






摘要:DeepSeek R1和QwQ 32B的出现突破了在家用设备上运行前沿大型语言模型(LLMs)的性能障碍。 虽然消费类硬件越来越强大,模型量化也在不断改进,但现有的端侧解决方案仍然需要GPU集群、大RAM/VRAM和高带宽,远远超出了普通家庭集群的处理能力。 本文介绍了prima.cpp,这是一个分布式推理系统,使用CPU/GPU、低RAM/VRAM、Wi-Fi和跨平台支持,在每天的家庭设备上运行70B规模的模型。 它使用mmap来管理模型权重,并引入了带有预取功能的管道环并行机制来隐藏磁盘加载。 通过模拟计算、通信、磁盘、内存(及其管理行为)和操作系统中的异质性,它为每个设备的CPU和GPU最佳地分配模型层,从而进一步减少令牌延迟。 提出了一种名为Halda的优雅算法来解决这个NP-hard分配问题。 我们在一个常见的四节点家庭集群上评估了prima.cpp。 它在30B+模型上优于llama.cpp、exo和dllama,同时将内存压力保持在6%以下。 这使得前沿30B-70B型号,如Llama 3、DeepSeek R1、Qwen 2.5和QwQ,成为家庭助理,使高级人工智能真正为个人所用。 代码是开源的,可以在https://github.com/Lizonghang/prima.cpp上找到。Huggingface链接:Paper page,论文链接:2504.08791
研究背景与目的
研究背景
随着大型语言模型(LLMs)的快速发展,其参数量级已经达到了数十亿甚至数百亿,为自然语言处理领域带来了革命性的进展。然而,这些前沿的LLMs对计算资源的要求极高,尤其是推理阶段,往往需要高端的GPU集群、大容量的RAM/VRAM以及高带宽的网络连接,这对于大多数普通用户来说是不可承受之重。尽管消费类硬件的性能在不断提升,模型量化技术也在不断改进,但现有的端侧解决方案仍然难以在家庭设备上高效地运行这些大型模型。
在此背景下,如何在低资源环境下加速LLMs的推理成为了一个亟待解决的问题。家庭设备,如笔记本电脑、台式机、手机和平板等,虽然单个设备的计算资源有限,但通过集群化的方式,可以汇聚成相当可观的计算能力。因此,探索如何利用这些日常家庭设备集群来运行大规模LLMs,具有重要的理论价值和实践意义。
研究目的
本文旨在提出一种分布式的推理系统(prima.cpp),该系统能够在低资源的日常家庭设备上高效地运行70B(700亿参数)规模的LLMs。通过充分利用家庭设备集群中的CPU/GPU资源,以及低RAM/VRAM、Wi-Fi和跨平台支持,prima.cpp旨在打破现有端侧解决方案对高端硬件的依赖,使得前沿的LLMs能够更加普及,让更多用户能够在自己的设备上享受到高级人工智能带来的便利。
研究方法
系统架构与关键技术
-
系统架构
prima.cpp是一个分布式的推理系统,它允许多个家庭设备通过Wi-Fi连接形成一个集群,共同承担LLMs的推理任务。每个设备都可以根据自己的计算资源(如CPU、GPU、RAM/VRAM等)来承担不同数量的模型层计算。系统采用了一种称为“管道环并行”的计算模式,其中设备以环形结构连接,每个设备处理完自己的模型层后,将结果传递给下一个设备,直到最后一个设备输出推理结果。
-
关键技术
-
mmap管理模型权重:为了减少内存占用,prima.cpp使用mmap(内存映射文件)来管理模型权重。这样,模型权重只有在需要时才会被加载到内存中,而不需要一次性加载整个模型到内存中,从而大大降低了内存压力。
-
管道环并行与预取机制:为了隐藏磁盘加载的延迟,prima.cpp引入了管道环并行机制,并结合了预取技术。在管道环并行中,设备以环形结构连接,每个设备可以多次参与推理过程,通过多次轮询来处理一个完整的令牌。预取机制则确保在设备开始计算之前,所需的模型层已经被加载到内存中,从而减少了磁盘I/O带来的延迟。
-
异质性建模与最优层分配:考虑到家庭设备集群中设备的异质性(如CPU/GPU性能、RAM/VRAM容量、磁盘速度等),prima.cpp建立了一个数学模型来模拟计算、通信、磁盘、内存(及其管理行为)和操作系统中的异质性。通过求解这个模型,系统可以为每个设备的CPU和GPU最优地分配模型层,从而进一步减少令牌延迟。
