







缓存
缓存,存储给定资源的拷贝并在下一次请求的时候将拷贝内容提供回去。当一个Web缓存在存储中有请求的资源,它将会截获该请求并返回存储值而不是从原始服务器重新下载。
缓存是系统优化中简单而又有效的工具,投入成本小但收获效益高。缓存有三个重要的概念:缓存命中、缓存命中率、缓存数据的一致性。
应尽可能的通过缓存直接获取数据,并且避免缓存失效。尽可能的聚焦在高频访问且时效性要求不高的热点业务上,并通过缓存预加载(预热)、增加存储容量、调整缓存粒度、更新缓存等手段来提高命中率。
使用缓存可以减少系统开销,提高系统效率
客户端响应缓存
HTTP 协议中对缓存进行控制的RFC7324规范,其中重要的是 cache-control 响应报文头。
在 ASP.NET Core中,只要给需要进行缓存控制的 Action 方法添加标注ResponseCache特性,ASP.NET Core会自动添加 cache-control 报文头:
[HttpGet]
[ResponseCache(Duration = 10)]
public DateTime GetNow()
{
return DateTime.Now;
}
ResponseCache 也可以标注到 Class 上
结果:

可以看到第一次请求确实向服务端发送了请求,有Size,Time,其他的Size是(disk cache),请求时间也是0ms,说明是从客户端缓存获取的。
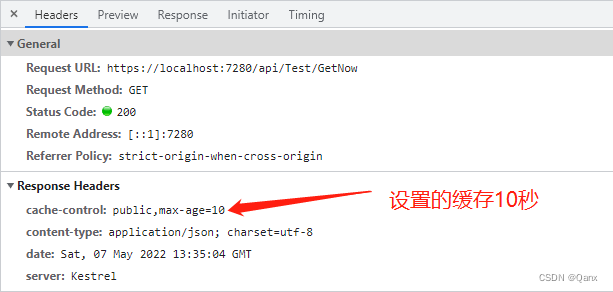
这里有个坑,就是如果你通过https使用自签名证书进行请求,那么无论使用那种缓存标头,Google都不会响应。相关问题可以参考关于谷歌浏览器缓存失效解析
服务器端响应缓存
在ASP.NET Core 中可以使用响应缓存中间件(Response Caching Middleware)来增加服务器端缓存。此时ASP.NET Core 不仅会继续根据[ResponseCache]的设置生成 cache-control 响应报文头来设置客户端缓存,而且服务器端也会按照[ResponseCache]的设置来对响应进行服务器端缓存。
服务器端缓存,可以理解为包裹在服务器外围的一层请求拦截器(如果缓存有该请求,那么就直接返回,不需要服务器处理了),主要用于多客户端(支持或不支持客户端缓存的客户端)访问同一个服务器的情况,能够降低服务器端的压力
服务器端安装响应缓存中间件 Microsoft.AspNetCore.ResponseCaching,在 Program.cs 中:
app.UseResponseCaching();
需要在app.MapControllers()之前。
调试运行,用 Postman 发送请求可以看到,在缓存时间内,服务器端请求并没有到达 Action,请求确实被服务器端缓存拦截了。然后用 Chrome 浏览器如图禁用缓存,发现服务器端缓存又失效了。
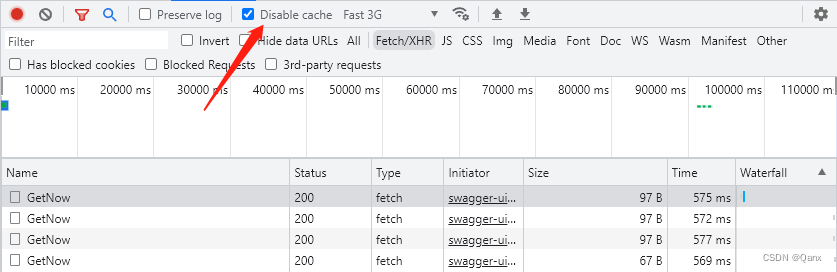
查看禁用客户端缓存和没禁用的请求区别,发现请求头中多了 cache-control: no-cache。
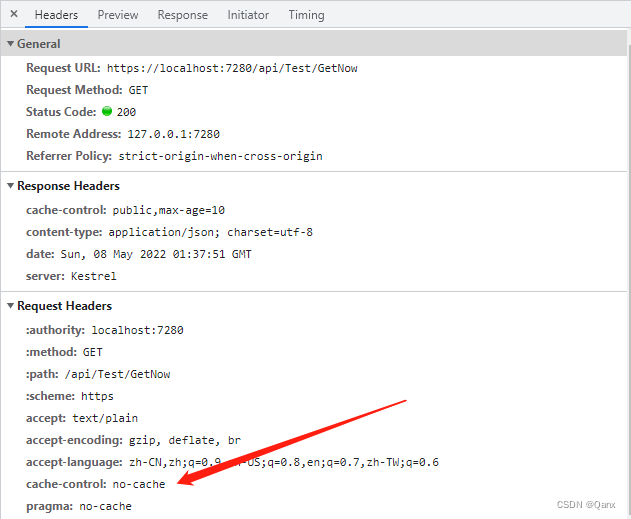
到此可以知道服务器端响应缓存是同样遵守 RFC7324 规范的,所以也就知道服务器端缓存比较鸡肋了:
- 并不能解决恶意请求给服务器带来的压力(可以自己构造请求头)
- 其他限制包括但不限于:只有响应状态码为 200 的 GET 或者 HEAD 请求才可能被缓存(由于遵守 HTTP 缓存协议)、报文头中不能含有 Authorization、Set-Cookie等
Authorization 会导致缓存失效、Set-Cookie 需要和服务器端交换信息,不能缓存
内存缓存(In-memory cache)
内存缓存的数据保存在当前运行的网站程序的内存中,是和进程相关的。在Web服务器中,每个网站是运行在单独的进程中的,所以不同网站的内存缓存也是相互独立不会互相干扰的。
由于在进程的内存中,所以网站重启后,内存被释放,内存缓存中的数据也就被清空了
内存缓存保存的也是一系列的键值对,类似 Dictionary
ASP.NET Core 中,在 Program.cs 添加缓存的服务(需要包 Microsoft.Extensions.Caching.Memory):
builder.Services.AddMemoryCache();
Controller 构造函数中注入IMemoryCache:
