






目的:不使用kettle,用python将1亿多行的csv文件转成sql文件,使用mysql进行读取。
背景概述
数据下载地址:User Behavior
根据官网介绍,本数据集包含了2017年11月25日至2017年12月3日之间,有行为的约一百万随机用户的所有行为(行为包括点击、购买、加购、喜欢)。数据集的组织形式和MovieLens-20M类似,即数据集的每一行表示一条用户行为,由用户ID、商品ID、商品类目ID、行为类型和时间戳组成,并以逗号分隔。
文件转换方法
kettle:安装方法和导入方法都有,见B站up主:自发秩序
python:那往下看吧。(注意:不要1亿条一次性一起转,亲测16G内存扑街,电脑好的当我没说)
2.实操
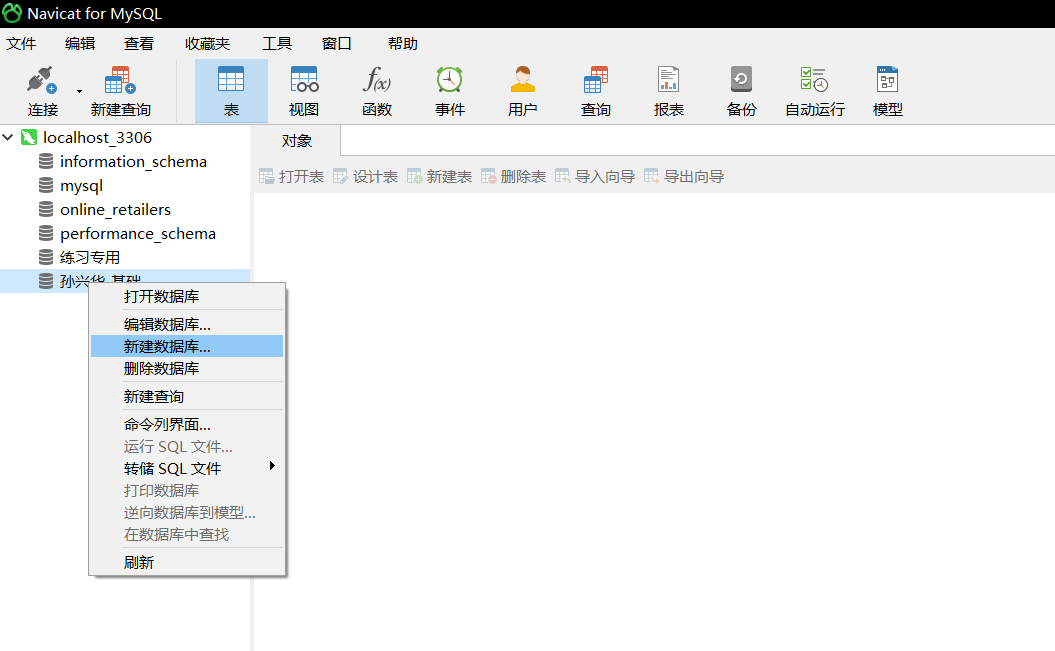
建库建表(使用navicat)


