内存块组成。可以在任意一端进行压入/弹出操作, 并且该操作的时间复杂度为 O(1)。
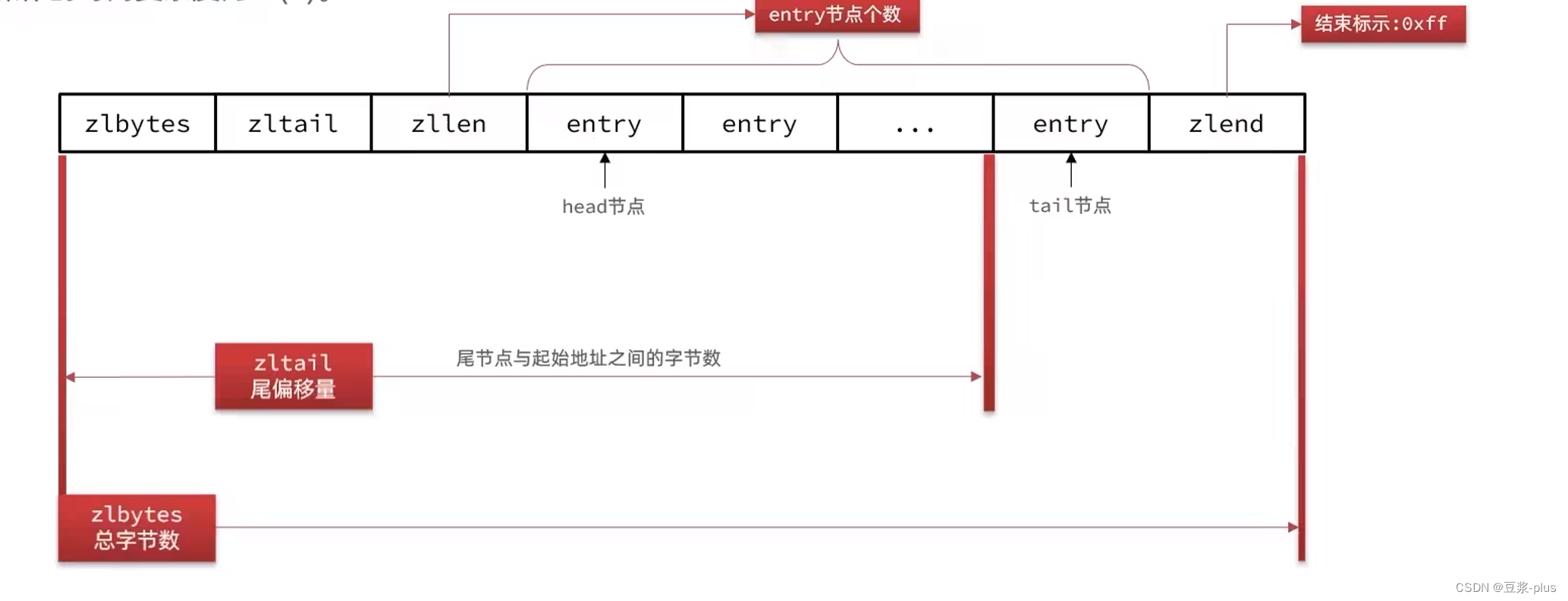
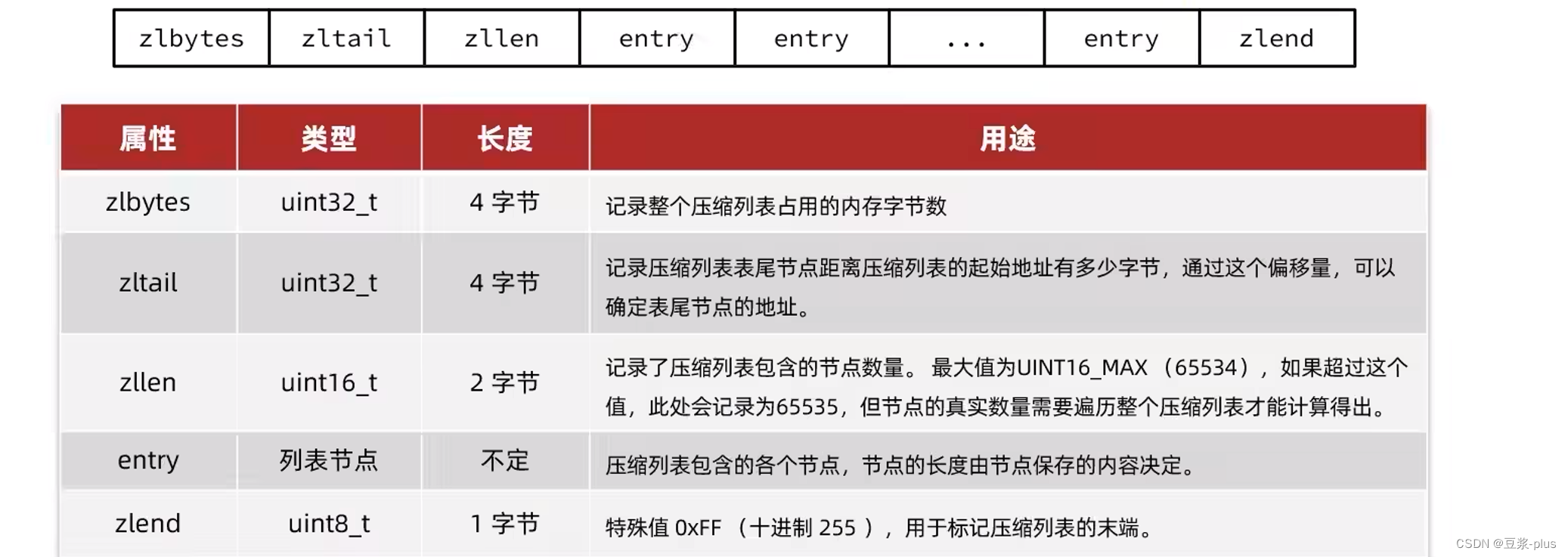
**ZipListEntry**
ZipList 中的Entry并不像普通链表那样记录前后节点的指针,因为记录两个指针要占用16个字节,浪费内存。而是采用了下面的结构:

- * previous_entry_length:前一节点的长度,占1个或5个字节。
- * 如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值
- * 如果前一节点的长度大于254字节,则采用5个字节来保存这个长度值,第一个字节为0xfe,后四个字节才是真实长度数据
- * encoding:编码属性,记录content的数据类型(字符串还是整数)以及长度,占用1个、2个或5个字节
- * contents:负责保存节点的数据,可以是字符串或整数

**Encoding编码**
ZipListEntry中的encoding编码分为字符串和整数两种:
字符串:如果encoding是以“00”、“01”或者“10”开头,则证明content是字符串

例如,我们要保存字符串:“ab”和 “bc”

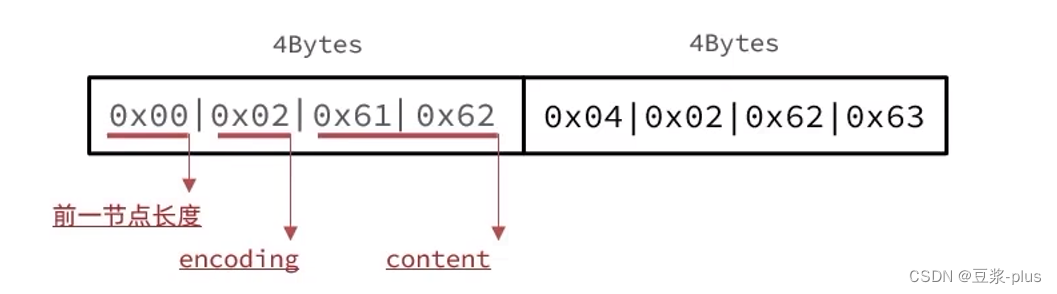

ZipListEntry中的encoding编码分为字符串和整数两种:
整数:如果encoding是以“11”开始,则证明content是整数,且encoding固定只占用1个字节
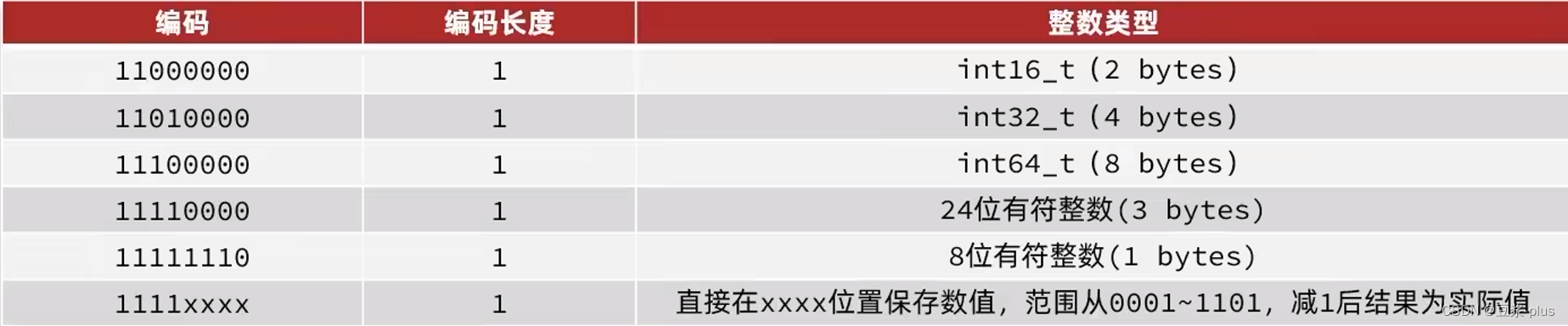

### 1.5 Redis数据结构-ZipList的连锁更新问题(未解决)
ZipList的每个Entry都包含previous_entry_length来记录上一个节点的大小,长度是1个或5个字节:
- 如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值
- 如果前一节点的长度大于等于254字节,则采用5个字节来保存这个长度值,第一个字节为0xfe,后四个字节才是真实长度数据
现在,假设我们有N个连续的、长度为250~253字节之间的entry,因此entry的previous_entry_length属性用1个字节即可表示,如图所示:


ZipList这种特殊情况下产生的连续多次空间扩展操作称之为连锁更新(Cascade Update)。新增、删除都可能导致连锁更新的发生。
**小总结:**
**ZipList特性:**
- * 压缩列表的可以看做一种连续内存空间的"双向链表"
- * 列表的节点之间不是通过指针连接,而是记录上一节点和本节点长度来寻址,内存占用较低
- * 如果列表数据过多,导致链表过长,可能影响查询性能
- * 增或删较大数据时有可能发生连续更新问题
8.1.4 QuickList:
问题1:ZipList虽然节省内存,但申请内存必须是连续空间,如果内存占用较多,申请内存效率很低。怎么办?
答:为了缓解这个问题,我们必须限制ZipList的长度和entry大小。
问题2:但是我们要存储大量数据,超出了ZipList最佳的上限该怎么办?
答:我们可以创建多个ZipList来分片存储数据。
问题3:数据拆分后比较分散,不方便管理和查找,这多个ZipList如何建立联系?
答:Redis在3.2版本引入了新的数据结构QuickList,它是一个双端链表,只不过链表中的每个节点都是一个ZipList。
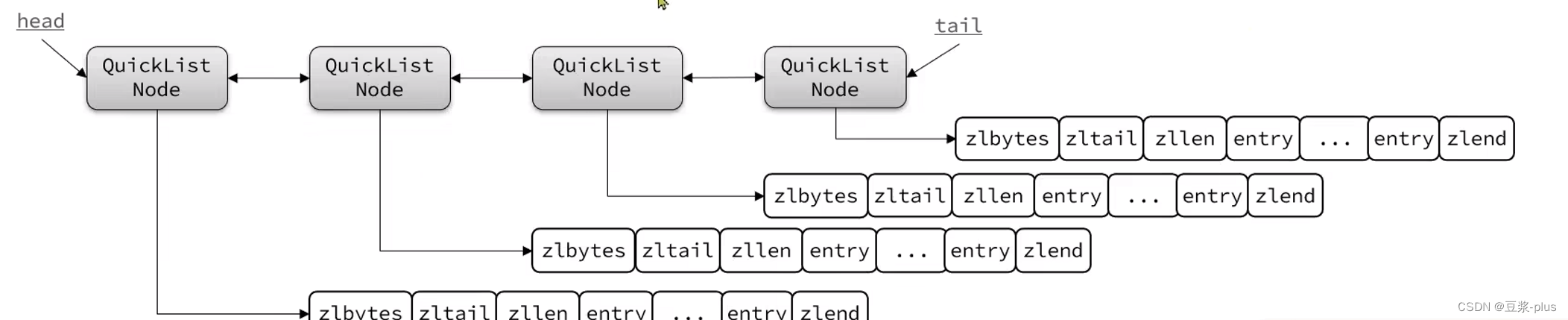
为了避免QuickList中的每个ZipList中entry过多,Redis提供了一个配置项:list-max-ziplist-size来限制。
- 如果值为正,则代表ZipList的允许的entry个数的最大值
- 如果值为负,则代表ZipList的最大内存大小,分5种情况:
- * -1:每个ZipList的内存占用不能超过4kb
- * -2:每个ZipList的内存占用不能超过8kb
- * -3:每个ZipList的内存占用不能超过16kb
- * -4:每个ZipList的内存占用不能超过32kb
- * -5:每个ZipList的内存占用不能超过64kb
其默认值为 -2:

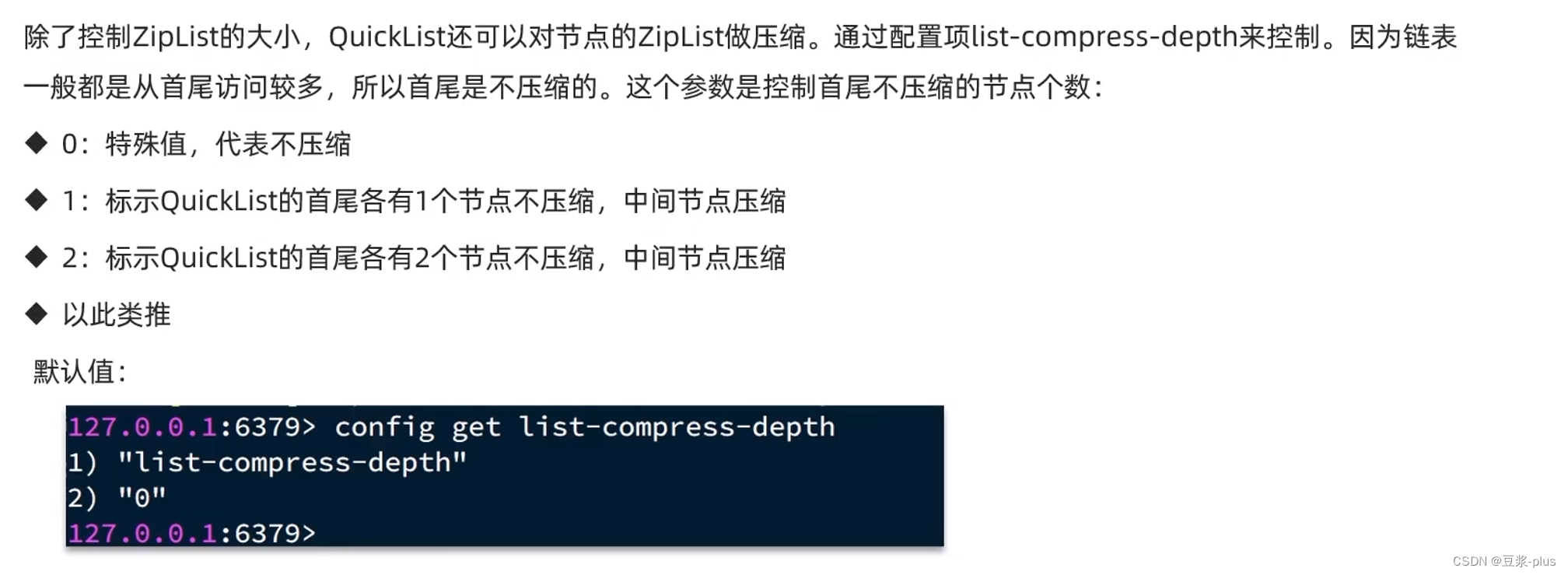
以下是QuickList的和QuickListNode的结构源码:

我们接下来用一段流程图来描述当前的这个结构
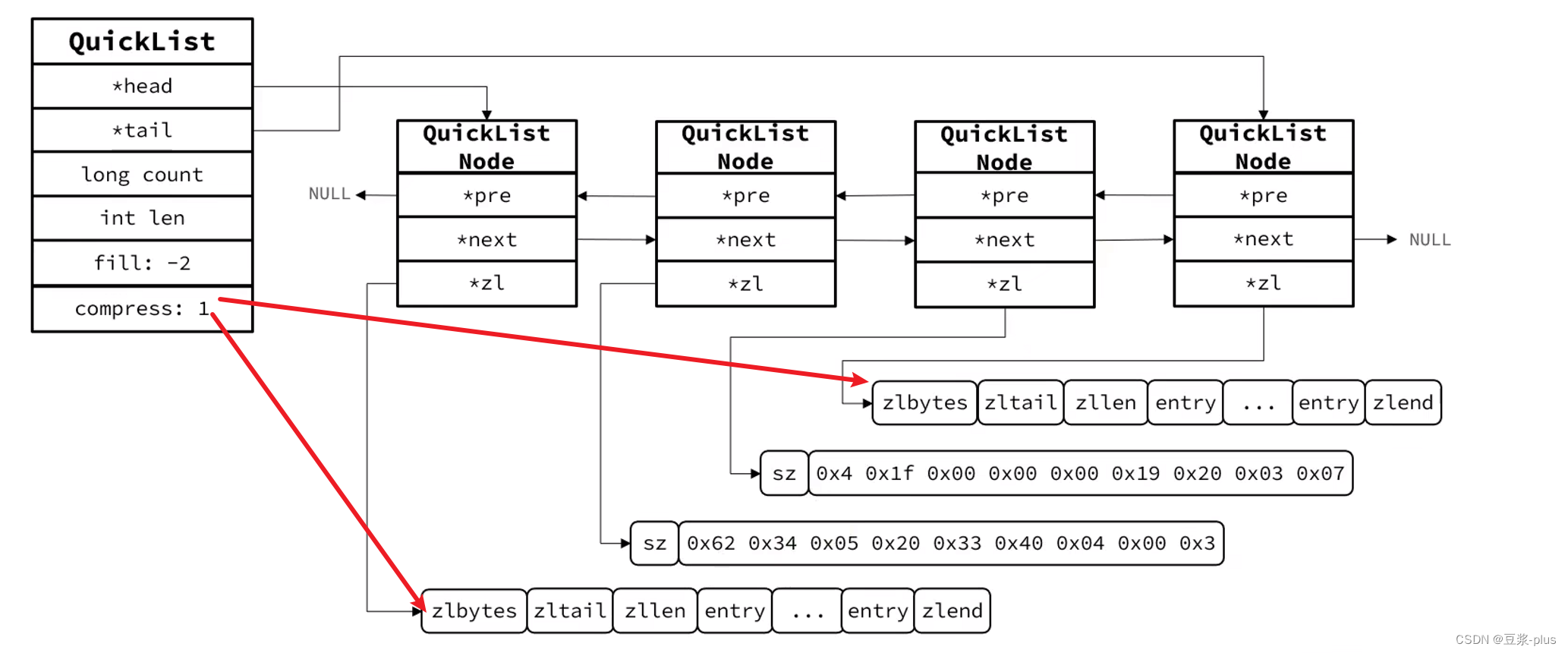
总结:
QuickList的特点:
- * 是一个节点为ZipList的双端链表
- * 节点采用ZipList,解决了传统链表的内存占用问题
- * 控制了ZipList大小,解决连续内存空间申请效率问题
- * 中间节点可以压缩,进一步节省了内存
8.1.5 SkipList:
SkipList(跳表)首先是链表,但与传统链表相比有几点差异:
- 元素按照升序排列存储
- 节点可能包含多个指针,指针跨度不同。

最多32级 (2的32平方)

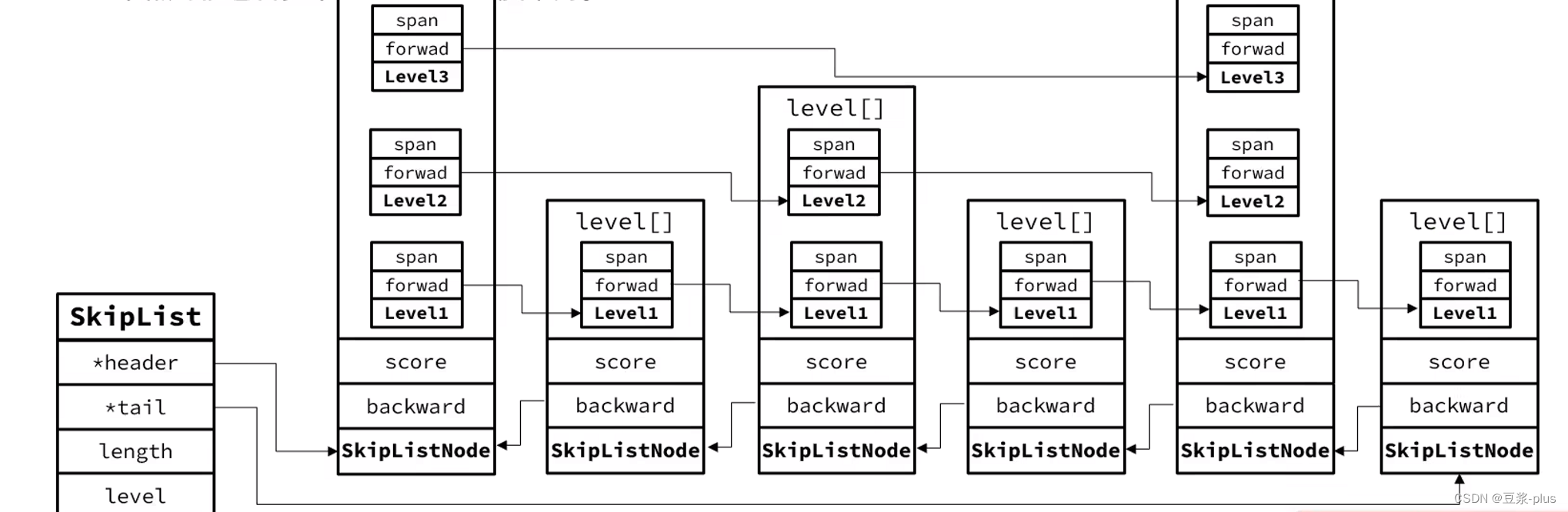
小总结:
SkipList的特点:
- * 跳跃表是一个双向链表,每个节点都包含score和ele值
- * 节点按照score值排序,score值一样则按照ele字典排序
- * 每个节点都可以包含多层指针,层数是1到32之间的随机数
- * 不同层指针到下一个节点的跨度不同,层级越高,跨度越大
- * 增删改查效率与红黑树基本一致,实现却更简单
8.1.6 RedisObject:
Redis中的任意数据类型的键和值都会被封装为一个RedisObject,也叫做Redis对象,源码如下:
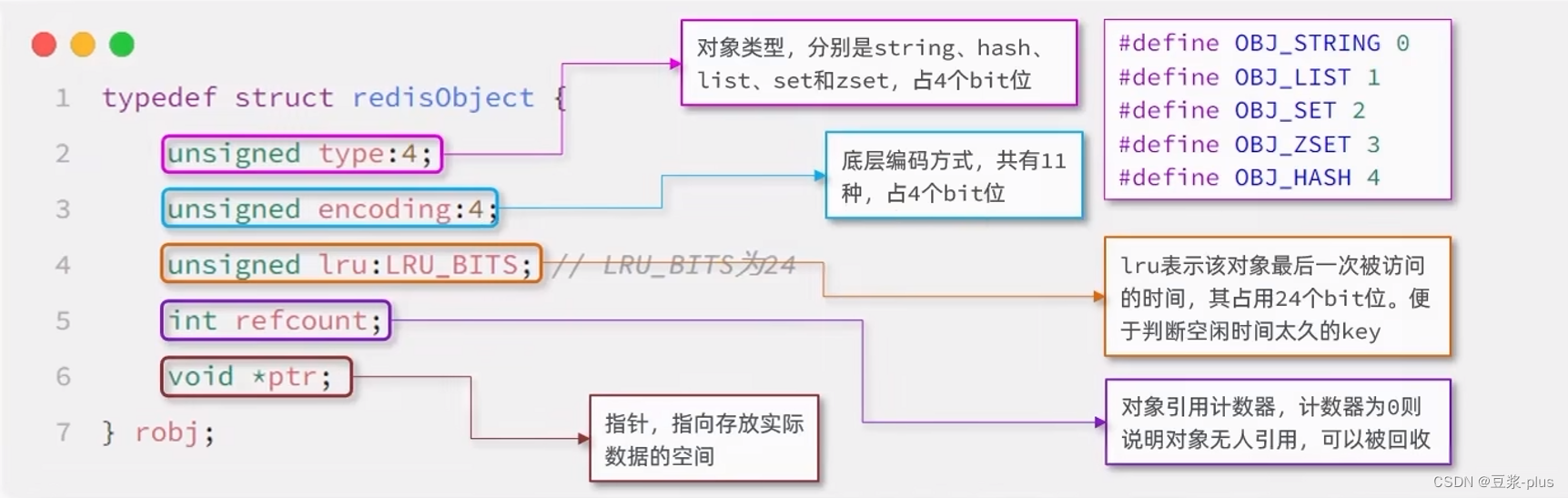
1、什么是redisObject:
从Redis的使用者的角度来看,⼀个Redis节点包含多个database(非cluster模式下默认是16个,cluster模式下只能是1个),而一个database维护了从key space到object space的映射关系。这个映射关系的key是string类型,⽽value可以是多种数据类型,比如:
string, list, hash、set、sorted set等。我们可以看到,key的类型固定是string,而value可能的类型是多个。
⽽从Redis内部实现的⾓度来看,database内的这个映射关系是用⼀个dict来维护的。dict的key固定用⼀种数据结构来表达就够了,这就是动态字符串sds。而value则比较复杂,为了在同⼀个dict内能够存储不同类型的value,这就需要⼀个通⽤的数据结构,这个通用的数据结构就是robj,全名是redisObject。
Redis的编码方式
Redis中会根据存储的数据类型不同,选择不同的编码方式,共包含11种不同类型:
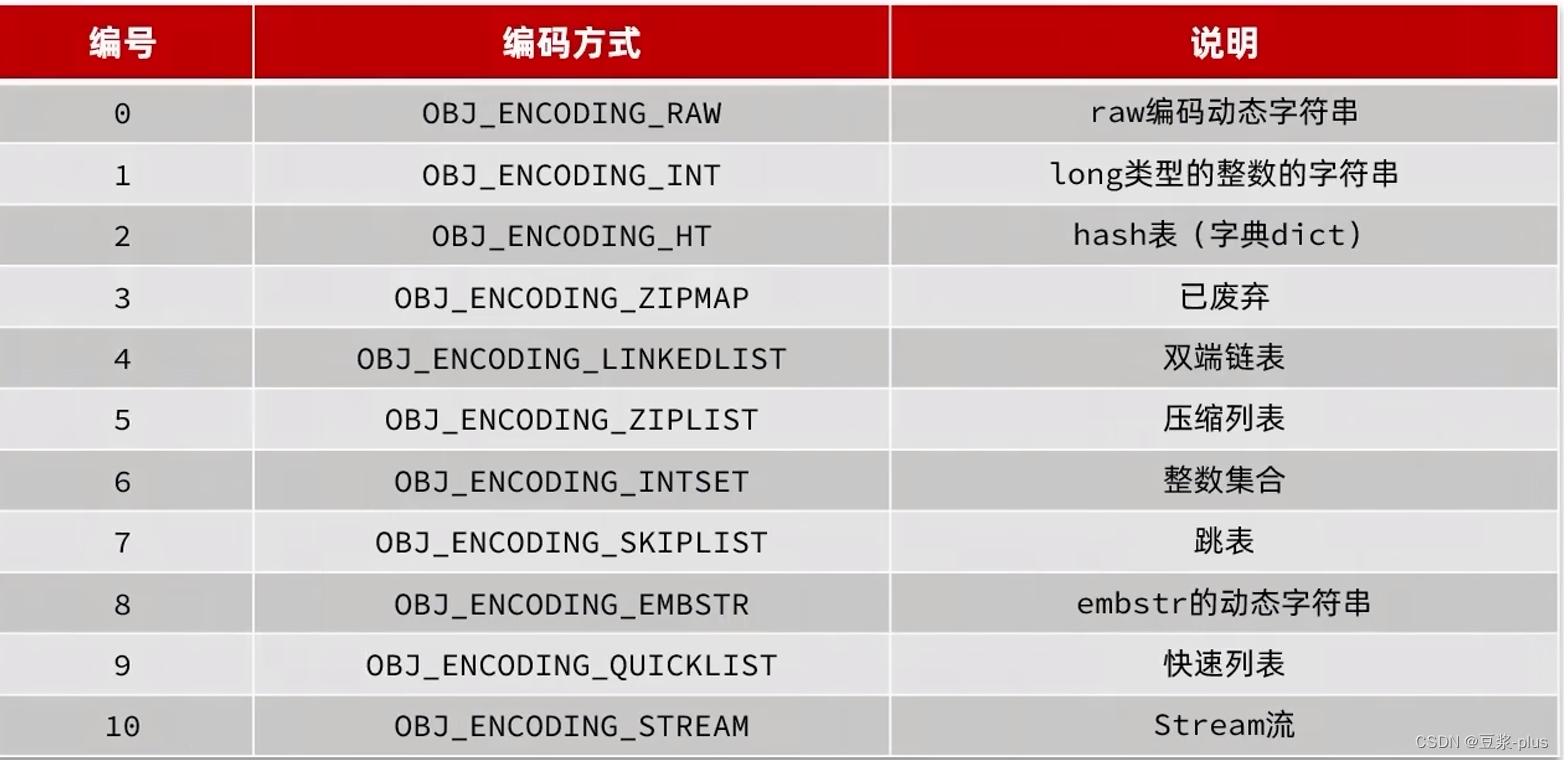
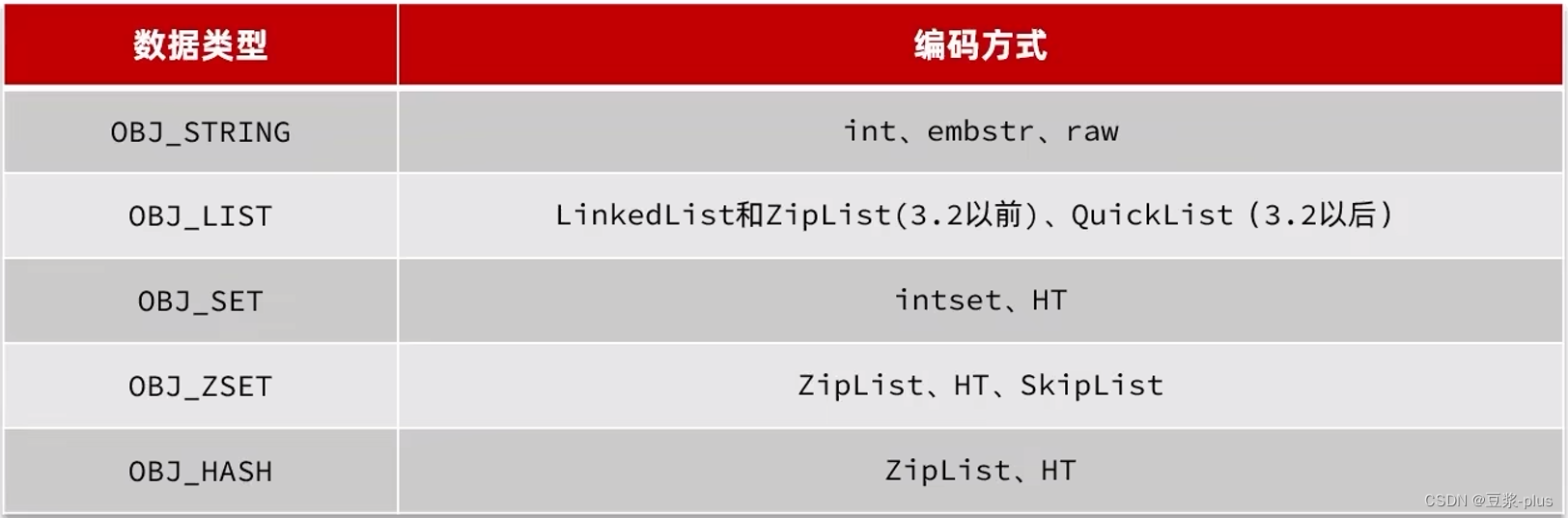
8.1.7 五种数据结构:
##Redis数据结构-String
String是Redis中最常见的数据存储类型:
- 其基本编码方式是RAW,基于简单动态字符串(SDS)实现,存储上限为512mb。
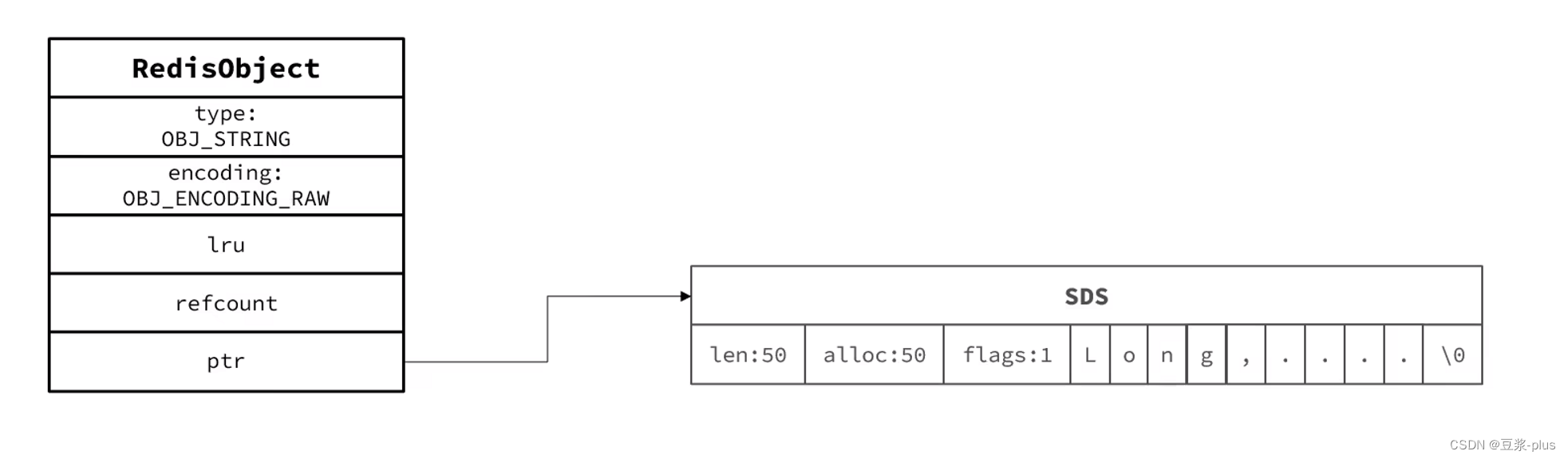
- 如果存储的SDS长度小于44字节,则会采用EMBSTR(embstr)编码,此时object head与SDS是一段连续空间。申请内存时只需要调用一次内存分配函数,效率更高。

