







引言
接着上一篇博客,我们继续解读内存访问(access)文件夹下的另一个子文件夹heap,主要对heapam.cpp进行学习和解读。本次主要学习heap_inplace_update和heap_bcm_redo两个函数。
文件路径
opengauss-server\src\gausskernel\storage\access\heap\heapam.cpp
Function name:heap_inplace_update
这个函数,heap_inplace_update,用于在PostgreSQL数据库中原地更新一个元组。这个函数是OpenGauss的堆访问方法(heapam)的一部分,提供了访问堆结构(无序)表中存储数据的函数。 以下是函数的源码以及完整注释:
/** This function, heap_inplace_update, is used to update a tuple in-place withina OpenGauss database.*/void heap_inplace_update(Relation relation, HeapTuple tuple, bool waitFlush){Buffer buffer;Page page;OffsetNumber offnum, maxoff;ItemId lp = NULL;HeapTupleHeader htup;uint32 oldlen;uint32 newlen;errno_t rc;/** For now, parallel operations are required to be strictly read-only.* Unlike a regular update, this should never create a combo CID, so it* might be possible to relax this restriction, but not without more* thought and testing. It's not clear that it would be useful, anyway.*/if (false) {ereport(ERROR,(errcode(ERRCODE_INVALID_TRANSACTION_STATE), errmsg("cannot update tuples during a parallel operation")));}buffer = ReadBuffer(relation, ItemPointerGetBlockNumber(&(tuple->t_self)));//Reads the buffer: It reads the buffer that contains the block where the tuple to be updated is locatedLockBuffer(buffer, BUFFER_LOCK_EXCLUSIVE);//Locks the buffer: It locks the buffer exclusively to prevent other processes from accessing it during the updatepage = (Page)BufferGetPage(buffer);// Get the pages from the Bufferoffnum = ItemPointerGetOffsetNumber(&(tuple->t_self));maxoff = PageGetMaxOffsetNumber(page);if (maxoff >= offnum) {lp = PageGetItemId(page, offnum);}if (maxoff < offnum || !ItemIdIsNormal(lp)) {ereport(ERROR, (errcode(ERRCODE_DATA_CORRUPTED), errmsg("heap_inplace_update: invalid lp")));}//Retrieve the offset of the tuple on the page and check its validity.htup = (HeapTupleHeader)PageGetItem(page, lp);oldlen = ItemIdGetLength(lp) - htup->t_hoff;newlen = tuple->t_len - tuple->t_data->t_hoff;if (oldlen != newlen || htup->t_hoff != tuple->t_data->t_hoff) {ereport(ERROR, (errcode(ERRCODE_DATA_CORRUPTED), errmsg("heap_inplace_update: wrong tuple length")));}/* NO EREPORT(ERROR) from here till changes are logged */START_CRIT_SECTION();//This is a critical section that includes