






摘要:逻辑推理是人类智能的基本方面,也是多模态大型语言模型(MLLMs)所必需具备的一项核心能力。尽管多模态推理领域已取得显著进展,但由于现有基准缺乏对逻辑推理类型的明确分类以及对推理本身理解的不清晰,导致无法全面评估这些模型的推理能力。为解决这些问题,我们引入了MME-推理(MME-Reasoning),这是一个旨在评估MLLMs推理能力的综合基准,其问题涵盖了所有三种推理类型(即归纳推理、演绎推理和溯因推理)。我们精心策划数据,以确保每个问题都能有效评估推理能力,而非感知技能或知识广度,并扩展评估协议以涵盖对多样化问题的评估。我们的评估结果显示,当对逻辑推理能力进行全面评估时,最先进的MLLMs存在显著局限性。即使是性能最先进的MLLMs,在综合逻辑推理方面的表现也有限,且在不同推理类型之间的表现存在明显的不平衡。此外,我们还对“思维模式”和基于规则的强化学习(Rule-based RL)等通常被认为能增强推理能力的方法进行了深入分析。这些发现突显了当前MLLMs在多样化逻辑推理场景中的关键局限性和性能不平衡,为理解和评估推理能力提供了全面而系统的见解。Huggingface链接:Paper page,论文链接:2505.21327
一、研究背景和目的
研究背景:
随着人工智能技术的飞速发展,多模态大型语言模型(Multimodal Large Language Models, MLLMs)在多个领域展现出了巨大的潜力。这些模型不仅能够处理文本数据,还能结合图像、音频等多种模态的信息,进行更加复杂和全面的理解和推理。逻辑推理作为人类智能的核心组成部分,是MLLMs实现高级认知功能的关键能力之一。然而,尽管多模态推理领域已经取得了显著进展,但现有的评估基准在全面评价MLLMs的逻辑推理能力方面仍存在明显不足。
具体而言,现有基准存在以下问题:
- 缺乏明确的逻辑推理类型分类:逻辑推理通常分为归纳推理、演绎推理和溯因推理三种类型,但现有基准往往没有对这些类型进行明确区分,导致评估结果无法准确反映模型在不同推理类型上的表现。
- 评估重点偏离推理能力:许多基准更侧重于评估模型的感知技能或知识广度,而非其逻辑推理能力。这导致模型可能通过记忆或模式匹配等方式取得高分,而并非真正理解了问题的逻辑结构。
- 评估协议不完善:现有基准的评估协议往往不够全面和细致,无法充分覆盖各种复杂的逻辑推理场景。
研究目的:
针对上述问题,本研究旨在开发一个名为MME-Reasoning的综合基准,以全面、系统地评估MLLMs的逻辑推理能力。具体目标包括:
- 明确分类逻辑推理类型:将评估问题明确分为归纳推理、演绎推理和溯因推理三种类型,以便更准确地评估模型在不同推理类型上的表现。
- 聚焦推理能力评估:精心策划评估数据,确保每个问题都能有效评估模型的逻辑推理能力,而非其感知技能或知识广度。
- 完善评估协议:扩展评估协议,覆盖多样化的评估问题,包括不同难度级别和多种问题形式(如选择题、填空题、规则题等)。
- 揭示模型局限性:通过全面评估,揭示当前MLLMs在逻辑推理方面的局限性和性能不平衡,为未来的研究和改进提供指导。
二、研究方法
1. 数据收集与整理:
为了构建MME-Reasoning基准,研究团队从多个来源收集了大量与逻辑推理相关的问题,包括教科书、在线资源、逻辑练习题集以及现有基准等。收集到的问题涵盖了数学、物理、化学、生物学等多个学科领域,以及逻辑游戏、谜题等非学科性问题。
2. 问题分类与标注:
对收集到的问题进行详细分类和标注,明确每个问题所属的逻辑推理类型(归纳推理、演绎推理或溯因推理)。同时,根据问题的难度级别(简单、中等、困难)和所需的关键能力(如模式分析、规划与探索、空间与时间理解等)进行进一步细分。
3. 基准构建:
基于分类和标注结果,构建MME-Reasoning基准。该基准包含1188个精心策划的问题,全面覆盖了三种逻辑推理类型和多个难度级别。每个问题都附有详细的答案和解析,以便后续评估和分析。
4. 评估协议设计:
设计了一套完善的评估协议,包括问题呈现方式、答案提交格式、评分标准等。评估过程中,要求MLLMs以自然语言形式回答问题,并提交其推理过程(如果可能)。评分时综合考虑答案的正确性和推理过程的合理性。
5. 模型评估与对比:
