







作者:kylequ,腾讯 PCG 数据工程师
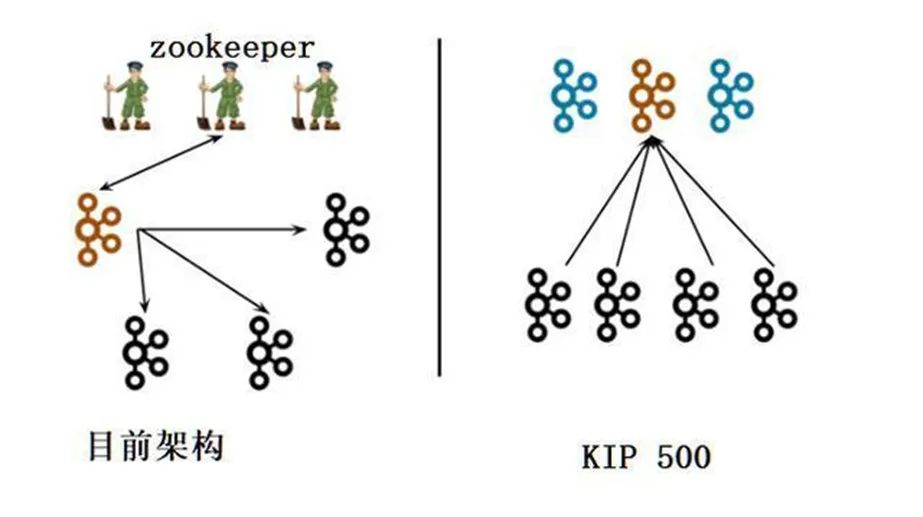
kafka3.0 的版本已经试推行去 zk 的 kafka 架构了,如果去掉了 zk,那么在 kafka 新的版本当中使用什么技术来代替了 zk 的位置呢,接下来我们一起来一探究竟,了解 kafka 的内置共识机制和 raft 算法。
1、Kafka 简介
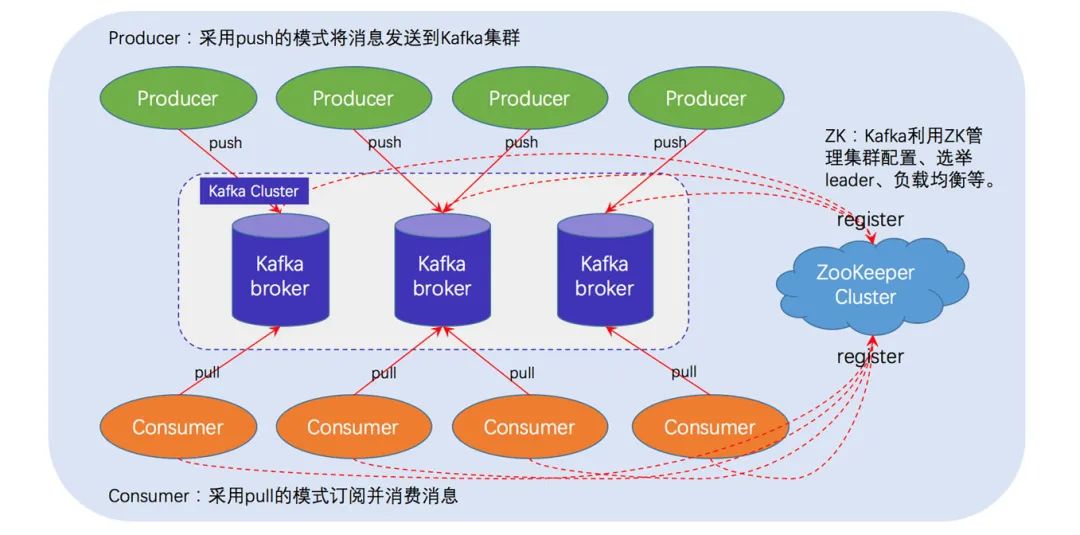
Kafka 是一款开源的消息引擎系统。一个典型的 Kafka 体系架构包括若干 Producer、若干 Broker、若干 Consumer,以及一个 ZooKeeper 集群,如上图所示。其中 ZooKeeper 是 Kafka 用来负责集群元数据的管理、控制器的选举等操作的。Producer 将消息发送到 Broker,Broker 负责将收到的消息存储到磁盘中,而 Consumer 负责从 Broker 订阅并消费消息。
1.1、Kafka 核心组件
1.producer:消息生产者,就是向 broker 发送消息的客户端。
2.consumer:消息消费者,就是从 broker 拉取数据的客户端。
3.consumer group:消费者组,由多个消费者 consumer 组成。消费者组内每个消费者负责消费不同的分区,一个分区只能由同一个消费者组内的一个消费者消费;消费者组之间相互独立,互不影响。所有的消费者都属于某个消费者组,即消费者组是一个逻辑上的订阅者。
4.broker:一台服务器就是一个 broker,一个集群由多个 broker 组成,一个 broker 可以有多个 topic。
5.topic:可以理解为一个队列,所有的生产者和消费者都是面向 topic 的。
6.partition:分区,kafka 中的 topic 为了提高拓展性和实现高可用而将它分布到不同的 broker 中,一个 topic 可以分为多个 partition,每个 partition 都是有序的,即消息发送到队列的顺序跟消费时拉取到的顺序是一致的。
7.replication:副本。一个 topic 对应的分区 partition 可以有多个副本,多个副本中只有一个为 leader,其余的为 follower。为了保证数据的高可用性,leader 和 follower 会尽量均匀的分布在各个 broker 中,避免了 leader 所在的服务器宕机而导致 topic 不可用的问题。
1.2、kafka2 当中 zk 的作用
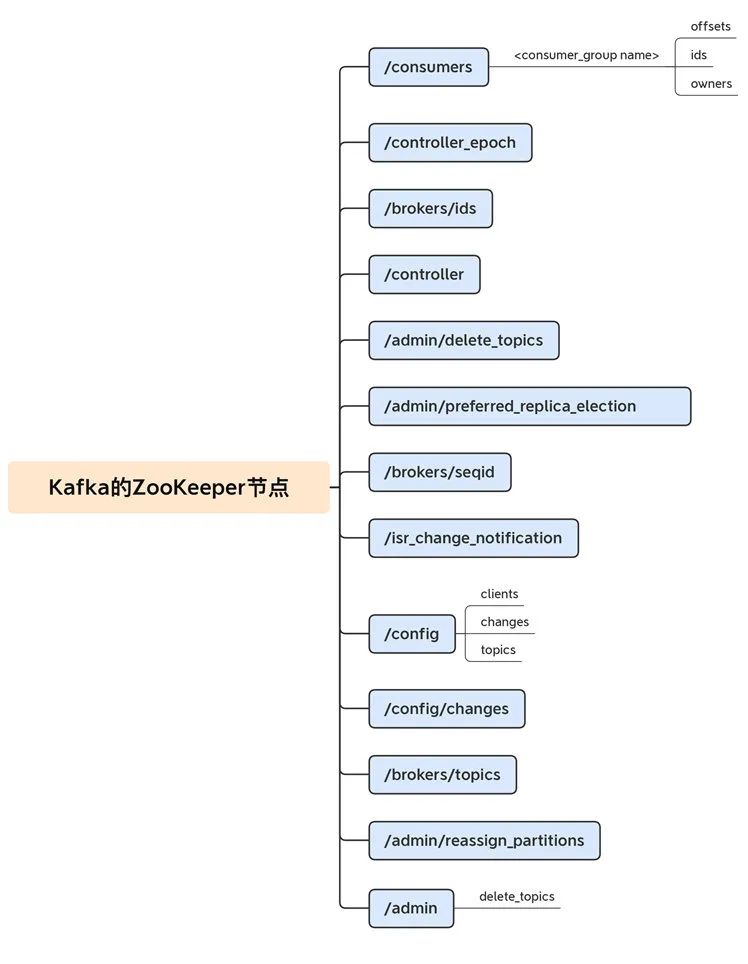
-
/admin :主要保存 kafka 当中的核心的重要信息,包括类似于已经删除的 topic 就会保存在这个路径下面
-
/brokers :主要用于保存 kafka 集群当中的 broker 信息,以及没被删除的 topic 信息
-
/cluster : 主要用于保存 kafka 集群的唯一 id 信息,每个 kafka 集群都会给分配要给唯一 id,以及对应的版本号
-
/config : 集群配置信息
-