operations for updating tuple data and marking the buffer as dirty.rc = memcpy_s((char*)htup + htup->t_hoff, newlen, (char*)tuple->t_data + tuple->t_data->t_hoff, newlen);securec_check(rc, "\0", "\0");MarkBufferDirty(buffer);XLogRecPtr recptr = InvalidXLogRecPtr;//This line of code defines a log record pointer and initializes it with an invalid value.//This pointer will be used later in the code to record the log position./* XLOG stuff */if (RelationNeedsWAL(relation)) {xl_heap_inplace xlrec;xlrec.offnum = ItemPointerGetOffsetNumber(&tuple->t_self);XLogBeginInsert();XLogRegisterData((char*)&xlrec, SizeOfHeapInplace);XLogRegisterBuffer(0, buffer, REGBUF_STANDARD);XLogRegisterBufData(0, (char*)htup + htup->t_hoff, newlen);recptr = XLogInsert(RM_HEAP_ID, XLOG_HEAP_INPLACE);PageSetLSN(page, recptr);}//If Write-Ahead Logging (WAL) is enabled for the relation, it constructs a WAL record for the update and inserts it into the WAL bufferEND_CRIT_SECTION();UnlockReleaseBuffer(buffer);if (waitFlush && (recptr != InvalidXLogRecPtr)) {XLogWaitFlush(recptr);}/** Send out shared cache inval if necessary. Note that because we only* pass the new version of the tuple, this mustn't be used for any* operations that could change catcache lookup keys. But we aren't* bothering with index updates either, so that's true a fortiori.*/if (!IsBootstrapProcessingMode()) {CacheInvalidateHeapTuple(relation, tuple, NULL);}}
in-place
要想实现in-place,同时保证事务的原子性,恢复未提交事务,WAL是通常情况下最行之有效的手段。 WAL,全称为Write-Ahead Logging,是数据库系统中常见的一种手段,用于保证数据操作的原子性和持久性。在计算机科学中,预写式日志(Write-ahead logging,缩写 WAL)是关系数据库系统中用于提供原子性和持久性(ACID 属性中的两个)的一系列技术。在函数heap_inplace_update如下位置应用
if (RelationNeedsWAL(relation)) {......}
在使用WAL的系统中,所有的修改在提交之前都要先写入log文件中。log文件中通常包括redo和undo信息。 这样做的目的可以通过一个例子来说明:假设一个程序在执行某些操作的过程中机器掉电了。在重新启动时,程序可能需要知道当时执行的操作是成功了还是部分成功或者是失败了。如果使用了WAL,程序就可以检查log文件,并对突然掉电时计划执行的操作内容跟实际上执行的操作内容进行比较。在这个比较的基础上,程序就可以决定是撤销已做的操作还是继续完成已做的操作,或者是保持原样。
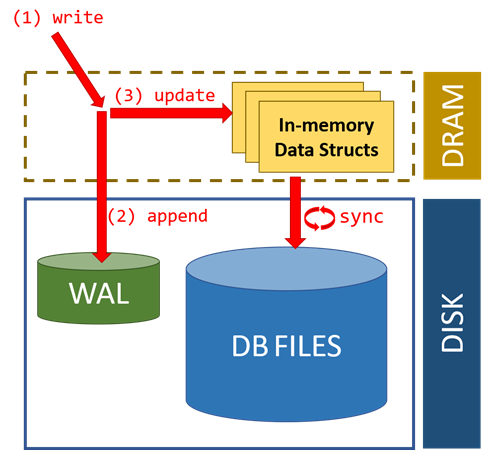
WAL允许用in-place方式更新数据库。另一种用来实现原子更新的方法是shadow paging,它并不是in-place方式。用in-place方式做更新的主要优点是减少索引和块列表的修改
举个例子,假设我们有一个数据库表,其中包含了一列是员工的薪水。现在,我们需要给所有员工的薪水增加10%。如果我们使用in-place更新,那么每个员工的薪水将直接在原始位置增加10%,而不会改变它们在磁盘上的位置。这意味着我们不需要更新任何索引或块列表,因为数据的物理位置没有改变。
