






目标:介绍机器学习领域,澄清核心概念,并将人工神经网络与其生物学基础联系起来。
主题:
- 什么是人工智能、机器学习和深度学习?—— 定义与区别
- 学习范式:监督学习、无监督学习和强化学习
- 生物神经元与人工神经元
- 神经元的组成部分:输入、权重、偏置、激活函数
- 前馈神经网络直观介绍
1. 简介 - 为什么要学习机器学习?
当我第一次接触机器学习时,我以为它就是花哨的数学和机器人。但就其核心而言,机器学习只是从实例中学习--这甚至连鸽子都能做到(字面意思--我们稍后再谈)。
在第一篇文章中,我们将探讨机器学习究竟是什么,它与人工智能有何不同,以及这一切是如何从生物学开始的。
2. 什么是人工智能、ML 和深度学习?
使用直观的比较:
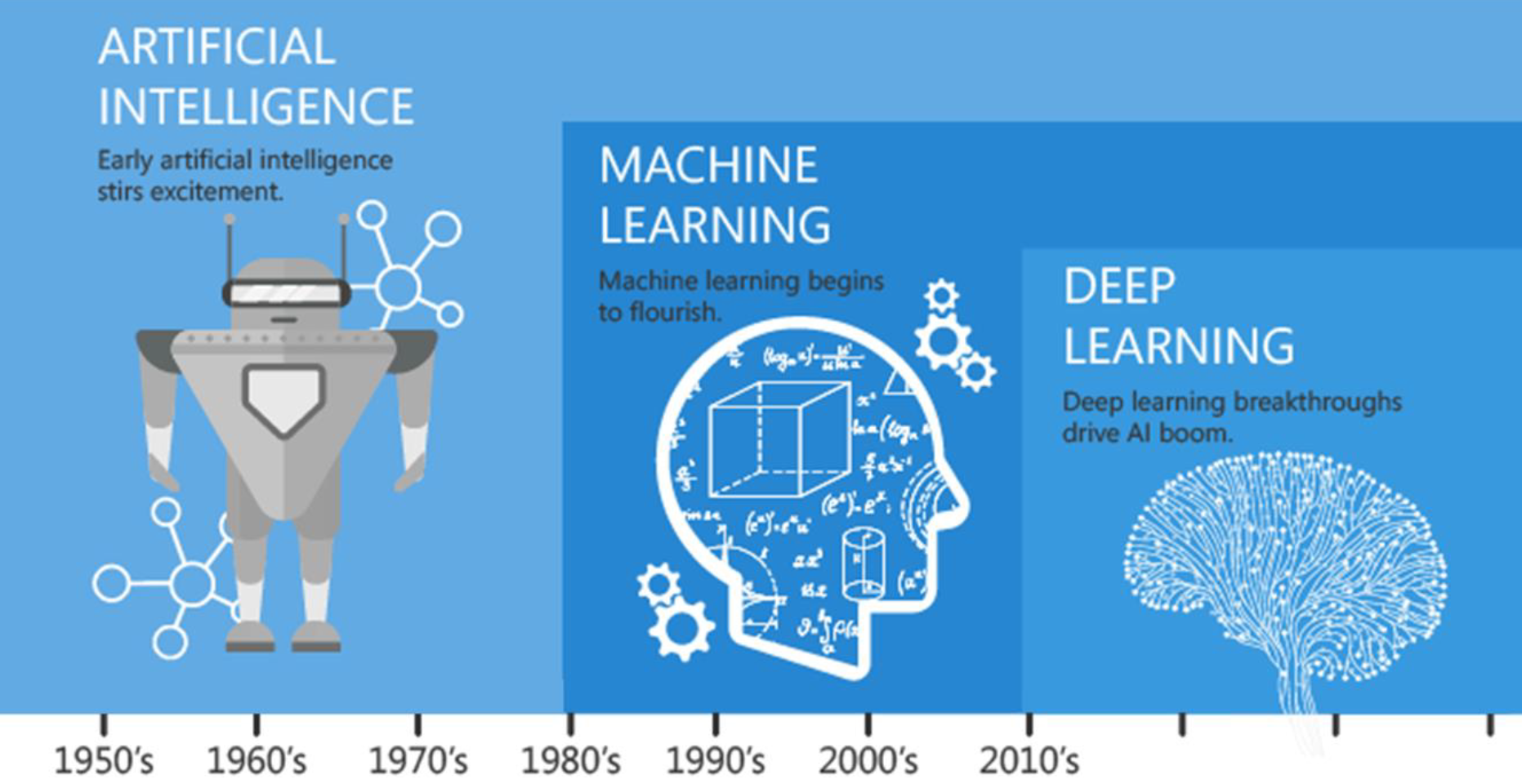
人工智能:宽泛的概念--任何模仿人类智能的东西。
机器学习: 人工智能的子集--从数据中学习,不需要硬核编程。
深度学习: 机器学习的子集--使用分层神经网络从图像或文本等非结构化数据中学习。
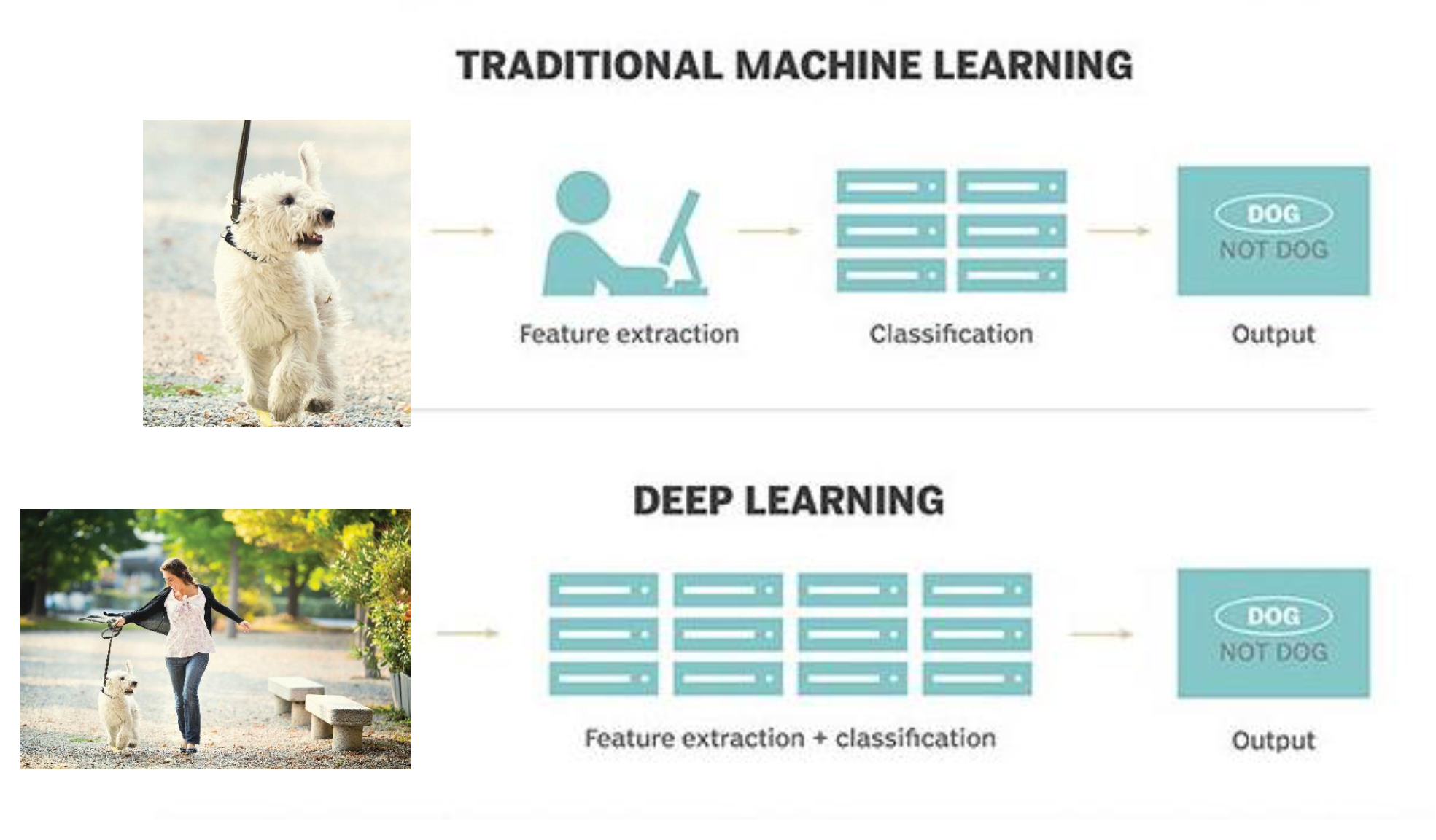
🧠 示例:
将人工智能视为整个大脑,将 ML 视为学习语言等特定技能,将深度学习视为通过聆听无数次对话来学习语言。
3. 学习类型: 监督学习、无监督学习、强化学习
用例子和表情符号进行分解:
监督学习: 有标签数据--预测房价
无监督学习:没有标签--客户分组
强化学习: 试错中学习--机器人走路
4. 从生物神经元到人造神经元
讲一个故事:
想象一下,一只鸽子正在学习从显微镜图像中识别癌细胞。听起来很荒谬?研究人员实际上是通过食物奖励来训练鸽子这样做的。这种 "从实例中学习 "的方法启发了早期的神经网络。
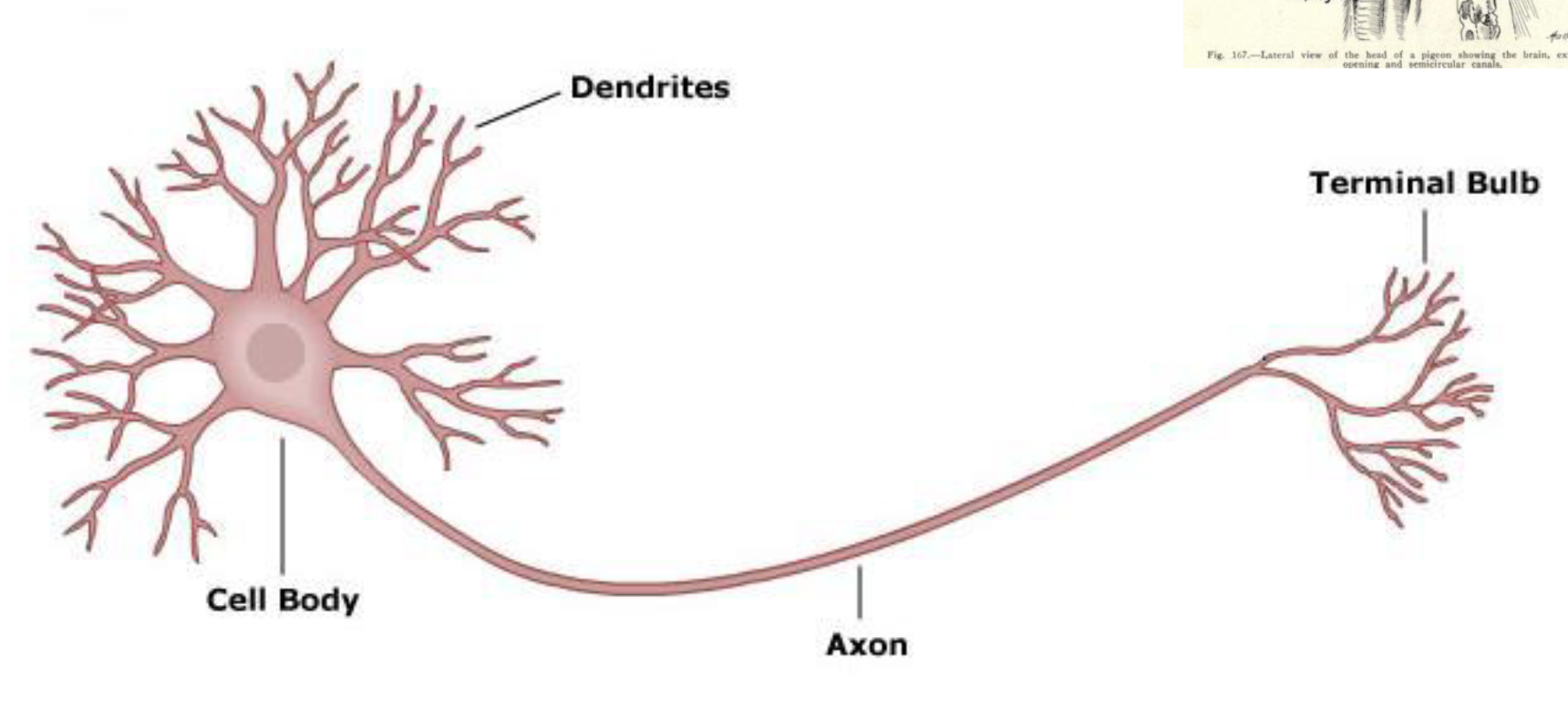
树突、体、轴突(生物)
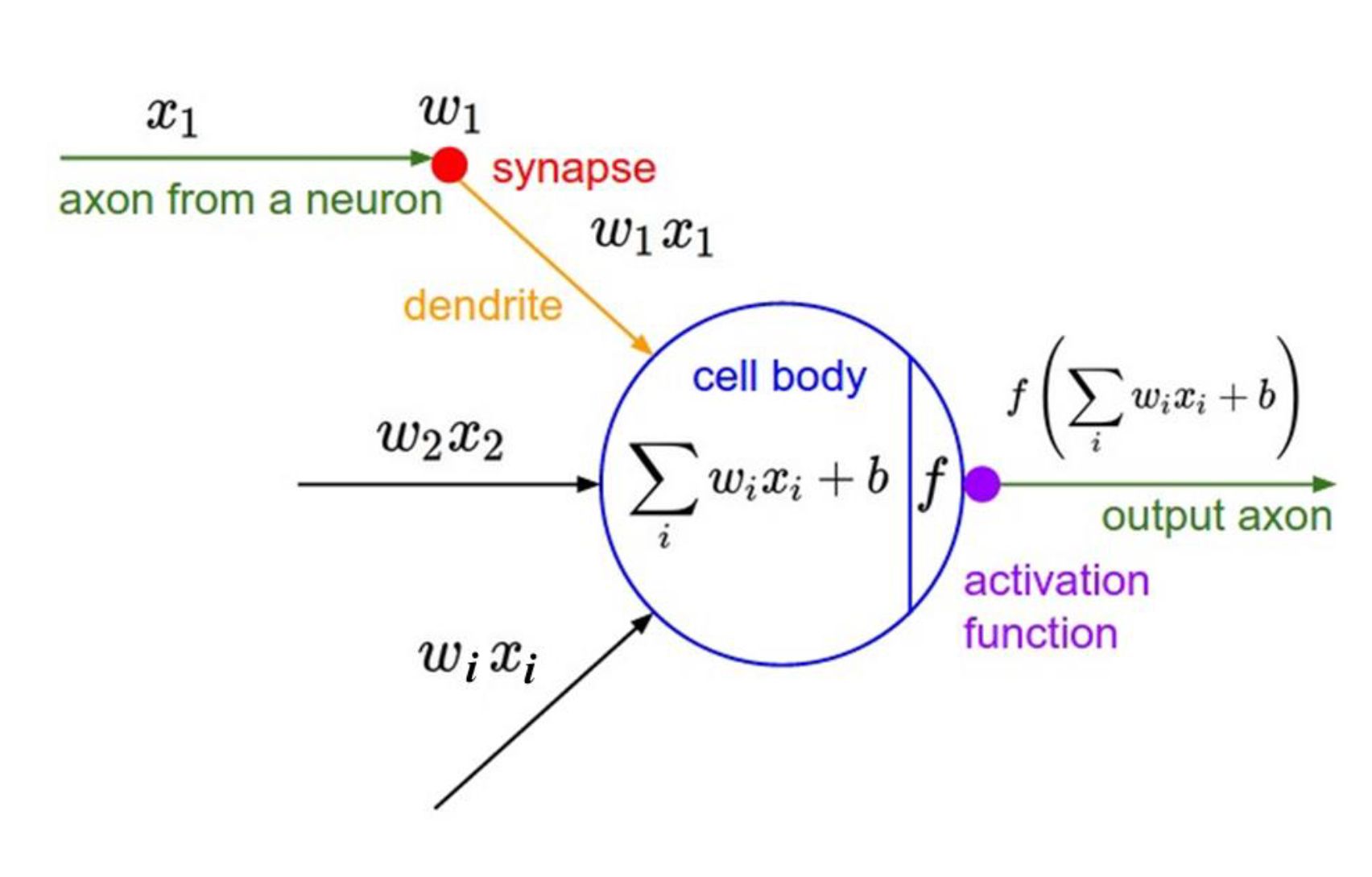
输入、权重、激活(人工)
5. 神经网络的直觉 显示一个简单的前馈图(3 层):