/controller :kafka 集群当中的控制器信息,控制器组件(Controller),是 Apache Kafka 的核心组件。它的主要作用是在 Apache ZooKeeper 的帮助下管理和协调整个 Kafka 集群。
-
/controller_epoch :主要用于保存记录 controller 的选举的次数
-
/isr_change_notification :isr 列表发生变更时候的通知,在 kafka 当中由于存在 ISR 列表变更的情况发生,为了保证 ISR 列表更新的及时性,定义了 isr_change_notification 这个节点,主要用于通知 Controller 来及时将 ISR 列表进行变更
-
/latest_producer_id_block :使用
/latest_producer_id_block节点来保存 PID 块,主要用于能够保证生产者的任意写入请求都能够得到响应。 -
/log_dir_event_notification :主要用于保存当 broker 当中某些 LogDir 出现异常时候,例如磁盘损坏,文件读写失败等异常时候,向 ZK 当中增加一个通知序号,controller 监听到这个节点的变化之后,就会做出对应的处理操作。
以上就是 kafka 在 zk 当中保留的所有的所有的相关的元数据信息,这些元数据信息保证了 kafka 集群的正常运行。
2、kafka3 的安装配置
在 kafka3 的版本当中已经彻底去掉了对 zk 的依赖,如果没有了 zk 集群,那么 kafka 当中是如何保存元数据信息的呢,这里我们通过 kafka3 的集群来一探究竟。
2.1、kafka 安装配置核心重要参数
Controller 服务器
不管是 kafka2 还是 kafka3 当中,controller 控制器都是必不可少的,通过 controller 控制器来维护 kafka 集群的正常运行,例如 ISR 列表的变更,broker 的上线或者下线,topic 的创建,分区的指定等等各种操作都需要依赖于 Controller,在 kafka2 当中,controller 的选举需要通过 zk 来实现,我们没法控制哪些机器选举成为 Controller,而在 kafka3 当中,我们可以通过配置文件来自己指定哪些机器成为 Controller,这样做的好处就是我们可以指定一些配置比较高的机器作为 Controller 节点,从而保证 controller 节点的稳健性。
被选中的 controller 节点参与元数据集群的选举,每个 controller 节点要么是 Active 状态,或者就是 standBy 状态。
2.1.1、Process.Roles
使用 KRaft 模式来运行 kafka 集群的话,我们有一个配置叫做 Process.Roles 必须配置,这个参数有以下四个值可以进行配置:
-
Process.Roles = Broker, 服务器在 KRaft 模式中充当 Broker。
-
Process.Roles = Controller, 服务器在 KRaft 模式下充当 Controller。
-
Process.Roles = Broker,Controller,服务器在 KRaft 模式中同时充当 Broker 和 Controller。
