






摘要:采用矢量量化(VQ)的掩码图像建模(MIM)在自监督预训练和图像生成方面都取得了巨大的成功。 然而,大多数现有方法都在努力解决共享潜在空间中生成质量与表示学习和效率之间的权衡问题。 为了突破这种范式的限制,我们提出了MergeVQ,它将标记合并技术融入到基于VQ的生成模型中,以在统一的架构中弥合图像生成和视觉表示学习之间的差距。 在预训练期间,MergeVQ通过编码器中自注意力块后的标记合并模块将top-k语义与潜在空间解耦,以进行后续的查找自由量化(LFQ)和全局对齐,并通过解码器中的交叉注意力恢复其细粒度的细节以进行重建。 对于第二阶段的生成,我们引入了MergeAR,它执行KV缓存压缩,以实现有效的光栅顺序预测。 在ImageNet上进行的广泛实验证实,MergeVQ作为一种AR生成模型,在视觉表示学习和图像生成任务中均取得了具有竞争力的性能,同时保持了良好的表征效率和推理速度。 代码和模型将在https://apexgen-x.github.io/MergeVQ上提供。Huggingface链接:Paper page,论文链接:2504.00999
研究背景和目的
研究背景
随着深度学习技术的发展,视觉生成和表示学习成为计算机视觉领域的重要研究方向。传统的视觉生成模型,如生成对抗网络(GANs)和变分自编码器(VAEs),在图像生成方面取得了显著进展。然而,这些方法在表示学习和生成效率方面存在局限性。特别是,在共享潜在空间中平衡生成质量和表示学习效率是一个挑战。
近年来,基于矢量量化(VQ)的掩码图像建模(MIM)方法,如BEiT,在自监督预训练和图像生成方面取得了巨大成功。这类方法通过量化连续视觉信号为离散标记,使自回归(AR)模型能够处理视觉模态。然而,现有的基于VQ的模型往往难以在生成质量和表示学习能力之间取得平衡。一方面,表示学习任务强调类间判别以最大化高级语义,而生成任务则优先重建细节。另一方面,VQ本身带来的训练障碍,如梯度近似问题,也限制了优化过程。
研究目的
本文旨在提出一种新颖的框架——MergeVQ,以突破现有基于VQ的生成模型的局限性。MergeVQ通过引入标记合并技术,在统一的架构中弥合图像生成和视觉表示学习之间的差距。具体来说,MergeVQ旨在实现以下目标:
- 高效表示学习:通过标记合并模块,将高级语义从潜在空间中解耦出来,同时保留足够的细节信息,以支持高质量的图像重建和生成。
- 高质量图像生成:利用解耦后的高级语义和标记合并带来的效率提升,实现高质量的图像生成。
- 统一的架构:设计一个能够同时支持表示学习和图像生成的统一框架,减少模型复杂性和训练成本。
研究方法
MergeVQ框架
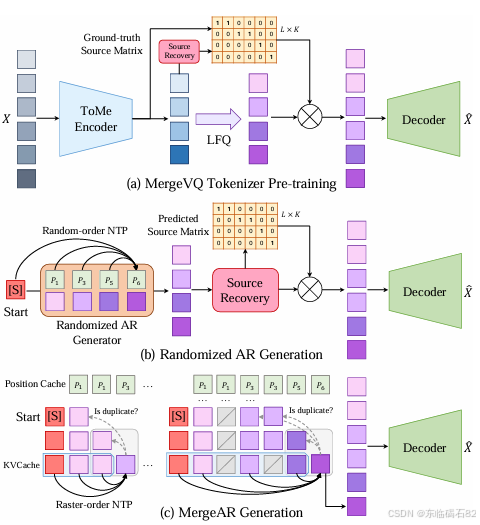
MergeVQ框架包含标记合并编码、量化、标记恢复和重建等关键组件,每个组件在实现高效和有效的视觉生成和表示学习中都发挥着重要作用。
- 标记合并编码:
- 输入图像首先通过一个CNN编码器提取特征图,然后将特征图展平为标记序列。
- 接着,使用包含标记合并模块的注意力编码器进一步压缩标记序列,同时生成一个源矩阵,该矩阵编码了合并标记和原始标记之间的空间关系。
- 量化:
- 采用查找自由量化(LFQ)方法将合并后的标记序列离散化。LFQ使用二进制向量作为码本,通过符号函数和索引计算将每个标记量化为二进制整数。
- 标记恢复和重建:
- 利用源矩阵中的空间先验信息,通过恢复模块将量化后的标记序列映射回原始长度的标记序列。
- 恢复后的标记序列通过解码器解码回像素空间,以重建原始图像。
标记合并与恢复
- 标记合并:通过迭代合并相似标记来减少标记数量,同时保留足够的空间信息。合并过程基于自注意力机制中的键(K)来计算标记之间的相似性,并选择最相似的对进行合并。
- 标记恢复:使用轻量级Transformer解码器作为源恢复模型,从量化后的标记中恢复源矩阵。在生成过程中,源恢复模型根据量化标记推断上下文,从而恢复原始标记序列。