- 如果存储的字符串是整数值,并且大小在LONG_MAX范围内,则会采用INT编码:直接将数据保存在Redis Object的ptr指针位置(刚好8字节),不再需要SDS了。

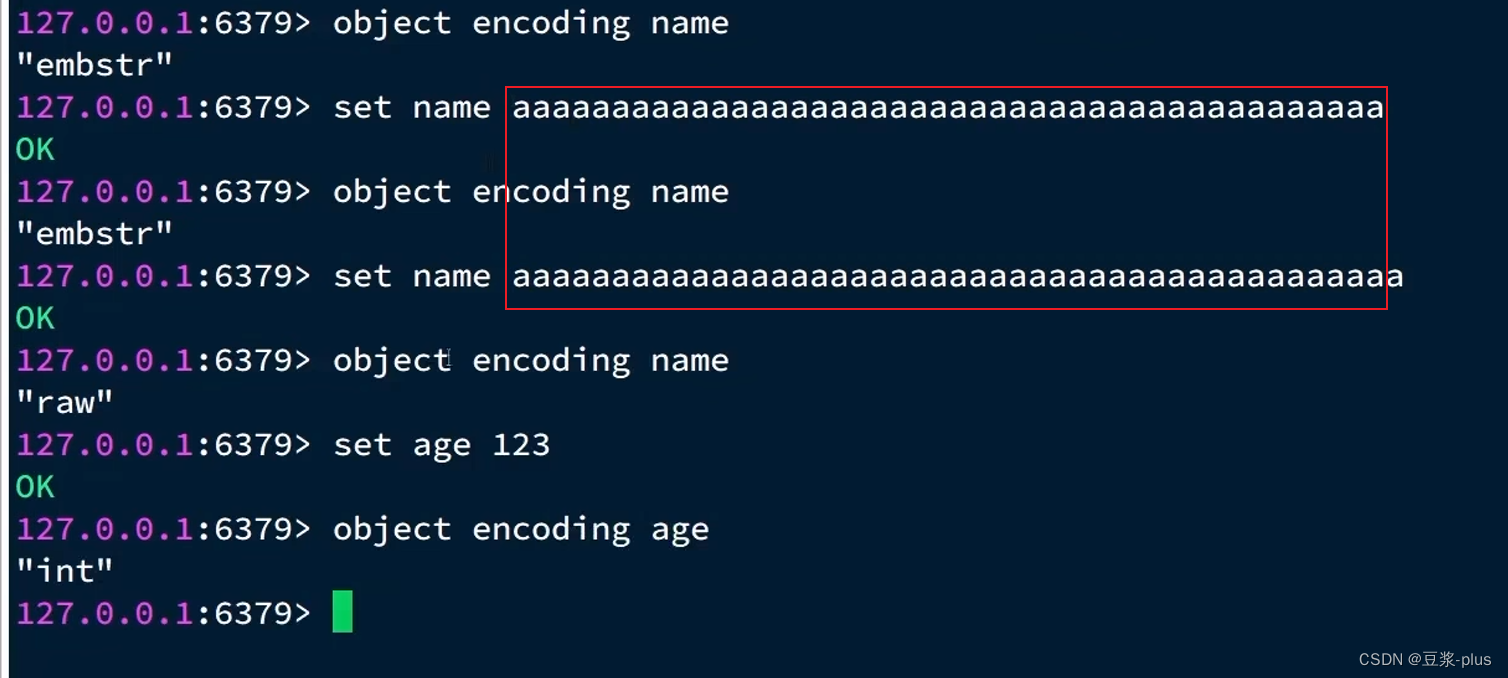
(1)底层实现⽅式:动态字符串sds 或者 long
String的内部存储结构⼀般是sds(Simple Dynamic String,可以动态扩展内存),但是如果⼀个String类型的value的值是数字,那么Redis内部会把它转成long类型来存储,从⽽减少内存的使用。
如果存储的字符串是整数值,并且大小在LONG_MAX范围内,则会采用INT编码:直接将数据保存在RedisObject的ptr指针位置(刚好8字节),不再需要SDS了。
确切地说,String在Redis中是⽤⼀个robj来表示的。
用来表示String的robj可能编码成3种内部表⽰:OBJ_ENCODING_RAW,OBJ_ENCODING_EMBSTR,OBJ_ENCODING_INT。
其中前两种编码使⽤的是sds来存储,最后⼀种OBJ_ENCODING_INT编码直接把string存成了long型。
在对string进行incr, decr等操作的时候,如果它内部是OBJ_ENCODING_INT编码,那么可以直接行加减操作;如果它内部是OBJ_ENCODING_RAW或OBJ_ENCODING_EMBSTR编码,那么Redis会先试图把sds存储的字符串转成long型,如果能转成功,再进行加减操作。对⼀个内部表示成long型的string执行append, setbit, getrange这些命令,针对的仍然是string的值(即⼗进制表示的字符串),而不是针对内部表⽰的long型进⾏操作。比如字符串”32”,如果按照字符数组来解释,它包含两个字符,它们的ASCII码分别是0x33和0x32。当我们执行命令setbit key 7 0的时候,相当于把字符0x33变成了0x32,这样字符串的值就变成了”22”。⽽如果将字符串”32”按照内部的64位long型来解释,那么它是0x0000000000000020,在这个基础上执⾏setbit位操作,结果就完全不对了。因此,在这些命令的实现中,会把long型先转成字符串再进行相应的操作。
##Redis数据结构-List
Redis的List类型可以从首、尾操作列表中的元素:
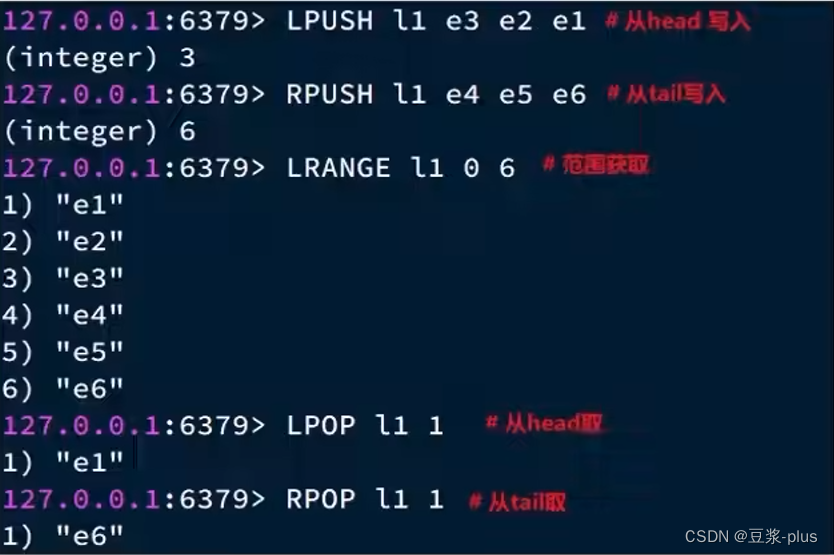
哪一个数据结构能满足上述特征?
- * LinkedList :普通链表,可以从双端访问,内存占用较高,内存碎片较多
- * ZipList :压缩列表,可以从双端访问,内存占用低,存储上限低
- * QuickList:LinkedList + ZipList,可以从双端访问,内存占用较低,包含多个ZipList,存储上限高
Redis的List结构类似一个双端链表,可以从首、尾操作列表中的元素:
在3.2版本之前,Redis采用ZipList和LinkedList来实现List,当元素数量小于512并且元素大小小于64字节时采用ZipList编码,超过则采用LinkedList编码。
在3.2版本之后,Redis统一采用QuickList来实现List:
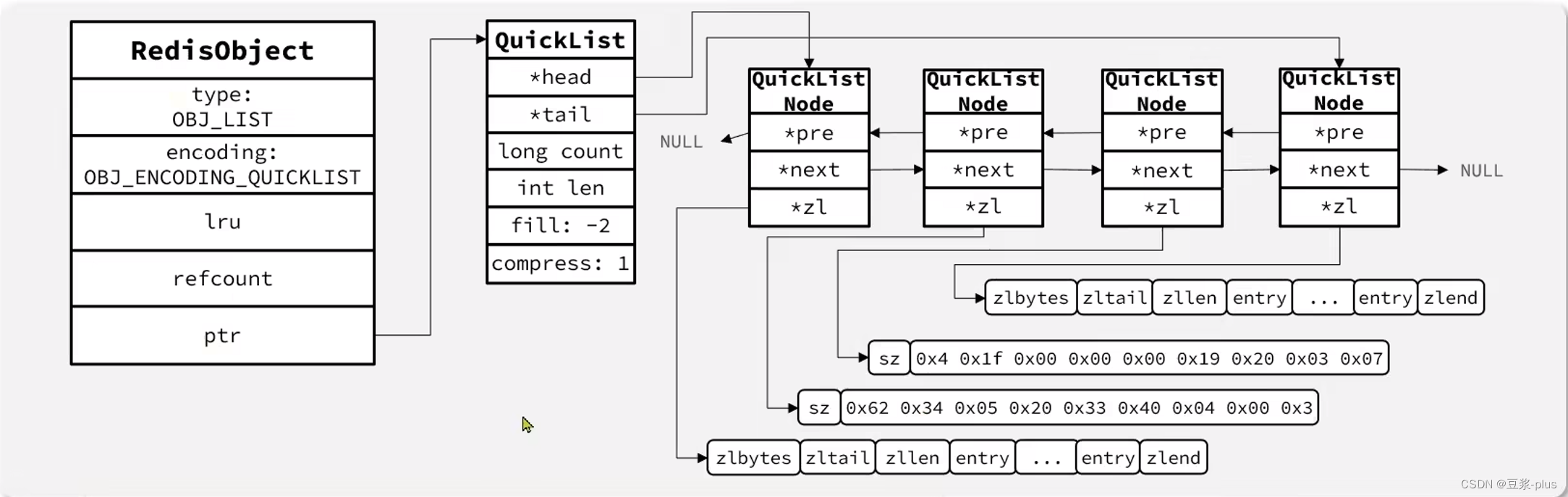
### Redis数据结构-Set结构
Set是Redis中的单列集合,满足下列特点:
- * 不保证有序性
- * 保证元素唯一
- * 求交集、并集、差集
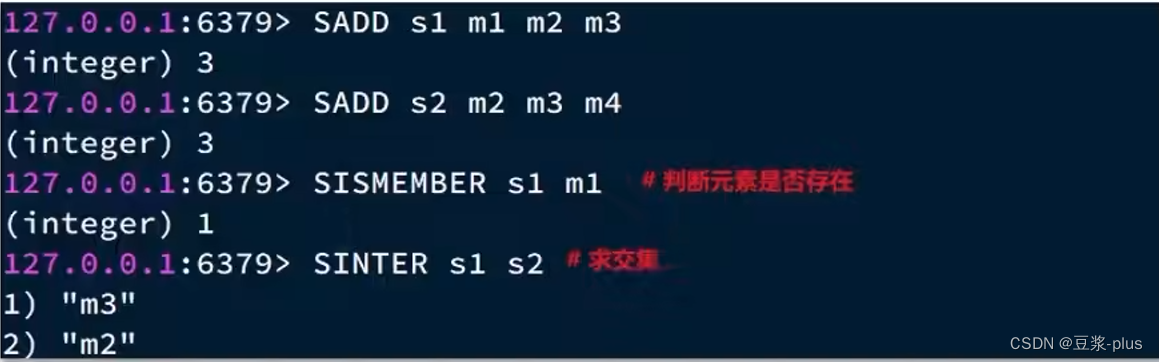
可以看出,Set对查询元素的效率要求非常高,思考一下,什么样的数据结构可以满足?
- HashTable,也就是Redis中的Dict,不过Dict是双列集合(可以存键、值对)
Set是Redis中的集合,不一定确保元素有序,可以满足元素唯一、查询效率要求极高。
- 为了查询效率和唯一性,set采用HT编码(Dict)。Dict中的key用来存储元素,value统一为null。
- 当存储的所有数据都是整数,并且元素数量不超过set-max-intset-entries时,Set会采用IntSet编码,以节省内存
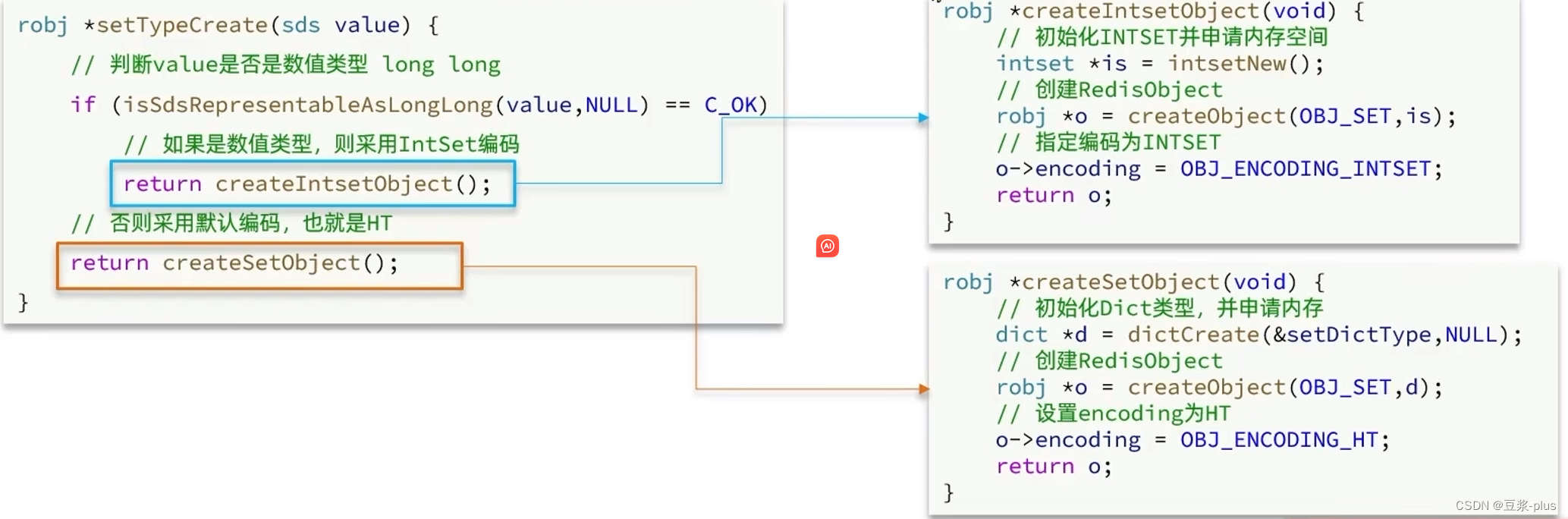
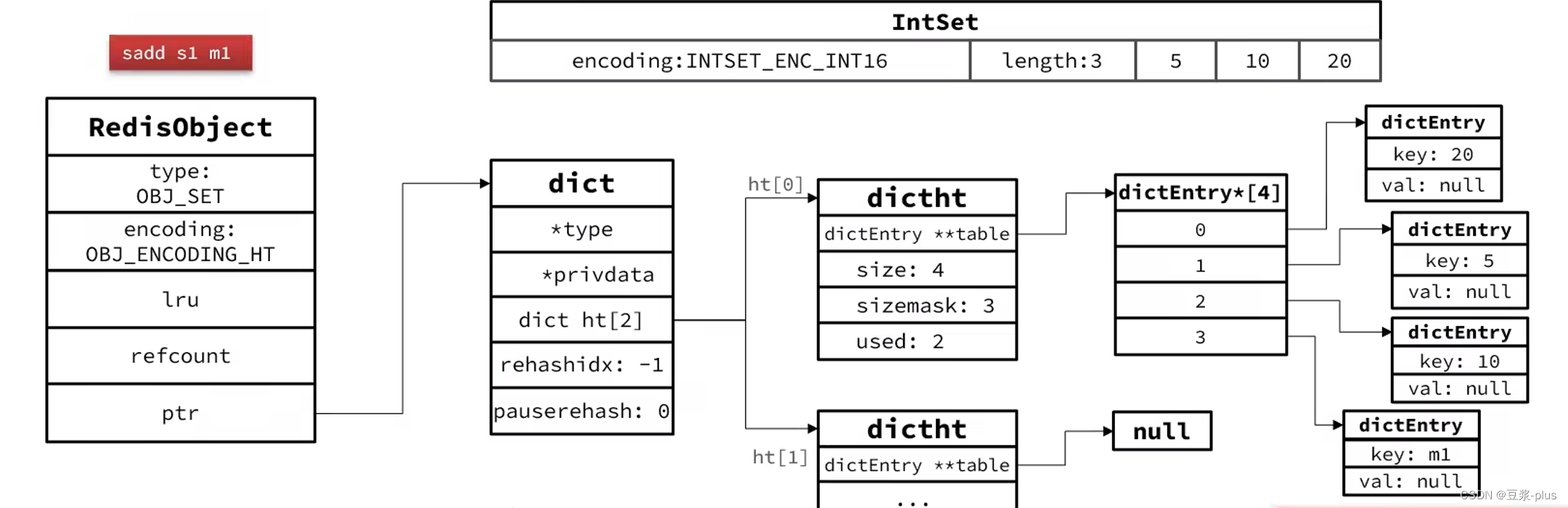
结构如下:
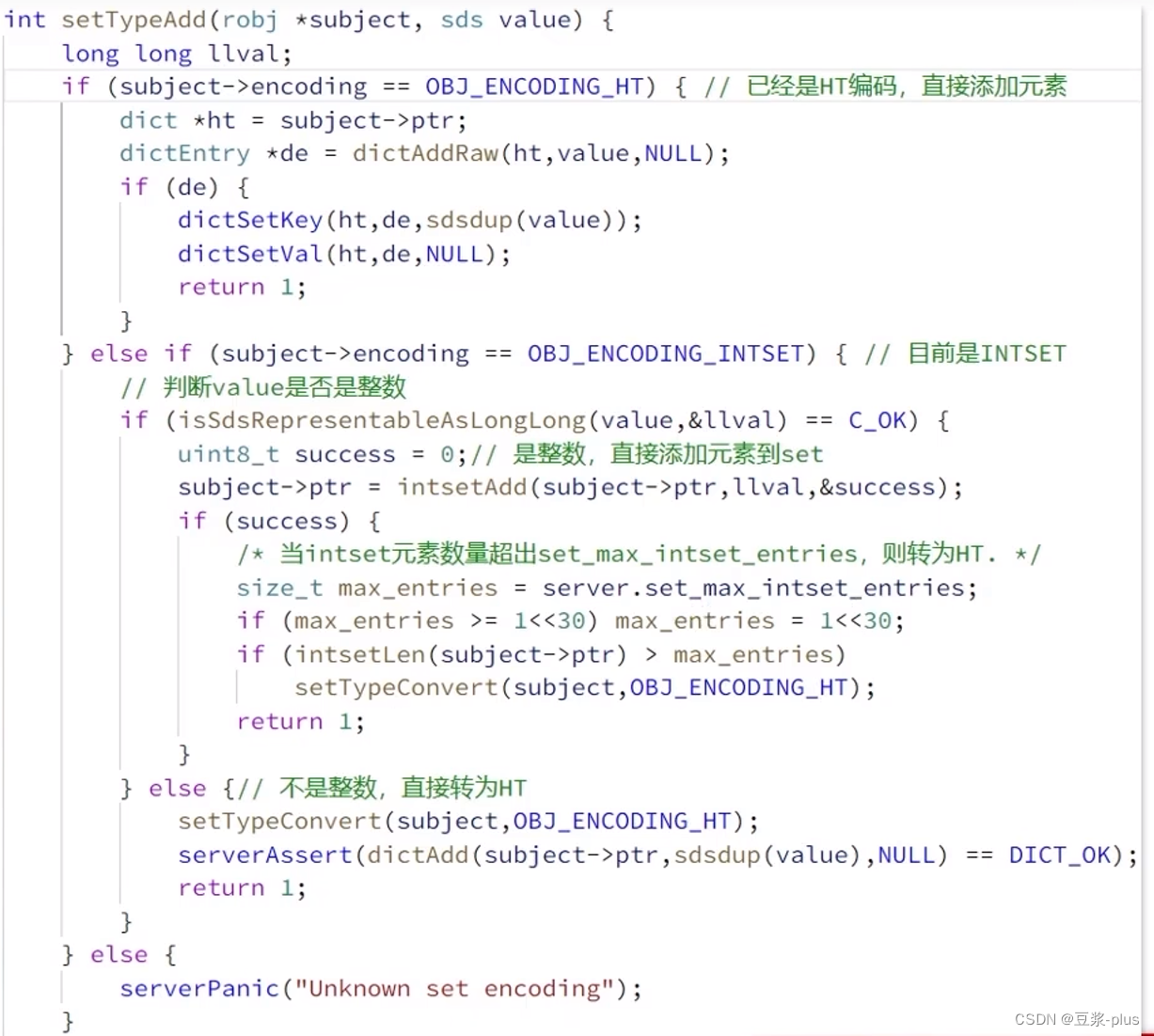