相反,如果我们不使用in-place更新,那么每次薪水增加时,新的薪水值将在磁盘上的其他位置写入,然后我们需要更新索引和块列表以反映新值的位置。这将需要额外的计算和I/O操作,从而降低了性能。 如下图所示:
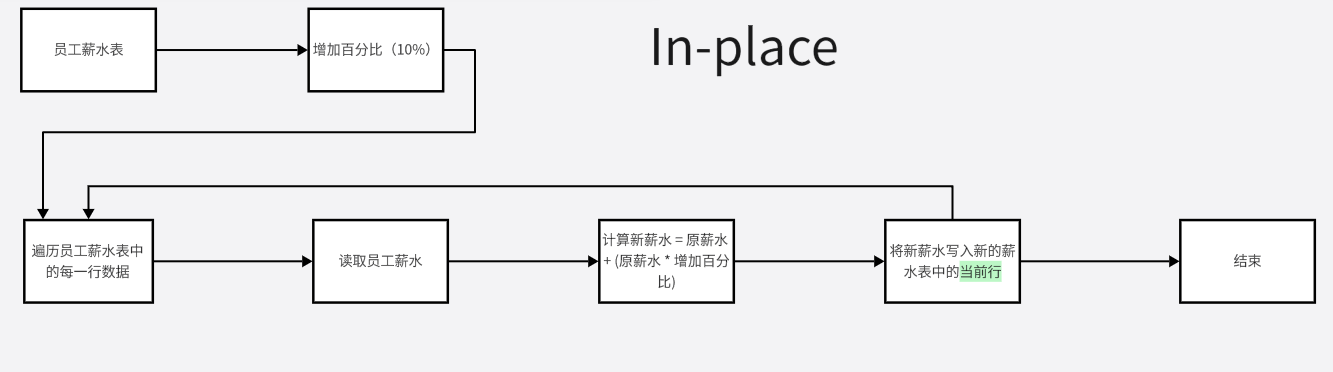
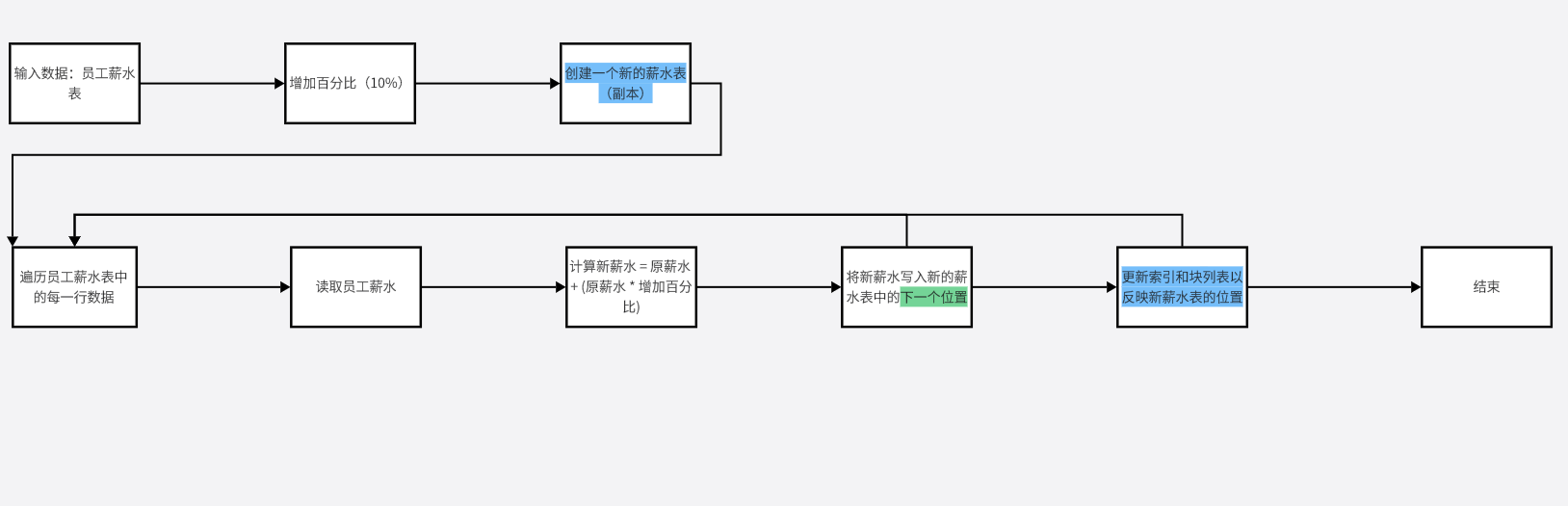
Function name:heap_bcm_redo
这个函数用于在数据库恢复过程中重做BCM(Block Change Map)的修改。BCM是一个数据结构,用于跟踪数据库中哪些块已经被修改过,从而在数据库崩溃恢复时只需要检查这些块。 以下是函数的源码以及完整注释:
/** Function name:heap_bcm_redo* xlrec:This is a pointer to the xl_heap_bcm structure, which contains information about the Block Change Map (BCM),such as block numbers, statuses, and counts.* node:This is a relation file node, which identifies a relation (i.e., a table) within the database. In PostgreSQL and openGauss, each table is composed of one or more files,each with an associated relation file node* lsn:This is a Log Sequence Number (LSN), which identifies a position within the log. During database recovery, LSN is used to determine which operations need to be redone.* Description:This function is used to redo modifications to the Block Change Map (BCM) during the database recovery process.* The BCM is a data structure used to track which blocks in the database have been modified, allowing for efficient checking of these blocks during database crash recovery.*/void heap_bcm_redo(xl_heap_bcm* xlrec, RelFileNode node, XLogRecPtr lsn){int col = xlrec->col;Relation reln = CreateFakeRelcacheEntry(node);Buffer bcmbuffer = InvalidBuffer;//If the number of columns is greater than 0, it indicates a column-stored table.//In this code block, the function processes each BCM for every column.if (col > 0) { /* cloumn store */BlockNumber curBcmBlock = 0;BlockNumber nextBcmBlock = 0;int i = 0;/* read current bcm block */curBcmBlock = HEAPBLK_TO_BCMBLOCK(xlrec->block + i);nextBcmBlock = curBcmBlock;BCM_CStore_pin(reln, col, ((xlrec->block + i) * ALIGNOF_CUSIZE), &bcmbuffer);LockBuffer(bcmbuffer, BUFFER_LOCK_EXCLUSIVE);do {/* deal with bcm block switch */if (nextBcmBlock != curBcmBlock) {curBcmBlock = nextBcmBlock;/* release last bcm block and read in the next one */UnlockReleaseBuffer(bcmbuffer);BCM_CStore_pin(reln, col, ((xlrec->block + i) * ALIGNOF_CUSIZE), &bcmbuffer);LockBuffer(bcmbuffer, BUFFER_LOCK_EXCLUSIVE);}/** Don't set the bit if replay has already passed this point.* and we are in t_thrd.xlog_cxt.InRecovery, no need to consider log_heap_bcm.