MergeAR生成方法
为了实现高效的自回归生成,MergeVQ引入了MergeAR方法。MergeAR利用标记稀疏性和位置记录系统显著加速生成过程。在训练过程中,通过采样合并比例和引入合并指令标记来构建因果掩码。在推理过程中,利用KV缓存存储先前生成的标记的键值对,并通过去除重复标记来进一步减少内存占用和计算成本。
研究结果
实验设置
本文在ImageNet数据集上进行了广泛的实验,以评估MergeVQ在自监督预训练和图像生成方面的性能。实验中采用了三种不同配置的MergeVQ模型:
- MergeVQ (G):用于纯图像生成。
- MergeVQ (G+R):同时支持图像生成和表示学习。
- MergeVQ (R):仅用于表示学习。
自监督预训练结果
通过线性探测(Linear Probing)和端到端微调(End-to-End Fine-Tuning)实验,验证了MergeVQ在自监督预训练方面的有效性。结果表明,MergeVQ在保持较少标记数量的同时,实现了与现有方法相当甚至更优的线性探测和微调准确率。特别是MergeVQ (R)模型,在仅使用36个标记的情况下,实现了79.8%的线性探测准确率和84.2%的微调准确率。
图像生成结果
在图像生成方面,MergeVQ同样表现出色。通过比较重建保真度(rFID)和生成质量(IS),发现MergeVQ在保持高效的同时,实现了高质量的图像生成。特别是MergeVQ (G+R)模型,在结合MergeAR生成方法后,实现了具有竞争力的gFID和IS分数。
消融研究
消融研究进一步验证了MergeVQ中各组件的有效性。结果表明,标记合并模块和源恢复模型在提高生成质量和表示学习能力方面发挥了关键作用。同时,KV缓存压缩技术显著提升了生成效率。
研究局限
尽管MergeVQ在表示学习和图像生成方面取得了显著进展,但仍存在一些局限性:
- 标记合并的复杂性:标记合并过程需要仔细设计合并策略和合并比例,以平衡生成质量和效率。不同的任务和数据集可能需要不同的合并配置。
- 模型复杂性:MergeVQ框架包含多个组件,如标记合并模块、源恢复模型和KV缓存压缩技术,这增加了模型的复杂性。在实际应用中,可能需要进一步优化模型结构以提高效率和可部署性。
- 数据集依赖性:本文的实验主要在ImageNet数据集上进行,虽然ImageNet是一个广泛使用的基准数据集,但MergeVQ在其他数据集上的性能可能需要进一步验证。
未来研究方向
针对上述局限性,未来的研究可以从以下几个方面展开:
-
自适应标记合并策略:开发更智能的自适应标记合并策略,根据任务和数据集的特点动态调整合并比例和合并方式。这有助于提高模型的泛化能力和适应性。
-
模型优化与简化:进一步优化MergeVQ框架的结构和参数设置,减少模型复杂性并提高推理速度。同时,探索将MergeVQ与其他先进的生成和表示学习方法相结合的可能性。
-
跨数据集验证:在更多基准数据集上验证MergeVQ的性能,以评估其泛化能力和鲁棒性。同时,探索将MergeVQ应用于其他视觉任务(如视频生成、图像编辑等)的可行性。
-
增强可解释性:研究如何提高MergeVQ模型的可解释性,使其能够提供更直观的理解生成过程和表示学习的机制。这有助于用户更好地理解和信任模型的输出。
-
实时生成与交互:针对实际应用场景中的实时生成和交互需求,进一步优化MergeVQ的生成速度和交互性能。例如,通过引入更高效的编码器和解码器结构、利用并行计算技术等方式来提高生成效率。
综上所述,MergeVQ作为一种基于解纠缠标记合并与量化的视觉生成与表征统一框架,在表示学习和图像生成方面取得了显著进展。然而,仍存在一些局限性需要未来研究进一步解决和优化。通过持续的研究和探索,我们有理由相信MergeVQ将在更多视觉任务和应用场景中发挥重要作用。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