###Redis数据结构-ZSET
ZSet也就是SortedSet,其中每一个元素都需要指定一个score值和member值:
- * 可以根据score值排序后
- * member必须唯一
- * 可以根据member查询分数

因此,zset底层数据结构必须满足键值存储、键必须唯一、可排序这几个需求。之前学习的哪种编码结构可以满足?
- * SkipList:可以排序,并且可以同时存储score和ele值(member)
- * HT(Dict):可以键值存储,并且可以根据key找value
同时两种:

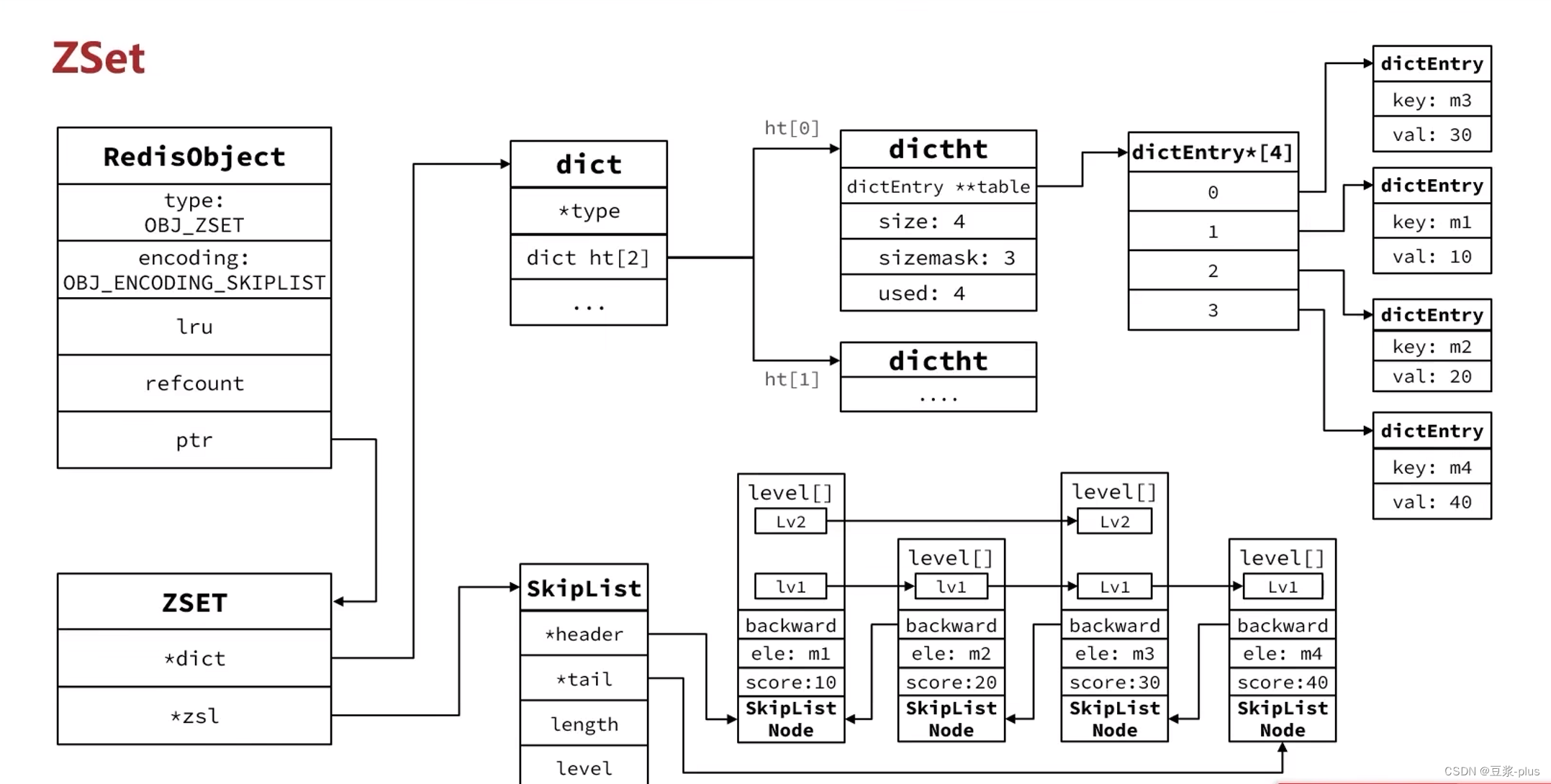
当元素数量不多时,HT和SkipList的优势不明显,而且更耗内存。因此zset还会采用ZipList结构来节省内存,不过需要同时满足两个条件:
- * 元素数量小于zset_max_ziplist_entries,默认值128
- * 每个元素都小于zset_max_ziplist_value字节,默认值64
ziplist本身没有排序功能,而且没有键值对的概念,因此需要有zset通过编码实现:
- * ZipList是连续内存,因此score和element是紧挨在一起的两个entry, element在前,score在后
- * score越小越接近队首,score越大越接近队尾,按照score值升序排列
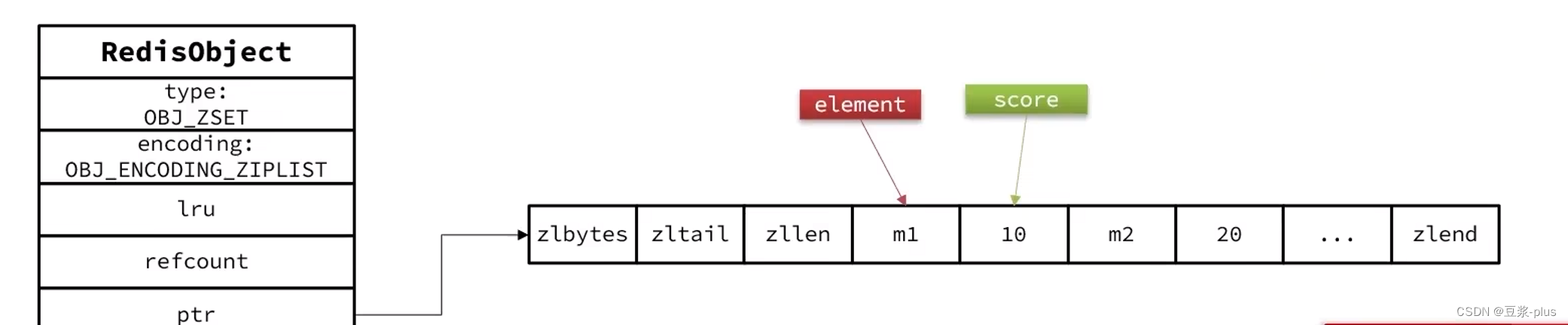
### Redis数据结构-Hash
Hash结构与Redis中的Zset非常类似:
- * 都是键值存储
- * 都需求根据键获取值
- * 键必须唯一
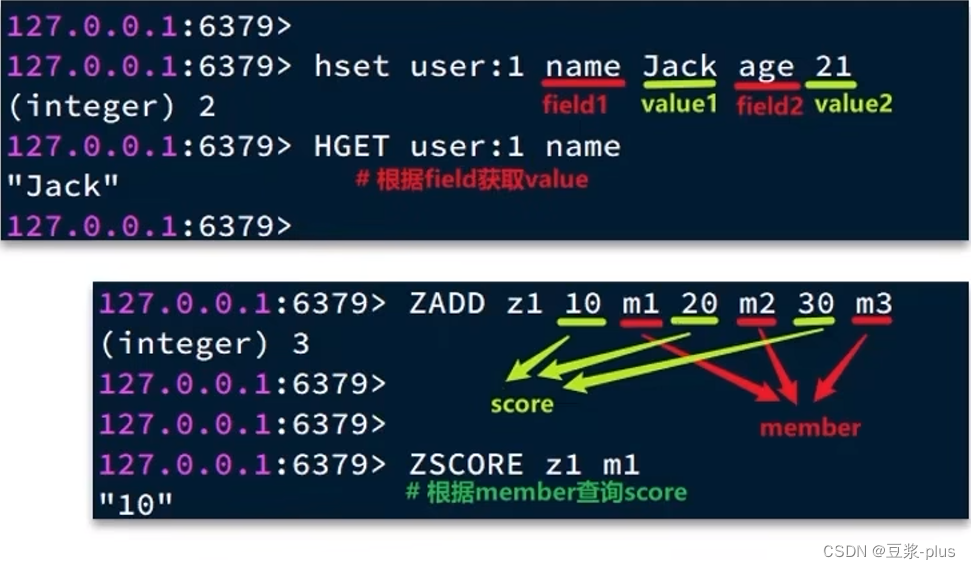
区别如下:
- * zset的键是member,值是score;hash的键和值都是任意值
- * zset要根据score排序;hash则无需排序
(1)底层实现方式:压缩列表ziplist 或者 字典dict
当Hash中数据项比较少的情况下,Hash底层才⽤压缩列表ziplist进⾏存储数据,随着数据的增加,底层的ziplist就可能会转成dict,具体配置如下:
- hash-max-ziplist-entries 512
- hash-max-ziplist-value 64
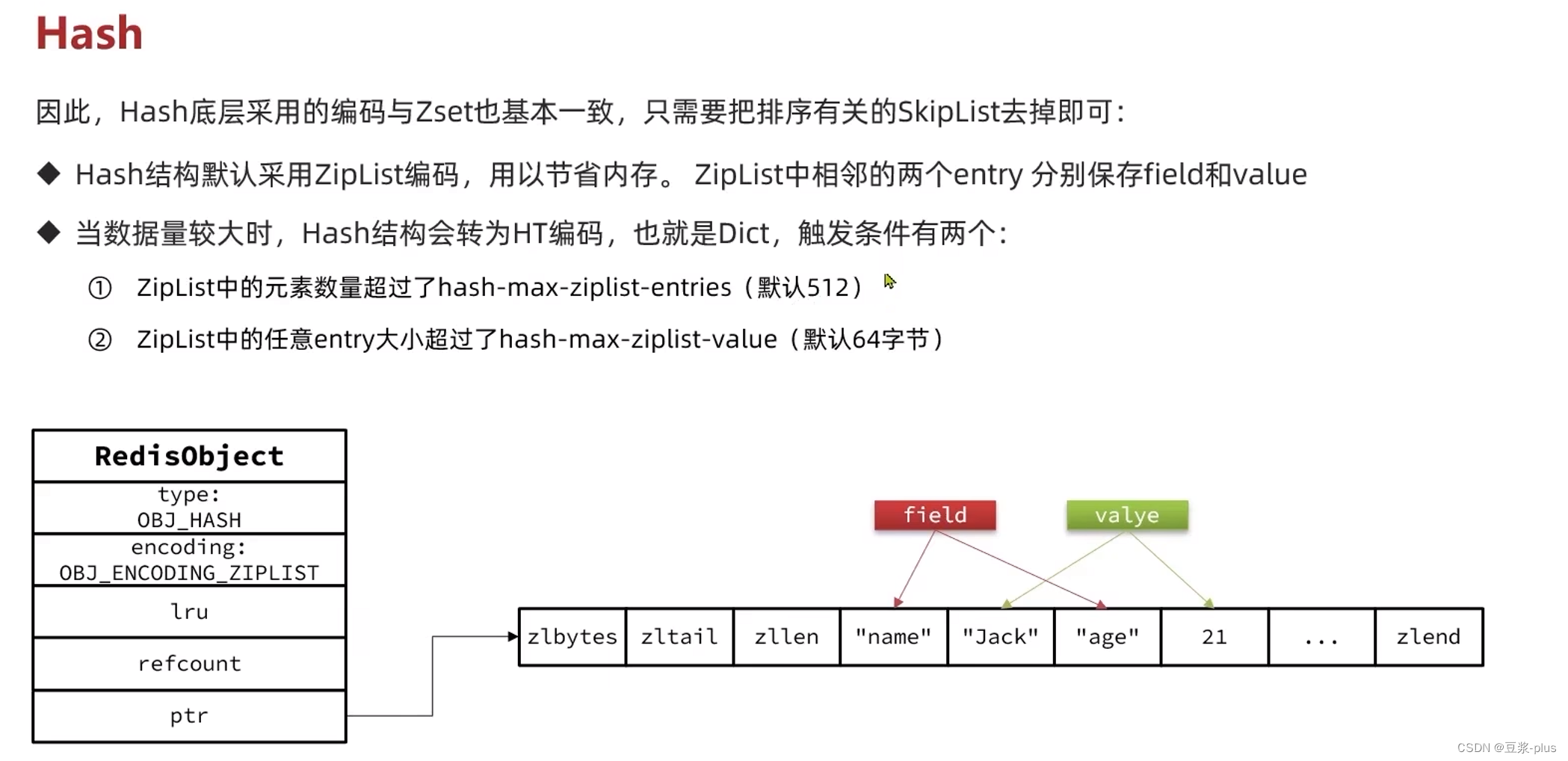
当满足上面两个条件其中之⼀的时候,Redis就使⽤dict字典来实现hash。
Redis的hash之所以这样设计,是因为当ziplist变得很⼤的时候,它有如下几个缺点:
- * 每次插⼊或修改引发的realloc操作会有更⼤的概率造成内存拷贝,从而降低性能。
- * ⼀旦发生内存拷贝,内存拷贝的成本也相应增加,因为要拷贝更⼤的⼀块数据。
- * 当ziplist数据项过多的时候,在它上⾯查找指定的数据项就会性能变得很低,因为ziplist上的查找需要进行遍历。
总之,ziplist本来就设计为各个数据项挨在⼀起组成连续的内存空间,这种结构并不擅长做修改操作。⼀旦数据发⽣改动,就会引发内存realloc,可能导致内存拷贝。
8.2 网络模型
8.2.1用户空间和内核空间
服务器大多都采用Linux系统,这里我们以Linux为例来讲解:

ubuntu和Centos 都是Linux的发行版,发行版可以看成对linux包了一层壳,任何Linux发行版,其系统内核都是Linux。我们的应用都需要通过Linux内核与硬件交互

