







目录
一,对数组进行排序:通常情况下我们可以使用Array.sort()来对数组进行排序,有以下3种情况:
二,对自定义类进行排序当我们处理自定义类型的排序时,一般将自定义类放在List种,之后再进行排序
普通排序

然后再使用java代码去实现它。以后我们讲任何数据结构与算法都是以这种方式讲解
1.1 Comparable接口介绍
public class Student implements Comparable<Student>{
private String username;
private int age;
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString(){
return "Student{'"+username+'\''+",age="+age+'}';
}
@Override
public int compareTo(Student o){
return this.getAge()-o.getAge();
}
}
class Test{
public static void main(String[] args) {
Student stu1=new Student();
stu1.setUsername("zhangsan");
stu1.setAge(17);
Student stu2=new Student();
stu2.setUsername("list");
stu2.setAge(19);
Comparable max=getMax(stu1,stu2);
System.out.println(max);
}
public static Comparable getMax(Comparable c1,Comparable c2){
int cmp=c1.compareTo(c2);
if(cmp>=0)return c1;
else return c2;
}
}
1.2 冒泡排序

import java.util.Arrays;
public class Bubble {
public static void sort(Comparable[] a) {
for (int i = a.length - 1; i > 0; i--) {
for (int j = 0; j < i; j++) {
if (greater(a[j], a[j + 1])) {
exch(a, j, j + 1);
}
}
}
}
private static boolean greater(Comparable v, Comparable w) {
return v.compareTo(w) > 0;
}
private static void exch(Comparable[] a, int i, int j) {
Comparable t = a[i];
a[i] = a[j];
a[j] = t;
}
}
class Test{
public static void main(String[] argc){
Integer[] a={4,5,3,2,1};
Bubble.sort(a);
System.out.println(Arrays.toString(a));
}
}
1.3 选择排序

import java.util.Arrays;
public class Selection {
public static void sort(Comparable[] a){
for(int i=0;i<=a.length-2;i++){
int minIndex=i;
for(int j=i+1;j<a.length;j++){
if(greater(a[minIndex],a[j])){
minIndex=j;
}
}
exch(a,i,minIndex);
}
}
private static boolean greater(Comparable v,Comparable w){
return v.compareTo(w)>0;
}
public static void exch(Comparable[] a,int i,int j){
Comparable t=a[i];
a[i]=a[j];
a[j]=t;
}
}
class Test2{
public static void main(String[] args) {
Integer[] a={4,6,8,9,2,10,1};
Selection.sort(a);
System.out.println(Arrays.toString(a));
}
}
