






摘要:大型视觉语言模型(VLM)的快速发展推动了纯视觉GUI代理的发展,该代理能够感知和操作图形用户界面(GUI),以自主完成用户指令。 然而,现有的方法通常采用离线学习框架,这面临两个核心限制:(1)严重依赖高质量的人工注释进行元素基础和动作监督,以及(2)对动态和交互式环境的适应性有限。 为了解决这些局限性,我们提出了ZeroGUI,这是一个可扩展的在线学习框架,用于以零人力成本自动化GUI代理训练。 具体而言,ZeroGUI集成了(i)基于VLM的自动任务生成,以从当前环境状态产生不同的训练目标,(ii)基于VLM的自动奖励估计,以评估任务成功,而无需手工设计的评估函数,以及(iii)两阶段在线强化学习,以持续与GUI环境交互并从中学习。 对两个先进的GUI代理(UI-TARS和Aguvis)的实验表明,ZeroGUI显著提高了OSWorld和AndroidLab环境中的性能。 代码可以在Github。Huggingface链接:Paper page,论文链接:2505.23762
文献总结:ZeroGUI: Automating Online GUI Learning at Zero Human Cost
一、研究背景和目的
研究背景:
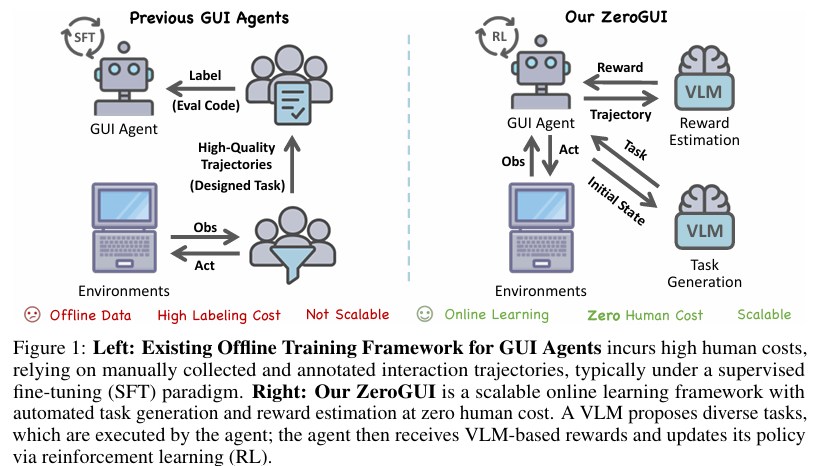
随着人工智能技术的快速发展,图形用户界面(GUI)自动化在数字任务自动化、智能副驾驶、人机交互等领域展现出巨大的应用潜力。近年来,大型视觉语言模型(VLMs)的兴起,使得纯视觉基础的GUI代理成为可能,这些代理能够感知GUI屏幕截图并执行点击、滚动、输入等操作,以完成用户提供的任务指令。然而,现有的GUI代理学习方法主要依赖于离线学习框架,这种框架面临两个核心限制:
- 高度依赖高质量的人工注释:离线学习框架需要大量高质量的人工注释来进行元素基础定位和动作监督。这些注释过程耗时费力,且难以扩展到多样化的平台和任务中。
- 对动态和交互式环境的适应性有限:现实世界中的GUI是非静态和不确定的,元素可能会移动、消失或根据系统状态表现出不同的行为。现有的GUI代理往往过度拟合于静态或狭窄定义的任务,难以在开放场景中泛化。
研究目的:
为了解决上述问题,本研究旨在开发一个可扩展的在线学习框架——ZeroGUI,以实现GUI代理训练的自动化,并消除对人工注释的需求。具体目标包括:
- 实现GUI代理训练的自动化:通过集成VLMs,实现任务生成和奖励评估的自动化,从而消除对人工注释的依赖。
- 提高GUI代理在动态和交互式环境中的适应性:通过在线学习框架,使GUI代理能够持续与GUI环境交互并学习,从而提高其对动态环境的适应性。
- 验证ZeroGUI框架的有效性:在OSWorld和AndroidLab等GUI环境中进行实验,验证ZeroGUI框架在提升GUI代理性能方面的有效性。
二、研究方法
1. ZeroGUI框架概述:
ZeroGUI框架由三个核心组件构成:基于VLM的自动任务生成、基于VLM的自动奖励评估以及两阶段在线强化学习。
- 基于VLM的自动任务生成:利用VLMs根据当前环境状态生成多样化的训练任务。这些任务通过随机初始状态截图和任务示例引导模型提出,旨在覆盖广泛的行为空间。
- 基于VLM的自动奖励评估:采用VLMs评估GUI代理完成任务的成功与否,无需手工设计的评估函数。通过轨迹截图和投票机制,提高奖励评估的精确性。
- 两阶段在线强化学习:包括在生成任务上的训练阶段和测试时的自适应阶段。在训练阶段,GUI代理通过强化学习从生成的任务中学习基本能力;在测试阶段,代理通过测试时的训练进一步适应目标测试任务。
2. 具体实现:
- 任务生成:使用GPT-4o等VLMs生成任务,每个提示包含任务示例和随机初始状态截图。为增加多样性,每次生成多个任务候选,并包含一部分不可行的任务以训练代理识别不可实现的目标。
- 奖励评估:采用Qwen2.5-VL-32B等VLMs进行奖励评估,通过所有轨迹截图的多数投票机制减少误报,提高评估的精确性。
- 强化学习:采用Group Relative Policy Optimization(GRPO)算法进行强化学习,并对其进行修改以适应多步轨迹优化和更稳定的训练。通过调整KL损失项,避免数值溢出或下溢,提高训练稳定性。
3. 实验设置:
- 评估环境:在OSWorld和AndroidLab两个GUI环境中进行评估。OSWorld包含369个任务,涵盖网页应用、桌面软件和操作系统级操作;AndroidLab包含138个测试任务,分为操作任务和查询检测任务。
