






目录
MySQL数据库结构
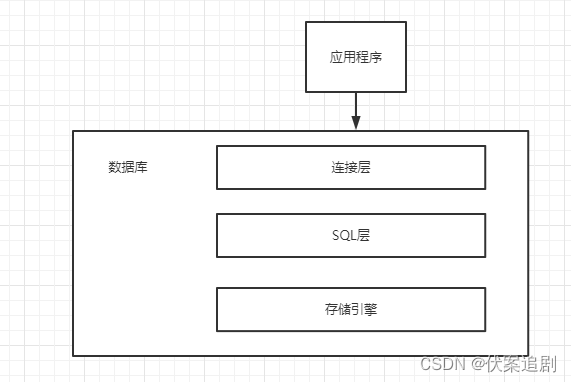
连接层:客户端和服务器端建立连接,客户端发送SQL至服务器端;
SQL 层:对SQL语句进行查询处理;
存储引擎层:与数据库文件打交道,负责数据的存储和读取。
MySQL执行流程
MySQL8.0之前的版本;

MySQL8.0版本
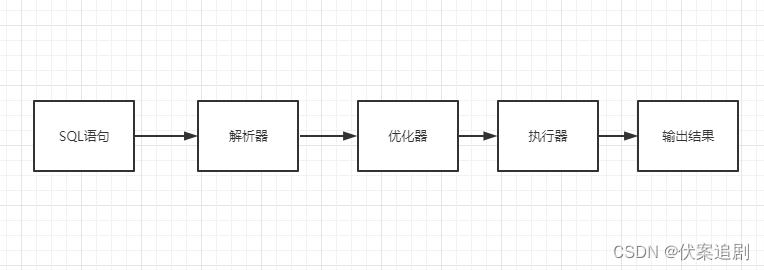
解析器:在解析器中对 SQL 语句进行语法分析、语义分析。
优化器:在优化器中会确定 SQL 语句的执行路径,比如是根据全表检索,还是根据索引来检
索等。
执行器:在执行之前需要判断该用户是否具备权限,如果具备权限就执行SQL查询并返回结果。
在 MySQL8.0 以下的版本,如果设置了查询缓存,这时会将查询结果进行缓存。
存储引擎
MySQL的存储引擎采用了插件的形式,每个存储引擎都针对特定的数据库应用环境。
MySQL每个表的设计都可以采用不同的存储引擎,可以根据数据处理需要来选择存储引擎。
常用的存储引擎:
InnoDB:MySQL5.5版本之后默认的存储引擎,特点是支持事务、行级锁定、外键约束等。
MyISAM:MySQL5.5版本之前是默认的存储引擎,不支持事务,也不支持外键,最大的特点
是速度快,占用资源少。
Memory:用系统内存作为存储介质,以便得到更快的响应速度。如果mysqld进程崩溃,则会
导致所有的数据丢失,用于临时存储;
Archive:有很好的压缩机制,用于文件归档,在请求写入时会进行压缩,所以也经常用来做
仓库。
NDB:也叫做 NDB Cluster 存储引擎,主要用于 MySQL Cluster 分布式集群环境,类似于
Oracle 的 RAC 集群。
数据存储结构