1.4 插入排序


import java.lang.reflect.Array;
import java.util.Arrays;
public class Insertion {
public static void sort(Comparable[] a){
for(int i=1;i<a.length;i++){
for(int j=i;j>0;j--){
if(greater(a[j-1],a[j])){
exch(a,j-1,j);
}else {
break;
}
}
}
}
private static boolean greater(Comparable v,Comparable w){
return v.compareTo(w)>0;
}
private static void exch(Comparable[] a,int i,int j){
Comparable t=a[i];
a[i]=a[j];
a[j]=t;
}
}
class Test3{
public static void main(String[] args) {
Integer[] a={45,4565,2,3,8,2};
Insertion.sort(a);
System.out.println(Arrays.toString(a));
}
}
二、高级排序
2.1希尔排序
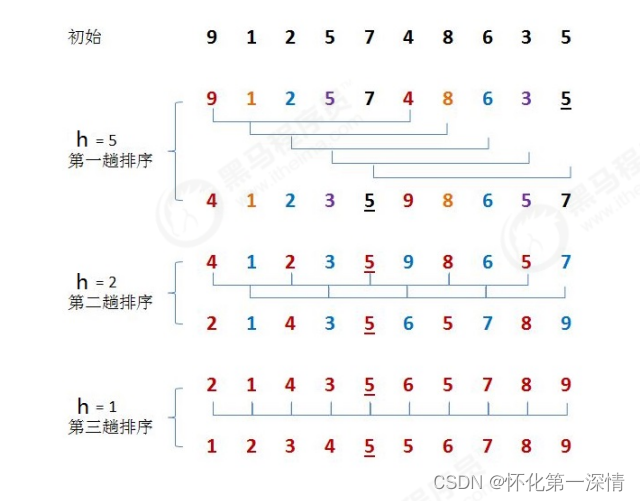
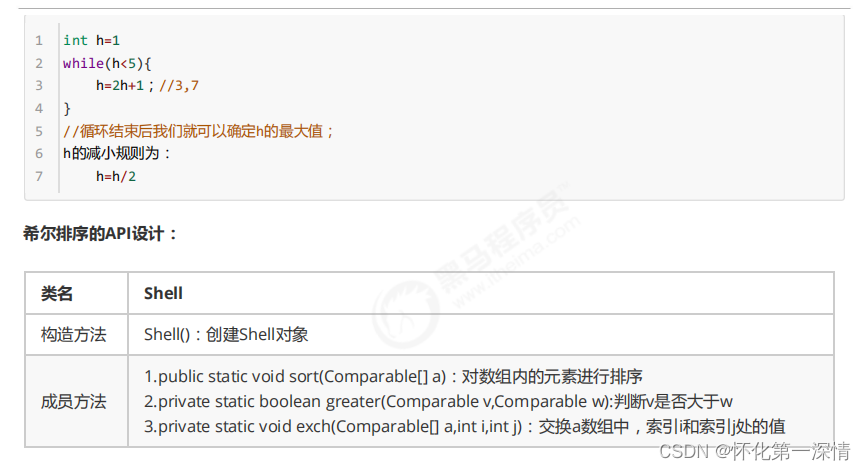
import java.util.Arrays;
public class Shell {
public static void sort(Comparable[] a){
int N=a.length;
int h=1;
while(h<N/2){
h=2*h+1;
}
while (h>=1){
for(int i=h;i<N;i++){
for(int j=i;j>=h;j-=h){
if(greater(a[j-h],a[j])){
exch(a,j,j-h);
}else {
break;
}
}
}
h/=2;
}
}
private static boolean greater(Comparable v,Comparable w){
