






研究自变量X和因变量Y的相关关系,尝试去解释Y的形成机制,进而达到通过X去预测Y的目的,回归分析通常所预测的目标函数是连续值。
三个主要任务:
1.识别重要变量,那些是重要变量,哪些不是。哪些X变量与Y相关,哪些不是。
2.判断相关性方向。自变量与因变量之间的相关性是正的还是负的。
3.估计回顾系数。就是看相关性强不强的权重。
数学建模中回归分析比较常用的是线性回归,所以这里我们只针对数学建模讲线性回归。
线性回归
线性与非线性相对的概念
这里用两个数据集和他们的函数图来帮助理解
- 线性:从数据和图可知图像呈直线


- 非线性:两个变量之间的关系不是一次函数关系的——图象不是直线,叫做非线性。


线性回归问题注意:
1.要预测的变量y与自变量x的关系是线性的
线性通常是指变量之间保持等比例的关系,用咱们的话就是y=kx(k为正数)
2.各项误差服从正太分布。
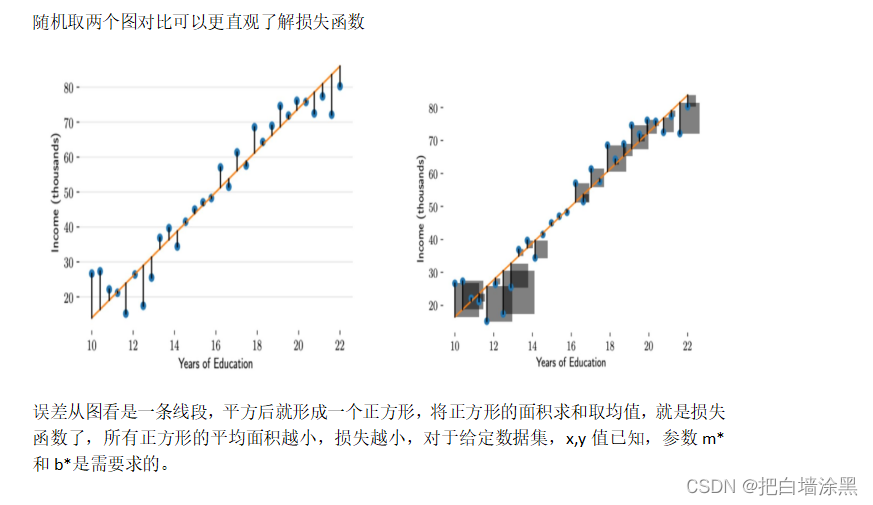
线性回归允许预测值与真实值之间存在误差,随着数据量的增多,这些数据的误差平均值为0;从图形上来看,各个真实值可能在直线上方,也可能在直线下方,当数据足够多时,各个数据上上下下相互抵消
3.变量x的分布要有变异性。
对变量 x有要求,要有一定变化,不然你怎么看y变化嘞
4.多元线性回归中不同特征之间应该相互独立,避免线性相关
如果不同特征不是相互独立,那么可能导致特征间产生共线性(就是变量间存在相互作用影响模型),进而导致模型不准确
5.线性回归是回归问题哦
预测明天是否下雨(分类问题),预测明天的降雨量多少(回归问题)
1.一元线性回归



2.多元线性回归


简单代码实现
import numpy as np
import matplotlib.pyplot as plt
x=np.array([1,2,3,4,5],dtype=np.float) #(x,y)这里是用两个数组分别对应他们的值建立函数图,xy一一对应的
y=np.array([1,3.0,2,3,5])
plt.scatter(x,y)
x_mean=np.mean(x)
y_mean=np.mean(y)
num=0.0
d=0.0
for x_i,y_i in zip(x,y):
num+=(x_i-x_mean)*(y_i-y_mean)
d+=(x_i-x_mean)**2
a=num/d
b=y_mean-a*x_mean
y_hat=a*x+b
plt.figure(2)
plt.scatter(x,y)
plt.plot(x,y_hat,c='r')
x_predict=4.8
y_predict=a*x_predict+b
print(y_predict)
plt.scatter(x_predict,y_predict,c='b',marker='+')
参考链接:(3条消息) 线性回归模型详解(Linear Regression)_taoKingRead的博客-CSDN博客















 3954
3954











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