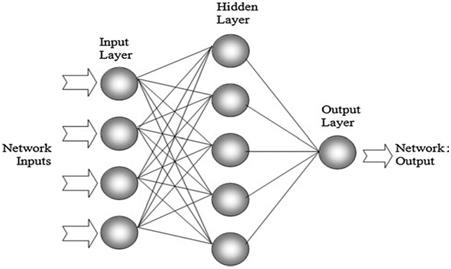
输入 → 隐藏 → 输出
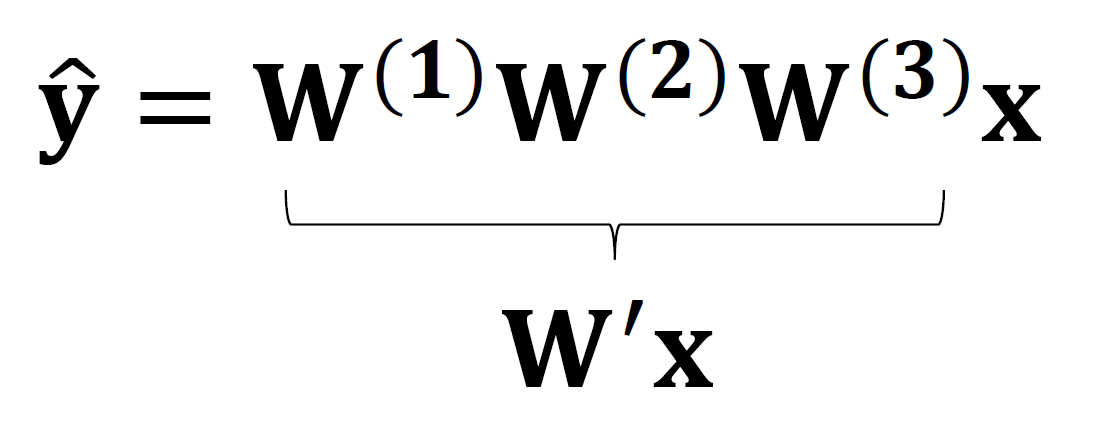
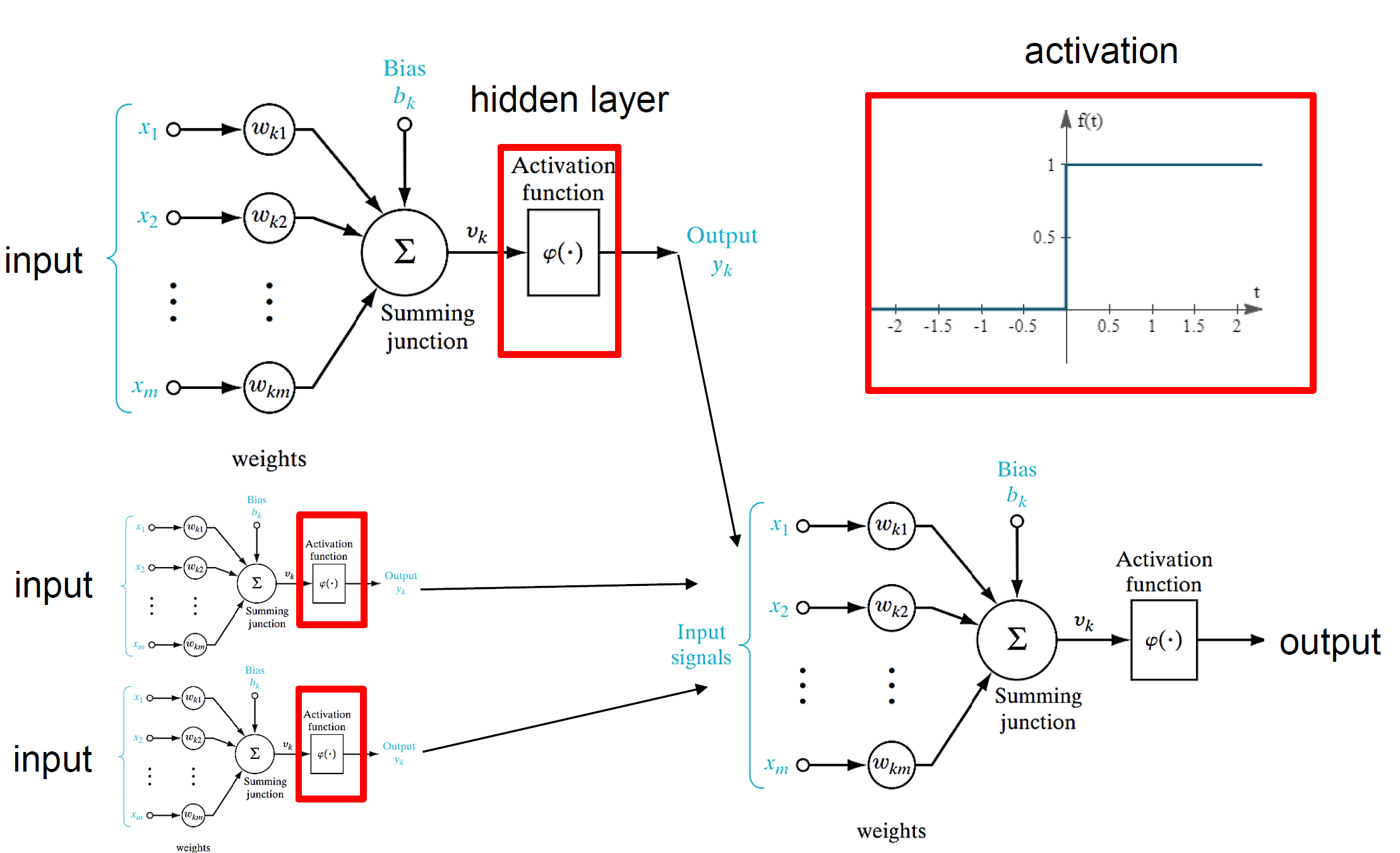
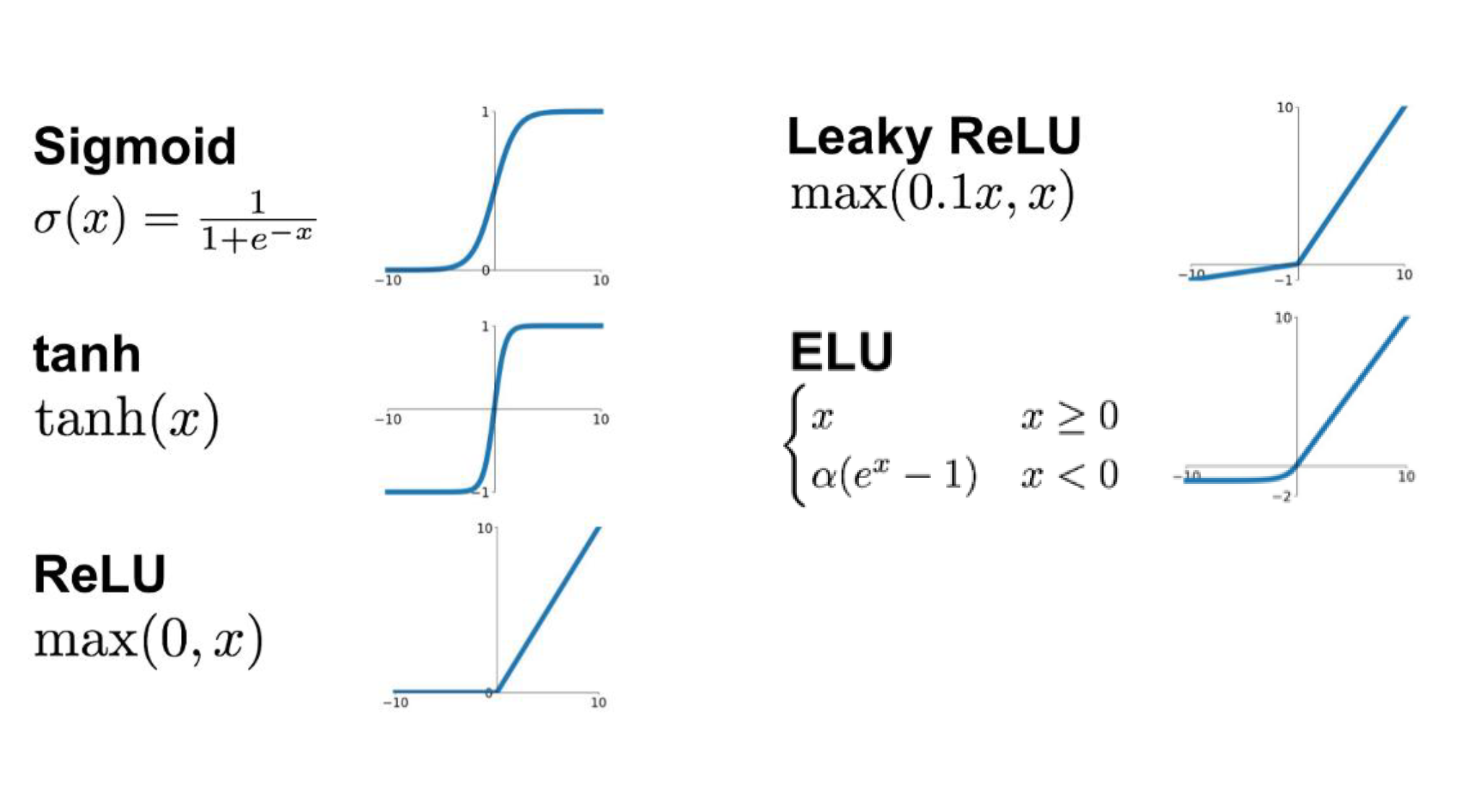
激活函数(例如,sigmoid、ReLU)
此时,机器就像一个简化的大脑,正在学习如何权衡输入和输出,但比我们更快、更一致。
以下代码,可以检验一下自己对数学公式的掌握:算出最后的输出是什么。
import numpy as np
