






不知道有没有关注播客,播客其实很久以前就出来了,记得iPhone里还专门有个Podcast的应用,但一直没有火起来,怎么着播客突然就成为新的趋势。这种主要以双人对话形式的音频节目包含的信息量丰富,涉及的话题广泛,弥补了既有内容形式的许多不足,我很喜欢使用的就有一个叫“小宇宙”的APP,“42章经”、“高能量”都是很不错的播客。关注播客又关注AI应用的同学,英伟达最近发布的一个项目PDF to Podcast值得留意,这个项目能够将任意多个的PDF文件转换成单人或者双人播客。Github源代码可以找到源代码。抛开项目各种细小琐碎的代理处理逻辑,这个项目最值得留意的是能够将很大量的Prompts通过指定Schema后如编程一样很结构的联动起来生成需要的内容。
1. 首先关注项目的实现架构从下图左下角可以看到项目实现步骤如下:
- 将目标PDF文件和可选的提供上下文环境的PDF文件通过Docling处理成Markdown格式(这个Docling后续值得关注下,似乎能够识别扫描版的PDF)
- 接下来一共通过9个Prompts来从原始PDF文档转化为最终的播客对话脚本,留意这9个Prompts使用的大语言模型各自不同。这个非常精细,找合适的模型干合适的事,能够省资源,不过也有点玩票,如果我来做,大概率就OpenAI或者ERINE或者千问最好版本的模型一站到底了。
- 调用ElevenLabs的Text-to-Speech来将文本转换为语音,ElevenLabs是目前最好的语音AI。
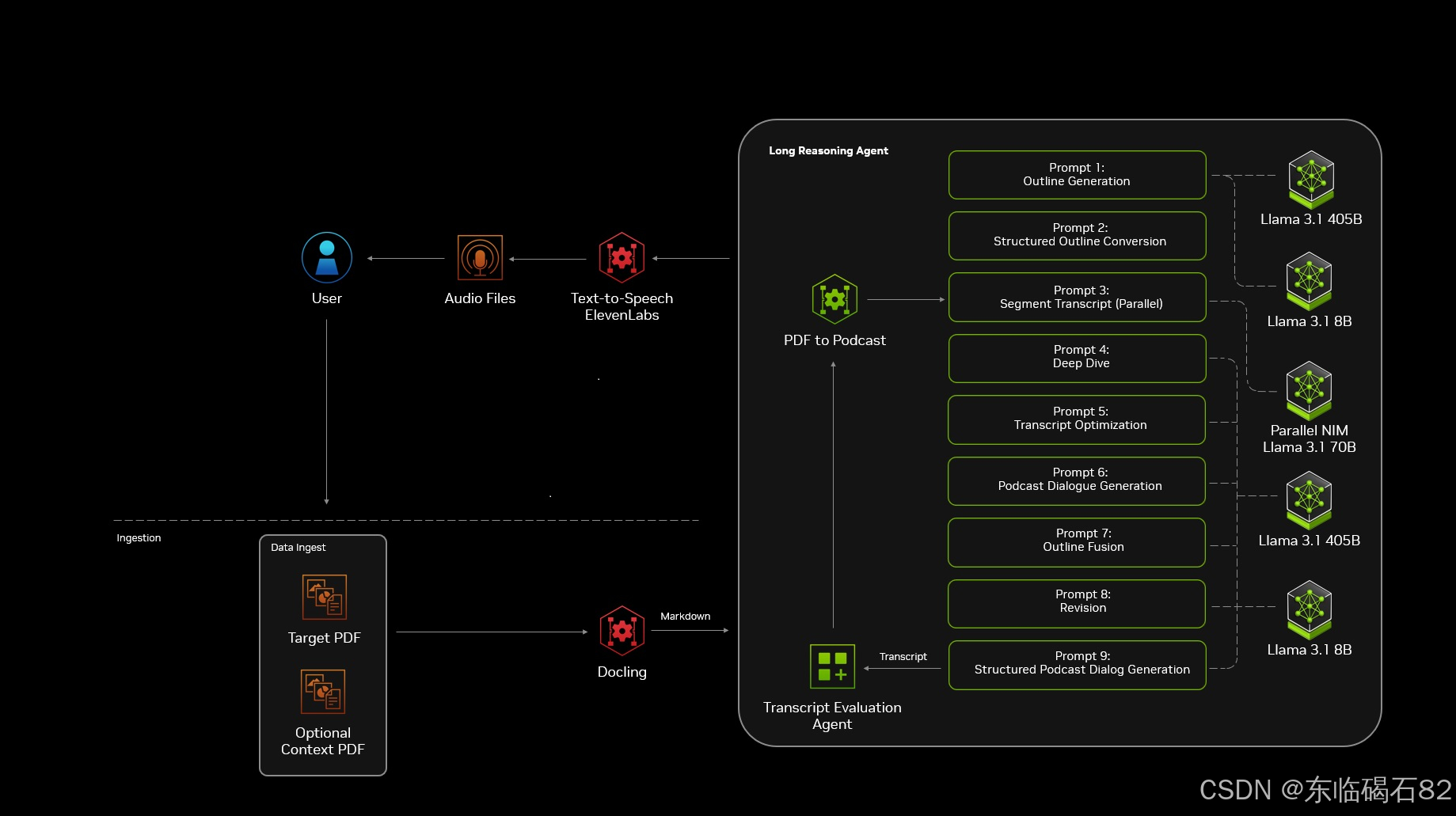
2. 下面我们着重关注下每个Prompt的使用技巧,这里我们仅罗列两人对话的Prompts,单人播客在这个项目中使用另一套Prompts。首先是生成PDF文档summary的Prompt,这个主要是从财务年报来进行汇总,可以看到Prompt内容与之相关,最后要求用markdown的格式输出。
# Template for summarizing individual PDF document
PODCAST_SUMMARY_PROMPT_STR = """
Please provide a comprehensive summary of the following document. Note that this document may contain OCR/PDF conversion artifacts, so please interpret the content, especially numerical data and tables, with appropriate context.
<document>
{{text}}
</document>
Requirements for the summary:
1. Preserve key document metadata:
- Document title/type
- Company/organization name
- Report provider/author
- Date/time period covered
- Any relevant document identifiers
2. Include all critical information:
- Main findings and conclusions
- Key statistics and metrics
- Important recommendations
- Significant trends or changes
- Notable risks or concerns
- Material financial data
3. Maintain factual accuracy:
- Keep all numerical values precise
- Preserve specific dates and timeframes
- Retain exact names and titles
- Quote critical statements verbatim when necessary
Please format the summary using markdown, with appropriate headers, lists, and emphasis for better readability.
Note: Focus on extracting and organizing the most essential information while ensuring no critical details are omitted. Maintain the original document's tone and context in your summary.
"""3. 再关注第二个Prompt,代码的逻辑会使用第一个Prompt逐个PDF汇总内容,然后再通过这个Prompt来基于所有的汇总内容来生成大纲:
# Template for synthesizing multiple document summaries into an outline
PODCAST_MULTI_PDF_OUTLINE_PROMPT_STR = """
