






摘要:用新知识增强现有模型是人工智能发展的一个重要方面。 本文介绍了一种将新语言集成到大型语言模型(LLM)中的新方法。 我们的方法成功地将以前未见过的目标语言整合到现有的LLM中,而不会影响其先验知识。 我们通过将阿拉伯语注入一个主要用英语训练的小型开源模型中,训练了一个名为Kuwain的15亿参数的小模型。 我们的方法在阿拉伯语性能方面取得了显著改进,在各种基准测试中平均提高了8%,同时以最少的原始模型数据保留了模型的现有知识。 这为用英语和阿拉伯语训练一个综合模型提供了一个经济有效的替代方案。 研究结果突出了高效、有针对性的语言模型扩展的潜力,而无需进行广泛的再训练或资源密集型过程。Huggingface链接:Paper page,论文链接:2504.15120
研究背景和目的
研究背景
随着自然语言处理(NLP)技术的飞速发展,大型语言模型(LLM)在各种NLP任务中取得了显著进展。然而,当前的大多数LLM仍然以英语为中心,对于其他语言的支持相对有限,尤其是像阿拉伯语这样具有独特语言特性和书写系统的语言。这种英语偏向性使得LLM在多语言环境中效果不佳,尤其是在处理具有显著语言差异的任务时。尽管开源模型在NLP领域取得了重大进步,但它们在处理阿拉伯语等语言的任务时仍存在固有局限性,这可能导致误解并降低模型的有效性。
此外,训练一个能够同时处理多种语言的大型综合模型需要巨大的计算资源和数据支持,这对于许多研究机构和开发者来说是不切实际的。因此,如何以高效且经济的方式扩展LLM的语言支持能力成为了一个亟待解决的问题。
研究目的
本研究旨在提出一种新颖的方法,将新语言(如阿拉伯语)集成到现有的LLM中,同时保留模型原有的知识。具体研究目的包括:
- 扩展语言支持:探索如何有效且高效地扩展单语言LLM以支持新语言,同时最小化成本。
- 保留原始语言性能:研究如何在引入新语言能力的同时,保持LLM原有的语言性能和知识,而不造成任何妥协。
通过实现这些目标,本研究期望为多语言LLM的发展提供一种经济高效的替代方案,特别是在资源受限的环境中。
研究方法
数据准备
本研究的数据集由1100亿个令牌组成,其中900亿个令牌为阿拉伯语,200亿个令牌为英语。数据来源于多个公开可用的开源资源,包括CulturaX、C4和ArabicText2022等。为了确保数据的多样性和质量,数据集还包含了阿拉伯方言数据,以保留阿拉伯语的语言丰富性和地区多样性。在数据预处理阶段,对阿拉伯语数据进行了详细的清洗和过滤,包括去除损坏或不可读字符、重复字符、标记和拉长字符、空白规范化等步骤。
模型训练
本研究以TinyLlama模型为基础,通过语言注入的方法将阿拉伯语集成到模型中。具体训练方法如下:
-
模型层扩展:受Llama-Pro模型启发,本研究在TinyLlama模型的基础上添加了新的解码器层。这些新层在训练过程中是可训练的,而原始层保持冻结状态,以确保模型原有的知识不被破坏。通过实验探索了不同数量和位置的新层配置,最终确定了最优的8层扩展方案。
-
词汇表扩展:针对阿拉伯语的特点,本研究扩展了TinyLlama模型的词汇表,添加了26,000个阿拉伯语令牌,使总词汇表大小达到54,000个令牌。词汇表的扩展显著提高了模型对阿拉伯语的表示能力,减少了训练过程中的令牌化成本。