用户的应用,比如redis,mysql等其实是没有办法去执行访问我们操作系统的硬件的,所以我们可以通过发行版的这个壳子去访问内核,再通过内核去访问计算机硬件
计算机硬件包括,如cpu,内存,网卡等等,内核(通过寻址空间)可以操作硬件的,但是内核需要不同设备的驱动,有了这些驱动之后,内核就可以去对计算机硬件去进行 内存管理,文件系统的管理,进程的管理等等
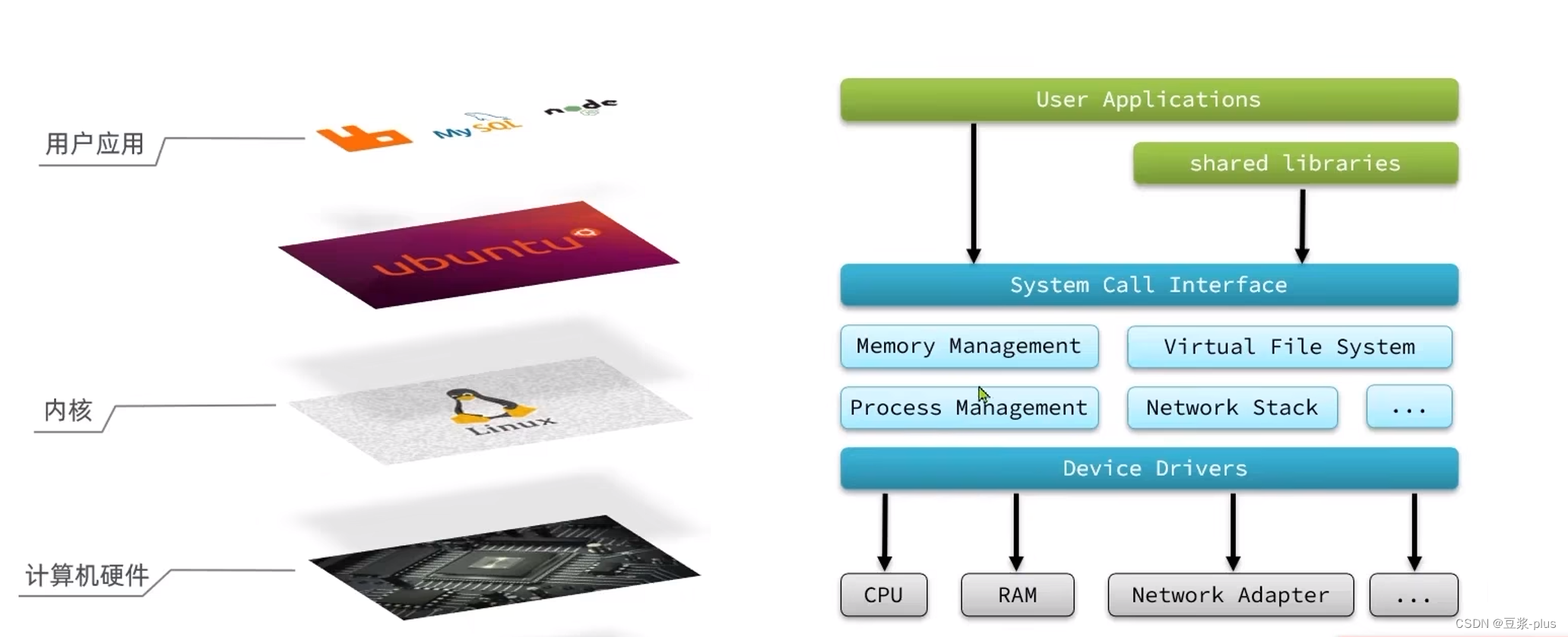
我们想要用户的应用来访问,计算机就必须要通过对外暴露的一些接口,才能访问到,从而简介的实现对内核的操控,但是内核本身上来说也是一个应用,所以他本身也需要一些内存,cpu等设备资源,用户应用本身也在消耗这些资源,如果不加任何限制,用户去操作随意的去操作我们的资源,就有可能导致一些冲突,甚至有可能导致我们的系统出现无法运行的问题,因此我们需要把用户和**内核隔离开**
进程的寻址空间划分成两部分:**内核空间、用户空间**
什么是寻址空间呢?我们的应用程序也好,还是内核空间也好,都是没有办法直接去物理内存的,而是通过分配一些虚拟内存映射到物理内存中,我们的内核和应用程序去访问虚拟内存的时候,就需要一个虚拟地址,这个地址是一个无符号的整数,比如一个32位的操作系统,他的带宽就是32,他的虚拟地址就是2的32次方,也就是说他寻址的范围就是0~2的32次方, 这片寻址空间对应的就是2的32个字节,就是4GB,这个4GB,会有3个GB分给用户空间,会有1GB给内核系统
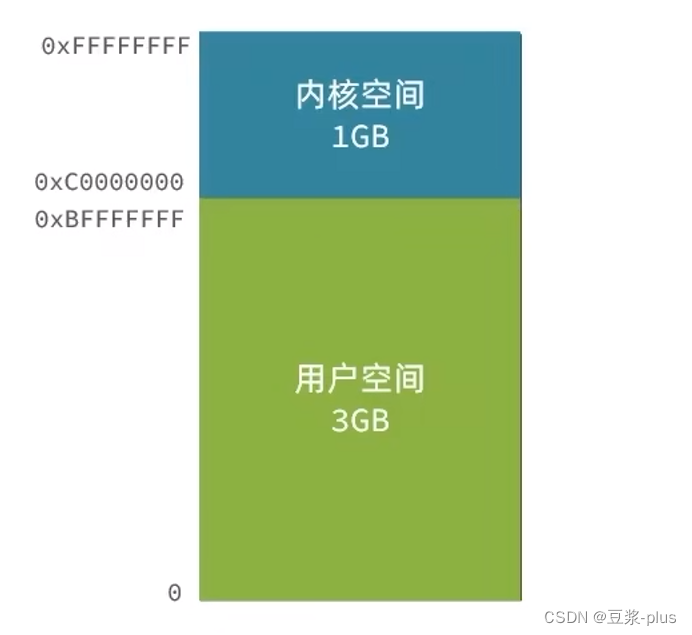
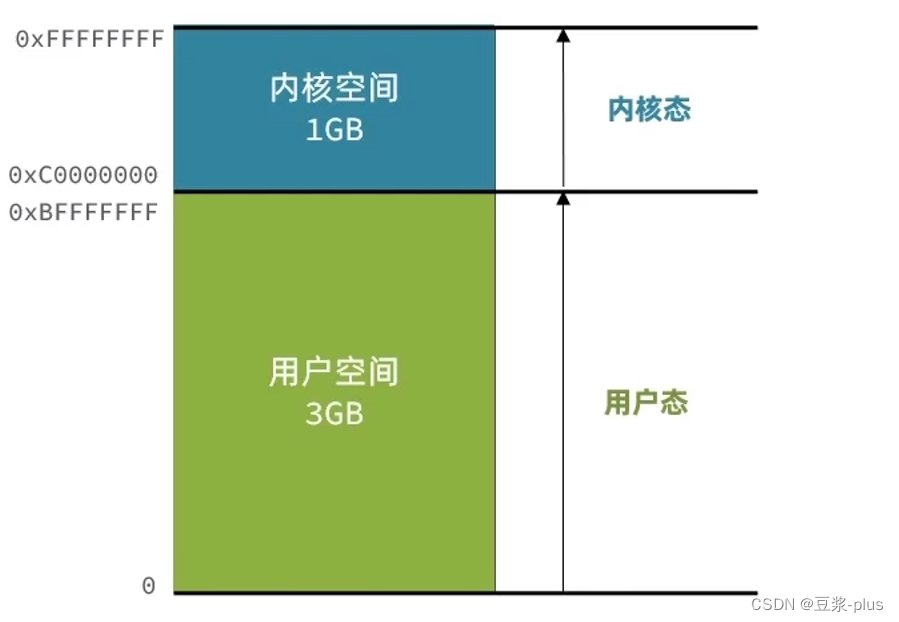
在linux中,他们权限分成两个等级,0和3,用户空间只能执行受限的命令(Ring3),而且不能直接调用系统资源,必须通过内核提供的接口来访问内核空间可以执行特权命令(Ring0),调用一切系统资源,所以一般情况下,用户的操作是运行在用户空间,而内核运行的数据是在内核空间的,而有的情况下,一个应用程序需要去调用一些特权资源,去调用一些内核空间的操作,所以此时他俩需要在用户态和内核态之间进行切换。