Create a structured podcast outline synthesizing the following document summaries. The podcast should be {{total_duration}} minutes long.
Focus Areas & Key Topics:
{% if focus_instructions %}
{{focus_instructions}}
{% else %}
Use your judgment to identify and prioritize the most important themes, findings, and insights across all documents.
{% endif %}
Available Source Documents:
{{documents}}
Requirements:
1. Content Strategy
- Focus on the content in Target Documents, and use Context Documents as support and context
- Identify key debates and differing viewpoints
- Analyze potential audience questions/concerns
- Draw connections between documents and focus areas
2. Structure
- Create clear topic hierarchy
- Assign time allocations per section (based on priorities)
- Reference source documents using file paths
- Build natural narrative flow between topics
3. Coverage
- Comprehensive treatment of Target Documents
- Strategic integration of Context Documents for support
- Supporting evidence from all relevant documents
- Balance technical accuracy with engaging delivery
Ensure the outline creates a cohesive narrative that emphasizes the Target Documents while using Context Documents to provide additional depth and background information.
"""留意这段代码里使用了较多的变量,以下是如何将这些变量进行替换的Python代码:
documents = []
for pdf in summarized_pdfs:
doc_str = f"""
<document>
<type>{"Target Document" if pdf.type == "target" else "Context Document"}</type>
<path>{pdf.filename}</path>
<summary>
{pdf.summary}
</summary>
</document>"""
documents.append(doc_str)
template = PodcastPrompts.get_template("podcast_multi_pdf_outline_prompt")
prompt = template.render(
total_duration=request.duration,
focus_instructions=request.guide if request.guide else None,
documents="\n\n".join(documents),
)
raw_outline: AIMessage = await llm_manager.query_async(
"reasoning",
[{"role": "user", "content": prompt}],
"raw_outline",
)
4. 接下来的提示词将前面生成的大纲转换为JSON格式:
# Template for converting outline into structured JSON format
PODCAST_MULTI_PDF_STRUCUTRED_OUTLINE_PROMPT_STR = """
Convert the following outline into a structured JSON format. The final section should be marked as the conclusion segment.