-
选择性训练:在训练过程中,仅对新添加的层进行训练,而保持原始层不变。这种选择性训练策略确保了模型在获得新语言能力的同时,不会忘记原有的知识。
研究结果
性能提升
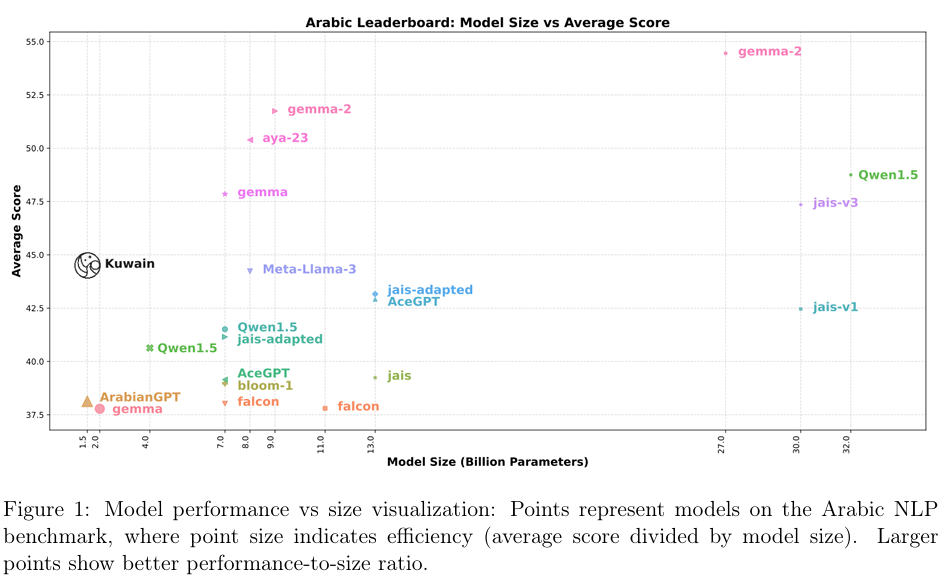
实验结果显示,通过本研究提出的方法,Kuwain模型在阿拉伯语任务上的性能得到了显著提升。在各种基准测试中,Kuwain模型相比TinyLlama模型平均提高了8%的性能。这表明,通过语言注入和模型层扩展的方法,可以有效地将新语言集成到现有的LLM中,同时提高其在新语言任务上的表现。
知识保留
除了在新语言任务上的性能提升外,Kuwain模型还成功地保留了TinyLlama模型原有的英语知识。实验结果显示,在保持20%的英语数据比例的情况下,Kuwain模型在英语基准测试上的性能与TinyLlama模型相当,甚至在某些情况下略有提高。这表明,本研究提出的方法在实现新语言集成的同时,不会损害模型原有的语言能力。
成本效益
本研究提出的方法在成本效益方面也表现出色。相比训练一个同时支持英语和阿拉伯语的综合模型,本研究的方法显著降低了训练成本和计算资源需求。通过仅训练新添加的层并保留原始层不变,本研究成功地在最小化数据使用的情况下实现了语言模型的扩展。
研究局限
尽管本研究在扩展LLM语言支持能力方面取得了显著进展,但仍存在一些局限性:
-
数据局限性:尽管本研究使用了大规模的阿拉伯语和英语数据集,但数据的质量和多样性仍有待提高。特别是在阿拉伯方言和特定领域的数据方面,仍存在较大的提升空间。
-
模型规模:本研究以TinyLlama模型为基础进行了实验,模型规模相对较小。在未来的研究中,有必要探索更大规模的模型以验证本研究方法的普适性和有效性。
-
语言覆盖:本研究主要关注了阿拉伯语的集成问题,对于其他语言的支持能力尚未进行充分验证。未来的研究可以探索将本方法应用于更多语言的可能性。
未来研究方向
针对上述研究局限,未来研究可以从以下几个方面展开:
-
大规模阿拉伯语数据收集:积极收集和处理更大规模的阿拉伯语数据,特别是阿拉伯方言和特定领域的数据,以提高模型的泛化能力和实际应用效果。
-
模型扩展与验证:将本研究提出的方法应用于更大规模的LLM中,验证其在不同模型架构和规模下的有效性和普适性。同时,探索将本方法应用于更多语言的可能性,以构建更加全面的多语言LLM。
-
性能优化与效率提升:进一步优化模型训练和推理过程中的计算效率和资源利用率,降低训练成本和部署难度。同时,探索更加高效的词汇表扩展和模型层扩展方法,以提高模型在新语言任务上的表现。
-
多语言融合与理解:深入研究多语言LLM中的语言融合和理解机制,探索如何在保持各语言独立性的同时实现跨语言的知识迁移和共享。这将有助于构建更加智能和高效的多语言处理系统。
综上所述,本研究通过提出一种新颖的语言注入和模型层扩展方法,成功地将阿拉伯语集成到现有的LLM中,同时保留了模型原有的知识。尽管存在一些局限性,但本研究为多语言LLM的发展提供了一种经济高效的替代方案,并为未来的研究提供了新的思路和方向。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