页:数据库管理存储空间的基本单位,包含多个数据行。
页如果按类型划分的话,常见的有数据页、系统页、Undo 页和事务数据页等。
查看页大小:mysql> show variables like '%innodb_page_size%';
区:是比页大一级的存储结构,在InnoDB存储引擎中,一个区会分配64个连续的页。InnoDB
中的页大小默认是16KB,一个区的大小是 64*16KB=1MB。
段:由一个或多个区组成,区在文件系统是一个连续分配的空间(在 InnoDB 中是连续的 64
个页),段中不要求区与区之间是相邻的。
段是数据库中的分配单位,不同类型的数据库对象以不同的段形式存在。创建数据表、索引
的时候,会创建对应的段,比如创建一张表时会创建一个表段,创建一个索引时会创建一个索引
段。
表空间:逻辑容器,表空间存储的对象是段,在一个表空间中可以有一个或多个段,但是一
个段只能属于一个表空间。
数据库由一个或多个表空间组成,表空间从管理上可以划分为系统表空间、用户表空间、撤
销表空间、临时表空间等。
InnoDB 中存在两种表空间的类型:共享表空间和独立表空间。
如果是共享表空间就意味着多张表共用一个表空间。如果是独立表空间,就意味着每张表有
一个独立的表空间,也就是数据和索引信息都会保存在自己的表空间中。独立的表空间可以在不同
的数据库之间进行迁移。
查看表空间的类型:mysql> show variables like '%innodb_page_size%';
页的结构
记录是按照行来存储的,但是数据库的读取并不以行为单位,否则效率会非常低。
数据库 I/O 操作的最小单位是页,与数据库相关的内容都会存储在页结构里。
数据页的内容
文件头(File Header)
页头(Page Header)
最大最小记录(Infimum+supremum)
用户记录(User Records)
空闲空间(Free Space)
页目录(Page Directory)
文件尾(File Tailer)
第一部分:文件头和文件尾,类似集装箱,封装页的内容,通过文件头和文件尾校验的方式
来确保页的传输是完整的。
文件头中有两个字段分别指向上一个数据页和下一个数据页;连接起来的页相当于一个双向
的链表。
第二个部分:记录部分:最小、最大记录和用户记录;页的主要作用是存储记录,所以“最小
和最大记录”和“用户记录”部分占了页结构的主要空间。
第三部分:页目录,起到了记录的索引作用;在页中,记录是以单向链表的形式进行存储
的。单向链表插入、删除方便,但是检索效率不高;
页目录中提供了二分查找的方式,用来提高页内记录的检索效率。
页目录实现原理:
1,将页内记录分成几个组;
2,页目录用来存储每组最后一条记录的地址偏移量,这些地址偏移量会按照先后顺序存储起
来,每个地址偏移量指向了不同组的最后一个记录。
3,在页内查找数据的时候,对页目录进行二分查找,然后定位到具体的数据记录;
数据页加载的方式
1. 内存读取
缓冲池管理器会尽量将经常使用的数据保存起来,在数据库进行页面读操作的时候,首先会
判断该页面是否在缓冲池中,如果存在就直接读取,如果不存在,就会通过内存或磁盘将页面存放
到缓冲池中再进行读取。
2. 随机读取
如果数据没有在内存中,就需要在磁盘上对该页进行查找,读取;
3. 顺序读取
顺序读取其实是一种批量读取的方式,因为我们请求的数据在磁盘上往往都是相邻存储的,
顺序读取可以帮我们批量读取页面;
一条 SQL 查询语句在执行前需要确定查询计划,如果存在多种查询计划的话,MySQL 会计
算每个查询计划所需要的成本,从中选择成本最小的一个作为最终执行的查询计划。
在执行完这条 SQL 语句之后,通过查看当前会话中的 last_query_cost 变量值来得到当前查
询的成本。这个查询成本对应的是 SQL 语句所需要读取的页的数量。
mysql> SHOW STATUS LIKE 'last_query_cost';
采用了顺序读取的方式将页面一次性加载到缓冲池中,然后再进行查找。即使页数量
(last_query_cost)增加,但是通过缓冲池的机制,查询时间不会增加多少。
查询优化器
查询优化器的目标是找到执行SQL查询的最佳执行计划。
执行计划就是查询树,它由一系列物理操作符组成,这些操作符按照一定的运算关系组成查
询的执行计划。
查询优化器中分为:逻辑查询优化阶段、物理查询优化阶段。
逻辑查询优化:通过改变SQL语句的内容来使得SQL查询更高效,逻辑查询优化是基于关系
代数进行的查询重写。
物理查询优化:关系代数的每一步都对应着物理计算,这些物理计算往往存在多种算法,因
此需要计算各种物理路径的代价,从中选择代价最小的作为执行计划。
生成执行计划的策略
生成最佳执行计划的策略通常有以下两种方式。
第一种是基于规则的优化器,规则就是人们以往的经验,或者是采用已经被证明是有效的方
式。通过在优化器里面嵌入规则,来判断 SQL 查询符合哪种规则,就按照相应的规则来制定执行
计划,同时采用启发式规则去掉明显不好的存取路径。
第二种是基于代价的优化器,这里会根据代价评估模型,计算每条可能的执行计划的代价,
从中选择代价最小的作为执行计划。基于代价的优化器会利用数据表中的统计信息来做判断,针对
不同的数据表,查询得到的执行计划可能是不同的,因此制定出来的执行计划也更符合数据表的实
际情况。
代价模型
查看和修改优化器用来统计各种步骤的代价模型;
SQL > SELECT * FROM mysql.server_cost
server_cost 数据表是在 server 层统计的代价;
SQL > SELECT * FROM mysql.engine_cost
engine_cost主要统计了页加载的代价;
修改参数:
UPDATE mysql.engine_cost SET cost_value = 2.0
WHERE cost_name = 'io_block_read_cost';
FLUSH OPTIMIZER_COSTS;
代价模型的计算
总代价 = I/O 代价 + CPU 代价















 2997
2997











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