<outline>
{{outline}}
</outline>
Output Requirements:
1. Each segment must include:
- section name
- duration (in minutes) representing the length of the segment
- list of references (file paths)
- list of topics, where each topic has:
- title
- list of detailed points
2. Overall structure must include:
- podcast title
- complete list of segments
3. Important notes:
- References must be chosen from this list of valid filenames: {{ valid_filenames }}
- References should only appear in the segment's "references" array, not as a topic
- Duration represents the length of each segment, not its starting timestamp
- Each segment's duration should be a positive number
The result must conform to the following JSON schema:
{{ schema }}
"""这里的一个技巧是最后两行的prompt,要求转换后的内容遵循指定的格式,以下是对应的Python代码实现,通过schema指定了JSON的输出格式:
# Force the model to only reference valid filenames
valid_filenames = [pdf.filename for pdf in request.pdf_metadata]
schema = PodcastOutline.model_json_schema()
schema["$defs"]["PodcastSegment"]["properties"]["references"]["items"] = {
"type": "string",
"enum": valid_filenames,
}
schema = PodcastOutline.model_json_schema()
template = PodcastPrompts.get_template(
"podcast_multi_pdf_structured_outline_prompt"
)
prompt = template.render(
outline=raw_outline,
schema=json.dumps(schema, indent=2),
valid_filenames=[pdf.filename for pdf in request.pdf_metadata],
)
outline: Dict = await llm_manager.query_async(
"json",
[{"role": "user", "content": prompt}],
"outline",
json_schema=schema,
)5. 接来下处理如果指定参考文档的情况,这个参考文档大概就是非主要的内容来源,但是有能够对播客脚本的生成起到帮助的辅助材料:
# Template for generating transcript with source references
PODCAST_PROMPT_WITH_REFERENCES_STR = """
Create a transcript incorporating details from the provided source material:
Source Text:
{{ text }}
Parameters:
- Duration: {{ duration }} minutes (~{{ (duration * 180) | int }} words)
- Topic: {{ topic }}
- Focus Areas: {{ angles }}
Requirements:
1. Content Integration
- Reference key quotes with speaker name and institution
- Explain cited information in accessible terms
- Identify consensus and disagreements among sources
- Analyze reasoning behind different viewpoints
2. Presentation
- Break down complex concepts for general audience
- Use relevant analogies and examples
- Address anticipated questions
- Provide necessary context throughout
- Maintain factual accuracy, especially with numbers
- Cover all focus areas comprehensively within time limit
Ensure thorough coverage of each topic while preserving the accuracy and nuance of the source material.
"""
6. 如果没有指定参考文档,则使用不同的Prompt:
# Template for generating transcript without source references
PODCAST_PROMPT_NO_REFERENCES_STR = """
Create a knowledge-based transcript following this outline:
Parameters:
- Duration: {{ duration }} minutes (~{{ (duration * 180) | int }} words)
- Topic: {{ topic }}
- Focus Areas: {{ angles }}
1. Knowledge Brainstorming
- Map the landscape of available knowledge
- Identify key principles and frameworks
- Note major debates and perspectives
- List relevant examples and applications
- Consider historical context and development
2. Content Development
- Draw from comprehensive knowledge base
- Present balanced viewpoints
- Support claims with clear reasoning
- Connect topics logically
- Build understanding progressively
3. Presentation
- Break down complex concepts for general audience
- Use relevant analogies and examples
- Address anticipated questions
- Provide necessary context throughout
- Maintain factual accuracy, especially with numbers
- Cover all focus areas comprehensively within time limit
Develop a thorough exploration of each topic using available knowledge. Begin with careful brainstorming to map connections between ideas, then build a clear narrative that makes complex concepts accessible while maintaining accuracy and completeness.
"""7. 再接下来要将大纲转化为对话:
# Template for converting transcript to dialogue format
PODCAST_TRANSCRIPT_TO_DIALOGUE_PROMPT_STR = """
Your task is to transform the provided input transcript into an engaging and informative podcast dialogue.
There are two speakers:
- **Host**: {{ speaker_1_name }}, the podcast host.
- **Guest**: {{ speaker_2_name }}, an expert on the topic.
**Instructions:**
- **Content Guidelines:**
- Present information clearly and accurately.
- Explain complex terms or concepts in simple language.
- Discuss key points, insights, and perspectives from the transcript.
- Include the guest's expert analysis and insights on the topic.
- Incorporate relevant quotes, anecdotes, and examples from the transcript.
- Address common questions or concerns related to the topic, if applicable.
- Bring conflict and disagreement into the discussion, but converge to a conclusion.
- **Tone and Style:**
- Maintain a professional yet conversational tone.
- Use clear and concise language.