return v.compareTo(w)>0;
}
public static void exch(Comparable[] a,int i,int j){
Comparable t=a[i];
a[i]=a[j];
a[j]=t;
}
}
class Test4{
public static void main(String[] args) {
Integer[] a={45,52,23,48,7543,3};
Shell.sort(a);
System.out.println(Arrays.toString(a));
}
}
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.Arrays;
public class SortCompare {
public static void main(String[] args)throws Exception {
ArrayList<Integer>list=new ArrayList<>();
BufferedReader reader=new BufferedReader(new InputStreamReader(new FileInputStream("reverse_shell_insertion.txt")));
String line=null;
while((line=reader.readLine())!=null){
list.add(Integer.valueOf(line));}
reader.close();
Integer[] arr=new Integer[list.size()];
list.toArray(arr);
testInsertion(arr);
testShell(arr);
}
public static void testShell(Integer[] arr){
long start=System.currentTimeMillis();
Shell.sort(arr);
long end=System.currentTimeMillis();
System.out.println("使用希尔排序耗时:"+(end-start));
}
public static void testInsertion(Integer[] arr){
long start=System.currentTimeMillis();
Insertion.sort(arr);
long end=System.currentTimeMillis();
System.out.println("使用插入排序耗时:"+(end-start));
}
}
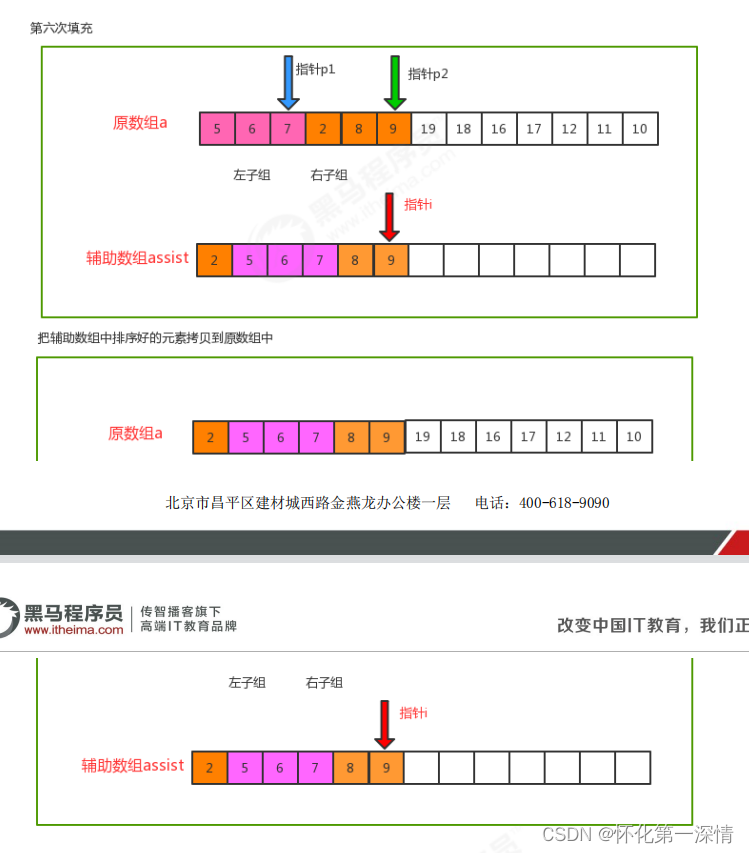
2.2.2 归并排序
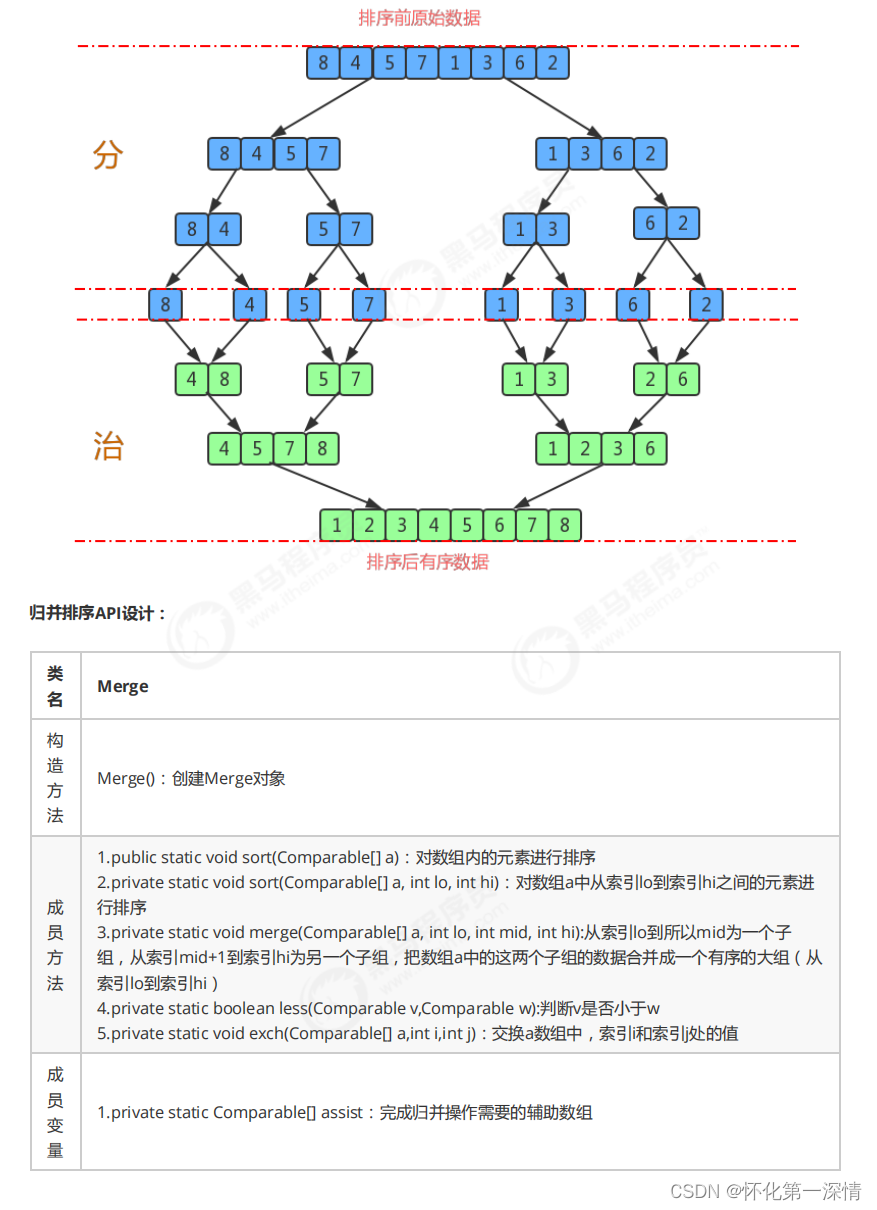

import java.io.BufferedInputStream;
import java.util.*;
public class Main{
private static int N=100010;
private static int[] a=new int[N];
private static int[] t=new int[N];
public static void main(String[] args) {
Scanner sc=new Scanner(new BufferedInputStream(System.in));
int n= sc.nextInt();
for(int i=0;i<n;i++){
a[i]= sc.nextInt();
}
int l=0,r=n-1;
mergeSort(a,l,r);
for(int i=0;i<n;i++){
System.out.print(a[i]);
if(i!=n-1) System.out.print(" ");
}
}
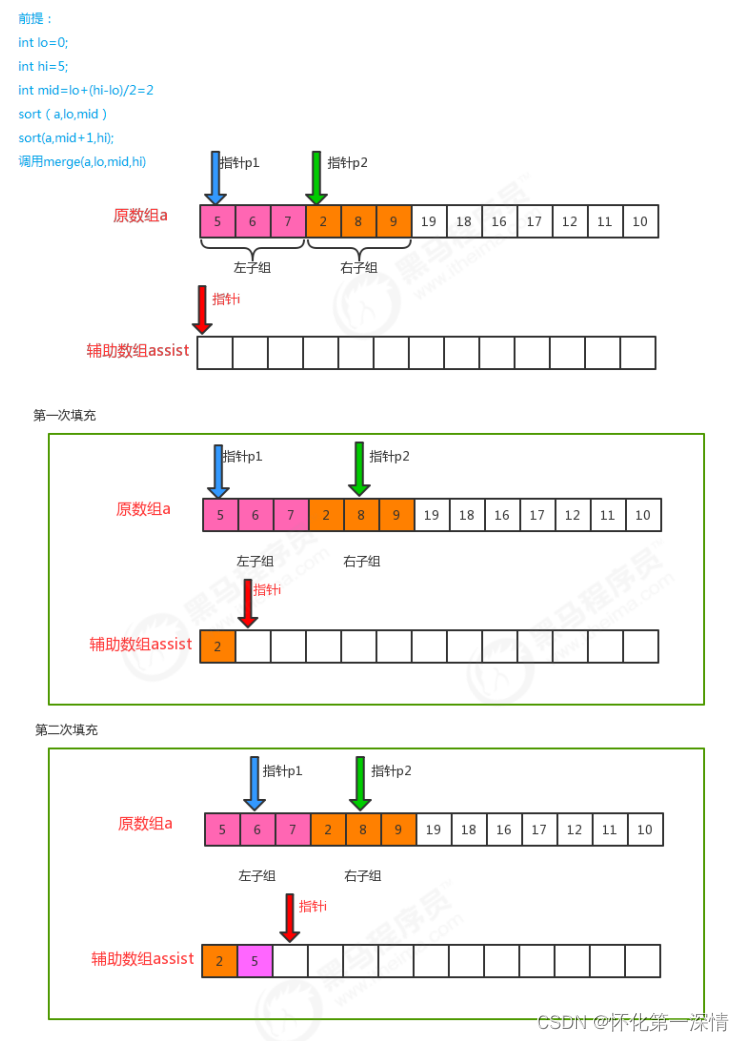
public static void mergeSort(int[] a,int l,int r){
if(l>=r){
return;
}
int m=l+r>>1;
mergeSort(a,l,m);
mergeSort(a,m+1,r);
int i=l,j=m+1,k=0;
while(i<=m&&j<=r){
t[k++]=a[i]<a[j]?a[i++]:a[j++];
}
while(i<=m){
t[k++]=a[i++];
}
while(j<=r){
t[k++]=a[j++];