比如:
Linux系统为了提高IO效率,会在用户空间和内核空间都加入缓冲区:
- 写数据时,要把用户缓冲数据拷贝到内核缓冲区,然后写入设备
- 读数据时,要从设备读取数据到内核缓冲区,然后拷贝到用户缓冲区
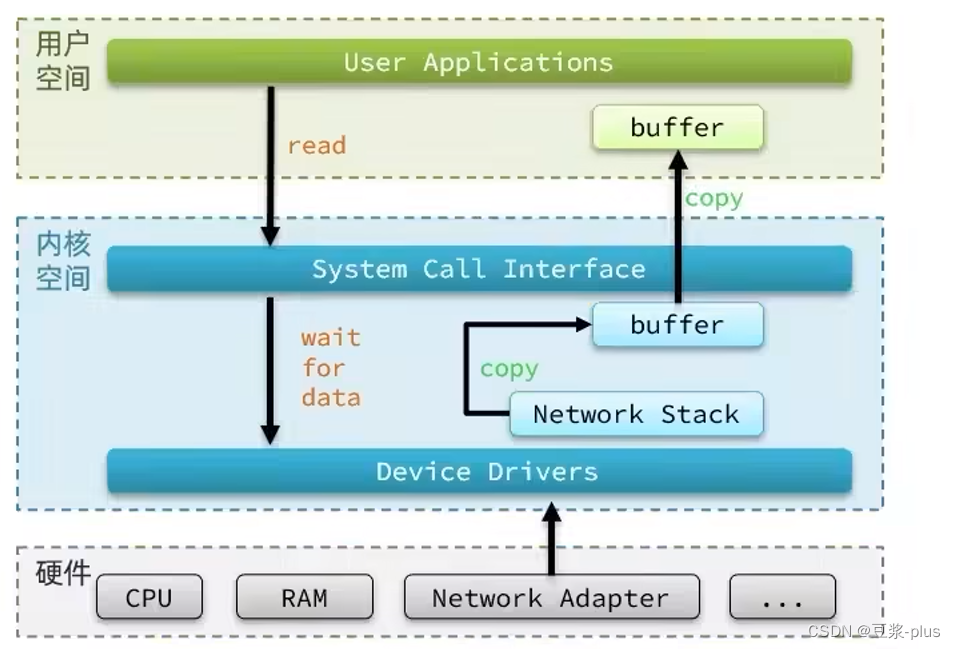
针对这个操作:我们的用户在写读数据时,会去向内核态申请,想要读取内核的数据,而内核数据要去等待驱动程序从硬件上读取数据,当从磁盘上加载到数据之后,内核会将数据写入到内核的缓冲区中,然后再将数据拷贝到用户态的buffer中,然后再返回给应用程序,整体而言,速度慢,就是这个原因,为了加速,我们希望read也好,还是wait for data也最好都不要等待,或者时间尽量的短。
8.2.2 阻塞IO
在《UNIX网络编程》一书中,总结归纳了5种IO模型:
- * 阻塞IO(Blocking IO)
- * 非阻塞IO(Nonblocking IO)
- * IO多路复用(IO Multiplexing)
- * 信号驱动IO(Signal Driven IO)
- * 异步IO(Asynchronous IO)
应用程序想要去读取数据,他是无法直接去读取磁盘数据的,他需要先到内核里边去等待内核操作硬件拿到数据,这个过程就是1,是需要等待的,等到内核从磁盘上把数据加载出来之后,再把这个数据写给用户的缓存区,这个过程是2,如果是阻塞IO,那么整个过程中,用户从发起读请求开始,一直到读取到数据,都是一个阻塞状态。
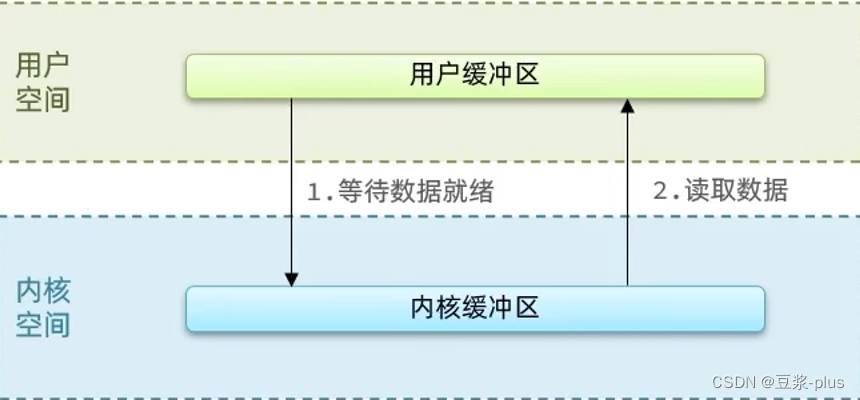
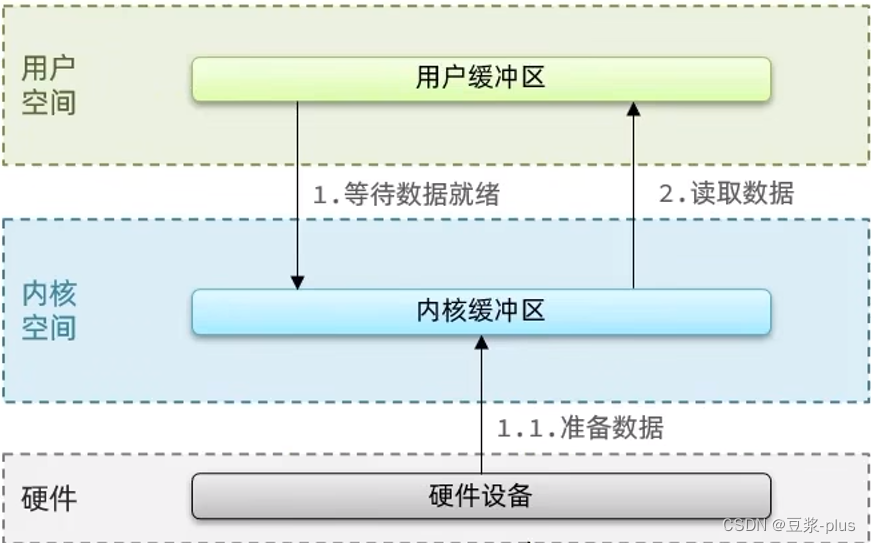
具体流程如下图:
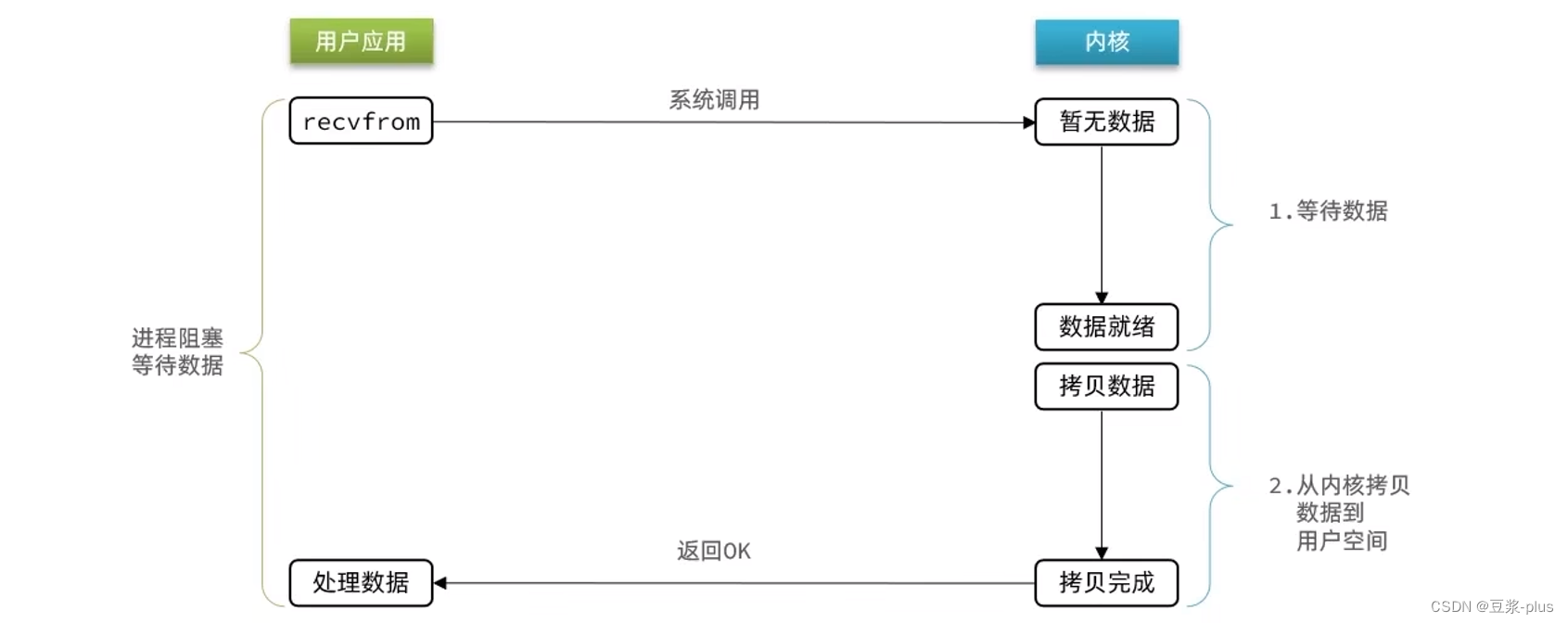
用户去读取数据时,会去先发起recvform一个命令,去尝试从内核上加载数据,如果内核没有数据,那么用户就会等待,此时内核会去从硬件上读取数据,内核读取数据之后,会把数据拷贝到用户态,并且返回ok,整个过程,都是阻塞等待的,这就是阻塞IO
总结如下:
顾名思义,阻塞IO就是两个阶段都必须阻塞等待:
**阶段一:**
- - 用户进程尝试读取数据(比如网卡数据)
- - 此时数据尚未到达,内核需要等待数据
- - 此时用户进程也处于阻塞状态
阶段二:
- * 数据到达并拷贝到内核缓冲区,代表已就绪
- * 将内核数据拷贝到用户缓冲区
- * 拷贝过程中,用户进程依然阻塞等待
- * 拷贝完成,用户进程解除阻塞,处理数据
可以看到,阻塞IO模型中,用户进程在两个阶段都是阻塞状态。
8.2.3 非阻塞IO
顾名思义,非阻塞IO的recvfrom操作会立即返回结果而不是阻塞用户进程。
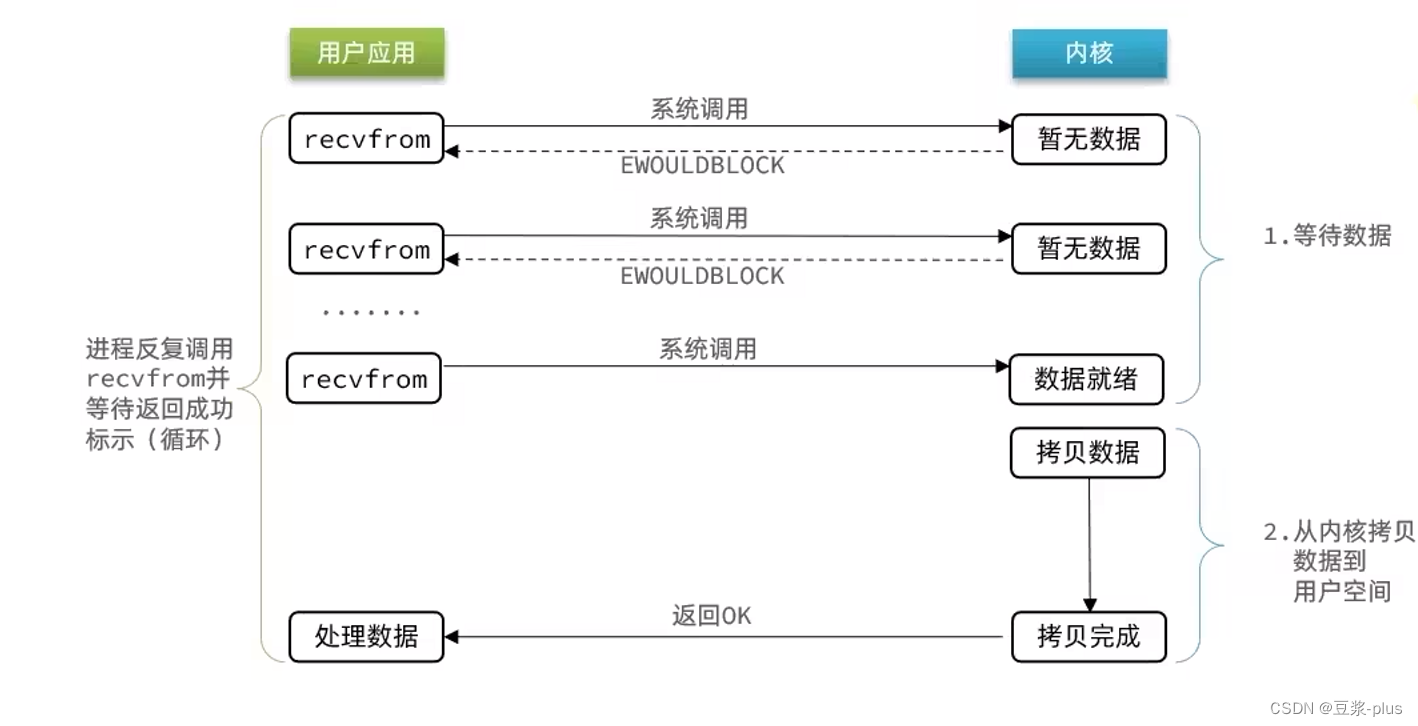
阶段一:
- * 用户进程尝试读取数据(比如网卡数据)
- * 此时数据尚未到达,内核需要等待数据
- * 返回异常给用户进程
- * 用户进程拿到error后,再次尝试读取
- * 循环往复,直到数据就绪
阶段二:
- * 将内核数据拷贝到用户缓冲区
- * 拷贝过程中,用户进程依然阻塞等待
- * 拷贝完成,用户进程解除阻塞,处理数据
- * 可以看到,非阻塞IO模型中,用户进程在第一个阶段是非阻塞,第二个阶段是阻塞状态。虽然是非阻塞,但性能并没有得到提高。而且忙等机制会导致CPU空转,CPU使用率暴增。
8.2.4 I0多路复用(面试)
无论是阻塞IO还是非阻塞IO,用户应用在一阶段都需要调用recvfrom来获取数据,差别在于无数据时的处理方案:
- 如果调用recvfrom时,恰好没有数据,阻塞IO会使CPU阻塞,非阻塞IO使CPU空转,都不能充分发挥CPU的作用。
- 如果调用recvfrom时,恰好有数据,则用户进程可以直接进入第二阶段,读取并处理数据
所以怎么看起来以上两种方式性能都不好
而在单线程情况下,只能依次处理IO事件,如果正在处理的IO事件恰好未就绪(数据不可读或不可写),线程就会被阻塞,所有IO事件都必须等待,性能自然会很差。
就比如服务员给顾客点餐,**分两步**:
- * 顾客思考要吃什么(等待数据就绪)
- * 顾客想好了,开始点餐(读取数据)
要提高效率有几种办法?
方案一:增加更多服务员(多线程)
方案二:不排队,谁想好了吃什么(数据就绪了),服务员就给谁点餐(用户应用就去读取数据)
那么问题来了:用户进程如何知道内核中数据是否就绪呢?
所以接下来就需要详细的来解决多路复用模型是如何知道到底怎么知道内核数据是否就绪的问题了
这个问题的解决依赖于提出的文件描述符(File Descriptor):简称FD,是一个从0 开始的无符号整数,用来关联Linux中的一个文件。在Linux中,一切皆文件,例如常规文件、视频、硬件设备等,当然也包括网络套接字(Socket)。
通过FD,我们的网络模型可以利用一个线程监听多个FD,并在某个FD可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源。
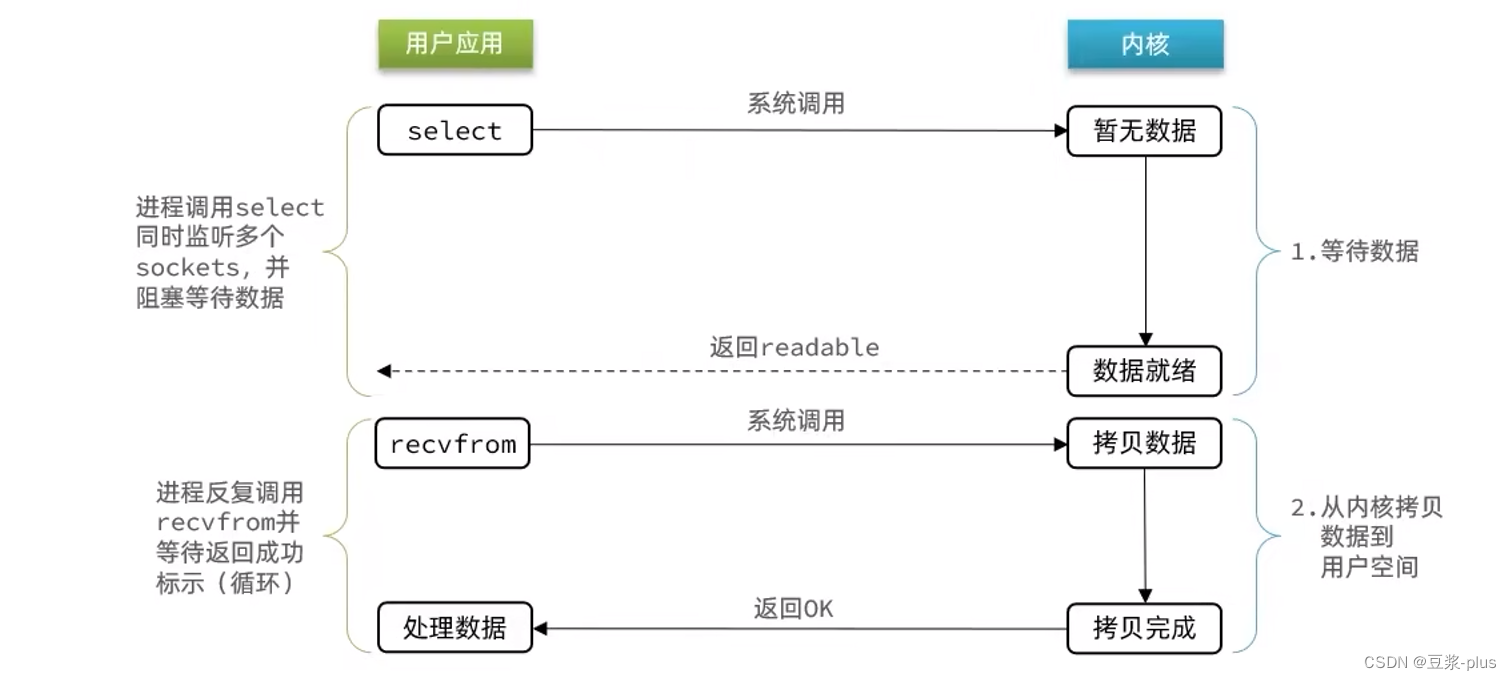
阶段一:
- * 用户进程调用select,指定要监听的FD集合
- * 核监听FD对应的多个socket
- * 任意一个或多个socket数据就绪则返回readable
- * 此过程中用户进程阻塞
阶段二:
- * 用户进程找到就绪的socket
- * 依次调用recvfrom读取数据
- * 内核将数据拷贝到用户空间
- * 用户进程处理数据
当用户去读取数据的时候,不再去直接调用recvfrom了,而是调用select的函数,select函数会将需要监听的数据交给内核,由内核去检查这些数据是否就绪了,如果说这个数据就绪了,就会通知应用程序数据就绪,然后来读取数据,再从内核中把数据拷贝给用户态,完成数据处理,如果N多个FD一个都没处理完,此时就进行等待。
用IO复用模式,可以确保去读数据的时候,数据是一定存在的,他的效率比原来的阻塞IO和非阻塞IO性能都要高
IO多路复用是利用单个线程来同时监听多个FD,并在某个FD可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源。不过监听FD的方式、通知的方式又有多种实现,常见的有:
- - select
- - poll
- - epoll
- 其中select和pool相当于是当被监听的数据准备好之后,他会把你监听的FD整个数据都发给你,你需要到整个FD中去找,哪些是处理好了的,需要通过遍历的方式,所以性能也并不是那么好
- 而epoll,则相当于内核准备好了之后,他会把准备好的数据,直接发给你,咱们就省去了遍历的动作。
###IO多路复用-select方式
select是Linux最早是由的I/O多路复用技术:

简单说,就是我们把需要处理的数据封装成FD,然后在用户态时创建一个fd的集合(这个集合的大小是要监听的那个FD的最大值+1,但是大小整体是有限制的 ),这个集合的长度大小是有限制的,同时在这个集合中,标明出来我们要控制哪些数据,
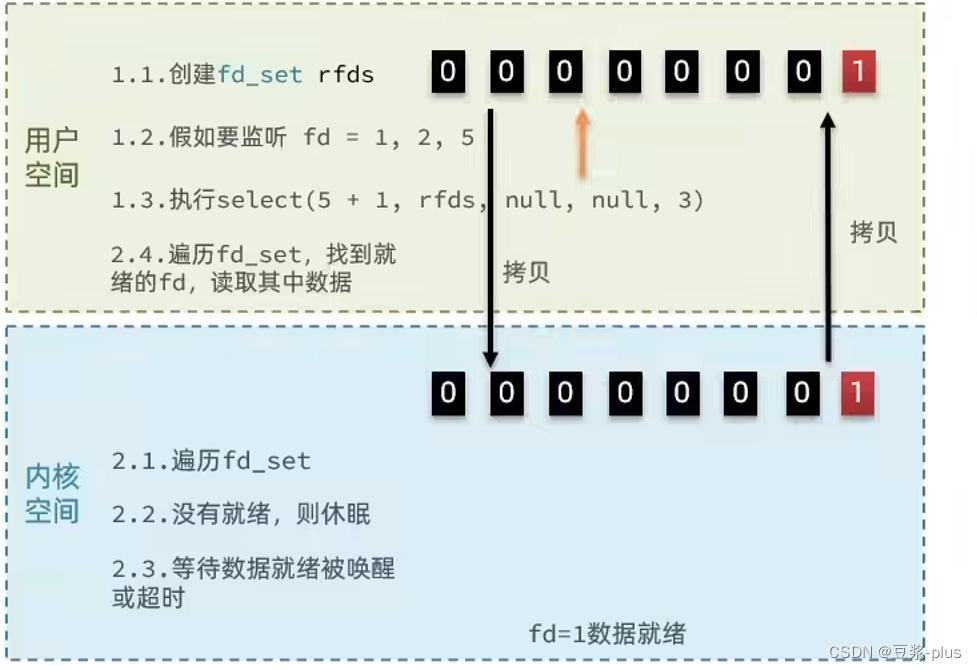
比如要监听的数据,是1,2,5三个数据,此时会执行select函数,然后将整个fd发给内核态,内核态会去遍历用户态传递过来的数据,如果发现这里边都数据都没有就绪,就休眠,直到有数据准备好时,就会被唤醒,唤醒之后,再次遍历一遍,看看谁准备好了,然后再将处理掉没有准备好的数据,最后再将这个FD集合写回到用户态中去,此时用户态就知道了,奥,有人准备好了,但是对于用户态而言,并不知道谁处理好了,所以用户态也需要去进行遍历,然后找到对应准备好数据的节点,再去发起读请求,我们会发现,这种模式下他虽然比阻塞IO和非阻塞IO好,但是依然有些麻烦的事情, 比如说频繁的传递fd集合,频繁的去遍历FD等问题
select模式存在的问题:
- 需要将整个fd_set从用户空间拷贝到内核空间,select结束还要再次拷贝回用户空间
- select无法得知具体是哪个fd就绪,需要遍历整个fd_set
- fd_set监听的fd数量不能超过1024
### 网络模型-IO多路复用模型-poll模式
poll模式对select模式做了简单改进,但性能提升不明显,部分关键代码如下:

IO流程:
- * 创建pollfd数组,向其中添加关注的fd信息,数组大小自定义
- * 调用poll函数,将pollfd数组拷贝到内核空间,转链表存储,无上限
- * 内核遍历fd,判断是否就绪
- * 数据就绪或超时后,拷贝pollfd数组到用户空间,返回就绪fd数量n
- * 用户进程判断n是否大于0
- *大于0则遍历pollfd数组,找到就绪的fd
**与select对比:**
- * select模式中的fd_set大小固定为1024,而pollfd在内核中采用链表,理论上无上限
- * 监听FD越多,每次遍历消耗时间也越久,性能反而会下降
### 网络模型-IO多路复用模型-epoll函数
epoll模式是对select和poll的改进,它提供了三个函数:
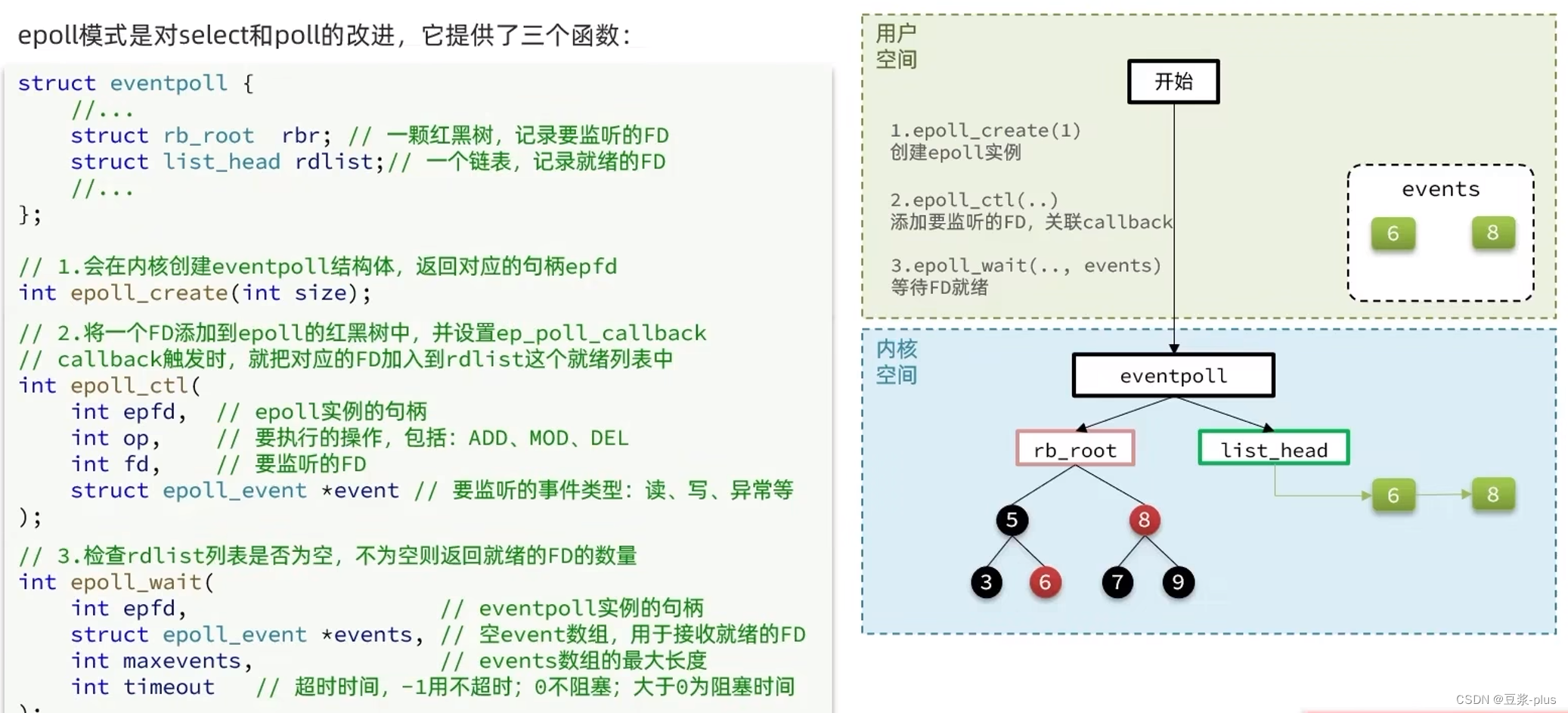
第一个是:eventpoll的函数,他内部包含两个东西
- 1、红黑树-> 记录的事要监听的FD
- 2、一个是链表->一个链表,记录的是就绪的FD
2、调用epoll_ctl函数
紧接着调用epoll_ctl操作,将要监听的数据添加到红黑树上去,并且给每个fd设置一个监听函数,这个函数会在fd数据就绪时触发,就是准备好了,现在就把fd把数据添加到list_head中去
3、调用epoll_wait函数
就去等待,在用户态创建一个空的events数组,当就绪之后,我们的回调函数会把数据添加到list_head中去,当调用这个函数的时候,会去检查list_head,当然这个过程需要参考配置的等待时间,可以等一定时间,也可以一直等, 如果在此过程中,检查到了list_head中有数据会将数据添加到链表中,此时将数据放入到events数组中,并且返回对应的操作的数量,用户态的此时收到响应后,从events中拿到对应准备好的数据的节点,再去调用方法去拿数据。
小总结:
select模式存在的三个问题:
- * 能监听的FD最大不超过1024
- * 每次select都需要把所有要监听的FD都拷贝到内核空间
- * 每次都要遍历所有FD来判断就绪状态
poll模式的问题:
* poll利用链表解决了select中监听FD上限的问题,但依然要遍历所有FD,如果监听较多,性能会下降
epoll模式中如何解决这些问题的?
- * 基于epoll实例中的红黑树保存要监听的FD,理论上无上限,而且增删改查效率都非常高
- * 每个FD只需要执行一次epoll_ctl添加到红黑树,以后每次epol_wait无需传递任何参数,无需重复拷贝FD到内核空间
- * 利用ep_poll_callback机制来监听FD状态,无需遍历所有FD,因此性能不会随监听的FD数量增多而下降
###网络模型-epoll中的ET和LT
当FD有数据可读时,我们调用epoll_wait(或者select、poll)可以得到通知。但是事件通知的模式有两种:
- * LevelTriggered:简称LT,也叫做水平触发。只要某个FD中有数据可读,每次调用epoll_wait都会得到通知。
- * EdgeTriggered:简称ET,也叫做边沿触发。只有在某个FD有状态变化时,调用epoll_wait才会被通知。

举个栗子:
- * 假设一个客户端socket对应的FD已经注册到了epoll实例中
- * 客户端socket发送了2kb的数据
- * 服务端调用epoll_wait,得到通知说FD就绪
- * 服务端从FD读取了1kb数据
- 回到步骤3(再次调用epoll_wait,形成循环)
结论
如果我们采用LT模式,因为FD中仍有1kb数据,则第⑤步依然会返回结果,并且得到通知
如果我们采用ET模式,因为第③步已经消费了FD可读事件,第⑤步FD状态没有变化,因此epoll_wait不会返回,数据无法读取,客户端响应超时。
### 网络模型-基于epoll的服务器端流程
我们来梳理一下这张图
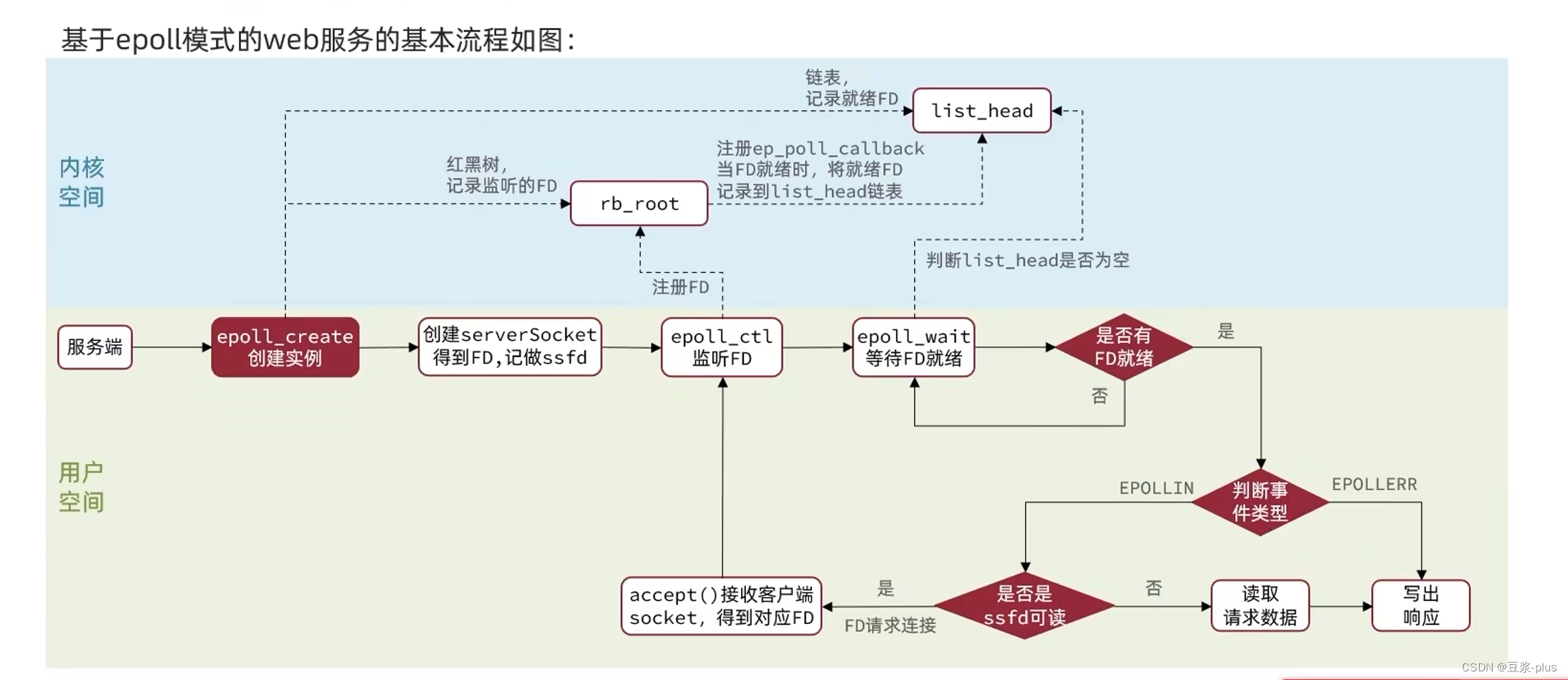
服务器启动以后,服务端会去调用epoll_create,创建一个epoll实例,epoll实例中包含两个数据
1、红黑树(为空):rb_root 用来去记录需要被监听的FD
2、链表(为空):list_head,用来存放已经就绪的FD
创建好了之后,会去调用epoll_ctl函数,此函数会会将需要监听的数据添加到rb_root中去,并且对当前这些存在于红黑树的节点设置回调函数,当这些被监听的数据一旦准备完成,就会被调用,而调用的结果就是将红黑树的fd添加到list_head中去(但是此时并没有完成)
3、当第二步完成后,就会调用epoll_wait函数,这个函数会去校验是否有数据准备完毕(因为数据一旦准备就绪,就会被回调函数添加到list_head中),在等待了一段时间后(可以进行配置),如果等够了超时时间,则返回没有数据,如果有,则进一步判断当前是什么事件,如果是建立连接时间,则调用accept() 接受客户端socket,拿到建立连接的socket,然后建立起来连接,如果是其他事件,则把数据进行写出
8.2.5 信号驱动IO
信号驱动IO是与内核建立SIGIO的信号关联并设置回调,当内核有FD就绪时,会发出SIGIO信号通知用户,期间用户应用可以执行其它业务,无需阻塞等待。
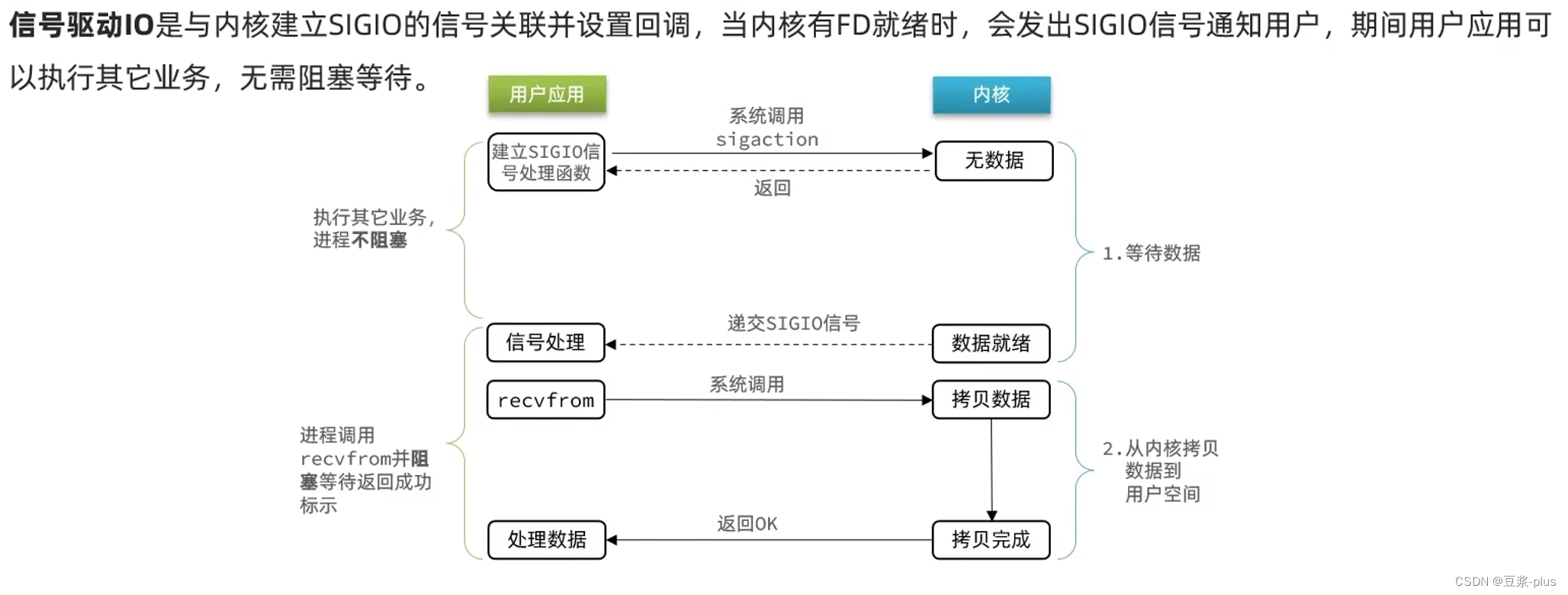
阶段一:
- * 用户进程调用sigaction,注册信号处理函数
- * 内核返回成功,开始监听FD
- * 用户进程不阻塞等待,可以执行其它业务
- * 当内核数据就绪后,回调用户进程的SIGIO处理函数
阶段二:
- * 收到SIGIO回调信号
- * 调用recvfrom,读取
- * 内核将数据拷贝到用户空间
- * 用户进程处理数据
当有大量IO操作时,信号较多,SIGIO处理函数不能及时处理可能导致信号队列溢出,而且内核空间与用户空间的频繁信号交互性能也较低。
8.2.6 异步I0
这种方式,不仅仅是用户态在试图读取数据后,不阻塞,而且当内核的数据准备完成后,也不会阻塞
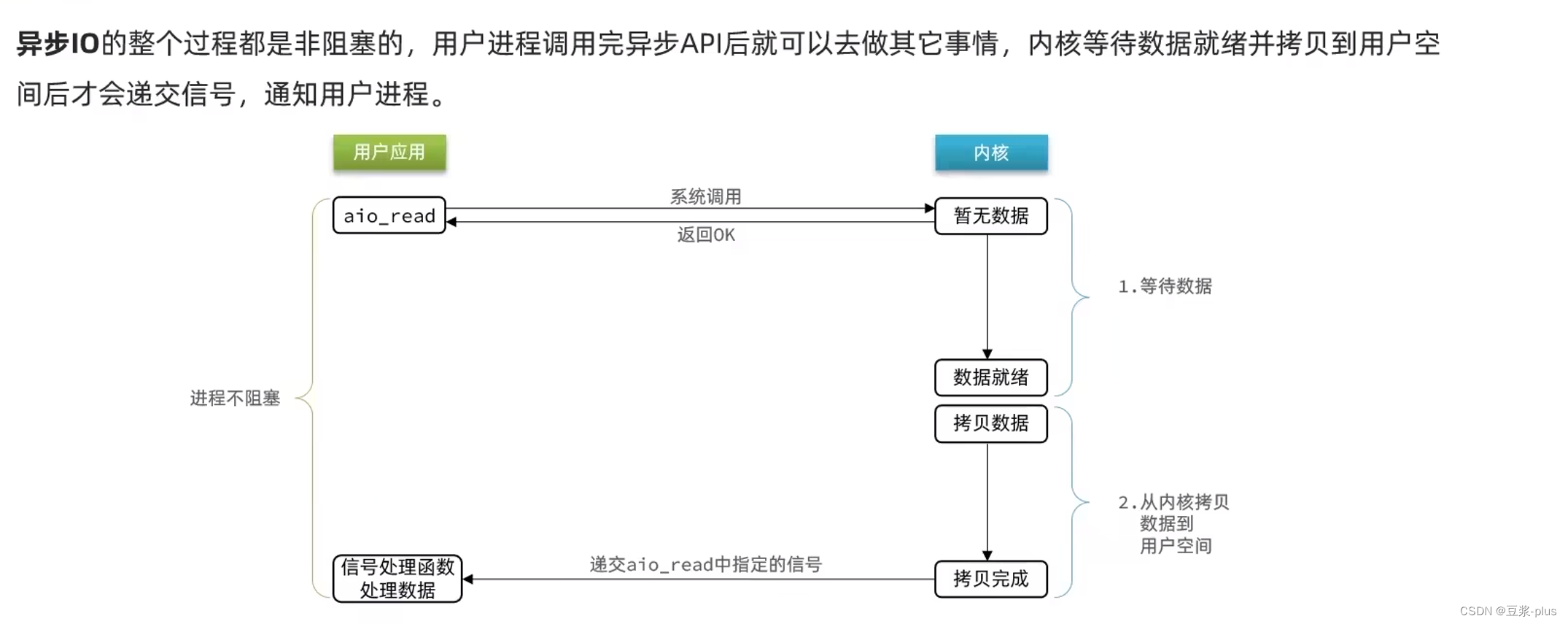
他会由内核将所有数据处理完成后,由内核将数据写入到用户态中,然后才算完成,所以性能极高,不会有任何阻塞,全部都由内核完成,可以看到,异步IO模型中,用户进程在两个阶段都是非阻塞状态。
对比:
最后用一幅图,来说明他们之间的区别