private readonly IMemoryCache _memoryCache;
private readonly StockDbContext _stockDbContext;
public StockTradingController(StockDbContext dbContext, IMemoryCache memoryCache)
{
this._stockDbContext = dbContext;
this._memoryCache = memoryCache;
}
// 使用
[HttpGet("{tradingRecordId}")]
public async Task<ActionResult<ApiResult>> GetTradingRecordDetail(long tradingRecordId)
{
var tradingRecord = await _memoryCache.GetOrCreateAsync(nameof(StockTradingRecord) + tradingRecordId, async (cacheEntry) =>
{
return await _stockDbContext.StockTradingRecords.AsNoTracking()
.Select(d => new StockTradingRecordDto()
{
Id = d.Id,
TransactionAmount = d.TransactionAmount,
ServiceCharge = d.ServiceCharge,
StampDuty = d.StampDuty,
State = d.State,
TransactionDateTime = d.TransactionDateTime,
TransactionNumber = d.TransactionNumber,
TransactionPrice = d.TransactionPrice,
TransferFee = d.TransferFee
})
.SingleOrDefaultAsync(d => d.Id == tradingRecordId);
});
if (tradingRecord == null)
{
return NotFound(new ApiResult(ApiResultCodeType.Failed) { Message = "未查询到交易记录详情" });
}
else
{
return new ApiResult(ApiResultCodeType.Success) { Data = tradingRecord };
}
}
缓存的过期时间策略
上面已经提到使用缓存必须要考虑的一个问题就是:缓存数据的一致性。在数据发送改变的时候可以调用Remove或者Set来删除或者修改缓存,这种方式能够使缓存及时的响应数据的更新。
另一种方式是通过设置缓存的过期时间
只要过期时间比较短,缓存数据不一致的情况不会持续很长时间。实际结合业务场景综合考量
绝对过期时间策略
绝对过期时间,当设置的过期时间一到,缓存立即过期。GetOrCreateAsync()方法的回调方法有一个ICacheEntry类型的参数,通过ICacheEntry可以对当前缓存项进行设置:
var tradingRecord = await _memoryCache.GetOrCreateAsync(nameof(StockTradingRecord) + tradingRecordId, async (cacheEntry) =>
{
cacheEntry.AbsoluteExpirationRelativeToNow = TimeSpan.FromSeconds(20); // 获取或设置相对于现在的绝对过期时间
/* ………同上,略……… */
});
滑动过期时间策略
滑动过期时间,当设置的过期时间还没有到时,缓存项被访问了,那么过期时间从被访问的时间开始重新计算。同样通过 ICacheEntry设置滑动过期时间:
var tradingRecord = await _memoryCache.GetOrCreateAsync(nameof(StockTradingRecord) + tradingRecordId, async (cacheEntry) =>
{
cacheEntry.SlidingExpiration = TimeSpan.FromSeconds(5); // 设置滑动过期时间,不会将缓存项生存期延长到绝对过期(如果已设置)之后