-
Halda算法:为了解决模型层分配这个NP-hard问题,本文提出了一种名为Halda的算法。该算法通过枚举所有可能的轮询次数(k),将原始问题转化为一系列标准的整数线性规划(ILP)问题,并通过迭代优化来找到最优解。
-
实验设置
本文在一个由四台日常家庭设备组成的集群上评估了prima.cpp的性能。这些设备包括一台Mac M1笔记本电脑、一台配备NVIDIA 3070 GPU的台式机、一台运行HarmonyOS的Mate40Pro手机和一台运行Android的Honor Pad平板电脑。实验采用了Llama系列的多个模型,包括Llama 3-8B、Llama 3-14B、Llama 3-30B等,以及最新的DeepSeek R1和QwQ 32B模型。
研究结果
性能评估
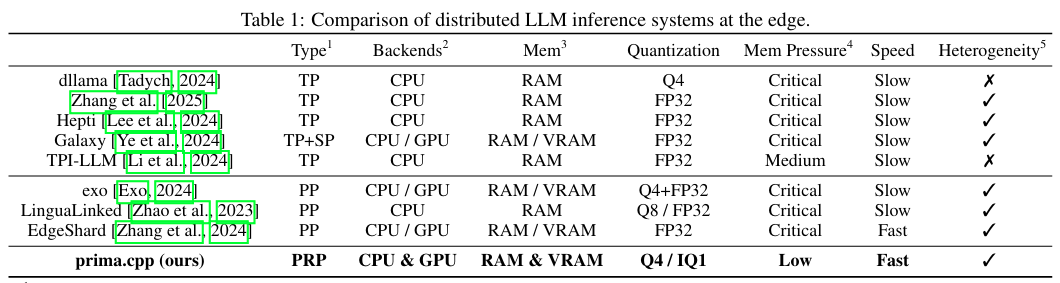
实验结果表明,prima.cpp在30B+模型上显著优于现有的端侧解决方案(如llama.cpp、exo和dllama)。具体来说,在推理速度方面,prima.cpp比llama.cpp快15倍,比exo和dllama快5-8倍。同时,prima.cpp的内存压力也远低于其他解决方案,保持在6%以下。这使得前沿的30B-70B模型(如Llama 3、DeepSeek R1、Qwen 2.5和QwQ)能够在家庭设备上高效运行,为个人用户提供高级的人工智能服务。
消融研究
本文还进行了消融研究,以评估不同组件(如Halda算法、预取机制和管道环并行)对系统性能的影响。结果表明,Halda算法通过最优地分配模型层,显著降低了令牌延迟;预取机制通过隐藏磁盘加载延迟,进一步提高了推理速度;而管道环并行则通过多次轮询来处理一个完整的令牌,充分利用了集群中的计算资源。
研究局限
尽管prima.cpp在低资源环境下加速LLMs推理方面取得了显著进展,但仍存在一些局限性:
-
设备类型与数量限制:本文的实验仅在一个由四台日常家庭设备组成的集群上进行了评估,未来需要探索更多类型的设备以及更大规模的集群。
-
推理速度仍有提升空间:尽管prima.cpp在推理速度上显著优于现有解决方案,但与云端推理相比仍有一定差距。未来需要进一步优化系统架构和算法,以提高推理速度。
-
低RAM/无SSD集群性能受限:在低RAM或无SSD的集群中,由于磁盘速度较慢,较大模型的推理速度可能会受到显著影响。未来需要研究如何在这种环境下提高推理性能。
-
内存竞争问题:当集群中运行其他应用程序时,可能会与prima.cpp产生内存竞争,导致推理速度下降。未来需要研究如何更好地管理内存资源,以减少内存竞争对推理性能的影响。
-
模型安全与合规性:随着大型LLMs的普及,模型的安全性和合规性问题也日益凸显。未来需要加强对模型的监管和审核,以防止恶意内容的传播和滥用。
未来研究方向
针对上述研究局限,未来可以从以下几个方面进行深入研究:
-
探索更多类型的设备与更大规模的集群:通过引入更多类型的设备(如智能电视、智能音箱等)以及构建更大规模的集群,可以进一步提高LLMs的推理性能,并拓展其应用范围。
-
优化系统架构与算法:通过改进系统架构和算法,如引入更高效的并行计算模式、优化模型层分配策略等,可以进一步提高推理速度并降低内存压力。
-
研究低资源环境下的推理加速技术:针对低RAM或无SSD的集群环境,研究如何通过数据压缩、模型剪枝等技术来减少内存占用和磁盘I/O延迟,从而提高推理性能。
-
内存管理机制研究:通过研究更高效的内存管理机制,如动态内存分配、内存共享等,可以减少内存竞争对推理性能的影响,并提高系统的稳定性和可靠性。
-
模型安全与合规性研究:加强对大型LLMs的安全性和合规性研究,包括模型训练数据的审核、推理结果的监控以及恶意内容的过滤等,以确保模型的合法合规使用。

















 3596
3596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