8.2.7 Redis网络模型
**Redis到底是单线程还是多线程?**
- * 如果仅仅聊Redis的核心业务部分(命令处理),答案是单线程
- * 如果是聊整个Redis,那么答案就是多线程
在Redis版本迭代过程中,在两个重要的时间节点上引入了多线程的支持:
- * Redis v4.0:引入多线程异步处理一些耗时较旧的任务,例如异步删除命令unlink
- * Redis v6.0:在核心网络模型中引入 多线程,进一步提高对于多核CPU的利用率
因此,对于Redis的核心网络模型,在Redis 6.0之前确实都是单线程。是利用epoll(Linux系统)这样的IO多路复用技术在事件循环中不断处理客户端情况。
**为什么Redis要选择单线程?**
- * 抛开持久化不谈,Redis是纯内存操作,执行速度非常快,它的性能瓶颈是网络延迟而不是执行速度,因此多线程并不会带来巨大的性能提升。
- * 多线程会导致过多的上下文切换,带来不必要的开销
- * 引入多线程会面临线程安全问题,必然要引入线程锁这样的安全手段,实现复杂度增高,而且性能也会大打折扣
Redis的单线程模型-Redis单线程和多线程网络模型变更
当我们的客户端想要去连接我们服务器,会去先到IO多路复用模型去进行排队,会有一个连接应答处理器,他会去接受读请求,然后又把读请求注册到具体模型中去,此时这些建立起来的连接,如果是客户端请求处理器去进行执行命令时,他会去把数据读取出来,然后把数据放入到client中, clinet去解析当前的命令转化为redis认识的命令,接下来就开始处理这些命令,从redis中的command中找到这些命令,然后就真正的去操作对应的数据了,当数据操作完成后,会去找到命令回复处理器,再由他将数据写出。

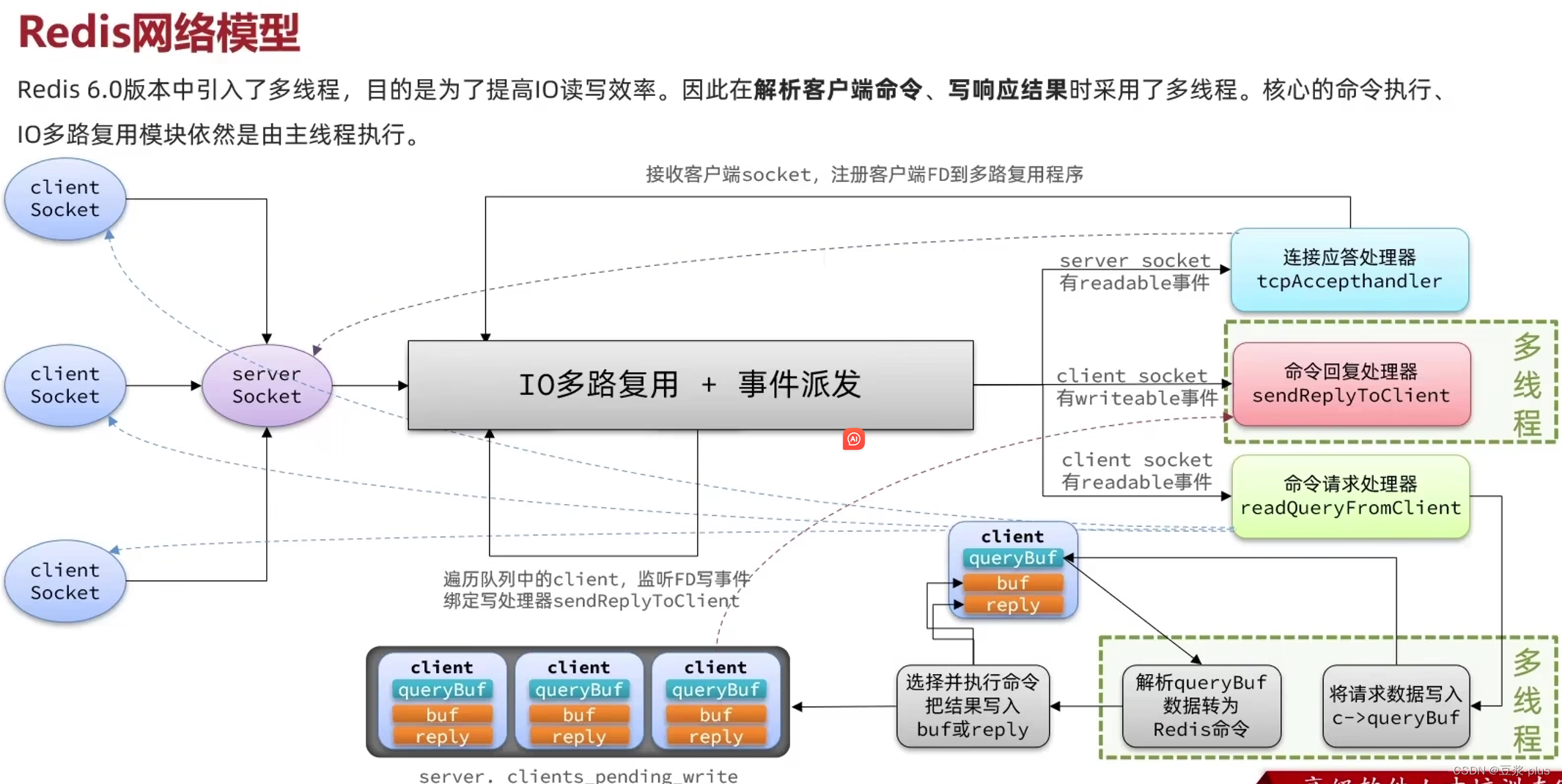
8.3 通信协议
8.3.1 RESP协议
Redis是一个CS架构的软件,通信一般分两步(不包括pipeline和PubSub):
- 客户端(client)向服务端(server)发送一条命令
- 服务端解析并执行命令,返回响应结果给客户端
因此客户端发送命令的格式、服务端响应结果的格式必须有一个规范,这个规范就是通信协议。
而在Redis中采用的是RESP(Redis Serialization Protocol)协议:
- Redis 1.2版本引入了RESP协议
- Redis 2.0版本中成为与Redis服务端通信的标准,称为RESP2
- Redis 6.0版本中,从RESP2升级到了RESP3协议,增加了更多数据类型并且支持6.0的新特性--客户端缓存
但目前,默认使用的依然是RESP2协议,也是我们要学习的协议版本(以下简称RESP)。
在RESP中,通过首字节的字符来区分不同数据类型,常用的数据类型包括5种:
- 单行字符串:首字节是 ‘+’ ,后面跟上单行字符串,以CRLF( "\r\n" )结尾。例如返回"OK": "+OK\r\n"
- 错误(Errors):首字节是 ‘-’ ,与单行字符串格式一样,只是字符串是异常信息,例如:"-Error message\r\n"
- 数值:首字节是 ‘:’ ,后面跟上数字格式的字符串,以CRLF结尾。例如:":10\r\n"
- 多行字符串:首字节是 ‘$’ ,表示二进制安全的字符串,最大支持512MB:
如果大小为0,则代表空字符串:"$0\r\n\r\n"
如果大小为-1,则代表不存在:"$-1\r\n"
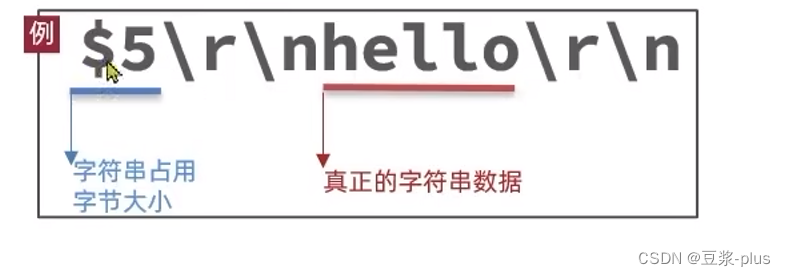
- 数组:首字节是 ‘*’,后面跟上数组元素个数,再跟上元素,元素数据类型不限:

8.3.2 模拟Redis客户端
Redis通信协议-基于Socket自定义Redis的客户端
Redis支持TCP通信,因此我们可以使用Socket来模拟客户端,与Redis服务端建立连接:
```java
public class Main {
static Socket s;
static PrintWriter writer;
static BufferedReader reader;
public static void main(String[] args) {
try {
// 1.建立连接
String host = "192.168.150.101";
int port = 6379;
s = new Socket(host, port);
// 2.获取输出流、输入流
writer = new PrintWriter(new OutputStreamWriter(s.getOutputStream(), StandardCharsets.UTF_8));
reader = new BufferedReader(new InputStreamReader(s.getInputStream(), StandardCharsets.UTF_8));
// 3.发出请求
// 3.1.获取授权 auth 123321
sendRequest("auth", "123321");
Object obj = handleResponse();
System.out.println("obj = " + obj);
// 3.2.set name 虎哥
sendRequest("set", "name", "虎哥");
// 4.解析响应
obj = handleResponse();
System.out.println("obj = " + obj);
// 3.2.set name 虎哥
sendRequest("get", "name");
// 4.解析响应
obj = handleResponse();
System.out.println("obj = " + obj);
// 3.2.set name 虎哥
sendRequest("mget", "name", "num", "msg");
// 4.解析响应
obj = handleResponse();
System.out.println("obj = " + obj);
} catch (IOException e) {
e.printStackTrace();
} finally {
// 5.释放连接
try {
if (reader != null) reader.close();
if (writer != null) writer.close();
if (s != null) s.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
private static Object handleResponse() throws IOException {
// 读取首字节
int prefix = reader.read();
// 判断数据类型标示
switch (prefix) {
case '+': // 单行字符串,直接读一行
return reader.readLine();
case '-': // 异常,也读一行
throw new RuntimeException(reader.readLine());
case ':': // 数字
return Long.parseLong(reader.readLine());
case '$': // 多行字符串
// 先读长度
int len = Integer.parseInt(reader.readLine());
if (len == -1) {
return null;
}
if (len == 0) {
return "";
}
// 再读数据,读len个字节。我们假设没有特殊字符,所以读一行(简化)
return reader.readLine();
case '*':
return readBulkString();
default:
throw new RuntimeException("错误的数据格式!");
}
}
private static Object readBulkString() throws IOException {
// 获取数组大小
int len = Integer.parseInt(reader.readLine());
if (len <= 0) {
return null;
}
// 定义集合,接收多个元素
List<Object> list = new ArrayList<>(len);
// 遍历,依次读取每个元素
for (int i = 0; i < len; i++) {
list.add(handleResponse());
}
return list;
}
// set name 虎哥
private static void sendRequest(String ... args) {
writer.println("*" + args.length);
for (String arg : args) {
writer.println("$" + arg.getBytes(StandardCharsets.UTF_8).length);
writer.println(arg);
}
writer.flush();
}
}
8.4 内存策略
Redis内存回收-过期key处理
Redis之所以性能强,最主要的原因就是基于内存存储。然而单节点的Redis其内存大小不宜过大,会影响持久化或主从同步性能。
我们可以通过修改配置文件来设置Redis的最大内存:

当内存使用达到上限时,就无法存储更多数据了。为了解决这个问题,Redis提供了一些策略实现内存回收:
8.4.1 内存过期策略
在学习Redis缓存的时候我们说过,可以通过expire命令给Redis的key设置TTL(存活时间):

可以发现,当key的TTL到期以后,再次访问name返回的是nil,说明这个key已经不存在了,对应的内存也得到释放。从而起到内存回收的目的。
Redis本身是一个典型的key-value内存存储数据库,因此所有的key、value都保存在之前学习过的Dict结构中。不过在其database结构体中,有两个Dict:一个用来记录key-value;另一个用来记录key-TTL。
这里有两个问题需要我们思考:
1.Redis是如何知道一个key是否过期呢?
利用两个Dict分别记录key-value对及key-ttl对
2.是不是TTL到期就立即删除了呢?
惰性删除
周期删除
**惰性删除**
惰性删除:顾明思议并不是在TTL到期后就立刻删除,而是在访问一个key的时候,检查该key的存活时间,如果已经过期才执行删除。
**周期删除**
周期删除:顾明思议是通过一个定时任务,周期性的抽样部分过期的key,然后执行删除。执行周期有两种:
- Redis服务初始化函数initServer()中设置定时任务,按照server.hz的频率来执行过期key清理,模式为SLOW
- Redis的每个事件循环前会调用beforeSleep()函数,执行过期key清理,模式为FAST
SLOW模式规则:
- * 执行频率受server.hz影响,默认为10,即每秒执行10次,每个执行周期100ms。
- * 执行清理耗时不超过一次执行周期的25%.默认slow模式耗时不超过25ms
- * 逐个遍历db,逐个遍历db中的bucket,抽取20个key判断是否过期
- * 如果没达到时间上限(25ms)并且过期key比例大于10%,再进行一次抽样,否则结束
* FAST模式规则(过期key比例小于10%不执行 ):
- * 执行频率受beforeSleep()调用频率影响,但两次FAST模式间隔不低于2ms
- * 执行清理耗时不超过1ms
- * 逐个遍历db,逐个遍历db中的bucket,抽取20个key判断是否过期
如果没达到时间上限(1ms)并且过期key比例大于10%,再进行一次抽样,否则结束
小总结:
RedisKey的TTL记录方式:
在RedisDB中通过一个Dict记录每个Key的TTL时间
过期key的删除策略:
- 惰性清理:每次查找key时判断是否过期,如果过期则删除
- 定期清理:定期抽样部分key,判断是否过期,如果过期则删除。
定期清理的两种模式:
- SLOW模式执行频率默认为10,每次不超过25ms
- FAST模式执行频率不固定,但两次间隔不低于2ms,每次耗时不超过1ms
8.4.2 内存淘汰策略
### Redis内存回收-内存淘汰策略
内存淘汰:就是当Redis内存使用达到设置的上限时,主动挑选部分key删除以释放更多内存的流程。
Redis会在处理客户端命令的方法processCommand()中尝试做内存淘汰:

淘汰策略
Redis支持8种不同策略来选择要删除的key:
- * noeviction: 不淘汰任何key,但是内存满时不允许写入新数据,默认就是这种策略。
- * volatile-ttl: 对设置了TTL的key,比较key的剩余TTL值,TTL越小越先被淘汰
- * allkeys-random:对全体key ,随机进行淘汰。也就是直接从db->dict中随机挑选
- * volatile-random:对设置了TTL的key ,随机进行淘汰。也就是从db->expires中随机挑选。
- * allkeys-lru: 对全体key,基于LRU算法进行淘汰
- * volatile-lru: 对设置了TTL的key,基于LRU算法进行淘汰
- * allkeys-lfu: 对全体key,基于LFU算法进行淘汰
- * volatile-lfu: 对设置了TTL的key,基于LFI算法进行淘汰
比较容易混淆的有两个:
- * LRU(Least Recently Used),最少最近使用。用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。
- * LFU(Least Frequently Used),最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高。
Redis的数据都会被封装为RedisObject结构:

LFU的访问次数之所以叫做逻辑访问次数,是因为并不是每次key被访问都计数,而是通过运算:
- * 生成0~1之间的随机数R
- * 计算1/ (旧次数 * lfu_log_factor + 1),记录为P,lfu log factor默认为10。
- * 如果 R < P ,则计数器 + 1,且最大不超过255
- * 访问次数会随时间衰减,距离上一次访问时间每隔 lfu_decay_time 分钟(默认1),计数器 -1
最后用一副图来描述当前的这个流程吧















 21万+
21万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