/* ………同上,略……… */
});
混合使用
单纯的使用滑动过期时间的场景是不存在的。如果一个缓存项一直被频繁访问,在理想情况下,这个缓存项的过期时间就会一直被续期而不过期,而这极有可能导致数据不一致。
可以对一个缓存项同时设定绝对过期时间和滑动过期时间,并且把绝对过期时间设定的比滑动过期时间长。这样缓存项在绝对过期时间内会随着访问被滑动续期,但是一旦超过了绝对过期时间,缓存项任然会被删除。
滑动过期时间,不会将缓存项生存期延长到绝对过期(如果已设置)之后
无论使用那种过期时间策略,程序中都会存在缓存数据不一致的情况。结合具体的业务场景选择合适的缓存粒度,也可以通过其他机制来获取数据源改变的消息,然后通过IMemoryCache的Set方法更新缓存。
缓存穿透
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,进而给数据库带来压力。
先看一下GetOrCreateAsync分解的写法(会造成缓存穿透):
string key = nameof(StockTradingRecord) + tradingRecordId;
var result = _memoryCache.Get<StockTradingRecordDto>(key); // 缓存为 null
if (result == null) // 判断为 null
{
// 查询数据库
result = await _stockDbContext.StockTradingRecords.AsNoTracking()
.Select(d => new StockTradingRecordDto()
{
Id = d.Id,
…………
})
.SingleOrDefaultAsync(d => d.Id == tradingRecordId);
// 写入缓存
_memoryCache.Set(key, result); // null 不会写入
}
如上面代码,缓存为 null ==> 查询数据库,查询到 null == > 尝试写入缓存(null 不写入) ==> 下次请求缓存为 null,如此循环往复,每次都会去数据库中查询,缓存对于不存在的数据时不起作用的,这就是缓存穿透。
解决方案有两种:
- 对 url 中的 key id 值进行对称加密,不暴露出真实的 key 值(这样就不能构造一个合法的一定不存在的 id 值了)
- 不管数据实际上存不存在,都把这个键存到缓存中(有效期可以设置的短一些),把值设置为一个特定值(业务中如果获取到的结果是这个特定值,则进行处理,如:返回
NotFound)
GetOrCreateAsync方法天然的可以避免缓存穿透,里面会将空值作为一个有效值(内部原理类似方案二,会同样缓存不存在的值 null)。
所以推荐使用
GetOrCreateAsync,如果不支持可以参照方案二进行特殊处理
缓存雪崩
导致缓存雪崩其中一种就是缓存时间集体过期,一致的过期时间导致数据库周期行的压力的问题。大量的缓存数据在同一时间过期,此时如果有大量的用户请求,都无法在通过缓存中处理,于是全部请求都直接访问数据库,从而导致数据库的压力骤增,严重的会造成数据库宕机,从而形成一系列连锁反应,造成整个系统崩溃,这就是缓存雪崩的问题。
应对缓存时间集体过期导致的雪崩有以下几种方案:
- 均匀分布过期时间:要点是给这些数据的过期时间加上一个随机数
- 互斥锁:如果发现访问的数据不在缓存里,就加个互斥锁,保证同一时间内只有一个请求来构建缓存
- 双 key 策略:主 key 设置过期时间,备 key 不设置过期时间,当访问不到主 key 的缓存数据时,就直接返回备 key 的缓存数据,在更新缓存的时候,同时更新主 key 和备 key 的数据。
- 后台更新缓存:业务线程缓存不设置有效期,让缓存“永久有效”,交由后台线程定时更新,后台线程也可以负责检测缓存是否有效或者业务线程发现缓存失效后发送一条消息通知告诉后台线程更新缓存
方案更详尽的解释看什么是缓存雪崩、击穿、穿透?
均匀分布的过期时间(即随机时间):
cacheEntry.AbsoluteExpirationRelativeToNow = TimeSpan.FromSeconds(Random.Shared.Next(10, 15)); // 随机10~15秒
其他方案要考虑业务场景。















 561
561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