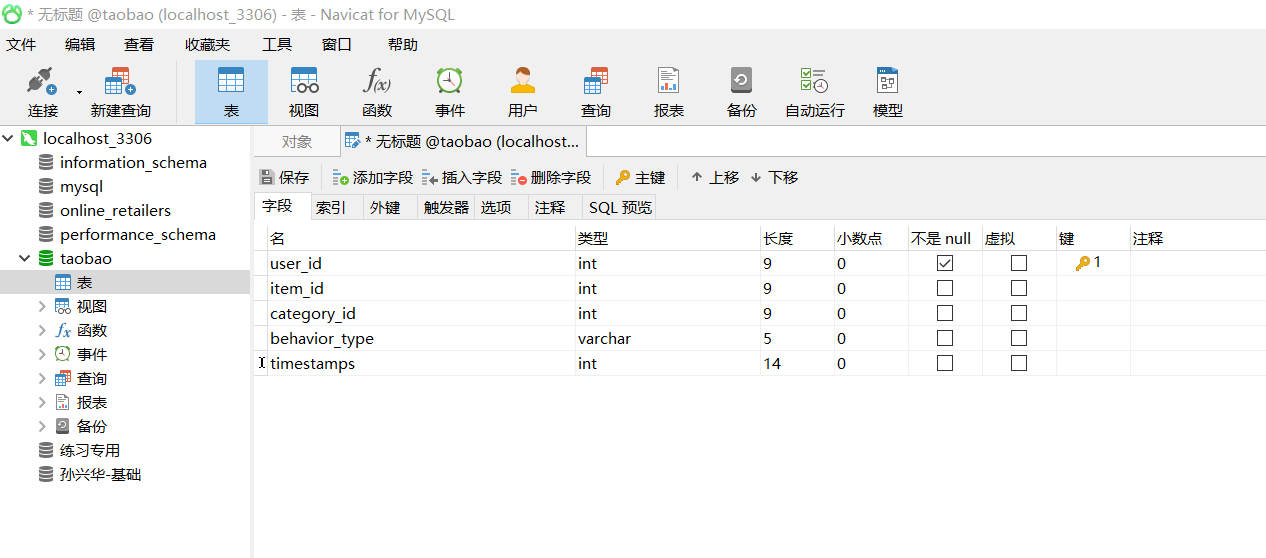
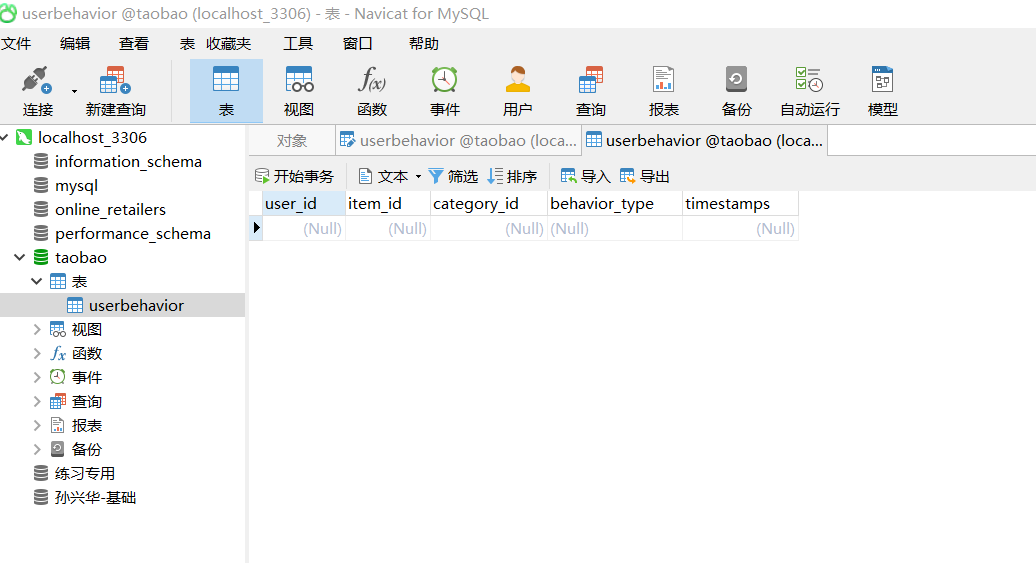
python代码
举个例子:构建1亿条数据,将数据切成5份,j作为index来定位切片下标。我们可以看到跑出来的代码实际上是缺了100150806这个数的,所以后面len(data)替换的时候记得+1。
import numpy as np
data = np.arange(1,100150806)
list = [0]
for i in range(2,11,2):
s = round(int(100150806)*i*0.1)
list.append(s)
print(list)
for j in range(0,5):
# print(j)
data2 = data[list[j]:list[j+1]]
print(data2)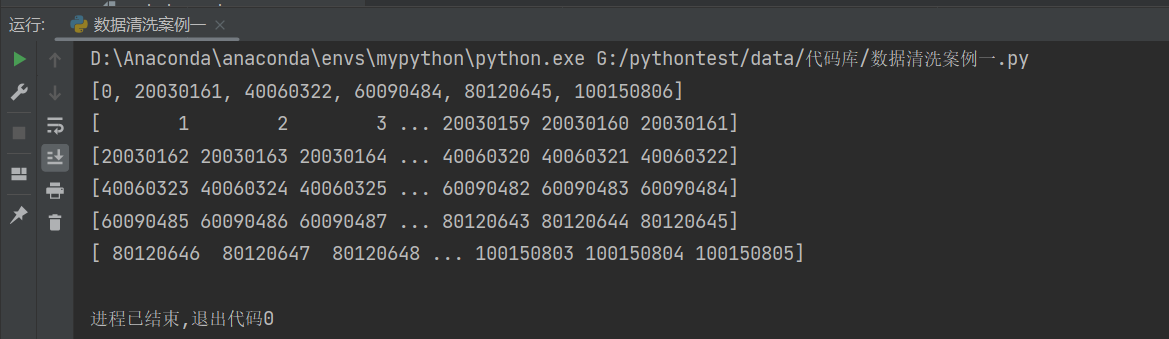
正式代码
# coding=gb2312
import pandas as pd
from sqlalchemy import create_engine
#获取dataframe文件
path = r'H:\UserBehavior\UserBehavior.csv'
data = pd.read_csv(path,header=0,encoding='utf-8',names=['user_id','item_id','category_id','behavior_type','timestamps'])
list = [0]
for i in range(2,11,2):
s = round(int(len(data))*i*0.1)
list.append(s)
print(list)
#数据切片
data1 = data[0:20030161]
data2 = data[20030161:40060322]
data3 = data[40060322:60090484]
data4 = data[60090484:80120645]
data5 = data[80120645:100150807]
# print(data4)
# 数据库信息
mysql_host = 'localhost'
mysql_db = 'taobao'
mysql_user = 'root'
mysql_pwd = '123456'
mysql_table = 'userbehavior'
def main():
engine = create_engine(
'mysql+pymysql://{}:{}@{}:3306/{}?charset=utf8'.format(mysql_user, mysql_pwd, mysql_host, mysql_db))
# 表名
data1.to_sql(mysql_table, con=engine, if_exists='append', index=False)
data2.to_sql(mysql_table, con=engine, if_exists='append', index=False)
data3.to_sql(mysql_table, con=engine, if_exists='append', index=False)
data4.to_sql(mysql_table, con=engine, if_exists='append', index=False)
data5.to_sql(mysql_table, con=engine, if_exists='append', index=False)
if __name__ == '__main__':
main()最后用mysql读取下数量,ok,没问题,导入完毕。
















 2871
2871











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









