







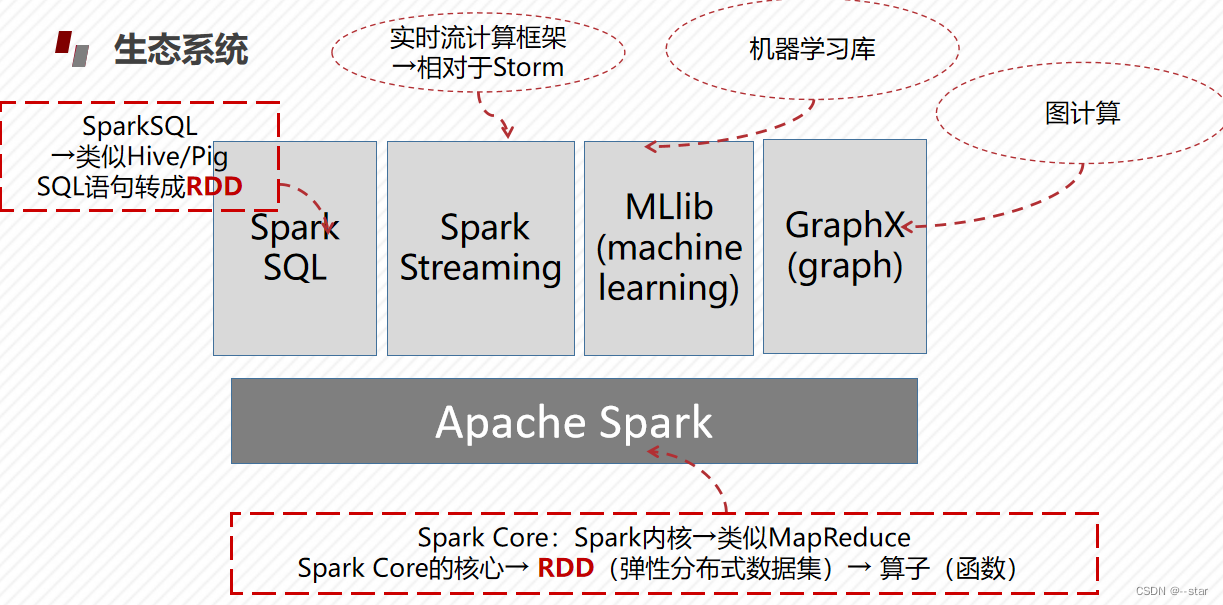
Spark 的生态系统
Spark SQL是一种结构化的数据处理模块。它提供了一个称为Data Frame的编程抽象,也可以作为分布式SQL查询引擎
Spark Streaming是一个Sprak API核心的一个存在可达到超高通量的扩展,并可处理实时数据流并容错。数据可以从许多来源Kafka,Flume,Twitter,ZeroMQ, Kinesis,TCP sockets并且可以使用复杂的算法和高级功能表示处理Map,Reduce,Join和Window。 最后,处理后的数据可以被推送到文件系统,数据库
MLlib(machine learning library)是Spark提供的可扩展的机器学习库。MLlib中已经包含了一些通用的学习算法和工具,如:分类、回归、聚类、协同过滤、降维以及底层的优化原语等算法和工具
MLlib提供的API主要分为以下两类:spark.mllib包中提供的主要API;spark.ml包中提供的构建机器学习工作流的高层次的APIGraphX在Graphs和Graph-parallel并行计算中是一个新的部分,GraphX是Spark上的分布式图形处理架构,可用于图表计算














 995
995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