-
如果 process.roles 没有设置。那么集群就假定是运行在 ZooKeeper 模式下。
如果需要从 zookeeper 模式转换成为 KRaft 模式,那么需要进行重新格式化。如果一个节点同时是 Broker 和 Controller 节点,那么就称之为组合节点。
实际工作当中,如果有条件的话,尽量还是将 Broker 和 Controller 节点进行分离部署。避免由于服务器资源不够的情况导致 OOM 等一系列的问题
2.1.2、Quorum Voters
通过 controller.quorum.voters 配置来实习哪些节点是 Quorum 的投票节点,所有想要成为控制器的节点,都必须放到这个配置里面。
每个 Broker 和每个 Controller 都必须配置 Controller.quorum.voters,该配置当中提供的节点 ID 必须与提供给服务器的节点 ID 保持一直。
每个 Broker 和每个 Controller 都必须设置 **controller.quorum.voters**。需要注意的是,controller.quorum.voters 配置中提供的节点 ID 必须与提供给服务器的节点 ID 匹配。
比如在 Controller1 上,node.Id 必须设置为 1,以此类推。注意,控制器 id 不强制要求你从 0 或 1 开始。然而,分配节点 ID 的最简单和最不容易混淆的方法是给每个服务器一个数字 ID,然后从 0 开始。
2.2、下载并解压安装包
bigdata01 下载 kafka 的安装包,并进行解压:
[hadoop@bigdata01 kraft]$ cd /opt/soft/
[hadoop@bigdata01 soft]$ wget http://archive.apache.org/dist/kafka/3.1.0/kafka_2.12-3.1.0.tgz
[hadoop@bigdata01 soft]$ tar -zxf kafka_2.12-3.1.0.tgz -C /opt/install/
修改 kafka 的配置文件 broker.properties:
[hadoop@bigdata01 kafka_2.12-3.1.0]$ cd /opt/install/kafka_2.12-3.1.0/config/kraft/
[hadoop@bigdata01 kraft]$ vim broker.properties
修改编辑内容如下:
node.id=1
controller.quorum.voters=1@bigdata01:9093
listeners=PLAINTEXT://bigdata01:9092
advertised.listeners=PLAINTEXT://bigdata01:9092
log.dirs=/opt/install/kafka_2.12-3.1.0/kraftlogs
创建两个文件夹:
[hadoop@bigdata01 kafka_2.12-3.1.0]$ mkdir -p /opt/install/kafka_2.12-3.1.0/kraftlogs