*/if (!XLByteLE(lsn, PageGetLSN(BufferGetPage(bcmbuffer)))) {BCMSetStatusBit(reln, xlrec->block + i, bcmbuffer, xlrec->status, col);ereport(DEBUG2,(errmsg("BCMSetStatusBit: oid:%u col:%d block:%lu status: %d",reln->rd_node.relNode,col,xlrec->block + i,NOTSYNCED)));}i++;nextBcmBlock = HEAPBLK_TO_BCMBLOCK(xlrec->block + i);} while (i < xlrec->count);UnlockReleaseBuffer(bcmbuffer);//Unlock and release the buffer.} else { /* row store */BCM_pin(reln, xlrec->block, &bcmbuffer);//Get the particular BCM buffer.LockBuffer(bcmbuffer, BUFFER_LOCK_EXCLUSIVE);if (!XLByteLE(lsn, PageGetLSN(BufferGetPage(bcmbuffer)))) {BCMSetStatusBit(reln, xlrec->block, bcmbuffer, xlrec->status, col);}//Judge the lsn to ensure that only after the modifications to BCM have been recorded in the log//will they be redone during the recovery process.UnlockReleaseBuffer(bcmbuffer);}FreeFakeRelcacheEntry(reln);}
BCM
Block Change Map(BCM)是数据库系统中用于跟踪哪些数据块已经被修改过的数据结构。在数据库恢复过程中,BCM可以帮助系统确定哪些数据块需要被检查和恢复。 SQL Server物理文件的结构如下图所示:

对于PFS,GAM等更多知识可以参考链接 页和区 | Microsoft Learn
在SQL Server中,BCM页面用于跟踪自上次日志备份操作以来由于批量记录操作而修改的范围。 在数据库文件里,BCM页是第7页。BCM对每个跟踪的页都有一个位。如果这个位标记是1,表示对应区在上次日志备份后因为大容量日志操作而修改。如果这个位标记为0,表示在上次日子备份后因为大容量日志操作而未被修改。一个BCM页可以保存近64000个区的信息。BCM页在每511232页重复一次。一个BCM页可以跟踪63904个区的信息。第2个BCM页会出现在第511239页 在批量记录恢复模式下,当执行日志备份时,SQL Server会扫描BCM页面,并将标记为已更改的范围包含在日志备份中,以及事务日志。这样,如果从数据库备份和一系列事务日志备份中恢复数据库,SQL Server可以使批量记录操作可恢复。
小结
heapam.cpp的框架如下表所示
| 模块 | 描述 |
|---|---|
| relation_open | 通过关系的OID(对象标识符)打开任何关系 |
| relation_openrv | 通过RangeVar指定的方式打开任何关系 |
| relation_close | 关闭任何关系 |
| heap_open | 通过关系的OID打开堆关系 |
| heap_openrv | 通过RangeVar指定的方式打开堆关系 |
| heap_close | 关闭堆关系(现在通常是一个用于relation_close的宏) |
| heap_beginscan | 开始对关系的扫描 |
| heap_rescan | 重新启动关系扫描 |
| heap_endscan | 结束关系扫描 |
| heap_getnext | 检索扫描中的下一个元组 |
| heap_fetch | 根据给定的TID(元组标识符)检索元组 |
| heap_insert | 将元组插入关系 |
| heap_multi_insert | 将多个元组插入关系 |
| heap_delete | 从关系中删除元组 |
| heap_update | 用另一个元组替换关系中的元组 |
| heap_markpos | 标记扫描位置 |
| heap_restrpos | 将位置恢复到标记的位置 |
| heap_sync | 同步堆,用于当未写入WAL(Write-Ahead Logging)时的情况 |
本次继续对heapam.cpp中的函数做了学习和解读,并且对heapam.cpp的函数框架做了初步总结,在下一篇博客当中,我将全面学习heapam.cpp的内容,并且对文件的函数做一个总结。















 912
912











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