}
for( i=l,k=0;i<=r;i++,k++){
a[i]=t[k];
}
}
}
2.3 快速排序
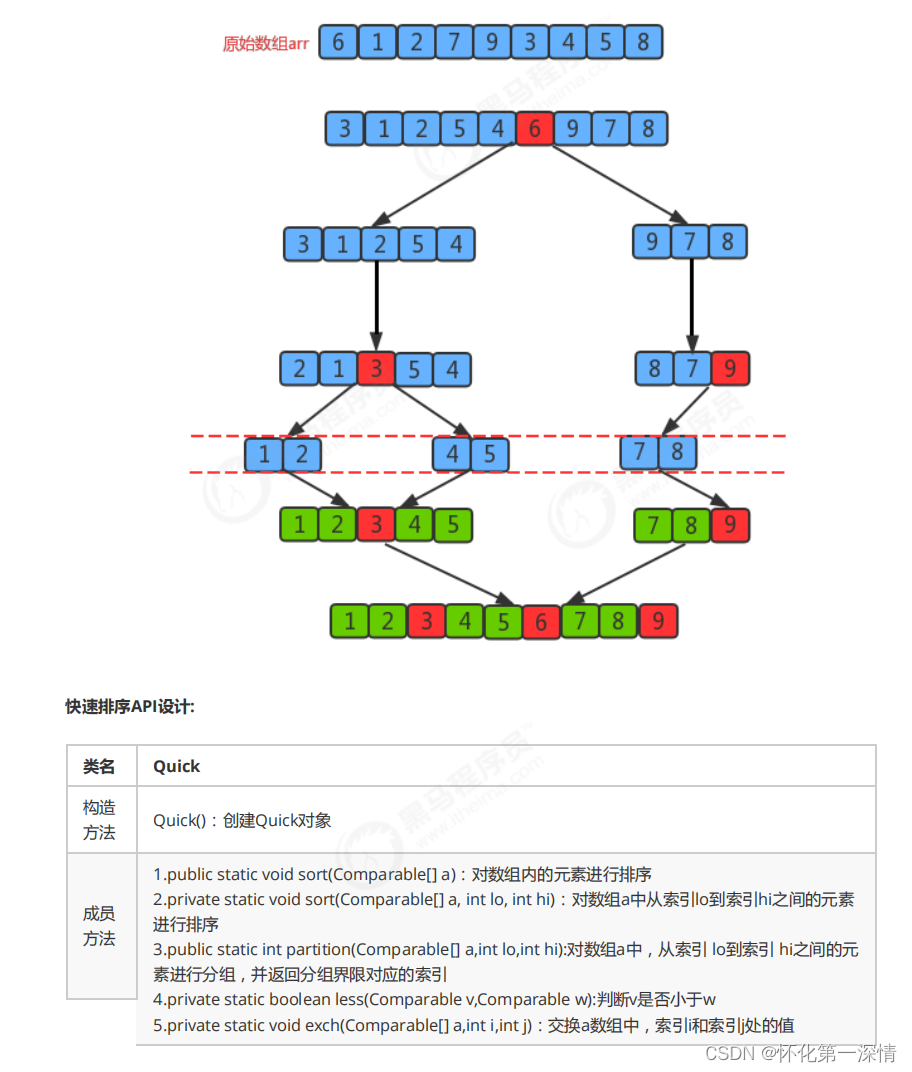
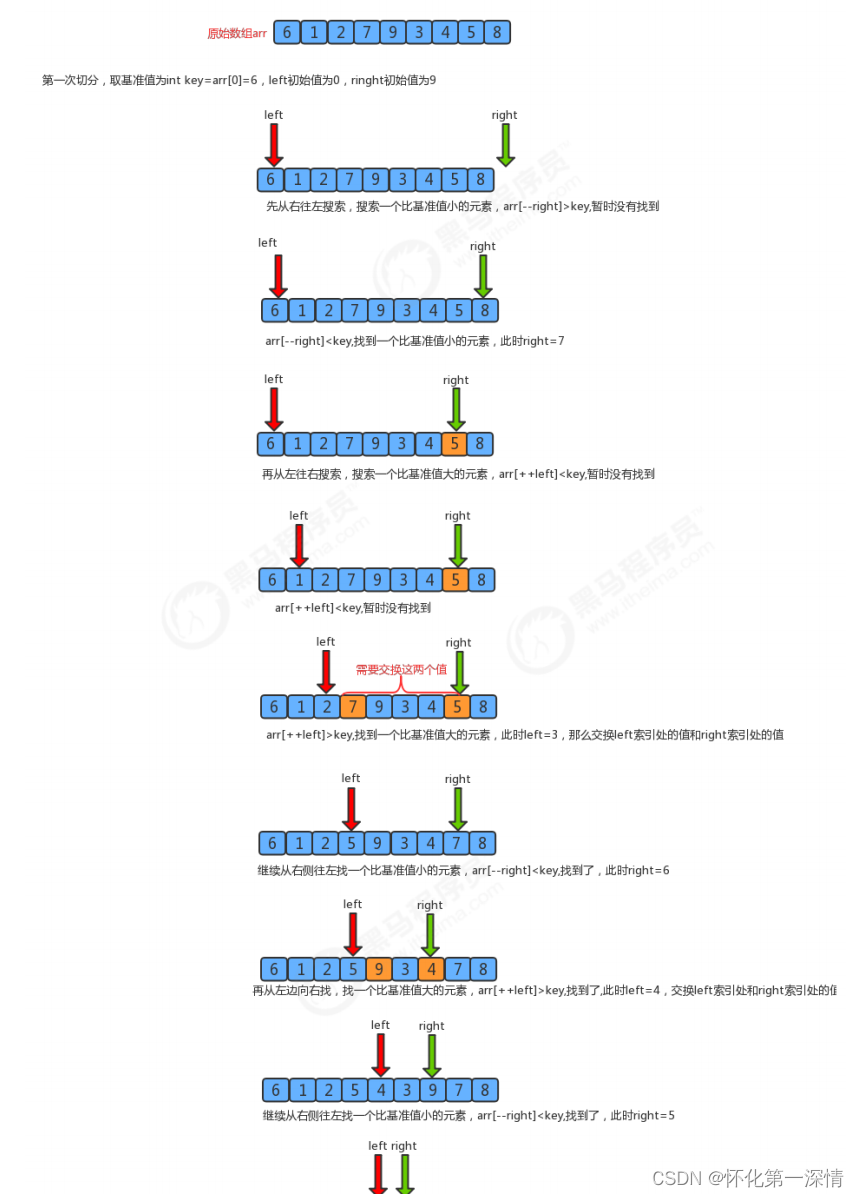
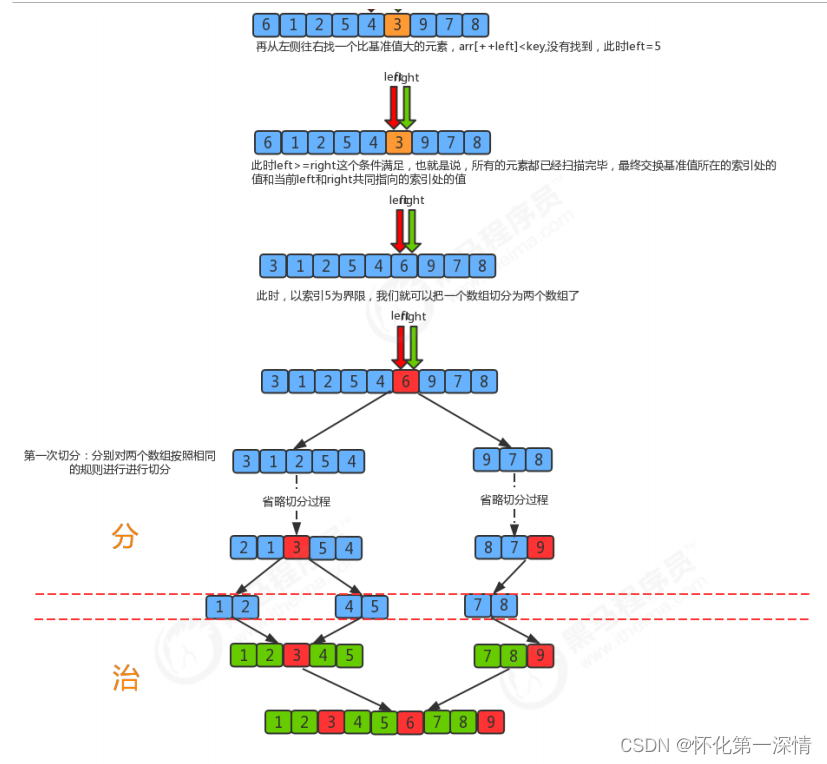
import java.util.Scanner;
import java.io.BufferedInputStream;
public class Main{
public static void main(String[] args) {
Scanner sc=new Scanner(new BufferedInputStream(System.in));
int n=sc.nextInt();
int[] a=new int[n];
for(int i=0;i<n;i++){
a[i]= sc.nextInt();
}
quickSort(a,0,n-1);
for(int i=0;i<n;i++){
System.out.print(a[i]);
if(i!=n-1) System.out.print(" ");
}
}
private static void quickSort(int[] a,int left,int right){
if(left>=right)return;
int x=a[(left+right)/2],i=left-1,j=right+1;
while(i<j){
do{
i++;
}while(a[i]<x);
do{
j--;
}while(a[j]>x);
if(i<j){
int temp=a[i];
a[i]=a[j];
a[j]=temp;
}
}
quickSort(a,left,j);
quickSort(a,j+1,right);
}
}
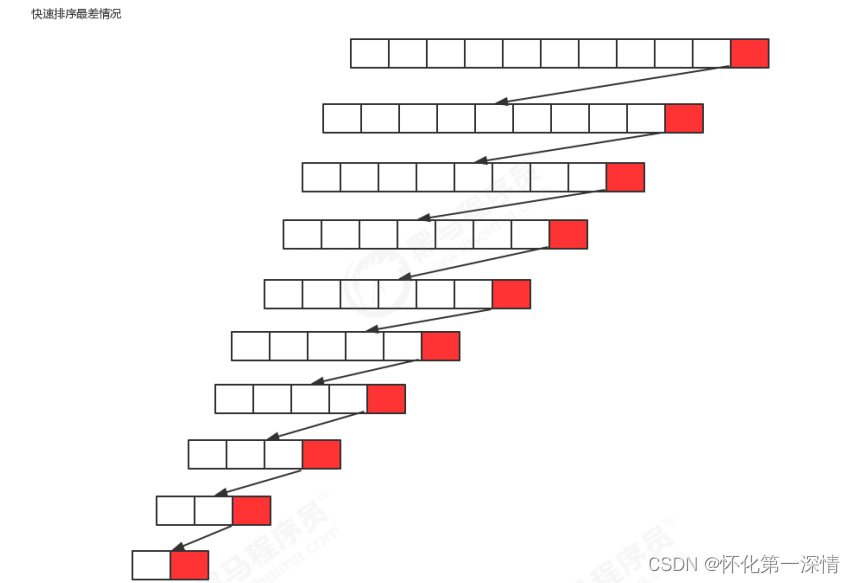
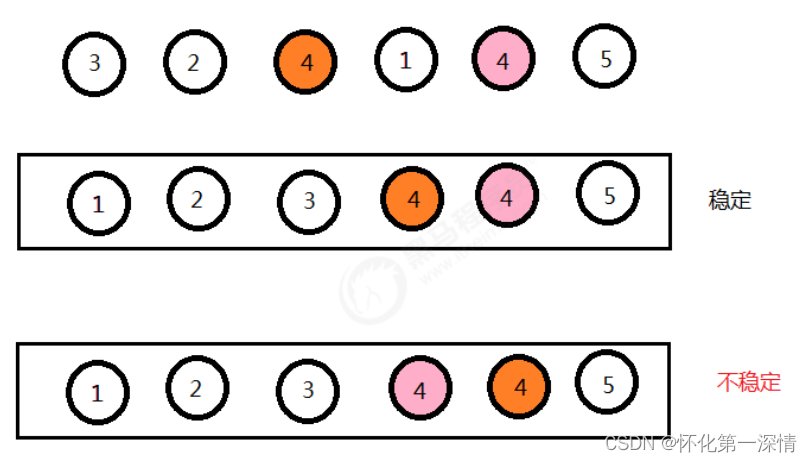
2.4 排序的稳定性
一,对数组进行排序:
通常情况下我们可以使用Array.sort()来对数组进行排序,有以下3种情况:
1.Array.sort(int[] a)
直接对数组进行升序排序
2.Array.sort(int[] a , int fromIndex, int toIndex)
对数组的从fromIndex到toIndex进行升序排序,注意这是左闭右开的
3.新建一个comparator从而实现自定义比较
import java.util.*;
public class no {
public static void main(String []args)
{
int[] ints=new int[]{2,324,4,57,1};
System.out.println("增序排序后顺序");
Arrays.sort(ints);
for (int i=0;i<ints.length;i++)
{
System.out.print(ints[i]+" ");
}
System.out.println("\n减序排序后顺序");
//要实现减序排序,得通过包装类型数组,基本类型数组是不行滴
//倒过来是大顶堆
Integer[] integers=new Integer[]{2,324,4,4,6,1};
Arrays.sort(integers, new Comparator<Integer>()
{
@Override
public int compare(Integer o1, Integer o2)
{
return o2-o1;
}
public boolean equals(Object obj)
{
return false;
}
});
for (Integer integer:integers)
{
System.out.print(integer+" ");
}
System.out.println("\n对部分排序后顺序");
int[] ints2=new int[]{212,43,2,324,4,4,57,1};
//对数组的[2,6)位进行排序
Arrays.sort(ints2,2,6);
for (int i=0;i<ints2.length;i++)
{
System.out.print(ints2[i]+" ");
}
}
}
二,对自定义类进行排序
当我们处理自定义类型的排序时,一般将自定义类放在List种,之后再进行排序