[hadoop@bigdata01 kafka_2.12-3.1.0]$ mkdir -p /opt/install/kafka_2.12-3.1.0/topiclogs
同步安装包到其他机器上面去
2.3、服务器集群启动
启动 kafka 服务:
[hadoop@bigdata01 kafka_2.12-3.1.0]$ ./bin/kafka-storage.sh random-uuid
YkJwr6RESgSJv-sxa1R1mA
[hadoop@bigdata01 kafka_2.12-3.1.0]$ ./bin/kafka-storage.sh format -t YkJwr6RESgSJv-sxa1R1mA -c ./config/kraft/server.properties
Formatting /opt/install/kafka_2.12-3.1.0/topiclogs
[hadoop@bigdata01 kafka_2.12-3.1.0]$ ./bin/kafka-server-start.sh ./config/kraft/server.properties
2.4、创建 kafka 的 topic
集群启动成功之后,就可以来创建 kafka 的 topic 了,使用以下命令来创建 kafka 的 topic
./bin/kafka-topics.sh --create --topic kafka_test --partitions 3 --replication-factor 2 --bootstrap-server bigdata01:9092,bigdata02:9092,bigdata03:9092
2.5、任意一台机器查看 kafka 的 topic
组成集群之后,任意一台机器就可以通过以下命令来查看到刚才创建的 topic 了
[hadoop@bigdata03 ~]$ cd /opt/install/kafka_2.12-3.1.0/
[hadoop@bigdata03 kafka_2.12-3.1.0]$ bin/kafka-topics.sh --list --bootstrap-server bigdata01:9092,bigdata02:9092,bigdata03:9092
2.6、消息生产与消费
使用命令行来生产以及消费 kafka 当中的消息
[hadoop@bigdata01 kafka_2.12-3.1.0]$ bin/kafka-console-producer.sh --bootstrap-server bigdata01:9092,bigdata02:9092,bigdata03:9092 --topic kafka_test
[hadoop@bigdata02 kafka_2.12-3.1.0]$ bin/kafka-console-consumer.sh --bootstrap-server bigdata01:9092,bigdata02:9092,bigdat 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2497
2497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