- 基准模型:选择UI-TARS-7B-DPO和Aguvis-7B作为基准模型,在OSWorld和AndroidLab环境中进行训练和测试。
- 评估指标:在OSWorld中报告成功率(SR)、pass@4和all-pass@4指标;在AndroidLab中报告成功率和子目标成功率(Sub-SR)。
三、研究结果
1. OSWorld环境中的结果:
- 性能提升:ZeroGUI显著提升了UI-TARS-7B-DPO和Aguvis-7B在OSWorld环境中的性能。具体而言,UI-TARS-7B-DPO在所有任务上的成功率提高了2.5个百分点(相对提升14%),在可行子集上的成功率提高了4.5个百分点(相对提升40%)。Aguvis-7B在所有任务上的成功率提高了1.9个百分点(相对提升63%),在可行子集上的成功率提高了2.1个百分点(相对提升88%)。
- 阶段贡献:生成任务训练和测试时训练两个阶段均对性能提升有贡献。生成任务训练显著提高了pass@4指标,表明大规模多样化的生成任务有助于扩展模型的能力覆盖范围;测试时训练主要提高了all-pass@4指标,表明代理在适应目标测试任务后行为一致性得到增强。
2. AndroidLab环境中的结果:
- 性能提升:ZeroGUI同样提升了UI-TARS-7B-DPO和Aguvis-7B在AndroidLab环境中的性能。具体而言,UI-TARS-7B-DPO在操作子集上的成功率提高了2.8个百分点,在所有任务上的成功率提高了1.8个百分点。
- 泛化能力:实验结果表明,ZeroGUI框架在不同交互式GUI环境中具有良好的泛化能力。
3. 消融研究:
- 任务生成设计:移除任务示例或每次仅生成一个任务会导致测试性能下降。提供任务示例有助于使生成任务与目标领域的分布保持一致,而生成多个任务则增加了多样性,对训练数据至关重要。
- 奖励评估设计:仅使用最终截图或包含代理响应进行奖励评估会导致精确度、召回率和测试成功率降低。排除代理响应并采用投票机制可提高精确度,从而提高测试成功率。
- 强化学习训练:与离线拒绝采样微调(RFT)和在线RFT相比,在线强化学习表现出更高的性能。此外,将GRPO中的k3-KL损失替换为k2-KL损失可提高训练稳定性和测试成功率。
四、研究局限
尽管ZeroGUI框架在提升GUI代理性能方面取得了显著成果,但仍存在以下局限性:
- 对特定软件知识的依赖:VLM在判断不可行性方面存在困难,部分原因在于缺乏特定软件的详细知识。这可能导致对不可行任务的检测能力下降。
- 噪声奖励的影响:包含误报的噪声奖励可能导致模型过度自信。尽管已采取措施减少误报,但噪声奖励仍可能对模型训练产生不利影响。
- 评估环境的局限性:现有的交互式环境(如OSWorld和AndroidLab)主要提供手动设计的测试任务和验证函数。构建包含多样化任务和相关成功验证器的训练集既昂贵又不可扩展。
五、未来研究方向
针对ZeroGUI框架的局限性和当前研究的不足,未来研究可关注以下几个方面:
- 增强VLM的特定软件知识:通过引入更多特定软件的知识和数据,提高VLM在判断任务不可行性方面的能力。这有助于减少误报和漏报,提高奖励评估的精确性。
- 改进噪声奖励处理机制:研究更有效的噪声奖励处理机制,如引入更复杂的投票机制或结合其他评估方法,以减少噪声奖励对模型训练的不利影响。
- 扩展评估环境:构建包含更多样化任务和相关成功验证器的训练集,以更全面地评估GUI代理的性能。同时,探索在更多不同类型的GUI环境中应用ZeroGUI框架,以验证其泛化能力。
- 探索多模态融合方法:结合视觉、语言和其他模态的信息,进一步探索多模态融合方法在GUI代理训练中的应用。这有助于提高代理对复杂GUI环境的理解和操作能力。
- 优化强化学习算法:针对GUI代理训练的特点,优化现有的强化学习算法或开发新的算法,以提高训练效率和稳定性。例如,可以研究更有效的探索策略或奖励函数设计方法。
综上所述,ZeroGUI框架为GUI代理训练的自动化提供了一种有效的解决方案,并在OSWorld和AndroidLab等GUI环境中验证了其有效性。未来研究可进一步探索如何增强VLM的特定软件知识、改进噪声奖励处理机制、扩展评估环境、探索多模态融合方法以及优化强化学习算法等方面,以推动GUI代理技术的进一步发展。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