一般我们对自定义类型数据进行重写Comparator来进行对数据进行比较
具体方法如下:
public static class Adam
{
int ID ;
int val ;
String name ;
Adam(int ID , String name , int val)
{
this.ID = ID ;
this.name = name ;
this.val = val ;
}
}
Collections.sort(list, new Comparator<Object>(){ //我们希望对自定义Adam中的ID进行排序
public int compare(Object a , Object b)
{
Adam student1 = (Adam)a ;
Adam student2 = (Adam)b ;
return student1.ID - student2.ID ;
}
});
Arrays.sort(int[])都是基于比较的排序的示例,因此必须具有最坏情况的复杂度Ω(n log n)
三. Arrays.fill()
用法1:接受2个参数
Arrays.fill( a1, value );
注:a1是一个数组变量,value是一个a1中元素数据类型的值,作用:填充a1数组中的每个元素都是value
例如:
boolean[] a1 = new boolean[5];
Arrays.fill( a1,true );
结果 a1[] = {true,true,true,true,true};
用法2:接受4个参数
例如:
String[] a9 = new String[6];
Arrays.fill(a9, “Hello”);
Arrays.fill(a9, 3, 5,“World”);
结果是 a9[] = {Hello,Hello,Hello,World,World,Hello};
第一个参数指操作的数组,第二个和第三个指在该数组的某个区域插入第四个参数,第二个参数指起始元素下标(包含该下标),第三个参数指结束下标(不包含该下标),注意:java的数组下标从0开始

















 1124
1124











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