- Incorporate natural speech patterns, including occasional verbal fillers (e.g., "well," "you know")—used sparingly and appropriately.
- Ensure the dialogue flows smoothly, reflecting a real-life conversation.
- Maintain a lively pace with a mix of serious discussion and lighter moments.
- Use rhetorical questions or hypotheticals to engage the listener.
- Create natural moments of reflection or emphasis.
- Allow for natural interruptions and back-and-forth between host and guest.
- **Additional Guidelines:**
- Mention the speakers' names occasionally to make the conversation more natural.
- Ensure the guest's responses are substantiated by the input text, avoiding unsupported claims.
- Avoid long monologues; break information into interactive exchanges.
- Use dialogue tags to express emotions (e.g., "he said excitedly", "she replied thoughtfully") to guide voice synthesis.
- Strive for authenticity. Include:
- Moments of genuine curiosity or surprise from the host.
- Instances where the guest may pause to articulate complex ideas.
- Appropriate light-hearted moments or humor.
- Brief personal anecdotes that relate to the topic (within the bounds of the transcript).
- Do not add new information not present in the transcript.
- Do not lose any information or details from the transcript.
**Segment Details:**
- Duration: Approximately {{ duration }} minutes (~{{ (duration * 180) | int }} words).
- Topic: {{ descriptions }}
You should keep all analogies, stories, examples, and quotes from the transcript.
**Here is the transcript:**
{{ text }}
**Please transform it into a podcast dialogue following the guidelines above.**
*Only return the full dialogue transcript; do not include any other information like time budget or segment names.*
"""8. 紧接着的部分有点意思,将之前的大纲、前一个步骤生成的对话脚本以及再前面的大纲的内容通过Prompt进行融合,进一步优化对话脚本的质量。
# Template for combining multiple dialogue sections
PODCAST_COMBINE_DIALOGUES_PROMPT_STR = """You are revising a podcast transcript to make it more engaging while preserving its content and structure. You have access to three key elements:
1. The podcast outline
<outline>
{{ outline }}
</outline>
2. The current dialogue transcript
<dialogue>
{{ dialogue_transcript }}
</dialogue>
3. The next section to be integrated
<next_section>
{{ next_section }}
</next_section>
Current section being integrated: {{ current_section }}
Your task is to:
- Seamlessly integrate the next section with the existing dialogue
- Maintain all key information from both sections
- Reduce any redundancy while keeping information density high
- Break long monologues into natural back-and-forth dialogue
- Limit each speaker's turn to maximum 3 sentences
- Keep the conversation flowing naturally between topics
Key guidelines:
- Avoid explicit transition phrases like "Welcome back" or "Now let's discuss"
- Don't add introductions or conclusions mid-conversation
- Don't signal section changes in the dialogue
- Merge related topics according to the outline
- Maintain the natural conversational tone throughout
Please output the complete revised dialogue transcript from the beginning, with the next section integrated seamlessly."""
9. 将最终的对话脚本转化为JSON格式供进一步处理:
# Template for converting dialogue to JSON format
PODCAST_DIALOGUE_PROMPT_STR = """You are tasked with converting a podcast transcript into a structured JSON format. You have:
1. Two speakers:
- Speaker 1: {{ speaker_1_name }}
- Speaker 2: {{ speaker_2_name }}
2. The original transcript:
{{ text }}
3. Required output schema:
{{ schema }}
Your task is to:
- Convert the transcript exactly into the specified JSON format
- Preserve all dialogue content without any omissions
- Map {{ speaker_1_name }}'s lines to "speaker-1"
- Map {{ speaker_2_name }}'s lines to "speaker-2"
You absolutely must, without exception:
- Use proper Unicode characters directly (e.g., use ' instead of \\u2019)
- Ensure all apostrophes, quotes, and special characters are properly formatted
- Do not escape Unicode characters in the output
You absolutely must, without exception:
- Convert all numbers and symbols to spoken form:
* Numbers should be spelled out (e.g., "one thousand" instead of "1000")
* Currency should be expressed as "[amount] [unit of currency]" (e.g., "one thousand dollars" instead of "$1000")
* Mathematical symbols should be spoken (e.g., "equals" instead of "=", "plus" instead of "+")
* Percentages should be spoken as "percent" (e.g., "fifty percent" instead of "50%")
Please output the JSON following the provided schema, maintaining all conversational details and speaker attributions. The output should use proper Unicode characters directly, not escaped sequences. Do not output anything besides the JSON."""
最后就是后续通过调用ElevenLabs的接口来生成音频了,当然里面也有些技术细节例如声音的选择等值得关注,感兴趣的读者可以自行探索。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