# ===== 1. Define Inputs =====
x = np.array([[0.2], # Shape: (input_dim, 1)
[0.5],
[0.1]])
# ===== 2. Layer 1 Parameters =====
W1 = np.array([[0.1, 0.4, -0.3], # Shape: (hidden_dim, input_dim)
[-0.2, 0.2, 0.5]])
b1 = np.array([[0.1], # Shape: (hidden_dim, 1)
[0.05]])
# ===== 3. Layer 1 Output =====
z1 = W1 @ x + b1 # Shape: (hidden_dim, 1)
a1 = np.maximum(0, z1) # ReLU activation
# ===== 4. Layer 2 Parameters =====
W2 = np.array([[0.3, -0.6]]) # Shape: (output_dim=1, hidden_dim)
b2 = np.array([[0.2]]) # Shape: (output_dim, 1)
# ===== 5. Layer 2 Output =====
z2 = W2 @ a1 + b2 # Shape: (1, 1)
y_hat = 1 / (1 + np.exp(-z2)) # Sigmoid activation
# ===== 6. Display Output =====
print("z1 (hidden pre-activation):\n", z1)
print("a1 (hidden activation):\n", a1)
print("z2 (output pre-activation):\n", z2)
print("y_hat (final prediction):\n", y_hat)
在实际应用中,可以直接调用现成的函数,更方便:


















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