使用MME-Reasoning基准对多种先进的MLLMs进行评估,包括闭源模型(如GPT-4o、Gemini-2.5等)和开源模型(如Qwen-2.5-VL、LLaVA-OneVision等)。通过对比不同模型在基准上的表现,分析其在逻辑推理方面的优势和不足。
三、研究结果
1. 模型整体表现:
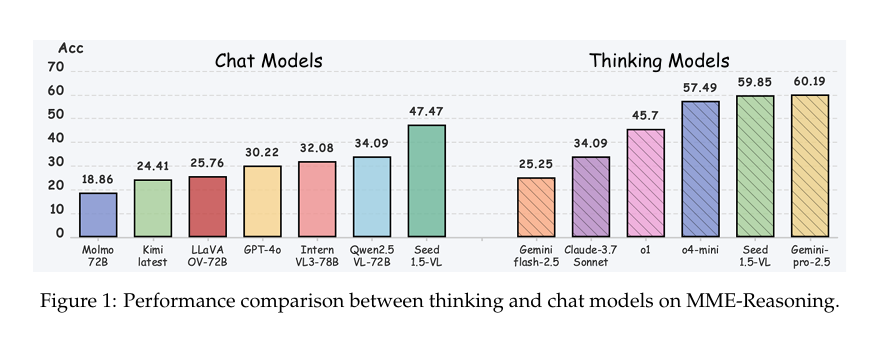
评估结果显示,即使是当前最先进的MLLMs在MME-Reasoning基准上的表现也有限。例如,表现最好的模型Gemini-2.5-Pro-Thinking的平均得分仅为60.2%,远低于人类专家的水平(83.4%)。这表明当前MLLMs在逻辑推理方面仍存在显著不足。
2. 不同推理类型的表现差异:
进一步分析发现,模型在不同推理类型上的表现存在明显差异。具体而言,模型在演绎推理上的表现相对较好,而在溯因推理上的表现则较差。这可能与溯因推理需要更多的创造性思维和假设生成能力有关,而当前MLLMs在这些方面仍存在局限。
3. 难度级别的影响:
随着问题难度的增加,模型的表现普遍下降。这表明当前MLLMs在处理复杂逻辑推理问题时仍面临挑战。特别是在需要多步推理和假设验证的问题上,模型的表现尤为不佳。
4. 思维模式与基于规则的强化学习的影响:
研究还探讨了“思维模式”(thinking mode)和基于规则的强化学习(Rule-based RL)对模型推理能力的影响。结果显示,采用“思维模式”的模型在推理过程中能够生成更长的推理链,从而在一定程度上提高了性能。然而,基于规则的强化学习方法并未能显著提升模型的推理能力,甚至在某些情况下导致性能下降。
四、研究局限
尽管MME-Reasoning基准在评估MLLMs逻辑推理能力方面取得了显著进展,但仍存在以下局限:
-
问题覆盖面的局限性:
尽管研究团队尽力收集了多样化的逻辑推理问题,但仍可能无法覆盖所有可能的逻辑推理场景。未来需要进一步扩展问题库,以更全面地评估模型的推理能力。 -
评估协议的简化性:
为了简化评估过程,研究团队对某些评估细节进行了简化处理。例如,在评估模型的推理过程时,主要关注了答案的正确性和推理链的长度,而未对推理过程的每一步进行详细分析。未来可以进一步完善评估协议,以更准确地评估模型的推理能力。 -
模型多样性的不足:
尽管评估了多种先进的MLLMs,但仍可能存在其他具有独特推理能力的模型未被纳入评估范围。未来可以进一步扩大模型评估的范围,以更全面地了解当前MLLMs在逻辑推理方面的表现。 -
对人类推理的模拟程度:
尽管MME-Reasoning基准旨在模拟人类逻辑推理的过程,但模型在基准上的表现与人类专家仍存在显著差异。这表明当前MLLMs在模拟人类推理方面仍存在不足,需要进一步研究和改进。
五、未来研究方向
针对MME-Reasoning基准的研究结果和现有局限,未来可以从以下几个方面展开深入研究:
-
扩展问题库和评估场景:
进一步扩展MME-Reasoning基准的问题库,涵盖更多学科领域和逻辑推理场景。同时,可以设计更多具有挑战性的评估问题,以更全面地评估模型的推理能力。 -
完善评估协议和方法:
改进评估协议和方法,以更准确地评估模型的推理能力。例如,可以引入更多维度的评估指标(如推理过程的合理性、创造性等),并对模型的推理过程进行更详细的分析和评估。 -
探索新的模型架构和训练方法:
针对当前MLLMs在逻辑推理方面的局限,探索新的模型架构和训练方法。例如,可以设计专门用于逻辑推理的模型架构,或采用强化学习、自监督学习等方法来提升模型的推理能力。 -
加强跨学科合作与交流:
逻辑推理是一个涉及多个学科的复杂问题。未来可以加强跨学科合作与交流,借鉴心理学、认知科学等领域的研究成果,为MLLMs的逻辑推理能力提升提供新的思路和方法。 -
关注模型的可解释性和透明度:
随着MLLMs在各个领域的广泛应用,其可解释性和透明度问题日益受到关注。未来可以研究如何提升MLLMs在逻辑推理过程中的可解释性和透明度,以便更好地理解和信任模型的决策过程。 -
推动实际应用与落地:
最终目标是将具有强大逻辑推理能力的MLLMs应用于实际场景中,解决复杂问题。未来可以加强与产业界的合作与交流,推动MLLMs在医疗、教育、金融等领域的应用与落地。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









